结合动态行为和静态特征的APT攻击检测方法
2023-09-25尹南南
梁 鹤,李 鑫,尹南南,李 超
1.中国人民公安大学信息网络安全学院,北京100038
2.公安部第一研究所,北京100048
近年来,高级持续性威胁(advanced persistent threat,APT)引起了人们的广泛关注[1]。攻击者利用目标系统的漏洞,使用各种方法和工具为特定目标(政府、金融机构或大公司)编排设计APT 攻击,如Stuxnet[2]。APT 攻击的特点是明确的目的性、入侵方法的多样性、长而隐蔽的持续性以及对目标系统的严重破坏性。攻击者拥有雄厚的资金实力和丰富的资源,入侵之前先通过社会工程等技术尽可能多地收集目标信息,然后,通过零日攻击、水坑攻击、恶意邮件等方式,定向侵入目标系统并长期潜伏,隐藏恶意活动的同时持续提升权限,直到能够窃取机密数据,达到把机密数据传输到特定的外部服务器的目的[3]。
目前,研究人员试图利用网络流量或安全日志信息挖掘隐藏的异常行为来发现APT 攻击的痕迹[4-5]。然而由于安全性和隐私性的要求,普通研究人员很难获得网络流量或安全日志信息。还有研究使用基于自己构建和开发的实验数据集进行检测[6-7]。这导致了实验数据和实际监测数据之间的不匹配,在研究和实验中,可以产生良好的结果,当应用于实际监测模型时,并没有产生预期的结果[8]。因此,需要探索其他方式开展APT攻击研究。与传统网络攻击类似,APT攻击者需要利用恶意软件发动网络攻击。因此,分析APT攻击中部署的恶意软件,为开展APT攻击研究提供了一种可行方法。
APT 恶意软件是专门为特定目标量身定制的恶意软件,相比传统恶意软件更具威胁性。检测过程中除了检测出该软件是具有恶意行为的APT恶意软件外,检测出其所属的APT 组织也同样具有重要意义。APT 恶意软件的组织分类能够指示出恶意软件的行为类别和执行目的,提供其危害程度等信息,有利于跟踪APT组织的发展变化,帮助研究人员对APT攻击溯源并快速评估网络空间安全的发展态势。
基于此本文提出了一种基于动态行为和静态特征结合的APT攻击检测方法。检测分为两个阶段,第一阶段对APT恶意软件进行识别,从APT恶意软件、传统恶意软件和良性软件中识别出APT恶意软件;第二阶段对已经识别出的APT恶意软件进行组织分类,最终实现对APT恶意软件的识别和组织分类。
1 相关工作
基于本文主题,本章将对学术领域和工业界常用的利用网络流量检测APT攻击和分析APT攻击中部署的恶意软件两方面对APT攻击检测做概括。
1.1 基于流量分析的检测
研究人员通常从大量网络流量中进行数据挖掘,基于显式特征或知识识别未知的APT 攻击行为,并预测APT攻击。
Shang 等[9]提出了一种检测未知APT 攻击的隐藏C&C通道的方法。首先从已知的多类攻击流中挖掘共享网络流特征;然后用合适的分类器来检测C&C流量;最后在公共数据集上进行测试。实验结果表明,在处理未知恶意网络流量时,该方法的F1评分达到0.968。
Liu 等[10]提出了基于GAN-LSTM 的APT 攻击检测方法,基于GAN模拟生成攻击数据,为判别模型生成大量攻击样本,基于LSTM模型的记忆单元和门结构保证了APT攻击序列中存在相关性且时间间距较大的序列片段之间的特征记忆。
Xuan 等[11]提出了一种基于网络流量异常行为的机器学习检测APT 攻击的方法,将网络流量中APT 攻击的异常行为定义在域和IP两个组件上,然后基于随机森林分类算法对这些行为进行评估和分类,以总结APT攻击的行为。
Li等[12]通过监控APT攻击的目标实体,提出了一种检测受感染主机的方法。通过在网络级别总结受感染主机的行为特征来量化特征向量,并将这些向量作为无监督学习的输入,以导出可疑主机列表。该方法检测受APT攻击的主机,准确率达到了97.3%。
1.2 APT恶意软件检测
