改进CEEMD-SVM的轴承故障识别方法及其应用
2023-09-25谢素超李雅鑫谭鸿创
谢素超 ,李雅鑫 ,谭鸿创
(1.中南大学 轨道交通安全教育部重点实验室,湖南 长沙 410075;2.中南大学 轨道交通安全关键技术国际合作联合实验室,湖南 长沙 410075;3.中南大学 轨道交通列车安全保障技术国家地方联合工程研究中心,湖南 长沙 410075)
伴随智能运维技术的完善,软硬件设施的发展,多种新技术被引入到铁路系统当中。列车故障检测和维护扩展到了系统协同工作、大数据融合和智能维护领域。基于数据驱动的健康监测系统成为列车故障检测系统未来的发展方向[1-2]。轴承作为列车走行部中关键零部件,其工作状态直接影响列车的安全,研究轴承故障识别,提高识别效率对于实现实时故障检测,建立列车智能健康监测系统有重要意义。在列车轴承故障诊断中常使用振动信号作为媒介,而振动传感器采集到的列车轴承振动信号往往是多种信号的调制、叠加,而且实际使用的数据多为不平衡数据集,这对轴承故障特征提取和故障识别带来较大困难[3]。在常用的信号分析方法中,傅里叶变换适用于平稳线性信号分析,小波分析在数据驱动的故障诊断方法当中自适应性不高[4]。经验模态分解(Empirical Mode Decomposition,EMD)克服了小波基函数自适应低的问题。VAN 等[4]将非局域(Non-local Means,NLM)方法和EMD 相结合对轴承信号进行分解,组合时域上的数据构建特征集,构建了59维的特征向量,增加了分类器的学习负担。集合经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)[5],通过白噪声掩盖信号本身噪声,解决了EMD 分解过程中模式混叠的现象。姚德臣等[6]采用EEMD 分解小波降噪后的信号,将IMF 分量的多尺度排列熵构成特征向量,使用SA-SVM对进行分类有较好的效果。李笑梅等[7]利用EEMD对信号进行分解后提取IMF 的能量值作为特征向量,利用径向基函数神经网络中实现列车轴承故障分类。但当故障信号噪声比较大时,为减少残余噪声,需要较高的迭代次数[8]。互补经验模态分解(Complementary Ensemble Empirical Mode Decomposition,CEEMD)解决了残余噪声问题且其迭代次数远小于EEMD[9]。LIU等[10]使用CEEMD对轴承故障信号进行分解,将IMF 分量的能量矩作为特征向量,使用LDWPSO-PNN 进行分类识别。CHEN 等[11]对高速列车齿轮箱内的齿轮故障信号进行CEEMD 分解,对不同故障的齿轮状态进行诊断。支持向量机(Support Vector Machine,SVM)在小样本分类中有较好分类效果,适用于现场样本量较少的学习情况。