基于矩阵填充的大型问卷调查数据缺失插补
2023-09-25高海燕李唯欣牛成英
高海燕,李唯欣,牛成英
(兰州财经大学 统计学院,甘肃 兰州 730020)
随着信息技术的发展,调查研究的媒介和手段也在不断发生改变。近年来,网络调查的兴起,为调查研究收集数据提供了便利,借助互联网收集问卷调查数据的比例增加。但几乎所有的大型问卷都不可避免地面临数据缺失的问题。例如,应答者无应答导致缺失、涉及隐私时人为处理导致缺失、文件丢失和记录不当使得数据在统计和处理阶段出现缺失、问卷过长导致应答者厌答等[1]。调查中的项目出现无应答和无效应答都会影响数据分析的质量和最终决策的准确性。因此,对问卷调查缺失数据进行插补预处理是十分重要的。
目前,针对大型问卷调查缺失数据的处理,学者们提出了一些插补方法。例如,赵雪慧[2]利用问卷分割的技术思路,将大型问卷分割成若干小型问卷,然后利用常规的多重插补方法对缺失数据进行处理。杨贵军等[3]提出一种择优回归插补方法,通过对目标变量和辅助变量之间的相关性进行分析来选取辅助变量。王霄等[4]利用聚类和排列组合等方法处理问卷,采用随机发放的策略进行数据采集,并运用多重插补对问卷采集过程中造成的数据缺失进行处理。Assmann等[5]提出一种基于贝叶斯估计的数据修复方法并应用在背景调查数据中。Kaplan等[6]对问卷数据进行了三种不同方式的抽样,相较于不同的插补方法,不同的抽样方式对减小偏差的影响更大。
矩阵填充(Matrix Completion,MC)方法作为一种处理和分析高维数据的新技术,当目标矩阵具有低秩或近似低秩性时,可以对存在大规模缺失的矩阵进行比较准确的填充,且已被广泛应用于信号处理、推荐系统、图像聚类、图像视频修复和视频背景建模等诸多研究领域。冯栩等[7]提出一种基于随机矩阵奇异值分解(Singular Value Decomposition,SVD)的奇异值阈值算法(Singular Value Thresholding,SVT),并通过对彩色图像和电影评分进行修复得到,该方法不仅有较好的数据预测效果,同时也大幅度缩短了时间。臧芳[8]利用低秩矩阵填充技术对真实气象数据进行仿真实验,通过对评价指标的计算证明该方法能较好地恢复气象数据。潘伟等[9]提出一种基于低秩矩阵填充技术的推荐算法,该方法在预测用户评分上具有良好的精度,能够进一步提高算法的性能。Gu等[10]研究了加权核范数极小化问题,利用图像的非局部自相似性,将该算法应用于图像去噪。Berg等[11]提出一种图卷积矩阵填充(GC-MC)模型,并通过在Douban、YahooMusic等多个数据集上进行实验分析,说明了该模型可以充分利用数据的辅助信息,具有较高的准确性。Bao等[12]提出一种基于SVT的矩阵补全技术。
MC方法将矩阵的秩作为一种稀疏测度,从有缺失的高维数据中探索本征低维空间,进而利用获得的本征低维空间来有效地修复缺失数据。因此,在满足某些条件下,大型调查问卷中的数据缺失插补问题可视为MC问题。如果数据的缺失机制是MAR(Missing At Random,MAR),那么插补结果将大大减少项目无应答和无效应答带来的偏差。因此,本文采用基于SVT算法的MC方法处理大型问卷调查数据中的缺失插补问题,并与热卡填充、K-近邻、链式方程多重插补、线性插值等四种常用插补方法进行对比。分析结果表明,MC方法插补效果较好,通过插补预处理可为大型问卷调查提供较为可靠的完备数据集,从而提高数据分析的质量和最终决策的准确性。
1 矩阵填充方法介绍
在MC问题中,首先假设数据间存在相关性,真实矩阵可以由低秩矩阵逼近,在此基础上,通过如下优化问题来实现MC[13]

