基于机器学习的机械设备故障预测
2023-09-25聂亚珍
聂亚珍,崔 俊
(湖北师范大学 经济管理与法学院,湖北 黄石 435002)
0 引言
制造业是国民经济的主体,近十年来,嫦娥探月、祝融探火、北斗组网,一大批重大标志性创新成果引领中国制造业不断攀上新高度。作为制造业的核心,机械设备在工业生产的各个环节都扮演着不可或缺的重要角色。但是,在机械设备运转过程中会产生不可避免的磨损、老化等问题,随着损耗的增加,会导致各种故障的发生,影响生产质量和效率。实际生产中,若能根据机械设备的使用情况,提前预测潜在的故障风险,精准地进行检修维护,维持机械设备稳定运转,不但能够确保整体工业环境运行具备稳定性,也能切实帮助企业提高经济效益。
现实生活中机械设备的使用情况数据是严重不平衡的,出现故障的设备远远少于正常设备的,为了更好的学习故障设备数据,要进行样本不平衡处理。目前针对不平衡数据集的研究主要集中在分类算法层面和数据预处理层面。分类算法层面主要是代价敏感学习[1]、集成学习[2]或改进现有分类算法[3]。数据预处理层面,主要有上采样和下采样方法,下采样包括随机下采样,样本邻域选择的下采样,样本邻域清理的下采样等。上采样包括随机上采样,SMOTE上采样及其改进的算法[4],ADASYN上采样[5]。由于工业设备异常的样本远远少于正常设备,对数据集进行过采样处理是解决数据量少且不平衡的有效办法。本文采用的是ADASYN算法。
变量选择的方法很多,常用方法有过滤法、包装法、嵌入法,并且在上述方法中又有单变量选择、多变量选择、有监督选择、无监督选择。结合工业设备数据的具体特点,本文采用树模型算法输出的feature importance值结合连续变量相关性分析来进行变量选择。
二分类和多分类预测的算法有很多,Logistics算法,神经网络算法,决策树算法,支持向量机算法,KNN算法,朴素贝叶斯算法,集成学习算法等。本文采用LightGBM算法进行二分类预测,来判别机械设备是否发生故障,用决策树模型进行多分类预测,用于判别机械设备发生故障的具体类别,并通过对决策树模型的可视化研究来探究每类故障的主要成因,找出与其相关的特征属性,进行量化分析,挖掘可能存在的模式/规则。
1 算法模型相关原理
1.1 One-hot编码
One-hot编码是一种非常有效的编码方式,它将不可排序的离散变量映射到欧式空间,离散变量的每种取值就是欧式空间中的某个点,这使得距离的比较与相似度的度量可计算,并且保持了原有离散变量的等距特性。欧式距离的计算公式如下:
