基于机器学习的钻井工况识别技术现状及发展
2023-09-23张菲菲崔亚辉于琛张同颖陈俊颜寒
张菲菲,崔亚辉*,于琛,张同颖,陈俊,颜寒
1.长江大学石油工程学院,湖北 武汉 430100 2.油气钻采工程湖北省重点实验室(长江大学),湖北 武汉 430100 3.中国石油渤海钻探工程技术研究院,天津 300280 4.中国石油渤海钻探工程公司,天津 300280 5.中国石油渤海钻探第一钻井工程分公司,天津 300280
现代钻井设备和监测基础设施的使用促进了钻井大数据技术的迅速发展。钻机仪器可容纳不同工作单元的各种传感器,如录井传感器和随钻测井工具,实时返回的各种钻井数据让现场工作人员可以更好地了解正在进行的井下钻井过程。但井下情况复杂,如极端钻井条件、传感器数据传输延时等,会出现噪音大、准确性差的钻井数据,难以判断真实的钻井工况。为了从高维、时序钻井数据中实时且准确地识别钻井工况,近些年国内外开展了大量研究,并开发了多个基于机器学习算法的工况识别模型。钻井工况识别属于高维数据分类问题,而分类分析作为有监督的机器学习中的主要任务之一,使得机器学习算法在钻井工况识别应用中表现出了显著的有效性和稳定性。鉴于此,笔者总结了机器学习分类算法在钻井工况识别技术中的应用现状及应用效果,探讨了基于机器学习算法的钻井工况识别技术发展趋势。
1 机器学习简述
1.1 机器学习发展历程
大数据时代带来了数据洪流,相比于简单的收集、传输与计算数据,更重要的是解剖数据、理解数据并从数据中提取有价值的信息。机器学习应运而生,通过深度理解、多重分析将数据转化为信息继而学习信息中的规律,通过算法而非特定指令对新数据做出预测或分类。其中有监督的机器学习将数据进行分类、回归来进行预测,通过更新参数来减少错误并提高算法。而无监督的机器学习将数据进行集群、密度估计、特征降维。机器学习的发展历程可以分为四个时期:
1)由感知机[1]开启的“推理期”(1960年之前)。感知机是一台能够识别罗森布拉特字母的机器,使用阈值元素将模拟信号转换为离散信号,是现代人工神经网络的原型。在该时期里,推理出了机械人迷宫揭秘鼠标[2]、强化概率神经模拟计算器[3],讨论出了自组织系统的仿真方法[4],利用相似的动物条件反射原理开发出了条件概率机[5]。
2)由决策树[6]和BP神经网络[7]推动的“学习期”(1960—1990年)。其中1960—1970年,提出了学习识别系统的设计和测试方法、模式识别问题的一般性陈述、机器学习问题的概率陈述,开发了基于有限集的近似函数简化方法、构造分离超平面的梯度型算法、平均风险最小化方法、极大极小优化算法、非光滑优化算法、递归目标不等式方法、在空间中寻找有限相交点的递归算法、自适应控制方法等。其中具有推动意义的里程碑机器学习系统有自适应线性神经网络[8]、最小均方算法[9]、随机网络[10]、决策树、表格最优值决策程序(BOXES)[11]。在1970—1980年,随着朴素贝叶斯法[12]、自适应阈值系统[13]、自组织多层神经网络[14]、离散时间随机环境的自适应控制器[15]等机器学习系统的提出,推动了多层神经网络的结构和学习能力得到进一步的研究。最终FUKUSHIMA等[16]在1980年提出了一种分层多层卷积神经网络。