(1)
其中,X∈m×n是修复后的低秩矩阵,M∈m×n为只观测到部分元素的待填充矩阵。Ω是观测到的元素对应位置(i,j)的集合,即若矩阵M中的元素Mij被观测到,则有(i,j)∈Ω.
由于式(1)的求解是NP-hard的[14],因此将通过求解矩阵核范数最小化问题近似恢复原始矩阵[15],并采用SVT算法。依据拉格朗日乘子定理,通过软阈值算子对迭代矩阵进行SVD,利用梯度下降方法构造迭代更新公式。以此来求解MC问题
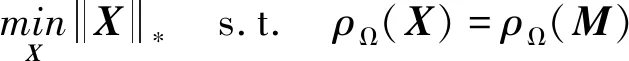
(2)
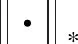
它是矩阵在观测矩阵上的投影,即用0替换X的缺失值,只留下可观测值。进一步,式(2)可转化为优化问题

(3)

对于式(3),设秩为r的矩阵X的SVD为
X=U∑VT
其中,∑=diag(σ1,…,σr)是对角矩阵,σi是正奇异值,U∈m×r,V∈n×r是列正交矩阵,并且rank(Xm×n)=r Sλ(X)=UDλ(∑)VT 其中,Dλ(∑)=diag((σ1-λ)+,(σ2-λ)+,…,(σr-λ)+),(x)+=max(x,0)表示取正部。 给定参数λ>0和初始值Y0=0,求解式(3)的迭代公式如下 (4) 其中,δk(k∈+)是正的标量步长序列,k为当前迭代次数。 表1 基于SVT算法的MC方法求解过程 本文选用中国国家调查数据库(CNSDA)发布的2015年网民社会意识调查数据的最终版。该调查由南开大学马得勇教授主持并负责具体实施。此次调查采用网络调查方式,调查时间主要集中在2015年7~8月,调查设定每个IP地址只能应答一次问卷,避免重复答题,并且剔除了答题时间小于7~8分钟的问卷,共得到涉及110个量表项目的3 781条记录。在此,选取其中包含58个量表项目的2 581条完整数据进行实验分析。 研究表明,问卷调查数据缺失属于完全随机缺失(Missing Completely At Random,MCAR)或非随机缺失(Missing Not At Random,MNAR)的情况并非常态,因而其大多属于随机缺失(Missing At Random,MAR)[16]。基于问卷调查缺失数据是MAR的假定,本文将采用随机缺失的方式对大型问卷调查数据进行不同比例的缺失处理。 运用MC方法重构矩阵必须满足两个基本假设:低秩性和相关性。假定要恢复的矩阵是低秩的或近似低秩的,即这个矩阵是有信息冗余的,其数据分布在一个低维的线性子空间上,这为大型矩阵缺失数据插补提供了理论上的可能性。另外,MC方法对元素采样的合理性提出要求,一般要求满足均匀采样的方式。 对于问卷调查,以应答者为行,设置项目为列,将构成一个含有项目无应答和无效应答的数据矩阵,即是一个不完整、含有缺失元素的“稀疏矩阵”。同时,问卷设计的项目与项目之间、应答者看待问题的态度及认知之间都具有一定的关联性,给出的项目应答是相似的,也就是说由问卷调查数据构成的大型稀疏矩阵具有低秩性特征,抽样调查数据相对来说分布合理。因此,大型问卷调查缺失数据插补问题可视为一个MC问题,适合用MC方法实现插补。 本次具体选取包含58个量表项目的2 581条完整数据进行随机缺失处理,从而得到缺失数据矩阵。这些量表类问卷项目具有6个选项,分别标记为1至6.为了避免随机删除时造成同类型项目集中缺失的现象,我们事先根据调查内容的相似程度对58个量表项目进行了调整排序。针对上述完整数据集,分别随机删除5%、10%、20%、40%、50%的数据,后续采用五种不同的插补方法对缺失值进行预测,并通过不同的指标比较插补效果。不同缺失比例下数据的分布情况如图1所示。