基于DSM-YOLO v5的无人机航拍图像目标检测
2023-09-25陈卫彪贾小军朱响斌冉二飞
陈卫彪,贾小军,朱响斌,冉二飞,谢 昊
1.浙江师范大学计算机科学与技术学院,浙江金华321004
2.嘉兴学院信息科学与工程学院,浙江嘉兴314001
3.浙江理工大学计算机科学与技术学院(人工智能学院),杭州310018
随着无人机(unmanned aerial vehicle,UAV)技术的发展和制造成本的降低,无人机的应用愈发地深入各行各业。目标检测任务是无人机应用最重要的组成部分,广泛应用于抢险救灾、测绘航测、应急救援等领域。目前目标检测算法主要分为两类,分别是以背景减去法、光流法和帧差法为代表的传统算法和以深度学习为代表的新型算法。在航拍图像的目标检测任务中,Yalcin 等[1]提出了利用光流法检测运动目标的特征,该方法对运动目标检测效果明显,但检测精度以及对静止目标检测效果差。Mei等[2]提出模板匹配检测目标的方法。将视频中含有运动图像的每帧单独提取,然后用提前准备好的车辆等物体的模板进行匹配检测。该方法对车辆等形状明显的物体检测效果较好,但存在计算量过大、难以部署的问题。
以深度学习为基础的目标检测算法又分为两类,分别是单阶段式(one-stage)和两阶段式(two-stage)。YOLO(you only look once)[3]是一种典型的单阶段式目标检测算法,它直接将目标边界定位问题转化为回归问题,图像被缩小到统一尺寸,并以网格进行均等划分。模型仅需要处理图像一次便能得到边界框坐标和类概率。两阶段式的检测算法先生成一系列的候选边界框作为样本,而后由卷积神经网络对样本进行分类,例如R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]、R-FCN[7]等。张瑞倩等[8]根据多尺度空洞卷积感受野大的特点,提出一种新的网络结构,提升了无人机航拍图像目标检测任务的查准率和查全率,但未能对网络做轻量化处理。陈旭等[9]通过增加特征融合模块、残差空洞卷积等方式,有效地提高了网络对无人机航拍图像的检测能力,改造之后的模型具有遮挡目标识别率高、虚警率低的优点,但网络所需要的算力大幅增长。韩玉洁等[10]以YOLO v4为基础,通过改变激活函数、损失函数和以自对抗训练的方式增强数据集,有效地提高了网络在无人机航拍图像目标检测任务中的检测精度,但依旧存在小目标检测能力差、网络模型体积大的问题。刘鑫等[11]以CenterNet为基础,通过增加自适应基础模块、全局注意力模块和高质量解码模块,在模型复杂度不变的前提下,提升了网络的检测精度,但网络所需参数量大、算力要求高,难于部署在无人机平台中。王浩雪等[12]针对无人机航拍图像小目标多、易被遮挡的特点,提出了S-YOLO v4网络,通过增加SE(squeeze and excitation)注意力模块、小目标检测层和改进损失函数的方式,增强了网络的鲁棒性,提升了网络的检测精度,但带来了网络体积和总参数量变大的问题。