面向服务质量感知云API 推荐系统的数据投毒攻击检测方法
2023-09-19陈真乞文超鲍泰宇申利民
陈真,乞文超,鲍泰宇,申利民
(1.燕山大学信息科学与工程学院,河北 秦皇岛 066004;2.燕山大学河北省计算机虚拟技术与系统集成重点实验室,河北 秦皇岛 066004)
0 引言
云时代,云应用程序接口(API,application programming interface)作为服务交付、能力复制和数据输出的最佳载体,已成为当今数字世界的基础设施[1]。云API 正在成为人工智能技术“飞入寻常百姓家”的重要管道[2],和实现面向服务软件开发与运行的核心要素。
然而,网络中云API 的激增使用户越来越难从众多功能同质化的云API 中选择高质量、个性化的云API 进行面向服务的软件开发。为了应对上述问题,研究者引入服务质量(QoS,quality of service)来刻画云API 的非功能侧特性[3],以表征云API 在某一方面的质量信息,如响应时间、吞吐量和可靠性等。但是由于高昂的时间成本、巨大的资源开销和服务质量情境依赖的特点,用户无法调用并测试全部候选云API 的性能来获取相应的服务质量数据,云API 提供商也很难提供符合用户情境特征的服务质量数据,故服务质量感知云API 推荐系统成为解决这一矛盾的自然选择[4]。将具备良好性能的云API 推荐给适用的人群,一方面可帮助用户从海量的云API 中发现高质量、高价值的云API;另一方面可辅助云API 提供商了解所提供云API 的服务质量,使其不断优化云API 并将高质量云API 提供给用户。
为了确保服务质量感知云API 推荐系统的客观性和准确性,广泛采用的策略是使用调用过云API的其他用户的服务质量历史记录,将此历史交互记录作为云API 推荐系统的数据基础[5]。值得注意的是,准确可信云API 推荐系统的一个重要前提是确保用户提交的每个服务质量的评估信息真实可靠。然而,由于云API 推荐系统自身的开放性,数据的真实性无法得到有效保证。例如,一些用户可能在服务质量评估时,为提高某些云API 的利用率而故意降低其他云API 的服务质量评分。服务提供商可能利用一些虚假用户故意提高自己的云API 的服务质量,从而影响用户反馈信息的可信度,使推荐模型产生错误,使推荐方向遵循攻击者的意愿[6]。因此,如何有效利用服务质量的差异来检测虚假用户,以抵御数据投毒攻击成为服务质量感知云API推荐系统应用亟待解决的现实问题。
目前,鲜有服务质量感知云API 推荐系统考虑虚假用户数据投毒攻击的影响。Zheng 等[7]提出服务质量感知云API 推荐系统将受到用户贡献的服务质量数据可信度的高度影响。Ye 等[8]在进行云API推荐时,仅将离群点作为虚假用户的恶意行为,并引入改进的正则项来避免虚假用户对推荐性能的影响。Manikrao 等[9]和Ran 等[10]提出通过第三方代理验证所有可用云API 服务质量的注册表,以提高云API 推荐系统的可信度。
可见,已有方法主要基于离群异常点检测[8,11]和代理验证[9-10,12]等策略进行服务质量数据安全防护,但没有考虑到在利用服务质量进行云API 推荐之前,服务质量数据在收集、存储和预处理过程中可能受到的来自恶意用户的数据投毒攻击。基于此,本文提出从服务质量感知云API 推荐系统数据端防御的视角出发,建立基于多特征融合的数据投毒攻击检测模型进行虚假用户检测,继而去除虚假用户以提高云API 推荐系统的可靠性和可信性。