例如,从图1(a)中可以看出,对于缺失5%的数据集,在58个量表项目中缺失最多的前5个项目是Q20_R9、Q29_R10、Q20_R7、Q29_R8和Q19_R8,其中缺失最多的Q20_R9,在154条数据中存在缺失。并且在不同的缺失比例下,缺失最多的前5个项目也不相同。 (a) 随机缺失5%数据集 本节将MC方法与热卡填充(Hot Deck Imputation,Hot Deck)[17]、K-近邻(K-Nearest Neighbor,KNN)[18]、链式方程多重插补(Multivariate Imputation of Chained Equations,MICE)[19]和线性插值等四种具有代表性的插补方法进行了比较。实验通过R语言来实现。 针对不同比例随机缺失的数据集,采用上述五种方法对大型问卷调查数据进行实践性的插补,由于插补后的某些数据带有小数并存在一些数据大于6的情况,不符合问卷调查数据的现实要求,故将带有小数的数据进行四舍五入,并将大于6的数据取为6.经过调整后的数据统计描述如表2所示。其中标准方差=插补后方差/完整数据方差*100[20]. 表2 基于五种不同方法的插补后数据统计描述 从表2中可以看出,通过KNN插补得到的数据,方差随着缺失比例的增大而增大;通过Hot Deck和MICE插补得到的数据,无论在何种缺失比例下,方差基本不变;而通过MC方法和线性插值得到的数据,方差随着缺失比例的增大而减小,但线性插值的方差下降幅度较小。相比而言,MC方法更适合解决大规模缺失数据插补时存在的偏差问题,使方差估计更有效。 采用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square error,RMSE)作为插补评价指标,从插补误差角度对五种方法的插补效果进行比较。 表3 基于五种不同算法的数据插补效果统计分析 从表3中可以看出,无论在何种缺失比例下,MC方法的插补准确率均接近50%,当缺失比例为10%时,准确率最高,为48.69%;与MC方法准确率较为接近的是MICE,但其插补误差较大;而Hot Deck虽然有随着缺失比例升高,准确率较为稳定的特点,但准确率较低,基本维持在31%左右;KNN在缺失比例低时,插补效果较好,而当缺失比例增加到20%以上时,准确率有明显的下降趋势;线性插值无论在何种缺失比例下,都不具有较好的插补效果。同时,结合MAE和RMSE可以看出,在任何缺失比例下,MC方法都具有较小的插补误差、具备更好的插补效果,明显优于其他缺失数据处理方法。因此,MC方法的综合表现更好。因此,在对大型问卷调查缺失数据进行处理时,MC方法的精度明显高于对比方法,具有良好的适用性。 大型问卷调查数据中存在缺失是较常见的数据质量问题。应答者在应答大型问卷时由于调查项目较多、问题表述不准确或问题难度大等原因而影响应答者对调查项目的认知,导致无回答或误答,从而影响问卷数据的质量。本文着眼于大型问卷调查缺失数据的插补问题,MC方法能够借助低秩或近似低秩矩阵的已知元素合理准确地恢复出该矩阵的其他未知元素。因此,可以将缺失数据插补问题看作MC问题,并利用低秩矩阵恢复技术解决该问题。实例分析表明,在不同缺失比例下,与其他四种方法相比,MC方法都具有较高的插补准确率和较低的插补误差,有助于进一步提高数据质量。MC方法为大型问卷的大规模随机缺失修复提供了一种新的处理思路。
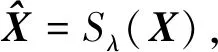

2 数据介绍与分析
2.1 数据介绍
2.2 大型问卷调查量表数据特征分析
3 实例分析
3.1 数据随机缺失处理

3.2 数据插补结果

3.3 指标比较与统计分析

4 结论
