服务器无感知计算场景下基于时空特征的函数调度
2023-09-22吴秉阳刘方岳章梓立贾云杉
金 鑫 吴秉阳 刘方岳 章梓立 贾云杉
(北京大学计算机学院 北京 100871)
(高可信软件技术教育部重点实验室(北京大学) 北京 100871)
(xinjinpku@pku.edu.cn)
随着云计算技术的发展,在云计算平台上开发和部署应用已经成为一种主流方式.传统云计算平台将资源以虚拟机和容器等形式提供给用户.除了开发应用逻辑外,用户还需要进行虚拟机和容器等资源的配置和管理.服务器无感知计算[1]是一种新兴的以函数为中心的云计算范式.服务器无感知计算向用户提供高层次的函数抽象在云计算平台开发和部署应用程序,让用户可以专注于应用逻辑的开发,而无需关注资源的配置和管理.
服务器无感知计算(serverless computing)以函数为粒度分配资源.用户基于函数抽象编写应用程序,并将其打包为函数镜像部署于服务器无感知计算平台.当函数请求到来时,函数请求被发往服务器无感知计算调度器,由调度器负责函数请求的调度和执行.调度器在集群中找到空闲服务器,在空闲服务器上加载相应的函数镜像,将函数镜像启动为一个函数实例运行来处理请求.
服务器无感知计算平台使用函数镜像存储系统来保存函数镜像.当加载函数镜像时,服务器需要通过网络从函数镜像存储系统将所需函数镜像传输到本地,有大量的网络传输和存储系统读取开销,本地函数运行时也需要加载相关依赖库和进行初始化操作,加载时间长.从远程函数镜像存储系统加载和启动容器及函数运行时的过程称为冷启动.为了优化函数启动时间,服务器无感知计算平台通常会在服务器本地对函数镜像进行缓存.当所需函数镜像在本地缓存时,服务器可以直接启动该函数镜像,而无需再从远程函数镜像存储系统加载.除此之外,容器和函数运行时也可以预先启动等待执行函数代码,这个函数启动过程称为热启动.
函数完成时间是从函数请求到来直到函数执行结束所经过的时间,其直接反映函数应用的性能,是衡量服务器无感知计算平台的重要指标.影响函数完成时间的因素主要包括排队时间、启动时间和执行时间3 个方面.函数排队时间指函数请求在调度器队列中等待被调度的时间.如果函数服务器本地没有缓存函数镜像,则需要通过冷启动从远程函数镜像存储系统加载并启动函数镜像和函数运行时,产生额外的冷启动开销.函数执行时间指函数镜像加载和启动后,函数实例运行处理函数请求的时间.
在服务器无感知计算场景下,对函数请求进行调度来优化函数完成时间是一项挑战,其主要面临问题规模大和动态性强2 个难点.
1)问题规模大.服务器无感知计算平台以函数为粒度进行调度,需要在短时间内调度大量并发的函数来执行处理函数请求.这要求调度器有很好的可扩展性,限制了调度器为每个函数维护过多的调度信息.
2)动态性强.来自用户的函数请求动态性强,不同函数执行时间、资源需求等时空特征差异较大,并且在调度时无法知道未来函数请求精确的任务时空特征,不能基于所有信息直接做约束求解.
现有服务器无感知计算相关工作使用先来先服务(first come first serve,FCFS)算法作为函数调度算法[2-4].当队头请求的函数执行时间很长,或者本地没有该函数镜像的缓存,冷启动时间很长时,会导致队头阻塞(head-of-line blocking),排在队列后面的请求需要等待很久才能被执行,使得整个系统的平均函数完成时间变长.最短任务优先(shortest job first,SJF)策略是一种经典的解决队头阻塞问题的策略.然而,在服务器无感知计算场景下,经典的最短任务优先策略不能完全解决队头阻塞问题,因为排在队头的请求可能因为冷启动造成较长的完成时间,影响队列后面请求的执行,仍旧造成队头阻塞.除此之外,最短任务优先策略等经典算法也没有考虑不同函数在资源消耗方面的空间特征,这导致资源消耗较大的函数任务可能阻碍后续多个资源消耗较少的任务并发执行,进而加剧队头阻塞.
目前有一些工作通过设计函数镜像缓存策略降低函数冷启动率[3-6].AWS 和Azure 等商用平台以及OpenWhisk 等开源平台使用固定函数镜像缓存策略.该策略在函数执行完成后,将运行时环境保存一个固定时间长度(例如10 min).一些工作对缓存策略进行了优化,比如利用贪心对偶大小频率(greedy-dual size frequency,GDSF)缓存算法等.这些工作侧重于设计更好的缓存策略来降低冷启动概率,但没有将冷启动与调度进行综合考虑.这些工作在调度上使用基础的FCFS 调度策略,即使通过缓存策略降低了冷启动概率,还是会遇到由于调度顺序不佳造成的队头阻塞问题,影响整个系统的平均函数完成时间.
为此,本文研究了服务器无感知计算场景下的函数调度问题,提出了针对服务器无感知计算的函数调度方案,主要贡献有3 个方面:
1)分析了服务器无感知计算场景下的函数调度问题,并定位了3 个影响函数完成时间的因素,分别是排队时间、启动时间和执行时间.基于该分析,提出了数学模型对服务器无感知计算场景下函数调度问题进行形式化建模,为函数调度问题提供优化目标.
2)设计了基于函数时空特征的服务器无感知计算调度算法FuncSched,综合考虑时间和空间2 个维度的特征.在时间维度上,利用时间分析器评估函数执行时间,并利用预热的函数镜像的状态和函数请求对应的位置预测函数启动时间;在空间维度上,考虑函数运行时的资源占用量.该策略根据时间和空间维度的特征计算函数请求优先级,基于优先级进行调度,并根据运行时状态对优先级进行动态更新.
3)针对服务器无感知计算场景下函数调度问题,为了验证本文所提调度算法的有效性,实现了原型系统,并使用了真实世界服务器无感知计算负载数据集进行实验.实验结果表明所提调度算法可以有效降低平均函数完成时间,并对性能提升原因进行了分析.实验还评估了所提调度算法与不同缓存策略的兼容性,表明所提调度算法在多种缓存策略下都能有效降低平均函数完成时间,从而验证了本文所提调度算法的有效性.