为提高分类精度,有学者采用遗传算法、粒子群算法、最小二乘法[12-13]等进行SVM 参数优化,或者将仿生智能优化算法引入到SVM 参数优化中[14-16]。张龙等[17]提出了一种基于多尺度熵和粒子群优化的SVM 机车轴承故障识别方法,识别精度达到了99.5%以上。针对分类数据集不平衡现象,RICHHARIYA 等[18]将一元学习同SVM 相结合,并通过欠采样和过采样解决数据不平衡问题。孟宗等[19]通过数据滑动取样构造平衡数据集,并使用深度卷积网络进行故障特征提取和故障种类识别。基于上述分析,将CEEMD 应用于振动信号的自适应分解,并根据相关性系数准则筛选分解后的IMF 分量,提取能够有效表征轴承的冲击和磨损状态的特征。采用人工鱼群优化过后的SVM 分类器进行故障类型识别,通过实验验证了该方法在小样本复杂种类的轴承故障识别中有较好的分类能力,且在不平衡数据集中展现出较强的鲁棒性。
1 轴承故障特征提取
1.1 信号分解
为降低噪声影响提取出包含异常信息的振动频段,采用CEEMD 对轴承的振动信号进行分解。已知原始信号为x(t)(如图1所示),在原始信号中附加互补高斯白噪声n(t),获得2n组新的信号。
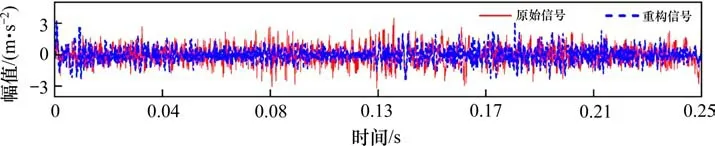
图1 原始信号以及重构信号Fig.1 Original signal and reconstructed signal
得到imfj为x(t)经过CEEMD 后的各阶本征模态函数,其中j为信号分解为本征模态函数的阶次,j=1,2,…,m。已知IMF分量同原始信号具有互相关关系,计算其同原始信号的相关性系数并进行排序:
提取相关性系数大于0.5 的IMF 分量,记作IMF=[imf1,imf2,…,imfi]。对比重构和原始信号可以看出,经过CEEMD 分解后,基于相关性重构本征模态函数的重构信号除去了一些异常高幅值的振动。重构信号与原始信号时域图形重合度较高,较好地保留了原始信号的信息[20]。
1.2 构建轴承故障特征集
按列车轴承故障形式,可将故障分为磨损类故障以及表面损伤故障。磨损类故障轴承,其振动为无规则随机的振动。表面损伤类故障,常表现为一个能量较大的宽频冲击,覆盖在原有轴承固有的振动信号当中引起谐振。在轴承故障信号中,不同的故障形式引起的冲击程度不同,将能量作为特征向量的一个要素,提取特征故障特征如下:
在轴承故障早期,时域指标对于轴承故障状态变化表现出较好的灵敏性,无量纲的时频域函数能够直观地表达出轴承在运转过程中的状态信息。其中峰值因子可以表征信号当中是否含有尖峰,峭度因子描述随机变量分布,裕度因子表征部件当中的磨损状态。因此将上述3个时域指标作为特征向量因子。N为信号长度:
虽然时频域的特征计算简单且直观,但稳定性不高,故加入频域特征进行补充。对重构信号进行短时快速傅里叶变换并计算其频率均方根:
T=(F1,F2,F3,F4,F5)为上述5 种指标构成的故障特征向量。从轴承故障振动信号特征出发,分析其较明显的时频域特征,耦合其中较为敏感且具有一定稳定性的指标构成特征向量,有利于实现高效的故障识别。
2 轴承故障特征提取
2.1 故障分类优化模型
在轴承故障类型识别阶段,常使用机器学习,深度学习模型,比如KNN,PNN 和SVM 等实现轴承的故障分类。由于SVM 在小样本学习有较好的效果,被广泛应用于轴承的故障识别。为提高SVM 参数寻优速度和质量,使用人工鱼群算法对传统SVM 进行优化改进。人工鱼群算法是一种基于鱼群觅食行为的新型仿生种群全局智能搜索算法。在一个全局范围内寻找最优解时其有较好的找寻能力以及收敛速度。使用该算法对SVM 参数寻找过程进行优化,流程图如图2所示。
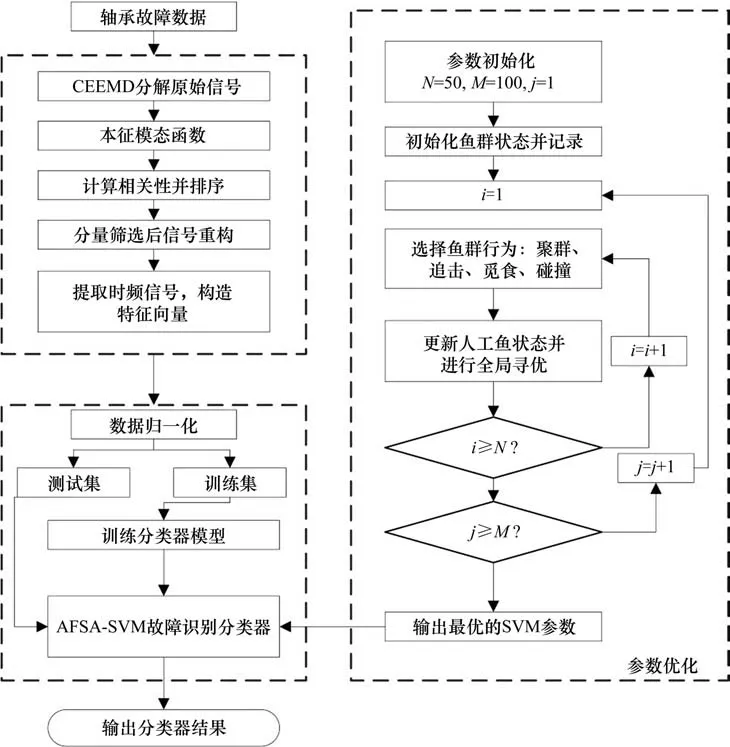
图2 轴承故障识别流程图Fig.2 Bearing failure identification flow chart
2.2 故障识别方法
基于上述分析,采用CEEMD 和SVM 实现轴承的故障特征提取和特征分类,构建了一种基于互补经验模态分解—支持向量机(CEEMD-SVM)轴承故障识别方法,具体流程如下:
1) 对原始信号进行CEEMD 分解获得IMF 分量:imf1,imf2,imf3,…,imfn;
2) 根据相关性原理,计算各个IMF 分量同原始信号的相关性系数,选取相关性较大的IMF 分量,对其进行重构,根据1.2 节的方法计算特征向量并进行归一化处理;
3) 从各个不同状态的轴承特征集中随机提取部分数据集构成平衡和不平衡训练集分别用于模型训练;
4) 剩余的数据集构成测试集测试分类器效果。
3 实验结果及分析
为验证所提出的轴承故障方法的可行性,泛化性能和优越性,分别使用美国西储大学的轴承故障数据以及实验室机械故障综合仿真测试平台的轴承故障数据进行故障识别实验。
3.1 实验1
数据来自凯斯西储大学,采用6205-2RS JEM SKF 深沟球轴承,采样频率为12 kHz。按照轴承故障状态分为内圈故障、外圈故障、滚子故障以及正常状态4种情况。对列车轴承故障类型进行识别时,用于训练的各种状态的特征集样本量较小,所以在进行轴承故障分类仿真测试时训练样本量少于测试样本量。实验时设置每种故障数据集中包含40组特征向量,其中10组为训练集30组为测试集。
首先使用CEEMD 对信号进行自适应分解,图3 为轴承内圈故障的原始信号,对其进行傅里叶变换得到频谱图(图4),4 000~5 000 Hz 以及1 000~2 000 Hz内存在幅值较大频段,可判断出在此频段内存在冲击能量。