根据分析过程中是否运行程序,恶意软件检测主要分为静态分析和动态分析[13]。静态分析在不需要执行程序的情况下对可执行程序进行分析,利用特征进行学习,优点是无需执行开销[14-15]。而动态分析是把待检测恶意软件放入虚拟机或者沙箱中运行,监控其是否有相应的恶意行为[16-17]。还有研究人员将静态分析和动态分析相结合,进行混合分析,充分利用两种分析技术的优势[18-19]。
Laurenza 等[20]基于从文件头、模糊字符串、导入、函数和目录获取的静态恶意软件特征,构建了APT恶意软件分类框架,能够快速识别恶意软件和APT攻击相关的恶意软件,准确率达到了96%。
沈元等[21]提出了一种基于深度学习的恶意代码克隆检测框架,通过反汇编技术对恶意代码进行静态分析,利用其关键函数调用图以及反汇编代码作为该恶意代码的特征,然后根据神经网络模型对APT组织库中的恶意代码进行分类,准确率达到了95.3%。
Sexton等[22]研究了基于统计的方法,利用大量入侵目标网络的恶意软件家族检测APT 恶意软件。该方法根据程序与已知恶意软件子程序的相似性对程序进行分类,将APT恶意软件分类为其所属的APT组织。
Friedberg 等[23]记录了APT 恶意软件在沙箱中运行时的动态行为,利用深层神经网络作为APT恶意软件的分类器,将提取的动态行为作为分类器的输入特征。
Han 等[24]提出了一种名为APTMalInsight 的APT 恶意软件检测和认知框架,他们系统地研究APT 恶意软件,并提取动态系统调用信息来描述其行为特征,利用已建立的特征向量,检测APT恶意软件并准确分类到其所属的APT组织。
基于流量分析的APT 攻击检测具有一定的检测效果,但是由于隐私性和安全性的考虑,研究人员很难获得网络流量,而基于自己模拟构建数据集的检测方法在实验中和现实检测时又很难匹配。基于静态分析的方法分析速度快且准确,但是可执行样本容易受到混淆和加壳的影响,动态分析能够捕获待测软件的行为轨迹,发现恶意行为,但是无差别地执行待检测样本会带来巨大的时间和资源开销。本文对APT 恶意软件的检测方法,首先在执行速度更快的Noriben 沙箱中运行待检测样本,提取待检测样本的动态行为特征,利用Transformer-Encoder 算法识别出APT 恶意软件,再用Python 编程提取APT 恶意软件的静态特征,利用1D-CNN 算法实现APT恶意软件的组织分类。本文的主要贡献如下:
(1)提出了一种基于动态行为和静态特征结合的APT攻击检测方法,分两个阶段实现检测过程。
(2)搭建Noriben 沙箱,提取待检测软件的进程行为、注册表行为、文件行为和网络行为特征,并去掉每个样本中前后重复的动态行为;提取APT恶意软件调用的DLL和API作为静态特征,组合为DLL:API的形式。
(3)将Transformer-Encoder 算法和1D-CNN 算法引入APT恶意软件检测领域,对比了其他热门的深度学习算法和机器学习算法,实验结果证明了本文检测模型的效率和提取特征的分类能力。
(4)利用本文检测方案检测了未知类型的软件,检测结果良好,证明文本方法具有较强的泛化能力。
2 算法结构
2.1 特征提取
2.1.1 动态行为特征提取
恶意软件在感染主机的过程中会有一系列行为操作,以Wannacry[25]蠕虫病毒恶意软件为例,其主程序释放恶意软件的可执行文件后,会先更改系统注册表注册本地服务,之后向内网探测和移动,对认为有价值的文件执行加密操作,然后删除原文件,最后强制重启电脑显示出勒索窗口。软件的动态行为可以表现软件执行的目的,不同类型软件的动态行为及其执行顺序差异很大,可以用来识别恶意软件的恶意性。
