电子病历的关系语义实体识别
2023-09-19蔡翟源奚雪峰崔志明盛胜利
蔡翟源, 陈 杰, 奚雪峰,3*, 崔志明, 盛胜利
(1.苏州科技大学电子与信息工程学院,江苏 苏州 215009;2.苏州虚拟现实智能交互及应用技术重点实验室,江苏 苏州 215009;3.苏州智慧城市研究院,江苏 苏州 215009;4.德州理工大学,得克萨斯州 拉伯克市 79401)
自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,其中命名实体识别(Named Entity Recognition,NER)是NLP 领域的最基础、最重要的任务之一。 命名实体识别的一般目标是对包括3 大类以及7 小类的文本段进行命名实体的抽取,将文本从非结构化的数据形式转化为结构化数据形式,方便存储以及后续对文本的处理应用,在信息抽取、机器问答等自然语言处理任务中有较为广泛的应用。
目前随着生物医学技术的发展,医疗领域的文献以及资料数目已经成几何级增长,运用NER 技术实现医疗文本的实体识别可以大大提高医疗效率。 特别是目前新型冠状病毒的爆发,更加引起人们对健康的关注,并且有力带动医疗技术的快速进步。 在医疗领域,医务工作者通过医疗管理系统,直接将患者的基本信息和病况信息录入系统,存储在服务器中,生成电子医疗数据,其中电子病历是最为常见的一种电子医疗文本。 对电子病历文本进行实体识别,将繁杂的医疗文本以结构化的数据形式存储起来,给医学工作者在后续的分析数据工作中节省了很多时间,并为医学工作提供更加高效的分析、研究和决策。
电子病历实体识别主要关注于临床病历中的疾病症状、检查、手术、药物等专有词语,相较于通用领域实体识别,电子病历实体识别的词语更倾向于短语结构,例如,在病历记录中,记录患者“无静脉曲张”包含疾病词“静脉曲张”和“患者未患有”两种信息。 目前国内公开的电子病历实体识别数据集——医渡云数据集,在疾病实体标记时,只标记出与疾病相关的专有名词,而没有将疾病与患者关联起来,例如“无静脉曲张”,医渡云数据集将“静脉曲张”标记为疾病实体,但是事实上,患者并未患有该病。 假如需要统计患有静脉曲张的病人数,仅识别出静脉曲张将会导致统计错误。
1 相关工作