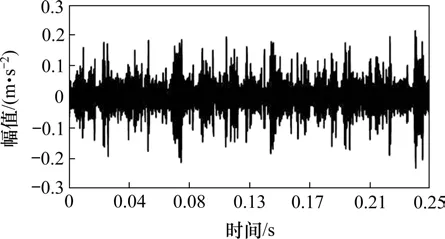
图3 轴承原始信号图Fig.3 Original signal diagram of bearing
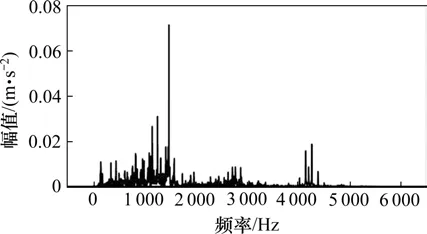
图4 振动信号频谱图Fig.4 Bearing failure identification flow chart
使用CEEMD 对信号进行分解得到10 个模态分量如图5 所示,对imf1,imf2,imf3,imf4进行快速傅里叶变化得到频谱图(图6),可以看出高频信号存在于前几阶IMFs 中。基于相关性对IMF 进行筛选,相关性系数如图7所示。imf1,imf2,imf3与原始信号相关性较高,其余同原始信号的相关性并不高。因此提取前3阶IMF重构后计算特征向量。由于特征元素之间的数量级差别较大,所以对数据进行归一化处理。图8 可以看出选取的5 个特征向量能够将不同状态的轴承分离。特征向量集随机分为测试集和训练集输入AFSA-SVM 分类器中进行分类测试。如图9所示,得到了精度较高的分类结果(120/120),验证了所提出的诊断方法的有效性。
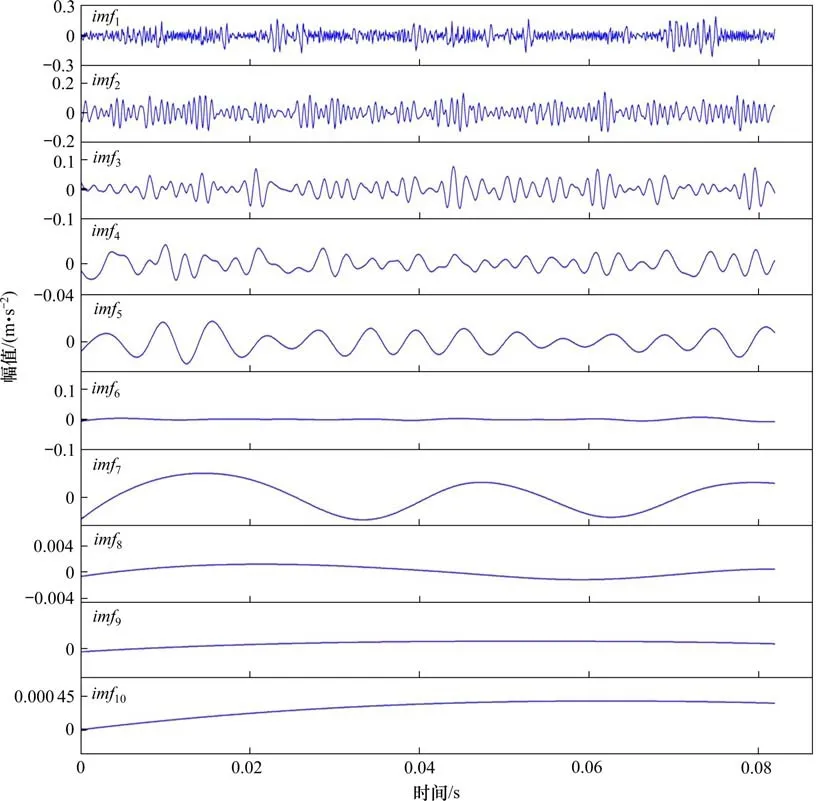
图5 分解后IMF分量Fig.5 Decomposed IMF components
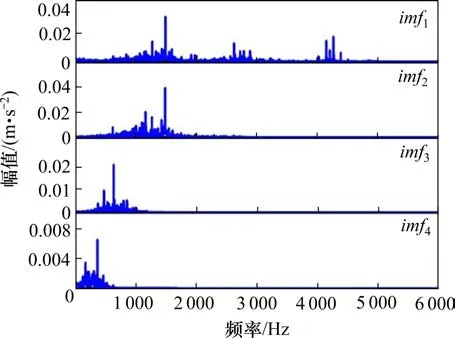
图6 前4阶IMF分量频谱图Fig.6 Spectra of the first four IMF components
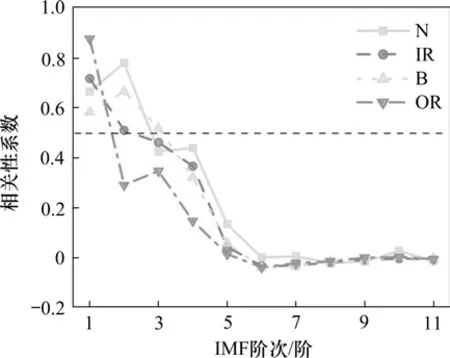
图7 相关性系数Fig.7 Vector correlation coefficient
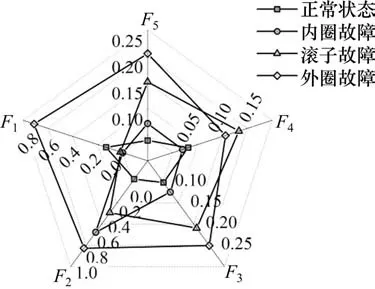
图8 不同状态下的特征向量Fig.8 Eigenvectors in different states
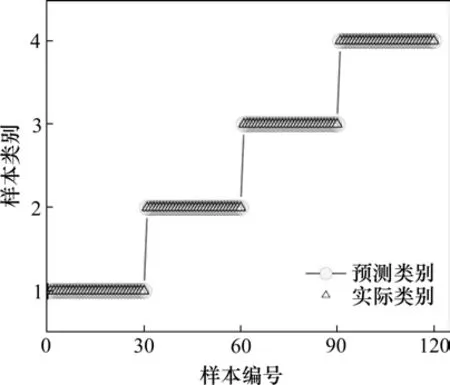
图9 4种状态的测试集分类结果Fig.9 Test set classification results for four states
3.2 实验2
使用中南大学轨道交通安全教育部重点实验室数据进行实验测试。实验室机械故障综合仿真测试试验台,如图10 所示。测试轴承的型号为MBER-12K,滚子数为8,球直径为0.312 5 mm,使用EDM 点蚀技术得到故障直径为1mm 的故障轴承进行实验。电动机转速为2 000 r/min,采样频率为32 kHz。采集了正常状态、内圈故障、外圈故障、滚子故障以及复合故障5种状态下轴承的振动信号用于轴承的故障识别实验。