1 相关工作
1.1 服务器无感知计算函数性能优化
函数性能优化是当前服务器无感知计算领域的重要研究方向.众多工作基于检查点/恢复、自模版启动、运行时环境预启动等多种技术缩减冷启动开销,减少用户请求的响应延迟.接下来,我们分类概述已有相关工作,并将其与本文工作进行比较分析.
当用户请求对应的镜像文件未存储在本地时,云平台需要首先从远端下载镜像文件,而后再启动运行时环境,这一过程的耗时可能长达数秒.为了优化镜像文件的下载速度,文献[7]基于共享网络文件系统对镜像文件进行存储和拉取,并基于延迟加载加速容器启动.文献[8]和文献[9]通过分布式文件系统存储镜像文件以提升读取效率.文献[10]使用P2P 结构加速容器镜像文件的分发.文献[11]基于树状P2P 网络加速虚拟机镜像文件的传输.文献[12]将虚拟机组织为动态变化的树结构以完成虚拟机镜像文件的快速分发,并采用树平衡算法在大型服务器无感知计算平台的高可变环境下保证树结构稳定.
部分工作将已就绪的运行时环境打包为快照文件并存储起来,在后续的用户请求到来时直接复现,从而缩减运行时环境的启动时间.文献[13]将用户函数代码、语言解释器、依赖库在内的运行时状态打包为Unikernels[14]快照文件以优化其后续启动速度.文献[15]通过多个容器间的状态共享支持高并发的负载场景.文献[16]基于类似思路实现了虚拟机间的即时编译(just-in-time compilation,JIT)文件共享.文献[17]同时对快照文件中的应用状态(如内存使用)及系统状态(如文件打开情况)进行按需恢复与延迟恢复,进一步加速其启动速度.
部分工作为使用相似运行时环境的一类函数创建普适的运行时环境模板,从而用户函数可以自模版快速启动.文献[5]借鉴了安卓系统中的Zygotes[18]机制,将常用的依赖库安装在本地,并以只读方式挂载到容器当中以跳过Python 依赖库的安装与加载过程.文献[19]利用调用频率较低的空闲容器创建Zygotes 容器.在Zygotes 容器中安装所有用户函数的依赖包,从而后续函数请求在函数执行过程中无需再进行依赖包加载.
在服务器无感知计算中,函数执行的时间通常只有数秒[3],而函数的冷启动时间包括函数镜像拉取开销和函数运行所依赖环境的启动开销,往往也需要几秒的时间[3],因此优化函数的冷启动是服务器无感知计算系统的重要目标.通过提前启动运行时环境可以避免冷启动的发生.主流商用及开源服务器无感知平台[2,20-22]通常在函数执行结束之后将运行时环境在集群中保留固定时长(例如10 min),由此调用频繁的用户函数能够实现稳定热启动,这类策略规则简单,但带来了显著的资源浪费.
部分工作基于调用预测针对性地预启动运行时环境.文献[3]从周期性角度对函数进行分类,对于周期性较差的函数使用ARIMA[23]等标准时间序列预测算法,而对于具有明显周期性的函数则使用基于直方频率分布的启发式规则进行负载预测,在函数最可能被调用的时段内维持预启动环境.文献[6]基于傅里叶变化对函数未来并发数进行预测.在此基础上,根据预测结果调整运行时环境在集群内的部署位置,将有更大可能被调用的运行时环境部署在高性能服务器上,调用概率较低的则部署在低性能服务器上,从而降低维持预启动环境的花费.文献[24]设计了长短直方预测(long-short term histogram,LSTH)算法,综合分析函数在天和小时粒度下的周期性特征,以适应机器学习任务以天为粒度的周期性特征以及以小时/分钟为粒度的偶然性波动.文献[25]基于长短期记忆(long short-term memory,LSTM)网络对函数调用历史进行特征抓取,在此基础上基于贝叶斯优化对预启动资源池进行动态调整.
在负载预测之外,部分工作优化固定内存大小下的实例集合以降低函数冷启动率.部分工作借鉴缓存策略管理预启动环境,将运行时环境视为缓存对象,将冷启动与热启动分别视为缓存未命中和缓存命中,从而将缓存策略应用于服务器无感知计算领域.文献[5]使用最近最少使用(least recently used,LRU)策略管理运行时环境的缓存.文献[4]则借鉴贪心对偶大小频率(greedy-dual size frequency,GDSF)缓存算法[26],综合考虑运行时环境的调用频率、大小、用户函数冷启动时间、最近调用间隔等因素,在内存中保留优先级最高的运行时环境.此外,部分工作致力于缩减单个运行时环境的内存占用,从而增加固定内存中可容纳的运行时环境实例个数.例如,文献[27]针对服务器无感知场景缩减USB 等虚拟机构件,从而将内存开销压缩至QEMU 的数十分之一;文献[28]同样通过优化虚拟机开销将单个安全容器的内存占用压缩至数百MB.
虽然已有工作从多个角度优化了服务器无感知计算场景下的函数完成时间,然而由于本节工作均未意识到调度算法对函数完成时间的影响,从而仍旧无法避免函数请求在高负载场景下的队头阻塞问题.与之相对的,本文提出了基于函数时空特征的服务器无感知计算函数调度算法FuncSched,降低函数完成时间.
1.2 任务调度
任务调度器通过调整任务执行顺序来优化任务完成时间.SJF 算法[29]能够有效避免长任务对后续多个短任务的长时间阻塞.最短剩余时间(shortest remaining time first,SRTF)优先算法[30]允许新到来的短任务抢占正在运行的长任务,以实现更优的任务完成时间.Gittins 索引策略[31]能够在用户任务耗时不定,但符合特定分布时降低平均任务完成时间,而多级反馈队列(multi-level feedback queue,MLFQ)算法[32]以及最小获得服务者优先(least attained service,LAS)算法[33]等启发式算法则规避了文献[29-31]所述算法必须对任务运行时间具有先验知识的弊端,从而适用于机器学习等难以估计任务运行时间的场景[34].此外,文献[35]通过频繁抢占长任务保证短任务的优先执行,从而优化尾部延迟.