本文主要的贡献如下。
1) 提出了面向服务质量感知云API 推荐系统的数据投毒攻击与检测问题,给出了服务质量感知云API 推荐系统数据投毒攻击与检测的形式化定义。
2) 提出了融合用户邻域(neighborhood)特征、QoS 深度特征和解释(interpretation)特征的数据投毒攻击检测(NQI-Detector)方法,从多个维度捕获虚假用户和真实用户的特征差异,提升数据投毒攻击的检测效果。
3) 在真实云API 服务质量数据集上进行大量实验,结果表明NQI-Detector 在面向服务质量感知云API 推荐系统的投毒攻击检测中展示出更优的检测效果。消融实验还解释了所提取特征的有效性。
1 基本概念
1.1 云API 推荐系统数据投毒攻击定义
数据投毒攻击[13]是指攻击者通过向原始数据集中注入脏数据来达到污染数据分布的目的,使数据分布出现偏差或错误,造成云API 推荐系统向用户推荐无质量保障的云API,继而导致构建的服务化软件质量无法得到保障,给企业带来商业风险。
一般来说,攻击者为了避免投毒数据被检测出来,通常会在构建的虚假用户数据中加入真实数据或使虚假用户数据分布与真实用户相似。虚假用户构建完成后批量注入推荐模型中来影响模型的训练和推荐结果。
定义1云API 推荐系统数据投毒攻击。服务质量感知云API 推荐系统数据投毒攻击表示为
1.2 云API 推荐系统数据投毒攻击方式
为了避免被发现,攻击者通常会根据云API 推荐系统的知识使用特定的攻击模型生成虚假用户配置文件[14]。不同攻击模型采用不同的方式来建立攻击文件,以模拟真实用户的服务质量数据。通常,一个虚假用户的攻击数据由四部分构成,即其中,AS是选择填充项集合,通常与目标云API 有一定的关联,以最大化攻击的有效性;AF是随机填充项集合,随机选取一组云API 用来伪装攻击者的攻击行为;AΦ是空白项集合,即用户未调用过的云API 集合;AT是目标项集合,一般包含一个或一组云API,根据投毒攻击用户的攻击目的来给目标云API 分配服务质量数据。
根据选择填充项的不同以及随机填充项的差异,数据投毒攻击可分为以下3 种类型:随机(Rnd,random)攻击、潮流(Bdg,bandwagon)攻击和均值(Avg,average tack)攻击。上述3 种数据投毒攻击需要消耗的攻击成本有所区别,所带来的攻击效果也将有所不同,具体对比如表1 所示。
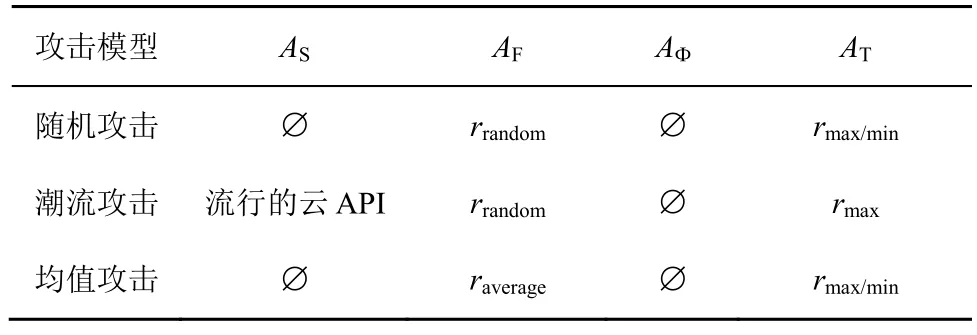
表1 数据投毒攻击方式对比
为了表示攻击者想要同时提高或降低多少云API 被推荐的概率,将AT的数量定义为攻击强度ε。因此通过数据投毒攻击模型f(·) 生成虚假用户的过程可以表示为u′=fx(AS,AF,AΦ,AT,ε),其 中,x={Avg,Rnd,Bdg}。
此外,考虑到攻击成本的限制,攻击者只能将有限的虚假用户注入数据集中,引入攻击规模b来表示一次性注入虚假用户的数量。因此,虚假用户投毒数据可进一步表示为其中,ξ(·) 表示虚假用户选取规则。
1.3 云API 推荐系统数据投毒攻击检测
2 云API 推荐系统的投毒攻击检测框架
面向服务质量感知云API 推荐系统的数据投毒攻击检测框架如图1 所示。该检测框架针对已被数据投毒攻击的云API 推荐系统,从多个角度提取用户特征,包括邻域特征、服务质量深度特征和解释特征,并融合提取的多个用户特征建立模型完成数据投毒攻击检测。具体包括以下4 个步骤。
