基于知识蒸馏的夜间低照度图像增强及目标检测
2023-09-21苗德邻刘磊莫涌超胡朝龙张益军钱芸生
苗德邻,刘磊,莫涌超,胡朝龙,张益军,钱芸生
(南京理工大学 电子工程与光电技术学院,江苏 南京 210018)
引言
近些年来随着深度学习理论的发展以及计算机计算性能的提升,目标检测和追踪技术已经广泛应用于智能监控、自动及辅助驾驶、信息安全系统等诸多领域;但是这些技术在现实环境下仍然面临很多问题,由于图像通常无法在最优的光条件下获取,往往会受到不可避免的环境因素如背光、非均匀照明、夜间微光等,以及技术限制如不足的曝光时间和过低的增益等影响,这类图像的视觉质量较差,目标检测和识别的精度远低于高质量图像。考虑到大多数目标检测模型都是基于高质量图像数据进行训练和测试的,如RCNN(region convolutional neural network)[1]、YOLO(you only look once)[2]、SSD(single shot multi-box detector)[3]
等,采用先对原始低照度图像进行图像增强的方式提高目标检测的精度是一种最简便的方式。LLNet(low-light net)[4]、MBLLEN(multi-branch lowlight enhancement network)[5]等端到端的低照度图像增强工作已经证明了利用神经网络提升低照度图像质量的可能性。同时,学者们也注意到Retinex 模型在传统的低照度图像增强以及图像去雾中有着不俗的表现,由此出现了基于利用神经网络来估计Retinex 中的照明分量以及反射分量的方法,如Retinex-Net[6]、LightenNet[7]等,都能起到很好的增强效果以及自适应性。为了实现神经网络的泛用性,很多研究者采集构建了一系列低照度场景数据集,包括SID(see-in-the-dark)[8]、LOL(lowlight)[9]等。除此之外,基于非匹配数据和非监督学习的方法也被应用在低照度图像增强中,如EnlightenGAN(enlighten generative adversarial networks)[10],还有一些基于零样本学习的方法,例如Zero-DCE(zero-reference deep curve estimation)[11]等,这种方法具有很低的数据成本以及极高的训练和推理速度。
上述低照度图像增强模型主要以人为的标准进行优化,即使在一些图像评价指标上表现出色,也很难对下游的目标检测任务起到很好的精度提升效果。不仅如此,先增强后检测的方法还会增加在边缘设备上部署的计算力需求。受到KRUTHIVENTI S S S 等人[12]和QI L 等人[13]的启发,本文提出了一种新的基于知识蒸馏的目标检测网络训练方法,不同于一些典型的知识蒸馏算法通过蒸馏大模型的知识来训练小模型[14],该方法通过构建一组像素级对齐的高质量和低照度图像对数据集,利用高质量图像的特征信息指导网络模型学习从相应的低照度图像中提取类似的信息,可以有效提高在夜间低照度环境或其他复杂条件下的低质量图像的目标检测精度。为了便于人眼对目标检测结果进行观察,本文创新性地在原有的目标检测网络模型框架上,引入了用于图像增强的增强解码器,其主要作用是利用目标检测主干网络的特征恢复出高质量图像,最终可以在一个模型上同时实现图像的增强和目标检测。