王胜科等[13]以CenterNet为基础,通过增加可变形双重注意力机制、改变极大值抑制方式和引入LegoNet卷积单元的手段,有效提高了网络的检测精度。但在模型的推理速度和模型体积轻量化改进上还有待于提升。Zhu 等[14]通过添加Transformer Encoder 模块和注意力机制,提高了无人机目标检测任务的检测精度,刷新了VisDrone2021 数据集的检测纪录,但算法所需的参数、网络层数以及算力大幅度提高。Liu 等[15]通过修改YOLO v3 的网络结构,增加ResNet模块,在高层网络结构添加额外的卷积结构以丰富空间信息,提高了小目标物体的检测能力。Lin 等[16]通过使用多尺度融合的特征聚合框架和高精度的上采样方法,改善了在高分辨率图像中的采样精度不足问题。Zhang等[17]通过密集裁剪和增加局部注意力模块的方式,改善了行人等目标由于占图像面积小、检测率低的问题,有效提高了对于无人机视角下的行人检测精度。Luo 等[18]在YOLO v5l 的基础上,对主干网络中的特征提取模块进行替换,并通过在Focus 模块中增加注意力机制、优化锚框尺寸等方法,提高了网络的精度,但其网络参数量高达2 700 万,难以部署至无人机等边缘设备中。Zhang 等[19]通过在YOLO v5 中增加CA(coordinate attention)注意力机制和CFEM(context feature enhancement module)模块,提高了网络对小目标的检测能力,但增加的模块也带来了参数量和算力的提升。Yang等[20]在YOLO v5的基础上,通过优化锚框尺寸、增加注意力机制、添加小目标检测层的方式提高了检测精度,但未考虑网络的参数量增加和算力需求变大等问题。李壮飞等[21]基于YOLO v5 网络,在其中引入SENet 注意力机制、增加小目标检测层、改进损失函数,提高了对于小车辆目标的查准率,但同时也带来了计算量增加的问题。苏凯第等[22]通过增加卷积层数来提高算法深度,采用多次循环神经网络提高训练速度,有效地提高了YOLO v5 的识别速度和精度,但也带来了更多的参数和更高的算力要求,难以适配无人机等边缘设备。
目前主流的目标检测算法采取基于卷积神经网络的深度学习方式,其特征提取和表达能力强,由于这些算法多用于自然视角下的目标检测场景,在对无人机航拍图像数据中的车辆、行人等小目标进行检测时,难以取得让人满意的效果。与普通场景的目标检测相比,无人机航拍图像存在以下几个特点:(1)检测目标像素占比少;(2)无人机硬件限制,难以提供足够的算力和空间;(3)航拍图像复杂,外界干扰因素大。
