基于深度强化学习的风储合作决策方法
2023-09-21翟苏巍李文云邱振宇张新怡侯世玺
翟苏巍,李文云,邱振宇,张新怡,侯世玺
(1.中国南方电网云南电网有限责任公司电力科学研究院,云南昆明 650217;2.中国南方电网云南电力调度控制中心,云南昆明 650011;3.河海大学物联网工程学院,江苏南京 210098)
0 引言
随着全球资源短缺以及人类不断增长的生活需求,世界各国积极呼吁进行节能减排,同时大力开发与研究清洁低碳能源,进一步加速全球能源转型[1-2]。常用清洁能源有风能、太阳能以及潮汐能等,风力发电凭借其资源丰富、成本低廉、技术相对成熟等优势,被认为是代替传统不可再生能源的首选[3-5]。但风能与环境因素有着极大的相关性,使其发电呈现随机性、不可控性、波动性等特点,严重影响电力系统的功率平衡,威胁电网的稳定安全运行[6-9]。研究表明,在风电场配备具有调节能力的储能系统可缓解以上问题,由此促使风储合作系统成为近年来的研究热点[10-11]。
目前,无需建立精确模型的强化学习算法在电力系统实时优化领域应用广泛[12-16]。在风储合作决策方面,国内外学者进行了初步探索[17-21],但仍存在一些问题:(1)现有风储合作系统研究几乎未考虑柔性负荷;(2)对基于强化学习的风储合作决策方法缺乏深入研究。研究表明,在风储合作系统中,对需求侧柔性负荷进行适当管理可以显著提高合作收益[22-24]。此外,现有研究仅采用深度Q 网络(Deep Q-Network,DQN)等传统方法,收益有待提升[25-27]。因此,有必要对现有深度强化学习方法进行优化以进一步提高风储合作系统的应用价值。
综上所述,针对最大化风储合作收益问题,提出一种基于深度强化学习的风储合作决策方法。研究的创新之处在于:构建了一种考虑恒温可控负荷和居民价格响应负荷的新型风储合作系统,提出竞争双深度Q 网络(Dueling-Double-Deep QNetwork,D3QN),并运用D3QN 对风储合作系统进行优化决策。算例分析表明所提算法在提高风储合作系统收益方面具有显著的优势。
1 风储合作系统
本文设计的风储合作系统如图1 所示。