部分工作通过任务分类与资源预留避免任务阻塞,优化任务完成时间.例如文献[36]将用户请求划分为长任务和短任务,并专门预留部分资源处理短任务,以避免短任务阻塞.另一些工作则通过提高调度效率缩减任务完成时间,例如文献[37]和文献[38]将长任务和短任务分别部署在集中式和分布式调度器上,由此避免巨量短期任务在调度过程中被阻塞.文献[39]和文献[40]则采用了工作窃取策略,允许空闲工作线程“窃取”高负载工作线程的任务队列,从而在分布式调度场景中实现良好的负载均衡,避免不必要的任务阻塞.其他工作则同时考虑到不同任务的延迟要求,例如BVT 算法[41]计算任务的排队时间与目标延迟时间的比值,并优先调度比值最大的任务.而文献[42]则允许用户通过声明式语言为高优先级任务预留部分计算资源,从而避免高优先级任务被低优先级任务阻塞.
文献[29-41]所述的工作没有考虑服务器无感知计算场景的时空特点,时间上不同的函数请求的执行时间差异很大,最高可差8 个数量级[3];空间上不同的函数请求的资源占用差异也很大[3].这些工作无法直接应用于服务器无感知计算场景的函数调度.本文根据函数时空特性,设计了面向服务器无感知计算场景的调度算法,在保证调度器高效运行的前提下优化函数完成时间.
2 问题定义和建模
2.1 问题分析
本文旨在研究面向服务器无感知计算场景的函数调度算法.服务器无感知计算平台提供基于函数的高层次抽象,使得用户无需显式配置和管理云资源,只需要编写和提交应用逻辑相关的函数.服务器无感知计算平台负责调度函数、分配资源和执行函数,图1 展示了服务器无感知计算平台的框架和工作流程.在这一框架中,控制平面的调度器需要结合函数时间分析器和资源管理器决定具体的函数执行顺序.在这种执行模式下,调度算法和函数镜像缓存策略[4,6]会极大影响函数执行性能.因此,本文研究的问题是在服务器无感知计算场景下的函数调度,以优化函数完成时间.

Fig.1 Architecture overview图1 架构概览
2.2 问题建模
1)系统建模.我们将服务器无感知计算平台的集群资源建模成一个大小为m×n的矩阵M.集群包含m个函数服务器,计算负载包含n个函数.M[i,j]=1表示第i个函数服务器上缓存了第j个函数对应的镜像;E(j)表示函数j的执行时间;D(j) 表示函数j对应的冷启动时间.
2)任务建模.总共有l个函数请求,函数请求的集合是F,F[k]表示第k个函数请求对应的函数编号,F[k]a表示第k个函数请求的到达时间,F[k]s表示第k个函数请求被系统调度开始执行的时间,F[k]e表示第k个函数请求被执行完成的时间,O为顺序数组[1,2,…,l]的置换数组.本文中主要符号及含义如表1所示.

Table 1 Symbol Table表1 符号表
基于上述问题建模,本文的研究问题包含如何设计函数调度算法和决定函数的执行顺序,以优化平均函数完成时间.
2.3 问题定义
对于第k个函数请求,如果要调度该函数到函数服务器i,其完成时间为F[k]e-F[k]a=E(F[k])+D(F[k])×M[i,F[k]]+F[k]s-F[k]a,由执行时间、冷启动时间和排队时间组成.要优化的目标是所有函数请求的平均完成时间,那么目标函数归约为:
式(1)中,不确定的变量有函数的调度时间F[k]s和函数的放置位置i.其中M[i,F[k]]表示函数是否是热启动,如果是热启动则不需要从全局函数镜像存储拉取镜像,对应的函数冷启动开销为0.
首先分析函数请求的执行顺序O所带来的约束条件.对于k=O[u],即顺序中的第u个函数请求,对应函数请求集合中的第k个元素.排在其顺序之前的所有函数请求(O[1],O[2],…,O[u-1])都应该比O[u]有更高的优先级,即需要满足约束条件:
即O[u]的调度时间一定不早于排在其前面的函数请求的调度时间.其次是集群资源的限制,令时刻t函数服务器i的空闲资源量为Vi(t),函数请求O[u]可以在函数服务器i上执行的约束条件是:
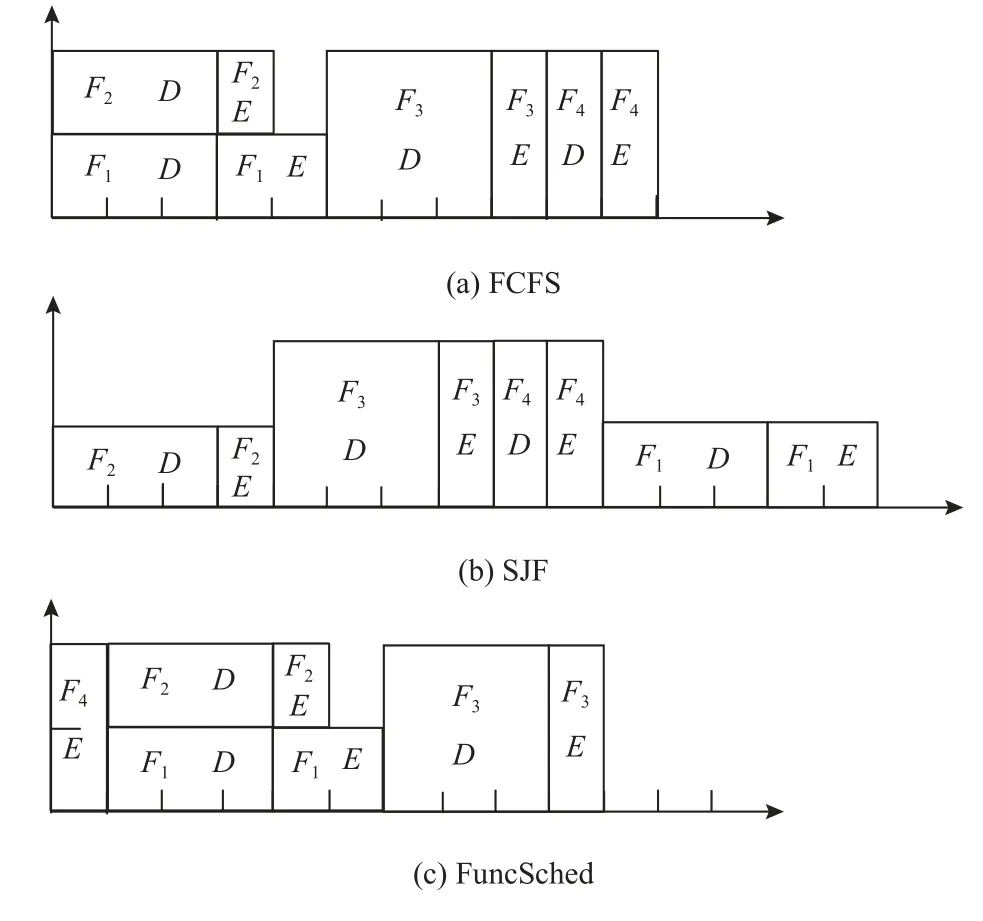
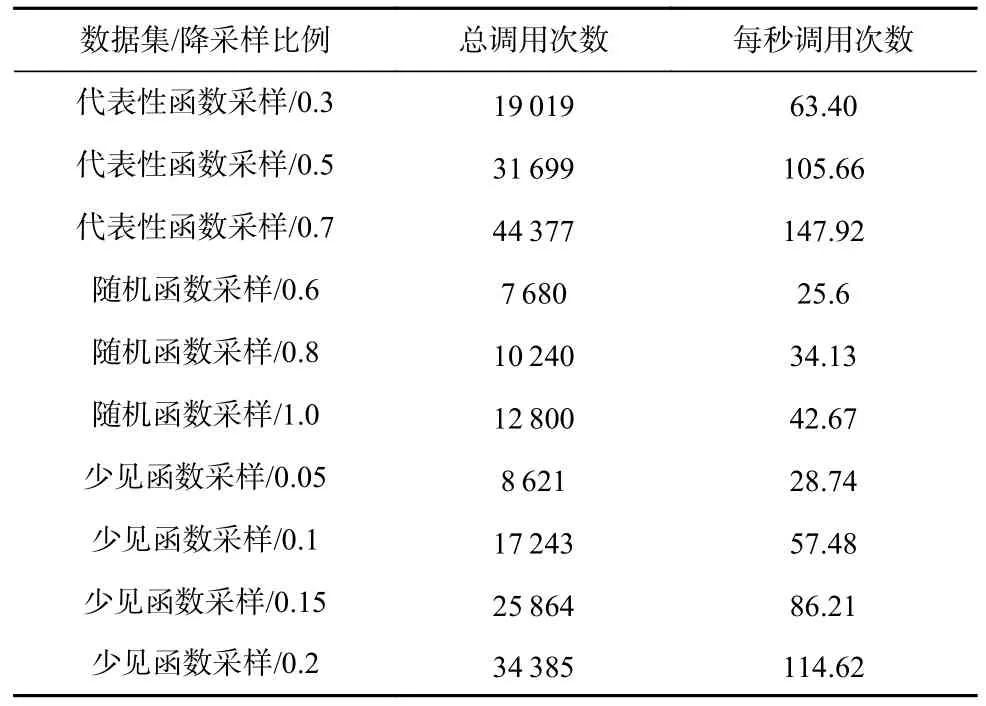
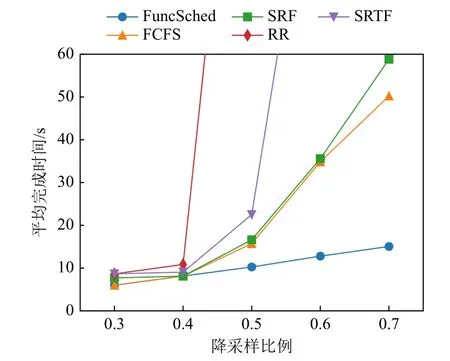
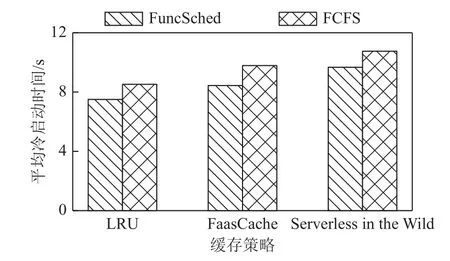
