一种基于混合模型的短期电价预测方法
2023-09-26谷新梅邓尚云严海贤
王 超,陈 奇,谷新梅,姜 湖,郭 芳,邓尚云,严海贤
(1.广州南方投资集团有限公司,广州 510663;2.中国能源建设集团广东省电力设计研究院有限公司,广州 510663;3.广东科诺勘测工程有限公司,广州 510663;4.佛山科学技术学院 机电工程与自动化学院,广东 佛山 528000)
0 引言
在电力市场中,电能可以像其他普通商品一样在市场环境下自由交易,因此能够反映电力供求关系的电价成为电力市场的重要因素之一[1-2]。近年来,许多研究人员已经证明,要实现电价精准预测的难度很大,因为电价在很大程度上取决于多种因素[3]。精准的电价预测不仅可以提升市场在调节能源资源配置上的效率、提高电网的优化调度能力,还能为各方市场参与者制定和调整市场决策提供重要依据[4]。因此,准确的电价预测对于整个电力系统和市场参与者来说具有十分重要的参考意义[5-6]。
电价预测的方法有很多,主要可以分为统计学方法、计算智能方法和混合模型方法。统计学方法大多依赖于线性回归,主要有自回归移动平均模型(Autoregressive Moving Average Model,ARMA)[7]、自回归积分移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA)[8]以及广义自回归条件异方差(Generalized Auto Regressive Conditional Heteroskedasticity,GARCH)[9-10]等。统计学方法在捕捉电价的非线性和高波动特征方面的能力有限,难以处理复杂的非线性时间序列问题[11]。计算智能方法通过在线更新期间调整权重的方式将多元函数逼近到所需的准确度,并且可以捕捉电价的复杂且动态的非线性特征[12],因此在电价预测问题上具有优越的性能。在众多计算智能方法中,长短期记忆神经网络(Long Short-Term Memory,LSTM)因其能够有效发掘时间序列的内部规律以及拟合非线性数据的优点,在预测领域得到众多学者的关注[13-15]。
在过去的几年中,受到学术界关注最多的方法是混合模型。然而单一的计算智能方法仍然忽略了电价序列中所包含的一些重要信息,其处理电价序列中的非线性及高波动性特征的能力还有提升的空间。混合模型方法具有强大的数据处理能力和挖掘电价数据特征信息的能力,一般由数据分解方法与预测模型组合而成[16]。在数据分解方法中,小波变换(Wavelet Transform,WT)[17-18]、经验模态分解(Empirical Mode Decomposition,EMD)[19]以及一些改进的方法如快速集成经验模态分解(Fast Integrated Empirical Mode Decomposition,FIEMD)[20]等已被广泛使用。虽然EMD 可以取得比WT 更好的结果,但它存在末端效应以及模态混叠的问题,影响EMD 的分解精度[21]。变分模态分解(Variational Mode Decomposition,VMD)能够实现自适应分解,很好地解决了EMD 末端效应和模态混叠问题[22]。在预测模型方面,LSTM成为众多学者们的选择,但LSTM只能从单方向上获取时序信息,被LSTM遗忘的信息中可能存在着重要的时序特征信息。
