面向工业巡检的图像风格迁移方法
2023-09-25朱仲贤毛语实蔡科伟刘文涛蒲道杰王子磊
朱仲贤,毛语实,蔡科伟,刘文涛,蒲道杰,杜 瑶,王子磊
1.国网安徽省电力有限公司超高压分公司,合肥230061
2.中国科学技术大学先进技术研究院,合肥230031
随着经济的不断发展,工业场景中的设备规模不断扩大,对于场景之中各类设备的状态检测及异常定位就显得格外重要。而由于传统的人工巡检费时费力且容易出现检测盲区,因此,基于智能巡检图像的缺陷检测任务成为智能化巡检的关键一环。
以光伏电站的巡检任务为例,为了更好地定位航拍图像中光伏组件的具体位置,目前的方法往往使用虚拟仿真技术建模还原场景,同时,该技术也可以实现物体缺陷的仿真与采集,扩充缺陷的数据样本。然而,由计算机生成的虚拟数据与真实数据相比有很大的风格差异,只能用于辅助训练。实践表明,在真实数据集上直接测试使用虚拟数据训练出的模型,其结果通常不尽人意。而如果将虚拟图像转换为真实图像的风格,模型性能会得到很大改善。显然,图像风格迁移任务为虚拟图像和真实图像的感知和理解搭建了桥梁。
然而,尽管图像风格迁移任务在理论和实践上有着广阔的应用[1-3],对于虚拟仿真图像到真实图像的风格迁移任务而言,受采集引擎本身技术的限制,在大部分自动化采集到的“对应”图像上,虚拟结果与真实结果无法完全对应,甚至存在较大程度的偏移。因此,无法直接应用配对图像的风格迁移算法。为了有效利用图像间相似但不完全相同的特点,同时防止对应图像间差异对生成图像的结构造成影响。本文提出了一种基于对比学习的图像风格迁移方法。具体地,模型采用与CycleGAN方法[4]相同的双向生成对抗网络,而与CycleGAN 及其衍生的一系列方法[5-6]不同,本文所用的方法没有用到循环一致性损失,而是使用了对比学习的InfoNCE 损失。本文结合数据集自身特点,提出了一种新的正负样本选取方法,与其他工作中只选取源域图像与生成图像不同,本文方法同时选取目标域图像作为参考,使生成器生成的图像在各部分与目标域相应内容更为相似。实验结果表明,与基于循环一致性损失的方法相比,本文的方法在多种指标上有明显的提升。本文的创新之处主要在于:
(1)针对现有风格迁移方法难以生成配对的虚拟图像问题,提出了基于CycleGAN 的联合对比学习方法,通过在源域图像与生成图像、目标域图像与生成图像之间进行特征对比,本文方法能够有效提高迁移图像的质量。
(2)在联合对比学习的框架下,本文进一步提出了针对性的正负样本选取方法,通过选取目标域图像作为参考,本文方法能够生成与目标域内容更为相似的虚拟图像。
(3)可视化的结果与定量的实验指标均表明,本文方法能够生成更加逼真的保留内容结构的目标图像,进而说明了本文所提出的风格迁移方法能够有效辅助真实数据稀少的光伏巡检等工业场景检测任务。
1 相关工作
1.1 图像风格迁移
图像风格迁移的目的是将属于源域的图像在保持内容信息的前提下转换到目标域,生成具有目标域风格和源域内容的图像。具体来说,对于域X及域Y,目标是获得映射G:X→Y,使得对于给定的输入图像x∈X,经过映射后的图像x̂无法与目标域中的图像y∈Y在风格上区分,即x̂∈Y,x̂=G(x)。从数学的角度看,图像风格迁移任务是在没有联合分布p(x,y)的情况下,通过学习分布p(x̂|x),估计条件分布p(y|x)。
当前,随着计算机视觉及图像处理等技术的高速发展,图像风格迁移的应用也越来越广泛:领域自适应常常将源域图像迁移至目标域的风格,将源域特征推向目标域[7];3D 姿态估计则使用合成图像训练姿态估计器,再通过风格迁移推广到真实图像[8]。而在工程领域,风格迁移往往用来扩充图像样本[9],其扩充的数据集在智能巡检和文字识别等场景下对于如缺陷识别及语义分割等任务目标,都起到了提升准确率的作用。
