基于深度学习视野自选择的密集匹配网路
2023-09-25张昊官恺金飞
张 昊 官 恺 金 飞
(1.中国人民解放军战略支援部队信息工程大学,河南 郑州 450000;2.西安测绘总站,陕西 西安 710000)
当前,通过光学图像密集匹配构建视差图是获得距离信息的主要方式[1],与传统方法相比,以深度学习为代表的基于数据驱动的方法在特征自动提取上具有无可比拟的优势。随着计算机硬件的发展和深度学习理论技术的完善,基于数据驱动的方法在密集匹配领域取得了一定成就。在经典的深度学习图像处理中,通常采用卷积方式提取图像特征。卷积核具有一定尺寸,称为感受野。卷积核尺寸通常采用3像素×3像素,因此所提取的特征也在3像素×3像素范围内。但图像不是在每个区域都有颜色的变化,且通常存在重复纹理、弱纹理以及无纹理的区域,直接进行卷积无法有效提取特征,易导致误匹配。针对上述问题,设计深度学习网络结构时,应针对每个像素选择最佳尺度,既能对抗弱纹理、无纹理和重复纹理,也能够避免多尺度求平均的问题。
1 网络结构设计
本文设计了一种视野自选择的密集匹配网络结构,简称视野自选择网络(AFSNet),特征提取部分采用PSMNet网络对应部分,视差计算过程采用不同扩张率的多尺度网络,对每个像素进行尺度选择,最后进行视差软回归[2],形成视差图。
网络的整体结构如图1所示。
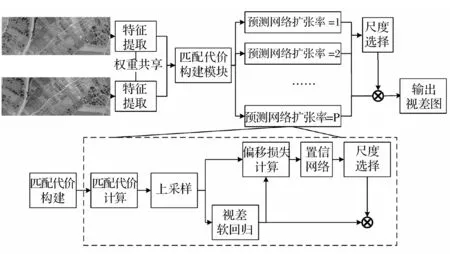
图1 自适应视野网络结构
1.1 多支路结构
由于密集匹配任务的特殊性,以SPP和ASPP为代表的多尺度叠加可能会造成不同尺度之间的相互干扰,但可以通过多个不同扩张率视野分别进行匹配,选择每个像素最佳尺寸。本文每个支路扩张率选取分为1、2、3进行实验。
1.2 偏移损失
偏移损失可用于判断合适的扩张率。偏移损失具体定义为视差范围内每个整数点位与回归视差值差的绝对值乘以该位置概率值结果的求和。对于每个像素而言,偏移损失越大,说明概率分布越分散,匹配效果越差,可能存在多个歧义点。
通过视差软回归函数计算像素点的视差回归值dmax;以视差回归值为基准,计算每个像素的偏移值的绝对值|d-dmax|;求偏移绝对值与概率乘积的和。
根据定义和计算步骤,任意像素偏移损失的计算过程为:
式中:maxdisp——最大匹配视差;d——当前视差值,0~maxdisp;i、j——图像行列坐标;k——不同扩张率的通道。
式中:Fsoftargmax——视差软回归,计算最佳视差回归值。
1.3 视野选择
明确了多支路选择标准后,可以采用带温度的softmax函数,若xk为输入张量x的第k个支路置信度测度,已选择合适的扩张率,其对应的概率为:
式中:Npath——支路的数量;c——支路置信度测度;T——温度项,温度越小,概率分布越趋近于代价c中的最大值,温度越大,概率分布越平滑。
在通道选择方面,本文设计了一种类似“注意力”模块的网络,称为视野置信度网络。其以偏移损失作为输入,通过一个三层置信网络,最终输出偏移代价。
视野置信度网络如图2所示。

图2 视野置信度网络
三层网络均采用1×1的卷积核,针对偏移损失进行微调,使其分布与网络学习到的视野权重分布相符合,最终选择出最适合的视野。
1.4 损失函数设计
多支路训练模式总损失函数定义为:
式中:Np——参与计算的支路数量;Lselect——最终生成的视差图和标签数据之间的光滑L1损失;Li——第i个支路匹配的结果标签数据之间的光滑L1损失。