为了有效处理电价序列中的非线性以及高波动性特征,改善LSTM 只能从单向获取时序信息的问题,本文实现了一种由VMD和WOA-ATT-BiLSTM组成的混合电价预测模型。该模型结合了VMD 在数据分解方面以及双向长短期记忆神经网络(Bidirectional Long Short-Term Memory,BiLSTM)在处理时间序列方面的优势。针对电价序列存在的非线性、高波动性特征,本文使用VMD 分解将原始的电价序列分解成多个子序列以便使预测模型能够更容易提取到电价序列中的特征信息;并且采用了能够从正反两个方向提取时序信息的BiLSTM作为预测模型。另外,在BiLSTM 中加入了能够对输入特征进行动态加权从而突出重要特征的注意力机制(Attention Mechanism,ATT),以提高模型的收敛速度和训练效率。最后采用鲸鱼算法(Whale Optimization Algorithm,WOA)对ATT-BiLSTM 模型的超参数进行迭代寻优,以提高模型的整体预测效果。
1 理论方法
1.1 VMD分解
文献[23]证明了将原始序列分解为多个子序列的方法有助于提高预测结果的准确性。同理,将该思想应用到电价预测问题中,将电价序列分解成多个子序列后再进行预测重构,可以提高最终的预测精度。VMD是一种完全非递归的自适应分解方式,该方法认为信号是由多个子信号叠加而成的,在获取序列信号的子序列过程中,通过搜寻变分模型最优解来确定每个子序列的频率中心和带宽,从而能够将原始序列信号有效地、自适应地分离成多个不同频率的子序列。原始电价序列经过VMD 分解后便能够转化为一组相对稳定且更为规律的子序列,原始电价序列中所含有的非线性、高波动性特征也随分解过程转化为子序列中相对平稳的、更为清晰的特征。因此,神经网络能够更容易地去捕捉、学习这些特征,从而增强预测效果。VMD模型的具体构造步骤为:
(1)利用Hilbert 变换获取每个模态函数uk( )
t的解析信号,得到其单边频谱。
(2)将各模态解析信号与对应的中心频率e-jwk混合,以将其频谱调制到相应的基频带。
(3)根据高斯平滑度和梯度二次方准则对信号进行解调,计算梯度的二次方L2 范数,获得各分解模态的带宽,得到分解后各模态分量变分约束模型为:
式中:uk—模态分量;
wk—中心频率;
K—分解后模态分量个数;
∂t—偏导运算;
δt—Dirac分布函数;
1/(πt) —冲击响应;
f(t)—原始序列信号。
为求解上述模型,引入惩罚参数α和Lagrange乘法算子λ将上述问题转化为非约束性变分问题,表达式为:
式中:L({uk} ,{wk} ,λ) —uk、wk、λ的拉格朗日表达式;
λ(t)—拉格朗日乘子。
利用交替方向乘子法来处理式(2),并通过持续交替更新unk+1(w)、wnk+1来求解式(1)中的变分模型最优解。新的uk、中心频率wk的更新公式为:
式中:ω—频率;
+1(ω)—在频域中第n+1次迭代计算时的第k个模态函数;
—第n+1 次迭代计算时第k 个模态函数的中心频率;
(ω)、(ω)、(ω)—f(t)、ui(t)、λ(t)的傅里叶变换(ui(t)为i≠t时的模态函数);
n—迭代次数。
1.2 ATT-BiLSTM模型
1.2.1 BiLSTM
LSTM 是循环神经网络(Recurrent Neural Network,RNN)的一种变体,通过引入记忆单元来控制信息的传递,解决了RNN 存在长期时序依赖的问题,并且能够计算时间序列中各个观测值之间的依赖性,从而在长时间序列的预测问题中得到广泛应用。
记忆单元能够根据当前的输入和前一个隐藏状态来决定允许通过的信息概率,并以此来实现整个网络对数据的记忆和遗忘功能,这使得LSTM 在处理电价预测这一长时间序列问题时具有很大优势。LSTM 神经元结构如图1 所示,在LSTM 神经元内,有3 个门结构负责信息的保存和遗忘。遗忘门能够根据选择来遗忘来自上一个神经元的信息;输入门控制着当前时刻的输入保存到神经元状态中;输出门控制着当前神经元的输出。

