多尺度可变形Transformer纸币序列号识别
2023-09-25张开生李旭洋
张开生,李旭洋
陕西科技大学电气与控制工程学院,西安710021
随着国内经济的迅速发展,近五年来我国国内现金流通量年均增速为5.9%,在各类交易流通中现金量仍然呈上升趋势[1]。根据艾媒数据(iiMedia Research)的一项关于我国居民外出使用现金交易情况的调查结果显示,截至2020 年我国四十岁以上人群中使用现金进行交易的人数占比达72.1%;五十岁以上人群中使用现金进行交易的人数占比高达93.6%。现金流通量和需求量的不断提升造成现金流通管理压力不断增大,为了确保国家发行的纸币得到良好的监督和管理,纸币的序列号承担着重要的角色:一是国库和银行需要通过纸币序列号进行数据统计。钞票由一些指定的印刷厂生产后,先要将其存储到国库中,随后发放到不同的银行或金融机构,以便在市场上正式发行流通。在国库接收印钞厂印制好的钞票前,工作人员需要统计各类型纸币的序列号范围,以便明确不同种类的纸币的总数以及纸币的总价值;二是当国库或银行发现一些已经销毁或者受损严重因而无法正常使用的纸币时,需要根据上述纸币的序列号通知印钞厂重新印制相同序列号的纸币[2]。三是公安机关及有关部门需要通过纸币序列号对走私、洗钱、金融诈骗等违法犯罪行为进行调查[3]。四是随着数字信息技术的不断进步和完善,为了完善货币的追踪溯源机制,纸币交易和数字货币交易将以纸币序列号为线索联系起来,将交易数据有机融合形成大数据,为货币溯源机制提供数据依据[4]。因此,开展纸币序列号识别技术的研究具有重要意义。
纸币序列号的识别任务主要是利用文字识别技术(optical character recognition,OCR)进行处理。该技术涉及文本检测和文本识别两个阶段:首先,通过光学技术和计算机技术对获取到的纸币图像中的序列号区域进行检测,然后识别出图像中的文字内容。自1980 年以来,研究人员已经针对该领域的各种问题开发出了许多识别系统。LeCun等人[5]首次将反向传播算法应用于手写体数字的识别过程中,提升了识别的泛化能力,识别准确率达到93%,而该方法在识别复杂背景文本时效果较差。Nakayama 等人[6]提出了一种基于神经网络的新模式识别方案,通过在标准图案中添加典型的手写字符,提升了复杂背景下文本识别的准确率。基于神经网络的方法[7-8]开启了文本识别的新阶段。卷积循环神经网络(convolutional recurrent neural network,CRNN)[9]集成了卷积神经网络(convolutional neural networks,CNN)和循环神经网络(recurrent neural network,RNN)来执行文本识别。然而上述识别方法由于神经网络结构在长距离依赖问题上的局限性,导致其仅能针对水平排列的规则文本进行识别。
实际上,在各种纸币流通的各类典型场景中,由于纸币的材质序列号区域经常受到污染、损坏或折叠,如图1 所示,导致该区域被部分遮挡或是变形,加之环境光线以及拍摄角度等问题,在识别过程中,纸币序列号区域呈现出边界框扭曲变形、字符大小不一致的不规则文本特点,极大地影响了OCR 识别技术的识别精度和识别效率。因此需要一种不规则文本识别方法,有效识别不规则排列的纸币序列号,减少人工的工作量,进一步提升原有纸币识别系统的识别效率和应用范围。

图1 受到污损或折叠的纸币示意图Fig.1 Illustration of defaced or folded banknotes
然而现行的不规则文本识别方法多数是在基于神经网络的规则文本识别方法基础上进行改良得到:TextBoxes[10]在卷积神经网络的基础上提出了一种场景文本检测器,通过使用旋转框和四边形并结合回归模型或损失函数实现任意方向的四边形文本检测,但对扭曲文本的检测效果不佳;EAST[11]则是直接预测图像中任意方向的四边形边框单词或文本行,省去了不必要的中间步骤,但受限制于网络结构,无法实现长文本识别;CRAFT[12]基于VGG-16全卷积网络体系结构设计,通过检测每个字符之间的亲和力来确定任意形状的文本区域,但检测过程中需要成本高昂的字符级注释和后处理步骤;Wang 等人[13]提出了一种具有自适应文本区域表示的场景文本检测方法,但仅限于RNNs 的顺序解码;近期提出的ABCNet[14]和ABCNet v2[15]方法通过参数化的贝塞尔曲线自适应地拟合定向或弯曲的文本边界框,虽然提高了检测性能与适用范围,但该方法无法适应由于纸币序列号区域严重扭曲变形后产生的边界框定位问题。为了提升不规则文本边框定位能力,TextDragon[16]围绕文本中心线生成多个局部四边形,并使用RoISlide操作来在文本实例内进行特征扭曲和聚合。尽管不需要字符级别的监督,但它仍然需要执行中心线检测,并进行相应的分组和排序,以将四边形转换为多变形文本边界;Qin 等人[17]提出了一种感兴趣区域屏蔽的方法通过将分割概率图与特征相乘以降低背景对文本识别的影响,但仍需要相应的后处理操作才能完成识别任务。
