开源数据的质量评估指标体系研究*
2023-09-22陈天莹
李 霄,陈天莹
(中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引 言
开源数据是指在开放环境下,通过合法方法从公开资料中获取的数据,数据可被任何人自由访问、重复使用与共享,没有版权、专利或其他限制。
随着互联网、大数据技术的快速发展,网络环境中的开源数据量井喷式增长,占据数据体量的95%。开源数据具备类型多样、及时性、开放性、海量多维等特点,为开源数据的深度分析与挖掘提供了坚实的数据基础。但是开源数据的多源异构、无组织管理、碎片化等特点,让人们无法对数据进行多维度评估,使得数据本身的不确定性、欺骗性等问题尤为突出,给网络安全威胁检测、网络攻击溯源、重大公共事件处置等带来了严峻挑战。
当前,开源数据主要面临的质量问题如下:
(1)缺乏开源数据质量评估体系。业界主要从通用质量评估角度,考虑数据的完整性、一致性、及时性和准确性等方面的质量,忽略了开源数据的不确定性、欺骗性等特点,未形成开源数据完整的质量评估体系。
(2)数据质量问题识别困难。大数据环境下,开源数据来源多样、数据源规格不统一,导致数据的元数据描述及理解错误、数据真假难辨,数据质量问题难以识别。
(3)数据质量评估效果难以量化。开源数据质量问题不尽相同,不同质量维度在其整体效果评估中权重不同,很难用数值进行多维度量化。
(4)数据质量问题无法有效闭环,溯源困难。业内的数据质量评估流程是通过定义数据质量规则,发现数据质量问题并告警,但未对质量问题进行持续跟踪、闭环与回溯,无法形成良性循环,提升整体数据质量。
本文研究开源数据质量评估体系,构建全面实用的开源数据质量维度、评估理论、跟踪方法,帮助增加开源数据的实效性、完整性、关联性,为开源数据分析与使用提供坚实的数据基础,支撑舆情监测、威胁分析和网络安全态势感知等业务应用。
1 国内外现状
开源数据质量评估是指对开源数据集中的数据进行评估和验证,以确保其准确性、完整性和一致性。国内学术界在开源数据质量评估方面的研究相对较少,大部分研究还停留在数据质量评估框架和方法的探讨阶段。例如:2019 年,邹培等人[1]借鉴全面质量管理原则与情境关联思路,针对开源数据本身具有的领域特征,提出了基于过程、情境关联和领域知识集成三位一体的开源数据评估模式,并以实际案例对此模式的实施进行具体阐述;2020 年,李晓彤[2]针对数据质量水平参差不齐,重创造轻管理、重数量轻质量、重开放轻利用的问题,分析了国内外数据质量评价框架并构建数据质量评价框架;2022 年,汪春播等人[3]提出基于元数据的开放政府数据质量自动评估系统,研究基于元数据的林业开放政府数据质量的自动获取、实时监测和定期评估,为一般性开放政府数据质量评估提供借鉴和参考。