1 基于知识蒸馏的低照度图像增强和目标检测算法
本文设计了一种结合目标检测和低照度图像增强的神经网络结构,可以巧妙地将目标检测和图像增强的算法集合在同一个卷积神经网络模型中。模型整体可以分为3 部分:负责提取图像特征信息的主干网络;通过提取的多尺度特征进行图像重建的低照度增强解码器;识别图像特征信息并判断图像中目标位置和类别的目标检测模块。图1 展示了教师网络和学生网络的网络结构以及蒸馏的位置,其中教师网络的输入为高质量图像,通过预训练使教师网络学习利用高质量图像的特征信息进行目标检测;学生网络的输入为低照度图像,通过蒸馏教师网络提取的高质量图像的特征信息进行训练,使学生网络可以在低照度图像上提取出类似于教师网络在高质量图像上提取的信息,并利用这些信息进行后续的目标检测和图像增强。由于目标检测和图像增强都需要利用主干网络所提取的特征信息,类似于文献[13]在特征金字塔上进行蒸馏的方法无法使学生网络直接学习到教师网络更浅层的特征信息,而这些浅层的信息对图像的增强有很大作用[10],故为了通过知识蒸馏来实现多任务模型的训练,最终选择了在目标检测主干网络上进行蒸馏。
1.1 主干网络结构
在目标检测中,主干网络通常用于提取输入图像的特征,而这一部分功能和上游的图像分类网络功能相近,往往会选择成熟的图像分类模型作为主干网络。同时在底层视觉任务如图像降噪,图像超分辨率以及图像复原等网络模型中,往往会采用一种编码器-解码器的结构,即先对输入图像进行特征提取或者称为编码过程,然后根据各级特征进行恢复或者称为解码过程。其中编码器往往会采用与图像分类模型类似的结构,因此在目标检测和图像增强任务中使用同一个主干提取网络是具有可行性的。
如图1 所示,主干特征提取网络框架基于CSPDarknet 主干网络实现,并采用了 YoloX[15]对CSPDarknet 做出的一些改进,诸如采用聚焦(Focus)来对输入图像进行降采样,通过调整CSPDarknet 的卷积层深度和宽度实现更轻量化的网络模型等。
CSPDarknet 可以分成5 个阶段,每个阶段分别提取出不同尺度的特征信息,对于一个分辨率为W×H的输入图像而言,5 个阶段的输出尺寸分别为W/2×H/2、W/4×H/4、W/8×H/8、W/16×H/16、W/32×H/32。在目标检测网络中,最后3 个阶段的输出会作为目标特征进行多尺度特征金字塔融合,而对于图像增强,我们并不需要远小于原始分别率的图像特征,通常只会利用前3 个阶段的输出结果进行解码恢复。综合而言,只需要保证学生网络第3 阶段的输出与教师网络相似,就可以很大程度上实现对教师网络的蒸馏。
1.2 低照度增强解码器
与目标检测不同,图像复原模型并不是一个概率模型,所需要的特征信息相较于目标检测任务也更多,仅通过一个尺度的特征信息生成的图像无法满足需求。基于U-net[16]架构的图像增强模型在各个底层视觉任务中都有优秀的表现,因此基于U-net 的结构设计了低照度增强解码器。