为了应对更加复杂的不规则文本识别需求,现行的不规则文本识别模型在加入了大量的感兴趣区域操作和后处理步骤后使得模型结构愈加复杂,同时应用于文本识别的神经网络结构在长距离依赖问题上的局限性也并未通过上述模型的提出而得到彻底的解决。另一方面,由于序列号本身的格式特点在经过扭曲变形后会产生大量尺度不一的文本信息,进一步限制了部分识别模型的识别精确度,因此文本识别模型需要精确度更高的多尺度文本特征信息提取能力。
针对上述问题,随着Transformer[18]在语言处理[19]和计算机视觉[20]领域得到越来越多的应用和实验,特别是SRN[21]和NRTR[22]在文本识别任务上的良好表现,进一步证明了Transformer 在文本识别任务上的应用前景。Transformer的结构可以在特征提取部分关注全局信息,通过替换额外的上下文建模模块有效解决神经网络存在的弊端,同时可以避免冗杂的感兴趣区域操作和后处理步骤,简化了模型的复杂程度。然而仅通过经典的Transformer结构设计不规则纸币序列号识别方法时,会出现由于其多头注意力机制在处理不规则纸币序列号文本特征图时提取多尺度特征的局限性,导致的模型收敛速度慢和特征空间分辨率有限的问题。基于此,针对目前不规则纸币序列号文本识别问题展开研究,采用线阵相机搭建纸币序列号检测识别系统,并提出一种结合多尺度可变形注意力和Transformer 模型(multi-scale deformable attention Transformer,MDATR)的纸币序列号识别方法,在统一框架中执行文本检测和识别,有效规避神经网络处理文本识别任务时的局限性和经典模型结构过于复杂的问题,改进经典Transformer 结构的注意力机制模块以提升方法的多尺度文本特征提取能力。对需要检测的纸币序列号进行高效的定位检测和识别。主要贡献如下:
(1)在编解码器的设计过程中,引入了多尺度可变形注意力模块。通过减少对骨干网络输出特征图的采样点个数,很大程度上降低了模型的计算成本,加快模型的计算速度。另一方面,多尺度可变形注意力模块能够充分利用多尺度特征图中的信息,从而获取到各类使用场景中丰富的纸币序列号文本信息。
(2)在不规则序列号文本的定位阶段,采用了一种多边形边界框检测机制,将编码器阶段输出的特征图信息经过候选框生成器标记出特征图中序列号文本的粗边界框,使用位置编码模块对粗边界框进行编码后,输入位置解码器训练不规则序列号边界框控制点坐标回归,进而引导边界框的检测,确定最终的序列号文本边界框。
(3)实验结果表明,对于纸币序列号文本图像,MDATR能够有效识别受折叠扭曲或污损遮挡的不规则序列号文本,同时与主流识别模型相比对规则序列号文本的识别表现良好,其在统一框架下检测与识别任务的处理方式能有效提升网络的推理速度。
1 系统结构
纸币序列号检测识别系统主要由4部分组成,图像采集单元、图像处理单元、运动控制单元和机械结构单元。系统总体结构如图2所示,纸币首先通过带有可调光源的摄像头,得到连续的模拟信号。图像采集卡将模拟信号转换为数字信号并将图像传输到计算机。通过MDATR 算法处理图像并对纸币的序列号进行检测识别。最后将结果输出到监视器,同时检测结果也将传输到目标参数输出接口,以供计算机使用。

图2 系统总体结构图Fig.2 Illustration of system overall structure
图像采集单元主要由CCD相机、可调节光源、图像采集卡等组成。CCD 相机为DALSA 公司的Spyder3 Color 系列双线CCD 线阵工业数字摄像机。该系列使用DALSA 独有的双线扫描传感器(dual-line sensor),通过双线彩色(biliner color)技术将线阵传感器上的一条线交替感应R、B 分量信息,另一条线感应G 分量信息,然后以插值的方法得到每个像素的RGB 分量信息。该系列相机采用Camera Link串行接口,传输距离可达100 m。光源对于产生合理“均匀”的、无反射的直射光线以供CCD 相机使用至关重要。因此,本系统选择FOSTEC灯,一种可调节的光源来满足这一要求。图像采集卡选用美国NI公司生产的PCI-1411图像采集卡。该卡有两路输入RS-170/NTCS和CCIR/PAL模式,可以输出同色、RGB、HSL格式的图像,支持单帧和序列帧。
图像处理单元主要由计算机组成。整套系统由计算机控制,通过可编程逻辑阵列(field programmable gate array,FPGA)[23]发送各种信息来控制电机与相机配合采集出纸币序列号区域的完整图像,将其输入检测算法并给出获得检测结果。
运动控制单元由两个电机以及FPGA组成,分别控制着轴承的进入与轴承的旋转,通过FPGA 给出触发信号,精准控制图像采集时间与触发频率。FPGA 采用Altera公司Cyclone 1V系列中的EP4CEl0资源,它具有10 320 个逻辑单元(LEs)、46 个M9K 存储器模块,每个模块都具有9 kb的嵌入式SDRAM存储器,并且可以根据需要配置成单端口、双端口RAM以及嵌入式FIFO存储器或者ROM;还具有8个PLL、10个全局时钟网络,可以满足不同模块的时钟频率。有23 个嵌入式18×18乘法器,可以实现DSP处理密集型应用。
机械结构单元包含外箱体、传送带、传动轮和传动轴,是检测系统实现图像采集的核心部件,决定该系统运行效率与检测精度。传送带、传动轮和传动轴构成传动机构,在电机的驱动下传送带和传动轮将动力传送给各个传动轴,使得传动机构稳定运转配合相机完成纸币序列号图像的采集工作。