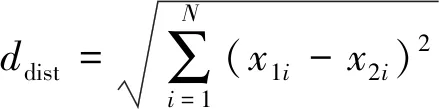
(1)
通过One-hot编码后,离散变量的每一个维度都可以看成一个连续变量。编码后的变量,其数值范围已经在[0,1],这与变量归一化效果一致。
1.2 ADASYN算法
ADASYN算法即自适应综合过采样方法。算法步骤如下:
1)计算不平衡度
记少数样本为ms,多数样本为ml,则不平衡度为:
d=ms/ml,d∈[0,1]
(2)
2)计算需要合成的样本数量
G=(ml-ms)*b,b∈[0,1]
(3)
其中b参数控制渴望的平衡水平,当b=1时,即G等于少数类和多数类的差值,此时合成数据后的多数类个数和少数类数据正好平衡。
3)计算比率r
ri=Δi/K,i=1,2,3,…,ms
(4)
分子Δi是xi(属于少数类别)的K个近邻中属于多数类别的样本数量。
4)将r归一化处理

(5)
5)计算对于xi需要生成的样本数量
6)gi个样本生成执行下面的循环:
从的K个邻近中随机选择一个少数类别xzi,合成数据样本公式如下:
si=xi+(xzi-xi)×λ
(7)
λ是[0,1]间的随机数。
1.3 相关性指标变量筛选
相关性度量的准则就是“最大相关最小冗余”,即输入变量与标签变量之间要有强相关,而输入变量之间要弱相关,以去除变量间的冗余,消除多重共线性问题。一般可以采用相关系数反映变量之间的相关性,相关系数计算公式如下:
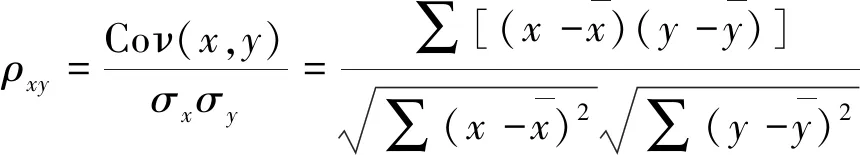
(8)
其中,Coν(x,y)是两个变量的协方差,σx为变量的标准差。协方差本身就能反映变量之间的相关性,这里除以各自的标准差是一种归一化去量纲的过程。相关系数结果的关联程度如表1所示。

表1 相关性水平
1.4 LightBGM模型变量选择
LightBGN变量选择时侧重于对变量的重要性进行排序,即LightBGM的结构构造完成后,对于每一个样本经过树结构的映射,都会经过某一个变量,则该变量的重要性就很高。反之,某一个变量组成的规则,只有很少的样本才会经过该变量,那么这个变量的重要性就很低。因此,LightGBM变量选择并没有给出选择多少变量,而是给出每个变量的重要性排序,剔除重要性低的变量。
1.5 LightGBM的基本原理
LightGBM的基本原理如下:
1)直方图算法(Histogram算法)