如图2 所示,图像增强模块利用了主干网络中的前3 个阶段的特征图,其尺寸分别为W/2×H/2、W/4×H/4和W/8×H/8。整体采用了类似U-net 的网络结构,通过跳跃连接将不同尺度的特征信息进行融合,并通过3 个上采样以及卷积层将图像的重建为W×H×3的RGB(red-green-blue)图像。其中上采样操作由若干个残差块以及一个反卷积构成,具体结构如图2(b)所示,残差块的主体部分由两个3×3 卷积层构成,残差边不做任何处理,直接将残差块的输入和输出相加得到结果。经过若干次残差块后,经过一次3×3 的反卷积进行上采样,得到分辨率翻倍、通道数减半的输出结果。在经过上采样块处理后,输出结果与主干网络中尺度相对应的特征层进行相加,作为下一个上采样块的输入。经过3 次上采样后,特征张量通过一次3×3 卷积输出一个通道数为3 的RGB 图像。
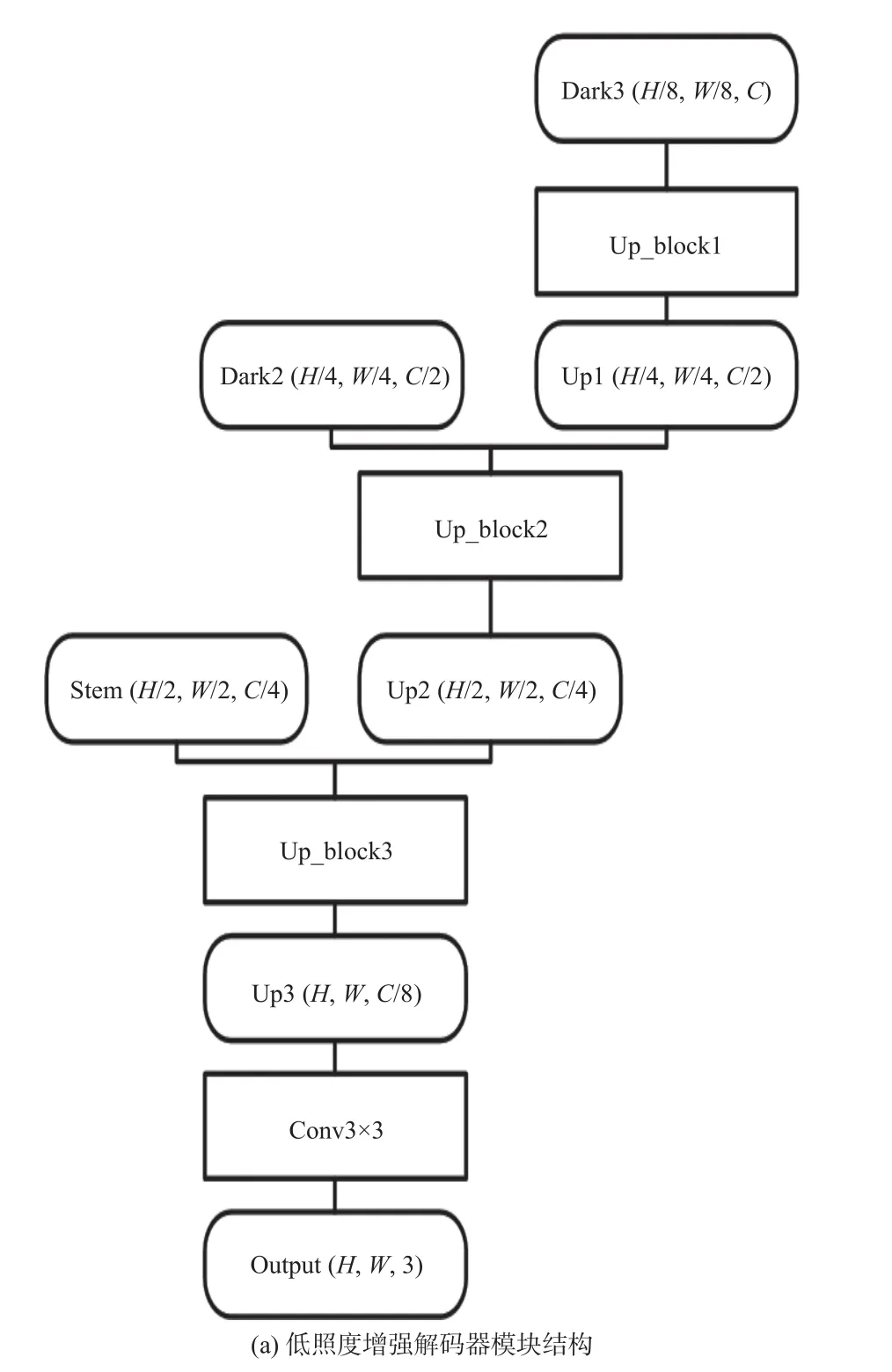
图2 低照度图像增强模块结构图Fig.2 Structure of low-light image enhancement block
1.3 目标检测网络结构
目标检测结构由空间金字塔网络(SPN)[17]、特征金字塔网络和解耦目标检测头构成。空间金字塔用于在低尺度下生成并融合不同尺度的特征,特征金字塔主要用于融合主干特征提取网络不同尺度的特征,使目标检测头能从多尺度多语义层次的信息中进行检测,以达到更好的检测精度。不同于标准YoloX 模型的FPN(feature pyramid network)特征金字塔网络,本文采用了PAN(path aggregation network)特征金字塔[18],不仅通过低尺度特征信息上采样融合到高尺度特征上,还通过下采样将高尺度信息往低尺度上融合。
检测部分采用无锚点的目标检测方法,且将分类和回归的任务进行解耦,不再通过先验知识设定锚点框输出预测框相对于锚点框的位置和形状偏移,而是直接预测相对于每个网格的位置偏移以及预测框的高度和宽度。
1.4 多任务训练的损失函数
本文方法涉及到的损失函数包含3 部分,目标检测损失、图像增强损失以及知识蒸馏损失。其中目标检测部分和YoloX 一样由3 个部分组成,预测框区域损失、目标置信度损失以及目标类别损失。
预测框区域损失,即获取到每个框对应的特征点后,取出该特征点的预测框,利用真实框和预测框计算IoU(intersection over union)损失:
式中Bpre和Bgt分别代表预测框和真实框的区域。
目标置信度损失和目标类别损失的表示形式是相同的,即:
式中:Ppre和Pgt分别代表预测的概率和真实的概率;w为每个类别损失函数的权重。
对于图像增强等底层视觉任务,最常使用的是L1距离或者L2距离损失。L1损失在对于输入和输出差距较大时不会有过大的梯度,在图像降噪任务中应用广泛,而L2损失常出现在图像超分辨率以及图像复原任务中。低照度图像增强既要进行图像信息的恢复,也要想办法去除图像中的噪声,因此本文采用结合两种损失函数优点的smoothL1损失作为图像增强目标的损失函数,即:
式中:y为参考图像;x为模型增强后的图像。由于学生网络和和教师网络采用的是完全相同的网络结构,对于两个网络而言,每一层对应的特征层输出的尺度是完全相同的。因此,无需对两个网络的特征层进行任何其他处理,只需要求两个特征层输出的距离即可。最小化教师网络和学生网络特征层差异可以表示为最小化以下函数:
最终的损失函数可以表示为
2 实验评估
2.1 数据集的构建
若想实现高质量正常照度目标检测知识向低照度低信噪比目标检测的迁移,就必须获得完全对齐的高质量正常照度目标图像和低信噪比低照度目标图像对。本文采用生成对抗网络以及低照度下均匀面真实噪声叠加的方式进行数据对的构造。