本文在动态特征提取过程中采用了Noriben沙箱环境,Noriben是一个基于python的开源项目(https://github.com/Rurik/Noriben),可直接下载搭建。Noriben 沙箱是对软件procmon.exe的简单改造,把它部署在虚拟机后,可以方便地对虚拟机内某一特定软件进行监控,并且将客户机信息实时反馈给主机。如图1是Noriben沙箱的工作流程。
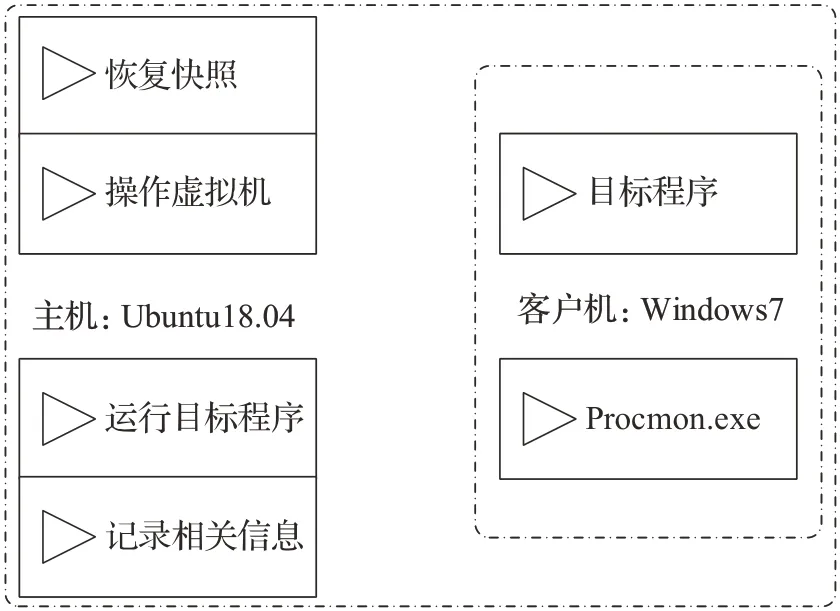
图1 Noriben沙箱工作流程图Fig.1 Noriben sandbox workflow diagram
首先由主机恢复客户机的快照,使其回到检测的最佳状态,然后操作虚拟机软件打开客户机,将待检测的目标程序复制进客户机的对应目录,运行起客户机内的procmon.exe 软件,然后由主机记录下客户机内目标程序的动态行为信息,生成CSV表格以便后续分析。
动态行为特征提取时,每个样本在沙箱中运行1 min,Noriben沙箱对应生成csv表格,使用Python脚本提取表格中的动态行为序列。这些动态行为包括4种:进程行为、文件行为、注册表行为和网络行为,一共提取了1 928种动态行为特征。在Noriben沙箱测试过程中,待测软件会因为各种原因反复执行特定的行为,这些行为有些是正常的,有些则是在非预期条件下的重复行为。为了消除这些重复行为对数据集的影响,且在不影响实验精度的情况下提高运行速度,删除了每个样本前后重复的行为特征。
算法1 动态行为特征去重

动态行为提取流程如图2所示,其中数据预处理过程如图3所示。
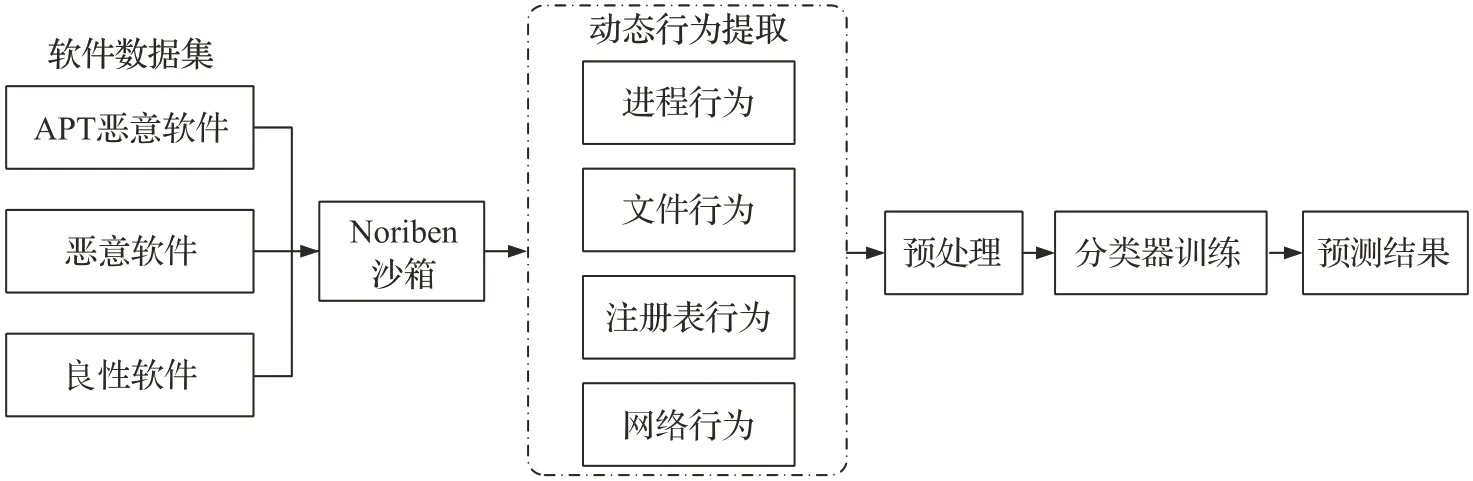
图2 动态行为提取流程图Fig.2 Flow chart of dynamic behavior extraction
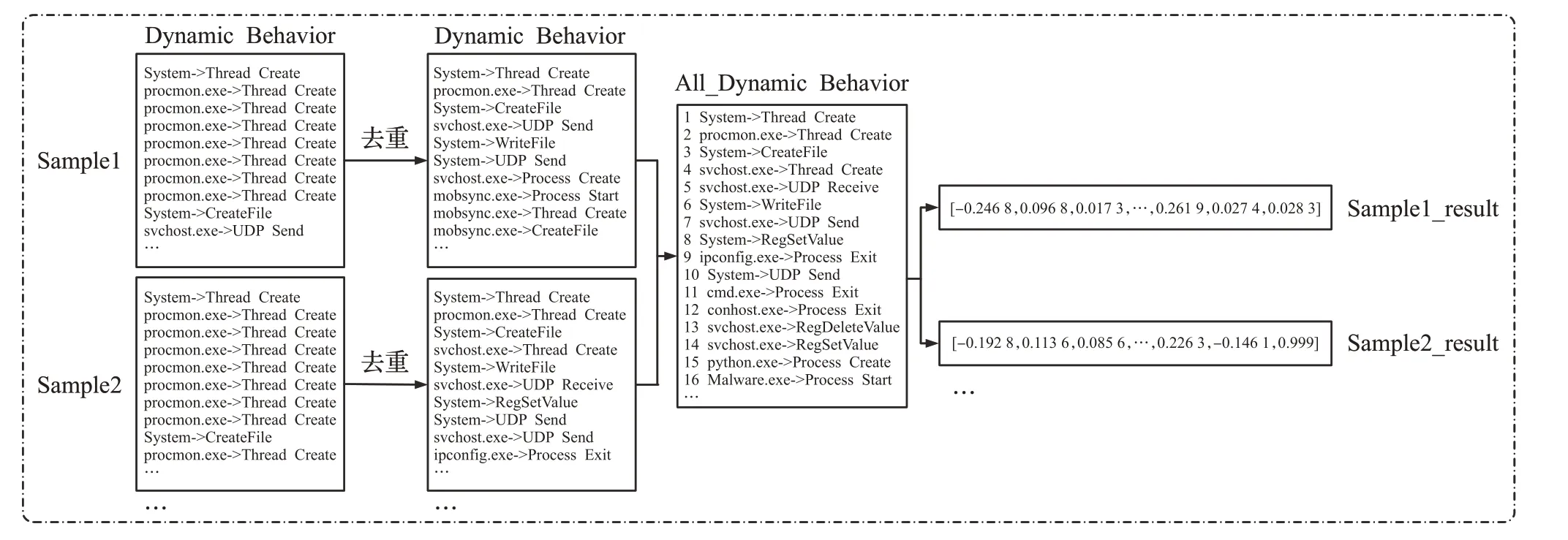
图3 动态行为数据预处理流程图Fig.3 Flow chart of dynamic behavior data preprocessing
2.1.2 静态特征提取
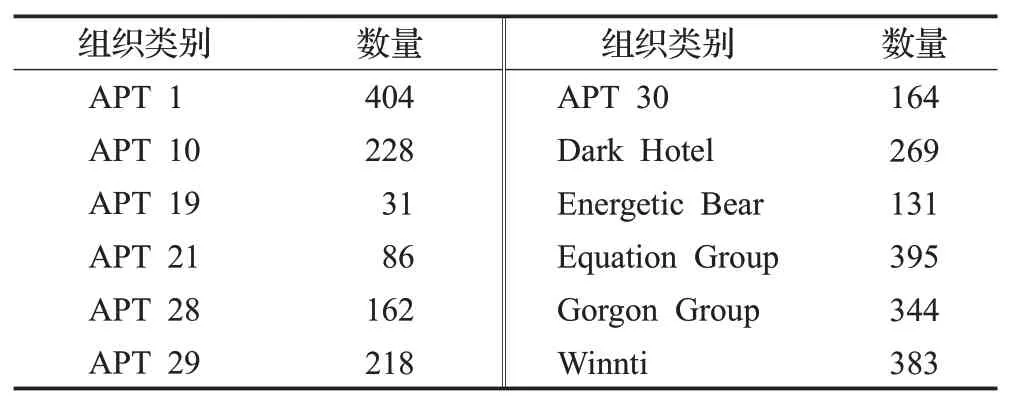
之前的文章[26]提取了入口点、DLL、资源语言,节数和资源种类数作为静态特征,5种特征融合后对于APT组织分类的准确率为93.7%,其中贡献率最高的特征为DLL,其作为单一特征进行分类就有83.0%的准确率。在每个APT 恶意软件被调用的DLL 目录下,包含多种API,之前的研究也证明了API 作为静态特征的分类能力[27-28],因此本文提取了DLL 和API 两种特征。考虑到DLL 和API 一对多的映射关系,把两种特征组合成了DLL:API 的形式。静态特征的提取流程如图4 所示。表1为提取的某个APT样本的DLL及其目录下的API。需要将数据编码形成神经网络可以处理的形式,若待测样本的特征集包含此类特征,用1 表示,否则用0 表示。最后将APT组织映射为整数标签,预处理之后的向量表如表2所示。

表1 某APT样本的DLL及其目录下的APITable 1 DLL of APT sample and API in its directory

表2 DLL:API特征向量表Table 2 DLL:API eigenvector table
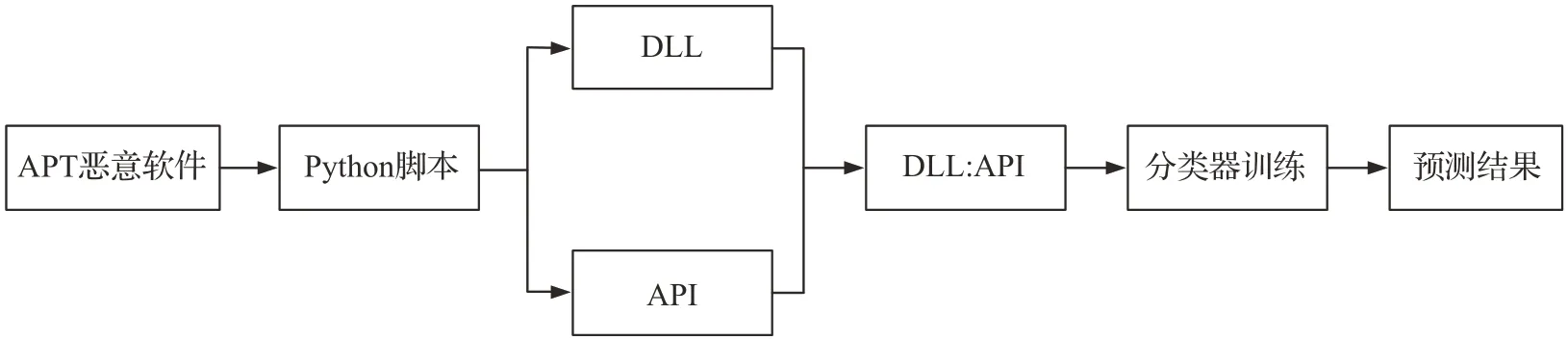
图4 静态特征提取流程图Fig.4 Flow chart of static feature extraction
算法2 提取APT恶意软件的DLL和API并组合为DLL:API的形式
输入:所有APT恶意软件样本的路径SampleList。


2.2 深度学习模型选取
近几年深度学习技术在网络安全领域蓬勃发展,许多研究也证明了其在代码分析方面的有用性,应用在恶意软件的恶意性识别和家族分类上取得了不错的效果[19,23-24,26-27]。下面将介绍本文模型两个阶段使用的深度学习算法。