电子病历的命名实体识别主要实现方案可以分为四大类:基于字典的方法、基于规则的方法、基于传统机器学习的方法以及基于深度学习的方法。早期基于字典的方法提取实体虽然在结构上有易于实现的优点,但是无法解决一词多义等问题,需要人工维护词典,并且召回率也比较低;后来出现了基于规则的方法,例如,李莹[1]对家族史病历,通过人工学习和发现的办法学习了一套浅层句法分析器,实现了家族病史实体提取。 这种基于规则的方法,需要手工制作符合数据集的特征集,在不满足提取规则的文本上无法正确提取结果。 以上两种方法均不能成功应用于未训练过的的实体识别,而医疗领域出现了新的病症名、药物名等词汇是较为常见的。
后来,基于统计的机器学习方法被应用于命名实体识别,包括隐马科夫模型(HMM)、最大熵马尔科夫模型(MEMM)、条件随机场模型(CRF)。 在医疗领域使用最多的就是条件随机场模型(CRF),刘凯等人[2]将CRF模型应用在中医电子病历实体识别中, 通过结合特征模板MT3 糖尿病病症的实体提取结果F1可以达到80%;栗伟等人[3]使用CRF 与规则相结合方法,先用CRF 进行病历实体的初始识别,然后基于规则进行病历实体识别结果优化,最后实体识别最高F1值可以达到87.26%。
随着计算机算力的大幅提升,基于深度学习的命名实体识别方法也应运而生,并且在命名实体领域取得了很好的结果。 基于深度学习的方法可以解决采用传统方法带来的过于依靠人工特征提取,提高了效率,因此成为近来的研究热点。 曹依依等人[4]构建了卷积神经网络CNN 与条件随机场CRF 的融合模型框架,F1值达到了90.31%。 陈德鑫等人[5]构建了基于CNN+BiLSTM 模型的在线医疗实体抽取研究,最后疾病和医院实体抽取F1值可以达到97%,其余的多种实体也都可以达到91%以上。 张华丽等人[6]使用结合注意力机制的BiLSTM-CRF 融合模型进行中文电子病历命名实体识别,通过注意力机制获取字符间的依赖关系,从而优化实体识别准确率。 2018 年,Devlin 等人[7]首次提出了BERT 预训练模型,此后BERT 被应用于实体识别领域,BERT 模型相比于传统的嵌入模型,可以更好的学习上下文语义信息。 陈琛等人[8]将BERT 预训练模型应用到医疗命名实体识别中,构建了BERT-BiLSTM-CRF 模型,其结果对比于Baseline 的F1值提高了1.1%。
2 多语义电子病历实体识别介绍
2.1 医渡云数据集介绍
医渡云数据集包括1 500 标注文本,1 000 条非标注文本。其中标注的实体类别6 种,标注的医疗实体词表6 292 个,总共标注了26 414 个实体数据。 标注数据集统计如图1 所示。