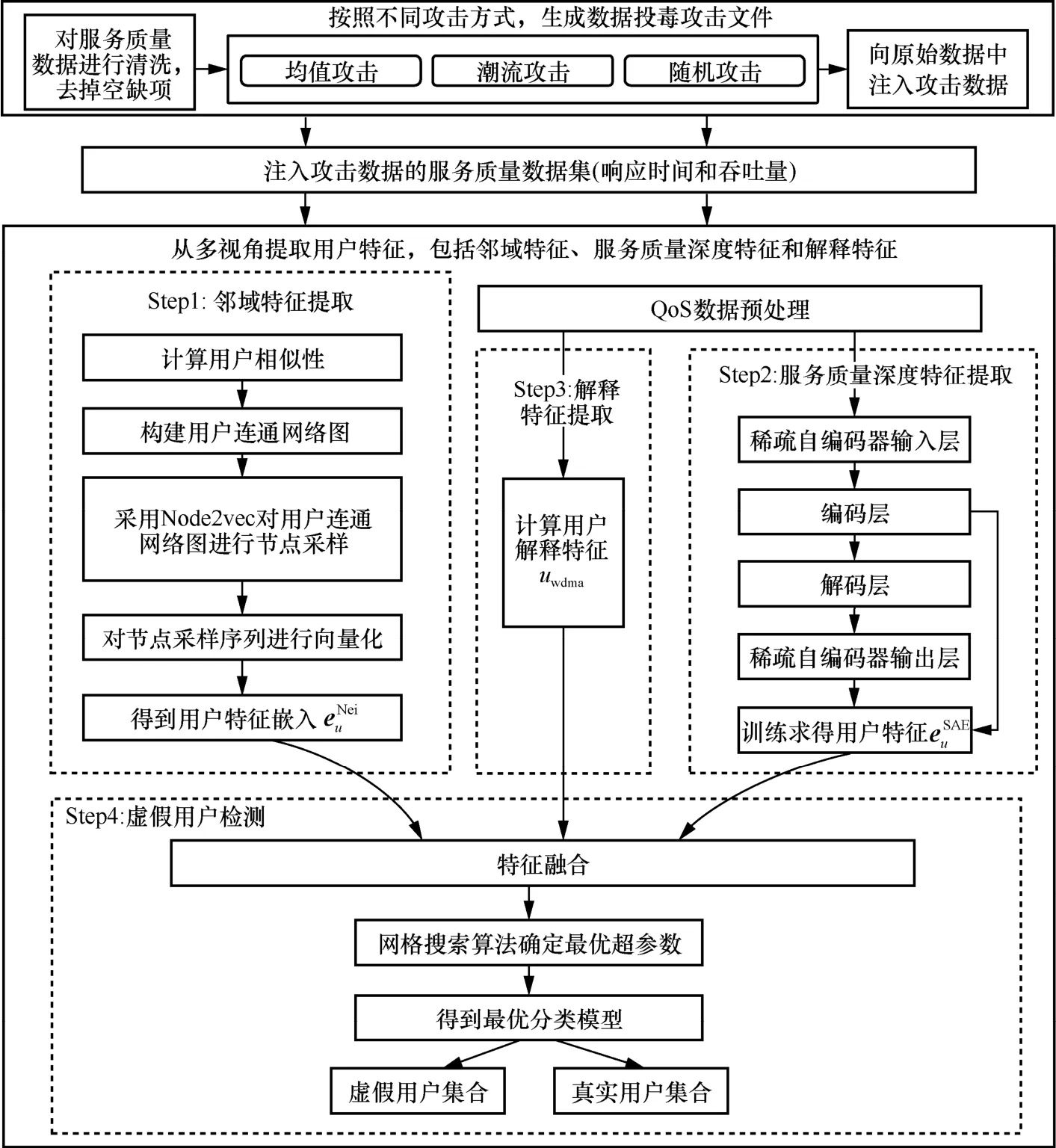
图1 面向服务质量感知云API 推荐系统的数据投毒攻击检测框架
Step1邻域特征提取。通过用户相似性函数来计算边缘权重,据此构建基于用户相似性的连通网络图,并使用Node2vec 算法捕获用户邻域特征。
Step2服务质量深度特征提取。从服务质量数据出发,利用稀疏自编码器(SAE,sparse autoencoder)模型挖掘用户潜在服务质量深度特征。
Step3解释特征提取。引入用户数据加权平均偏差设计用户解释特征。
Step4虚假用户检测。结合网格搜索算法优化虚假用户检测器得到最后的分类结果。
3 投毒攻击检测模型的建立
3.1 邻域特征提取
以往的研究中,皮尔逊相关系数通常用于衡量用户之间的相关性。然而,用户-云API 的服务质量的交互历史数据十分稀疏,皮尔逊相关系数很容易受到数据稀疏性的影响,当共同交互项数量很少时,很难通过少量的共同交互数据来准确评估2 个用户的相似性[15-16]。由表1 可知,相同的攻击模型具有相似的选择填充方式,基于此,本节从用户与云API 交互行为的相似性中提出边缘权重度量,该度量根据服务质量的相关信息(如选择项、填充比率差异和评级偏差)进行计算,综合分析共同交互项的数量和交互数据偏差来衡量用户相似性。进一步,搭建用户连通网络进行邻域特征提取。
定义3用户相似性。2 个用户之间的相似性是指用户的服务质量数据的相似程度。具体地,用户u和v之间的相似性为
其中,Ua表示与云APIa产生过交互的用户u集合,λ表示用户u和v所调用云API 的影响参数。用户u和v的服务质量偏差判定函数δ(ru,a,rv,a)为
其中,τ表示2 个用户与同一个云API 交互产生的服务质量偏差阈值,当偏差超过τ时,有理由认为2 个用户的服务质量体验不同,用户之间的相似性不强。当2 个用户之间的相似性够强时,即S(u,v)的值足够大时,会在用户连通网络图中的2 个顶点(或用户)之间创建一条边。由于虚假用户和真实用户之间具有不同的相似性模式,因此可以利用距离阈值拉近相似性更强的用户。但是这一阶段计算的用户距离不足以充分表示虚假用户和真实用户之间的差异。为了发现更深层和更稳定的关系,利用Node2vec 算法基于用户连通网络图对用户的邻域特征进行进一步提取。
Node2vec 算法同时考虑了网络结构的同质性和结构相似性[17],在随机游走模型的基础上,通过参数p和参数q控制随机游走过程中的邻域采样策略。当p> 1时,偏向广度优先搜索(BFS,breadth first search)策略;当q< 1时,偏向深度优先搜索(DFS,depth first search)策略。Node2vec 随机游走采样策略如图2 所示,在广度优先采样策略下,节点u1的向量与其邻居节点u2~u5相近,表现出较大的同质性;在深度优先采样策略下,首先通过深度延伸,节点u1的向量和u7的向量相近,表现出结构的相似性。
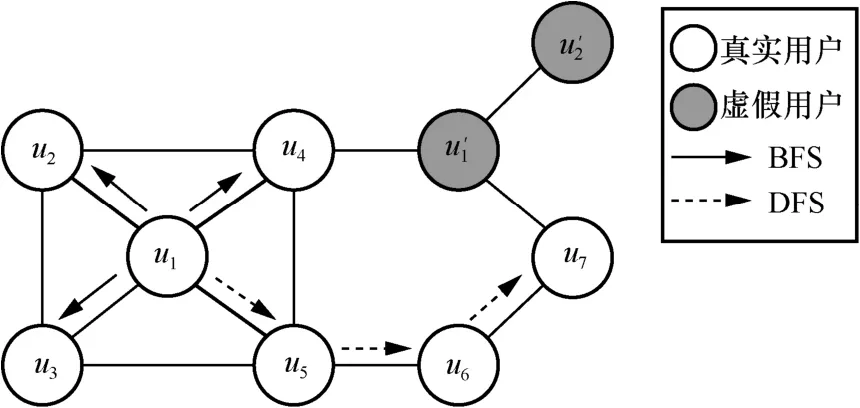
图2 Node2vec 随机游走采样策略
用户邻居信息嵌入是将用户实体和邻居关系参数化为向量表示。在搭建好的用户连通网络图中,优化的目标是在给定目标节点的条件下,使目标节点和其邻居节点同时出现的概率最大,确保当前节点下一步能转移到邻居节点。因此,目标函数为