针对以上问题,本文以YOLO v5算法为基础,提出一种基于深度可分离的多头网络结构,将其命名为DSM-YOLO v5(depthwise separable multiplex YOLO v5)算法,通过增加检测头的数量提升检测精度,增加深度可分离结构降低网络的算力要求。与当前主流无人机航拍图像目标检测算法不同的是,在聚焦提高网络检测能力的同时降低了网络的参数量。
1 DSM-YOLO v5网络结构
1.1 YOLO v5网络结构
YOLO v5 作为目前目标检测领域中的主流算法,分为v5s、v5m、v5l、v5x 四个版本,可以根据不同的应用领域动态调整网络结构和深度。基于无人机平台的算力和内存空间有限的特点,本研究选择参数量最小的YOLO v5s[23]进行对比实验。YOLO v5s 主要由Backbone、Head 和Output 层三部分组成,相较于YOLO v4,Backbone中添加了focus层,能够对特征图进行切片,提高特征提取能力。Head 层保持和YOLO v4 同样的网络结构,其主要功能有特征融合、目标检测,采取自顶向下的网络结构,将高层特征与底层特征融合,以此加强网络的特征融合能力。通过对不同尺度的特征图进行检测,最大限度地提高目标检测的精度,Output 层则根据预设好的三个锚框对输出特征图进行预测,使用非极大值抑制去除低可信度的数据,最终输出检测的结果。
然而,在应对无人机航拍图像目标检测任务时,YOLO v5s 算法所需要的体积和算力仍然超出目前无人机平台所能提供的硬件算力,难以有效部署在无人机等移动设备上进行实时检测。为了解决这一问题,对YOLO v5s算法进行轻量化改进具有重要的实用价值。
1.2 深度可分离算法
深度可分离算法由谷歌团队提出,其核心思想是将一个普通卷积替换成深度卷积和逐点卷积[24]。深度卷积先用Channel为1的滤波器对每个输入通道进行单独卷积,在此过程之中,Padding 及Stride 均为1,保证输出特征图的尺寸和通道保持不变。在逐点卷积的过程中,对深度卷积输出的特征图使用大小为1×1 的滤波器进行卷积,最终输出特征图,特征图的尺寸和通道数都和普通卷积输出的结果一致。深度可分离模块结构如图1所示。

图1 深度可分离模块结构Fig.1 Depthwise separable model block structure
假设普通卷积使用M个大小为DK的卷积核,输入特征图的通道数为N,大小为DF,则普通卷积的计算量Fconv[25]为:
在使用深度可分离模块替换普通卷积的前提下,计算分为两个步骤,分别是深度卷积和逐点卷积,其计算量Fdepth[25]为:
用公式(1)除以公式(2),最终得到的结果便是:
由于在MobileNet 网络中,卷积核的大小DK一般为3,由公式(3)可以推出,深度可分离模块的计算量为普通卷积模块计算量的1/9~1/8[25]。
1.3 改进的YOLO v5网络结构