图1 风储合作系统Fig.1 Wind-storage cooperative system
由图1 可知,风储合作系统包括外部大电网、风电场(Wind Farm,WF)、居民价格响应负荷(Residential Price-responsive Load,RPL)、恒温可控负荷(Thermostatically Controlled Load,TCL)、储能系统(Energy Storage System,ESS)、能源控制器(Energy Controller,EC)。其中,EC 负责TCL 的开关控制、ESS 的充放电控制以及系统与外部大电网之间的电能交易控制。
1.1 系统电源
风储合作系统电源包括外部大电网、WF、ESS。考虑到风电的间歇性和不可控性,单独使用WF 无法平衡系统内电能供需关系,因此系统需接入外部大电网。风电短缺时,外部大电网可为系统提供电能;风电过剩时,外部大电网也可接收多余电能。为体现场景真实性,向外部大电网采购或卖出电能均采用电力市场t时刻上调电价和下调电价。
传统风储合作系统往往采用风力发电数学模型模拟真实风电场,但由于风电场运行场景多变,数学模型往往难以精确描述。目前,世界范围内芬兰的风储合作系统发展较为成熟,需求侧柔性负荷相关参数完善,为了尽可能贴合实际风电场的应用需求,测试系统的真实可用性,本文使用芬兰某风电场1 a 的实际发电数据来进行研究[23]。
社区储能系统作为第三方投资的集中式独立储能电站,能够将分散的电网侧、电源侧、用户侧储能资源整合并优化配置,实现储能资源统一调度,且可实施精准充放电控制,提高电力系统柔性调节能力。基于社区储能系统的优点,为合理优化用能配置、降低用能成本、提高经济效益,本文研究均采用社区储能系统,其ESS 模型为:
t时刻ESS 的荷电状态(State of Charge,SOC)用物理量表示,其表达式为:
式中:Bmax为ESS 最大存储电能。
EC 实施ESS 充放电控制流程可概括为2 部分:(1)EC 给出充电信号后,先参考值以判断ESS 是否可充电,再根据实际情况进行充电,将过剩电能出售给外部大电网;(2)EC 给出放电信号后,ESS 再次对相关条件进行验证以判断操作可行性并释放所需电能,若ESS 出现电能短缺,则由外部大电网提供差额部分电能,EC 来支付相应采购费用。
1.2 居民负荷
1.2.1 恒温可控负荷
TCL 因体量大、控制灵活、能量热守恒等特点,成为电网重要的柔性资源。假设绝大多数居民家庭均配备空调、热水器、冰箱等TCL,且每个TCL 均配备独立控制器。独立控制器首先从TCL 聚合器接收动作指令,然后验证温度约束以修改动作,从而将温度保持在可接受的范围内。t时刻第i个TCL 修改后的动作指令为:
1.2.2 居民价格响应负荷
假设居民每日用电量由居民日常基础用电量和受电价影响的柔性负荷组成,其中柔性负荷是指在使用时间上存在一定自由度的用电设备,能够在用户可接受的时间范围内提前或延后运行。在居民价格响应负荷模块中,t时刻第h个居民用电负荷为:
2 风储合作决策
2.1 双竞争深度Q网络
现有研究将DQN 和状态行为价值网络(State Action Reward State Action,SARSA)等强化学习策略用于风储合作决策。DQN 和SARSA 的缺点为:(1)DQN 和SARSA 均采用同一网络生成期望值和最大期望值,导致神经网络的时序差分目标不断变动,不利于算法的收敛以及神经网络参数的最终稳定;(2)在训练前期模型不够稳定时使用最大期望值可能会导致EC 对某一动作的预期收益估计存在偏差,进而做出错误决策,无法实现最优决策。针对以上2 点问题,本文使用D3QN 算法对风储合作系统进行优化求解。与DQN 和SARSA 相比,D3QN 的区别在于:
1)参考双深度Q 网络(Double DQN,DDQN),构造2 个结构相同的神经网络分别作为估计网络和目标网络。估计网络用于选择对应最大期望值的动作,其网络参数不断更新;目标网络用于计算期望值的目标值y,其网络参数固定不变,但每隔一段时间会更新为当前估计网络参数的值。
2)参考竞争深度Q 网络(Dueling DQN,DDQN)对深度神经网络结构进行调整,将输出端划分为表征当前状态好坏的“状态—价值”函数V和衡量当前状态下各个动作额外价值的优势函数W。D3QN中Q 网络的输出端函数F由V和W输出的线性组合组成,其表达式为:
2.2 风储合作决策要素定义
为运用深度强化学习方法解决风储合作决策问题,需将风储合作系统转换为离散马尔科夫决策模型,采用EC 根据系统各个模块的反馈信息做出相应指令动作。对马尔科夫决策模型各要素进行3项定义:
1)状态空间。状态空间由EC 在t时刻决策时所使用的信息组成,包括可控状态分量、外部状态分量和时间相关分量。可控状态分量包括EC 能够直接或间接影响的所有变量,如和δt。外部状态分量由EC 无法控制的所有变量组成,如t时刻温度Tt、风力发电量Et及上调电价Mupt。时间相关分量包含模型中与时间强相关的信息。ECt时刻状态空间st表达式为:
2)动作空间。动作空间包括TCL 动作空间aTCL、电价动作空间apri、电能短缺动作空间aD和电能过剩动作空间aK,且aTCL,apri,aD,aK均为无量纲量。ECt时刻动作空间at表达式为:
3)奖惩函数。深度强化学习算法的目标是最大化奖励函数。对风储合作系统而言,为使售电商收益最大化,惩罚函数为风力发电成本和电能传输成本之和,奖励函数为运营毛利,即t时刻出售给负荷和外部大电网电能所获收入It减去惩罚函数。因此,t时刻奖励函数Rt和惩罚函数Jt为:
3 算例分析
为验证本文所提D3QN 算法的优越性,将DQN,SARSA,D3QN 3 种算法进行对比分析。研究算例所采用计算机配置为Windows11,Python3.8,Tensorflow1.14,CPU 为AMD R7-5800H,GPU 为RTX3060,内存为16 GB。ESS 参数、WF 参数、外部大电网参数、负荷参数、算法参数分别如表1—表5 所示。