2 纸币序列号识别算法研究
如图1所示,与一般图像不同,受到折叠、损坏或污损影响的纸币序列号区域会产生扭曲变形和遮挡的问题,导致采集到的该区域图像具有更复杂的表现形式,通常不会以水平的规则文本的形式出现。因此结合多尺度可变形注意力机制提出基于Transformer的MDATR方法,对多种情况下的纸币序列号文本进行检测识别,算法流程示意图如图3所示。首先,编码器在输入图像上执行多尺度可变形注意力机制,并且通过引导生成器从特征图中生成粗糙的边界框。这些边界框被编码并添加到可学习的控制点查询嵌入之上,以指导控制点的学习。控制点查询通过位置解码器和前馈网络(feedforward network,FFN)[24]进行馈送,以预测序列号边界框坐标。字符解码器以位置解码器的共享参考点作为多尺度交叉注意力机制的输入,为相应的序列号文本预测字符。

图3 MDATR算法流程示意图Fig.3 Schematic diagram of flow of MDATR algorithm
2.1 编码器结构设计
编码器的结构如图3所示,输入图像首先通过骨干网络减小通道维数,输出特征图。由于编码器的输入一般为序列形式,因此需要将得到的特征图的空间维度降低为一维,进而得到低纬特征图作为编码器的输入。编码器中的每一层都由一个多尺度可变形自注意力机制模块、一个前馈网络以及相应的层归一化组成。另外,由于Transformer 体系结构是空间不相关的,因此需要采用固定位置编码[25-26]对其进行补充,这些位置编码将被添加到每个注意力层的输入中。
现阶段文本识别任务中的一个首要问题是获取到的文本图像中普遍存在多尺度文本信息,这导致文本的检测识别系统需要准确、有效地处理多尺度文本信息,在纸币序列号的识别任务中也存在同样的问题。现阶段的相关文献中,大多数研究人员尝试通过利用多尺度特征图(multi-scale feature map)来克服这一障碍实现对小尺寸文本的准确识别。例如,在所提出的方法中采用特征金字塔网络(feature pyramid networks,FPN)[27]有效识别多尺度文本信息,然而却由于繁杂的中间处理过程增加了模型结构的复杂度。
在开发基于Transformer 的文本识别模型时同样利用多尺度特征图来应对这一问题,与先前的研究方法不同的是,常规的Transformer 结构中一般使用多头注意力机制处理特征图,多头注意力机制可被定义为式(1)所示:
其中,q∈Ωq为具有表示特征zq∈ℝC的查询元素,k∈Ωk为具有表示特征xk∈ℝC的键值元素,C为特征维数,Ωq和Ωk分别表示查询元素集合和键值元素集合;h表示注意力头,Wh和W′h为可学习权值,Ahqk为注意力权值。然而,常规的多头注意力机制在处理特征图的过程中,可能会查看特征图中所有可能的空间位置,导致大量查询和键值元素的产生,最终使得多头注意力机制的计算复杂度升高。
为了应对常规多头注意力机制处理特征图中存在的问题,研究人员引入了可变形注意力机制,无需关注特征图的所有空间位置,只需要关注参照点周围的一组关键采样点,可变形注意力机制可被定义为:
其中,k表示采样个数,K表示采样总个数,Δphqk和Ahqk分别表示第h个注意头中第k个采样点的采样偏移量和注意力权重。可变形注意力机制通过为每个查询只分配少量固定数量的键值,可以有效减轻收敛和特征空间分辨率的问题。
本文的研究中为了能够高效利用系统所采集图片中的多尺度特征信息,在编码器设计中采用可变形注意力机制并进行扩展,引入多尺度可变形注意力机制模块,其结构示意图如图4所示。
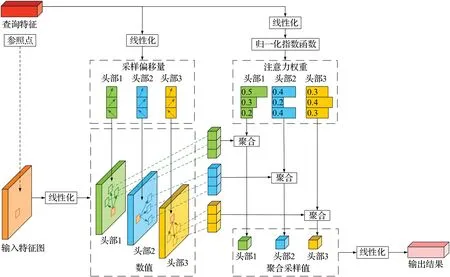
图4 多尺度可变形注意力机制示意图Fig.4 Illustration of multi-scale deformable attention
与一般的注意力机制不同点在于,该模块能够聚合多尺度特征,不需要对特征图中H×W个点进行采样,而是对检测目标参照点周围的L×K个点进行采样,这在很大程度上既降低了计算成本还能够充分利用特征图中的多尺度信息,加速模型收敛。具体地,给定一组L层的多尺度特征图,其中,为查询q的参考点归一化坐标,多尺度可变形注意力机制可表示为:
其中,h、l、k分别是注意力头、输入特征图层数和采样点的键值。Amlqk表示查询q的注意力权重,针对K个采样点进行归一化。ϕl表示将归一化坐标映射到第l层特征图的比例,ΔPhlqk表示为查询q生成适当的采样偏移量,将它们二者相加以形成特征图Fl的采样位置。Wh和W′h是可训练的类似于多头注意力机制中的权重矩阵。
2.2 解码器结构设计
纸币序列号识别任务中的文本边界框控制点坐标和相应的字符预测可统一看作集合预测问题。即给定一张图像G,系统需要输出一组文本边界框控制点坐标以及字符,定义为。其中g是每个文本的索引,表示文本的N个初始边界框控制点坐标,表示文本的M个字符。为了在同一框架中实现预测,在本文所提出的模型中同时利用两种适用于预测不同模态的解码器来解决这一问题,两个解码器分别是用于文本边界框位置检测的位置解码器和用于字符识别的字符解码器。