Lselect和Li的定义:
式中:D——最终的预测视差图;DTrue——视差标签真值。
式中:Di——第i个通道的预测视差图。
2 实验环境
为消除随机因素可能引起的误差,实验在多个数据集上进行测试。
其中SceneFlow用于生成迁移学习所需的预训练模型;KITTI[3-4]两个数据集为近景驾驶场景数据集;Vaihingen[5]为遥感数据集。实验计算机CPU 为XEON E5-2680,显卡为GTX TITAN X 12G;在Windows10操作系统下进行,基于Pytorch深度学习框架实现。优化器采用Adam,β1和β2分别设置为0.900和0.999。
2.1 实验过程
为验证AFSNet的有效性,使用该网络在多个数据集上与DispNet、PSMNet进行了对比。
首先在SceneFlow数据集上进行10轮的预训练,然后综合考虑数据集规模和网络收敛速度设置微调的训练轮数。DispNet在KITTI的两个数据集上微调2 000 轮,Vaihingen 数 据 集400 轮;而PSMNetB、PSMNetS和AFSNet三个网络为专用密集匹配网络,在KITTI数据集上进行500轮微调,Vaihingen数据集上100轮微调。
2.2 评价指标
评价指标采用绝对终点误差(EPE)和3像素误差(3PE),两个指标能够从不同角度反映匹配误差。EPE能够反映匹配的整体精度,3PE关注误差超过3像素的点占总数百分比。
3 实验与分析
为验证提出的AFSNet的有效性,在除Scene Flow之外的三个数据集上进行了验证实验。首先在Scene Flow进行10轮的预训练,然后综合考虑数据集规模和网络收敛速度设置微调论数,微调数与实验保持一致。
精度从低到高依次是DispNet、PSMNetB、PSMNetS以及AFSNet。将实验生成的视差图进行比对,可以发现AFSNet误差图的实验效果最好,视差非连续边缘的匹配误差得到了明显改善。EPE和3PE均比其他方法有较大幅度下降。
为进一步验证各支路的以及选择器的有效性,在SceneFlow上进行了各支路的消融实验。训练过程中各个子网收敛速度相似,但由于扩张率的不同,在收敛过程中的EPE指标各异。
自适应视野网络效果对比如表1所示。
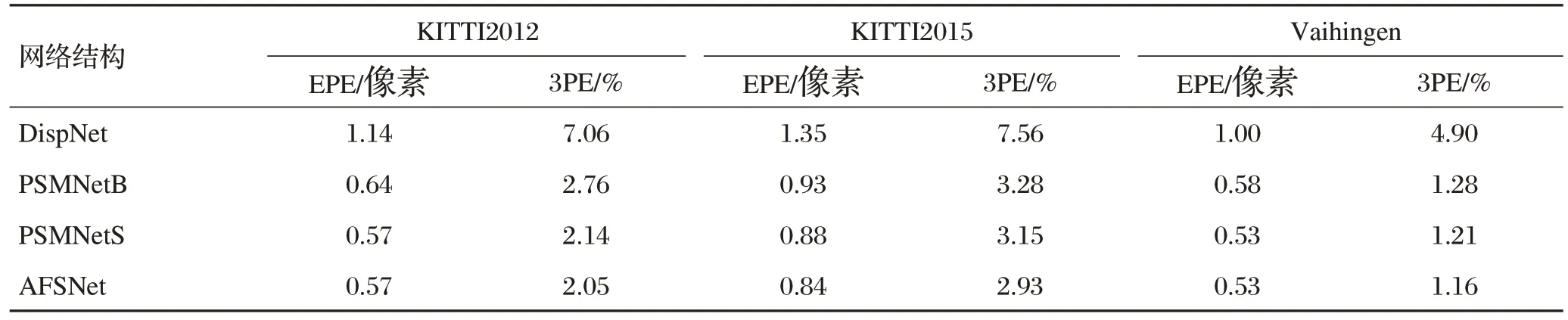
表1 自适应视野网络效果对比
各支路消融实验结果如表2所示。
最终的实验结果验证了各支路叠加的有效性,扩展率为1、2、3的支路在叠加后精度得到了提升,从侧面印证了偏移损失和置信网络能够有效选择出最佳视野。将合成结果以及各支路结果进行可视化,结果如图3所示。


图3 各支路可视化结果
从可视化结果能够看出,随着扩张率增加,匹配视差图出现网格状,导致匹配精度降低,不同扩张率在不同区域效果不一。扩张率小,整个视差图纹理精细,但对于光照区域的弱纹理、无纹理区域则难以准确匹配。最终合成的视差图精度优于多个支路单独匹配的效果。
4 结语
本文针对视差不连续边缘匹配过程多尺度信息相互干扰的问题,设计了一种视野自选择的密集匹配网络AFSNet,该网络利用偏移损失和置信网络作为选择依据,从多支路预测网络选择最佳视野,并进行了实验验证。AFSNet能够有效减少视差非连续边缘的误差,进一步提升网络匹配的精度;偏移损失和置信网络作为选择依据能够有效选择最佳尺度,实现合并后的视差图精度优于任意支路视差图精度;在参与测试的网络中,AFSNet模型泛化性整体优于其他参与测试的网络。