在无人机航拍图像目标检测中,由于检测目标所占图像的比例较小,传统YOLO v5s 的Backbone 层难以有效提取目标物的特征,导致最终的查准率、查全率低,并且在Head 层生成特征图的过程中,未与网络高层进行残差连接,致使特征图中丢失部分检测目标细节。为了提高YOLO v5s模型的小目标感知能力,在原有三个检测头的基础上加深网络结构,额外添加一个新的检测头,该检测头在高层网络中,输出160×160 大尺寸特征图,由于YOLO v5s 网络整体下采样倍数较大,而无人机航拍图像中小目标物体面积占比极小,经过高倍数下采样之后,小目标物体的特征已和背景融为一体,难以提取。相较于传统YOLO v5s 的三个小尺寸80×80、40×40、20×20检测头,大尺寸检测头能够从网络高层提取小目标特征,有效加强对于小目标物体的感知能力。在Head 层中,为了提高网络对于小目标物体特征的提取能力,将Head层与Backbone的高层进行残差连接。
为了降低网络的参数,将原有Conv 模块中的普通卷积替换为深度可分离卷积,组成新的深度可分离卷积模块Conv_ds,加入深度可分离卷积模块Conv_ds 后,DSM-YOLO v5 相较于YOLO v5s,额外加深了网络层数,使得DSM-YOLO v5具有更好的特征表达能力。虽然网络层数增加了,但是由于深度可分离模块的特点,整个网络的体积及参数量却降低了。通过残差连接的方式,加深了特征融合的能力,能更有效地提取小目标物体的信息。改进的整个网络结构如图2(a)所示,图2(b)为其中的子模板结构。
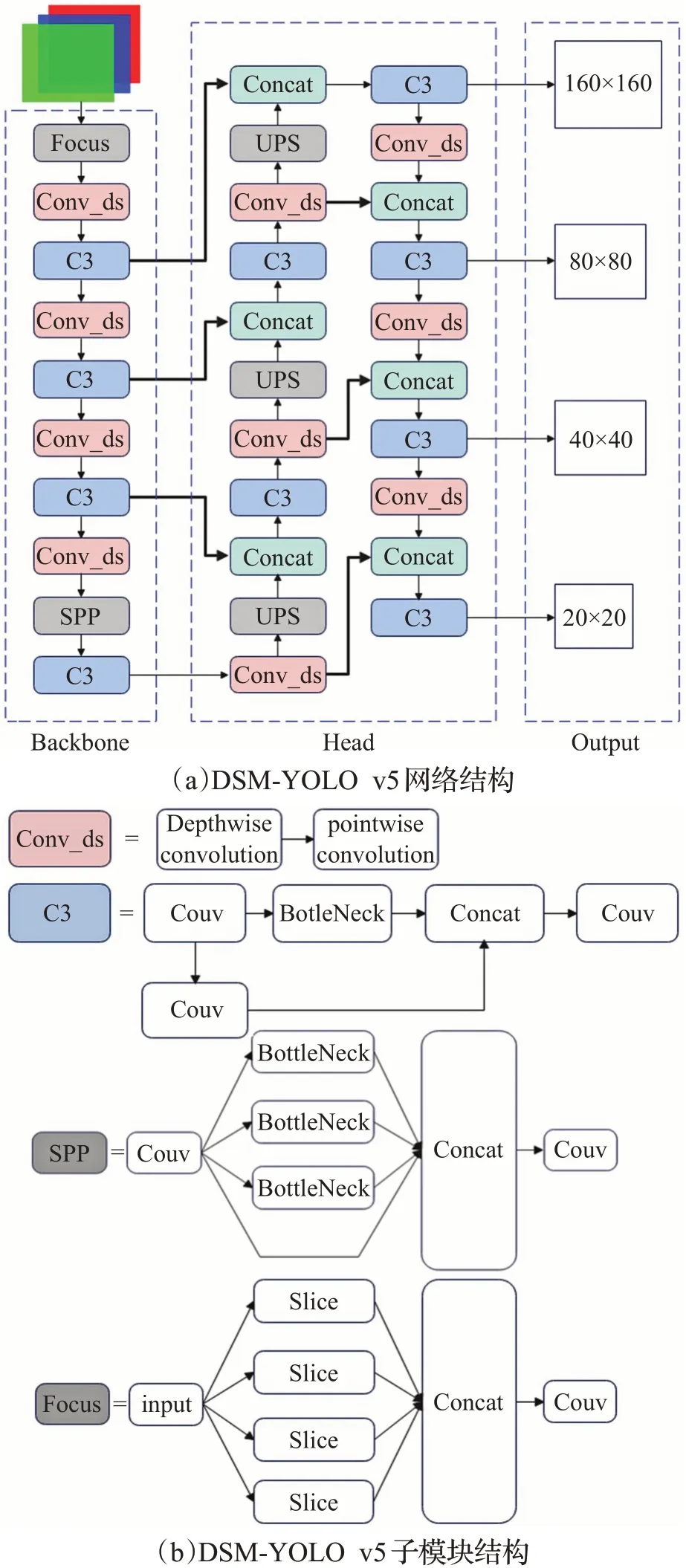
图2 DSM-YOLO v5网络结构Fig.2 DSM-YOLO v5 network structure
2 实验结果与分析
2.1 实验数据
实验采用VisDrone2019[26]数据集。VisDrone 数据集由天津大学机器学习与数据挖掘实验室的AISKYEYE团队发布,数据集取自中国14个不同的城市,环境多种多样,城市与乡村、各种天气和照明条件。图像检测目标密度广,稀疏与密集均有,是目前中国无人机航拍数据量最大、覆盖范围最广、环境最复杂的数据集之一。如图3所示,VisDrone2019数据集共包含10类航拍检测目标,由6 471 张训练集、548 张验证集、3 190 张测试集图片组成。其中,训练集平均每张图片含有53个标签,测试集平均有71 个标签,并且每个类别均有不同程度的遮挡。数据集类别由pedestrian、people、bicycle、car、van、truck、tricycle、awning-tricyle、bus、motor 组成。由于使用的网络结构为深度可分离模块,所以在预训练权重上使用了基于imagenet 数据集训练的mobilenetv1 权重文件。

图3 VisDrone2019数据集Fig.3 VisDrone2019 dataset