图1 LSTM神经元结构图Fig.1 Structure of LSTM neuron
LSTM神经元的状态更新公式为:
式中:ft—t时刻的遗忘门状态;
Wf、Wi、Wo—遗忘门、输入门和输出门的权重矩阵;
WC—神经元状态更新权重矩阵;
bf、bi、bo—遗忘门、输入门和输出门的偏差矩阵;
—神经元内部候选状态;
bc—神经元状态更新偏差矩阵。
BiLSTM 在LSTM 的基础上针对双向输入进行了改进。LSTM只能在一个方向上处理电价序列数据,而BiLSTM 增加了一个反方向的LSTM 模型,如图2所示,这种结构使得BiLSTM能够从正反两个方向学习电价序列的特征,从而获取到被LSTM 忽略的信息。正反两个方向的LSTM 之间参数独立,共享网络输入,两者的输出合并后即为当前时刻网络的输出。利用双向输入,BiLSTM可以从更多角度学习电价特征信息并提高预测精度。

图2 BiLSTM网络结构图Fig.2 Structure of BiLSTM network
BiLSTM 的正、反向更新公式及组合输出公式为:
式中:htl、htr—当前时刻向前、向后的隐含层向量;
h、h—前一时刻向前和后一时刻向后的隐含层向量;
W1、W2、W3、W4—权重矩阵;
bhl、bhr—隐藏层向前、向后的偏移向量;
by—输出层偏移向量。
1.2.2 注意力机制(ATT)
注意力机制的思想借鉴了人类的视觉注意力机制,是一种分配注意力资源的手段。在人类视觉观察过程中,视觉系统可以快速扫描全局并筛选出有用的信息,即所谓的视觉焦点,同时忽略不相关信息。同理,ATT 能够将有限的计算能力集中到重点信息上,从而帮助BiLSTM 更快速有效地从电价序列中获得想要的信息,忽略干扰信息。ATT 的核心原理是根据输入元素对输出的影响对其分配不同的权重,从而筛选出重要的特征,提高BiLSTM模型的训练效率和收敛速度。本文采用Bahdanau Attention机制,其具体原理如图3所示。

图3 注意力机制原理图Fig.3 Schematic diagram of attention mechanism
定义当前时刻BiLSTM 的隐藏状态和输出为St和yt,St的计算公式为:
式中:St-1、yt-1—前一时刻BiLSTM 的隐藏状态和输出;
ct—包含前后信息的环境向量,由隐含层输出加权求得。
其中,hj—第j个隐含层输出向量;
αt,j—当前时刻各个隐含层输出的权重,其计算公式为:
式中:etj、etk—t时刻隐含层j和k的注意力分布值。
1.3 鲸鱼算法(WOA)
由于ATT-BiLSTM 模型框架中存在许多超参数,这些超参数会对模型的整体预测效果产生巨大影响。因此,为准确预测电价,本文采用鲸鱼算法来优化ATT-BiLSTM 模型框架中的超参数,以提高模型的预测效果。WOA 是一种模拟座头鲸捕食猎物行为的新型元启发式优化算法,包含围猎、攻击、寻猎三个阶段。设定鲸鱼种群数量为N,定义p 为[0,1]范围内的随机数。
1.3.1 围猎
这时p<0.5 且 |A|<1(A 为系数向量)。该算法将距离目标猎物最近或目标猎物的位置定义为种群最优的鲸鱼个体位置。其他鲸鱼个体将尝试向当前种群最优位置靠近,位置更新公式为:
式中:D—当前鲸鱼个体与最优位置之间的距离;
X*(T)—当前最优解位置向量;
X(T)—当前鲸鱼个体所处的位置向量;
X(T+1) —第T+1 次迭代时鲸鱼个体所处的位置向量;
T—迭代次数;
C—系数向量。
A 和C 的计算公式为:
r —[0,1]之间的随机向量;
Tmax—最大迭代次数。
1.3.2 攻击
这时p≥0.5。鲸鱼在狩猎时会以螺旋运动的方式向猎物游去,用公式表示为:
式中:D'—鲸鱼个体与最优位置之间的距离,
D'= |X*(T)-X(T)|;
b—定义对数螺线形状的常数;
l—均匀分布的随机向量[-1,1]。
鲸鱼种群会在一个不断缩小的圆圈内,同时沿螺旋路线游动来围绕猎物。因此,假设Pi为选择收缩包围方法的概率,1-Pi则为螺旋模型更新鲸鱼个体位置的概率。数学模型为:
当 |A |∈[- 1,1] 的值在时,鲸鱼的新位置为当前它与猎物位置之间的任意位置。当 |A |<1 时,鲸鱼会攻击猎物。
1.3.3 寻猎
这时p<0.5 且 ||A >1。鲸鱼执行随机搜索猎物的行为。通过随机选取一个鲸鱼个体的位置,并以该位置为基础来更新其他鲸鱼个体的位置,使得整个鲸鱼种群偏离该猎物,从而能够选择更为合适的猎物。这种方式能够提高WOA 的探索能力。数学模型为:
式中:Xrand—随机选取的鲸鱼个体位置的向量。
2 模型设计
2.1 ATT-BiLSTM模型结构
本文所提出的模型中ATT-BiSTM 部分的结构如图4 所示,由数据输入、BiLSTM 层、ATT 层、全连接层和输出层构成。ATT层的加入能够保留编码器输入序列的中间输出结果,然后训练模型选择性地学习这些输入。ATT 层可以对BiLSTM 层从正反两个方向捕获的序列特征进行适当的加权,并根据权重进行求和,使得整个模型得到更低的损失函数和更高的模型正确率。

图4 ATT-BiLSTM模型网络层结构Fig.4 Network layer structure of ATT-BiLSTM model
2.2 基于VMD 和WOA-ATT-BiLSTM 的模型预测框架
图5 为VMD-WOA-ATT-BiLSTM 模型的整体预测框架及流程,从左到右依次是WOA优化超参数部分、模型预测部分和数据处理部分。以模型预测部分为主线,原始电价序列经VMD自适应分解后获得多个具有不同中心频率的子序列,随后经数据归一化输入到ATT-BiLSTM 模型中。同时初始化WOA 种群并对ATT-BiLSTM 模型的超参数进行迭代寻优寻找最优参数。随后按比例将输入的数据划分为训练集和测试集,并将WOA输出的最优参数组合作为ATT-BiLSTM模型的参数进行预测得到各个子序列的预测结果,最后经反归一化再累加重构得到最终的预测值。

图5 VMD-WOA-ATT-BiLSTM模型预测流程框图Fig.5 Flowchart of VMD-WOA-ATT-BiLSTM model prediction
3 案例分析
3.1 数据准备
本文算例以法国电力市场2021年1月10日至2月20日共6周的日前现货电价数据作为数据集,包含42 d、1008个时段的电价数据,如图6所示。其中前五周作为训练集,最后一周共168 个观测点作为测试集,该数据可以从北欧电力市场公开的数据集Nordpool 获取。在输入到预测模型之前,原始电价序列经过VMD分解后得到多个子序列,分解得到的子序列经数据归一化后输入到模型中进行训练和测试。
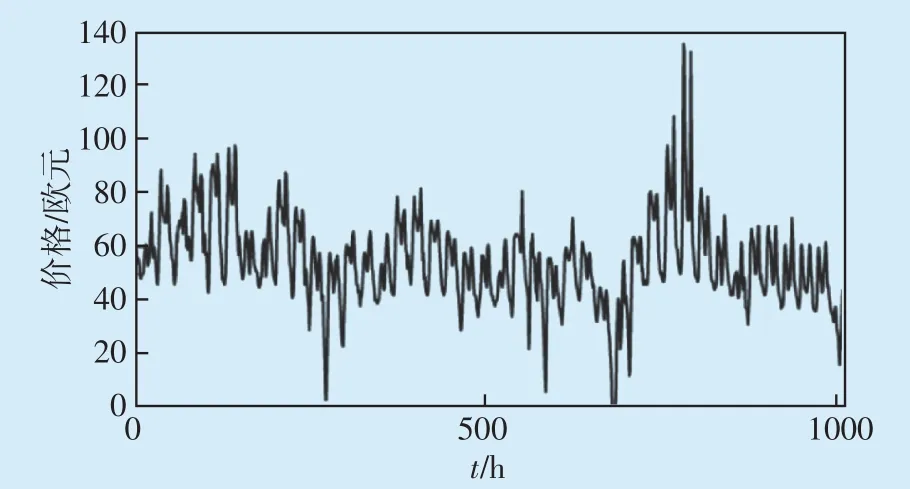
图6 原始电价序列Fig.6 Original electricity price series
为使数据更好地拟合模型,提高预测模型的预测效果,需要对分解后的各模态分量进行数据标准化处理。本文采用Min-Max 归一化方法将数据集归一化至0~1的范围。Min-Max归一化方法是对原始数据进行线性变换,令minx 为数据集的最小值,maxx 为最大值,x 的原始值x0通过Min-Max 归一化至区间[0,1]中的x'。归一化的公式为:
经过模型预测之后得到每个子序列的预测结果,需经过反归一化后再进行累和重构得到最终的预测结果。反归一化公式为:
式中:y —反归一化前子序列预测值;
Y —反归一化后子序列预测值。
3.2 预测误差指标
为评估本文方法的预测效果,采用平均绝对误差XMAE、平均绝对百分比误差XMAPE和均方根误差XRMSE来检验各预测模型的预测结果。各指标的计算公式见式(27)—(29),预测误差指标的值越小说明预测效果越好。
式中:yi—真实值;
—预测值;
n—测试集样本大小。
3.3 结果分析
为更好地评估模型的预测效果,本文采用了LSTM、BiLSTM 以及ATT-BiLSTM 模型作为对比进行预测实验,并且使用EMD 和VMD 分解比较它们在提高预测效果方面的帮助。其中LSTM模型设置了两层隐含层和一层全连接层,节点数分别为32、32、10;BiLSTM模型设置了BiLSTM层、全连接层,节点数分别为32、32、10;ATT-BiLSTM模型在BiLSTM模型的基础上增加了注意力机制层。3种神经网络模型的超参数模型的学习率均为0.001,迭代次数为100,超参数batchsize 为16。另外,EMD 和VMD 的分解个数均为6。
6 种模型的预测结果如图7 所示。从图中可以看到,相较于其他对比模型,VMD-WOA-ATT-BiLSTM模型的预测曲线能够很好地拟合实际值曲线,说明VMD-WOA-ATT-BiLSTM 能够更好捕捉到实际电价的走势,具有更高的预测精度。在对比模型中,LSTM模型与实际值曲线的拟合程度较差,且在尖峰电价时刻与实际值偏离较大。BiLSTM 模型相较于LSTM 模型具有更好的预测效果。此外,在加入了注意力机制层后,ATT-BiLSTM 模型相比于BiLSTM能更好地拟合实际值曲线,说明注意力机制层的加入有助于提高模型预测精度。同时,在添加了EMD 和VMD 分解的对比模型中可以看出,经过分解后再预测的方式能够明显提高预测的精度,并且VMD比EMD更能提高最终的预测精度。

图7 预测结果对比曲线Fig.7 Comparison curve of prediction results
为更清晰地展示各个模型的预测效果,计算了每个模型的XMAE、XMAPE、XRMSE如表1所示。VMD-WOA-BiLSTM 模型预测值在ATT-BiLSTM 模型的基础上有了显著的提升,其中XMAPE降低了3.52%,XRMSE降低了1.94 欧元/MWh,XMAE降低了1.38欧元/MWh。
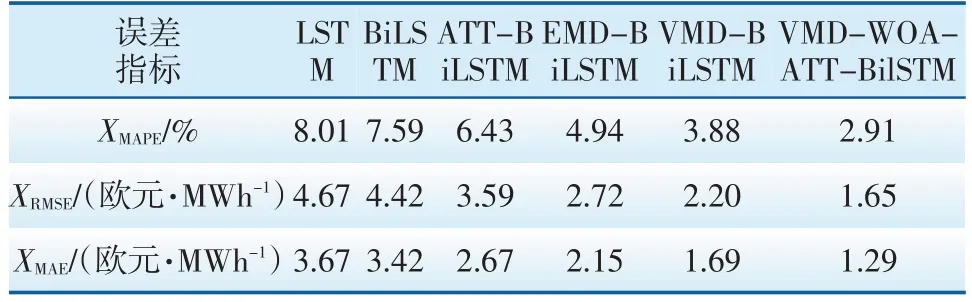
表1 不同模型的预测误差指标对比Tab.1 Comparison of prediction error indicators of different models
4 结论
电价预测是一项具有挑战性的工作,而精准的电价预测能够为市场参与者们制定市场策略提供重要的依据,以便在市场交易中降低风险或最大化利益。为有效处理电价序列中存在的非线性与高波动性特征,本文通过将VMD分解和WOA-ATTBiLSTM结合构成一个混合电价预测模型,并采用了法国电力市场的电价数据进行实验验证。通过与其他模型的对比可以得出以下结论:
(1)引入了电价序列分解方法将原始序列分解为多个子序列后能够降低电价序列的非线性特征与高波动性特征,并提高预测模型的预测效果;并且通过EMD与VMD两种分解方式的对比也说明更好的分解方式能够进一步处理电价非线性与高波动性特征。
(2)在BiLSTM 神经网络层中增加注意力机制能够使得神经网络对电价序列的中特征信息有更好的提取效果,进而改善模型的预测精度。
将分解与预测模型相结合的混合模型相较于单一的预测方法有着更为优越的预测性能,说明将不同数据处理方式与更优秀的模型相结合能够在电价预测问题上取更好的效果。
