存算分离架构下Part 元数据的单独管理策略
2023-09-22刘丹琪
刘丹琪, 蔡 鹏
(华东师范大学 数据科学与工程学院, 上海 200062)
0 引 言
传统的数据仓库通常面向可预测的数据量和重复的查询操作, 例如企业内部的资源规划管理系统、客户关系管理系统以及年度业务报告分析等. 然而, 随着数据量的持续增长、数据多样性和复杂性的增加以及业务需求的不断变化, 数据仓库需要处理的工作负载变得不可预测, 并且要求其在实时或近实时的范围内响应, 以支持公司实时运营和决策. 这种新的工作负载给传统的查询引擎和数据仓库带来了新的挑战. 传统的数据仓库通常采用Shared-Nothing 架构, 该架构可能会面临高成本、缺乏灵活性、性能低下和效率低下等问题, 无法满足新的工作负载需求[1]. Shared-Nothing 架构存在两个问题[2-3], 首先, 数据被分片后发送到各个节点, 每个节点仅负责处理本节点上的数据, 节点之间不共享数据, 计算和存储紧密耦合在一起, 导致计算节点所提供的CPU、内存、存储和带宽等硬件资源与工作负载所需硬件资源之间难以实现完美匹配. 其次, 该架构缺乏弹性, 在增加和减少节点时需要对大量数据进行重新划分, 增加了网络带宽消耗, 导致延迟增加, 系统性能显著下降.
ClickHouse 是一种基于Shared-Nothing 架构的列式数据管理系统, 凭借其卓越的性能、高可用性和可扩展性, 成为许多企业的首选系统[4]. ClickHouse 因其优异的查询性能和数据压缩技术, 已经在很多大型互联网企业中得到了广泛应用, 如头条、阿里、腾讯、携程等. 尽管ClickHouse 在许多方面表现出色, 但是其架构也存在一些限制. 首先, 由于计算和存储紧密耦合, 当工作负载发生变化, 例如查询量激增时, ClickHouse 存储和计算等硬件资源的利用可能会出现不平衡, 从而导致系统出现瓶颈和延迟. 其次, ClickHouse 缺少弹性, 无法独立扩展计算和存储资源.
为了解决Shared-Nothing 架构中存在的硬件资源利用不充分和缺少弹性的问题, 当前的主流云数据仓库中都采用了存储与计算分离的架构[5-6]. 在存算分离架构下, 当前的主流云数据仓库也对元数据进行了单独管理. 作为存储系统的关键组成部分, 元数据包含了关于数据的描述信息, 如类型、格式、位置和访问权限等. 存储系统中存在大量的元数据增、删、改、查操作, 这些操作频繁进行且对系统性能影响较大. 如果元数据访问性能不佳, 将导致数据访问效率低下、系统负载过高、响应时间延长等问题, 从而影响存储系统的稳定性和可靠性[7-8]. 因此, 优化元数据访问性能成为实现高效数据管理的关键因素之一. 此外, ClickHouse 节点启动的过程需要从磁盘上读取所有元数据文件, 并在内存中构建. 对于大量数据而言, 启动过程可能需要花费几十分钟甚至几个小时. 因此, 必须对远程共享存储上的数据进行高效管理.
当前主流的云数仓都将元数据存储于分布式数据库中进行管理, Snowflake[3]将数据库模式、访问控制信息、加密信息、统计信息等元数据信息存储于FoundationDB[9]上. Amazon Redshift[10-11]基于AWS Glue 的catalog 实现元数据管理, 存储了数据库表、视图、列的定义信息等元数据. Google BigQuery[12-13]采用Goods 提供元数据自动管理技术. 但是, 这些未对元数据内容进行详细分类和细粒度管理, 而大多数查询仅需要使用元数据的一小部分即可进行加速和优化. 因此, 对于元数据的内容进行详细分类和定制化管理显得尤为必要. 在存算分离的环境下, 对元数据进行详细分类和定制化管理, 不仅能够有效地管理远程共享存储中的数据, 而且更能够提高元数据利用效率, 加速系统查询过程. 这样的优化方案有望满足多种各样的企业级数据处理场景的需求. 为达到最佳管理效果, 元数据应当被细分为多个类别, 并根据其属性进行分类. 在此基础上, 可以制定出相应的管理策略, 以进一步提高元数据的利用效率, 从而为云数仓的优化和发展提供有力的支持.