在国外,开源数据已经成为一个战略性的数据资源,对开源数据质量评估的研究比较丰富。例如:2016 年,Ackerman 等人[4]对经常用于社会科学分析的开源事件数据集的来源和可信度进行评估与分析,他们开发了一个样本来源评估模式,目的是在案例、来源和变量层面对开源事件数据的有效性进行测量;2016 年,Van Schalkwyk 等人[5]考虑了开放数据的供应、需求和使用,表明开源数据有可能改善大学作为公共机构的管理方法。2018 年,Monika 等人[6]研究了链接开源数据领域的质量评估方法;2018 年,Blasio 等人[7]研究了法国、意大利和英国的政府开源数据领域的质量评估理论;2021 年,Šlibar等人[8]阐述了开源数据质量评估的重要性,对与开源数据相关的研究论文中使用的数据质量维度、子维度和度量进行了概述,同时列举了多个领域的开源数据评估研究方法。
综上可知,开源数据质量是数据分析挖掘的基础,如何结合开源数据特征,探索开源数据质量评估体系、评估流程,提升开源数据质量,为开源数据的分析挖掘提供可靠性高、准确度高的数据基础,是开源数据工程亟须解决的问题。
2 开源数据质量评估体系
开源数据质量评估体系是开源数据质量评估能够落地的前提。从开源数据特征、数据内容、效能作用等角度出发,构建开源数据质量检测指标和评估体系,满足不同的数据质量评估需求。数据质量评估体系包括数据置信度评估、数据核查评估、数据价值度评估、数据综合质量评估和专采数据核准5 大类型,由数据及时性、数据完整性、数据波动性、数据唯一性、数据规范性、数据使用度、数据缺失性、数据相似性、数据新鲜度、数据覆盖度10 个维度组成,通过多维度组合完成相应的质量评估。开源数据质量评估体系如图1 所示。

图1 开源数据质量评估体系
2.1 开源数据质量评估体系
开源数据质量评估体系基于质量检测指标,面向网络威胁检测、威胁溯源分析、重大事件真假研判、重要目标画像生成等不同的应用场景,形成数据置信度评估、数据核查评估、数据价值度评估、数据综合质量评估和专采数据核准5 大类型。
2.1.1 数据置信度评估
数据置信度评估主要针对开源数据来源多、类型庞杂、数据内容冲突等因素引起的数据真实性、可用性等问题,结合数据缺失度、数据规范性、数据新鲜度、多源数据间的相似性等维度,构建数据置信度模型,计算数据置信度。
2.1.2 数据核查评估
数据核查评估主要是对上级机关下发的数据清单以及业务部门提出的数据需求进行存量数据的核查与评估。数据核查评估通过构建存量数据的“数据指纹”结合数据缺失性、完整性、新鲜度、相似性、及时性等维度,对开源数据进行监测,生成数据核查评估分析结果。
2.1.3 数据价值度评估
数据价值度评估主要是在数据服务选择阶段和数据使用阶段对数据价值进行评估。其中,数据服务选择阶段主要是为用户提供数据的对比,智能化、多维度地评估最优质量数据,为数据选择提供决策依据,确保获取或者购买开源数据服务达到最优。一般采用镜像开源样例数据,从覆盖度、新鲜度、规范性、完整性、及时性、唯一性等维度与存量数据比对,综合评价价值度;数据使用阶段主要是为用户梳理存量数据资源的使用情况,确保数据资源最优的服务与业务分析工作的支撑,一般采用接口、共享库两种方式,深度分析数据的使用频率、使用范围、使用者等,构建综合评价模型,生成数据的使用价值度评估分析结果。