LightGBM采用了基于直方图的算法将连续的特征值离散化成了K个整数,构造宽度为K的直方图,遍历训练数据,统计每个离散值在直方图中的累积统计量。在选取特征的分裂点的时候,只需要遍历排序直方图的离散值。使用直方图算法降低了算法的计算代价,XGBoost采用的预排序需要遍历每一个特征值,计算分裂增益,而直方图算法只需要计算K次,提高了寻找分裂点的效率;降低了算法的内存消耗,不需要存储预排序结果,只需要保存特征离散化后的值。
但是特征值被离散化后,找到的并不是精确的分割点,会不会对学习的精度上造成影响呢?在实际的数据集上表明,离散化的分裂点对最终学习的精度影响并不大,甚至会更好一些。因为这里的决策树本身就是弱学习器,采用直方图离散化特征值反而会起到正则化的效果,提高算法的泛化能力。
大多数的决策树学习算法的树生成方式都是采用按层生长(level-wise)的策略。如图1所示:

图1 按层生长策略
不同的是,LightGBM采用了一种更为高效的按叶子生长(leaf-wise)的策略。该策略每次从当前决策树所有的叶子节点中,找到分裂增益最大的一个叶子节点,然后分裂,如此循环往复。这样的机制,减少了对增益较低的叶子节点的分裂计算,减少了很多没必要的开销。与leve-wise的策略相比,在分裂次数相同的情况下,leaf-wise可以降低误差,得到更好的精度。Leaf-wise算法的缺点是可能会生成较深的决策树。因此,LightGBM在Leaf-wise上增加了限制最大深度的参数,在保证算法高效的同时,防止过拟合。如图2所示:

图2 按叶子生长策略
3)单边梯度采样算法(Grandient-based One-Side Sampling,GOSS)
LightGBM使用GOSS算法进行训练样本采样的优化[3]。在AdaBoost算法中,采用了增加被错误分类的样本的权重来优化下一次迭代时对哪些样本进行重点训练。在GBDT算法中没有样本的权重,LightGBM算法采用了基于每个样本的梯度进行训练样本的优化:具有较大梯度的数据对计算信息增益的贡献比较大;当一个样本点的梯度很小,说明该样本的训练误差很小,即该样本已经被充分训练。然而在计算过程中,仅仅保留梯度较大的样本(例如:预设置一个阈值,或者保留最高若干百分位的梯度样本),抛弃梯度较小样本,会改变样本的分布并且降低学习的精度。GOSS算法的提出很好的解决了这个问题。
GOSS算法的基本思想是首先对训练集数据根据梯度排序,预设一个比例,保留在所有样本中梯度高于该比例的数据样本;梯度低于该比例的数据样本不会直接丢弃,而是设置一个采样比例,从梯度较小的样本中按比例抽取样本。为了弥补对样本分布造成的影响,GOSS算法在计算信息增益时,会对较小梯度的数据集乘以一个系数,用来放大。这样,在计算信息增益时,算法可以更加关注“未被充分训练”的样本数据。