在1980—1990年,误差反向传播算法[17]的提出代替了标准梯度下降法,大大加快了神经网络算法的迭代速度。在这十年间具有推动意义的里程碑机器学习系统有自组织神经网络模型(Neocognitron)、自组织特征映射网络(Kohonen network)[18]、单层全连接循环神经网络(Hopfield network)[19]、误差反向传播算法、多层前馈网络[20]、时间延迟神经网络[21]、延迟奖励学习(Q-learning)[22]、反向传播卷积神经网络[23]。
3)由支持向量机[24]发起的“统计期”(1990—2004年)。CORTES和VAPNIK[24]提出了适用于一般不可分离情况的SVM算法,利用简单的递归算法使数据快速收敛于最优支持超平面。在该时期具有推动意义的里程碑机器学习系统还有循环网络[25]、统计梯度跟随算法[26]、时间差异学习[27]、模糊神经网络[28]、支持向量机、无监督学习[29]、长短期记忆网络[30]、双向循环神经网络[31]、随机决策森林[32]、强化学习[33]、最大边际马尔可夫网络[34],通过统计的优化和控制思想来提高算法的收敛速度。
4)由深度神经网络复兴的“深度学习期”(2004年至今)。随着大数据趋势和并行计算内存的成本降低趋势,计算性能翻倍的深度学习算法也得以协同发展。深度残差学习[35]提出了利用残差连接来大幅加深神经网络层数,之后的深度残差网络[36]、宽残差网络[37]、聚合残差变换深度神经网络(ResNeXt)[38]也都依次突破了神经网络深度下限。在这十年间具有推动意义的里程碑机器学习系统还包括了监督学习的深度监督网络[39];半监督学习的半监督深度学习[40]、半监督递归自动编码器[41];无监督学习的深度信念网络[42]、多任务深度神经网络[43]、可扩展无监督学习卷积深度信念网络[44]、深度前馈神经网络[45]、自我监督学习(ALBERT-xxlarge)[46]、大型自监督模型(SimCLRv2)[47]、并行计算的大规模自回归模型(PanGu-α)[48];卷积网络的反卷积网络[49]、深度卷积神经网络[50]、区域卷积神经网络[51]、轻量卷积神经网络(SqueezeNet)[52]、多尺度深度卷积神经网络[53]、移动卷积神经网络(MobileNet)[54];递归网络的矩阵向量递归神经网络[55]、神经张量网络[56]、深度递归神经网络[57];强化学习的深度强化学习[58]、可扩展分布式深度强化学习(IMPALA)[59];还有在线学习[60]、神经图灵机[61]、大规模生成对抗网络(BigGAN)[62]、终端轻量级神经网络(MnasNet)[63]、大规模迁移学习(BiT-L)[64]、循环理性网络(Rational DQN Average)[65]、自动高效共享分离范式(M6-10T)[66]、扩展转换模型(DeepNet)[67]。
图1展示了推理期、学习期、统计期中33个里程碑机器学习系统的时间轴,图2展示了“深度学习期”中33个里程碑机器学习系统的时间轴,可以看出里程碑系统出现的频率越来越快。
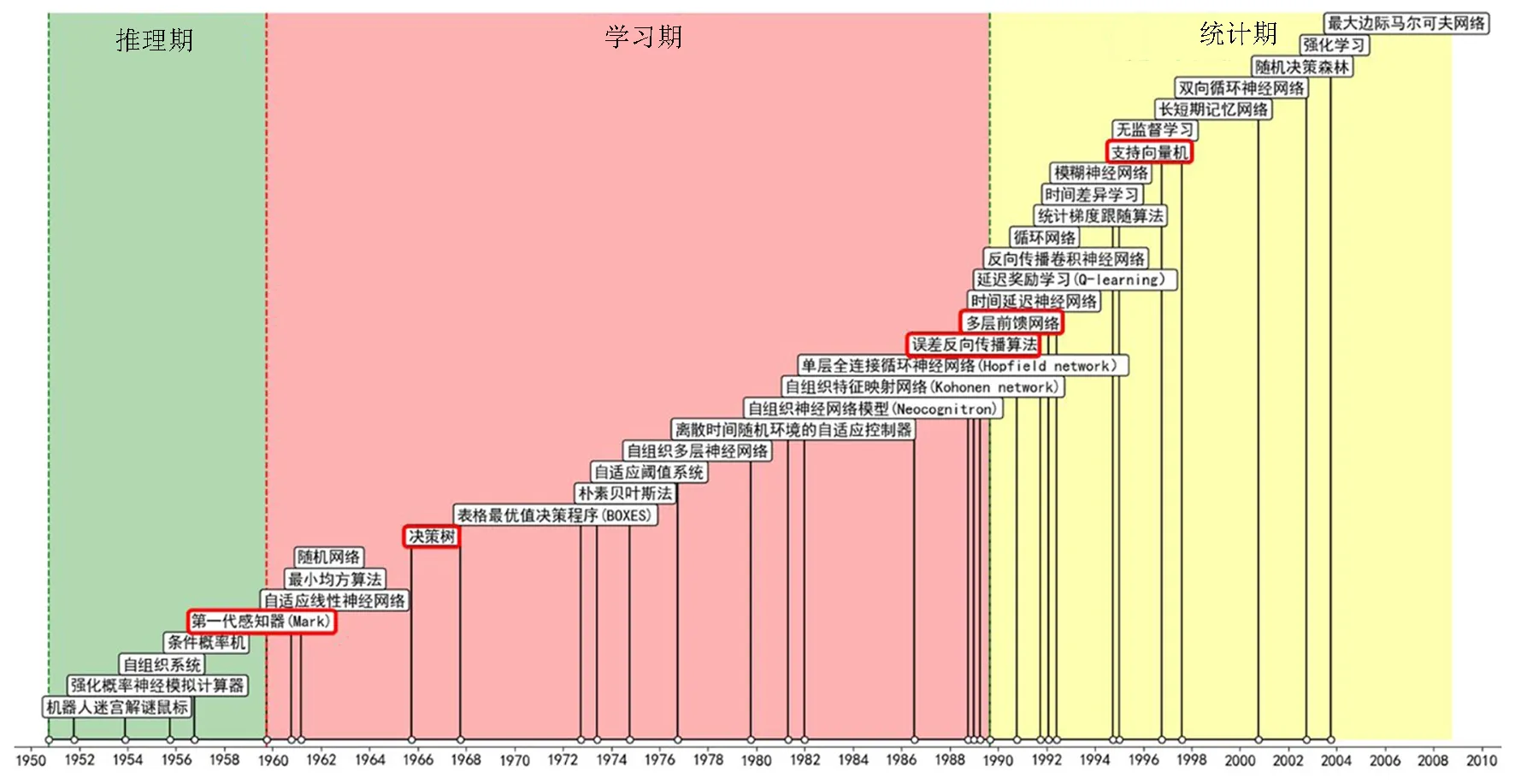