1.2 生成对抗网络
在计算机视觉中,生成对抗网络(generative adversarial network,GAN)一般包括两个网络,即生成网络G(generator)和鉴别网络D(discriminator)。G 是一个图片的生成网络,输入一个随机的噪声z,通过它生成图片;D是一个图片的鉴别网络,确认一张图片是不是“真实”的。在训练过程中,生成网络G 尽量生成真实的图片去欺骗鉴别网络D,而鉴别网络D尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈(gaming)过程”。最后博弈的结果,G可以生成足以“以假乱真”的图片。
1.3 虚拟图像到真实图像的迁移任务
对于无配对图像的风格迁移任务,现有方法提出了一系列解决方案。具体地,研究者们引入了对抗学习的思想[10],使用生成对抗网络,其中生成器使用随机噪声图生成具有目标域风格和源域内容的图像,判别器辨别输入的图像是来自目标域的生成图像还是来自源域有的图像,从而提高生成图像与目标域图像的相似程度。在此基础上,一些方法[11-13]使用内容编码器和风格编码器将图像特征解耦为对应的特征,通过特征的跨域组合解码,生成目标图像。然而其中仍然存在一系列问题,具体来说,现有的风格迁移算法没有对风格信息和结构信息做明确区分,在某些数据集上,会出现较为夸张的形变。
2 基于对比学习的图像风格迁移算法
2.1 虚拟仿真光伏电站数据集
为了辅助光伏电站中的智能巡检,本文使用虚幻4引擎仿照真实场景搭建了光伏板、树木、土地、变压箱等设备的1∶1虚拟模型。同时,也对光照、道路、草皮损坏等进行了建模,以更加贴近真实的电站场景。在制作好场景设备模型后,为了将这些设备摆放在对应的位置,以得到一个像素级的虚拟光伏电站场景,需要对光伏电站整体布局进行设置,使得电站整体布局与实际布局相接近。具体地,电站中出现的设备类型共包括11×2 的光伏板40 块、6×2 的光伏板4 块、电线杆2 处、指示牌2处、变电箱1个、水坑1处、房屋1座。
对于每张输入的真实场景图像,引擎从虚拟场景的对应位置进行采集,使得虚拟场景与真实场景尽量匹配。而为了在图像采集阶段尽量消除真实与虚拟图之间的误差,在真实图像位置的不同高度处分别采样两张图像,分别为与真实场景同一高度以及略高于真实场景位置,具体采集效果如图1所示。

图1 真实与虚拟图像对比Fig.1 Comparison of real and virtual images
可以看出,受采集引擎本身技术的限制,在大部分自动化采集到的“对应”图像上,虚拟结果与真实结果无法完全对应,甚至存在较大程度的偏移。因此,无法直接应用配对图像的风格迁移算法,如pix2pix[13]等。而本文提出的基于对比学习的风格迁移方法,可以在有效利用对应图像相似性的同时,去除严格的像素级别约束,从而达到良好的迁移效果。
2.2 网络模型
受Han等人[14]启发,本文提出了一个双向的生成对抗模型,如图2所示。该模型以CycleGAN模型为基础,采用双向训练的训练方法,学习两个映射G:X→Y和F:Y→X,从而使每个域对应的生成器更充分地学习到对应域间映射关系;另一方面,在生成器的编码器后添加特征提取器,组成一个嵌入模块,来提取以图像块为基础的图像特征,进行对比学习。特别地,本文提出了一种新的正负样本选取方法及对比损失计算方法——联合对比损失。相比于仅使用生成图像和原图像特征进行对比的方法,本文方法能更好地利用目标域图像的信息,从而生成更逼真的迁移结果。