其中,u表示任意节点(用户),NS(u)表示采样序列中节点u的邻居节点。在一个节点游走序列中,任意节点出现的概率等于该节点之前的所有节点出现概率的乘积,具体形式为
假设一个节点作为源节点和作为近邻节点时共享相同的特征向量空间。那么,式(6)中的条件概率式可进一步表示为
其中,E(·) 是节点特征向量映射函数,V是连通网络图中节点集合。综上,式(5)中的目标函数可更新为
3.2 服务质量深度特征提取
自编码器(AE,autoencoder)能够从原始输入中提取特征,其结构通常包含输入层、编码层和解码层。将服务质量数据x作为AE 的输入,并通过式(9)得到编码作为隐式特征。
其中,fp表示编码层的激活函数,W(1)表示编码层的权重矩阵,s表示编码层偏置向量。
类似地,解码层的向量可以通过式(10)来重构输入向量。
其中,fq表示解码层的激活函数,W(2)表示解码层的权重矩阵,t表示解码层的偏置向量。
AE 中的特征提取可以被描述为最小化输入和输出之间的误差的过程,将AE 中的参数表示为Θ={W(1),W(2),s,t},AE 的目标函数为
其中,L(·) 是输入空间的损失函数。在目标函数的推进下更新所有参数,获得最优解。
在进行分类任务提取特征时,原始的自编码器只是简单地充当恒等函数,不能准确反映训练服务质量数据集的独特统计特征。一般在重建训练数据的过程中,需要使隐藏层节点数小于输入节点数,但是也可以在增加隐藏层节点数的同时,对其加入一定的稀疏限制来达到同样的效果,确保每次得到的特征编码尽量稀疏。
为了限制隐藏层节点数和活跃度,使大部分隐藏层的节点被抑制,小部分被激活,达到稀疏化数据特征的目的。本文采用稀疏自编码器提取用户服务质量深度特征,故原始基于AE 的编码和解码过程式(9)和式(10)更新为
本文引入KL(Kullback-Leibler)散度为模型添加稀疏性限制,使隐藏层大部分节点的活跃度很小。因此,式(11)的重构误差可以进一步表示为式(14),当目标函数J(SAE)(Θ)取最优值时,挖掘得到隐式特征。
其中,β表示惩罚因子,选取Sigmoid 函数作为激活函数,神经元的输出接近激活函数上限1 时,该神经元状态为激活;当神经元的输出接近激活函数的下限0 时,该神经元状态为抑制。那么当某个约束或规则使神经网络中大部分神经元的状态为抑制时,该约束为稀疏性限制,KL 散度作为交叉熵与信息熵的差值,其计算式为
3.3 解释特征提取
服务质量感知云API 推荐系统的数据投毒攻击的特点在于,攻击者在预测平台上注入大量虚假用户的服务质量数据,以获取符合自身意图的推荐结果。服务质量感知云API 推荐系统的脆弱性与其过于依赖底层交互数据(如用户提交的服务质量)来训练模型以及无法有效区分真实用户和虚假用户有关。由于解释特征能很好地标记带给推荐系统性能变化的攻击者,本文引入用户数据加权平均偏差(WDMA,weighted deviation from mean agreement)uwdma作为用户解释特征,其具体形式为
其中,Nu表示所有与用户u交互的云API 的数量,Na表示云APIa被调用的数量。用户解释特征uwdma能很好地衡量用户对一组云API 的服务质量相对于其他用户的偏差,同时针对稀疏云API 的服务质量偏差给予较高权重,平衡服务质量稀疏性所带来的问题,带来很高的信息增益。
3.4 虚假用户检测
邻域特征提取模块、服务质量深度特征提取模块和解释特征提取模块从多角度得到了用户的多元嵌入表示,将多特征进行融合作为最终虚假用户检测模块的输入,即