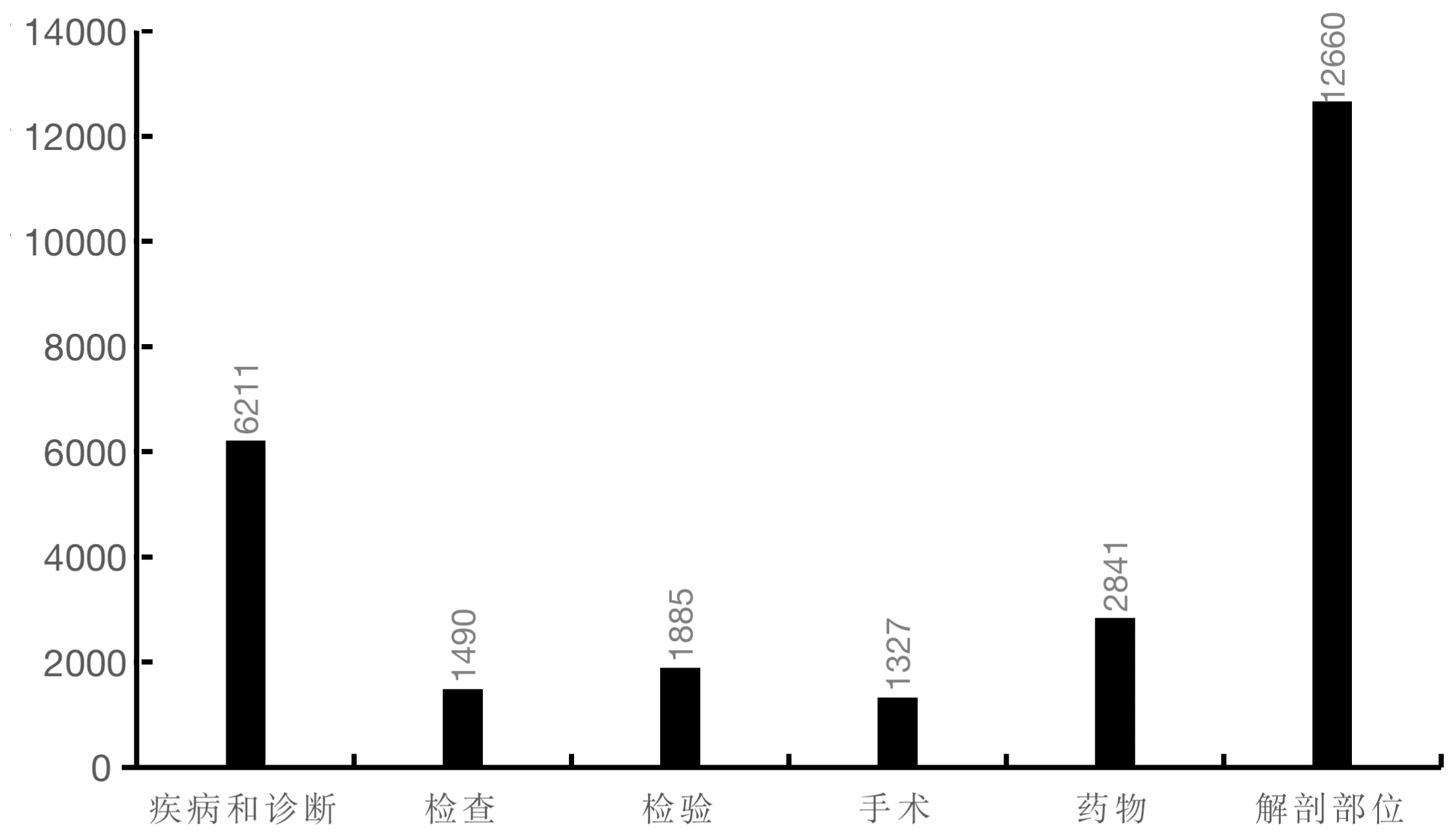
图1 实体类别统计
对于医渡云数据集实体类别的基本释义见表1。医渡云数据集采用的标注策略为BIO 标注模式,也就是将实体的开头字标记为B-X(其中X 为实体类别),实体的中间字标记为I-X,其余字符定义为无关字符,标记为O。

表1 医渡云数据类别描述
举例说明:“患者腹疼痛加重”。 这句话中“患者”、“加重”都是无关字符,标签定义为O,“腹疼痛”为医疗实体中的疾病类,具体细分“腹”为实体“腹疼痛”的开始,标签标记为B-疾病,“疼痛”为“腹疼痛”的内部,对“疼痛”分别标记为I。 该数据集对医疗领域的疾病专有名词做出标注,采用的标签为单语义标签,一个标签只包含名词类别,无法涵盖该名词与患者的关系,在很多场合,需要判断患者现在是否存在腹疼痛,或者是以往出现过腹疼痛的情况,因此,单标签无法包含相应的语义信息。
2.2 数据集标签分类及标注策略
在电子病历的文本信息挖掘任务中,除了医疗名词信息识别之外,名词实体与患者之间的关系信息识别也是其他任务展开的基础,这种关系信息的识别任务也是其他诸多工作的基础[9]。 关系信息主要反映疾病或症状在病历文本中存在的状态,这种状态主要体现在疾病或症状是否发生在患者本人身上,或已发生的疾病或症状与患者本人之间的程度,如是否当下发生的疾病或症状。 参照卫生部发布的电子病历数据组与数据元标准[9]以及I2B2 2010 评测任务提出的关系信息类别,并且对医渡云数据集进行观察分析,最终将“疾病与诊断”类和患者的关系分为四类:“当前的”“可能的”“既往的”“否认的”。表2 对这四类关系做出进一步描述。

表2 疾病与患者关系类别描述
由于需要在标签中包含关系信息,原来的医渡云标注方案无法做到,因此,文中引入多标签标注方案,例如,医渡云数据集里:“2014-11-20 复查MRI 提示右附件区囊实性肿块,考虑卵巢癌。 ”该句话中将“卵”标注为B-疾病,“巢癌”分别标记为I-疾病,但在此句话中“卵巢癌”仅仅是医生推测患者可能存在的疾病,并非实质性确定为患者患有的疾病,在文中定义的标签中,沿用原数据集的BIO 标注模式,并结合上下文语义,将其标签做出调整。上例中调整后,“卵”:B-疾病-可能的;“巢癌”:I-疾病-可能的。经过这样的转换,将仅包含名词实体信息的标签转换为带有关系的实体标签。 标注实例如图2 所示。
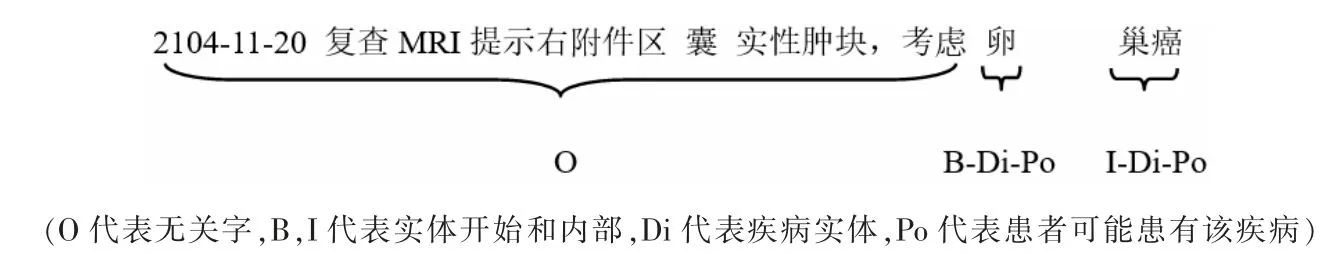