图2 基于对比学习的双向网络模型Fig.2 Bidirectional network model based on contrastive learning
具体而言,模型包含两个生成器G、F和两个判别器Dx、Dy。每个生成器都由编码器(Genc、Fenc)和译码器(Gdec、Fdec)组成。在此基础上,在每个编码器后添加一个两层的全连接网络作为特征提取器,分别记为Hx、Hy,编码器与特征提取器共同组成一个嵌入模块,如图3所示。具体地,对于域X,使用Genc与Hx作为嵌入模块embeddingx;对于域Y,则使用Fenc与Hy作为嵌入模块embeddingy。其中,生成器G学习域X到域Y的映射,生成器F则学习逆向映射;判别器Dx和Dy用来保证迁移图像属于正确的图像域;嵌入模块embeddingx和embeddingy将编码器提取的特征进行进一步投影。

图3 嵌入模块示意图Fig.3 Schematic diagram of embedded module
在训练过程中,两个生成器同时学习相反的域间映射,并输出对应的迁移图像,结合判别器的输出计算对抗损失。同时,对于每个方向的迁移,使用对应域的嵌入模块提取源域图像、生成图像、目标域图像的特征簇,并计算联合对比损失;为了进一步提高模型的稳定性,使用身份损失来防止生成器对图像进行多余的改变。
2.3 联合对比损失
(1)最大化互信息
与CUT方法[15]类似,使用噪声对比估计的框架来最小化输入与输出之间的互信息,具体地,将“查询样本”v与“正样本”v+之间相关联,而与数据集中其他内容,也就是所说的“负样本”v-进行对比。将查询样本、正样本和N个负样本都映射为K维向量,其中v,v+∈表示第n个负样本,并对这些向量作L2 归一化。这样,就建立了一个(N+1)类分类问题,来计算查询向量所对应的正样本被从另外N个负样本中选取出的概率。从数学上看,可以用交叉熵损失计算:
(2)多层的基于图像块的对比损失
在无监督学习的设置下,不论是图像规模还是图像块规模,都可以使用对比学习的方法。注意到在风格迁移领域,不仅输入和输出的整个图像需要共享内容,二者对应图像块也需要共享内容。因此,本文使用图像块作为对比学习的基本单位。进一步地,由于使用的编码器是基于卷积神经网络的结构,如果给定空间位置和编码器层数,其输出特征即可对应输入图像中一个特定图像块的特征表示,而图像块的大小取决于感受野、网络结构和网络层。因此,通过使用编码器中多个层的输出特征,可以对比不同大小的图像块的特征,其中深层的特征对应着较大的图像块。
使用embeddingx提取域X的特征,使用embeddingy提取域Y的特征。对于图像对(x,y),在Genc(X)中选取L层并将其输入Hx,从而将一幅图像映射到一簇特征其中代表选取的第l层的输出。这样一来,每个特征实际上就代表了图像中的一个图像块。记每个被选取的层中空间位置为s∈其中Sl为每层中空间位置的个数,也是图像块的个数。对于图像y,采取同样的操作,Hy输出的特征簇记为每次选取一个特征作为查询样本,记对应的特征(正样本)为,其余所有特征(负样本)为为每层的通道数,也就是特征向量的维数。对于一对图像,对比损失可以写为:
(3)正负样本选取
在现有的基于对比学习的风格迁移算法中,用作对比的图像对(x,y)往往是生成图像和对应原图像。然而,在同一位置上,虚拟引擎采集到的图像虽然与真实图像内容存在一定的偏移和区别,但二者之间仍存在相似性。另一方面,考虑到生成图像不应仅仅与原图像对应位置的图像块在特征上相似,也应该与目标域图像在相同内容上有相似的特征。因此,将图像配对后输入网络,将生成图像与目标图像也进行类似的对比,提出一个新的正负样本选取方法,如图4所示。

