Web溯源蜜罐对抗防御技术研究
2023-09-23丁锐
丁锐
(昆仑数智科技有限责任公司 北京 100026)
Web 网络是基于超文本和HTTP 协议的全球性、动态交互的跨平台分布式图像信息系统。为方便业务迭代和部署,各类企业和国家机关部门平台持续推进信息化建设,搭建了大量Web 服务网站。基于网络的攻击也成为最有效的攻击手段。然而,随着信息技术的快速发展,网络威胁种类不断增加,网络攻击的复杂度也随之提升。现如今,如Web防火墙、入侵检测技术等传统的网络安全防护手段已经无法有效阻挡攻击者,由于占据主动优势的攻击者总会通过多种技术手段来绕过上述防护措施,进而攻陷需要重点保护的Web网络系统。
欺骗诱捕技术是网络攻防对抗中较为特殊的技术,通过欺骗攻击者访问虚假目标,在消耗其精力的同时,获取大量的攻击证据信息及网络流数据,极大地加强了防守方在网络攻防对抗中的主动权。随着网络攻击对抗升级,传统的单向边界防御技术愈发不能满足企业应对高级未知威胁的需求,蜜罐技术的出现及成熟改变了这一被动防御的局面。蜜罐(Honeypot Technology)是一种通过工具诱骗攻击者,使安全人员能够观察攻击者行为的主动网络防御技术[1],其应对的不是攻击或漏洞,而是关注攻击者本身。该项技术通过欺骗诱捕打乱攻击节奏,增加攻击复杂度,给企业增加更多响应时间,并有可能对攻击者进行分析溯源从而预防攻击。溯源蜜罐的出现使防守方可以通过技术仿真诱导攻击者进入事先准备好的模拟环境,实时监控并收集攻击者的IP和身份信息,从而快速反制攻击者。一个优秀的蜜罐,具备以下功能和技术特点:(1)能够模拟大多数常见协议;(2)能够模拟影响面广泛的应用协议和漏洞;(3)能够在TCP/UDP全端口捕获未知的恶意扫描;(4)蜜罐便于协议扩展;(5)蜜罐结果的数据格式简单便于分析。然而,攻防的对抗性驱使攻击者开发了一系列“反蜜罐”技术用于检测当前Web 环境是否属于溯源蜜罐,进而实施攻击逃逸等行为。
为提高Web站点的网络安全建设水平,针对WEB溯源蜜罐技术存在的安全问题,本文研究了Web 环境中溯源蜜罐的研究现状,分析了其技术的类型和特点,并给出了基于攻防对抗思想的Web溯源蜜罐安全防御体系构建思路。
1 Web溯源蜜罐研究现状
Web 蜜罐系统通过在网络中部署大量感应节点,实时感知目标周边的网络环境,同时将感应节点日志实时存储和可视化分析,实现对网络环境中的威胁情况快速感知。蜜罐从概念到落地从 1998 年开始。该技术发展初期主要是通过虚拟的操作系统和网络服务,对入侵者实施欺骗。21 世纪初期,蜜罐技术根据针对攻击的回应方式可以分为回应式和黑洞式,前者对攻击者的所有探测和攻击行为都予以满足和应答,后者则是完全不予应答。2020年至今,由于企业网络逐渐呈现架构高复杂化、安全报警信息海量化的特点,给欺骗防御技术即蜜罐技术在模拟对象类型、仿真精细度、自动化程度等方面提出了更高的要求。厂商和安全研究人员不断对蜜罐技术进行优化,从而逐渐形成新型蜜罐、蜜网、分布式蜜罐、分布式蜜网和蜜场等多种落地形态。
1.1 溯源蜜罐概念与研究进展
溯源蜜罐通过Web 跟踪技术和基于前端的信息探测技术实现对攻击者的追踪溯源和反制。Web跟踪技术是一种通过采集访问者浏览器或设备的指纹,并植入持久化跟踪Cookies 来持久跟踪访客的技术。通过此类技术可以对在不同时间段采用不同IP 地址的相同攻击者持续跟踪,形成完整的画像。