4)Exclusive Feature Bundling 算法(EFB)
国内资料表明先天性听力损伤其发病率高达2‰~6‰,在目前可筛查的出生缺陷中其发病率最高[1],轻中度听力障碍均能影响患儿的语言、认知及社交能力的发展[2]。目前自动耳声发射检查(otoacoustic emission,OAE)已广泛应用于新生儿听力筛查。本所从2006年起利用耳声发射检查对本县出生的3个月内婴儿进行听力筛查,现将2006-2011年开展的听力筛查情况进行总结分析,报道如下。
LightGBM算法不仅通过GOSS算法对训练样本进行采样优化,也进行了特征抽取,以进一步优化模型的训练速度。但是这里的特征抽取与特征提取还不一样,并不减少训练时数据特征向量的维度,而是将互斥特征绑定在一起,从而减少特征维度。该算法的主要思想是:假设通常高维度的数据往往也是稀疏的,而且在稀疏的特征空间中,大量的特征是互斥的,也就是,它们不会同时取到非0值。 这样,可以安全的将互斥特征绑定在一起形成一个单一的特征包(称为Exclusive Feature Bundling)[6]。
模型评估指标Recall召回率公式如下:
其中TP是真正例即正确预测出来故障的设备数,FN为假反例即错误预测为正常的设备数。召回率衡量了在所有正例中模型正确预测的概率。
1.6 决策树模型
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy表示系统的凌乱程度,使用算法ID3,C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念[4]。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
模型评价指标准确率Acc公式如下:
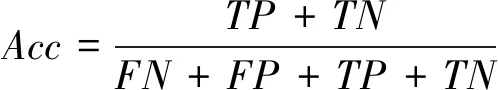
(10)
其中TP为真正例,TN为真反例,FP为假正例,FN为假反例。多分类问题需要求出所有类别的上述值然后算出平均值代入公式求出。
2 实验与结果分析
2.1 实验数据