2.2.1 Transformer-Encoder
Vaswani等[29]在2017年改进了seq2seq模型,抛弃了传统的RNN结构,设计了一种多头注意力机制,通过堆叠编码-解码(encoder-decoder)结构,得到了Transformer模型。Transformer算法广泛应用在自然语言处理(NLP)领域,并取得了开创性的效果。本文提取的待检测软件的动态行为特征是较长的序列数据,Transformer算法的结构天然适合处理此类数据。对于APT 恶意软件的识别,本质上属于三分类任务,因此本文只关注Transformer算法的编码(Encoder)部分,如图5 所示,本文N取6。编码部分由两个重要的模块组成,多头注意力和前馈网络(feedforward network,FFN)。多头注意力机制相当于多个自注意力机制合并,FFN 提供非线性变换,这两个模块之后都进行残差连接和层标准化。
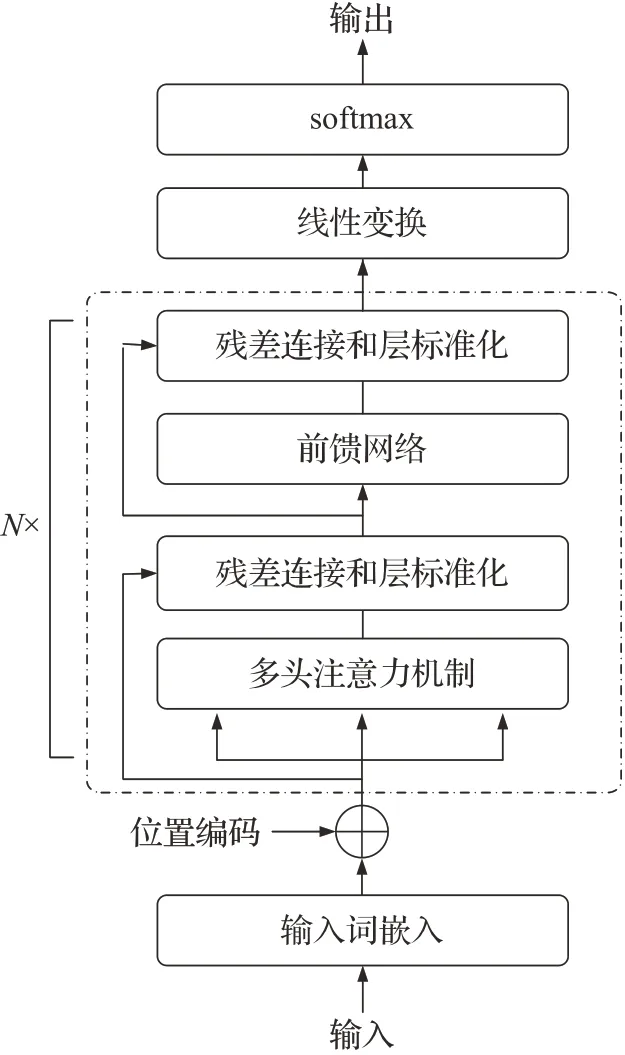
图5 Transformer-Encoder结构图Fig.5 Transformer-Encoder structure diagram
位置嵌入:不采用CNN 和RNN 结构,无法充分利用序列的位置信息,Transformer采用基于频率变化的位置编码解决这个问题。第n个单词的位置嵌入计算公式,如式(1)、(2):
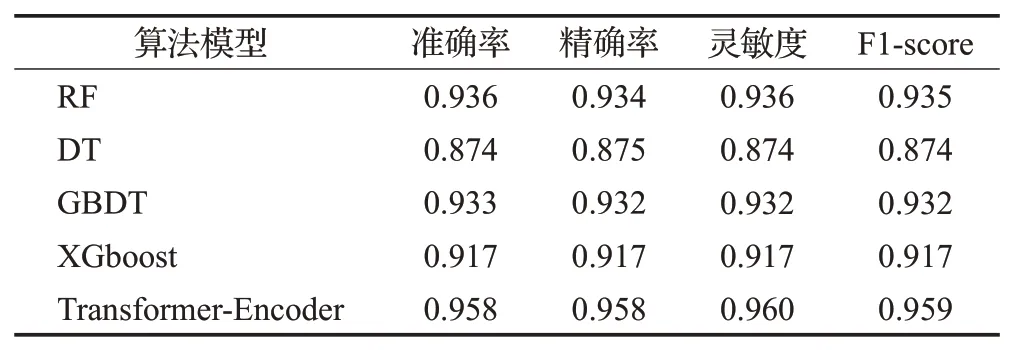
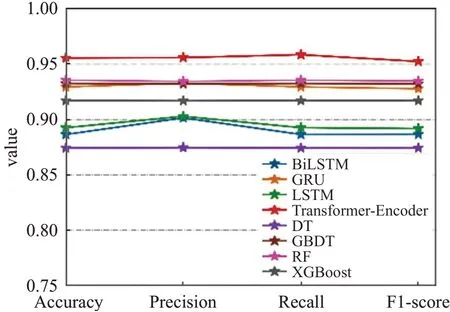
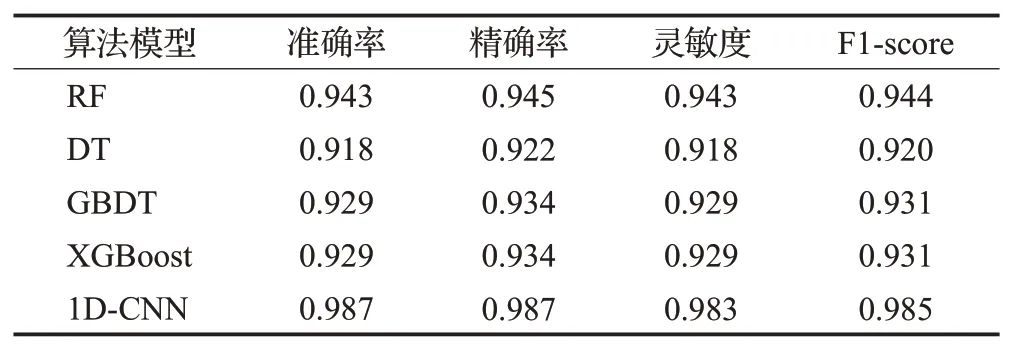
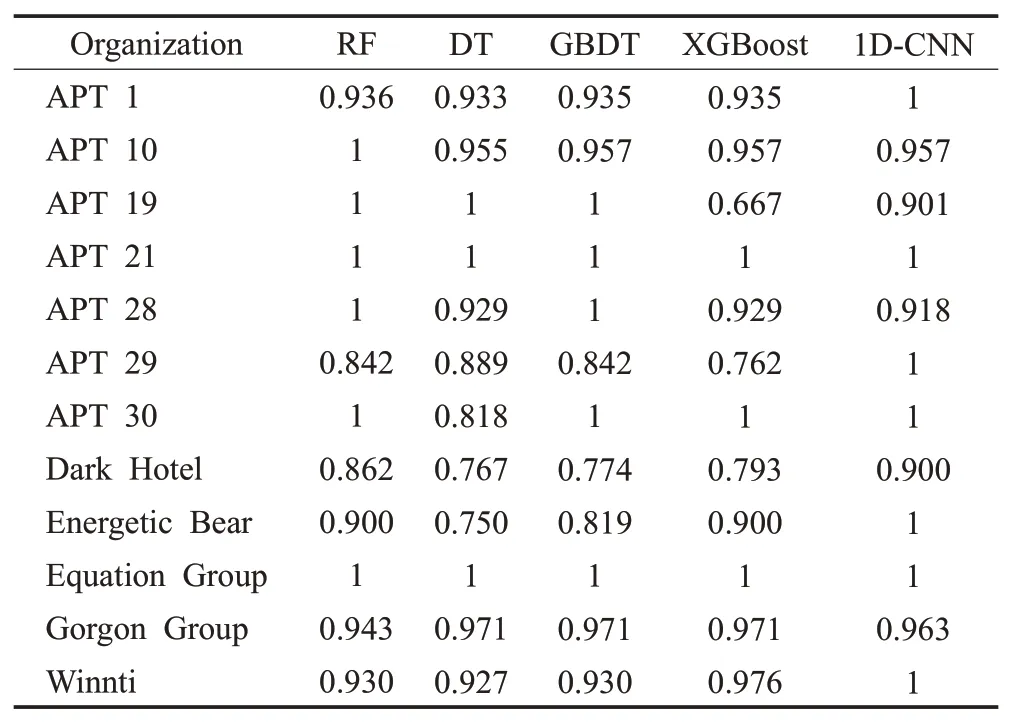
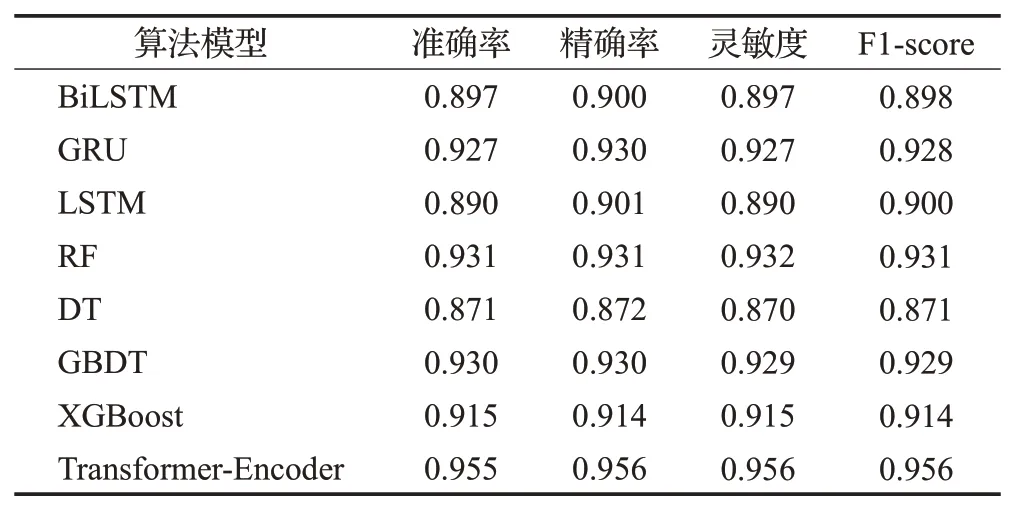
其中,PE代表位置嵌入,提供每个时刻的位置信息,n代表输入序列的第n个单词,d表示输入的词向量的维度,2i和2i+1 分别表示属于奇数维和偶数维(2i 多头注意力:缩放点积注意力是多头注意力的核心,其使用点积进行相似度计算的方法相比一般的注意力,会更快更节省空间。输入矩阵经过线性变换之后得到查询矩Q、键值矩阵K和数值矩阵V,三者都是向量组成的二维矩阵,作为缩放点积注意力的输入,如式(3): Q和K矩阵经过点积操作之后,除以尺度标度来进行缩放,目的是避免矩阵内积过大而造成经过softmax函数后的结果太逼近0或1,影响最终概率的计算。经过softmax层归一化后,得到自注意力的得分值,再与矩阵V进行点积操作,最终得到自注意力的输出。其中dk是矩阵QK的列数,即向量的维度。缩放点积注意力计算出每个词和各个词之间的注意力,赋予每个词全局语义信息。 上述过程重复h次即为多头注意力,如式(4),但是要注意不同层的权重矩阵参数是不同的。Wq、Wk和Wv为计算时的权重参数矩阵,其中Wq∈Rdm×dk,Wk∈Rdm×dk,Wv∈Rdm×dv,dm是模型的维度,dk、dv分别是权重矩阵的维度,默认(dm=dk=dv)/h,Wi是一个向量,为权重参数矩阵的第i个维度,最后将并行计算后的结果进行拼接,即Concat操作,如式(5),WC是拼接层的权重系数。 前馈网络:多头注意力的输出会经过一个全连接网络FFN,它包含两个线性变换和一个激活函数ReLU,这层网络结构可以提高模型的非线性变换能力,计算公式如下: 其中,W1,W2∈Rdm×df为可学习参数矩阵,df =1 024 是一个超参数,为中间层维度,b1∈Rdf、b2∈Rd,都为可学习向量,x为输入。 2.2.2 1D-CNN 1D-CNN常应用于自然语言处理领域,在处理短序列时甚至比机器学习算法更有成效,它能很好地识别出数据中的简单模式,然后在后续更加高级的层中生成更复杂的模式。