基于改进YOLOv3的遥感小目标检测网络
2023-09-21陈成琳
陈成琳,鲍 春,曹 杰,郝 群
(1. 北京理工大学光电学院,北京 100081;2. 北京理工大学长三角研究院(嘉兴),浙江 嘉兴 314003)
1 引言
随着卫星和航空摄影技术的成熟,遥感图像检测在城市规划、智能监测、精准农业等民用和军事领域发挥着越来越重要的作用。 在这种需求的推动下,近年来人们在光学遥感图像目标检测方面做了大量的研究。众所周知,高质量、大规模的数据集对于训练基于深度学习的目标检测方法具有重要意义。目前,通用的目标检测器已经比较成熟,一些主流的单阶段、双阶段及多阶段检测算法对大、中目标有着较好的性能,但对小目标的检测仍存在较大的发展空间。光学可见光遥感图像一般是从卫星或者航空摄影采集得到,受其成像机制的影响,采集的图像往往具有如下特点[1]:①遥感图像视野比较广阔,使得背景复杂度高,且采用俯视拍摄,目标的方向不确定。②遥感图像的拍摄高度从几百米到近万米不等,且地面目标也大小不一,使得目标具有尺度多样性。③遥感图像中目标普遍较小且目标分布不均匀。遥感图像自身的这些特性使得检测难度大大增加。
小目标本身尺寸较小,经过卷积神经网络后,目标的特征信息与位置信息逐渐丢失,在深层特征图中小目标检测困难,经典的Faster R-CNN[2]就是利用了网络的最后一层进行预测。Liu等[3]提取不同层次的特征进行预测,利用浅层特征对小目标进行检测,但该方法没有充分融合不同尺度的特征,对浅层信息的使用不够充分。通过多尺度学习,可以将目标深浅信息融合,进一步提升小目标检测性能。特征金字塔网络FPN[4](Feature Pyramid Networks)是最常见的一种多尺度网络,它将不同尺度的特征图与上采样之后的特征图融合之后的结果来做预测。Kong等[5]提出了一种跳层特征提取网络,有效融合了高层语义信息和底层高分辨率信息。这种跳层特征提取是多尺度提取特征方式的一种,现在已经成为小目标检测的一种常规手段。Liu等[6]在不同分支的卷积层上加入不同尺寸与膨胀率的空洞卷积以融合不同特征,能够在不增加额外参数和计算量的情况下提高特征分辨率和扩大感受野,提高了对小目标检测的鲁棒性。通过结合生成对抗网络也可以提升小目标检测性能。Li等[7]提出的感知生成对抗网络PGAN,将低分辨率的特征变成高分辨率的特征,以提高对小目标的特征表示。类似的工作还有SOD-MTGAN[8],其将小目标的模糊图像生成具有详细信息的高分辨率图像,为使得生成器恢复更多细节以便于检测。