2.2.1 位置解码器
为了准确预测每个文本实例中的序列号边界框控制点坐标,扩展传统的Transformer 中的查询为复合查询。假设有Z个这样的复合查询,每个复合查询中的各个查询元素各自对应一个文本实例。其中的每个查询元素又由子查询组成,即:另一方面,为了能够应对可能出现的同时识别多个序列号的任务需求,通过结构化的方式获取到不同文本实例之间以及单个文本实例之间的不同子查询之间的关系,所设计的位置解码器中引入了分解自注意力机制[28],该机制示意图如图5 所示。分解自注意力机制首先在各查询元素内部子查询之间运行内部关联自注意力机制,然后在各查询元素之间运行相互关联自注意力机制。内部关联自注意力机制利用部分的上下文信息进行关系预测,例如,主题查询和对象查询分别是“人”和“车”有助于预测谓词“驾驶”。相互关联自注意力机制则是利用上下文信息,增强每个图像的整体关系预测,这对于针对同一文本实例的多个交互检测特别重要。

图5 因式分解自注意力机制示意图Fig.5 Illustration of factorized self-attention
初始控制点查询被反馈到位置解码器。经过多层解码,由预测置信度的分类头和输出每个控制点坐标的2通道回归头得到最终控制点查询预测结果。
这里预测的控制点可以是N个多边形顶点,也可以是贝塞尔曲线的控制点。对于多边形顶点,可以使用从左上角开始并按顺时针顺序移动的序列;对于贝塞尔控制点,可以使用伯恩斯坦多项式[29]构建参数曲线:
其中,伯恩斯坦多项式定义为:
对单个序列号文本可以使用两条三次贝塞尔曲线,对应于文本的两个可能弯曲的边,随后通过跨t采样将贝塞尔曲线转换回多边形。
2.2.2 多边形边框检测机制
纸币序列号识别任务的集合预测问题通过解码器部分进行数学建模,其贝叶斯推理过程为:P(Y|I)∝P(I|Y)P(Y),其中P(I|Y)通过交叉注意力机制获取到查询和输入之间的关系,P(Y)则通过自注意力机制模拟Y的先验配置。然而当Y很复杂,即文本呈现出不规则排列时,在复合查询的情况下P(Y)很难学习。因此,为了避免这一情况,在模型中引入一种多边形边框检测机制,通过检测并使用文本实例的粗边界框来指导系统进行文本多边形边界的检测。这个过程利用与具体序列号图像G相关的信息形成特定于输入的先验知识,有助于控制点坐标回归的训练。
多边形边框检测机制如图6 所示。由编码器输出的特征图作为输入传输到候选框生成器中,作为多边形边框检测机制的核心,候选框生成器针对特征图检测出可能是文本的内容,进而输出文本的粗边界框坐标及其概率,并筛选出概率最高的前Z个框,其坐标表示为随后由位置编码模块结合粗边界框坐标进行编码并将结果添加共享字符查询嵌入输入到位置解码器,最终得到序列号文本的边界框预测结果。

图6 多边形边框检测机制示意图Fig.6 Illustration of polygon detection process
基于此,初始控制点查询可进一步表示为:
其中,φ(α(g))作为粗边界框的位置编码结果,在单个序列号文本的N个子查询之间共享,对序列号文本的整体位置和规模进行建模;α(g)作为因式分解自注意力机制的初始参考点;(b1,b2,…,bn)是控制点查询嵌入,在Z个查询中共享,对与特定边界框位置无关的控制点之间的一般关系进行建模;在位置编码模块,候选粗边界框经过正弦位置编码φ(⋅),随后经过线性化和层归一化处理,结合共享控制点查询嵌入输入到位置解码器,最终得到精确的多边形边界框。
2.2.3 字符解码器
字符解码器的设计思路类似于位置解码器,其中位置解码器的控制点查询被字符查询取代。初始字符查询包括可学习的字符查询嵌入和一维正弦位置编码,并在不同的文本实例之间共享。具有相同索引的字符查询和控制点查询属于同一个文本,因此多尺度可变形注意力机制的参考点是共享的,以确保从图像中获得相同的上下文特征信息。分类头负责接收最终的字符查询并在多个字符类中进行预测。
3 实验与分析
为了进一步验证所提出的纸币序列号检测识别方法MDATR模型的有效性,通过所搭建的纸币序列号检测识别系统采集一定数量的人民币序列号图像,同时结合韩元和日元的纸币序列号图像数据组成本次实验的数据集。
3.1 实验数据
考虑到所设计的纸币序列号检测系统的可移植性以及实际应用中的场景复杂性,为更加全面地验证所提出的方法的性能,实验过程中所使用的人民币、韩元和日元纸币等9 组数据集中包括:扭曲变形、受到污染的纸币序列号区域图像,即不规则纸币序列号图像,相对平整的纸币序列号区域图像,即规则纸币序列号图像,以及应用场景中的纸币序列号区域图像。具体地,数据集A 至数据集D 为不规则排列或受污损的纸币序列号图像,数据集E至数据集H为规则排列的纸币序列号图像,数据集I为应用场景中的纸币序列号图像,该数据集图像包括但不仅限于实际应用场景中的纸币序列号文本呈现出的扭曲变形、旋转、文本模糊、阴影遮挡以及大小不一等特点。图7为每组数据集中典型图像的示意图。

图7 纸币序列号图像数据集示意图Fig.7 Illustration of image dataset of banknote serial numbers