2.1.4 数据综合质量评估
数据综合质量评估提供通用的数据质量评估模型,可设置每类数据的不同质量检测指标的权重,生成数据综合质量评估模型,得到综合质量评分。
2.1.5 专采数据核准
专采数据核准主要面向网络安全的特殊业务要求,例如,对特定数据项进行高频开源数据采集,实时检测数据是否按照采集要求来进行数据采集,确保业务所需开源数据的高可用性和正确性。
2.2 开源数据多维质量检测指标构建
开源数据多维质量检测指标在全国信息技术标准化技术委员会的数据质量评价指标指导下,在规范性、完整性、准确性、一致性、及时性等维度的基础上,结合开源数据的特征,扩充缺失度、新鲜度、唯一性、波动性和使用度,形成全面、多维的指标检测体系。
2.2.1 数据及时性
数据及时性是指开源数据的产生、传递、处理等过程的时效。主要从数据采集及时性、数据入库及时性、数据推送及时性以及数据治理及时性4 个方面来评估数据的及时性,涵盖了数据的产生、采集、推送、存储、治理全生命周期的评估。
2.2.2 数据完整性
数据完整性是按照数据规则要求,数据元素被赋予数值的程度。主要包括数据空置率、数据字段完整度、数据内容完整度。其中,数据空置率是开源数据字段为空所占该类型数据整体的比例;数据字段完整度是开源数据字段与原有数据字段的数量是否一致,是否存在新增字段或原来不存在的字段;数据内容完整度是指数据字段的内容是否与字段本身的类型和含义一致。
2.2.3 数据波动性
数据波动性是指开源数据在一定时间范围内的变化情况。主要包括数据分类波动性和字段波动性。其中,数据分类波动性是指统计某一类型数据的数据采集量、采集频率及采集周期的变化情况;字段波动性是指统计某一类型数据的某些字段的数据采集量、采集频率及采集周期的变化情况。
2.2.4 数据唯一性
数据唯一性是指开源数据内容和含义的唯一性。主要包括数据重复率和字段一致性。其中,数据重复率是指同一数据源、同一类型的数据及字段的重复比例;字段一致性是指数据内容与字段的含义存在冲突或相同内容的字段的数据含义存在歧义。
2.2.5 数据规范性
数据规范性是指数据符合数据标准、数据模型、业务规则、元数据或权威参考数据的程度。主要包括文件数据接入规范性、数据流接入规范性、数据库接入规范性。其中,文件数据接入规范性是指文件接入过程中的各类规范性问题检测,如文件系统连接失败、文件读取失败、文件目录为空、文件格式错误等;数据流接入规范性是指数据流接入过程中的各类规范性问题,如消息中间件连接失败、获取topic 失败、topic 配置异常等;数据库接入规范性是指数据库接入过程中的各类规范性问题,如数据库连接失败、字段获取失败、数据写入失败等。