数据增强也是提升小目标检测的最简单有效的方法之一,具体增强方式有随机裁剪、翻转、旋转、缩放以及CutOut[9]、MixUp[10]、Mosaic[11]等。Kisantal等[12]提出了一种复制粘贴的方法,通过在图像中多次复制粘贴小目标的方式来增加小目标的训练样本数,从而提升了小目标的检测性能。除此之外,还有一些研究者通过改变模型的训练方式来提高小目标的检测精度。Singh等[13]提出了图像金字塔的尺寸归一化算法SNIP,借鉴多尺度训练的思想,针对大、中、小分辨率特征图分别提取小、中、大目标候选框,对小目标检测非常有效,但其训练速度很慢。Chen等[14]设计了一种基于小目标Loss反馈驱动机制的图像拼接法来提升小目标检测。
为提高遥感小目标识别精度,本文基于YOLOv3[15]模型,首先增加了一层预测层并优化了loss来针对小目标检测。其次引入了注意力机制,来区分背景和目标。最后在DIOR[16]和 NWPU VHR-10[17]数据集上进行实验验证。实验结果表明,该方法有效提升了对小目标的检测精度,且模型满足实时性的要求。
2 改进的 YOLOv3 模型
2.1 特征提取
目标的特征表示一般由骨干网络提供,其特征表示的优劣对检测精度有至关重要的影响。然而,遥感图像中小目标居多,考虑到小对象的特异性,直接应用原始骨干网络来提取小对象的特征并不是最优的。原始网络关注于通用目标,会产生一个较大感受野,这使得小物体容易受到感受域内周围背景杂波的干扰。小物体特征比较简单,不需要过深的网络来拟合。基于此,本文构建了一个新的带注意力机制的特征提取模块AM Block(Block with Attention Module ),其能够更好地区分目标和背景,得到具有背景感知的目标特征。其结构如图1所示。
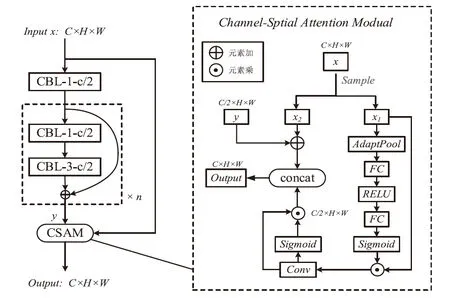
图1 AM Block结构
图1中,CBL-k-c 表示c个卷积核大小为k×k的Conv和BN、LeakyRelu 的组合体,输入为 x,经过一系列卷积操作后得到y,将x和y输入到CSAM(Channel-Spatial Attention Module)可以得到输出Output。CSAM可用如下公式表示
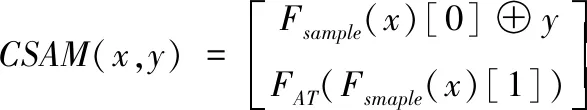
(1)
其中⊕表示元素加,[·]表示concat连接,是张量上的操作。输入x按照维度采样,分别取偶数和奇数通道得到Fsample(x)[0]和Fsample(x)[1],尺度不变,通道数减半。Fsample(x)[0]和y通过元素加求和,然后和经过注意力函数FAT(·)处理的Fsample(x)[1]在通道维度上连接,得到最终的输出。