在前四组数据集中:数据集A 包含面值为1 000 日元和5 000日元的纸币,数据集B包含面值为2 000日元和10 000 日元的纸币。数据集C 包含面值为1 元、5 元人民币的纸币,数据集D 包含面值为50 元人民币的纸币;在后四组数据集中:数据集E包含面值为1 000日元的纸币,数据集F包含面值为2 000日元的纸币,数据集G包含面值为10 000韩元的纸币,数据集H包含面值为1 元和5 元人民币的纸币。数据集I 包含面值为1 元、5元和50元人民币的纸币。其中,数据集A中有6 860个训练数据和1 000个测试数据;数据集B中有5 670个训练数据和1 780个测试数据;数据集C中有5 100个训练数据和1 900个测试数据;数据集D中有4 900个训练数据和1 890 个测试数据。数据集E 中有5 600 个训练数据和1 010个测试数据;数据集F中有5 500个训练数据和1 880个测试数据;数据集G中有5 020个训练数据和1 910 个测试数据;数据集H 中有5 200 个训练数据和1 620 个测试数据;数据集I 中有2 009 个训练数据和1 000个测试数据。
3.2 评价指标
为了评价MDATR对纸币序列号的识别性能,本文采用了几个主流的评价基准来评估所提出识别方法中模型的性能,主要包含:精确率(Precision)、召回率(Recall)和F值(F-Measure)。这些评价指标定义如下:
其中,TP(true positive)表示预测正确的正类的数目,TN(true negative)是分割正确负类数目,FP(false positive)是指预测错误的正类数目,FN(false negative)表示预测错误的负类数目。
精确率(Precision)是指模型正确预测为正的占全部预测为正的比例。召回率(Recall)是识别正确的正例占总的正例的比重。F 值(F-Measure)是为了避免精确率(Precision)和召回率(Recall)出现相矛盾的情况而设计的综合评价指标,即精确率(Precision)和召回率(Recall)的加权调和平均值。以上三个指标的数值越大代表预测效果越好。运算的速率方面采用了每秒的传输帧节数(frames per second,FPS)作为衡量指标。
3.3 损失函数
二分匹配。由于模型输出固定数量的预测结果,并且与文本实例的实际数量G不符,因此需要得到二者之间的最佳匹配来计算损失。具体地,需要得到函数σ使得匹配成本Cm最小,即:
其中,Y(g)是真值(ground truth),Y(σ(g))是匹配的预测结果。为了进一步提升处理效率,使用控制点坐标来指导字符解码的学习。因此,匹配成本被定义为置信度和坐标偏差之和。对于第g个文本实例及其匹配的第σ(g)个查询,其匹配成本函数定义为:
式(11)中的第二项是真值(ground truth)坐标和预测控制点坐标之间的L-1 距离。
式(10)中使匹配成本最小的问题可以利用匈牙利算法[31]有效地解决。使用相同的二分匹配的方法将候选框生成器中的候选框与作为控制点边界框的真值(ground truth)进行匹配。
文本实例分类损失。采用焦点损失函数作为文本实例的分类损失。对于第g个查询,损失函数定义为:
其中,Im( )
σ是映射函数σ的图像。
控制点损失。L-1 距离损失用于控制点坐标回归:
字符分类损失。将字符识别视为一个分类问题,其中每个类都分配了一个特定的字符。本文中使用交叉熵损失函数:
解码器的损失函数包括上述三个损失:
边界框中间监督损失。为了使多边形边界框检测机制中的候选框预测更准确,在编码器中引入了中间监督。采用前文中的二分匹配将预测出的候选框与文本框真值(ground truth)进行匹配,其映射函数表示为σ′,整体损失表示为:
3.4 实验细节
系统的硬件处理器为Intel Core i9 9900X @3.5 GHz;内存为128 GB;显卡为NVIDIA Geforce RTX 2080Ti 11 GB,操作系统为Windows 11 22H2。采用Python3.6编程语言以及深度学习开发框架Pytorch环境进行程序的编写。在实验过程中选用ResNet-50[33]作为骨干网络。多尺度可变形Transformer 的参数设置:可变形注意力机制中H=8,采样点K=4,编解码器层数N=6。
MDATR在SynthText 150k、MLT 2017[34]和Total-Text[35]的混合数据集上进行了共计300 000 次迭代的预训练。多边形变体的基本学习率为1×10-4,并在第240 000次迭代时衰减0.1倍。对于用于预测参考点坐标的线性投影、多尺度可变形注意力机制和骨干网络的采样偏移,学习率按0.1 倍缩放。本文采用改进的自适应梯度法AdamW[36]作为模型优化器,其中β1=0.99,β2=0.999,权重衰减为10-4,复合查询个数Q=10。最大文本长度M=15,多边形控制点数N=50。损失函数的权重因子为λcl=2、λco=5、λch=4、λg=2。设置焦点损失函数中ε=0.25、γ=2.0。
3.5 实验结果与分析
3.5.1 不规则纸币序列号识别