2.2.6 数据使用度
数据使用度是指根据数据的使用频度来衡量数据的使用价值。数据使用度需要借助数据接口或者数据使用日志分析的方式进行使用度检测。
2.2.7 数据缺失性
数据缺失性是指结合历史数据评价样例数据的缺失情况。主要包括字段缺失性和数据内容缺失性。其中,字段缺失性是对比样例数据和历史数据的字段项是否存在缺失的情况;数据内容缺失性是对比样例数据和历史数据的内容是否存在缺失的情况。
2.2.8 数据相似性
数据相似性是指样例数据与历史数据的相似程度。主要包括字段相似性和数据内容相似性。其中,字段相似性是指样例数据和历史数据的字段之间的相似程度;数据内容相似性是指样例数据和历史数据的内容之间的相似程度。
2.2.9 数据新鲜度
数据新鲜度是指样例数据与历史数据产生事件的比较。主要包括时间新鲜度和内容新鲜度。其中,时间新鲜度是对比样例数据和历史数据的产生时间,判断样例数据的时间是否晚于历史数据;内容新鲜度是对比样例数据和历史数据的内容,判断样例数据的内容是否比历史数据丰富。
2.2.10 数据覆盖度
数据覆盖度是指计算样例数据内容覆盖历史数据的程度。
3 开源数据质量评估流程
开源数据质量评估流程是在开源数据评估体系的基础上,通过开源数据源配置、多维数据质量检测模型配置、数据质量评估模型配置、数据质量跟踪与闭环、结果反馈与优化等流程,实现开源数据质量评估体系落地。主要流程如图2 所示。
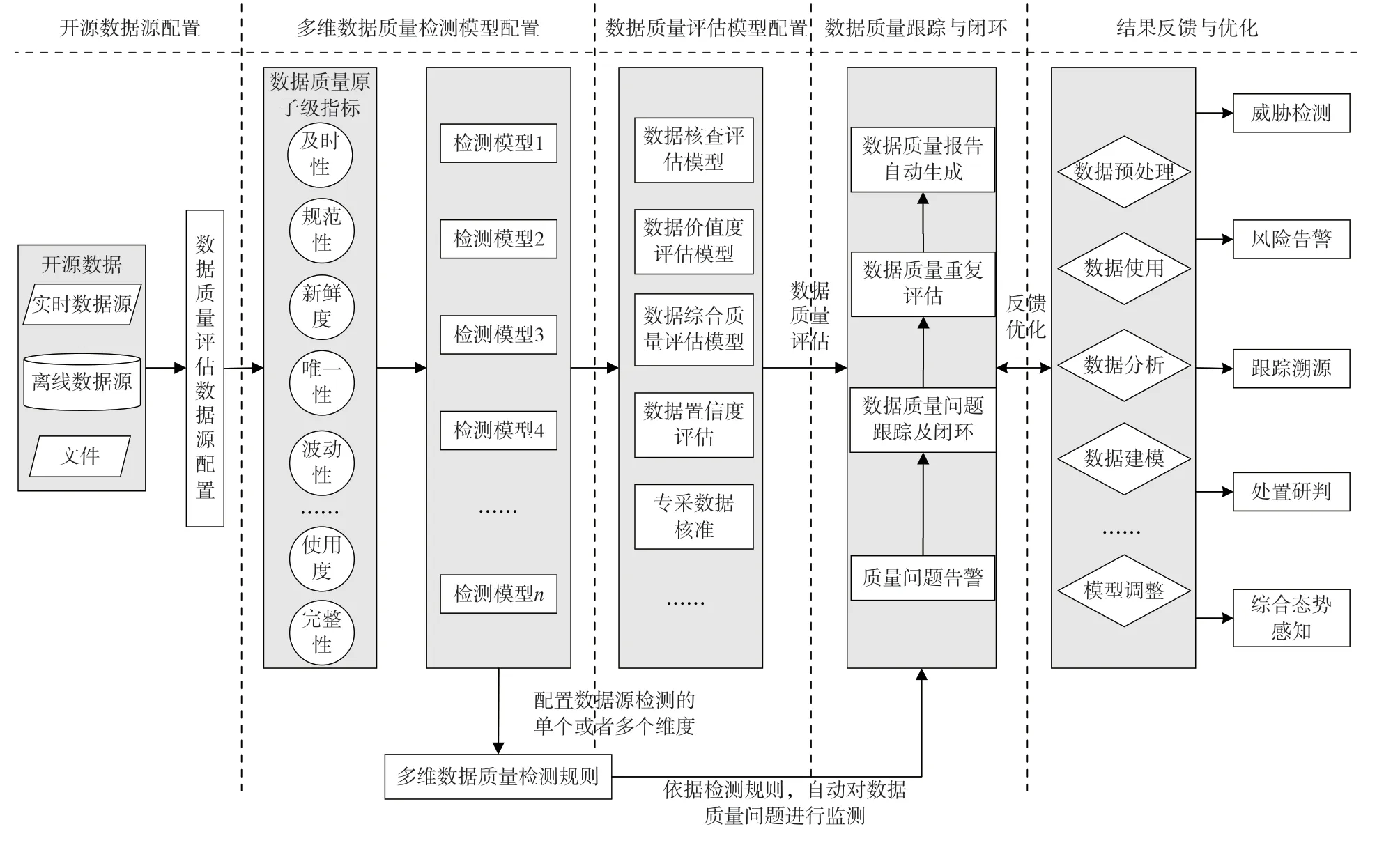
图2 开源数据质量评估流程
(1)开源数据源配置。配置开源数据源的基础信息,实现实时、离线与文件类数据源的接入,自动对数据源进行语义分析,提取数据指纹。
(2)多维数据质量检测模型配置。基于数据质量原子级指标,结合不同网络安全业务需求,构建适用于不同业务的数据质量检测模型。
(3)数据质量评估模型配置。基于开源数据质量评估的安全业务需求,组合不同的数据质量检测维度,形成数据核查评估、数据价值度评估、数据综合质量评估、数据置信度评估和专采数据核准等不同类型的质量评估模型。
(4)数据质量跟踪与闭环。依据策略或规则自动检测数据质量问题,实时告警,持续对数据质量问题进行跟踪与闭环,综合评估数据质量,为数据质量打分,并自动生成数据质量报告。
(5)结果反馈与优化。为数据使用各环节提供质量结果,系统依据结果反馈,设备自动对数据质量评估结果进行动态计算,优化数据质量评估效果。
4 结 语
目前,我国的开源数据质量研究尚处于初级阶段,在理论、方法和技术上还需深入地探索和突破。生成式大模型作为新一代的人工智能技术,数据主要来源于开源数据,一旦数据存在错误,就会导致大模型输出的准确性和公正性存在偏差,带来大量的虚假信息,严重干扰分析、研判和处置结果。因此,亟须将大数据、人工智能与开源数据质量评估体系深度结合,提升开源数据的质量,使其真正成为网络安全积极防御的倍增器。