本文调研了ClickHouse 的各类元数据, 并发现Part 元数据在所有元数据中的占比最大. 利用Part 元数据可以开发各类元数据工具, 例如: 利用列信息、索引信息等来加速查询, 根据访问频率标记热点数据, 追踪异常元数据以维护数据安全等. 通过实验发现, 在ClickHouse 的节点启动的过程中,Part 元数据的加载速度非常缓慢, 节点在此期间无法提供服务, 严重影响了系统的可用性. 因此, 本文的研究目标是在存算分离架构下对ClickHouse 的Part 元数据进行单独管理.
本文的主要贡献如下:
(1) 调研Shared-Nothing 架构存在的问题及ClickHouse 中当前存在的各类元数据, 并通过实验测试了ClickHouse 节点启动时间.
(2) 在存算分离架构下, 提出了一套Part 元数据管理策略. 首先, 采集ClickHouse 当前的Part 元数据文件, 并对各个小的元数据文件进行合并. 然后, 设计相应的键值组织策略, 并经过序列化和反序列化后, 将元数据存储到分布式键值数据库中. 此外, 为了保证远程共享存储中的数据和分布式键值数据库中的元数据一致, 设计了一套同步策略.
(3) 采用以上策略, 实现了一个针对Part 元数据单独管理的元数据管理系统, 并通过实验验证了其可以加速ClickHouse 节点启动过程, 同时支持存算分离架构下的高效节点动态扩缩容.
1 问题分析
1.1 Shared-Nothing 架构存在的问题
如图1 所示, Shared-Nothing 架构中的每个节点都拥有自己独立的CPU、内存和磁盘等硬件资源, 计算和存储资源之间紧密耦合, 不存在共享资源. 因此, 将表进行水平分割, 分配给多个独立工作的服务器, 通过增加服务器就可以增加处理能力和容量. 虽然Shared-Nothing 架构具有强扩展能力、多租户的隔离性和数据局部性等优势, 但也存在以下缺点:

图1 Shared-Nothing 架构Fig. 1 Shared-Nothing architecture
(1) 硬件资源利用不充分. 不同的工作负载对于CPU、内存和磁盘的需求各不相同. 然而, 在Shared-Nothing 架构中, 每台服务器所拥有的硬件资源是固定的, 无法根据工作负载的需求灵活调整.不同类型的查询对存储和计算资源的需求也不同. 为了满足各种类型的查询需求, 用户不愿为每个查询类型配置独立的集群. 因此, 为了支持这些查询, 需要在一个集群中同时满足计算和存储资源的要求, 这会导致计算或存储资源出现过剩的情况. 此外, 中小型业务通常集中在一个集群中, 大型查询会消耗大量的计算或存储资源, 对该集群中的其他租户造成影响.
(2) 缺少弹性. 工作负载是动态变化的, 同时, 客户对数据的访问存在偏斜性. 然而, 在Shared-Nothing 架构中, 数据被划分为多个片区, 并分发给各个节点, 无法根据动态变化的工作负载和数据的偏斜性灵活调整各个节点需要处理的负载. 此外, 添加和删除节点时需要重新划分大量数据, 这不仅增加了网络带宽的消耗, 还会导致性能显著下降.
Shared-Nothing 架构的主要特点在于计算和存储之间的紧密耦合. 为了应对上述问题, 需要将计算和存储分离开来, 使它们能够独立进行扩展.
1.2 Part 元数据单独管理的重要性
在ClickHouse 中, 数据以数据片段 (Part) 的形式进行组织, 每个数据片段中都有相应的元数据文件, Part 元数据是ClickHouse 中最主要的元数据. 本文将ClickHouse 中的元数据分为7 个类型: 数据库定义、表定义、虚拟集群、数据信息、函数和字典信息、用户信息、日志信息. 其中, Part 元数据的数据量在所有元数据中占比最大, 并且远远超出其他元数据类型.
当Part 元数据的数据量庞大时, 其加载过程对ClickHouse 的启动时间产生巨大影响. 在节点启动期间, ClickHouse 需要读取各类元数据文件, 并在内存中构建相应信息. 鉴于Part 元数据占比很大,读取所有Part 元数据文件并在内存中构建数据片段 (Part) 的过程非常耗时, 在此期间系统无法提供服务, 严重影响系统的可用性.