图2 多标签标注实例
相对于专业名词标注,疾病与患者的关系语义不需要专业知识也可以进行标注。 笔者在医渡云数据集标注的基础上进行疾病关系标注,该数据集并未完全将所有的疾病或者症状标注出来,因此,文中也不会对原来未标注的专有名词进行标注。 原数据集不仅提供了原文以及标签数据,还提供了已经标注的名词的词表,这便利了研究者的标注工作。 根据词表中的疾病与诊断类对应的专有名词笔者定位到原文中,通过阅读上下文,将标注为疾病类别的实体加入以上四类关系语义,形成多标签标注数据集。
3 模型
文中提出的用于实体识别的模型基于端到端的结构[10]。 主要由四部分组成:ALBERT 预训练模型、BiLSTM 编码层、Attention 机制、CRF 解码层。 将电子病历文本输入ALBERT 模型中,输出接BiLSTM 的输入层,通过Attention 机制获得强关注信息,最后将Attention 向量输入到CRF 层进行序列解码,得到每个字的标注类型,模型的结构图如图3 所示。
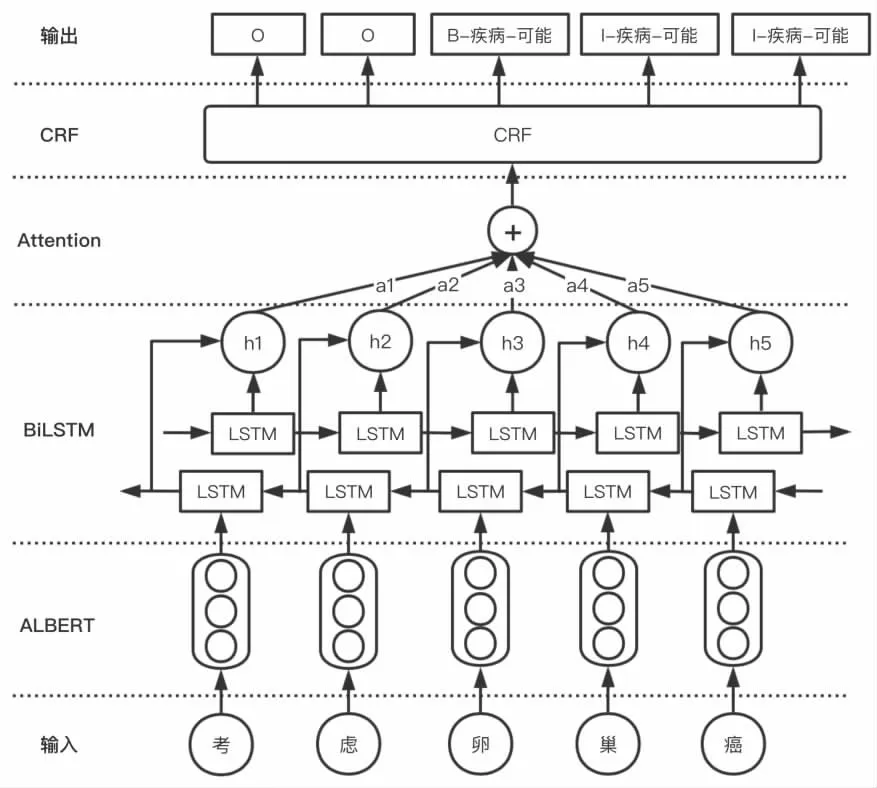
图3 模型结构图
3.1 预训练模型层
3.1.1 BERT 模型
语言模型在自然语言处理中是一个很重要的概念,BERT 模型是谷歌在2018 年提出的大型语料库预训练模型, 该模型推出后, 就在自然语言处理任务中被广泛应用, 并且在很多方面取得了超越人类的能力。BERT 模型解决了传统语言模型单向编码以及无法融合文本语义信息的缺陷, 因而也可以通过上下文关联解决一词多义的问题。BERT 模型结构图4 所示。BRERT 模型参照了GPT[11]模型与ELMO[12]模型的优点,采用了双向Transformer[13]结构作为编码器,使用Transformer 替代LSTM,使得模型可以更好地表达语义信息。Transformer 是一种基于注意力机制的编码单元。通过Transformer 结构,可以将文字内部联系关联起来。模型的结构图如图5 所示。
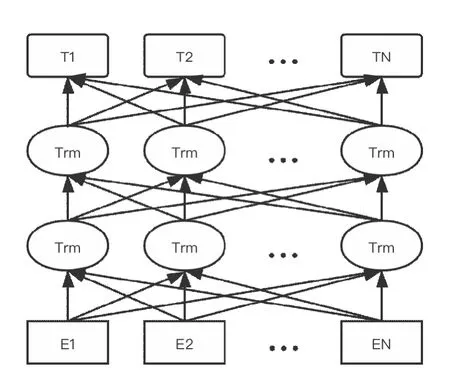
图4 BERT 预训练语言模型
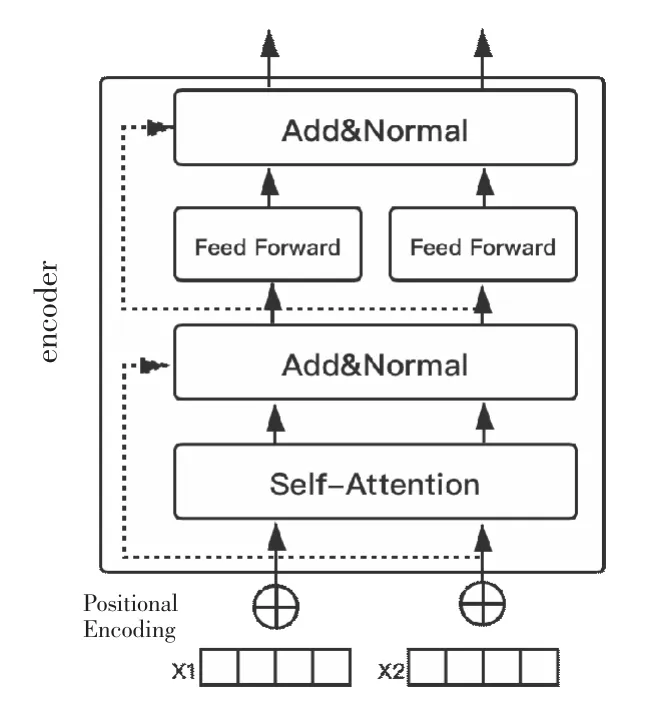
图5 Transformer 编码结构

图6 LSTM 内部结构
BERT 在训练时增加Masked 和下文预测两种任务。 使得模型可以更好地获取词语间信息和整体表达。