为了方便训练,将VisDrone 的文件结构修改为PASCAL VOC结构,并在训练开始前,对所有数据使用Mosaic技术进行数据增强[27]。随机选取四张图片,对其进行翻转、缩放、色域调整等操作,再将其组合成一张新的图片,以此增强数据样本的多样性,并且能够在硬件资源有限的情况下,提高网络的训练能力。
2.2 训练环境
实验平台采用12核Intel®Xeon®Platinum 8255C CPU @ 2.50 GHz,内存为45 GB,操作系统为Ubuntu 20.04。以Python 3.8 实现网络模型,代码编辑器采用PyCharm Community Edition 版本,使用Pytorch 框架。显卡为RTX2080Ti,cuda版本为11.3。
2.3 评价指标
为更有效直观地展示DSM-YOLO v5的改进效果,以平均精度值(mean average precision,mAP)、查全率(recall)、查准率(precision)作为网络结构在无人机航拍图像目标检测任务中学习能力的评价依据。以网络模型的体积大小和所需要的参数量作为网络对无人机航拍图像目标检测任务适应能力的指标。模型需要的体积和占用的参数越小,则代表算法更加匹配无人机航拍图像目标检测任务。
2.4 实验结果
整个训练过程迭代300个epoch。为保证模型的稳定,在前3 个epoch 采用warmup 预热学习策略,初始学习率设置为0.01,后续则采用余弦退火算法控制学习率衰减,余弦退火算法超参数lrf 为0.2,最低学习率为0.002。经过300 个epoch 的训练之后,得到的损失曲线如图4所示,其中Box_loss代表模型预测边界框和真实边界框之间的差异大小,Class_loss为分类损失,用于判断模型是否能准确识别出图像中的对象,并将其分类到正确的类别中。Object_loss为置信度损失,用于监督grid中是否存在物体,计算网络的置信度。从图4中可以看出,当epoch 为300 轮时,DSM-YOLO v5 网络的各项loss值已经不再下降,网络已收敛,趋于稳定。
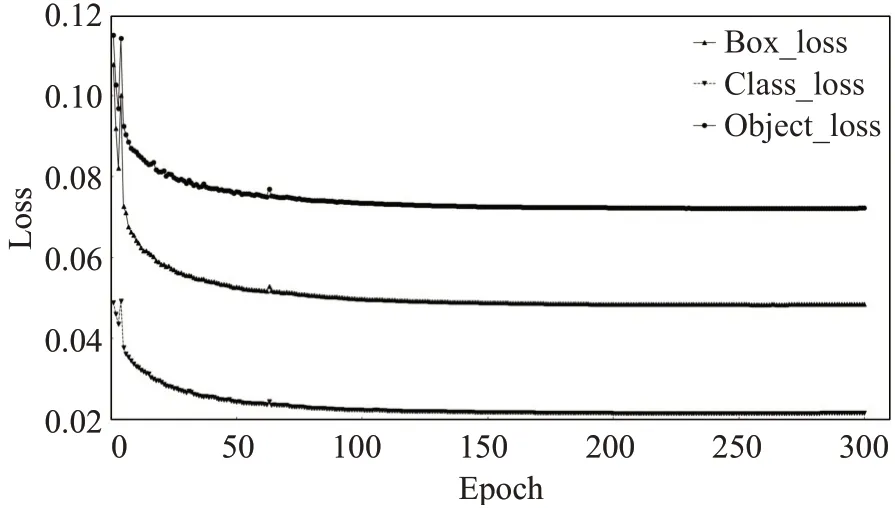
图4 DSM-YOLO v5损失曲线Fig.4 DSM-YOLO v5 loss curve
利用训练后的网络结构进行目标检测,使用的数据为测试集的样本数据。如图5 所示,其中图5(a)为YOLO v5s的实验结果,图5(b)为DSM-YOLO v5的实验结果。可以看出DSM-YOLO v5 在除bicycle 分类外,其他各个分类的精度都优于YOLO v5s,pedestrain、people、car、van、truck、tricycle、awning-tricycle、bus、motor九个类别分别提高0.044、0.021、0.069、0.061、0.048、0.021、0.008、0.042、0.042。在IoU(intersection over union)为0.5时,DSM-YOLO v5的mAP值为36.8%,高于YOLO v5s。