即要求目标放置服务器的空闲资源数量足够容纳即将要调度的函数请求,假设数组A表示函数请求放置的服务器标号,那么在决定O[u]的放置策略时,∀q 综上所述,该问题的数学模型为: 目标函数: 约束条件,即式(2)(3): 约束条件(2)保证了调度的优先级,约束条件(3)保证了有资源执行对应函数. 在第2 节的问题建模指导下,本文分析了服务器无感知计算调度的挑战和现有算法的局限性.基于问题建模和现有调度算法现状,本节针对服务器无感知计算的特点,提出了一个基于函数时空特征的服务器无感知计算函数调度算法FuncSched,在兼容现有其他服务器无感知计算优化模块的基础上,实现更低的平均函数完成时间. 服务器无感知计算旨在让用户只需编写跟实际业务逻辑相关的代码,无需关心底层资源调度、机器配置、分布式执行等复杂底层硬件集群细节和日常运维难点.这一计算编程模型虽然减轻了用户开发负担并降低了用户运维成本,但是也极大增加了服务器无感知计算调度的难度.具体来说,服务器无感知计算调度存在问题规模大和动态性强2 个技术难点. 首先,由于用户编写的服务器无感知计算框架代码需要以函数粒度来进行调度,服务器无感知计算调度器需要在短时间内调度大量并发函数执行[3].这要求服务器无感知计算调度算法要有很好的可扩展性.此外,对于每个函数不能维护过多的信息,因为这会极大增加调度器的资源消耗和复杂度.第2 节针对函数调度优化建模的约束求解问题难以在短时间内解出,这是因为其建模出的约束求解问题本身就已经难于整数线性规划问题,属于NP 问题,不能在线性时间复杂度内解出.而在约束求解问题中,变量O可能达上百乃至上千量级.如此大规模的函数调度问题不能采用指数级的约束求解器来给出调度方案.许多函数执行时间很短,指数级时间复杂度的约束求解器调度本身的时间消耗很可能远大于函数执行时间本身,造成极大性能损耗. 其次,服务器无感知计算调度需要面对动态性强的函数执行请求.在第2 节的问题建模中,函数请求到达时间F[k]a很难在每次调度执行时知道其全部信息.因此,服务器无感知计算调度也不能基于所有信息的情况直接做约束求解,进而也不能达到最优调度计划.现有研究也表明函数请求到达规律很难用泊松分布、定时执行等模型来完全拟合[3],因此也很难基于预测来得到较好的调度方案最优近似解. 服务器无感知计算平台中的函数镜像缓存模块也影响服务器无感知计算调度.函数镜像缓存模块有自己的存储策略.在设计函数调度算法时,需要考虑与函数镜像缓存模块的兼容,并通过优化调度算法进一步降低平均函数完成时间. 现有服务器无感知计算框架,例如OpenWhisk,Knative 等,通过预热(prewarm)、延迟函数镜像存活时间(keep-alive)等机制[2-3]优化函数性能.最新的相关研究工作也从缓存策略等方面对服务器无感知计算进行优化提升[4-5].但这些工作都是优化单一用户函数应用的执行性能和资源分配.当大量用户函数请求同时被触发时,用户函数间会产生资源竞争.如何在用户函数调用请求间进行资源调度,目前的实践和最新研究都深度不够. 具体来说,目前的服务器无感知计算框架,当面对大量同时到达的用户函数调用请求时,采用的是FCFS 算法进行调度,即 这样的调度算法优势在于其调度算法执行开销较小,不会较大影响函数调用的端到端完成时间.另一方面,这一调度算法会产生队头阻塞.当一个函数请求执行时间较长时,后继的函数请求将经受很长的等待时间,进而造成函数性能下降. 针对3.1 节和3.2 节所述的问题和挑战,本文提出了一个面向服务器无感知计算场景的基于时空特征的函数调度算法FuncSched 以优化函数完成时间,并且能兼容服务器无感知计算的函数镜像缓存模块.这一算法从经典的SJF 算法泛化而来,但是Func-Sched 同时考虑到了函数任务的时间和空间2 个维度的特征. 3.3.1 函数时间特征估测 在时间维度上,本文利用了服务器无感知计算平台中的用户函数会被反复调用的特点,提前利用时间分析器评估每个用户函数需要执行的时间E(j).服务器无感知计算调度器以这个时间指标指导函数调度.传统的SJF 算法以任务执行时间E(j)为标准,优先调度E(j)最小的任务执行,从而避免了先到达的任务因为执行时间较长阻塞后续任务的问题.与之不同的是,FuncSched 同时综合考虑了函数执行时间和函数在服务器无感知计算平台的启动时间.设计背景在于,细粒度函数的执行时间通常较短,而函数的启动时间反而会对函数任务最终的端到端完成时间产生较大影响.当函数处于热启动状态时,函数可以立刻执行;当函数处于冷启动状态时,即使函数执行时间较短,较长的函数启动时间也会阻塞后继函数. 函数启动时间,其不仅与函数自身代码逻辑紧密相关,也受服务器无感知计算框架的函数镜像缓存模块的影响.函数镜像缓存模块的决策具有动态性,其会基于现有负载、用户要求等在运行时做出决策,从而影响函数启动时间.对于这一动态变化的函数运行开销,一个设计背景是,函数镜像缓存模块只会影响预热的函数镜像的状态和函数请求对应的位置F[k].因为服务器无感知调度平台中的函数镜像缓存模块对调度器白盒可见,因此调度器可以提前预测后继函数请求需要经历的启动时间.具体来说,FuncSched 会维护一个变量W(j),表示函数j可以被热启动的函数请求数量.当函数j的镜像被预热或有函数j请求结束时,调度器即可立即将W(j)加1,表示新增一个可以热启动的函数请求容量.当函数j的镜像被驱逐或有函数j请求开始执行时,调度器立即将W(j)减1,表示减少一个可以热启动的函数请求容量.