3.1.2 ALBERT 模型
ALBERT 模型是Lan 等[14]在2019 年提出的轻量级BERT,在3 个方面对BERT 模型进行了改进:(1)对嵌入的因式分解;(2)跨层参数共享;(3)句间连贯性损失。 将ALBERT 预训练模型直接用于电子病历词表征会存在不准确的问题,因为电子病历的文字表述并不是与公共语料库描述方式相似,其中的词语与句子也是专业术语,因此,必须使用ABERT 针对医疗领域语料库进行预训练,文中利用ALBERT 模型对电子病历文本进行预训练学习文字表示。
3.2 BiLSTM 层
临床电子病历信息数据通常具有复杂的上下文关系以及复杂的医学用语, 单向LSTM 无法处理上下文信息,所以本文利用BiLSTM 计算捕捉文本的双向语义依赖关系[15]。 BiLSTM(长短期记忆神经网络)是一种特殊的RNN网络,解决了普通神经网络在长序列时出现的梯度爆炸以及梯度消失的问题。 LSTM 结构有两个状态: 一个ct(cell state);另一个ht(hidden state)。 RNN 中的ht相当于LSTM中的ct,对于传递下去的ct改变的很慢,通常输出的ct是上一个状态传过来的ct-1加上一些数值。
3.3 Attention 层
经过BiLSTM 后,虽然模型学习了丰富的上下文信息,但是每一个特征的权重都是一样的,没有突出不同词的重要程度。 例如, “患者于5 天前出现腹部疼痛”,“患者”该词对症状“腹部疼痛”的识别没有影响,模型将患者和其他词汇以同等的权重进行特征提取,无法突出关注更加有用的信息,因此,文中在基础的实体识别模型中加入Attention 机制,使得模型可以学习到每一个元素的重要程度,从而提高识别精度。 Attention将BiLSTM 输出隐层进行加权[16]。
3.4 CRF 层
模型的最后一层用于标签的预测,一般的实体标签预测的方法都是将预测的标签当做是相互独立的,但事实上每个标签都是有联系的。例如,疾病实体“慢性支气管炎”,经过标注的结果为{B,I,I,I,I,I },在这个标注的结果中,不能出现类似{B,O,I,I,I,I}这种O 在I 之前的情况。
所以在进行标签预测的时候还要对标签序列进行合理性约束,CRF 通过特征约束捕捉序列标签的关系,输出序列预测类型。 CRF 约束标签的依赖关系,避免出现无效的序列标签输出。 将通过Attention 层的权重向量经过CRF 层解码,最终输出预测的标签结果。
4 实验设计