在4.2 节中, 我们模拟了生产环境, 在ClickHouse 中插入数据, 并测试了其启动时间. 实验结果显示, 启动时间在小时级别. 这样小时级别的启动时间是无法被容忍的. 在存算分离架构下, 将Part 元数据放置于远程共享存储中会导致更高的延迟. 因此, 本研究将重点放在Part 元数据的管理和利用上, 通过合并各个小的Part 元数据文件并存储于分布式键值数据库中, 利用分布式键值数据库的快速读写能力, 加速节点启动过程中Part 元数据的加载过程.
2 系统架构与功能模块
本文提出了一个高效的Part 元数据单独管理架构, 通过降低存算分离架构中从远程共享存储中读取Part 元数据的延迟, 能够更高效地管理数据. 系统架构如图2 所示, 从底部向上依次为元数据存储层、元数据管理层和应用层. 元数据管理层涵盖了元数据管理系统的各个功能模块: Part 元数据采集模块、键值映射模块、序列化反序列化模块和数据与元数据同步模块. 这些模块实现了元数据管理以及提供各种数据服务等功能. 数据存储层由分布式键值数据库构成, 如RocksDB[7]、FoundationDB[8]等, 这些数据库具有优异的读写性能, 能够提供高效的元数据存储服务. 应用层包含ClickHouse、Spark[14]、Hive[9]等主流云数据仓库, 其查询效率相比传统数据仓库提高数倍, 单个查询的峰值处理性能高达每秒数TB, 提供快速数据分析处理和高效查询等能力.

图2 Part 元数据管理架构Fig. 2 Part metadata management architecture
3 Part 元数据单独管理策略
3.1 Part 元数据采集
本文对Part 元数据进行了系统整理, 如图3 所示. Part 元数据来源于数据存储层上的Amazon S3 (amazon simple storage service)[15]、 HDFS (hadoop distributed file system)[16]、 Azure Blob Storage[17]等文件系统存储的数据. 在ClickHouse 中, 数据以数据片段 (Part) 形式进行组织, 每个数据片段对应磁盘上的一个数据目录. 每次数据写入都会生成一个新的数据片段, 其目录下包含data.bin 数据文件以及uuid.txt、columns.txt、checksums.txt 等元数据文件. 这些元数据文件存储了数据片段的唯一标识信息、列信息、文件校验信息等内容. 利用Part 元数据可以开发各类元数据工具[12],对数据进行有效管理. 例如, 利用索引文件可以加速查询过程, 利用文件校验信息可以对数据集进行重复检测和相似度判断, 利用TTL (time-to-live) 能够回收和清理旧版本数据. 此外, 还可以采用监控异常元数据、追溯元数据的来源信息、标记敏感数据等方式维护数据安全, 通过计算访问元数据频率方式查找热点数据等.
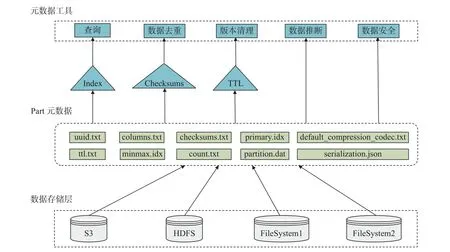
图3 Part 元数据Fig. 3 Part metadata
3.2 键值组织策略
FoundationDB、RocksDB 等分布式键值数据库具有可扩展性强、高可用性和高性能等特性, 能够提供高效的数据存储服务. 为了将Part 元数据存储在分布式键值数据库上, 需要采用统一的键值存储模型, 其具有数据存储灵活、数据结构简单等特点.
在节点首次启动时, 为了获取数据位置信息, 需要遍历磁盘中的分区目录. 然而, 在存算分离架构下, 数据存储于远程共享存储上, 遍历远程共享存储上的分区目录代价高昂, 进一步增加了磁盘I/O 的开销. 因此, 本文在分布式键值数据库上单独设计了键值映射模型, 用于存储数据位置信息. 在存算分离架构下, 获取数据位置信息的过程不再需要遍历远程共享存储上的分区目录, 而是直接从分布式键值数据库中获取相关信息.
如图4 所示, 针对Part 元数据, 为确保所有数据片段的键具有唯一性, 每个键包含节点ID、分割符、table 的唯一标识和数据片段名称. 分割符′x00′的设计用于实现范围查询操作. 对于范围查询操作, 具有相同前缀的键在逻辑空间上是连续的, 因此可以利用get_range(key_prefix+′x00′,key_prefix+′xff′)获取所有具有相同前缀的键值对象. 键值包含了3.1 节中调研的所有元数据信息.针对数据位置信息元数据, 键中添加了 p artDisk_prefix 前缀, 用于区分Part 元数据和数据位置信息元数据, 并在键值中包含了分区目录的位置信息, 以便从远程共享存储中查找数据.