图1 推理期、学习期、统计期里程碑机器学习系统时间轴Fig.1 The timeline of reasoning period,learning period and statistical period milestones of machine learning system
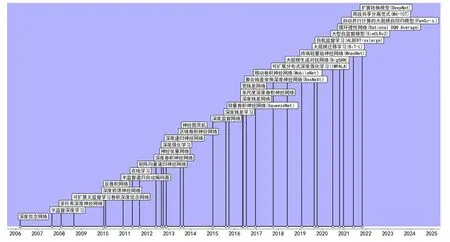
图2 深度学习期里程碑机器学习系统时间轴Fig.2 The timeline of deep learning period milestone of machine learning system
1.2 机器学习模型项目流程
机器学习在工程中作为一种快速分类工具,能够处理更复杂和不确定性更强的数据,从而大幅降低对误差、噪声和干扰的敏感度,最大程度地实现数据驱动,减少人为干预,促进大数据化与智能化。
按照图3中的机器学习项目流程,确定建立钻井工况识别机器学习模型的一般流程:①确定工况识别是多分类问题;②收集不同工况的钻井、录井数据,分析其时序、统计特征,进而设计模型的样本筛选、数据划分、模型选择以及模型评价标准;③提取有工况标注的、数据质量较好的样本数据,进行数据清洗;④利用专家经验和机器学习算法进行特征选择和处理;⑤选择较合适的一种或多种模型对提取的样本进行训练,反复调节模型的超参数,通过分类结果反向获取最佳性能参数;⑥利用验证集进行模型分类评价,选出分类效果最佳模型进行部署开启实际应用;⑦监控实际应用中表现出的模型分类效果,若不满足要求则进行模型重构和重训。
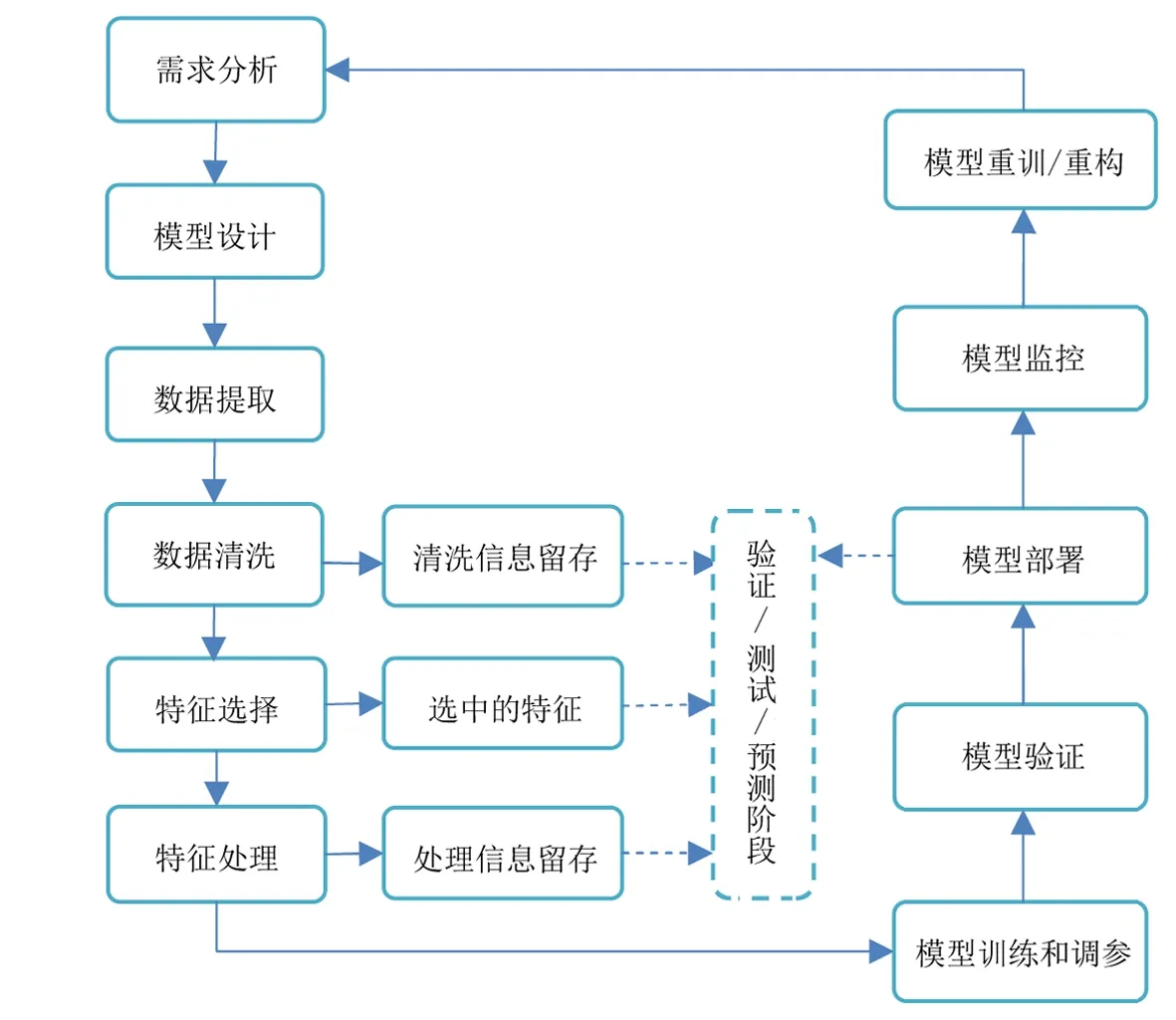
图3 机器学习项目流程Fig.3 The project flow for machine learning
2 钻井数据处理
2.1 钻井参数分类
钻井工程的监测通过钻机的4个传感器系统(旋转系统、循环系统、提升系统和计算系统)协作完成,通过传感器采集到的数据包含有大量的钻井信息,是判别钻井工况的重要依据。表1列举了4个系统的7大传感器、16个主要钻井参数。
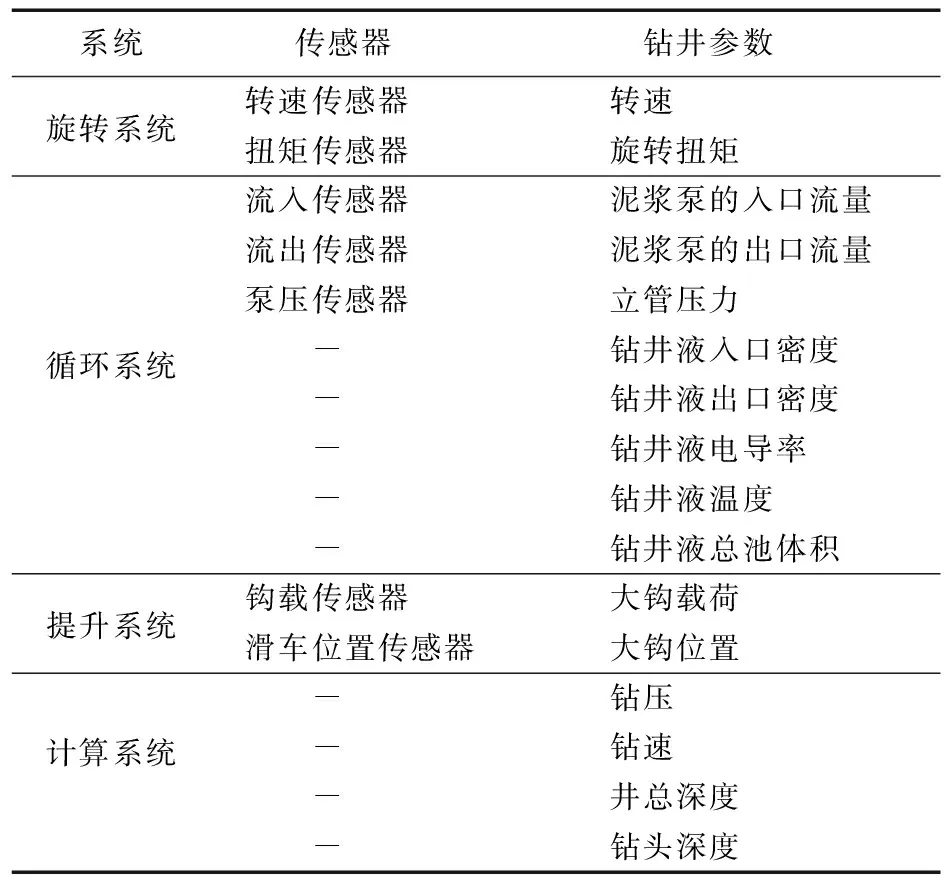
表1 钻井工程主要钻井参数
1)旋转系统包括顶驱电机和转盘,转动钻柱提供旋转动力。与该系统相关的传感器有:转速传感器和扭矩传感器,测量每分钟的转数和表面的旋转扭矩[68]。
2)循环系统包括地面管道、立管、钻杆、钻铤、钻头喷嘴、裸眼和出油管、泥浆清洗设备、泥浆罐、离心预充泵、容积式主钻井泵[69],通过在井壁上建立压力平衡来保持井筒中裸眼段的稳定,清除岩屑并清洁井筒。与该系统相关的传感器有:流入/流出传感器和泵压传感器,测量泥浆泵的入口/出口流量、密度、电导率等和立管处的压力[68]。
3)提升系统包括绞车、起重滑车、吊钩和吊卡、死绳固定器、钢丝绳和井架,将钻柱或其他必要设备从钻孔中取出[69]。与该系统相关的传感器测量有:钩载传感器和滑车位置传感器。钩载传感器读取大钩的重量和负载,滑车位置传感器测量移动滑车和钻机地面之间的距离[68]。