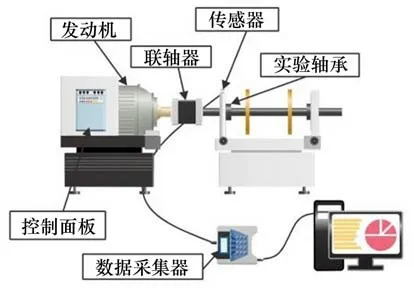
图10 机械故障综合仿真测试试验台示意图Fig.10 Schematic diagram of mechanical fault comprehensive simulation test bench
样本长度为3 000,样本数量为500,IMF分量的相关性系数如图11 所示,在该段信号中,前4个分量同原始数据相关性系数在0.5 以上,故选取前4个IMFs进行重构。
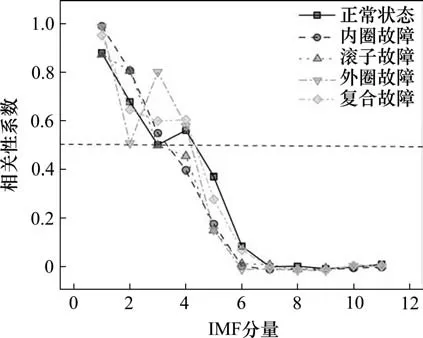
图11 IMF分量同原始信号的相关性系数Fig.11 Schematic diagram of mechanical fault comprehensive simulation test bench
图12(a),12(b)和12(c)为时域范围内的3 个特征向量,在时域范围内,3 个无量纲指标均表现出了其对于异常状态的灵敏度。但是基于时域特征构成的特征向量并不足以将5种状态完全分离,因此加入频域特征和能量值对其进行补充。图12(d)和图12(e)为样本的能量值和频率均方根。从数量级上来看在能量维度上能够有效的分开正常状态、外圈故障以及滚子故障,但是内圈故障和复合故障交织在一起。在频域中,复合故障和外圈故障交织在一起,借助频率均方根可以将内圈和复合故障进行区分。将上述的特征值进行耦合,构成五维的特征向量,既包含了对异常冲击的灵敏性,同时兼备了对于5 种状态的故障类型识别的稳定性。

图12 样本特征值Fig.12 Sample eigenvalues
对500 组样本进行划分,输入AFSA-SVM 分类实验,分别测试了训练集与测试集数量比例为8∶2,7∶3,6∶4,5∶5,4∶6,3∶7,2∶8 的分类能力。每组实验进行3次重复实验取最低准确率作为最终结果,如图13 所示,训练集只有100 组时准确率可以达到99.5%,在7 组学习训练中AFSASVM 分类器的准确率均在99%以上,当训练集比例为7:3 及以上时,可以准确识别每一个样本的故障类型。

图13 各个测试组的识别准确率Fig.13 Recognition accuracy of each test group