表1 ESS参数Table 1 ESS parameters

表2 WF参数Table 2 WF parameters

表3 外部大电网参数Table 3 External large power grid parameters

表4 负荷参数Table 4 Load Parameters

表5 算法参数Table 5 Algorithm parameters
3.1 惩罚函数曲线
惩罚值由风力发电成本、从外部电网购入电力成本、电力运输费用构成。DQN,SARSA,D3QN 算法的惩罚函数曲线对比如图2 所示。其中,损失值为无量纲量。
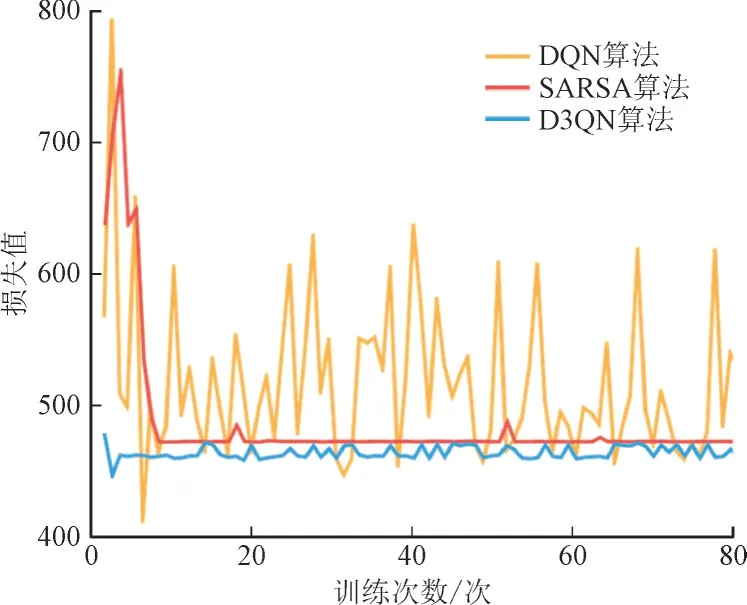
图2 DQN,SARSA,D3QN算法的惩罚函数曲线对比Fig.2 Comparison analysis of penalty function value curves using DQN,SARSA and D3QN
由图2 可知,3 种算法的惩罚值均随着训练次数的增加而减少并逐渐收敛,对比发现D3QN 算法的收敛性能较其他2 种算法表现更好。这是因为DQN 和SARSA 算法均采用同一网络生成期望值和最大期望值,不利于算法收敛,而D3QN 使用2 个Q网络来分别计算期望值和最大期望值,直接减少了相关性,进而提高了算法收敛能力。
3.2 奖励函数曲线
DQN,SARSA,D3QN 算法的奖励函数曲线对比如图3 所示。其中,奖励值为无量纲量。
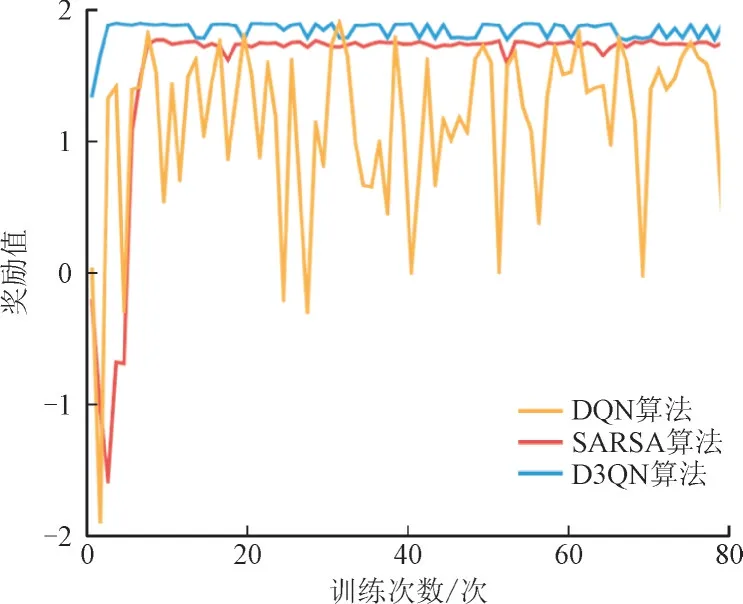
图3 DQN,SARSA,D3QN算法的奖励函数曲线对比Fig.3 Comparison analysis of reward function value curves using DQN,SARSA and D3QN