4)系统的参数由传感器读数计算得到:钻压计算为大钩载荷值中减去管柱重量;钻速计算为钻井作业期间钻柱移动的速度;井总深度计算为钻柱长度和地面标高与钻柱达到的最大值之间的距离;钻头深度是指当钻柱挂在吊钩上且未卡在钻台上时的钻柱长度。
2.2 数据清洗
传感器通常处于恶劣的工作环境中,采集的原始数据包含了大量的噪声、异常点,在测试曲线上表现为与钻井参数无关的统计起伏或毛刺干扰。针对这些问题,在钻井参数被分析前有必要清洗掉缺失值、噪声数据、离群点等,解决数据的不一致性问题,以便提供高质量、更有效的钻井数据信息,更好地建立工况识别模型。
对于缺失率较低的数据可以根据已有数据分布进行填补,或使用无监督机器学习的K-最近距离邻法[70],将所有样本进行聚类划分,再通过划分种类的均值对各自类中的缺失值进行填补。而缺失率较高的数据直接剔除。
对于噪声数据,应用最广泛的是小波降噪算法[71],通过多次对正常数据进行不同层次的噪声分解,再重构留下的正常数据,以得到除去了高频噪声且同时保留原始数据趋势特征的钻井数据。对于离群点,利用简单统计分析(箱线图、四分位点)、基于绝对离差中位数(MAD)、基于距离、基于密度、基于聚类等多种方法联合检测离群点避免错漏,发现后直接剔除。
2.3 特征选择
单一工况并非跟所有的钻井参数都相关,选择与当前研究工况相关的特征参数作为工况判定依据,首先通过统计特征分析、时序特征分析对钻井参数进行初步过滤。统计特征分析是通过计算不同工况所有录井数据的均值和标准差、最大值、最小值、数量、分位数等统计描述进行特征选择;而时序特征分析是通过探究不同工况下钻井数据随时间变化趋势差异进行特征选择。统计特征分析、时序特征分析可以衍生出新的集成特征参数:特征加和、特征之差、特征乘积、特征除商,如钻头深度时序之差和大钩位置时序之差可展示出钻头的移动方向;井总深度与钻头深度之差可表征出钻头在井下的位置。
初步过滤后可利用过滤法、包装法、嵌入法对钻井数据进行特征二次选择。过滤法按照特征相关性指标进行特征评分排名;包装法根据目标函数选择特征;嵌入法通过机器学习训练来确定特征的优劣。过滤法、包装法、嵌入法之间的特点、时间复杂度、过拟合程度差异以及算法示例如表2所示。过滤法计算量最小,运行时间最短,但包装法和嵌入法更精确,比较适合具体到算法去调整。当数据量很大的时候,优先使用过滤法;使用逻辑回归时,优先使用嵌入法;使用支持向量机时,优先使用包装法。

表2 过滤法、包装法、嵌入法之间的差异
3 工况识别技术中机器学习的应用
基于机器学习算法的钻井工况识别技术通过对钻井过程参数进行监测,保证钻井效率,减少各类损失,为实现钻井设备的自动化和钻井工程的智能化提供一些新的思路。本节将依次介绍在钻井工况识别中应用较广的四种分类器,分析基于BP神经网络、支持向量机、随机森林和深度学习的机器学习模型的原理、应用参数以及模型性能。
3.1 基于BP神经网络的钻井工况识别
BP神经网络由RUMELHART[7]在1986年提出,是目前训练神经网络最有效的算法之一,也是整个神经网络的核心之一。BP神经网络的特点在于设定期望误差,利用后向传递梯度搜索优化传播参数,将误差降到目标期望误差以下才停止迭代[72]。