1D-CNN之所以称为一维,是因为它的卷积核沿着一个方向移动,从输入序列中按照一定大小的窗口长度提取局部一维序列段,然后与一个权重做点积计算,输出结果为新序列上的一部分。 本文使用的1D-CNN 结构图如图6 所示。输入的每个待检测样本的文本序列需要经过三个卷积层、三个池化层和三个全连接层,每个卷积层后面有一个ReLU激活函数并对应一个池化层,最终通过softmax分类层实现多分类任务。 图6 1D-CNN结构图Fig.6 1D-CNN structure diagram 1D-CNN模型的计算公式如下: Zi表示第i层的特征向量,Wi表示第i层卷积核的权重矩阵,bi表示第i层卷积核的偏重向量,⊗表示卷积运算符,f表示激活函数。 ReLU激活函数计算公式如下: 本文的模型流程图如图7所示。 图7 本文检测模型图Fig.7 Proposed detection model diagram 第一阶段进行APT恶意软件的识别,首先用Noriben沙箱提取待检测软件的动态行为特征,预处理后形成可以用深度学习模型处理的特征集,用Transformer-Encoder 算法识别出APT 恶意软件;第二阶段在第一阶段识别结果的基础上进行APT恶意软件的组织分类,用Python编程实现APT恶意软件PE头中DLL和API的提取,预处理后用1D-CNN算法对APT恶意软件进行组织分类。 实验的第一阶段,本文收集了APT 恶意软件,传统恶意软件和良性软件三类软件作为数据集,其中APT恶意软件来源于GitHub(https://github.com/cyber-research/APTMalware),下载了3 594个可执行样本,传统恶意软件来源于VirusShare(https://www.virusshare.com),共有5 980 个可执行样本,良性软件为实验室收集的和在Windows 应用商店(https://apps.microsoft.com)爬取的,加起来共有1 100个可执行样本。删除了APT恶意软件中信息不全和样本数量过少的组织样本后,最后三类软件的数量比大约为1∶6∶2,数据集分布如表3所示。 表3 识别阶段数据集分布表Table 3 Identification stage data set distribution table 实验的第二阶段是在第一阶段识别结果的基础上,对APT 恶意软件进行组织分类,这里直接使用APT 恶意软件数据集作为训练数据,数据集包含12 个组织类别,分布情况如表4。 表4 分类阶段APT组织及其样本分布Table 4 APT tissue and its sample distribution in classification stage 两个实验阶段的数据集均划分为8∶1∶1的比例,分别为训练集、验证集和测试集,三者没有任何交叉。训练集只用来训练选择的神经网络模型,计算梯度和损失值。验证集用来验证训练的模型,实验过程中选择验证准确率高且损失值小的模型进行保存。测试集对保存的模型进行预测,检测模型的实际效果。 本文所用实验设备信息如表5所示。 表5 实验设备及环境Table 5 Experimental equipment and environment 本文实验过程第一个阶段是APT恶意软件的识别,实际上是三分类问题;第二个阶段是APT恶意软件的组织分类,为多分类问题。为了评估分类算法的性能,选择用混淆矩阵和损失值表示分类结果。实验中所用的性能指标如下几类: 准确率(Accuracy)表示实验模型中正确分类的样本占实验总样本的比例,计算公式为: 精确率,也称查准率(Precision),表示模型中正确分类的正例个数占分类为正例的实例个数的比例,计算公式为: 灵敏度,又称查全率(Recall),表示模型中正确分类的正例个数占实际正例个数的比例,计算公式为: F1-score 是基于Recall 与Precision 的调和平均,即将查全率和查准率综合起来评价,综合判断分类模型对于某类样本的预测能力,计算公式为: 其中,TP表示正确预测到的正例的数量,FP表示把负例预测成正例的数量,FN表示把正例预测成负例的数量,TN表示正确预测到的负例的数量,n代表软件类别或APT组织数。 