通过维护变量W(j),FuncSched 可以实时感知函数镜像缓存模块对函数启动时间的影响,进而增强对函数整体运行时间的把控.除此之外,利用W(j)进行函数调度的过程还将函数启动时间的判定从每轮函数调度逻辑的关键路径上移除,降低了大规模调度细粒度函数的开销.并且,这一数据结构所需存储空间小,不会让调度器产生额外的存储压力. 3.3.2 函数空间特征估测 在空间维度上,FuncSched 调度时考虑了每个函数的运行时资源占用情况.传统的调度算法,无论是FCFS 算法或者SJF 算法,其都是基于时间维度的调度算法.但是在服务器无感知计算环境中,函数资源占用差异较大,如果单纯按照函数运行时间进行任务调度,仍然很难达到较低平均函数完成时间.例如,一个资源消耗量非常大的函数请求,即使其完成时间很短,也可能会导致很多可以并行执行且资源消耗很少的函数请求被阻塞,进而产生更长的平均函数完成时间.因此,函数的资源消耗情况也是函数调度需要考虑的关键因素.在资源消耗的度量上,FuncSched 选择采用函数占用内存作为表示函数资源消耗的中间量,其原因有2 个方面:这一方面是因为用户在提交函数给服务器无感知计算平台时,会指定用户函数需要的内存大小,该信息调度器比较容易被获取;另一方面,根据商用服务器无感知计算平台AWS Lambda 的测算[27],内存成本大约占服务器成本的40%,是服务器中最重要的资源之一. 3.3.3 FuncSched 调度算法整体流程 通过综合考虑每个函数的时间特征和空间特征,本文提出了一个新型的函数请求优先级指标P(k).对于使用函数容器j的函数请求k,P(k)计算为 基于这一优先级P[k],FuncSched 将优先调度P[k]最小的函数请求. 对于一个函数而言,它的整个生命周期如图2所示.首先在函数镜像提交时,FuncSched 的性能分析器会基于提交的函数镜像测算出该函数的冷启动时间D(j)、任务执行时间E(j)以及函数资源消耗量R(j),并将这些数据保存在函数性能数据存储库中.当该函数的函数请求到达时,调度器会从函数性能数据存储库中将该函数的时间特征、空间特征取出,并结合函数镜像缓存模块提供的空闲可用的函数容器数W(j)来综合算出该请求的优先级P(k).当该函数优先级最高时,调度器会触发函数服务器执行该函数.根据函数镜像实时情况,调度器会相应更新W(j)的值,并更新其待执行的函数请求的优先级P(k).最后,这些请求将根据优先级重新排序,具体算法如算法1 所示. 算法1.基于时间感知的函数调度算法. 3.3.4 调度示例 图3 展示了一个不同调度算法的示例.该示例中,一个包含2 个单位内存的函数服务器需要服务4 个依次到来的函数请求F1,F2,F3,F4,其中只有F4有已经预热的函数镜像,F1,F2占用一个单位内存,F3,F4占用2 个单位内存.D表示函数请求的冷启动时间,若函数请求为热启动则不存在D;E表示函数请求的执行时间.可以看到,FCFS,SJF 和FuncSched 的平均函数完成时间分别是7.25,9.25 和5.5.因为FuncSched考虑了缓存机制的影响和函数的空间特性,会优先执行F4函数请求,这样一方面减少了函数请求的等待时间,另一方面也增大了函数的热启动概率,进而实现了最优的平均函数完成时间.而FCFS,SJF 只考虑了函数请求的时间特性,严格要求函数请求按序执行,忽略了缓存机制和函数空间特性,效果均不理想. Fig.3 Example of different algorithms图3 不同算法的示例 3.3.5 函数执行公平性 当使用FuncSched 调度时,如果优先级P[k]较高的函数请求不断到达,可能会导致有些函数的饥饿.这是因为整个服务器无感知计算平台的资源可能会一直分配给不断到达的函数高优先级请求,而其他函数请求一直处于待执行状态. 对于这种状况,FuncSched 会维护一个更高的优先级队列Qstarve,并设置一个可调节的阈值StarveThreshold.当一个函数请求的等待时间F[k]s-F[k]a>StarveThreshold时,该请求将会被调入Qstarve.在Qstarve中,所有函数请求按照等待时间从大到小排序,队头函数请求将被FuncSched 调度器最先执行.当Qstarve为空时,剩余函数请求再按照函数请求优先级P[k]执行.依靠这一机制,FuncSched 能够避免低优先级函数请求的饥饿情况. 3.3.6 FuncSched 调度性能优化 每当空闲可用的函数容器数W(j)发生变化时,调度器就需要对所有依赖该函数镜像的函数请求更新其优先级P[k],并对这些函数请求进行重排序.这有一定的调度开销,尤其是在整个服务器无感知计算平台负载很大的情况下. 针对这一问题,一个关键观察是,对于同一函数,其所有待执行的函数请求优先级P(k)相同.因此,可以将这些函数请求按照依赖的函数镜像聚合在一起,形成按照时间排序的函数请求列表,在Qstarve为空时,FuncSched 通过对聚合后的集合按照优先级排序来进行调度.