在虚假用户检测模块中使用改进的网格搜索算法[18]对SVM 模型中的超参数进行优化,通过穷举搜索找到分类模型中的最优参数。改进的网格搜索算法流程如图3 所示。
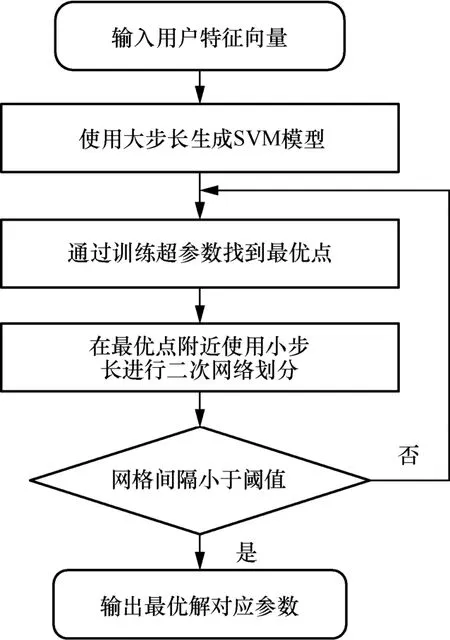
图3 改进的网格搜索算法流程
本文中使用的改进的网格搜索算法将惩罚参数c和不同核函数中的核参数a分别取M和N个预设超参数值域,以笛卡儿积的形式生成M×N个(c,a)的参数组合,利用不同的参数组合训练不同的SVM 分类器,从而在M×N个参数组合中得到准确率最高的分类器对应的参数作为最优参数。
4 算法设计
检测方法NQI-Detector 将数据投毒攻击检测分为用户特征提取和虚假用户检测2 个步骤。
4.1 用户特征提取
用户特征提取步骤如算法1 所示。
算法1用户特征提取
算法1中第1)~7)行是计算用户相似度,并构建基于相似性的用户连通网络图G。第8)~14)行是用户邻域特征的表示学习,通过优化学习参数计算节点采样序列,得到节点采样序列的向量化表示。第15)~18)行得到了用户-云API 服务质量深度特征表示,通过反向传播训练稀疏自编码器更新参数。第19)~20)行按照式(16)得到用户解释特征。
在时间复杂度方面,算法1 在生成用户连通网络图G时,第2)行遍历|U|次,在第3)行计算目标用户u遍历所有邻居节点v∈U计算相似性,故第1)~7)行的时间复杂度为O(|U|2)。在用户邻域特征提取中,问题规模为|U|,故第8)~14)行的时间复杂度为O(|U|)。第15)~20)行计算时间复杂度为O(1)。综上,算法1 的时间复杂度为O(|U|2+|U|)。在空间复杂度方面,第1)~7)行需借助一个大小为|U|×|U|的辅助矩阵来存储用户连通网络图G,故其空间复杂度为O(|U|2)。在第8)~14)行提取用户邻域特征时,需要借助2 个变量walk、walks 以及用户邻域特征向量与问题规模即用户集合U的大小无关,故其空间复杂度为在第15)~20)行服务质量深度特征和解释特征提取中,仅需要借助3 个变量DN、SAE、uwdma以及用户邻域特征向量故其空间复杂度为综上,算法1 的空间复杂度为
4.2 虚假用户检测
虚假用户检测步骤如算法2 所示。
算法2虚假用户检测
算法2 的第1)行将算法1 中提取的特征通过拼接操作进行特征融合,第2)~12)行从网格优化搜索中找到最合适的参数,第13)~14)行利用训练得到的参数完成虚假用户检测。
在时间复杂度方面,算法2 采用改进的网格优化算法训练SVM,在第2)~5)行以嵌套方式通过2 个for 循环获得SVM 最优的惩罚参数c和核参数a。在第6)行训练SVM 执行时,需要遍历第1)行获取的用户特征向量eu,故算法2 的时间复杂度为O(M×N×|eu|),其中,M为惩罚参数c的预设值集合的大小,N为核参数a的预设值集合的大小。在空间复杂度方面,算法2 第1)行需借助一个大小为|eu|的辅助数组存储用户特征向量,故其空间复杂度为O(|eu|)。第2)~12)行进行SVM 模型训练时,仅需借助 svmscore、bestscore和best_parameters 等变量,与问题规模M×N无关,故其空间复杂度为O(1)。综上,算法2 的空间复杂度为O(|eu|)。