图4 正负样本选取示例Fig.4 Example of positive and negative sample selection
对于生成图像中的图像块v,即图4(b)中红色框,将v作为查询样本时,在源域和目标域图像对应位置的图像块被视为正样本(图4(a)和图4(c)中的红色框),而源域和目标域图像其余位置的图像块则被视为负样本(图4(a)和图4(c)中的黄色框)。也就是说,对于源域图像x、生成图像x̂、目标域图像y,对(x,x̂)及(x̂,y)都进行对比损失计算。
另一方面,注意到生成器的结构,编码器更靠近图像的层所提取的特征更容易是域相关的风格特征,而更靠近译码器的层提取的特征更倾向于域不变的内容特征。因此,对于图像对(x,x̂),直接应用公式(2)中的对比损失;而对于图像对(x̂,y),为了避免生成图像与目标域图像出现过拟合的问题,只选取更接近图像的一侧,即浅层特征进行对比学习,同时为了防止出现感受野过小的问题,将每层特征图使用双线性差值法还原为输入图像的大小,并在还原后的特征图上取32×32的图像块,对其中特征取平均值进行对比损失的计算,其中,正负样本的选择方式与上文所述方案相同。
综上所述,联合对比损失如下:
上述联合对比损失实际上是传统方法的变形与改进,可以有效地替代循环一致性损失,第一项对比损失在一定程度上起到了重建损失的作用,后一项则起到了感知损失[16]的作用。同时,使用联合对比损失可以加强训练的稳定性,加快收敛速度,并避免退化解。
2.4 其他损失
(1)对抗损失
对抗损失用来保证生成器生成视觉上与目标域图像相似的结果,对于映射G:X→Y及其判别器Dy,对抗损失为:
通过上述对抗损失,生成器G试图生成图像G(x)使之看起来与目标域中的图像相似;而判别器Dy试图尽可能准确地分辨出图像G(x)和真正的目标域图像y。类似地,对于映射F:Y→X及其判别器Dx,有:
因此,总的对抗损失为:(2)对抗损失
为了避免生成器对图像做出不必要的改变,引入身份损失。与CycleGAN中类似,将目标域的真实样本输入对应的生成器,并做正则化计算,具体地,该损失函数为:
(3)总体损失函数
综上所述,联合以上三类损失,构建完整的损失函数,表示为:
其中,λGAN、λcon、λidt为控制相应损失权重的超参数。
3 实验结果
3.1 数据集生成和数据预处理
如2.1节中所述,对于每一张真实图像,都在相应的虚拟场景中生成两张不同高度的图像,共计338张虚拟图像。根据对应关系,将图像的分辨率全部调整为512×512,并将对应图像拼接得到分辨率为512×1 024图像,如图5所示,作为训练集。而对于测试集,则不需要输入对应的真实图像,仅仅需要输入虚拟引擎采集的虚拟图像,即可输出迁移后的伪真实图像。

图5 匹配后的图像对Fig.5 Matched image pair
3.2 实验设置
使用Ubuntu16.04操作系统在两块GeForce GTX1080TI上进行训练,所使用的深度学习框架为Pytorch1.5.0。
采用随机梯度下降训练模型,选用Adam 优化器,优化器参数β1=0.5,β2=0.999,并使用学习率衰减策略,当训练轮数超过总轮数的一半时,学习率线性递减,初始学习率为1E-4。与CycleGAN 中相同,使用基于ResNet[16]的生成器与基于PatchGAN[17]的判别器。
3.3 全监督方法结果