研究进展方面,ACAR G等人提出了一种通过Canvas画布为每个不同的浏览器生成不同CRC32指纹的蜜罐技术[2]。ENGLEHARDT S等人在调研了100万个网站后,发现大量站点使用AudioContext API获取不同设备在音频信号处理时的差异,进而得到可供跟踪的音频指纹[3]。同时,杨德全等人利用WebGL 和底层硬件特性实现了对使用不同浏览器的相同硬件设备的追踪[4]。刘德莉提出了利用浏览器的favicon图标缓存绕过现代浏览器的隐身模式保护追踪用户。溯源蜜罐可利用上述技术对单个攻击者持久追踪,实现精准的信息搜集,为蜜罐决策提供准确的数据[5]。基于前端的信息探测技术可以通过在前端执行Javascript 主动探测访客的信息,通过WebRTC探测启用了代理的浏览器的真实IP地址以及内网地址的方法,结合WebRTC获取的内网IP地址,可以通过端口扫描的手段探测内网信息,而在获取内网信息后可以通过CSRF 反向攻击攻击者内网中的脆弱设备[6]。除此之外,为了更深层次地溯源,防御者可以结合社会工程学,投放“蜜标”文件,诱导攻击者在自己的个人设备上打开,从而反向控制攻击者的设备[7]。溯源蜜罐可利用上述技术探测攻击者的信息甚至反控攻击者的设备。
为对抗蜜罐的主动探测,攻击者会部署反蜜罐措施来检测并阻止蜜罐的主动探测,而当前主流的防护措施都基于Web插件实现。Web插件是可被装载到浏览器中执行的Javascript 程序,该程序具有比一般网页脚本更高的权限,能监听并修改任意网页的DOM和网络请求,攻击者可通过编写定制的蜜罐防护插件同溯源蜜罐进行对抗。主流的蜜罐防护插件包含了蜜罐指纹静态扫描功能以及可疑动作动态拦截功能。其中,静态扫描功能通过扫描网页DOM 和JS 脚本内容并与已有指纹库对比,实现对已知蜜罐的检测;可疑动作动态拦截功能通过Javascript 函数劫持和网络请求事件监听实现对可疑动作行为的拦截。
1.2 溯源蜜罐的主要部署形态
随着安全对抗技术的不断发展,蜜罐工具软件及其核心功能实现机制都在不断发生变化。业务上云和数据规模的爆炸式增加,导致溯源蜜罐产业面临着一个新型问题:在分布式系统或大规模云环境中,如何有效部署不同类型、不同形态的溯源蜜罐,从而扩大攻击威胁的监测范围与能力。在这种背景下,蜜网和蜜场等概念被学者提出。下面详细介绍两种大规模溯源蜜罐的技术特点与主要架构形态。
蜜网技术是指使用大型网络将多个溯源蜜罐嵌套连接在一起,融合真实业务网站与模拟组网场景,组建而成的大型诱捕网络,攻击者难以分辨其网络架构与真实业务系统的区别,因此,就能够随机选择一部分主机收集攻击者行为,另一部分则可实时更新安全策略,达到提高网络策略交互的目的。一般来说,蜜网系统的关键技术需要满足大型网络主动控制、威胁漏洞捕获和攻击行为分析三大核心需求,其主要架构形态如图1所示。蜜网系统可通过网络主动控制技术首先确保融合网络里真实业务主机不受侵害;其次,利用威胁漏洞捕获技术检测黑客破坏过程的全部行为数据;最后,基于攻击行为分析全面分析蜜网捕获的多维数据,从而帮助系统安全人员分析黑客的具体攻击路径和技术利用细节。

图1 蜜网集群体系架构示意图
蜜场技术是基于物理设备管理运维和网络攻击重定向诱骗效果增强综合考虑的一种分布式代理扩展的蜜罐系统。蜜场的应用极大降低了溯源蜜罐系统实现成本和运维的难度,同时较好地兼顾了通信流量的时效性,也增强了蜜罐代理网络的功能。
如图2 所示,蜜场体系架构主要包括真实生产服务器,业务网络中的重定向器,安全专家维护的溯源蜜罐系统。具体来说,安全专家将全部溯源蜜罐集中部署到一个受控的伪装网络环境,同时对其进行数据维护、管理和分析。在真实业务系统网络中,仅仅部署一些体量较轻的重定向服务器,主动把一些未经授权和验证的网络流量与会话重定向到集中的蜜场环境里,同时,由溯源蜜罐和攻击源进行实时交互,达到更加主动、深入地分析分布式网络安全威胁的目的。
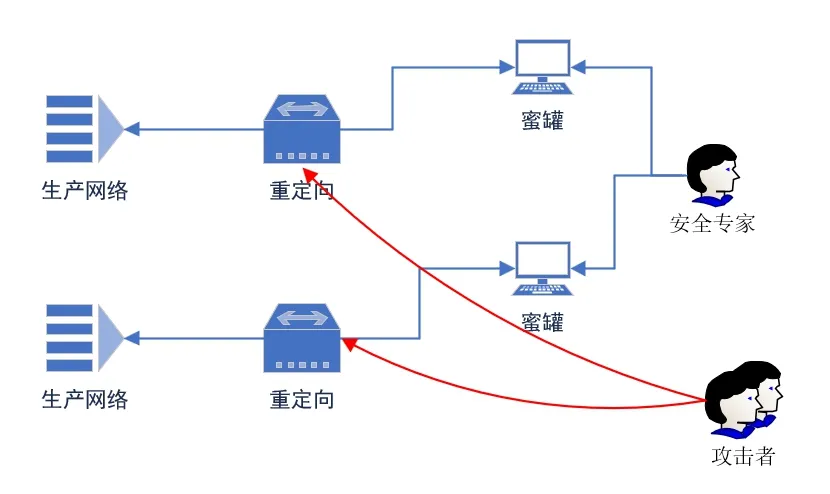
图2 蜜场体系架构示意图
1.3 溯源蜜罐的对抗识别技术