由于算法1 和算法2 以线性方式顺序运行,故NQI-Detector 整体的时间复杂度为O(|U|2+|U|+M×N×|eu|),空间复杂度为其中由于M、N和|eu|在算法实际执行时均为有限值,故NQI-Detector 的时空复杂度主要依赖于问题规模|U|,NQI-Detector 可应用于大规模云API 推荐系统的数据投毒攻击检测。另外在数据给定后,以预处理方式执行算法1 进行用户特征提取,可进一步提升NQI-Detector 对投毒攻击检测的整体时空效率。
5 实验与分析
5.1 实验准备
1) 实验数据。本文实验数据来自真实世界的云API 服务质量数据集WS-DREAM[19]。WS-DREAM记录了真实世界的多个云API 被分布在不同地理位置的339 个用户调用所产生的服务质量数据。实验数据统计信息如表2 所示。
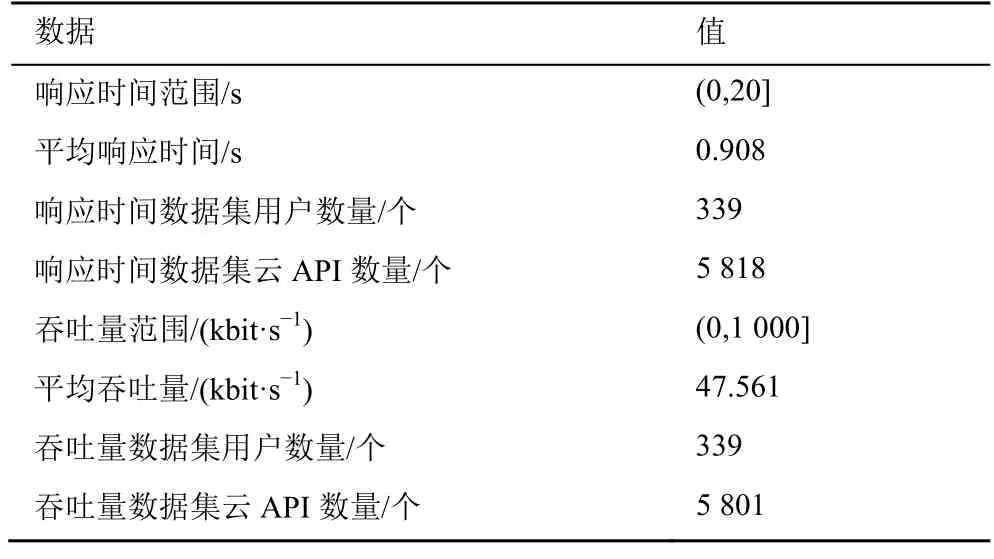
表2 实验数据统计信息
在开放网络环境下,网络中可用云API 数量很多,但是单个用户通常只调用过少量云API,因此用户-云API 服务质量矩阵是十分稀疏的。为了使实验与真实的云API 应用场景保持一致,在用户-云API 服务质量矩阵上采用A/B模式来稀疏化服务质量数据集。
2) 参数设置。由于不同类别的服务质量数据变化范围不同,服务质量偏差阈值τ的取值依赖于具体服务质量类型。因此,在响应时间数据集中设置偏差阈值τ=5,吞吐量数据集中设置偏差阈值τ固定为250。此外,SVM 模型惩罚参数c和核参数a在响应时间数据集中设置为(5,0.5),在吞吐量数据集中设置为(20,0.5)。
3) 评价指标。为了评估虚假用户检测效果,采用广泛使用的准确率(Precision)、召回率(Recall)和F1 值作为评价指标,分别定义如下
其中,TP 表示正确判断出的正例数量,FP 表示被误认为正例的数量,FN 表示被误认为负例的数量。
4) 实验环境。硬件环境:英特尔处理器(四核),内存32 GB。软件环境:编程语言Python3.0,编程环境VS Code。
5.2 对比实验
考虑到目前还没有专门的针对服务质量感知云API 推荐系统的数据投毒攻击检测算法,为了证明所提方法检测性能的准确性和优越性,选择4 种先进的数据投毒攻击检测算法,将其迁移到云API服务质量感知推荐领域,进行对比分析。4 种对比数据投毒攻击检测算法如下。
1) PCA-VarSelect[20]。典型的无监督投毒攻击检测算法,可自动构建用户特征,通过概率潜在语义分析(PLSA)找到具有相似偏好的用户群体,结合PCA-VarSelect 从多元统计学角度重新描述评级矩阵。
2) Bayes-Detector[21]。一种有监督虚假用户检测方法,利用矩阵分解为每个用户构建隐式特征,随后使用贝叶斯模型生成潜在标签信息来更新隐式特征以完成虚假用户检测。
3) DL-DRA[22]。一种有监督方法,使用双三次插值算法减少评级矩阵的稀疏性,并使用结构化深度学习网络进行检测。
4) DSAE-EDM[23]。一种深度学习投毒攻击集成检测方法,直接采用深度自动编码器自动提取用户的潜在特征以达到攻击检测的效果。
为了验证所提方法能否很好地解决面向服务质量感知云API 推荐系统的数据投毒攻击检测问题,实验分别在响应时间数据集和吞吐量数据集上进行数据投毒攻击检测方法的比较分析。此外,考虑到当数据投毒攻击规模较小时,通常很难区分虚假用户和真实用户。在实验过程中,将攻击强度设置为4%,攻击规模分别设置为3%、5%、10%和25%,以F1 值为评价指标,实验结果如图4 所示,具体分析如下。