微软公司开源的服务器无感知计算平台实际用户函数执行数据集Azure Functions显示,大约20%的服务器无感知函数应用产生了99.6%的函数请求[3],所以待执行的函数请求所属的函数镜像是有限的.通过聚合函数请求能进一步降低函数请求的调度开销. 为了评估所提调度算法的性能,本文基于真实世界服务器无感知计算负载数据集,进行了一系列实验.本节首先对实验中算法的实现进行详细说明,然后介绍实验环境和数据集的选择,最后展示实验结果并进行深入分析. 本文基于开源的OpenWhisk 服务器无感知计算框架实现了原型系统.通过修改中央控制器和工作结点代码,实现了所提的基于时空特征的函数调度算法FuncSched,其能够兼容各种函数镜像缓存策略. 在中央控制器端,实现了基于时空特征的优先级调度器.当调度器接收到任务时,它将任务插入一个优先级队列中.当有空闲资源,包括空闲内存或者空闲的热容器时,调度器会从优先级队列中选取具有最高优先级的任务,并将其下发到工作节点进行执行.为了配合优先级队列的实现,实现了缓存容器统计组件以及函数冷启动和执行时间测量统计组件,以支持优先级的计算. 在工作节点端,在容器池的源代码中复现了3 种现有函数镜像缓存算法,分别是LRU 算法、Faas-Cache[4]的优先级驱逐算法、Serverless in the Wild[3]的基于历史统计的预热和驱逐算法.为实现Serverless in the Wild 的预热算法,修改了中央控制器与工作节点之间的通信机制,使系统能够根据算法预测结果及时预热和驱逐指定容器. 本文实验使用了一个由9 台机器构成的集群,其中1 台机器用作控制节点,另外8 台机器用作工作节点.每台机器都配置了Ubuntu 18.04 操作系统,并配备了硬件规格:1 个Xeon E5-2450 处理器(8 核,2.1 GHz)、16 GB 内存(4×2 GB RDIMMs,1.6 GHz)、4 个500 GB 7.2K SATA 硬盘.通过Kubernetes 在这9 台节点的集群上部署了OpenWhisk. 本文实验选取微软Azure Functions 数据集[3],该数据集为Azure Functions 服务器无感知计算平台上的函数样本,包含超过5 万个函数,每个函数信息包含函数调用记录、执行时间和内存占用大小. 为了评估所提调度算法在不同种类任务集上的性能,本文采取和文献[4]相同的采样方法,通过代表性函数采样、少见函数采样、随机函数采样3 种方法,采样出具有不同降采样比例的小样本.每个小样本集均包含200 个不同函数在5min 内的数千次到数万次调用.每个数据集分别选取从低到高多个不同的降采样比例采样,代表不同的负载量,以综合评判测试算法在不同负载状况下的性能.3 种采样方法的具体采样原理描述及其选取目标为: 1)代表性函数采样指以调用频率为标准,从数据集中调用频率分布的四分位分别进行采样,总计采样出200 个函数样本.这样的数据集既能包含较少调用的函数,又能包含频繁调用的函数,可以检验算法在典型工作场景下的性能. 2)少见函数采样指200 个最少调用的函数的随机样本,这样的函数常常导致冷启动,可以检验算法对冷启动的感知和利用. 3)随机函数采样指随机采样的200 个函数样本. 每个样本集在不同降采样比例下的总函数调用次数和调用频率如表2 所示. Table 2 Total Invocation Amount and Frequency in Traces表2 样本数据集中函数调用总次数和频率 本节说明评估FuncSched 算法综合性能的实验指标和对照组,展示实验结果并对所提算法在不同场景下的性能进行分析. 采取平均函数完成时间作为性能指标.函数完成时间包括排队时间、冷启动时间、执行时间3部分. 在对照算法方面,实验选取OpenWhisk 默认的FCFS 算法作为对照组. 综合性能实验在代表性函数采样、随机函数采样和少见函数采样3 个数据集上进行,计算了Func-Sched 调度算法在各参数下的平均完成时间加速比,即以对照算法的平均完成时间除以FuncSched 算法平均完成时间.在综合性能的各项实验中,均采取了LRU 缓存策略作为函数镜像缓存策略. 图4 展示了综合性能实验的结果.可以看到,在各个数据集上,FuncSched 均有高达2~6 倍的加速比. Fig.4 Average completion time on different traces with LRU algorithm图4 结合 LRU 算法在不同数据集上的平均完成时间 如图4(a)所示,在代表性函数采样数据集上,当降采样比例为0.6 时,可以取得2.7 倍的加速比.当降采样比例为0.7 时,加速比提升到3.3 倍.在典型场景下,FuncSched 能实现较高加速比,能够大幅提升系统在大多数场景下的性能. 