根据轴承故障发生的位置,可以将轴承的故障类型分为内圈故障,外圈故障,滚子故障以及混合故障。轴承的振动具有周期性特征,当经过损伤部位时表现出周期性的冲击。只同轴承材料、结构、制造情况等有关的频率称为固有频率。出现损伤时由于损伤部位的冲击造成的频率称为故障频率,在频谱图中表现为故障频率的倍频出现[21]。如表1 所示,根据轴承的尺寸可计算出轴承转频与故障频率的关系。对样本信号进行快速傅里叶变化,选取轴承2 倍频到4 倍频之间特征频率范围内幅值的最大值作为特征向量使用SVM 和AFSA-SVM 进行分类测试,结果如表2 实验组1,2所示。
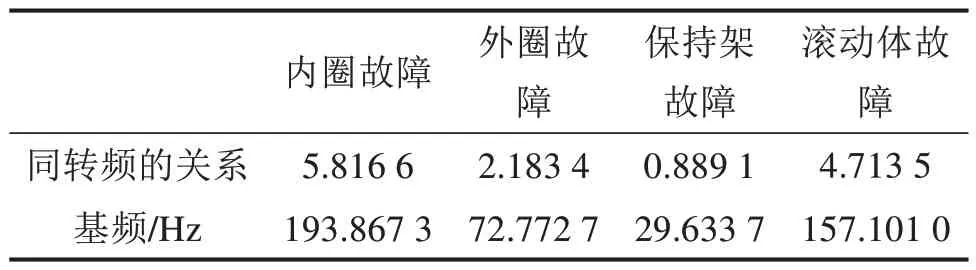
表1 轴承故障频率Table 1 Bearing failure frequency
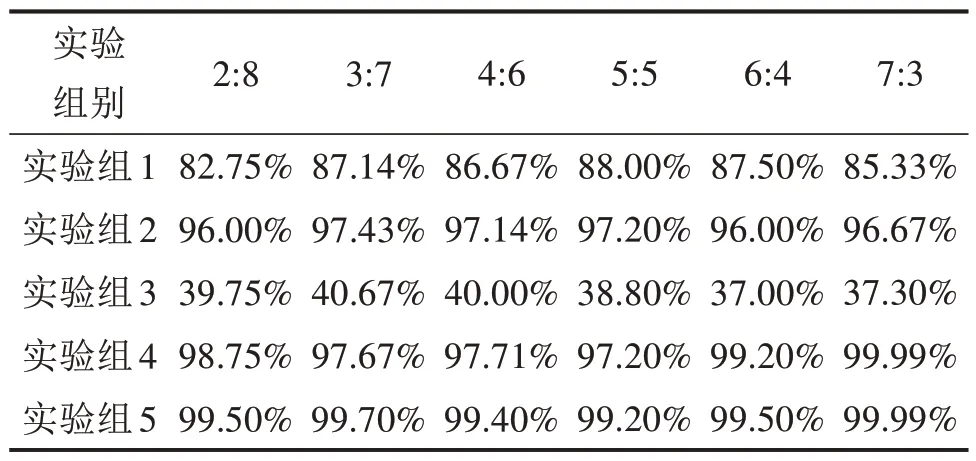
表2 改进方法前后对比Table 2 Improvement and comparison for improvement methods
基于EMD 以及SVM 的轴承故障识别方法中,较成熟的识别方法为使用EMD 对原始信号进行分解,提取IMF 分量的能量熵作为分类的特征向量。基于网格搜索进行SVM 的参数寻优,实现轴承的故障诊断。此方法在凯特西储大学轴承故障数据当中表现出较优的效果,但在噪声较大以及故障类别复杂的数据分类当中泛化能力不高,如表2所示,基于轴承故障频率范围提取特征的方法准确率在80%以上,使用ASFA-SVM 时识别准确率相较于SVM 有所提高,但相较于本文所提出的特征工程方案,准确率下降了3%左右,且当训练组多于测试组时出现过学习现象。实验组3的数据组为使用EMD 对数据进行分解重构,构成特征向量未进行归一化处理输入SVM 进行分类训练和测试。实验组4 在1 组数据基础下进行了归一化处理。实验组5 则为本文方法。在7 种比例的分类识别实验中,由于数据的数量级差别很大所以是否归一化对识别准确度有很明显的影响。EMD-SVM 的识别效果相较于本章方法准确率较低,但基本在90%以上,一方面因为实验室数据噪声较小,且认为破坏得到的轴承故障特征比较明显,数据质量较高。另一方面,基于故障振动特点选取的特征向量,有较好的表征能力。从分类速度来看,为寻得较优参数需扩大网格搜索范围缩小步长,因此在达到90% 以上准确率的基础下,EMD-SVM 方法的寻优时间在100 s 以上,而CEEMD-AFSASVM 的寻优时间在20~30 s 之间,极大的提高了识别效率。
将所提出的方法同在分类任务中表现较好的网络对比,如表3所示。深度网络利用卷积层代替人为的特征工程,虽然能够节约人工筛选的时间且保证较高的识别精度,但是在工程实际应用中,一个好的特征工程,往往要比深度网络更合适。由表3 可以看出虽然CNN,ResNet18 等深度网络可以达到98%以上的准确率,但是对于变化比例的测试组识别结果不稳定,CEEMD-AFSF-SVM 的效果更佳,识别准确率能够稳定保持在99%以上。