廖明燕[73]先使用三层BP神经网络进行工况分类再利用D-S证据理论进行融合决策,利用泥浆流量、大钩高度、立管压力、扭矩等15种特征参数来实现9种异常工况识别和正常工况识别;之后对比优化了算法的超参数、分析了异常工况的实际参数特征与专家经验的不同之处。但是识别模型只评估了训练数据的分类性能,没有进行交叉验证评估测试数据;异常工况实例数据也较少,只测试了其中5种工况。
姜萌磊[74]将阈值法和BP神经网络算法融合得到工况识别模型,利用5个特征参数,实现了11个工况的实时识别,与钻井日报对比得到了94.7%的正确率。但是识别模型没有进行算法参数优化,特征值较少,训练数据也没有进行交叉验证。
表3对比了基于BP神经网络钻井工况识别的不同模型特点、超参数、样本数量、特征参数、识别工况类型以及识别效果,主要区别在于算法超参数中的隐藏层节点个数和学习率。姜萌磊[74]模型识别的是机理并不复杂的常见钻井工况,样本数量也不大,且输入参数只有5个却要识别出10个工况,这种情况学习率就需要降低以得到更精细的输入参数分类阈值、容纳更大的分类阈值变化幅度[75];而隐藏层节点个数可以适当减小,防止出现过拟合问题。廖明燕[73]的模型输入层有15个参数且输出层是10个复杂的事故工况,隐藏层节点个数应适当提高,否则无法拟合参数与事故工况间的复杂关系;学习率应适当提高来加快模型的训练时间,以抵消输入层、输出层、隐藏层节点个数较大对训练时间的影响,但也不能过大会忽略很多分类阈值变化、降低识别效果[75]。学习率取值在0.01~0.9之间,最低的学习率得到的模型识别性能不一定最好,适当降低不应直接选择0.01;而适当增加但不能过大也不应自选为0.5,应当融合自适应优化学习率算法来得到更有效的工况识别性能。
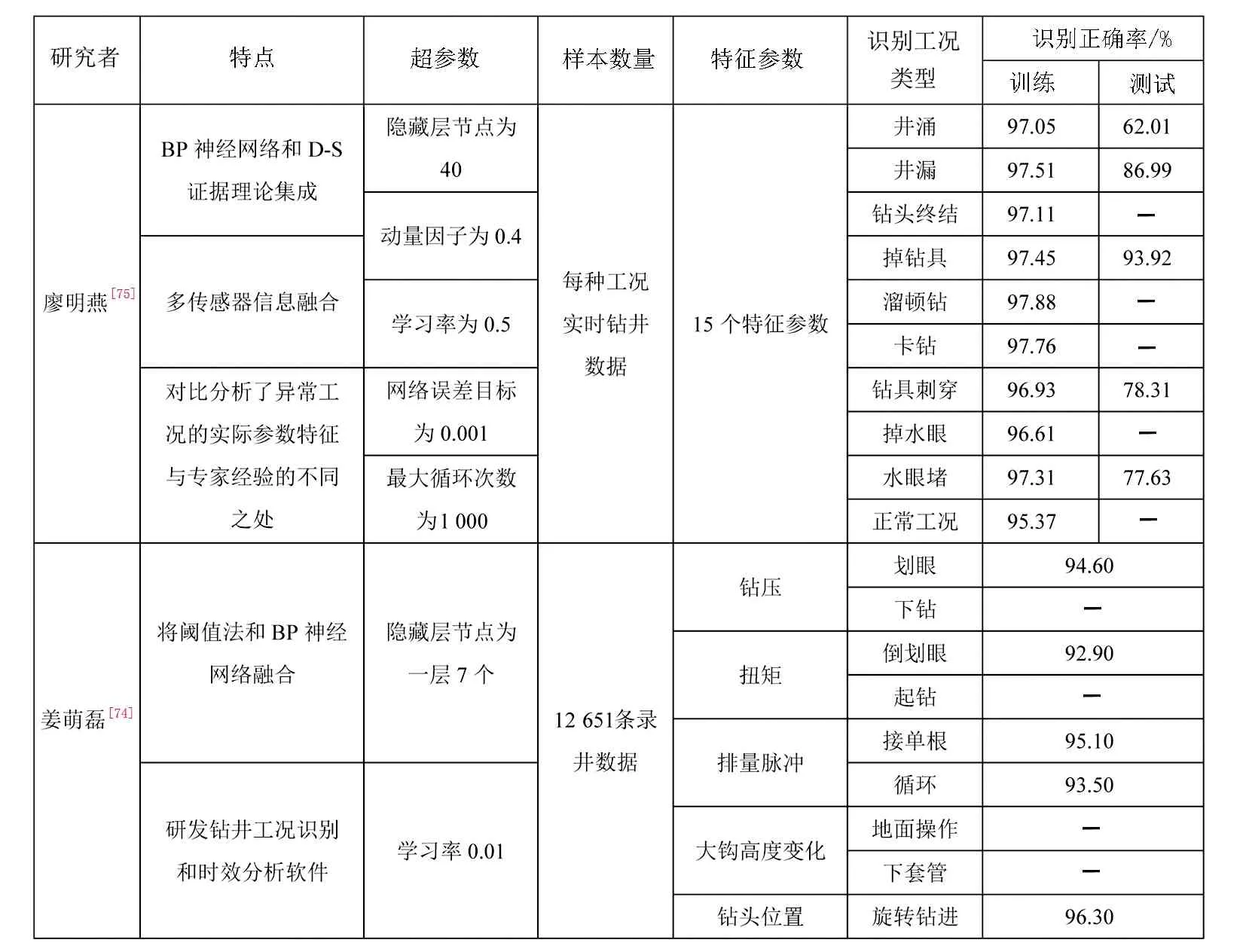
表3 基于BP神经网络的不同模型特点及超参数对比
3.2 基于支持向量机的钻井工况识别
支持向量机(SVM)由CORTES等[24]在1995年提出。SVM最初是作为二元分类器开发的,但它扩展到使用“一对多”[76]或“一对一”[77]方法对于多分类问题时,只能通过构建多个决策边界来解决。其中“一对多”是指每种分类对其他所有分类进行决策边界构建[76];而“一对一”则是对任意两个分类之间构建决策超平面,若要分出n类则需要构建个决策超平面,这种方法准确率最高并且训练时间最短[77]。当支持向量机解决非线性分类问题时,先使用核函数将数据进行高维映射,再利用线性分类组合出边距最大化的最佳超平面[76]。SVM算法使用凹函数作为代价函数来实现局部最优解的排除从而得到全局最优解,对于稀疏样本数据算出的损失函数值也比较小,这些特点使得SVM算法建立的模型非常稳定且拥有高效的分类功能[78]。
SERAPIAO等[79]使用“一对一”多类SVM算法,选择了测井数据中的5个特征参数,学习了3784个真实测井数据,识别出了6种工况。由于钻井工况中的旋转钻进和滑动钻进、旋转划眼和倒划眼存在多个特征参数相似,使用“一对多”不能保证一个类与其他类之间实现良好的区分,所以使用了“一对一”分类方法。但是存在模型筛选出的特征值较少;识别模型的惩罚因子和核函数也没有进行调参来优化参数;起下钻和循环得到的测井数据较少,数据不平衡、分布不均匀;模型没有很好地分离旋转钻进和旋转划眼、滑动钻进和倒划眼或工具调整等问题,因此应该增加更多钻井特征参数来将其区分。