如图4(b)所示,即使是在随机函数采样数据集上,系统也取得了高达2.2 倍的加速比.随机函数采样往往包含大量执行时间和频率均较短的函数,系统整体负载偏低,FuncSched 仍然能够取得较大的性能提升,可见FuncSched 算法能够普遍适用于服务器无感知计算的各个工作场景. 如图4(c)所示,在少见函数采样数据集上的加速比最为显著.当降采样比例达到0.10 时,FuncSched能实现5 倍的加速比.当降采样比例达到0.20 时,加速比进一步提高至6 倍.对于服务器无感知计算平台,由于函数请求特征差别较大,大量函数请求只需消耗较少资源,少数函数请求消耗大量资源,冷启动时间较长.故能实现在该类少见函数采样上的性能优化,对于整体系统性能提升至关重要. 下面分析平均完成时间随降采样比例增加的变化趋势.在图4 中可以看到,随着降采样比例的增加,FuncSched 的平均完成时间仅缓慢增加.相比之下,FCFS 算法在超过一定降采样比例后,平均完成时间迅速增加,使其性能显著差于FuncSched.这在代表性函数采样和少见函数采样数据集上效果尤为明显.在代表性函数采样数据集上,当降采样比例为0.4 时2 种算法性能基本一致;当降采样比例为0.5 时FuncSched 开始优于FCFS;当降采样比例达到0.6 时,FCFS 算法下的平均完成时间就已经达到FuncSched算法的3 倍以上.同样地,在少见函数采样数据集中,降采样比例为0.05 时,两算法性能基本一致;当降采样比例达到0.10 时,FCFS 算法的平均完成时间达到FuncSched 算法的3 倍以上.故FuncSched 能够承受远多于FCFS 算法负载,同时保持相对较低的平均完成时间. 为了进一步对比FuncSched 和一些在操作系统等领域广泛应用的经典调度算法的区别,本文在代表性函数采样数据集上,分别采取不同参数进行了实验,记录了函数请求的平均完成时间.除了FCFS外,实验比较了其余3 种经典调度算法. 1)时间片轮转调度(round robin,RR)算法.这是任务调度系统常用的算法,每个任务每次被调度时获得至多固定长度的时间片.本文实验选取的时间片为100 ms. 2)最短剩余时间优先(shortest remaining time first,SRTF)算法.相比FuncSched 算法,SRTF 算法只考虑时间特征,不考虑空间特征.该算法每次调度剩余执行时间最短的函数请求执行,调度器在每个函数请求执行至多100 ms 后决定是否抢占. 3)最小运行时内存优先(smallest runtime memory first,SRF)算法.相比FuncSched 算法,SRF 算法只考虑空间特征,不考虑时间特征,每次调度选取占用内存最小的函数请求. 图5 展示了FuncSched 与这些经典调度算法的实验对比结果.可以看出,由于函数冷启动开销较大,带有抢占的算法,即RR 算法和SRTF 算法,会因为频繁抢占带来频繁的冷启动开销,性能差于Open-Whisk 原始的FCFS 算法.另外,只考虑空间特征的算法SRF 因为只考虑了函数的单一维度特征,性能差于FuncSched 算法.故可以说明综合考虑空间特征和时间特征能使得服务器无感知计算调度器获得更优的性能. Fig.5 Average completion time of FuncSched and classical scheduling algorithms图5 FuncSched 和经典调度算法的平均完成时间 本节通过分析平均完成时间的各个组成部分,分析FuncSched 算法相对于FCFS 算法得到大比例性能提升的原因.函数完成时间包括排队时间、冷启动时间和执行时间.由于对于同一个数据集的同一个降采样比例,平均执行时间相同,平均排队时间和平均冷启动时间不同,故本节对后两者进行分析. 图6 展示了FuncSched 和对照算法在不同缓存策略下平均排队时间的对比.数据集选取为代表性函数采样,降采样比例为0.7.从平均排队时间上看,在Serverless in the Wild 的缓存策略下,FuncSched 减少了92.5%的排队时间,而在排队时间最低的 LRU缓存策略下,FuncSched 也减少了83.9%的排队时间.可见FuncSched 通过优先调度执行时间较短、内存消耗较少的函数,显著减少了函数请求的平均排队时间. Fig.6 Average queuing time of different policies图6 不同策略的平均排队时间 图7 展示了FuncSched 和对照算法在不同缓存策略下平均冷启动时间的对比.数据集选取为代表性函数采样,降采样比例为0.7.平均冷启动时间减少了高达12.5%.在FuncSched 中仍存在的冷启动通常包括2 部分:一部分是因为调用十分稀少导致缓存性价比较低,故在调用时的冷启动是最佳选择;另一部分是因为调用频率很高,故需要维护大量容器尽快执行该类函数的请求,以实现低服务延时,这些较大数量的容器初始化时就会有相应的冷启动开销也是不可避免的.