表3 同深度学习网络的对比Table 3 Comparison with deep learning networks
3.3 实验3
在上述任务中中,使用的数据集是标签量一致的平衡数据。但在实际中用于模型训练的数据集多为不平衡数据集。在有监督分类器中,标签数量多少直接影响其学习结果,当使用SVM 对不平衡数据进行分类时,其对于数据量较大的标签更加敏感,这将对识别精度产生影响。
在解决不平衡数据集分类问题时,常从2个方面入手,一是对数据集进行欠采样或者过采样处理,得到平衡数据集。二是对算法进行改进,通过提高算法对于小样本数据集的学习能力,提高识别准确率。3.2 节验证了所提出的故障识别方法对于小样本集有理想的识别效果。可以认为改进的轴承故障识别方法在面临不平衡数据集时,能够克服样本较丰富类别对于分类器灵敏度的影响。为验证其对于不平衡数据集的识别效果,从实验2故障特征向量集中以1∶9,2∶8,3∶7,4∶6,5∶5的比例从各个状态中提取训练集进行轴承不平衡数据集的训练及分类测试。
如图14 所示,5 种提取比例在轴承5 种状态中进行排列组合,一共进行120 组识别训练和测试。用于验证模型识别准确率的样本量为250组。改进SVM 的轴承故障识别方案在不平衡数据分类测试中,识别准确率最高可达100%(250/250),最低为98.4%(245/250),平均准确率为99.3%。在使用BP网络以及KNN 实现不平衡故障分类实验中(图15),各个故障状态数据比例影响了分类器的稳定性,准确率低于CEEMD-AFSA-SVM 轴承故障识别方法,验证了该方法在不平衡数据识别中的有效性和稳定性。

图14 不平衡数据集识别准确率Fig.14 Identification accuracy of unbalanced data sets
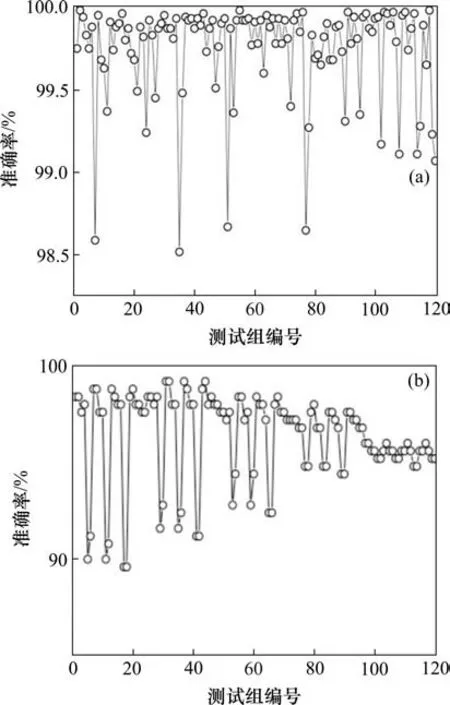
图15 不平衡数据集识别准确率Fig.15 Identification accuracy of unbalanced datasets
4 结论
1) 采用CEEMD分解原始信号,对IMF分量筛选重构后提取5 个维度的数据构成故障特征向量,降低了轴承故障特征向量集的计算难度,同时兼具了对轴承故障表征的敏感性和稳定性。
2) 在工程实际应用中轴承故障往往并不是单一的,在进行故障轴承仿真实验时增加了复合故障轴承,提出的提取特征向量方法对于区别复合故障以及其余3种单一故障和正常状态达到了理想效果。
3) 经过2个试验台的轴承故障数据对提出的轴承故障诊断方法进行测试,该方法能有效识别多种故障类型,且对于不平衡数据集也能达到98.3%以上的识别准确率,对于列车轴承故障识别具有实际应用价值。