图4 不同数据投毒攻击检测方法的对比结果
1) 在攻击强度确定的前提下,当随机攻击的攻击规模设置为3%时,PCA-VarSelect 的F1 值低于0.8,无法有效区分真实用户和虚假用户。这是由于传统攻击检测算法PCA-VarSelect 的数据降维过程是线性的,在恢复数据时会有一定程度的失真。NQI-Detector 能够非线性提取用户特征,在低攻击强度下达到很好的效果。当攻击强度增大到25%时,DSAE-EDM 和DL-DRA 都可以有效检测。
2) 潮流攻击中,在低攻击规模下的响应时间数据集中,DSAE-EDM和DL-DRA的F1值都不到0.85,没有很好地完成虚假用户的潮流攻击检测。考虑到具有相似情境的用户所具备的服务质量也相似,只挖掘服务质量数据特征是不够的,NQI-Detector 与DSAE-EDM 相比,构建了基于相似性的连通网络,增加了对用户邻域特征的挖掘,达到了强化用户特征的目的,不但克服了传统的人工检测特征在面对不同类别的攻击时所展现出来的普适性不强的问题,而且增加了虚假用户识别的准确性。
3) 均值攻击下吞吐量数据集的检测任务的完成情况要明显好于响应时间数据集,其原因可能在于均值攻击自身的攻击特点,由于现实因素,吞吐量数据集的数据范围远大于响应时间数据集,导致依靠求取均值完成虚假用户填充项的均值攻击会更大地偏离真实用户的服务质量,这有利于几种虚假用户检测算法捕获到更明显的用户特征,从而取得更优的效果。
5.3 不同攻击强度下的检测效果分析
本节实验通过对云API 服务质量数据集注入不同攻击强度的数据投毒攻击来评价NQI-Detector 的性能,设置攻击规模为5%。所提方法固定攻击规模为5%的虚假用户时,分别注入不同攻击强度(4%、8%、12%和16%)的随机攻击、潮流攻击以及均值攻击的数据投毒攻击检测结果如图5 所示。从图 5 可以看出,随着攻击强度的增大,NQI-Detector 的召回率和准确率会逐渐提高,检测效果逐步增强。这也与具有较高攻击强度的数据投毒攻击更容易检测出攻击行为的预期一致。
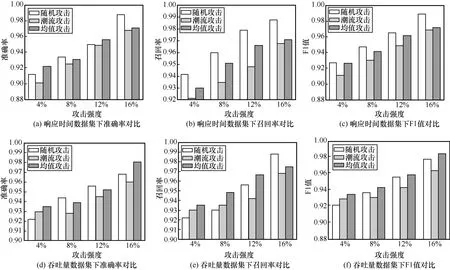
图5 不同攻击强度下的检测结果
5.4 不同攻击规模下的检测效果分析
本节实验通过对云API 服务质量数据集注入不同攻击规模的数据投毒攻击来评价NQI-Detector 的性能,设置数据投毒攻击强度为4%,NQI-Detector对不同攻击规模的3 种攻击在不同评价指标下检测效果对比如图6 所示。
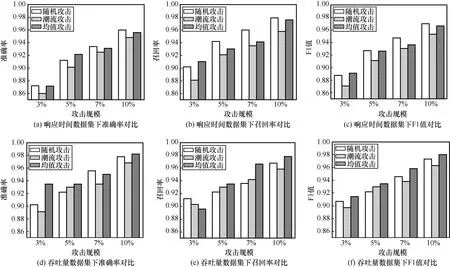
图6 不同攻击规模下的检测结果
一般情况下,注入5%规模的数据投毒攻击已经消耗了恶意用户很高的知识成本,选择攻击规模分别为3%、5%、7%、10%。从图6 可以看出,在较小和较大的攻击规模下,NQI-Detector 依然保持良好的检测能力,这也验证了其在云API 服务质量数据集上的检测有效性。在图6(c)和图6(f)的F1 值检测结果中,NQI-Detector 对潮流攻击的检测性能低于均值攻击的性能指标。这是因为采用潮流攻击生成虚假用户时,攻击者利用赋予流行云API 更优的服务质量来包装自己,将自己伪装成经常使用流行云API 的真实用户,使检测方法不易检测出来。此外,由于随机攻击在生成虚假用户时,虚假用户与云API交互产生的服务质量值具有不确定性,继而导致了随机攻击和潮流攻击、均值攻击之间的检测结果关系是不固定的。