通常可以认为一幅图像是由图像信号和无关的噪声组成的,即:
式中:Ii,j为图像;si,j为信号;ni,j为噪声。一般情况下,信号的大小是大于噪声的大小的。但对于低照度下的均匀面而言,相比一个频率很低的低频信号,图像可以看作是以信号为均值上下波动的一个随机过程。这种情况下,si,j可以通过均值滤波提取低频的方式得到,然后将噪声的均值调整为0,最终提取出来的噪声可以表示为
最后利用非匹配的低照度图像数据集以及正常高质量图像数据集对循环生成对抗神经网络(cycle generative adversarial networks,CycleGAN)[19]进行训练,得到一个能够将正常照度图像转换为具有夜间低照度特性的图像的生成器G(x)。将从均匀面上提取出来的噪声叠加在生成的低照度特性图像上就得到了训练所需要的低照度-高质量目标检测图像对数据集。
2.2 训练环境
CycleGAN 具有独特的循环训练机制,可以实现非匹配的数据集之间的相互转换。为了训练出可以将正常高质量图像转换为具有夜间低照度特性的图像,本文采集了1 550 张包含行人、车辆等目标的真实夜间低照度图像,同时在ImageNet[20]和COCO 数据集中收集了大量高质量的正常照度图像2 480 张。利用这些夜间低质量图像数据集和收集到的高质量图像组成非匹配的数据集,对CycleGAN 网络进行训练。利用训练得到的高质量图像-夜间低照度图像转换模型和公开的PASCAL VOC 目标检测数据集,生成了共9 963 组带标签的夜间低照度-正常高质量图像对。
同时,为了降低图像的信噪比,对夜间的地面、墙体等均匀面场景进行采集,构建了共10 组不同照度分辨率为1 920×1 080 像素的均匀面图像视频序列,然后从这些视频中随机提取噪声叠加到生成的9 963 组图像对中,将这9 963 组数据中的三分之一即共2 989 对图像划分为验证集,其余6 974 对图像划分为训练集。
训练过程分为3步,首先利用原始高质量的PASCAL VOC 数据集训练教师网络,然后利用知识蒸馏的方式对学生网络的主干网络和目标检测网络进行200 轮的训练,学习率为2×10-4,且采用余弦退火法进行学习率的下降。随后冻结主干网络,利用图像对对低照度图像增强解码器进行训练50轮,学习率为1×10-4,然后进行学习率线性下降至0 的方法再次训练50 轮。本次实验基于Nvidia RTX 2080Ti GPU 进行训练。
2.3 图像增强效果
本文通过在真实低照度数据集LOL 数据集上的峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structural similarity,SSIM)指标来验证网络模型在低照度图像增强任务上的效果,同时利用自然图像质量评价器(natural image quality evaluator,NIQE)[21]对比验证模型在真实低照度场景下的增强效果,其中NIQE 值越低代表图像质量评价越高,PSNR 和SSIM 值越高代表图像越接近参考图像。进行对比的方法包括EnlightenGAN、Zero-DCE 以及CycleGAN,结果如表1 所示。