此次实验的数据为某企业机械设备的使用情况及故障发生情况数据,用于设备故障预测及故障主要相关因素的探究。数据包含9 000行,每一行数据记录了机械设备对应的运转及故障发生情况记录。因机械设备在使用环境以及工作强度上存在较大差异,其所需的维护频率和检修问题也通常有所不同。数据提供了实际生产中常见的机械设备使用环境和工作强度等指标,包含不同设备所处厂房的室温(单位为开尔文K)记为SW1,其工作时的机器温度(单位为开尔文K)记为SW2、转速(单位为每分钟的旋转次数rpm)记为ZS、扭矩(单位为牛米Nm)记为NJ,及机器运转时长(单位为分钟min)记为SYSC。除此之外,还提供了机械设备的统一规范代码、质量等级及在该企业中的机器编号,其中质量等级分为高、中、低(HML)三个等级。对于机械设备的故障情况,数据提供了两列数据描述——“是否发生故障”和“具体故障类别”。其中“是否发生故障”取值为0/1,0代表设备正常运转,1代表设备发生故障;“具体故障类别”包含6种情况,分别是NORMAL、TWF、HDF、PWF、OSF、RNF,其中,NORMAL代表设别正常运转(与是否发生故障”为0相对应),其余代码代表的是发生故障的类别,包含5种,其中TWF代表磨损故障,HDF代表散热故障,PWF代表电力故障,OSF代表过载故障,RNF代表其他故障。
2.2 实验步骤
1)对原始数据集的离散变量机器质量等级进行One-hot编码。
2)对编码后的数据集进行ADASYN上采样。
3)对采样之后的样本进行变量筛选。
4)筛选后的数据集进行二分类模型训练;筛选后数据集去除正常样本进行多分类模型训练。
5)对多分类模型可视化,并进行成因分析。
流程图如图3所示:
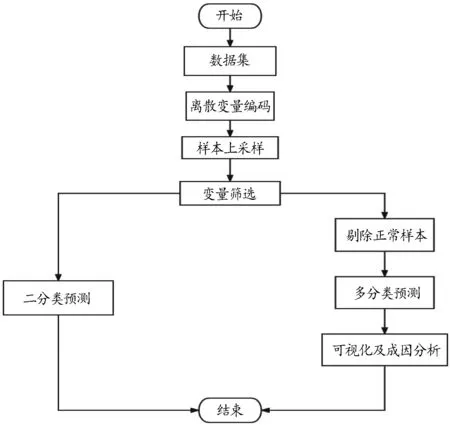
图3 流程图
2.3 实验结果
对离散变量机器质量等级进行One-hot编码结果如表2所示:

表2 机器质量等级的One-hot编码
ADASYN上采样结果如图4所示:
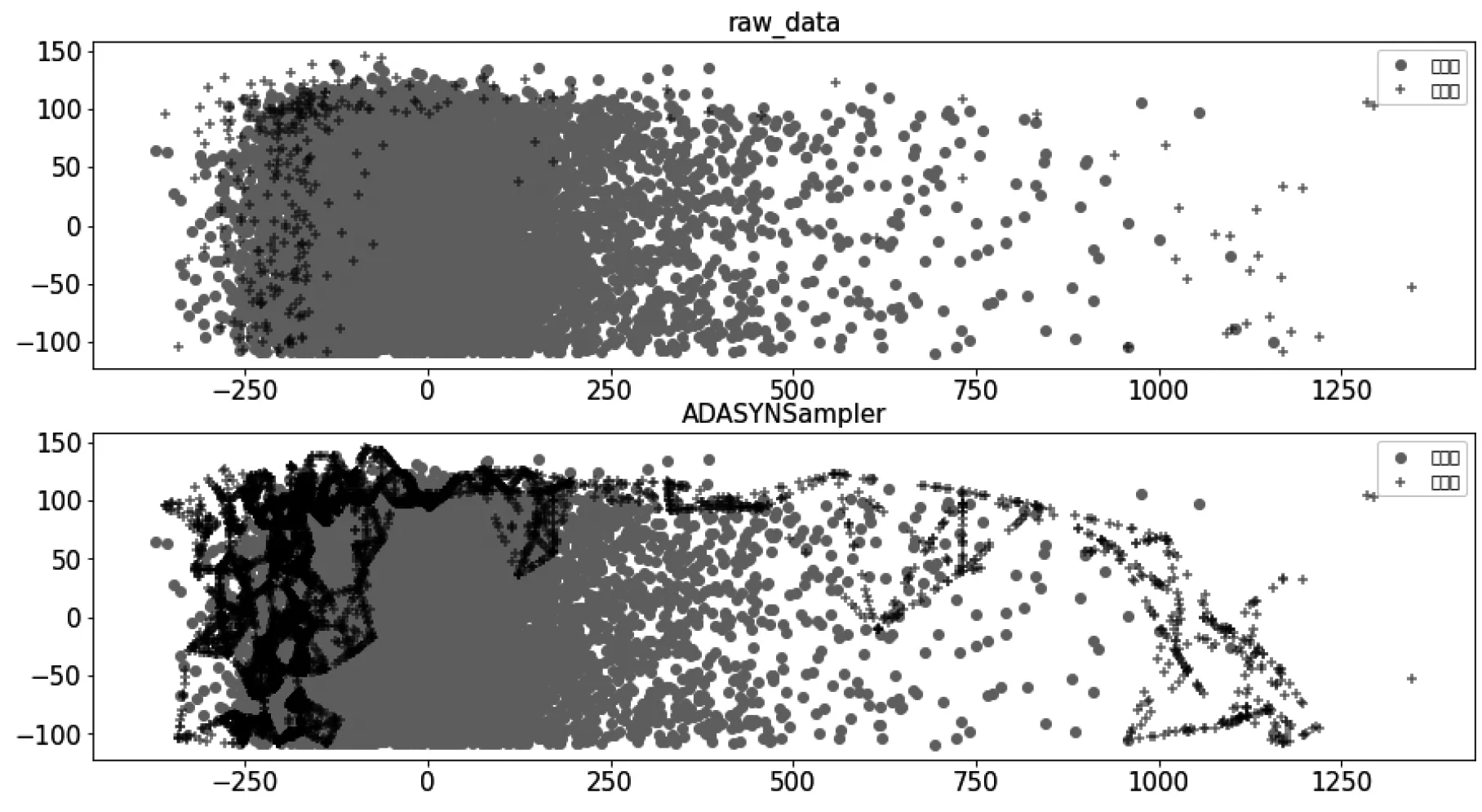
图4 采样前后对比图
连续变量相关性分析如表3所示。
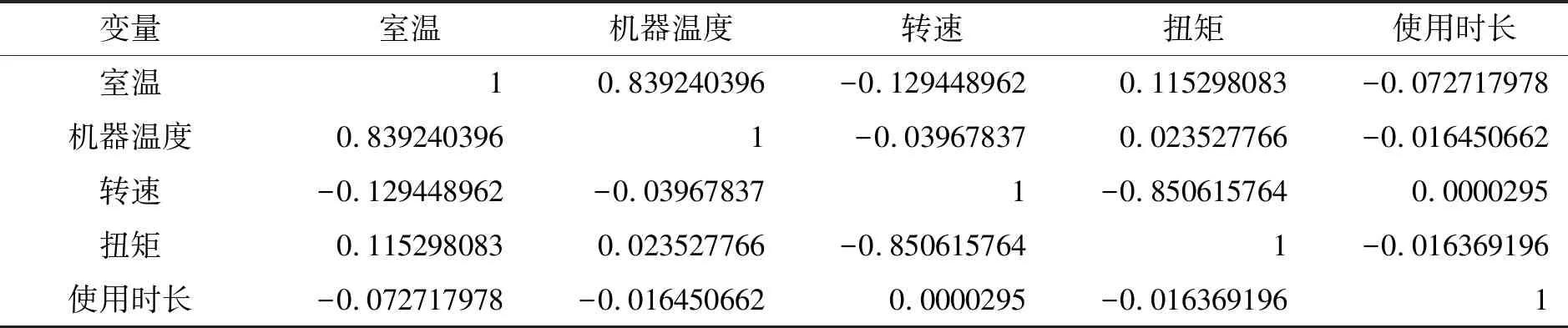
表3 变量之间相关系数
可以看到室温和机器温度的相关系数为0.839,表示两者有很强的相关性,因此需要剔除其中一个变量,LightGBM算法训练数据,输出变量重要性排序如图5所示:
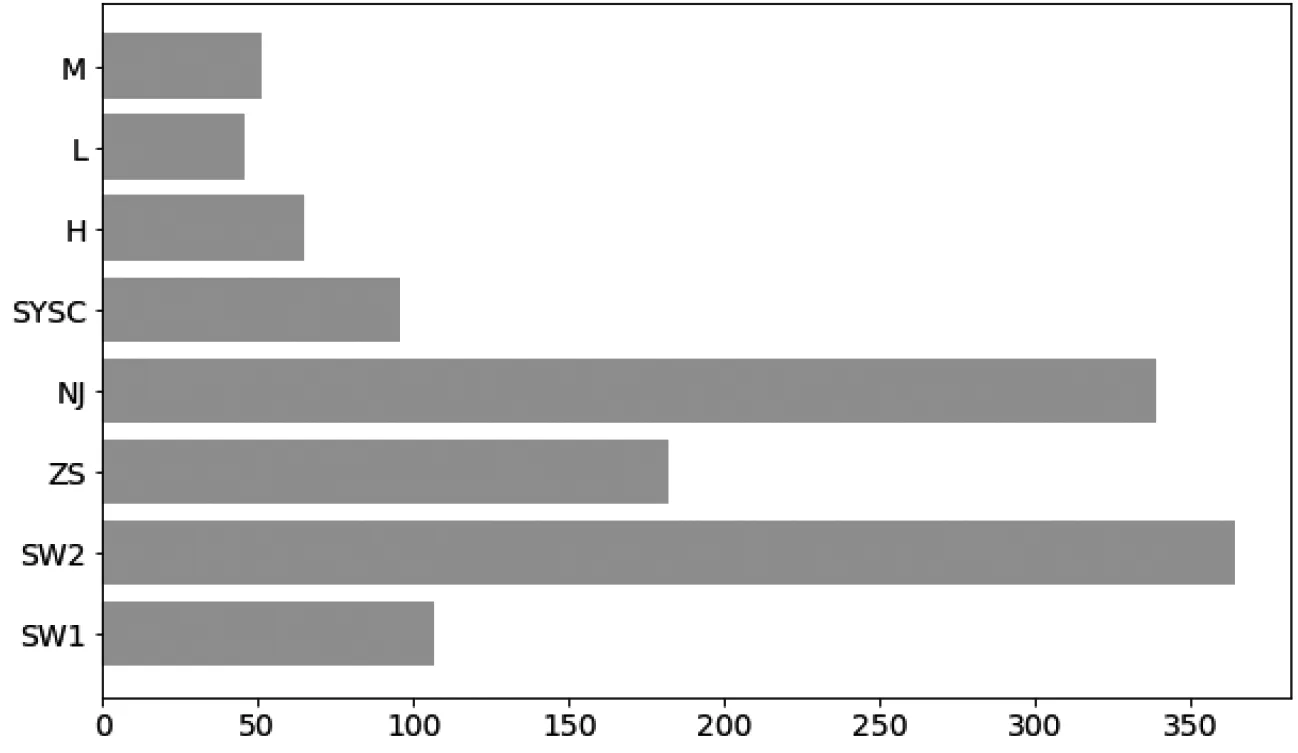
图5 变量重要性排序
可以看到SW1(室温)的重要性低于SW2(机器温度)的重要性,因此剔除室温变量。最终我们选取工作时的机器温度、转速、扭矩及机器运转时长和机器质量等级五个变量作为预测指标。
用LightGBM算法对数据进行二分类预测,最终模型评估指标Recall为0.9437.