ESMAEL等[80]将平均泥浆流量、平均大钩载荷、钻头测深、井眼测深、大钩位置、平均泵压、平均钻速、平均转速、平均扭矩、平均钻压、钻头测深和井眼测深的差值这12个钻井参数进行统计特征分析,计算了每个特征参数的22个统计特征参数,组合成242个特征集。特征数量优化结果显示使用特征排序中的前38个特征时有最佳精度。之后,ESMAEL等[81]对支持向量机模型进行了调参优化,并对比了人工神经网络、规则归纳、决策树和朴素贝叶斯算法。实例结果显示支持向量机和规则归纳的精度较高,而朴素贝叶斯的分类效果最差。但是只给出了前15个的特征参数,也没有解释这些钻井参数统计特征值的意义,也没有总结分析每种工况对应的特征参数区别;在实例中证明了38个特征训练出的识别模型比242个特征的精度提高了10%,但是没有给出具体识别的工况类别。
孙挺等[82]与上述三个模型相比,多筛选出了钻速、大钩高度、扭矩、出口排量这4个特征参数,多分类出了接力柱、下钻、下油管和钻塞工况,并通过对比线性、多项式、径向基和两层感知器这四种核函数识别结果优选了核函数为径向基核函数,利用交叉验证筛选了最优化参数,最终得到的识别模型测试集准确率为95%。但是特征值较少;训练及优选对比数据集也比较小,每种工况只有100条数据;并且实例应用只是进行了时效统计,没有对比钻井日报作业描述进行实例应用效果评价。
表4对比了基于支持向量机的钻井工况识别钻井工况识别的不同模型特点、超参数、样本数量、特征参数、识别工况类型以及识别效果,主要区别在于算法超参数中的惩罚因子和特征参数个数。惩罚因子C越大,模型对数据越包容。但包容越大可以使模型学习到越多的该工况的钻井数据,同时也会造成两种甚至于多种工况之前的边界重合、分类界限模糊,所以惩罚因子一定要根据识别正确率来进行调参优化。而特征参数个数也同样不是越多越好,过多的特征参数不止会增加模型训练和优化的时间,造成计算资源的浪费;同时也会混淆机器学习的视线,造成过拟合的结果。
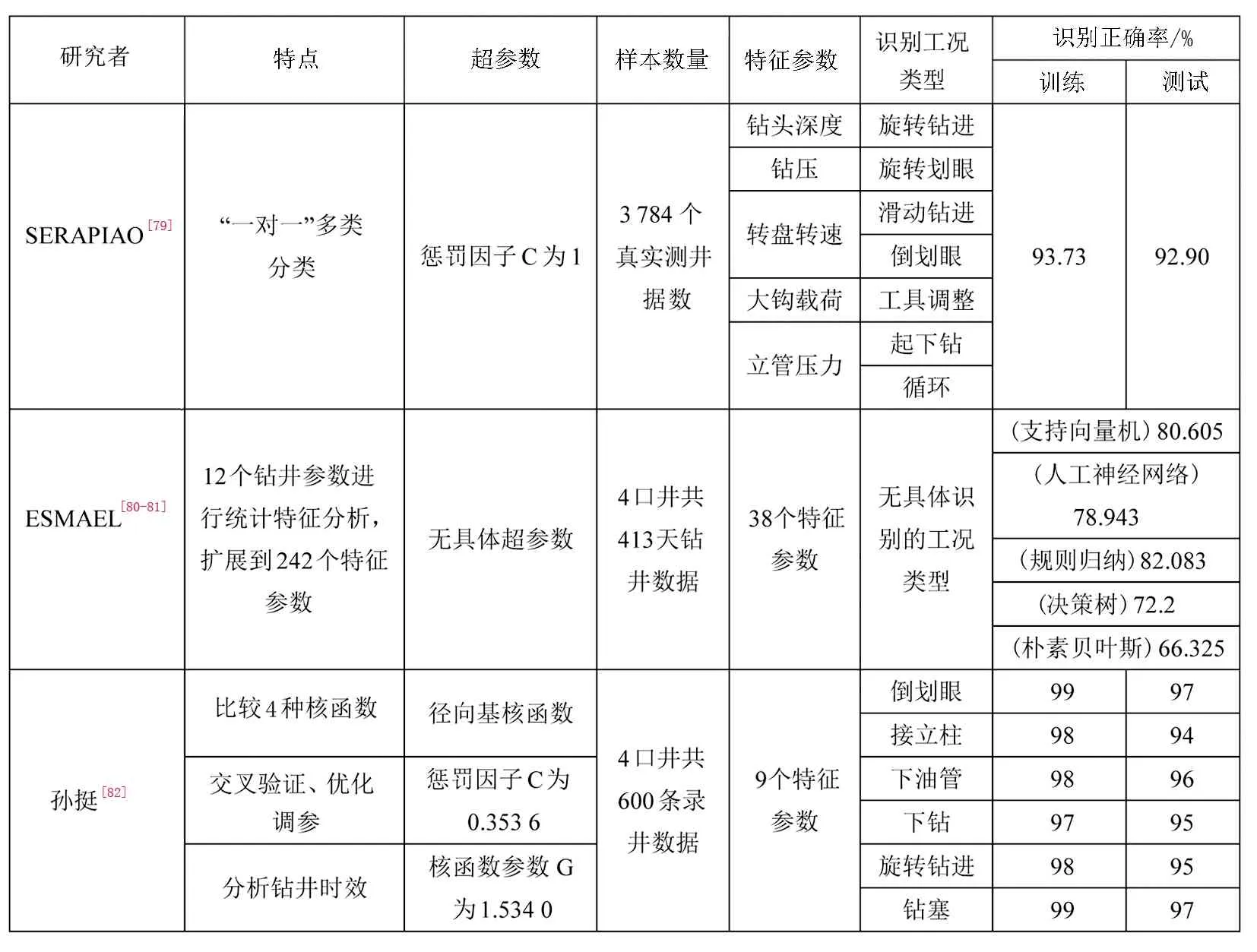
表4 基于支持向量机的不同模型特点及超参数对比
3.3 基于随机森林的钻井工况识别
随机森林由BREIMAN[83]在2001年提出,通过建立不同的自举数据集,在树的每个节点用随机的特征样本来构造多个决策树,避免了决策树[84]算法高误差、高方差和过拟合的问题。随机森林算法也可以通过计算决策树中给定输入变量的拆分引起的熵损失,反映出特征重要性进而优化模型的特征筛选。
TRIPATHI等[85]利用真实的测井数据进行10-折交叉验证,开发了模糊规则-随机森林的集成工况识别分类器,并与决策树、随机森林、支持向量机这3种算法进行了分类效果对比,显示出了模糊规则-随机森林算法的高精度和对钻井数据不确定性的高包容。筛选出了大钩载荷、出口排量、井深、钻头深度4个特征参数来形成模糊集,训练出了拥有12条模糊规则的分类器。随机森林分类器筛选了大钩载荷、钻头深度、井深、转速、泵冲程5个特征参数,使用了70个决策树,设定了最大叶子节点数为300以防止过拟合,最大终端节点数为15以防止过度装配,分割所需的最小样本数为1。在实例中,模糊规则-随机森林工况识别模型在10个钻井工况的识别中实现了100%的正确率。而决策树不能很好地区分旋转钻进和滑动钻进,将转动循环误分类为滑动循环,倒划眼也被错误分类为旋转钻进;随机森林将旋转钻进误分类为滑动钻进,倒划眼被错误分类为滑动钻进、旋转钻进和滑动循环,转动循环被错误分类为滑动循环;支持向量机不能很好地区分旋转钻进和滑动钻进,转动循环被误分类为滑动循环、划眼和滑动钻进。