4.1 数据集
文中构建的多语义电子病历数据集是在医渡云数据集基础进行人工标注形成,针对原数据集疾病与诊断实体类,额外增加了四类关系信息,将单标签数据变为多标签数据。 在标注数据时发现原数据集某些标签存在偏移的现象,即一段病历描述中标签的起始和结束序列位置都与原文存在一定偏差,笔者对这些标签进行了校正。 原数据集总共6 211 个疾病与诊断实体,经过标注后,“当前的”疾病总共4 293 个,“否认的”疾病总共418 个,“可能的”疾病共1 235 个,“既往的”疾病共265 个。文中将数据集大致按照8∶1∶1 的比例进行分配为训练疾病和诊断-可能的集、验证集、测试集。 各类实体分布见表3。
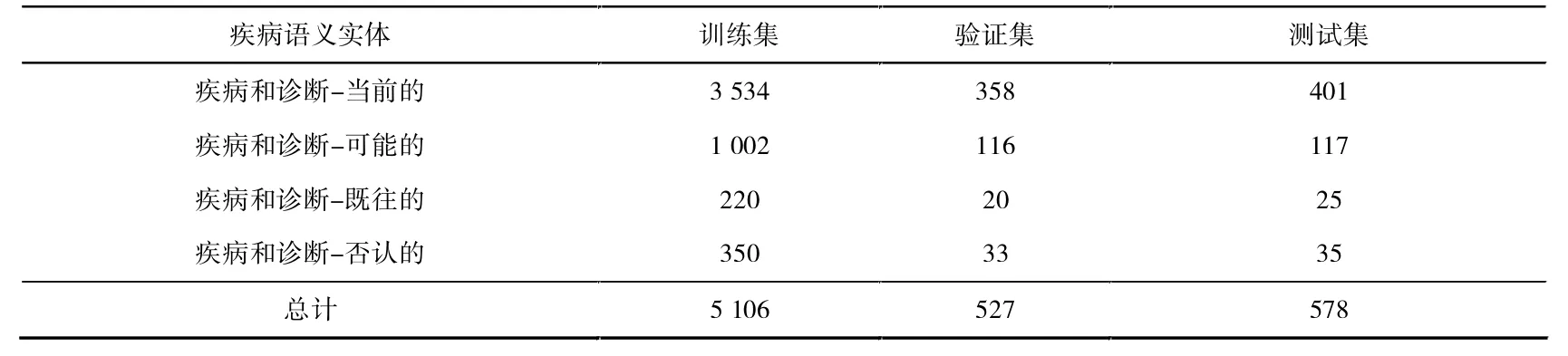
表3 关系语义实体数量分布
4.2 评价指标
该实验采用的评价指标主要是精确率(Precision)、召回率(Recall)和F1-Score。
精确率代表在被所有测试集中预测为正的样本中实际为正样本的概率,表达式为
其中,TP代表预测为正,实际为正,预测正确;FP代表预测为正,实际为负,预测错误。
召回率是针对原测试集而言的,其含义是在实际为正的样本中被预测为正样本的概率,表达式为
其中,FN代表预测为负,实际为正,预测错误;TP代表预测为正,实际为正,预测正确。
F1-Score 同时考虑精确率和召回率,让两者同时达到最高,取得平衡。F1分数表达式为
4.3 实验环境设置
该实验的环境配置:操作系统(Ubuntu 14.0),CPU(i7-9850H@2.60GHz),GPU(GTX 2080Ti*4),Python(3.7.3),Tensorflow(1.15.2),内存(16GB DDR4)。
该论文实验基于TensorFlow-Gpu1.15.2 深度学习框架和keras、numpy、seqeval 等第三方库, 使用1.8 M大小的ALBERT _TINY 模型;使用四块2080Ti 显卡进行训练。
4.4 实验结果及分析
4.4.1 模型有效性分析
为了验证模型的有效性,先使用文中的模型在医渡云原始数据集上进行测试,并对比上文所述的几种典型模型。包括CNN-CRF 模型、BiLSTM-CRF 模型、BERT-BiLSTM-CRF 模型以及文中模型。实验结果对比见表4。

表4 典型模型实验对比