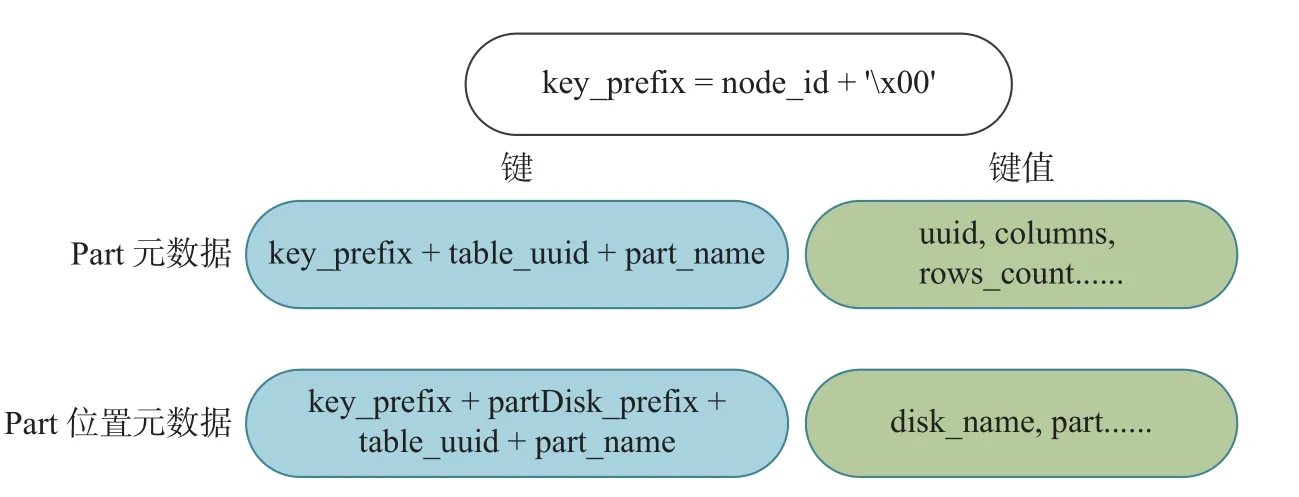
图4 键值组织方式Fig. 4 Key-value organization
3.3 序列化和反序列化方式
由于元数据存储层采用了分布式键值数据库, 元数据需要被序列化为二进制或字符流的形式, 以便存储和读取. 序列化将元数据对象转换为可以被存储的字节流或字符串, 反序列化则将字节流或字符串转换为原始的元数据对象. 在进行序列化和反序列化时, 需要考虑效率和压缩率的因素.
本文采用基于Protocol Buffer 的序列化与反序列化方式. 这种方式不仅在效率上具有优势, 而且支持丰富的数据类型, 并且能够提供良好的压缩率. 图5 展示了将ClickHouse 中存储的Part 元数据文件序列化为分布式键值数据库中的元数据对象的过程. 在ClickHouse 中, Part 元数据通常包含许多小的元数据文件, 但是小文件的存储存在以下3 个缺点[18]:

图5 序列化与反序列化Fig. 5 Serialization and deserialization
(1) 小文件的数据内容较少, 管理效率较低.
(2) 对于小文件, 数据块可能分散存储在磁盘上的不同位置, 产生大量的磁盘碎片, 这不仅降低了访问性能, 还浪费了磁盘空间.
(3) ClickHouse 中存在大量必要的小文件合并操作, 但是合并小文件的代价非常昂贵.
因此, 为了更加方便地对小文件进行管理, 本研究首先提取元数据文件中的内容, 再将各个小的Part 元数据文件进行合并. 其次, 根据Protocol Buffer 所提供的数据结构类型, 如double、uint32、uint64 等基本数据类型、数组类型、map 类型等, 为元数据文件中的内容选择合适的数据结构. 最后,将这些定义好的数据结构保存在后缀为.proto 的文件中, 并转换成proto 对象, 存储到分布式键值数据库中. 通过合并小文件为大文件, 首先, 提高了元数据的检索和查询效率, 减少了文件读写的I/O 操作延迟. 其次, 将可能连续访问的小文件合并存储, 增加了文件之间的局部性, 将原本小文件的随机访问转变为顺序访问, 极大地提升了性能.