由于本文数据集使用相似但不完全一致的图像对,为了有效地完成风格迁移任务,一个简单的想法就是直接使用全监督风格迁移网络,将对应的真实图像视为ground truth进行实验。
然而,直接使用有监督算法的结果却不尽如人意。以经典的pix2pix 算法为例,说明直接使用有监督算法的缺陷,从而说明本文所提方法的优越性。
可以发现,由于有监督的风格迁移方法在通常情况下使用像素级别的L1 损失作为约束条件,模型在学习的过程中会将目标域图像的内容一起学习到目标域的特征中,从而在生成图像上保留相应的内容。如图6(b)中,很明显在右上角的光伏板上,源域(内容域)与目标域(风格域)的对应位置内容不一致,所以导致了光伏板错位的问题;同理,在图像下部出现了光伏板缺失,也就是内容丢失的问题,这些问题会在很大程度上影响下游任务的质量,甚至在一些对图像细节要求较高的任务上,如语义分割、图像配准等,单纯使用有监督的迁移模型生成的图像完全无法得到应用。因此,为了在该数据集上生成逼真且内容不发生变化的仿真图像,本文的算法还应该基于无监督的图像迁移方法,另一方面,上述问题也说明了,像素级别的严格约束对于该任务来讲只能起到负面作用,不利于生成图像的内容完整性和一致性。

图6 pix2pix算法结果Fig.6 pix2pix algorithm results
3.4 与无监督方法对比
为了证明本方法的有效性,在数据集上训练Cycle-GAN、DSMAP[12]、CUT 三种方法,分别对应基于循环一致性损失、基于解耦方法和基于对比学习方法的三种风格迁移思路。为了更好地比较迁移结果,使用各方法对应文献中给出的参数及实验设置,各方法训练环境均相同。与3.3节类似,给出了各方法的可视化效果图,从视觉相似度的角度说明了本文方法的优越性,同时,也同样给出了用户感知结果。另一方面,由于本文算法所用的模型不包含解耦和逐像素计算损失过程,因此迁移时间较其他方法有较大程度的缩短。最后,使用FID指标在特征层面定量地计算迁移结果与目标域的相似性。
(1)可视化结果
图7列出了不同迁移方法对应的迁移结果,给出了数据集中两种典型场景:密集光伏板场景和包含空旷草地场景下的迁移效果示意图。

图7 不同方法迁移效果样例图Fig.7 Example of transfer effect of different methods
对结果做分析:在样例1中,CycleGAN方法出现了明显的内容结构缺失问题,很大一部分光伏板在迁移后成为了草地的纹理;CUT 方法的清晰度则有明显的不足,出现了较为明显的模糊现象,同时,光伏板上的纹理也与源域图像存在一定差别,色块感较强;而本文提出的方法在大体上保存了光伏板的整体内容,生成的图像也没有明显的模糊感。在样例2 中,CycleGAN 方法与本文方法迁移效果都比较好,但CycleGAN方法左侧的小块光伏板同样渐变为草地;而CUT 方法仍然存在模糊的问题,生成图像中光伏板也会出现变型的问题。而在上述两个样例中,DSMAP 方法都比较明显地暴露了解耦不充分的问题,可视化结果较差。此外,上述所有方法都出现了一定程度的整体偏移,这是由无监督风格迁移任务本身的任务设置导致的,在不加入其他监督的条件下,仍是研究的重点与难点。
(2)FID结果
FID 是基于Frechet 距离的特征对比方法,FID 的值越小,说明两组特征的分布越相似,因此,该指标常被用作生成对抗网络的性能评估指标。具体地,Frechet距离的计算方法为:
其中,G1、G2为需要进行比较的高斯分布,m1、m2分别为G1、G2的均值,C1、C2分别为G1、G2的协方差。FID使用Google 提出的非对称深度卷积网络Inception-v3[18]来提取图像的激活特征,并计算二者的Frechet 距离。由于Inceptionv3网络提取的图像特征更为多样化,使用该网络输出特征计算的Frechet距离能更好地反应图像间的分布相似度。在本实验中,计算各方法生成图像与目标域图像间的FID值,进一步对比各方法生成图像的质量。表1 给出了各对比方法与本文方法所得到的生成图像集合与目标域图像集合的FID指标。

表1 不同方法FID值对比Table 1 Comparison of FID values of different methods
根据表1 结果分析,本文的方法在FID 指标上明显低于DSMAP 方法和CUT 方法。与CycleGAN 方法相比,虽然改进幅度不大,仍然有一定优势。结合训练时间,可以认为,本文方法在生成效果上略优于CycleGAN的结果,主要体现在物体缺失问题的改善上,但在训练时间上有较大优势,总体而言,本文方法略优于现有风格迁移方法。
(3)LPIPS结果
感知相似度(LPIPS)由Zhang 等人[19]于2018 年提出,使用深度特征来度量图像间的相似度。与其他评估指标不同,该指标旨在反映人类的视觉相似度——即符合人类判断方式的图像相似度。具体地,对于图像x和x0,利用Alex 网络从L层中提取特征堆栈并进行单元归一化计算,将第l层特征结果记为。随后,对其进行缩放激活并计算l2距离,其具体计算方法为:
其中,H、W为图像尺寸对应参数,wl为缩放权重。
在本实验中,计算各方法生成图像与目标域图像间的LPIPS值。表2出了各对比方法与本文方法所得到的生成图像集合与目标域图像集合的LPIPS指标。

表2 不同方法LPIPS值对比Table 2 Comparison of LPIPS values of different methods
根据表2结果分析,本文的方法在感知相似度上明显低于其他几种算法。通过观察实验结果可以发现,LPIPS 值的高低与可视化结果基本一致。因此可以认为,从视觉感知的相似程度上,本文方法略优于现有风格迁移方法。
(4)用户感知
以随机的顺序向用户展示上述对比方法与本文方法的生成结果,请用户比对生成图像与源域、目标域图像,并提出下列问题:
问题1 哪张图片更好地保留了内容信息(形状、语义等)?
问题2 哪张图片的迁移效果更为清晰?
问题3 哪张图片的更接近目标域中的图片?
由于DSMAP 方法的可视化结果相较而言较差,因此只使用CycleGAN、CUT 与本文方法进行对比,每个用户被展示的图像不相同,结果如图8所示。
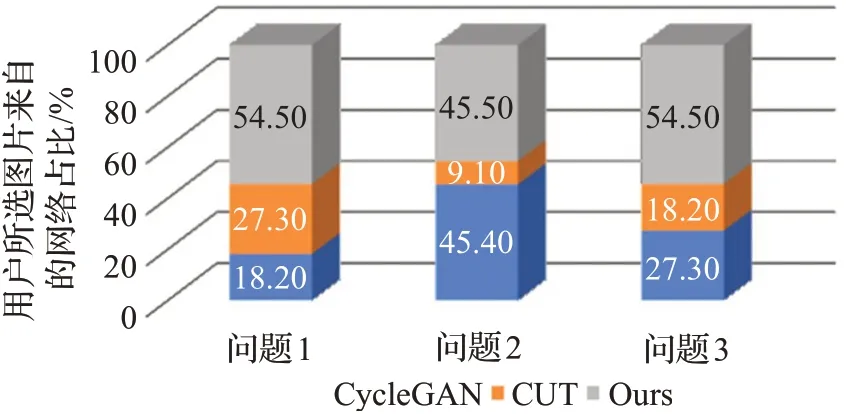
图8 用户感知结果Fig.8 User perception results
显然,对于三个问题,本文的方法都获得了最高的得分。对于问题1,超过一半的用户认为本文的方法能更好地保留图像的形状和语义信息,27.3%的用户则认为CUT 的内容一致性更好,只有不到20%的用户认为其保留内容的能力更强;对于问题2,CycleGAN和本文方法的得分相近,说明在纹理等风格信息迁移方面,二者效果相差不大,均远好于CUT方法;对于问题3,超过一半的用户认为本文方法得到的生成图像与目标域中原始图像更为相似。综上所述,从视觉感知的角度看,本文方法具有更好的迁移效果。