故可知FuncSched 以降低平均任务完成时间为目标,把冷启动时间考虑在优先级内,优先执行热启动函数,从而减少冷启动发生率,使得冷启动时间几乎减少到最低值. Fig.7 Average cold start time of different policies图7 不同策略的平均冷启动时间 为了展现FuncSched 对于系统中单个函数的性能提升情况,实验统计了所有函数每次调用的完成时间.图8 展示了函数完成时间的累计分布函数图.这是在代表性函数采样数据集、降采样比例为0.7 下的实验结果.可以看出,FCFS 算法有大量函数完成时间显著高于FuncSched 算法.FCFS 算法有25.9%的函数完成时间超过100 s,大量函数请求经历高完成延迟.相比之下,FuncSched 完成时间超过100 s 的只有5.2%,保持了较高的响应速度.这表明FuncSched相对于原始OpenWhisk 在性能方面对于大部分函数都能使其性能明显提升. Fig.8 Function completion time CDF图8 函数完成时间累积分布函数 服务器无感知计算的函数请求有时存在服务级别目标(service level objective,SLO),常见的例如延迟目标.图9 展示了FCFS 算法和FuncSched 算法在不同SLO 下的任务完成率,FuncSched 算法能够将任务完成率提高27%~41%.由此可见,FuncSched 可以提升函数整体SLO 达成率,不会导致运行时间较长的函数过多违背SLO. Fig.9 Function finish rate under SLO图9 函数的 SLO 达成率 FuncSched 能够兼容不同的函数镜像缓存策略.在各个函数镜像缓存策略下,FuncSched 相较于FCFS都能大幅减少函数请求的平均完成时间.为了验证这一点,本文在3 个数据集上进行了一系列实验,将FuncSched 和FCFS 与LRU,FaasCache 和Serverless in the Wild 这3 种函数镜像缓存策略相结合,并分别测量了平均完成时间.实验在代表性函数采样数据集上进行. 图10 展示了在3 个数据集上,FuncSched 和FCFS采用不同缓存策略以及不同降采样比例下的平均任务完成时间.在3 种缓存策略下,FuncSched 相较于FCFS 均有高达4~5 倍的加速比.在平均完成时间的绝对值上,当降采样比例不高于0.7 时,FuncSched 都能将平均完成时间保持在15 s 以内,而FCFS 的平均完成时间会迅速上升至60 s 以上.实验结果表明Func-Sched 能够兼容各种函数镜像缓存策略,并能显著降低函数平均完成时间. Fig.10 Average completion time under different cache policies图10 不同缓存策略下的平均完成时间 本文研究了服务器无感知计算场景下的函数调度问题.通过对服务器无感知计算场景的分析和数学建模,提出了基于函数时空特征的服务器无感知计算函数调度算法FuncSched.FuncSched 通过分析函数的时间特征和空间特征,并且综合考虑函数自身逻辑和服务器无感知计算平台函数镜像缓存机制的影响,实现了对函数性能的精准评估.基于函数的时空特征,FuncSched 通过调度算法避免了函数请求的队头阻塞现象,进而降低了平均函数完成时间.针对FunSched 原型系统的实验结果表明,FuncSched 能够在各种函数请求场景中显著降低平均函数完成时间,并且兼容各种服务器无感知计算函数镜像缓存算法. 未来的工作包括3 个方面:1)考虑将函数运行的生命周期分为函数拉取和函数执行等多阶段进行异步调度,并考虑预测函数调用时间并预先异步拉取函数镜像等机制和更细粒度的并发影响[43];2)研究本地函数镜像缓存的预取策略,将预取策略与调度算法进行协同设计,进一步优化函数完成时间;3)将函数调度扩展到函数工作流,根据函数工作流的函数依赖关系,设计面向函数工作流的函数调度算法,优化函数工作流完成时间. 作者贡献声明:金鑫提出研究思路和算法设计;吴秉阳、刘方岳和章梓立负责实验设计和完成实验;贾云杉负责文献调研;所有作者都参与了文章撰写和修改.3 服务器无感知计算调度算法
3.1 服务器无感知计算调度的挑战
3.2 现有服务器无感知计算调度的局限性
3.3 基于时空特征的函数调度算法FuncSched
4 实验结果与分析
4.1 调度算法实现
4.2 实验环境与数据集
4.3 综合性能实验与分析

4.4 性能提升原因分析

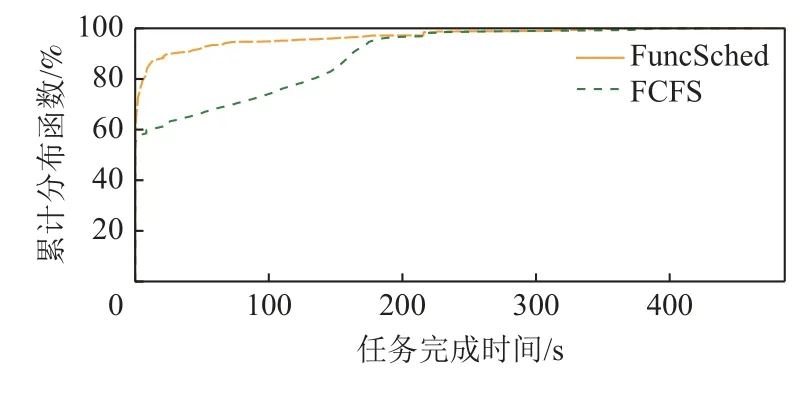
4.5 函数完成时间分布
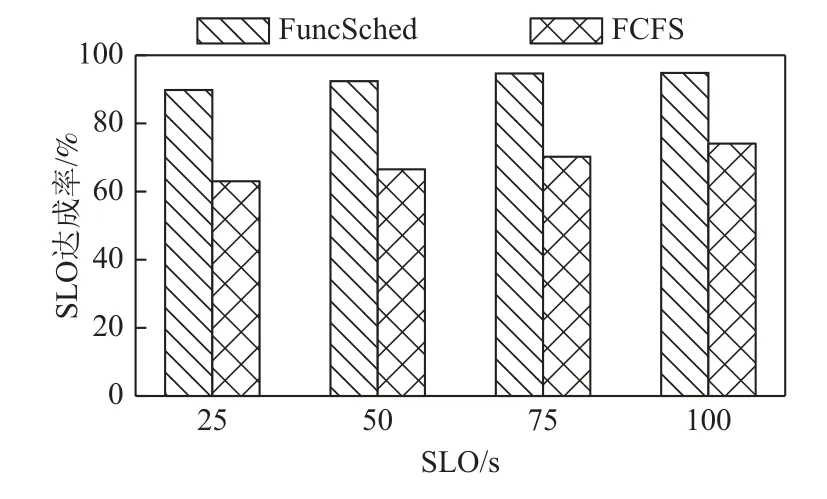
4.6 缓存策略兼容性

5 总结