针对低交互蜜罐的识别技术已较为成熟,攻击者通过尝试构造一些较为复杂但不常见的操作即可快速识别当前环境是否为低交互溯源蜜罐。而中、高交互的溯源蜜罐识别,攻击者需要在短时间内融合多种技术才能做出有效分析,中、高交互溯源蜜罐的主要对抗识别技术如下。
1.3.1 根据协议返回特征识别蜜罐
开源蜜罐在模拟各个协议时,会在响应中带有一些明显的特征,可以根据这些特征来检测蜜罐。以Memcached 协议为例,在实现Memcached 协议时Dionaea 把很多参数做了随机化,但是一些参数如version、libevent和rusage_user等都是固定的。因此,可以通过组合查询其固定参数来确定当前环境是否为溯源蜜罐。
1.3.2 根据协议实现的代码缺陷识别蜜罐
部分开源的蜜罐中模拟实现部分协议并不完善,因此,可以通过发送一些特定的请求包获得的响应来判断是否为蜜罐。
1.3.3 根据Web特征识别蜜罐
部分开源蜜罐提供了Web 服务,这些Web 服务中常常会带有一些明显的特征,可以根据这些特征来检测蜜罐,如特定的js 文件、build_hash 或者版本号等。以HFish 为例,HFish 在默认8080 端口实现了一个Word-Press登录页面,页面中由一个名为x.js的JavaScript文件用来记录尝试爆破的登录名密码,通过判断WordPress登录页是否存在x.js文件就可直接判断是否为蜜罐。
1.3.4 根据命令信息上下文特征识别蜜罐
部分开源蜜罐存在命令执行上下文明显的特征,通过构造特定命令,分析其返回的上下文信息来检测蜜罐。
1.3.5 根据模糊测试技术识别蜜罐
模糊测试通过构造随机的数据输入测试系统查看系统响应或者状态,以此发现潜在的安全漏洞。这里可以通过预定义关键字实现对扫描器的干扰。从而对蜜罐特征进行判断。
2 Web溯源蜜罐防御体系构建思路
在后疫情时代,基于Web 服务的移动办公和远程接入等应用场景已成为新的常态模式,针对Web 网络的攻击行为也愈发猖獗[8]。然而,传统基于边界的网络安全防护体系已难以解决新场景下的安全攻击威胁,攻击者也提出了大量反蜜罐的检测技术用于实时发现和逃逸蜜罐环境。为有效应对反蜜罐技术,安全研究人员还提出了“反-反蜜罐”技术用于迷惑攻击者。
2.1 部署反静态扫描模块
攻击者利用静态扫描技术将已知蜜罐的代码片段搜集至指纹库,通过前端代码匹配实现对已知蜜罐的检测。因此,在构建Web溯源蜜罐防御体系时,应当使用随机算法融合生成具有多种特征的前端代码,用于混淆指纹库匹配,进而破坏攻击者的反蜜罐检测过程。此外,也可利用前端代码动态加载技术躲避攻击者针对DOM内容的静态扫描。
2.2 部署蜜罐防护插件识别模块
逃逸动态拦截无法使用通用的代码混淆实现,需要通过Web 插件指纹识别技术来检测反蜜罐Web 插件是否存在,以此变更探测策略针对性完成有效的检测逃逸。具体而言,可通过在Web 界面的资源文件设置特定的访问路径,前端代码可根据路径的生成方式构造资源路径,尝试访问插件中对应的资源来识别插件指纹。
2.3 部署反动态拦截模块
成功识别反蜜罐Web 插件指纹后可根据插件实现的缺陷,针对性逃逸动态拦截功能,继续主动探测,从而达到溯源攻击者的目的,即可通过制造回调函数错误,绕过网络请求拦截。插件在实现网络请求监听时需设置自身的回调函数,当回调函数执行出错时,如未设置错误处理,请求将直接被放行。因此,蜜罐可通过构造特殊的请求URL,刻意制造数组下标越界或除0错误,逃逸回调函数的检测。
3 结语
Web系统的健壮程度关系到人民财产安全和国家安全,保障其网络安全具有重大现实意义。本文总结了Web溯源蜜罐的研究现状和主要技术特点,通过详细分析蜜网和蜜场的技术特点和网络架构,为安全研究人员搭建满足业务需求的蜜罐网络提供了一定的参考和帮助,最后分析了攻击者对抗蜜罐技术的常用手段,并给出了对抗条件下的WEB溯源蜜罐防御体系构建思路。