5.5 敏感特征消融实验分析
为了进一步研究所提取的3 个检测特征的有效性,本节将设计6 个消融变体实验,以分析这些特征对提高数据投毒攻击检测的准确率是否有正向影响。给出组件x∈{N,S,W,NS,NW,SW},其中,N、S和W分别表示NS、NW和SW 分别表示相应特征组合,使用NQI-x表示实验对照组没有嵌入对应组件。表3 和表4 展示了在响应时间数据集和吞吐量数据集上的实验结果,攻击强度设置为4%,攻击规模设置为10%。
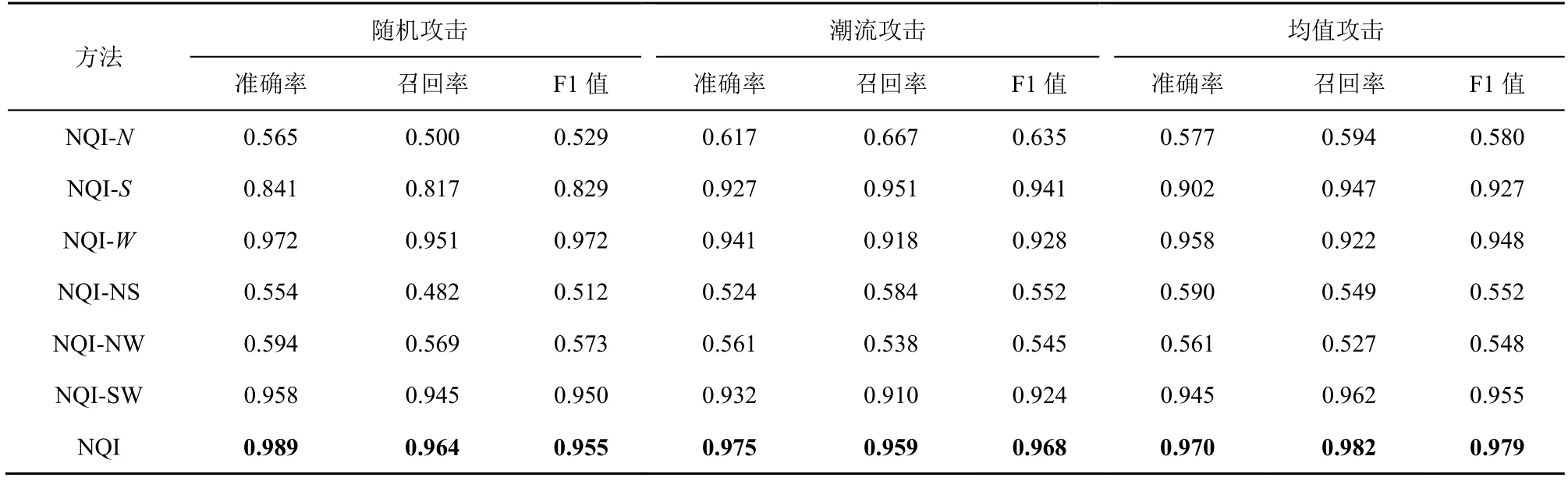
表3 在响应时间数据集上消融变体实验对比结果
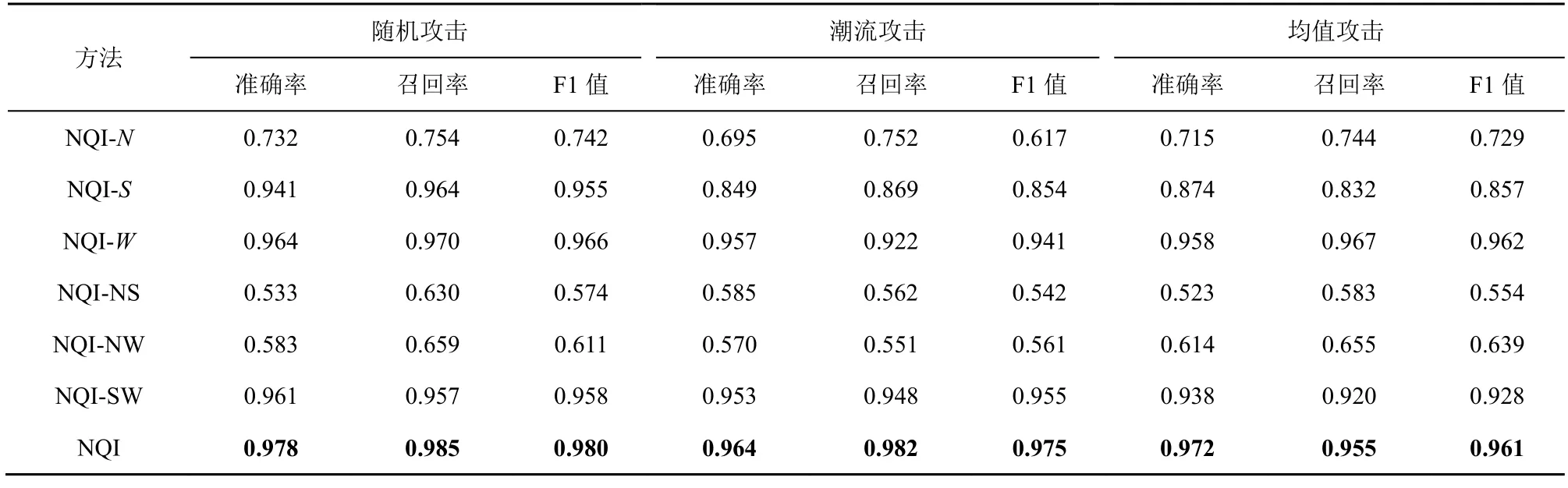
表4 在吞吐量数据集上消融变体实验对比结果
如表3 和表4 所示,NQI-N相对于NQI-S和NQI-W表现较差,这表明用户邻域特征在检测任务中起到了主要作用。此外NQI-NS 在面对各类投毒攻击时性能最差,这表明解释特征在单独应用于检测时表现出了较差的性能。然而,将解释特征和服务质量深度特征相结合可以有效地检测攻击者,这种改进在响应时间数据集上表现并不明显,但是在吞吐量数据集上,这2 种特征的结合更加有效。
5.6 提取特征可视化分析
Bayes-Detector 作为先进的使用隐式特征进行数据投毒攻击检测的方法。5.2 节实验结果表明所提NQI-Detector 比Bayes-Detector 方法更加有效。为了探究这一原因,采用可视化方法来分析所提取的用户特征表示。本节实验使用Maaten 等[24]提出的T-SNE(T-distributed stochastic neighbor embedding)对提取的特征可视化处理,T-SNE 将高维数据内部的特征放大,使相似的数据在低维中距离更近,不相似的数据在低维中距离更远。使用T-SNE 分析2 种方法所提取的服务质量数据集上的用户特征,响应时间数据集和吞吐量服务质量数据集上2 种数据投毒攻击检测方法所提取的用户特征的视化结果如图7 所示。
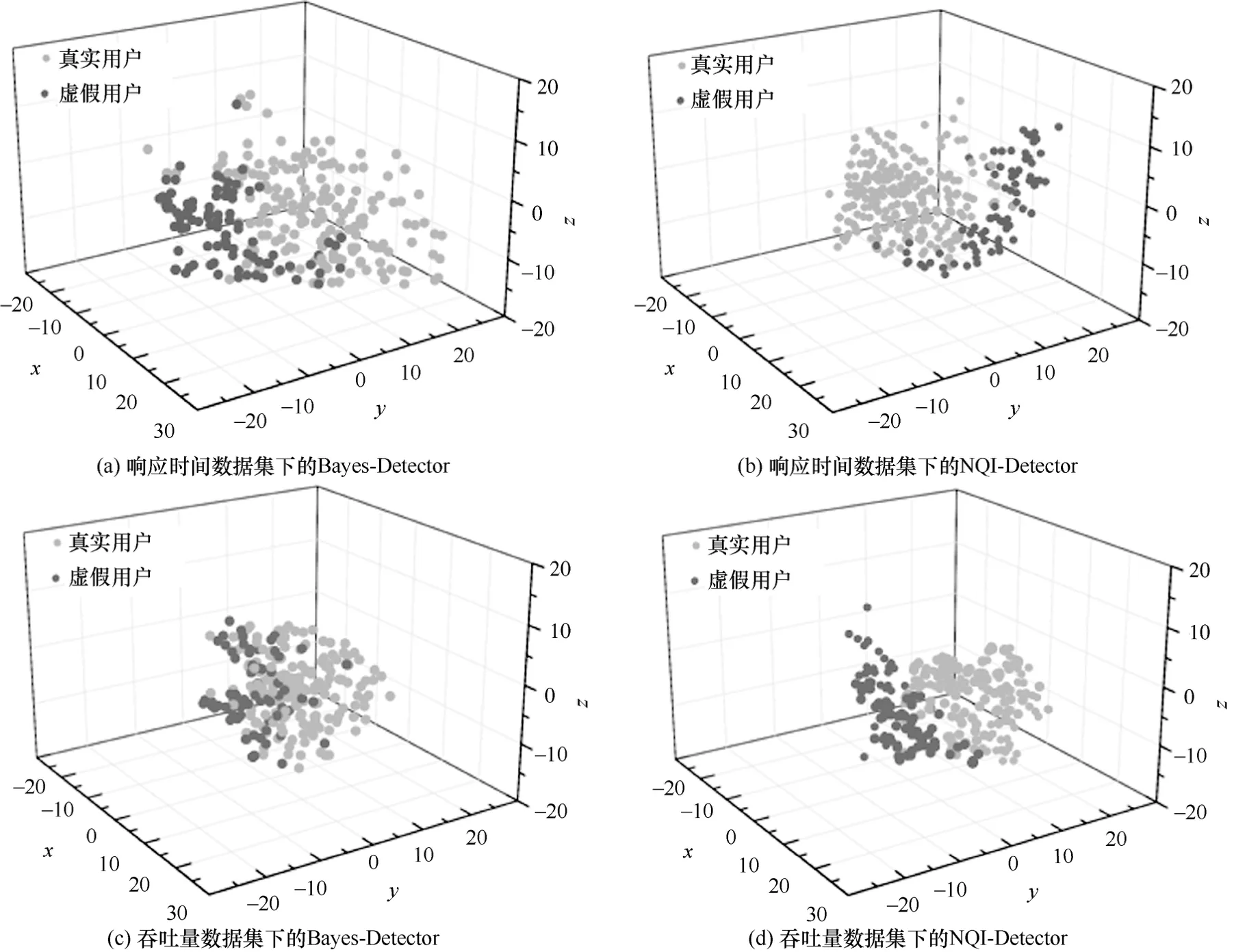
图7 不同服务质量数据集下的用户特征可视化分析
从图 7 可知,与 Bayes-Detector 相比,NQI-Detector 所提取的用户特征中重叠的用户数量更少,相似用户的特征分布更紧密,虚假用户与真实用户之间的边界更清晰。因此,NQI-Detector 在检测云API 服务质量数据集中的虚假用户时更有效。
6 结束语
为了解决服务质量感知云API 推荐系统中的数据投毒攻击问题,本文提出了一种面向服务质量感知云API 推荐系统的基于多特征融合的数据投毒攻击检测方法。首先,根据设计的相似性函数构建了用户连通网络图,利用Node2vec 算法通过图上的随机游走捕获用户邻域特征;其次,从服务质量数据视角,利用稀疏自编码器挖掘用户服务质量深度特征表示,并构建了用户解释特征。然后,采用特征嵌入技术连接用户的邻域特征、服务质量深度特征与解释特征,实现了用户的多元嵌入表示。在此基础上,结合网格搜索优化虚假用户检测器,提升高维稀疏环境下虚假用户的检测效果。最后,从多个方面进行实验,系统地分析了所提出的数据投毒攻击检测方法在服务质量感知云API 推荐系统中的有效性。