在四组不规则或受污损纸币序列号数据集(数据集A 到数据集D)上进行测试,使用四个数据集和六种检测识别模型进行性能评估和对比,实验中选用的测试模型包括:ABCNet v2、TextNet[37]、CharNet[38]、Mask TextSpotter[39]以及PGNet[40]等模型。在实验过程中每个模型均进行了多测试,并将测试结果平均值作为测试准确度进行汇总。实验结果如表1所示,所提出的MDATR模型在数据集A 和数据集D 上的测试准确率分别为93.4%和92.2%,优于其他方法;在数据集B上的测试准确率与ABCNet v2模型的测试准确率相同为89.2%;在数据集C上的预测结果MDATR模型的准确率为91.2%,但相较于同一数据集下预测准确率最优的ABCNet v2模型仅降低了0.3%。
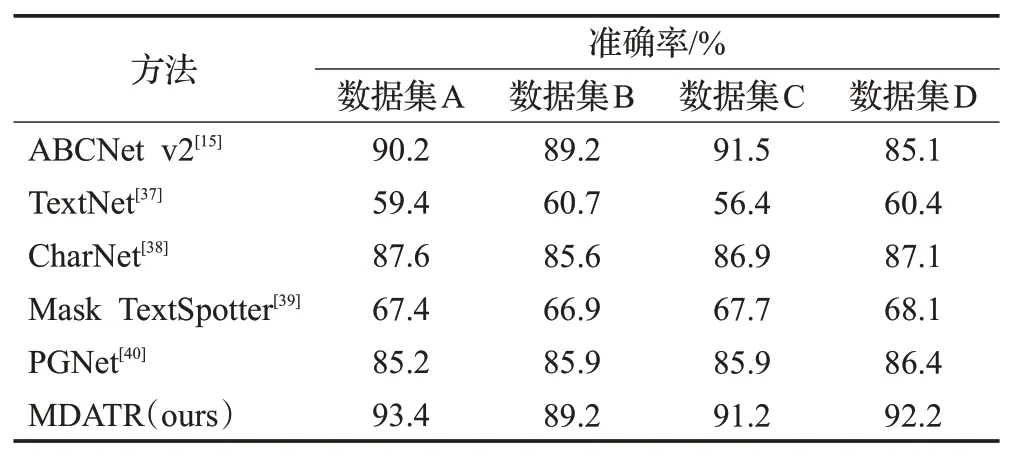
表1 不同模型的不规则纸币序列号识别结果Table 1 Recognition results of different models on irregular banknote serial numbers
TextNet的检测识别过程是通过生成四边形文本区域,然后进行感兴趣区域转换,进而完成文本识别任务。尽管此方法可以识别不规则文本,但对于任意形状的文本区域,其四边形文本区域检测效果并不佳;CharNet是在一次检测任务中同时执行字符和文本检测,但需要字符级注释;Mask TextSpotter模型是基于Mask RCNN[41]构建的,该模型针对目标图像执行文本和字符级别的分割,需要在获得最终结果之前进行进一步分组;ABCNet v2为弯曲文本引入贝塞尔曲线,并开发了用于特征提取的贝塞尔-对齐方法。但是低阶贝塞尔曲线在检测相对严重弯曲或波浪形的文本边框时存在局限性;PGNet是将多边形文本边界转换为中心线,边界偏移和方向偏移,并针对这些目标执行多任务学习。但在消除感兴趣区域操作时,仍需要使用专门设计的多边形恢复过程。
相较于上述模型,MDATR 模型使用了位置解码器和字符解码器的双解码器结构可同时进行文本框的定位和字符的识别,多尺度可变形注意力机制能更有效地提取图像中文本的多尺度特征信息,多边形边界框检测机制能够准确地检测出变形的文本边界,模型的检测精度更高。另一方面,由于文本边界框控制点坐标的直接回归,对纸币序列号的检测识别过程中不需要类似PGNet 模型和ABCNet v2 模型中采用的后处理步骤和感兴趣区域的相关操作,提高计算效率。图8为MDATR在不规则纸币序列号数据集上的可视化检测结果。

图8 不规则或受污损纸币序列号检测结果示意图Fig.8 Sketch of irregular text or defaced banknote serial number detection results
表2是在数据集A和数据集D上的详细实验结果。在纸币序列号区域相对模糊且存在污渍遮挡的数据集A 上,MDATR 模型的测试结果中F 值指标为87.2%,相比于之前准确率最高的ABCNet v2 模型高出0.3%;在检测的精确率上MDATR 相较ABCNet v2 模型高出3.7%,达到93.4%。在纸币序列号文本边界框相对更加扭曲变形的数据集D上,MDATR模型的优势更加突出,F值相较于ABCNet v2模型提升了2.4%达到86.7%,而在精确率指标上提升更为明显,相较于精确率最高的CharNet模型提升了6.1%。
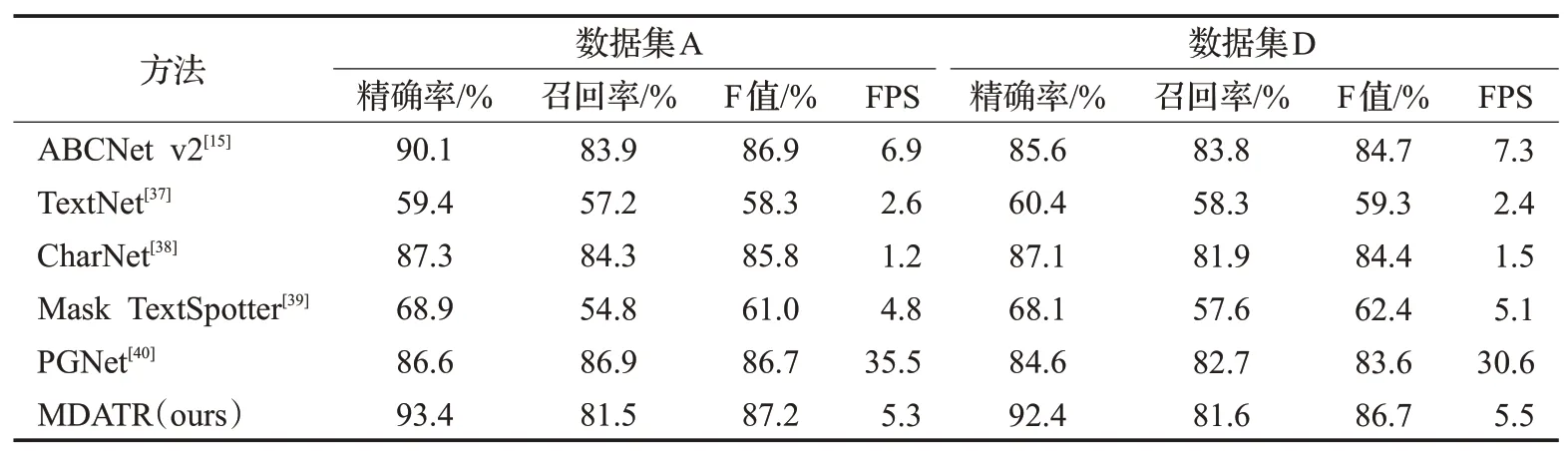
表2 在数据集A和数据集D上的实验结果Table 2 Experimental results on dataset A and dataset D
3.5.2 规则纸币序列号识别
在规则纸币序列号数据集(数据集E 至数据集H)共四个数据集上,使用包含本文提出模型在内的八种文本识别模型进行横向的检测识别性能评估和对比实验。实验过程中所选用的测试模型包括:ABCNet v2、TextNet、CharNet、Mask TextSpotter、TEAA[42]、Textboxes[43]、Text Percrptron[44]以及MDATR 模型。在该实验过程中每个模型均进行了多次测试,实验结果其平均值。实验结果如表3 所示,图9 为MDATR 模型在规则纸币序列号数据集上的可视化检测结果。
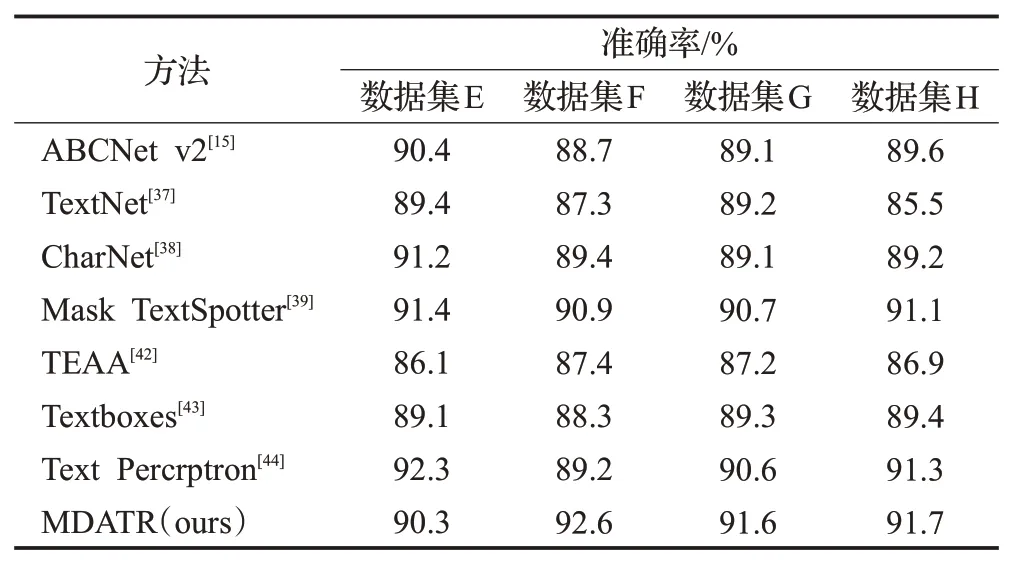
表3 不同模型的规则纸币序列号识别结果Table 3 Recognition results of different models on regular banknote serial numbers
由表3 可知,在数据集F、数据集G 和数据集H 上,MDATR模型的测试准确率分别为92.6%、91.6%和91.7%,与其他测试模型对比实验效果最优。TEAA 模型提出了新的文本对齐层以改进传统的感兴趣区域操作,但对于模糊文本和背景较为复杂的文本信息识别效果较差,因此在对比实验中的识别准确率最低;Textboxes 模型基于VGG-16网络对序列号文本进行快速定位,随后采用RCNN识别文本框中的文字内容,应对大字符间距文本和多角度文本时检测效果较差;Mask TextSpotter 模型采用区域候选网络(region proposal network,RPN)进行文本的检测和识别,但由于RPN的结构限制,模型不能处理方向密集或纵横比过大的文本;Text Percrptron模型采用一种基于分割的文本检测器和形状变换模块对文本区域进行检测,使得模型的开发需要大量的中间环节。与上述模型不同的是,MDATR模型基于Transformer模型开发,不依赖于感兴趣区域操作因此省去了大量中间开发环节,同时可变形注意力机制能够克服文本模糊和复杂背景问题。本组实验中在数据集E上MDATR模型的识别准确率相较于Text Percrptron模型降低了2.2%,然而在其余数据集的测试过程中,MDATR 模型的识别准确率分别提升了3.8%、1.1%和0.4%,体现了本文提出模型的优越性。