3.4.1 APT恶意软件的识别结果分析 经实验本文所用的Transformer-Encoder 算法的最优参数设置为:batchsize 取32,6 个Encoder 结构堆叠,多头注意力选择8个头,优化函数选择Adam,训练500轮。 为了验证所提方法的有效性,实验第一阶段的方法与主流的深度学习算法BiLSTM、GRU、LSTM和机器学习算法随机森林(RF)、决策树(DT)、GBDT、XGboost算法做了全面对比。表6 为本文与其他三种深度学习算法的实验结果,可以看出Transformer-Encoder算法对比LSTM、BiLSTM和GRU优势明显,准确率达到了95.8%,比第二高的GRU高了2.8个百分点。 表6 Transformer-Encoder与主流深度学习算法实验结果Table 6 Experimental results of Transformer-Encoder and mainstream deep learning algorithms 图8为四种算法模型的训练损失值曲线图,代表四种算法模型在训练数据集过程中的损失值变化。损失值是衡量预测值和实际值相似程度的指标,根据图8,四种算法模型的损失值随着epoch 的增大逐渐降低,当epoch 的值到达2 000 后,损失值趋于稳定,达到收敛状态,其中Transformer-Encoder 算法的损失值最低,即预测结果与实际值最为相似,实验效果最好。图9为训练准确率曲线图,代表四种算法模型在设置的实验轮次内的实验准确率变化,随着epoch的增加,四种算法模型训练准确率先增大,epoch在到达2 000后逐渐趋于稳定。 图8 四种深度学习算法的损失值变化Fig.8 Loss value variation of four deep learning algorithms 图9 四种深度学习算法的训练准确率变化Fig.9 Changes in training accuracy of four deep learning algorithms 图10和图11为验证准确率曲线图和最大验证准确率曲线图,前者表示在每一轮训练中使用验证集验证的准确率变化曲线,由图10 可知,在前几个epoch 时,Transformer-Encoder 算法便迅速趋于稳定,明显高于其他算法模型,且验证准确率的曲线(红色曲线)对比图9而言,高度近乎一致,即结果没有过拟合,验证效果较好。而后者是取每轮的最大验证集,即最优训练结果,是从图10中取得的每轮的最好结果,Transformer-Encoder算法的收敛速度最快,因此曲线最早变得平滑。通过这四张图可以直观地看出Transformer-Encoder 算法在本文实验第一阶段识别APT 恶意软件上,对比其他三种算法,效果有明显的提升。 图10 四种深度学习算法的验证准确率变化Fig.10 Change of verification accuracy of four deep learning algorithms 图11 四种深度学习算法的最大验证准确率变化Fig.11 Maximum verification accuracy change of four deep learning algorithms 表7为本文模型与几种常用的机器学习算法模型的实验结果,可以看出Transformer-Encoder算法比机器学习算法效果更好。随机森林在实验中也取得了较好的效果,是因为其结构上的优势,采用多个决策树共同决策,擅长处理高维特征,因此也取得了较好的实验效果。