由图3 可知,DQN 算法的奖励值波动较大且奖励值普遍偏小,SARSA 算法的奖励值虽然趋于稳定,但奖励值一直低于D3QN 算法。对比发现对于不同的训练次数,D3QN 算法的奖励值均高于SARSA 算法和DQN 算法,说明D3QN 算法更优。这是因为D3QN 的输出端包含衡量各动作额外价值的优势函数,有利于提高奖励值。
3 种算法训练结果如表6 所示。
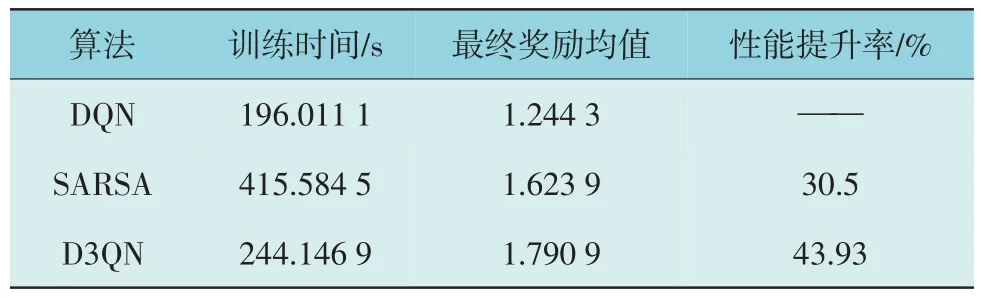
表6 3种算法训练结果Table 6 Training results of three algorithms
由表6 可知,D3QN 算法的最终奖励均值高于其他2 种算法,对比发现基于D3QN 算法的风储合作系统整体性能得到了明显的提升。
3.3 收益对比分析
为对3 种算法性能的优劣进行更直观的呈现,选取10 d 数据来展示3 种算法所获每日收益。10 d内每日收益对比如图4 所示。

图4 10 d内每日收益对比图Fig.4 Comparison analysis of daily profit for 10 days
由图4 可知,10 d 内SARSA 算法与D3QN 算法的每日收益都高于DQN 算法,且10 d 中有9 d D3QN 算法的表现均优于SARSA 算法。说明基于D3QN 的风储合作决策算法可充分协调风电、储能、外部大电网、恒温可控负荷、居民价格响应负荷,在提升系统收益方面具有显著优势。
4 结语
本文针对最大化风储合作收益问题,提出一种基于深度强化学习的风储合作决策算法。算例分析表明,所提方法不仅避免了次优策略选择问题,且相比传统深度强化学习算法,显著提高了风储合作系统收益。由于深度强化学习算法学习过程中训练时间较长且对大量训练样本的依赖性较强,现阶段该方法在实际工程中的应用仍存在一些挑战。在未来的研究工作中仍需进一步探索解决,以便更好地将深度强化学习应用到实际系统中。