用决策树模型进行多分类预测,最终模型评估指标Acc为0.9168.决策树模型训练结果可视化如图6所示。
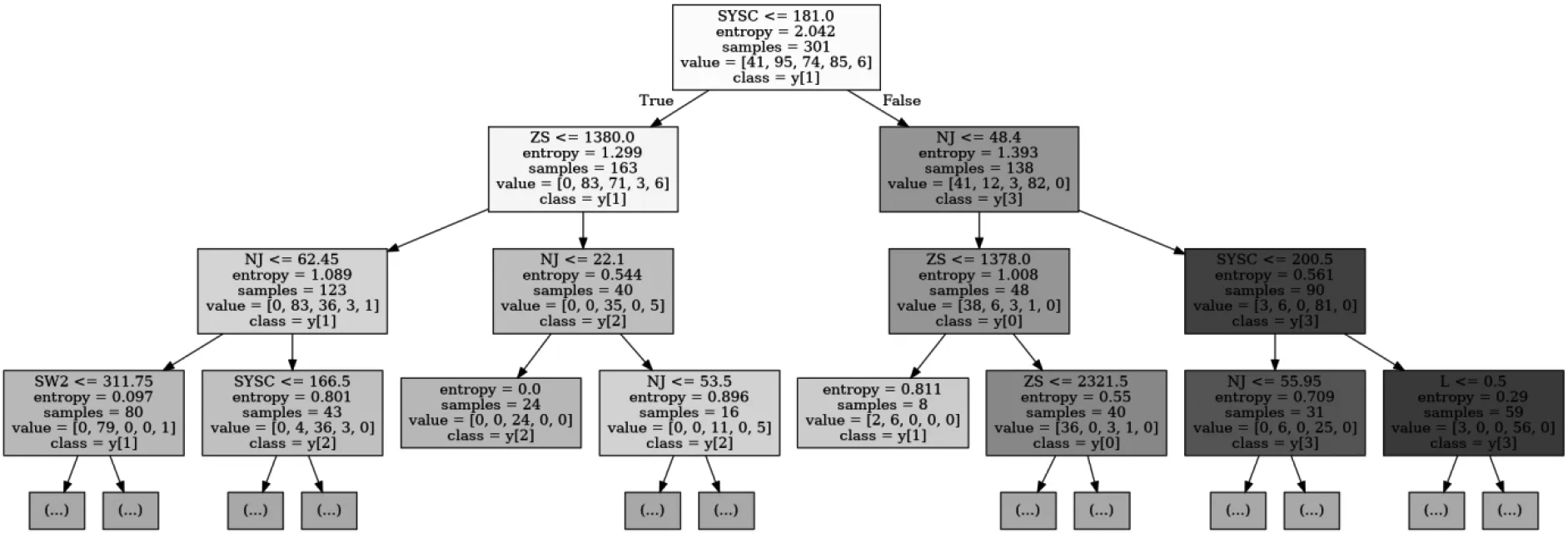
图6 决策树模型可视化
对可视化结果进行分析,可以得到不同故障类型的成因:
1)TWF因为转速过快,发生TWF故障的设备大都转速超过1 378 rpm.
2)HDF是因为工作时机器温度过高,温度都在310 K左右。
3)PWF是因为机器扭矩过小,很多都小于22 N·m.
4)OSF是因为机器工作时间过长,都在181至200分钟之间。
5)RNF具体成因未知,可能受多重因素影响。
3 总结
在实际生产中,根据机械设备的使用情况,提前预测潜在的故障风险,精准地进行检修维护,维持机械设备稳定运转,不但能够确保整体工业环境运行具备稳定性,也能切实帮助企业提高经济效益。本文通过机器学习算法对工业机械设备的使用情况数据进行建模,旨在对工业设备故障进行预测。
企业可以通过本文提出的方法分析不同故障的成因,在实际生产中,注意这些成因,合理地生产和使用机器设备,避免造成严重损失。本文还有值得进一步研究的空间,如可采用更多算法探析故障成因,挖掘更多更详细、更准的规则。