为了直观观察实验结果,将几种深度学习算法和机器学习算法的实验结果形成折线图如图12所示,Transformer-Encoder算法实验结果各项指标都最高,其中RF、GRU、GBDT和XGBoost的各项指标也都达到了90%以上。 表7 Transformer-Encoder与常用机器学习算法实验结果Table 7 Experimental results of Transformer-Encoder and common machine learning algorithms 图12 识别阶段本文与其他算法模型的实验结果对比Fig.12 Comparison of experimental results between proposed and other algorithm models in recognition stage 3.4.2 APT恶意软件的组织分类结果分析 经实验所用的1D-CNN 算法的最优参数设置为3个卷积层,每个卷积层有3个卷积核、3个池化层、3个全连接层,步长为2,batchsize 取32,优化函数用Adam,激活函数用Relu,训练500轮。 实验第二阶段的方法同样与3.4.1小节一样同其他几种算法做全面对比,实验过程中发现BiLSTM、GRU和LSTM算法效果不佳,因此重点与机器学习算法作对比。表8为1D-CNN与RF、DT、GBDT、XGBoost算法的实验结果,图13 为1D-CNN 实验结果的混淆矩阵图。为了直观观察实验结果,把几种评价指标数据形成折线图如图14 所示,可知1D-CNN 在APT 组织分类的实验中取得了98.7%分类准确率,对比其他机器学习算法效果有很大提升。 表8 1D-CNN与常用机器学习算法的实验结果Table 8 Experimental results of 1D-CNN and common machine learning algorithms 图13 1D-CNN实验结果混淆矩阵Fig.13 Confusion matrix of 1D-CNN experimental results 图14 分类阶段本文与其他算法的实验结果对比Fig.14 Comparison of experimental results between proposed and other algorithms in classification stage 表9为1D-CNN 和其他四种机器学习算法在每个APT组织的分类准确率,可以看出1D-CNN分类准确率很高,有7个APT组织的分类准确率都达到了1,虽然在个别组织的分类准确率略低于其他机器学习算法,但是整体效果远高于其他算法。 表9 在每个APT组织的分类准确率Table 9 Classification accuracy in each APT organization 将1D-CNN 处理DLL:API 特征的方法与近期其他文献的同类方法做对比,比较结果如表10所示。文献[21]以APT 恶意软件的关键函数调用图和反汇编代码作为特征,需要提取大约68万个自定义函数,数据处理量巨大,而且分类准确率偏低,为95.3%。文献[26]提取了入口点、DLL、资源语言,节数和资源种类数五种特征,提取的特征种类数偏多,处理特征更耗时,且分类准确率偏低,只有93.7%。相比以上方法,本文方法仅仅提取了DLL和API两种特征,组合为DLL:API的形式,数据处理过程更简单,准确率也有较大提升,证明了本文所提特征的分类能力,和所用模型的有效性。 表10 同类方法比较Table 10 Comparison of similar methods 本节实验,利用2.3 节提出的检测方案对随机收集的未知类型的PC 端软件进行检测,以检测其在实际应用中的检测效果。