表1 不同方法的图像质量评价Table 1 Parameters of image quality assessment of different methods
从对比结果来看,本文的方法在NIQE 指标上接近EnlightenGAN 的水平,且明显超过了Zero-DCE和CycleGAN 的效果,同时该方法在PSNR 和SSIM指标上均优于EnlightenGAN。证明了该方法在低照度图像增强上具有可行性。
本文还对4 种方法处理的图像质量进行了对比和主观判断,对比结果如图3 所示。其中第1 列展示了原始的低照度夜间图像,第2~5 列分别为EnlightenGAN、Zero-DCE、CycleGAN 以及本文方法处理的结果。

图3 不同方法的低照度图像增强效果对比Fig.3 Visual comparison on low-light image enhancement effect of different methods
可以看出,本文方法对夜间低照度图像具有明显的对比度和动态范围增强以及降噪的效果。通过对比可以发现,其余3 种方法处理的结果都有较为明显的噪声残留,而本文在构造的训练数据集中叠加了真实的噪声,可以使神经网络模型具有一定的降噪效果。
2.4 检测精度
为了验证知识蒸馏对夜间低照度场景下的目标检测精度提升的效果,采用本文所构建的验证集中2 989 张图像以及公开的夜间低照度目标检测数据集ExDark[22]中的2 194 张夜间低照度图像的平均精确度(mean of average precision,mAP)作为检测精度的评估指标,并与正常照度下的精度以及未采用知识蒸馏的精度进行对比,其中mAP计算的IoU 阈值为50%。结果如表2、图4~图5所示。

表2 不同方法的目标检测精度Table 2 mAP of different methods

图4 在真实低照度图像数据集中的mAP 指标测试结果Fig.4 Test results of mAP indicators on real low-light images dataset

图5 低照度图像增强和目标检测测试结果Fig.5 Test results of low-light image enhancement and object detection
从测试结果整体上来看,采用知识蒸馏的方式可将在构造数据集下的夜间低照度目标的检测精度提高16.58%,在真实数据集下的目标检测精度提高18.15%,且对每一种目标的精度都有所提升,尤其是对车辆等交通工具的识别精度提升最大。在真实低照度图像的测试中还发现,一些小目标以及在光源附近的目标很容易出现漏检的情况,这可能是由于训练数据对中缺少真实灯光,尤其是多个光源场景下的数据所导致的。
3 结论
本文设计了一种可以同时进行夜间低照度图像增强以及目标检测任务的神经网络模型,合成构造了具有夜间低照度特性的图像数据集,利用特征知识蒸馏的方式对网络模型训练。在数据集上的实验表明,本文的方法具有可行性,能够有效提升夜间低照度下的目标检测精度,图像增强效果也能够达到甚至优于一些主流方法。此外该方法还可以有效提升高噪声低照度图像的信噪比,产生对人眼视觉友好的增强图像,多任务共享主干的结构还有效降低了计算成本。未来的工作将探索实现在利用高质量图像训练的大模型上进行低照度、小模型的蒸馏。利用对抗模型进行无监督训练也是进一步提升图像质量的探索方向。