表5展示了基于随机森林的钻井工况识别模型的样本数量、特征参数、识别工况类型,对比了不同机器学习算法的识别效果,从单纯随机森林83.90%到模糊规则-随机森林100%的正确率,展示了融合算法在工况识别精度上的绝对优势。
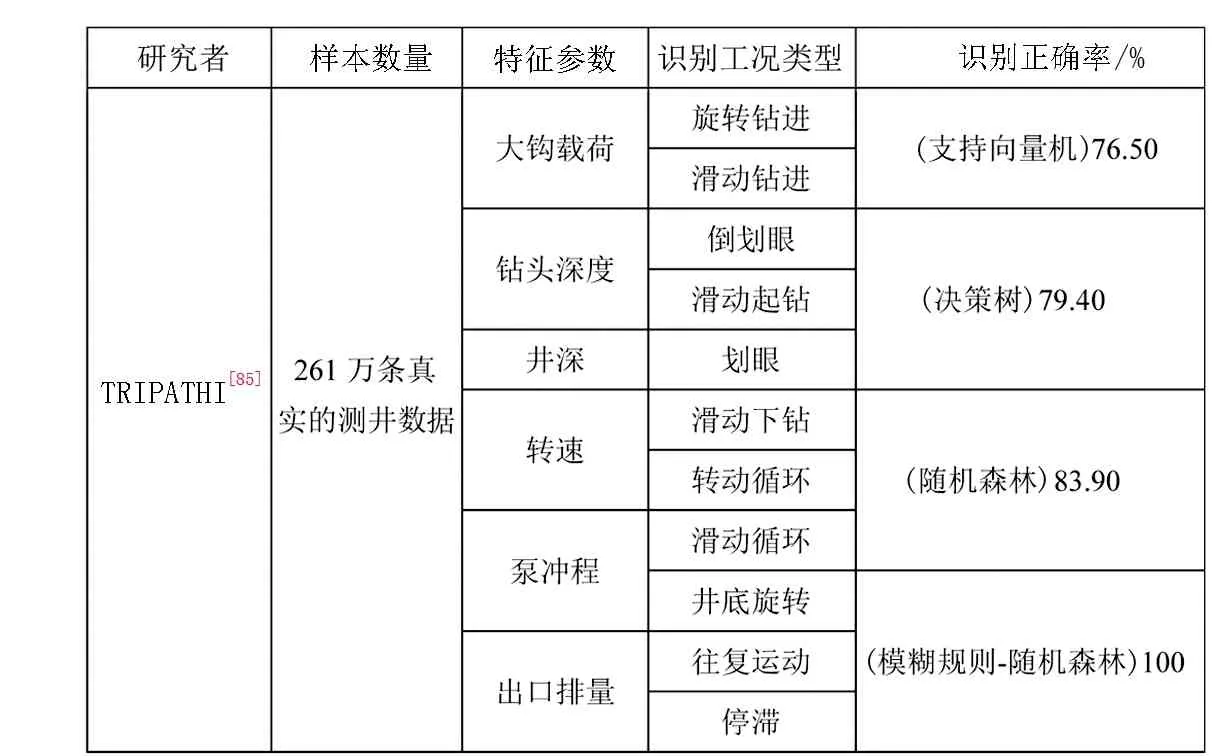
表5 基于随机森林的模型识别效果
3.4 基于深度学习的钻井工况识别
深度学习即“更深层次”神经网络,由HINTON等[86]在2006年提出。计算机硬件基础设施的升级使得深度学习拥有了更深的处理层和更强大的计算能力[87],多种数据转换函数实现了更复杂、抽象的表示层[88],海量数据支持了更自主学习数据特征和结构的功能层[89],使基于深度学习的模型表现出更高的性能和精度。
王超等[90]使用基于无监督的双向生成对抗网络和一维有监督的卷积神经网络(CNN)的端到端深度神经网络结构,利用内流压力、环空压力、环空温度、钻压、扭矩、XYZ三个方向的钻速这些钻井参数,建立了工况识别模型。由于归一化上限问题进行了钻井参数预处理,将井底流体压力减去了静水压力、井底温度减去地温梯度。利用一维七层离散小波分解和重构来处理数据高频噪音,消除了井深变化对于数据的影响。耦合分析了不同工况下钻井参数波动规律。工况识别模型在循环、旋转钻井、滑动钻井、跳钻、固井、下钻、泵送和停滞工况的分类效果非常好;对泵开启、泵关闭和起泵工况的分类效果不太好。将真实钻井数据与钻井并发症的理论进行了对比分析。但钻井并发症数据较少;而且深度学习模型解释性差,没有说明超参数;由于深度学习超参数微调代价大,所以也没有调参对比,分类性能只能在特征工程上优化。
表6展示了基于深度学习的钻井工况识别模型的样本数量、特征参数、识别工况类型以及识别效果。随着智能油田及钻井大数据技术的发展,大量的钻井数据更适合利用深度学习算法来建立工况识别模型。数据越多,模型识别性能越好,模型稳定性和适用性也越强,不仅可以稳定识别一口井从头到尾的工况,还可以适用于同一区块甚至于同一地区的其他井。随着深度学习的进一步发展,更深层的神经网络也会更加细化各种工况的分类标准,最近提出的DeepNet方法[67]更是把网络加至1000层。
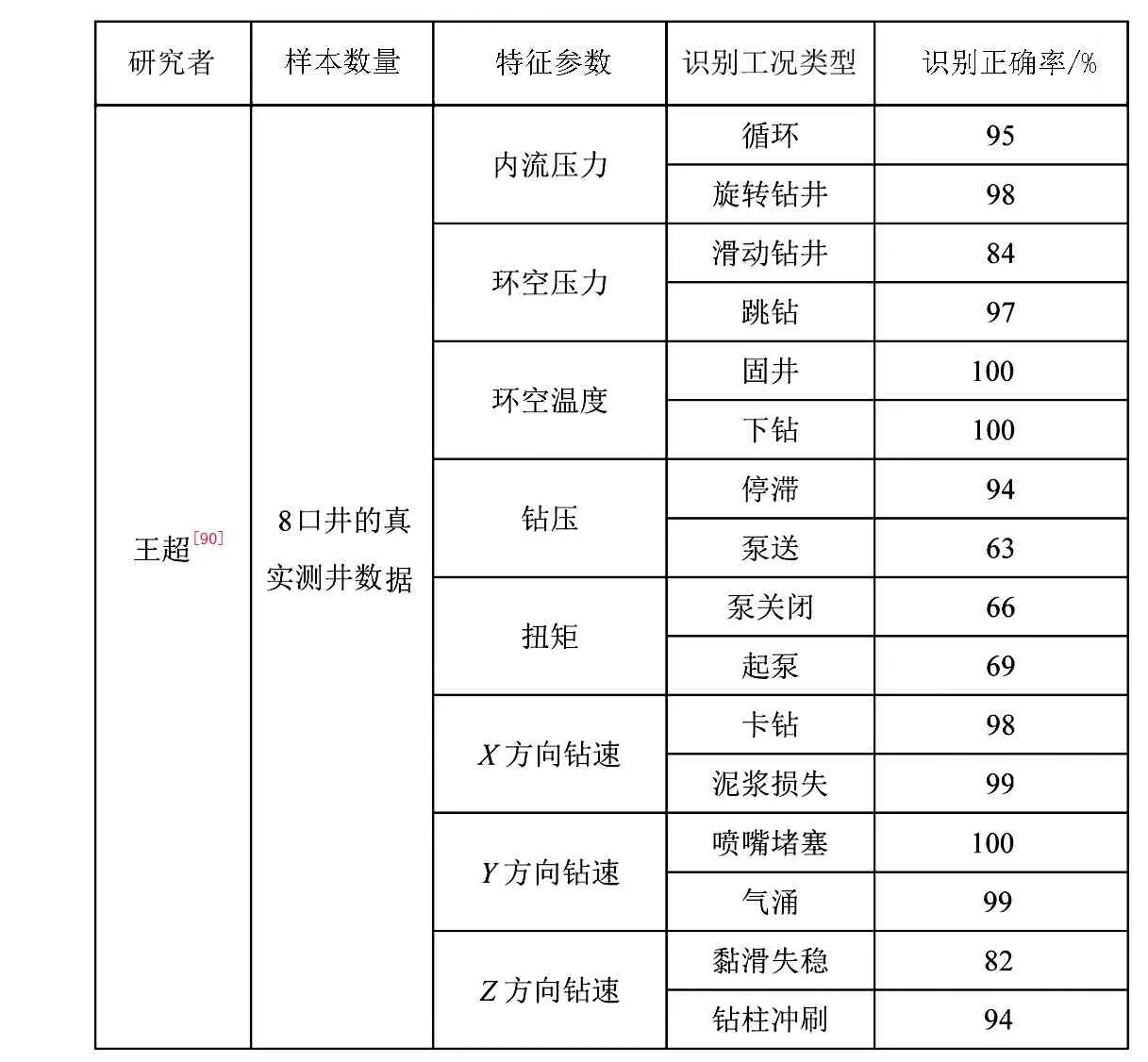
表6 基于深度学习的模型识别效果
BP神经网络的理论很难确定如何移动权值才能减少误差,对数据精度的要求比较高[72],当钻井工况(井涌、井漏、钻具刺穿、水眼堵等复杂工况)没有很好地线性分离时,得到的模型性能较差。支持向量机没有局部最小值问题,但对于大规模训练数据由于高维矩阵转置将耗费大量的机器内存和运算时间。随机森林在数据量较少或低维数据中不能产生很好的分类效果,尤其当其中的决策树数量较高时,模型运行较慢,不适于实时性要求很高的工况识别项目。深度学习需要大量数据和较长的训练时间,模型无法明确解释每一步做出选择的原因,且在实际应用中比较适应于泵关闭、起泵、黏滑失稳等复杂工况。