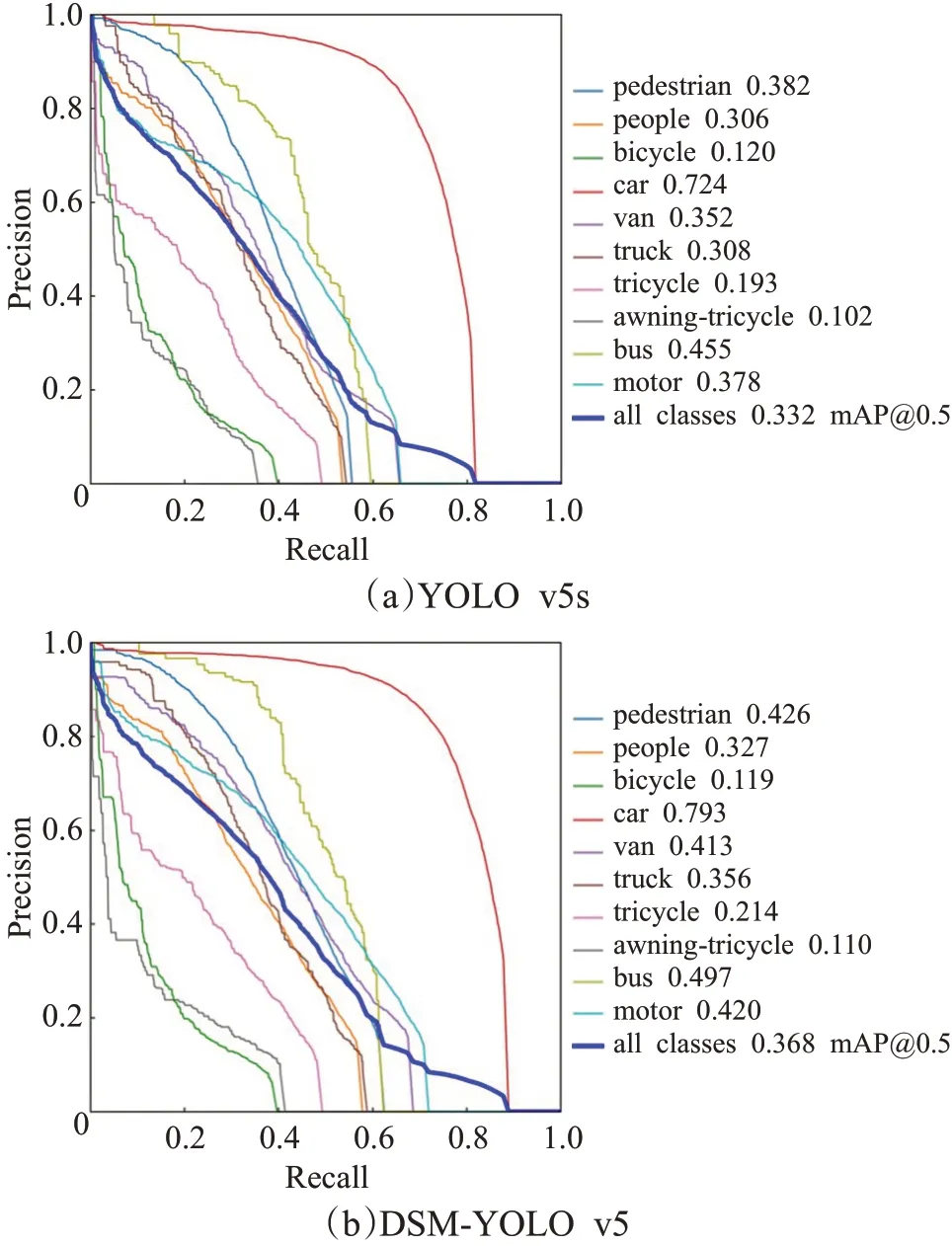
图5 Precision-Recall曲线图Fig.5 Precision-Recall curve
为了对网络结构性能进行验证,选取DetNet59[28]、CornerNet[28]、Fast R-CNN[29]、CenterNet[30]、MixedYOLOv3-LITE[31]、YOLO v5s 算法进行目标检测对比实验,实验结果如表1所示。在mAP@0.5上,DSM-YOLO v5取得了明显的提升,相较于DetNet59 提高21.5 个百分点、CornerNet 提高19.4 个百分点、Fast R-CNN 提高15.1 个百分点、CenterNet 提高10.6%、MixedYOLOv3-LITE 提高8.3 个百分点、YOLO v5s 提高了3.6 个百分点。在pedestrain、people、car、van、truck、tricycle、bus以及motor八个类别上达到了最大的AP,分别为42.6%、32.7%、79.3%、41.3%、35.6%、21.4%、49.7%以及42%。实验结果表明,改进的算法能够较明显地提高网络对于小目标的检测能力,在无人机航拍图像目标检测任务中表现较好。

表1 不同算法在VisDrone2019数据集上的目标检测结果Table 1 Target detection results of different algorithms on VisDrone2019 dataset
相较于普通的目标检测任务,无人机航拍图像对网络结构的特征提取能力要求更高,对目标的精确识别难度更大,传统的目标检测算法难以满足要求。DSMYOLO v5 通过加深网络结构,增加浅层和深层网络残差连接,以及增加小目标检测头的方式,有效地提高了网络对于无人机航拍图像目标检测任务的识别能力,对于复杂场景、高密度场景的目标,经过高倍率下采样之后,其特征已经无法识别,密集目标和背景混杂在一起,和深层连接的检测头难以识别。新增的160×160 检测头直接和浅层网络相连接,能够在进行高倍率下采样之前获得复杂场景、高密度场景的目标的特征信息,能有效识别目标。由于无人机硬件本身的限制,小型无人机平台对于算法的参数量、模型体积比较敏感,DSM-YOLO v5与YOLO v5 中的两种模型s 型和l 型的性能比较结果如表2 所示,DSM-YOLO v5 通过使用深度可分离的思想,将传统YOLO v5s 的Conv 普通卷积模块替换为深度可分离模块Conv_ds,有效地减小了网络的参数量和模型体积,YOLO v5l 虽然在检测精度上小幅优于DSM-YOLO v5,但其所需的参数量和模型的体积分别为DSM-YOLO v5的8.4倍和8.1倍。DSM-YOLO v5在保证精度的前提下,大大降低了网络结构对硬件的要求,更有利于算法在无人机等小型设备上使用。