首先在GitHub上下载APT恶意软件样本(https://github.com/Cherishao/APT-Sample),随机从中选取1 000 个不同组织类别的样本,然后在Windows应用商店和各大应用市场下载1 000 个未知类型的软件,再上传至VirusTotal(https://www.virustotal.com/)查毒网站进行在线分类检测,可以准确检测出所下载软件是否具有恶意性,其检测结果作为本节实验的基准。经VirusTotal网站检测,1 000个软件中有263个恶意软件,737 个良性软件。两个试验阶段仍然采取3.4.1 小节和3.4.2小节所用的深度学习模型和机器学习模型所得的结果进行对比。Transformer-Encoder 和其他算法模型识别未知类型APT恶意软件的结果如表11所示。 表11 识别未知类型APT恶意软件的结果Table 11 Results of identifying unknown type APT malware 由表11可知,Transformer-Encoder模型在未知类型的软件检测中,相比于其他几个算法模型,可较好地识别出APT 恶意软件,获得较高的准确率和F1 评分。识别结果几乎与3.4.1 小节的实验结果一致,是因为识别阶段为三分类,仅根据三种类型软件的动态行为从中识别出APT 恶意软件,而APT 恶意软件的动态行为与恶意软件和良性软件区别较为明显。 APT 恶意软件的组织分类结果如表12 所示,由于BiLSTM、GRU 和LSTM 模型检测效果不佳,与3.4.2 小节一样,这里不再进行对比,仅对比1D-CNN模型与RF、DT、GBDT、XGBoost等机器学习算法模型的分类结果。 表12 对未知类型APT恶意软件的组织分类结果Table 12 Organization classification results of unknown type APT malware 由表12可知,对于APT恶意软件的组织分类,1D-CNN模型和几种机器学习模型的实验结果相比3.4.2小节略有下降,1D-CNN 模型的分类效果仍然好于其他模型,各项指标均高于其他模型。实验表明,虽然在应对未知类型的APT恶意软件组织分类时的准确率略有下降,在未知类型的软件检测中,本文所提方案仍然能够较为准确地识别出APT 恶意软件,并较为准确地将识别出的APT恶意软件进行组织分类,切合对APT攻击检测的实际需要。 本文提出了一种综合的APT攻击检测方案,先后实现对APT恶意软件的识别和组织分类。在APT恶意软件识别方面采用了动态分析的方法,使用Noriben 沙箱捕获待测软件的进程行为、文件行为、注册表行为和网络行为,使用Transformer-Encoder算法对APT恶意软件进行识别,准确率高达95.8%,优于当前流行的BiLSTM、GRU、LSTM 深度学习算法和RF、DT、GBDT、XGBoost等机器学习算法。在APT恶意软件组织分类方面,采用静态分析的方法,提取可执行文件PE头的DLL和API,组成DLL:API的形式,用1D-CNN算法取得了98.7%的APT 恶意软件组织分类准确率,优于RF、DT、GBDT、XGBoost 等机器学习算法,相比之前文章的分类方法,提取了更少的特征,准确率增加了5个百分点。实验证明,本文方法的两个实验阶段都有很高的准确率,在应对未知类型软件时仍然可以有效识别出APT恶意软件并准确进行组织分类。但是本文依旧存在不足之处,虽然Noriben 沙箱运行较快,但是仍然会在实验前期耗费大量时间,并且本文所用样本量仍然较少。后续将优化特征提取方式并扩大实验样本容量。
2.3 本文检测方案
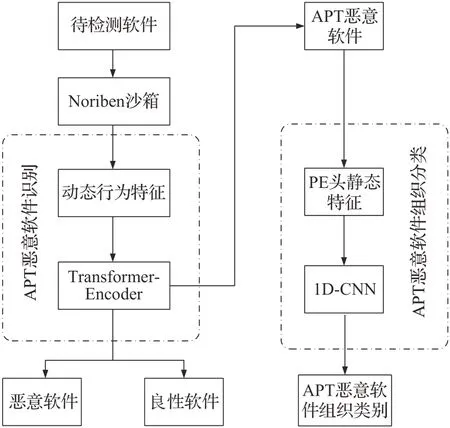
3 实验
3.1 数据集选取

3.2 实验平台配置

3.3 性能指标选取
3.4 实验结果分析








3.5 未知类型软件检测

4 结束语