除了各自不同的算法缺陷外,机器学习模型还有一个通病是非常依赖训练数据,若应用井的地理区域环境差别较大、钻井设备参数差别较大时,识别误差便会增加,且难以改善性能,导致模型的后期维护成本高。这就说明了基于机器学习的钻井工况识别模型泛化能力不足,不同训练数据的模型识别的适应性和准确度不一。针对这种缺陷就可以将机器学习模型与物理模型相结合,物理模型中的分类阈值要根据静态参数(地层参数、钻柱设计、钻具组合、钻井液参数等)实现动态变化,使阈值判别标准更实时化,改善工况识别模型的泛化能力。
由于不同工况的钻井机理复杂度不一,需要的特征参数数量以及分类要求不同,导致不同模型对不同钻井状态识别的适应性和准确度不一。而每种机器学习算法都有自身的优势和不足,将每个好而不同的算法进行组合集成,利用“集体智慧”实现纠正个体错误,得到综合决策的效果,改善不同工况的分类性能。
4 基于机器学习的工况识别技术发展展望
基于上述对机器学习算法在工况识别技术的应用情况,阐述4点未来的发展方向:
1)特征工程自动化。钻井工况识别性能在很大程度上取决于特征值的选取质量和数量。大部分的特征值都由人工通过数据统计特征、时序特征的探索式分析而来,存在耗时较长、复用性较差等缺点,并且很难适应于井涌、井漏、钻具刺穿、水眼堵、泵关闭、起泵、黏滑失稳等复杂工况。特征工程自动化使用机器学习的过滤、包裹、嵌入等算法进行特征选择,通过自动优化工具将特征进行组合并衍生新特征,来应对越来越复杂的钻井机理。
2)利用结果反向优化识别模型。大部分的机器学习工况识别模型只给出了最终的识别结果,没有分析每种工况的错误识别数据。根据工况识别错误的钻井数据来调整模型的特征选择、优化算法的超参数、寻找更高分类性能的机器学习算法。
3)提高模型可解释性。机器学习算法向着精度和性能不断提高的方向发展,带来了模型解释难度也随之越来越高的问题。模型解释提供了模型决策的路径,在模型应用期间提供更快的异常数据检测、更清晰的错误预测原因,进而优化机器学习算法和模型。模型解释作为钻进数据的归集和沉淀,可以帮助更好地理解钻井过程中各类工况对应的井下参数变化,提供钻井过程优化以及钻井设备优化的新思路。
4)半监督学习取代监督学习。由于钻井数据本身都是没有工况标注的,目前只能借助钻井日志、完井报告以及钻井专家经验进行辅助标记其中小部分的数据,剩下的数据虽然没有工况标注但它的分布也会提供一些有用的信息。针对较少标注样本、较多未标注数据的工况识别问题,利用半监督学习取代目前普遍使用的监督学习,自主学习未标注样本既可以降低工况标注成本,又能提高模型识别精度。半监督学习先将有工况标注的这部分数据训练出一个中间模型,再利用这个中间模型将没有工况标注的剩余数据进行工况伪标注,利用自训练(以钻井专家经验和钻井领域知识为判断伪标注是否正确的准则)或协同训练(以数据分布的稠密距离相近、低密度分离、降维局部密集为判断伪标注是否正确的准则)挑选出伪标注正确的数据加入标注数据集,最后利用新的标注数据集训练出工况识别模型。