表2 YOLO v5与DSM-YOLO v5各项指标对比Table 2 Comparison of indicators between YOLO v5 and DSM-YOLO v5
为了验证DSM-YOLO v5 网络的有效性,选择额外的DroneVehicle 数据集和RSOD 数据集进行测试。DroneVehicle数据集为无人机航拍下的红外汽车图像数据集,其中训练集共有17 957张图片,测试集8 980张图片,验证集共有1 467张图片,共含有car目标428 086个、truck 目标25 960 个、bus 目标16 590 个、van 目标12 708个和feright car 目标17 173 个。RSOD 为遥感图像数据集,其中训练集818 张图片,测试集99 张图片共含有aircraft目标4 993个、oiltank目标1 586个、overpass目标180 个和playground 目标191 个。DSM-YOLO v5 的检测结果如表3 所示,对于DroneVehicle 数据集,AP 值最高为car类98.1%,Recall最高为car类95.5%,Precision最高为car类94.9%,mAP@0.5为81.3%。在RSOD数据集中,AP值最高为aircraft类98.8%,Recall最高为overpass类98.9%,Precision最高为oiltank类98.7%,mAP@0.5为90.6%。实验数据表明DSM-YOLO v5 的检测效果较好,在不同的数据集中能达到令人满意的检测效果。与VisDrone2019相比,DroneVehicle数据集属于红外图像,RSOD 数据集属于遥感图像,整体色调、明暗等画面风格统一,减小了目标检测的难度,DroneVehicle和RSOD数据集中的目标轮廓明显,不存在重叠遮挡、目标俯视图不会随视角大幅度变化。

表3 DSM-YOLO v5在不同数据集上的检测结果Table 3 Detection results of DSM-YOLO v5 on different dataset
为了验证DSM-YOLO v5中所提出的大尺寸检测头和MobileNet轻量化改进的实际效果,对DSM-YOLOv5网络进行消融实验,实验结果如表4所示。其中第一行到第四行分别屏蔽不同尺寸的检测头。屏蔽160×160检测头时,mAP@0.5 为33.2%,屏蔽80×80 检测头时,mAP@0.5 为34.8%,屏蔽40×40 检测头时,mAP@0.5 为36.3%,屏蔽20×20 检测头时,mAP@0.5 为38.1%,从数据可以看出,160×160 的检测头对精度的提升最大,能有效提高网络的检测能力。第五行和第六行的对比可以看出,MobileNet 轻量化模块的加入导致检测精度小幅度下降,Precision 值从53.7%下降为51.1%,Recall 值从39.7%下降为37%,mAP@0.5从38.4%下降为36.8%,下降值并不明显,但其网络结构所需参数量却大大降低。考虑到无人机平台的算力低和空间小特性,算法的轻量化处理存在必要性。