输入特征图中目标和背景信息混合在一起,CSAM通过一个分支将采样信息直接合并到y上,使这些特征更加强调背景感知;另一分支首先对每个通道内的信息做全局平均池化,然后通过全连接层将特征维度降低到输入的1/16,经Relu 激活后再通过一个全连接层恢复原先的维度。将通过Sigmoid激活函数得到的结果自适应地对原始特征的通道权重进行标定来提升有用的特征。将加权后的特征通过一个卷积后对特征图上的每一个像素进行激活,并与前面通道加权后的特征相乘,得到经过双重注意力调整的特征图。该特征图的所有通道和每一个通道都可以学习到一个权重,用来指导混合特征,以区分目标和背景。图2展示了本文算法和YOLOv3提取的特征图对比示意图,从图中可以看出,相比于YOLOv3,改进后的结构能更有效的突出小目标特征,保留一些细节信息,抑制背景噪声。

图2 特征可视化对比图
2.2 检测头优化
输入图像经过特征提取网络得到了不同尺度的特征图。浅层特征层目标信息相对较充分,更加关注的是图像细节纹理等特征;深层特征层目标信息相对较少,更加关注比较抽象的语义信息。而小对象本身尺寸较小,经过多次下采样,特征信息逐渐丢失,使得在深层特征层中包含的目标信息很有限。使用浅层特征层进行预测可以有效提升对小目标的检测精度。网络具体框架见图3所示,其中Darknet53-A(Darknet53-Attention)是使用AM Block替换Bottleneck后的特征提取网络,输入图像经过特征提取网络和PFN得到四层不同尺度的特征图P2,P3,P4,P5,分别为原图的1/4、1/8、1/16、1/32,相较于原始YOLOv3增加了P2尺度特征图来进一步预测小目标。
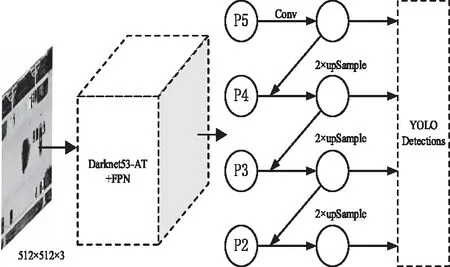
图3 网络整体架构
2.3 损失函数
YOLOv3损失由回归损失、分类损失和置信度损失三部分组成,回归部分由L2损失函数计算,其余部分由交叉熵损失函数计算得到。在目标检测领域,目标框的四个位置不是相互独立的,而使用L2损失函数独立的计算四点位置的损失并求和得到最终的回归损失不够合理。而且预测框的评价指标采用IOU(Intersection over Union),损失的计算和评价不一致。综合考虑,引入CIOU[18](Complete IOU)来计算目标的回归损失。该损失函数充分考虑了框回归的3个几何因素(重叠区域、中心点距离、宽高比)。同时考虑到,小物体和大物体产生的损失不平衡问题,将回归损失乘以一个2-wh的比例系数(w和h代表预测框的宽高),来增强对小目标的识别。总的损失函数计算公式如下:
Loss(object)=
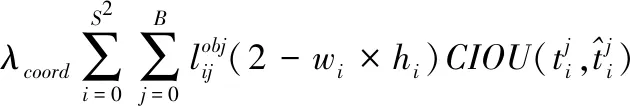
(2)
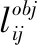
3 实验和结果分析
3.1 数据集和实验环境
NWPU VHR-10数据集是仅用于研究的公开提供的10类地理空间物体检测数据集,共包含800幅超高分辨率遥感图像,数据集规模较小。
DIOR是一个用于光学遥感图像目标检测的大规模基准数据集。数据集包含23463个图像(训练集、测试集分别有11725、11738张图像)和192472个实例,涵盖20个对象类。目标尺度和长宽比变换范围较大。在MS COCO[19]中定义面积小于32×32的为小目标,大于92×92的为大目标,处在二者之间的为中目标。根据这个标准,统计DIOR数据集中大、中、小目标占总目标比例分别为27.7%、29.5%、42.8%,小目标占比近一半。
本文算法统一图像输入大小为512×512,批次大小均为16,训练次数为200Epoch,采用SGD梯度下降方法,动量为0.9,衰减系数为0.0005。学习率更新分两阶段。首先采用warm-up预热学习率,用一维线性插值来进行对每次迭代的学习率进行更新,学习率为0.01逐渐上升到0.1,然后采用余弦衰减策略来对学习率进行更新。使用旋转、平移、翻转、Mosaic进行数据增强。具体实验在Pytorch1.7.1深度学习框架上进行,并在GPU服务器NVIDIA RTX 3080Ti 的CUDA环境中进行计算加速,详细配置见表1。
3.2 衡量指标
本文选择 AP、mAP@0.5作为模型精度衡量指标;选择FPS(Frame Per Second)作为模型的速度衡量指标,定义为每秒可检测的图像数量;选择模型体积和参数量GFLOPs作为模型大小衡量指标。AP是每一类目标的检测精度,mAP@0.5是IOU在0.5阈值下计算的各类目标AP平均值,也是准确率-召回率(PR)曲线与坐标轴所围成的面积(见式(3))。PR曲线以召回率(Recall, R)作为横坐标轴,准确率(Precision, P)作为纵坐标轴绘制而成。
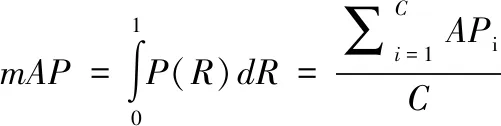
(3)
其中C表示有C个类别,当C=1时,mAP=AP,准确率和召回率的计算公式如下