将文中的实验结果与CNN-CRF、BiLSTM -CRF、BERT-BiLSTM-CRF 三种模型的实验结果对比,根据F1指标可以发现,检验实体识别可以达到最高96.3%的好效果,大多数实体的精确率、召回率均有所提升,不仅如此采用ALBERT 预训练模型的训练速度也要提升不少。 为了更加直观地展现提升情况,文中又构建了如图7 所示的F1-Score 对比图(其中疾病类代表疾病与诊断),从图中可以清晰的看到ALBERT-BiLSTM-CRF模型(粗实线)的描绘图面积最大,这说明在所有医疗实体识别类别中,该模型的效果好过其余典型模型。 该模型F1-Score 均好于其他模型。 由于BERT 参数量众多(文中采用的BERT 模型参数达到了334 M),相较于BERT 模型,文中采用的同样隐层量的ALBERT 模型,参数量仅为18 M,如此巨大的参数缩减,极大降低了模型训练的成本,提高了模型运行的速度,并且得到了比BERT 模型更好的结果。
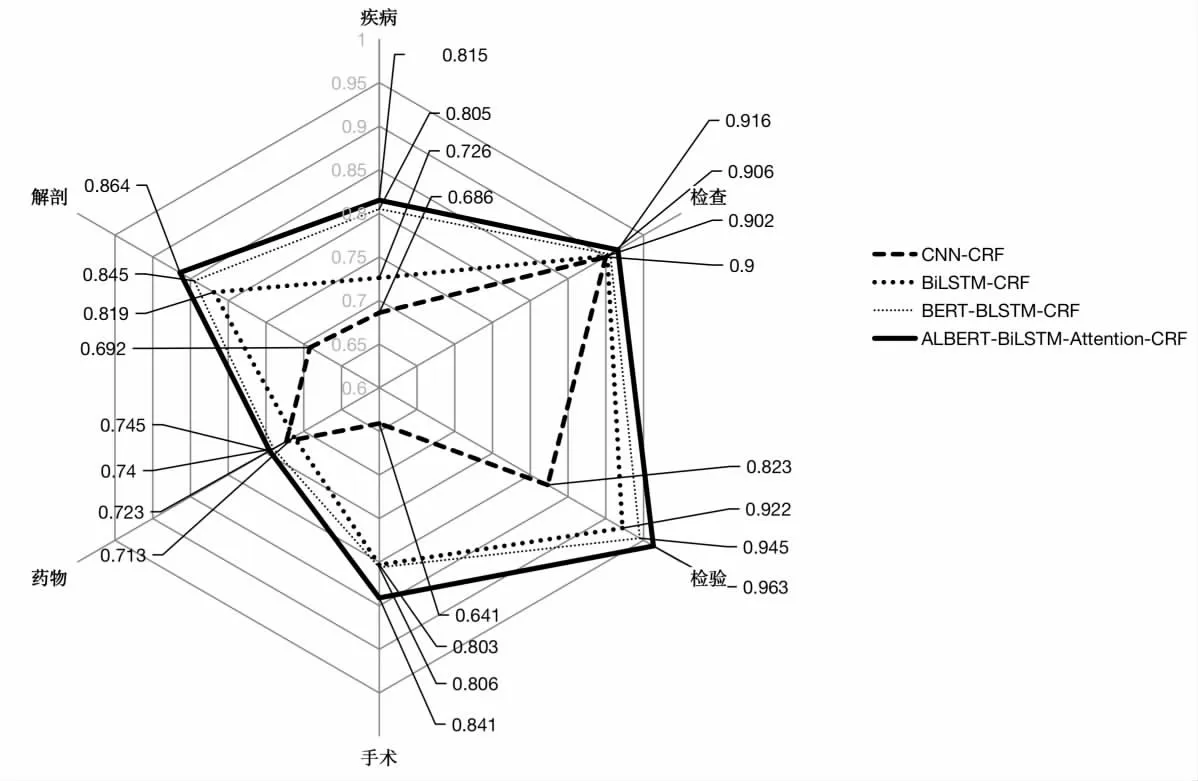
图7 4 个模型在6 种实体类别中的F1-Score 表现雷达图
将对比模型与文中实验模型进行消融实验,用于研究模型每个组件对实体识别结果的贡献度。 为了便于分析结果,该消融实验所得到的评价指标数值均为所有实体类别的平均值。 表5 中的衡量指标表明了模型的各个部分被单独分割之后,模型的性能会出现降低。当去掉CRF 解码层后,观察到三个基线模型和文中模型都出现了性能上的大幅降低,降低幅度大概在10%,因此,表明CRF 层对于此任务至关重;当BiLSTMCRF、BERT-BiLSTM-CRF、ALBERT-BiLSTM-Attention-CRF 这三个模型结构简化成单向版本, 性能也出现了不同幅度的降低,降低幅度分别为5.32%、3.70%、3.20%,可以看出文中的模型相对于其他模型在鲁棒性上有所提升;该模型中的Attention 层被去除后,模型的性能下降了2.2%。 通过这些实验,可以发现文中的模型具有更好的实验结果。
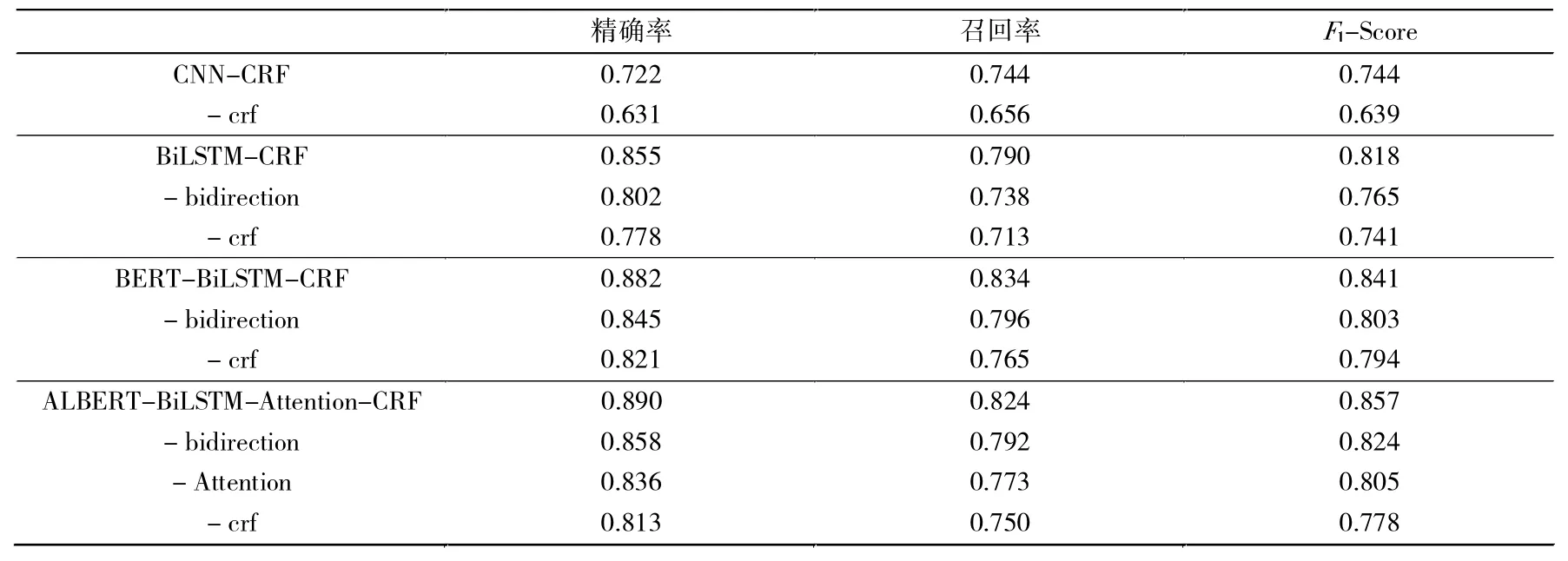
表5 消融实验
4.4.2 多标签数据集实验
上述实验证明了该模型的优越性,将该模型应用于标注的关系语义数据集,为了得到较为优秀的实验结果,对Dropout(丢弃率)进行调整实验,使用不同的Dropout 分别进行实验,结果见表6。

表6 不同Dropout 对实验结果的影响