表4 消融实验Table 4 Ablation experiment
2.5 目标检测
为了更加直观地展示DSM-YOLO v5 在无人机航拍图像上的目标检测能力,选择了部分实验结果,如图6所示。图6 上面一行的三张图像是使用YOLO v5s 网络结构的检测结果,下面一行的三张图像则是使用DSM-YOLO v5网络结构检测的结果。显然,对于远处小而密集的物体,DSM-YOLO v5在检测时能够准确地识别,而YOLOv5s的检测效果逊色于DSM-YOLO v5。综合来看,DSM-YOLO v5 其检测效果优于YOLO v5s算法。

图6 目标检测结果Fig.6 Target detection results
为了验证DSM-YOLO v5算法的鲁棒性,本文选取了不同环境和光线下的场景作为检测对象。检测结果如图7 所示。通过图7 第一行的三张图片,可以看到在光线较弱的情况下,DSM-YOLO v5仍然能够有效地检测出大多数有效目标。这表明DSM-YOLO v5 算法具有一定的光线适应性,能够适应多种光照条件下的目标检测任务。此外,DSM-YOLO v5算法还能够在各种室内和室外环境中正常运行,这进一步证明了其鲁棒性。第二行的三张图片显示了DSM-YOLO v5 在目标密集的情况下的检测效果。这是一个具有挑战性的场景,因为目标过于密集,算法很容易将它们误判为一个单独的目标,或者错过其中的一些目标。然而,DSM-YOLO v5能够有效地检测出每一个目标,并且准确地识别它们的位置和类别,表现出较强的鲁棒性和准确性。

图7 DSM-YOLO v5目标检测结果Fig.7 DSM-YOLO v5 target detection results
3 结语
根据无人机航拍图像的特点,提出了一种能够在复杂环境、密集场景中进行目标检测的网络结构DSMYOLO v5。通过加深特征融合部分的网络深度、增加额外的小目标检测头的方式,能够有效地提高无人机航拍图像的检测效率,提高查准率、查全率等各项指标。将普通的卷积模块替换为深度可分离模块,能明显减少网络所需要的参数,以及模型所占用的空间,使其更有效地应用在无人机硬件设备中。根据在VisDrone2019数据集、DroneVehicle 数据集和RSOD 数据集上的实验结果,DSM-YOLO v5在无人机航拍图像目标检测任务之中,各项指标都优于目前主流的目标检测网络结构。虽然DSM-YOLO v5 算法在无人机航拍图像的目标检测任务当中表现较好,但仍需要进行改进,如网络层数较多,目标检测的精度和速度还有待提升,接下来将继续在网络结构、体积、参数量、检测速度等方面进行更深入的研究。