结合3.3 节中可视化的结果,对用户感知结果做分析:CycleGAN 方法的生成图像普遍会存在图像边界和小块物体的缺失问题,而CUT 方法的结果更容易出现变形而不是缺失的问题,因此用户在视觉上观察的结果会优于CycleGAN。本文方法大部分生成图像都可以较好地保留光伏板等主体内容的信息,仅在图像边缘处容易出现错误,具体如失败样例分析中所述,因此,本方法在问题1 中得到了最多用户的认可。至于生成图像的清晰度,不难发现,CycleGAN 方法的纹理迁移更为细致,尤其是对背景内容而言,因此,其与本文方法得分相似。综合来讲,在CycleGAN方法没有出现明显内容缺失的情况下,其迁移效果同样较为优秀,但其稳定性低于本文方法,生成数据的方差较大,因此,CUT与CycleGAN方法的整体迁移效果略差于本文提出的基于对比学习的方法。
(5)训练时间
由于本方法不使用像素级别的约束,而只在特征层面上计算损失,且不包含解耦操作,因此,该方法在训练时间上较其他方法有明显的优势。为了验证该效果,对几种算法的训练时间进行了对比,结果如表3所示。

表3 不同方法训练时间对比表Table 3 Comparison of training time of different methods
可以看出,本文方法及相关对比学习方法在训练时间上有明显的优势。而与只进行单向迁移和计算的CUT算法相比,本文方法的训练速度略慢,但仍远快于基于循环一致性损失的方法,与基于解耦思想的DSMAP算法相比,本文方法的训练速度有了本质上的提升。因此,本文方法在很大程度上节约了时间和算力成本,这无疑有利于扩大风格迁移算法在工程上的应用。
(6)失败样例分析
受数据集中数据分布和方法本身的限制,提出的方法也并非可以成功转换所有图像,本节将挑选典型的失败样例进行分析,如图9所示。

图9 典型错例Fig.9 Typical error example
在样例1中,图像左下角的道路被错误地转换为了光伏板的纹理,但图像主体的光伏板没有发生转换错误;而在样例2 中,位于图像右上的光伏板转换效果较差。通过对数据集中其他相似场景的分析,发现样例1中的问题往往出现在图像边缘的小块的道路上且并非所有的位于边缘区域的道路都被错误转换,而对于较长的、横穿整幅图像的道路则没有这个问题,因此推断,由于缺乏实例级别的监督信息,模型错误地将学习到的位于图像边缘的光伏板结构匹配到图9(a)中这种位于图像边缘的道路上。对于样例2,发现数据集中所有位于类似位置的光伏板转换效果都较差,结合训练所用的真实和虚拟图像,推断该问题的产生主要是由于训练数据集中包含的类似图像有限,只有极少数图像拥有相似的场景,模型无法充分学习到斜置光伏板的信息,因此试图将其转换成正置光伏板的纹理,导致错误的发生。
4 结束语
本文主要对图像风格迁移任务中的结构一致性问题进行了研究。针对虚拟引擎生成的图像与真实图像相似但不完全相同的问题,提出一种基于对比学习的图像风格迁移方法。首先,介绍了虚拟引擎的建模仿真过程及图像采集的过程,说明相关技术限制下无法生成与真实图像完全配对的虚拟图像的现状;随后,针对上述问题,提出了一种基于CycleGAN 的联合对比学习方法,通过在源域图像与生成图像、目标域图像与生成图像之间进行特征对比,提高迁移图像的质量,在保持图像主体内容结构不发生较大变化的同时生成更为逼真的“伪”目标域图像。以光伏巡检图像为代表的实验结果表明,本文所提方法在保留内容结构上优于CycleGAN及DSMAP方法,同时在图像的逼真程度上优于CUT方法;另一方面,通过定量计算图像深层激活特征的相似程度,即FID 指标,本文方法也更优于上述几种算法。综上所述,本文方法在虚拟到真实图像的迁移上具有良好效果,为虚拟引擎仿真建模生成数据在工程方面的大规模应用提供了技术保障。然而,由于相关的研究工作较少,目前基于对比学习的图像风格迁移方法的主要创新点都是围绕正负样本的选取展开的,因此未来可以考虑改进相关损失函数,更改嵌入模块结构等方式,为该领域的研究开辟新的道路。