3.4 Part 元数据和数据同步策略
在存算分离架构下, 数据放在远程共享存储上, 而元数据放在分布式键值数据库中. 读写流程如图6 所示. 在读请求中, 首先查询元数据, 若能成功查询到元数据, 则通过元数据位置信息去远程共享存储中查询对应的数据; 若未查到元数据, 则直接在远程共享存储上查询数据并将相应的元数据更新至键值数据库. 然后返回查询到的数据. 在写请求中, 先从键值数据库中查询所需要的元数据信息, 在远程共享存储中将数据修改完成后, 回到键值数据库更新相应的元数据信息.

图6 读写流程Fig. 6 Read and write process
然而, 由于数据和元数据分别存储在远程共享存储和键值数据库上, 一旦涉及写操作, 就可能出现数据版本不一致的情况. 如图7 所示, 当从客户端发来两个并发的写请求时, 首先, 线程1 和线程2的写请求依次从键值数据库中读取元数据信息; 接着, 线程1 的写请求更新了远程存储中的数据 (步骤三); 然后, 线程2 的写请求再次更新了远程存储中的数据 (步骤四). 然而, 由于网络延迟等原因, 线程1 对键值数据库中元数据的更新可能会晚于线程2 (步骤六晚于步骤五), 这导致最终写入远程共享存储中的数据是线程2 的新值, 而写入的元数据是来自线程1 的旧值, 即元数据版本落后于数据版本.在这种情况下, 如果客户端再次发送读请求 (步骤七), 将会读取到旧的元数据版本. 此外, 在写操作中还可能出现一种情况, 即数据更新成功但元数据更新失败. 这种情况也会导致元数据版本落后于数据版本. 另外, 在3.2 节中, 每次更新涉及两类元数据时, 即Part 元数据和数据位置信息元数据, 必须保证对这两类元数据的更新是原子操作, 否则可能导致这两类元数据不一致.

图7 并发写入冲突Fig. 7 Concurrent write conflicts
由于每次读写操作都需要先查询键值数据库中的元数据, 为了确保远程共享存储中的数据和键值数据库中的元数据的一致性, 以及Part 元数据和数据位置信息元数据两类元数据的一致性, 本文针对元数据设计了一套同步策略.
在键值数据库中维护了两组键值对. 第一组键值对为
基于以上同步策略, 图8 展示了在本文提出的数据与元数据同步策略下的读写流程.

图8 同步策略下的读写流程Fig. 8 Read and write process under synchronization strategy
对于写请求的具体流程: ① 客户端给服务器发送一条写请求. ② 在键值数据库中查找数据位置信息和锁队列. 若锁队列不为空则等待, 否则获取写锁并更新锁队列. ③ 在远程共享存储中修改数据及版本号. ④ 在键值数据库中更新元数据及锁队列. ⑤ 若第④步操作失败, 则将该Part 元数据的键值放入消息队列中, 并进行异步重试更新, 同时针对异步重试更新设定了超时时间. 若在超时时间内修改失败, 在后续的读请求中发现数据版本更新时, 会进行元数据的更新.
对于读请求的具体流程: ① 客户端给服务器发来一条读请求. ② 在键值数据库中查找数据位置信息和锁队列, 若锁队列不为空则等待. ③ 在远程共享存储中查找相应版本的数据. ④ 若第②步中未查找到数据位置信息, 说明该数据不在锁队列中, 并且元数据版本号小于当前读取到的数据版本号.此时, 更新该数据的元数据及位置信息元数据.
在该策略下, 当存在两个并发的写请求时, 第一个写请求在键值数据库上查询元数据时, 会获取写锁并更新锁队列, 从而避免与第二个写请求的冲突. 同时, 当存在两个并发的读写请求时, 读请求在键值数据库上查询元数据时发现锁队列不为空也会进行等待, 从而避免读写冲突的问题.
4 实 验
4.1 实验环境
实验部署了ClickHouse 集群和FoundationDB 集群, FoundationDB 集群作为存储Part 元数据的数据库. 实验在Ubuntu 20.04.4 LTS 操作系统上进行, CPU 型号为AMD EPYC 7K62 48-Core Processor CPU @ 2.53 GHz, 4 核, 4 线程; 16 GB 内存. FoundationDB 版本为7.1.27, ClickHouse 版本为22.3.2.2-lts.