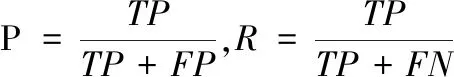
(4)
其中TP、FP和FN分别代表预测为正的正样本、预测为正的负样本和预测为负的正样本。
3.3 结果分析
图4显示了改进算法在训练过程中网络的各类损失的变化曲线。横轴代表迭代次数,纵坐标是损失值。可以看出,随着训练迭代,网络的损失稳定下降,收敛过程比较稳定。
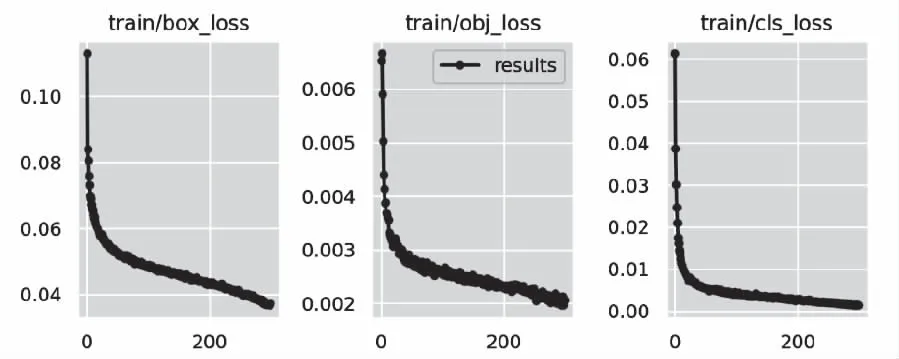
图4 损失变化曲线
表2比较了改进算法和 YOLOv3 算法在NWPU VHR-10上的各类目标精度和平均精度。从表中可以看出,改进的YOLOv3算法中某些类别有小幅度下降,在汽车、桥、港口、篮球场类别有大幅度上升,平均精度mAP提高8.84%。

表2 在NWPU VHR-10的精度评估
表3比较了改进算法和 YOLOv3 算法在DIOR数据集上的模型精度、速度、体积和参数量,可以看出改进算法的mAP比YOLOv3 提升14%,FPS从83下降到66,体积增大5M,参数量也增加了24GFLOPs,但都在可接受的范围,且仍然可充分满足实时性的要求。
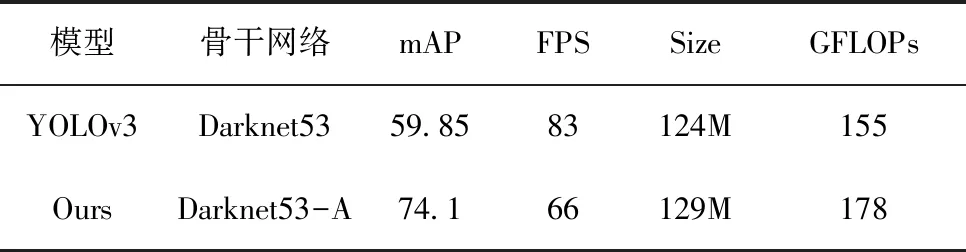
表3 在DIOR数据集上模型的验证结果
表4是不同模型在DIOR上的精度对比分析,分别对比了改进算法和YOLOv3、SSD、FasterRCNN with FPN[16]、RetinaNet[20]的检测精度。从实验数据可以看出,改进的YOLOv3 模型在大多类目标精度和平均精度远高于其它模型,验证了所改进方法的有效性。
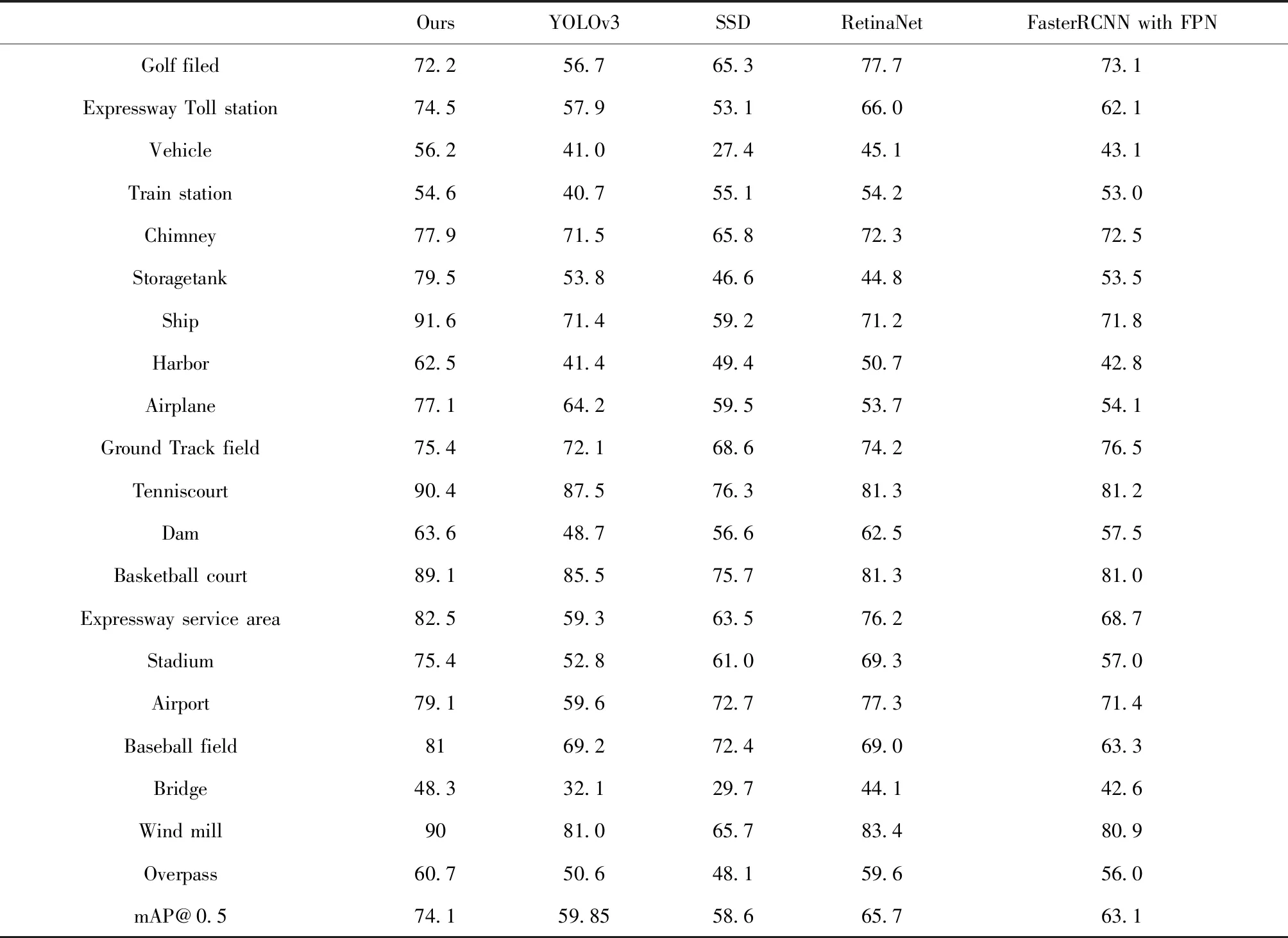
表4 不同模型在DIOR数据集上的精度评估
图5展示了改进算法在NWPU VHR-10和 DIOR数据集上的部分检测结果。第一、二行分别为NWPU VHR-10和DIOR数据集在不同背景复杂度下不同类目标的检测结果可视化图。可以看到,包含小目标在内的大部分目标都可以很好地检测到。

图5 模型检测结果图
4 结论
本文提出了一种基于YOLOv3的遥感小目标检测模型,设计了一种新的带注意力机制的特征提取模块,其能够更好的抑制背景噪声,突出目标特征;增加了一个检测层且优化了损失函数,进一步提高了对小目标的识别精度。然而本文算法仍存在一些局限性,在选用的数据集中存在不同程度的类别不平衡问题,如何在现有的基础上提升少样本类别的检测精度是下一阶段的改进和研究的目标。