3.5.3 一般纸币序列号识别
为验证所提出模型应对复杂场景下纸币序列号识别任务时的有效性,在一般纸币序列号数据集上,使用包含本文提出模型在内的六种文本识别模型进行横向的检测识别性能评估及对比实验。选用的测试模型包括:ABCNet v2、TUTS[17]、TextNet、Mask TextSpotter v3[45]、MSR[46]和SPRN[47]和模型。实验过程中每个模型均开展了多次实验,最终结果取均值,实验结果如表4所示。

表4 不同模型的一般纸币序列号识别结果Table 4 Recognition results of different models on general banknote serial numbers
由表4可知,本次实验中MDATR模型的识别精确率为93.7%,F值为87.6%,实验效果最优。Mask TextSpotter模型受限于候选区域网络限制,不能有效识别多尺度特征信息,因此识别精度不佳,Mask TextSpotter v3 模型则是改进了区域候选网络,结合硬感兴趣区域掩码操作克服了处理极高宽比或不规则形状文本时的局限性,使得识别精确率达到90.6%;MSR模型利用多尺度形状回归网络,提取并融合不同尺度的特征,对文本尺度变化具有很好的容忍度,识别精确率达到84.2%;SPRN模型利用区域定位网络快速定位文本并估计文本尺度,随后通过文本检测器和后处理过程实现多尺度文本检测,但模型设计复杂处理时间较长;TUTS 模型则是利用改进的感兴趣区域操作来提取不规则文本区域中有用的多尺度特征信息,识别准确率达到87.6%,但感兴趣区域操作也使得模型的计算复杂度依然较高。
MDATR 模型利用多尺度可变形注意力机制,通过减少采样点个数降低模型计算量,同时提取并融合图像的多尺度特征信息。与TUTS 模型相比,MDATR 模型的识别精确率提升了6.9%,F值提升了1.7%。
图10为不同模型在一般纸币序列号图像数据集上的实验结果示意图。由图10可知,Mask TextSpotter v3模型相对于Mask TextSpotter模型利用分段建议网络提升了对不规则文本的识别精度,然而其在应对旋转角度较大的文本和小尺寸文本识别时,检测精确度较差;MSR模型使用了多尺度回归网络,用于融合多尺度特征信息,相比Mask TextSpotter v3模型能够有效避免旋转角度影响,但其针对于严重变形的多尺度文本或模糊的小尺寸文本识别准确率较差。TUTS模型为了更好地处理多尺度文本特征,引入了感兴趣区域掩码操作提取有用的多尺度特征信息,但增加了模型复杂度的同时在识别有阴影遮挡或是模糊文本时识别效果较差。

图10 一般纸币序列号检测结果示意图Fig.10 Diagram of banknote serial number detection results under complex scenario
与上述方法相比,提出的MDATR模型利用可变形注意力模块精确提取小尺寸检测目标,融合多尺度特征信息,并实现了更优的特征编码以及特征融合。另外由于仅在参考点周围取一定数量的采样点,降低了采样点个数,与常规注意力机制相比有效降低了模型复杂度,提升了计算效率;同时MDATR模型还将多尺度特征信息在双解码器中共享,结合多边形边框检测模块准确预测多边形文本控制点位置以及相应的字符坐标。在纸币序列号呈现出扭曲变形、文本模糊、阴影遮挡以及大小不一等特点时,MDATR 模型仍能够相对准确地识别出纸币序列号文本信息,在应对多尺度文本和小尺寸文本识别任务时,其优势尤为明显。
3.5.4 消融实验
本文提出的MDATR 模型主要是针对纸币序列号图像数据集的特点进行文本识别。为了进一步验证MDATR 模型中各个模块的有效性和优越性,在一般纸币序列号图像数据集上开展了消融实验。其中,选取的对比模型包括:Textboxes、Mask TextSpotter v3和CPN[48]。消融实验结果如表5所示,图11为消融实验结果示意图。

表5 消融实验结果Table 5 Detection results of ablation experiments

图11 消融实验结果示意图Fig.11 Diagram of ablation experiment results