4.2 节点启动性能
本实验选取了ClickHouse 官方提供的数据集OpenSky 作为研究对象. 该数据集是在对完整OpenSky 数据进行清洗处理后得到的, 记录了COVID-19 新冠肺炎期间空中交通的演变情况. 数据集包含了自2019 年1 月1 日以来超过2 500 个基站接收到的所有航班信息, 总计约6 600 万条数据. 为了尽量模拟实际生产环境, 本实验利用OpenSky 数据集创建了2 000 张MergeTree 表, 每张表包含16 个字段、300 个数据片段, 一共60 万个数据片段. 目前ClickHouse 已经支持将S3 作为远程共享存储系统. 本实验设置了3 组实验对象进行比较. 第1 组采用原生的ClickHouse 架构, 数据和元数据存储在本地磁盘上. 第2 组在第1 组的基础上, 引入S3 作为远程数据存储. 第3 组在第2 组的基础上,将Part 元数据单独存储在FoundationDB 上进行管理.
将OpenSky 数据集导入后, 本文对3 组实验对象中ClickHouse 节点的启动时间进行了对比, 得到的实验结果如图9 所示. ClickHouse 在启动过程中需要读取Part 元数据文件, 并在内存中构建相应信息. 由于Part 元数据数量庞大, 这一过程极其漫长, 因此, 原生ClickHouse 的启动时间达到了小时级别. 当将数据存储在远程共享存储上时, 启动时间变为了原来的1.5 倍. 这是因为从远程共享存储获取数据会增加网络开销, 并且在启动过程中需要从远程共享存储中读取众多Part 元数据文件. 然而, 通过将Part 元数据单独存储在FoundationDB 上, 并利用其快速的读写性能, 可以显著缩短从FoundationDB 中读取Part 元数据并在内存中构建相应信息所需的时间, 大大降低了ClickHouse 节点的启动时间, 仅需要不到20 min.

图9 启动时间对比Fig. 9 Comparison of startup time
4.3 扩缩容效率
为了评估存算分离架构下将Part 元数据单独管理后节点的扩缩容效率, 本实验设计了两组对象进行比较. 第1 组采用S3 作为远程数据存储的ClickHouse 架构, 第2 组在第1 组的基础上将Part 元数据单独存储在FoundationDB 上. 实验步骤如下: 首先, 初始化TPC-H 数据集并将其导入两个对照组集群. 然后, 针对两组对照组进行扩容耗时实验和缩容耗时实验. 扩容实验将3 节点集群扩展为4 节点, 而缩容实验将4 节点集群收缩为3 节点. 实验结果的评估指标设定为扩缩容耗时, 即从接收新增或移除节点请求开始到成功执行扩缩容并达到集群正常服务性能所需的时间, 结果如图10 所示.

图10 扩缩容效率对比Fig. 10 Comparison of expansion and shrinkage efficiency
对于第1 组对象而言, 当集群中存在3 个ClickHouse 节点时, 会建立一张3 节点分布式表. 当集群扩展为4 个节点时, 创建一个4 节点的分布式表, 并将数据从旧的分布式表复制到新表中. 因此, 扩缩容耗时主要取决于全量数据复制的时间. 而对于第2 组对象而言, 集群扩容时只需在元数据管理系统上选择一部分数据分配给新的节点, 无需进行大量数据迁移, 扩缩容效率将大幅提升. 在数据量从20 GB 增长到60 GB 的范围内, 原生ClickHouse 架构的扩缩方案耗时呈现线性增长, 而采用FoundationDB 对元数据进行单独管理后, 扩缩容时间整体维持在4 s 以内.
5 总 结
本文调研了传统的数据仓库中主流的Shared-Nothing 架构存在的问题, 并在存算分离架构下提出了一套Part 元数据管理策略, 以及利用该策略实现了一个针对Part 元数据单独管理的元数据管理系统. 鉴于Shared-Nothing 架构计算和存储紧密耦合的特性, 本文提出了将存储和计算分离的需求.具体而言, 首先对Shared-Nothing 架构中存在的问题和ClickHouse 当前的各类元数据进行了调研, 并通过实验测试了ClickHouse 节点的启动时间. 接着, 在存算分离架构下提出了一套Part 元数据管理策略. 该策略首先采集ClickHouse 当前的Part 元数据文件, 合并各个小的元数据文件, 并设计相应的键值组织策略. 在序列化和反序列化后, 将元数据存储在分布式键值数据库中. 此外, 为了确保远程共享存储中的数据和分布式键值数据库中的元数据的一致性, 设计了一套同步策略. 通过采用以上策略,成功实现了一个针对Part 元数据单独管理的元数据管理系统, 并通过实验验证了该系统能够加速ClickHouse 节点的启动过程, 并支持存算分离架构下的高效的节点动态扩缩容.