从表6 可以看出,Dropout 从0.1 到0.5 变化过程中,结果存在波动,但Dropout 为0.1 时整体效果最好,因此,选用Dropout 为0.1。 最终得到关于精确率、召回率、F1-Score 三个评价指标的实验结果,见表7。

表7 实体识别结果
观察实验数据, 四类带有修饰信息的类别总体F1-Score 达到了74.1%, 其中疾病和诊断-当前的类F1-Score 达到了80.3%的实验结果,相较于原数据集疾病和诊断类别81.5%的结果,最高分数的实体类实验结果下降了1.2%,这是由于将原疾病和诊断类别进行拆分后造成的。根据F1-Score 可以发现,当前的疾病诊断类的指标表现最好达到了80.3%,既往的疾病诊断类最差只有65.4%。 这四类实体识别的精确率差距较大,推测原因主要是疾病和诊断-当前的类训练数据最多,疾病和诊断-既往的数据量最少,较少的数据量导致模型没有很好地学习到既往的类别的上下文语义特征。 疾病和诊断-否认的类别和疾病和诊断-既往的类别训练数据都相对较少,但是疾病和诊断-既往的的语义信息较为复杂,识别结果比疾病和诊断-否认的类别效果差很大。
5 结语
针对医疗领域实体数据集,笔者提出了ALBERT-BiLSTM-Attention-CRF 模型,在上游采用ALBERT 进行预训练模型,学习词表示,使用BiLSTM 融合上下文表征,通过Attention 进行关注表征,最后通过CRF 约束标签预测。 发挥了ALBERT 模型的学习文本信息的优势,也融合了语义依赖表征,在极大削弱了BERT 的参数的情况下,显著减少了训练时间,最后还取得了突破传统医疗实体识别方法的效果。 并且针对医渡云数据集标注不完善,缺少语义信息的问题,提出一种多标签的标注法,进行再标注。 实验表明,再标注后的数据集识别效果良好,既可以识别出疾病诊断类,又可以识别疾病与患者的关系,为医疗实体数据集标注提出了一种新的标注策略。
仍需要改进的地方:(1)标注的数据集数量过少,不利模型学习到足够特征,后续可以通过数据增强等技术扩大数据量。 (2)文中仅针对疾病与诊断类进行语义关系标注,除此之外,手术、药物也存在相应的语义关系(手术药物均有既往的与当前的等语义信息),但由于医渡云数据选用的电子病历描述的手术、药物实体往往都是当前发生的实体,既往的或者其他语义的实体过少,不适合进行二次标注。 后续笔者会在新的数据集上应用文中的方法进行实验验证。 (3)模型可以进一步考虑电子病历的特征,融入汉字偏旁等字形特征,提高识别精度。