多尺度可变形注意力模块有效性验证。为验证该模块的有效性,使用ResNet 最后阶段的特征图进行实验。如表5 所示,CPN 模型利用CNN 网络提取多尺度文本的空间特征,同时在模型主干中加入了可变形卷积,用以增强对于变形和长文本信息的适应性,其识别精确率、召回率和F值分别达到89.8%、82.7%和86.1%。相比之下,结合图11可知,多尺度可变形注意力模块能够有效提取多尺度文本特征信息,针对目标文本周围进行采样以充分利用文本多尺度信息,对于严重扭曲变形的纸币序列号文本识别效果良好,相较于常规的可变形卷积该模块的变形准确性较高,检测的精确度、召回率和F 值分别达到92.5%、79.1%和85.1%。在MDATR 模型中,多尺度可变形注意力模块将进一步提升模型对纸币序列号文本的识别效果。其中,文本识别精确率、召回率和F 值分别提高2.0%、4.6%和2.6%。由此可以进一步证明,多尺度可变形注意力模块能够有效应对纸币序列号文本图像识别中的扭曲文本信息,进而提升模型的识别准确率。
另一方面,为验证采样点个数对于多尺度可变形注意力模块识别准确率的影响,本小节针对这一问题进行了实验,实验结果如表6所示。当没有应用多尺度注意力时,采样点数量K=1 时,多尺度可变形注意力模块的作用类似于可变形卷积,此时的识别精确率、召回率和F 值较低,仅能达到83.6%、81.2%和82.4%;使用多尺度输入代替单尺度输入,结合多尺度可变形注意力,可以将识别精确率提升4.7%。
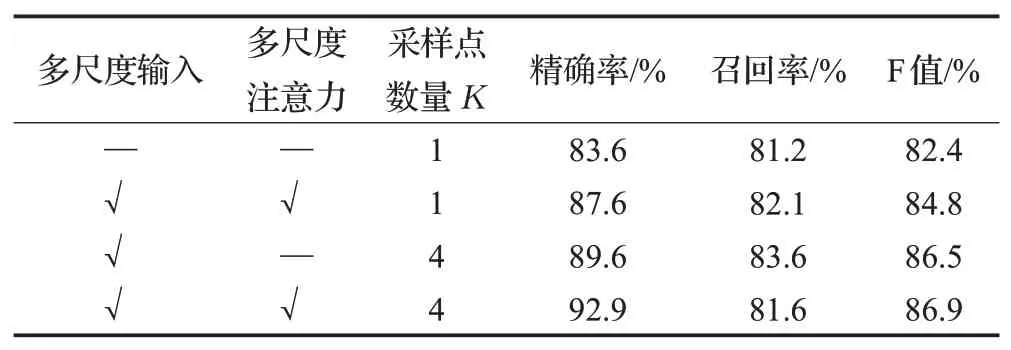
表6 不同采样点个数下的实验结果Table 6 Experimental results with different number of sampling points
当采样点数量增加至K=4 时,可以进一步提高识别精确率至89.6%;此时引入多尺度可变形注意力,允许多尺度特征之间的跨特征信息交换,可以将识别精确率、召回率和F 值分别提高至92.9%、81.6%和86.9%。由此可以证明,采样点个数会对多尺度可变形注意力模块的识别准确性产生一定的影响,当采样点个数K=4时,模型的实验效果相对较好。
多边形边界框检测机制有效性验证。为证明该机制的有效性,将式(6)中的粗边界框位置编码结果替换为可学习嵌入向量进行消融实验,以验证该机制对于序列号文本的识别准确性是否存在影响,同时引入对比模型进一步验证该机制的优越性。
由表5 可知,Textboxes 模型通过VGG-16 网络和RCNN实现对多边形文本的定位和识别,但其在处理多方向文本或阴影遮挡的文本时,检测效果较差,因此在实验过程中识别精确率最低,仅达到62.1%。Mask TextSpotter v3模型利用分段建议网络检测弯曲文本的文本,结合感兴趣区域操作克服阴影遮挡的问题,将识别精确率、召回率和F 值分被提升至89.6%、78.8%和83.9%,然而分段建议网络无法有效实现对于多尺度文本或多角度文本的检测。
与上述模型不同的是,在MDATR模型中多边形边界框检测机制主要是将编码器得到的特征图输入到候选框生成器中,检测出可能是文本的内容,进而输出文本的粗边界框坐标及概率,并筛选出概率最高的Z个粗边界框,由正弦编码φ(⋅)结合粗边界框坐标进行编码,并将编码结果添加共享控制点查询嵌入输入到位置解码器。同时融合编码器提取的多尺度特征信息,以获取多尺度文本和小尺寸文本的边界框控制点坐标,进而确定最终序列号文本的边界框,以提升对多边形文本边界框的定位准确率。采用多边形边框检测机制后序列号的识别精确率至91.6%。
另一方面,在MDATR模型中结合多尺度可变性注意力模块,多边形边界框检测机制可以将序列号文本识别的准确率、召回率和F值分别提升0.9%、2.9%和2.1%,分别达到93.4%、81.4%和86.9%,进一步证明多边形边框检测机制能够提升模型应对多尺度序列号文本的识别准确率。图11的可视化结果表明,Mask TextSpotter v3模型在应对模糊文本和小尺寸文本时识别效果不佳;而在MDATR模型中引入了多边形边框检测机制后,模型针对于一般场景下的不规则纸币序列号文本框的定位更加精准,这进一步证明,多边形边界框检测机制能够准确的定位出纸币序列号文本的边界框,帮助模型提升在实际场景中纸币序列号图像的识别准确性。
4 结束语
针对纸币序列号由于污染、破损或折叠等情况而影响序列号检测和识别的问题,设计一种纸币序列号检测识别系统,实现快速、准确、全面的纸币序列号检测和识别。该系统的主要特点在于:不同于现有的大多是纸币序列号识别算法是基于字符分割实现的,该方法结合多尺度可变形注意力机制在Transformer的基础上由一个编码器和两个解码器构成的新框架,以并行处理的方式实现纸币序列号的检测识别,提升运算速率;针对纸币序列号区域扭曲变形的问题,采用一种多边形边界框检测机制,实现由边界框引导的多边形检测,保证扭曲的纸币序列号检测精度;针对纸币序列号可能存在的字符大小不一的问题,采用多尺度可变形注意力模块,降低模型结构复杂度。
实验结果表明,在面对不规则文本同时受到污染的纸币序列号检测识别任务时,MDATR 模型检测精度达到93.4%;在应对复杂场景下的纸币序列号文本识别任务时,MDATR模型相较于主流识别模型,将识别精确度提升了6.9%。与目前主流的文本检测识别模型相比,该方法对纸币序列号的检测更准确高效,尤其是对于多尺度纸币序列号文本而言识别效果良好。本文为纸币的检测和识别技术探索提出了一个可靠的研究思路与方案,具有良好的应用前景。
