面向纵向联邦学习的对抗样本生成算法
2023-09-19陈晓霖昝道广吴炳潮关贝王永吉
陈晓霖,昝道广,吴炳潮,关贝,王永吉
(1.中国科学院软件研究所协同创新中心,北京 100190;2.中国科学院大学计算机科学与技术学院,北京 100049;3.中国科学院软件研究所集成创新中心,北京 100190)
0 引言
作为人工智能训练的基础,数据在推动机器学习的发展中扮演着核心角色。据预测,互联网数据量在2025 年将暴增至175 ZB[1]。而伴随全球范围内公众对数据安全的日益关注以及数据安全相关法律法规的实施,数据在各机构与企业间的流通受到严格约束[2-4]。因此,研究合规的数据获取和使用方法成为人工智能领域的重要挑战。自2016 年谷歌公司首次将联邦学习[5]作为一种解决方案以来,它便受到了广泛的关注。
根据Yang 等[6]的划分方式,联邦学习应用可以按照数据分布分为横向联邦学习与纵向联邦学习(VFL)2 种类型。横向联邦学习针对的是参与方数据样本空间不同而数据特征空间相同的情况。纵向联邦学习针对的是参与方数据特征空间不同而数据样本空间相同的情况,这种建模方式适用于不同业务属性的参与方协同建模。纵向联邦学习在国内不同领域得到了广泛应用。例如,微众银行[7]使用本地持有的用户授信数据和合作公司持有的用户消费信息构建了风控领域的纵向联邦神经网络,提高了风险识别能力;字节跳动公司[8]通过纵向联邦树模型引入外部数据源构建了一个推荐领域的纵向联邦树模型,广告投放增效209%;此外,纵向联邦模型还应用到智能制造[9]和智能电网[10]等领域,在保护数据隐私的同时处理预测任务。
随着纵向联邦学习的广泛应用,其安全性问题逐渐受到研究人员关注。Zhu 等[11]提出了梯度泄露问题,在该问题中,建模过程的中间传输变量或传输梯度会泄露一部分的原始数据信息,恶意参与方据此可以推理原始数据。此后,许多研究人员分别在模型训练阶段和推理阶段设计了不同的攻击方案。在训练阶段,Weng 等[12]针对逻辑回归模型和集成树模型通过反向乘法攻击和反向求和攻击的方式重构原始数据;Fu 等[13]针对纵向联邦学习网络提出了3 种标签推理攻击的方式,包括补全本地模型的被动标签推理攻击、增加本地模型权重占比的主动标签推理攻击以及梯度标签的直接标签推理攻击。在推理阶段,Luo 等[14]提出了一种模型逆向攻击的通用推理框架,该框架借助生成模型并通过观察模型的输出来反向更新恢复样本的原始数据;Jin 等[15]则利用样本对齐提供的样本空间信息,采用逐层迭代的方法来恢复原始数据;Yang 等[16]利用零阶梯度估计的方式计算模型参数构造推理模型,从而对原始数据进行特征推理攻击。这些方法的攻击目标是纵向联邦数据的隐私性,而纵向联邦学习模型同样可能受到恶意参与方数据篡改,引发模型安全性威胁,例如本文研究的对抗攻击。
联邦学习的对抗攻击指的是恶意参与方在推理阶段利用持有的样本部分特征构建对抗样本,削弱全局模型的预测能力。纵向联邦学习场景具备高通信成本、快速模型迭代和数据分散式存储的特点,具体如下。1)纵向联邦学习框架在实现模型的协同训练或推理过程中,各参与节点需要进行多轮次的参数和数据交换,这造成了极大的通信成本[17]和计算负担[18]。2)纵向联邦学习模型在应用及上线过程中会定期进行版本迭代以适应数据的变化并提升模型性能。③在纵向联邦学习场景中,数据被分散存储于不同的参与方本地[6],恶意参与方仅能获得本地特征空间权限,并通过勾结或推理攻击[14-15]来获取部分样本空间的其他特征数据,而获取全局样本空间是有挑战性的。基于上述场景特点,纵向联邦场景下生成的对抗样本需要具备较高的生成效率、鲁棒性及泛化能力。
为了解决上述问题,本文首先对纵向联邦学习场景中的对抗攻击、集中式机器学习的对抗样本生成算法和生成对抗网络进行理论介绍;其次,提出了纵向联邦学习的对抗样本生成框架并扩展6 种集中式机器学习对抗样本生成算法作为基线算法;再次,在上述框架下提出了一种生成算法VFL-GASG;最后,通过实验验证所提算法相比于其他算法在效率、鲁棒性和泛化性方面的能力,并进一步验证实验参数对攻击效果的影响。本文贡献主要包括以下3 个方面。
1) 本文在纵向联邦学习场景下提出了一种具备高扩展性的白盒对抗样本生成框架,恶意参与方通过局部样本特征构造对抗样本从而影响模型的准确性,该框架可以适用于基于有限内存的拟牛顿求解(L-BFGS)[19]、符合梯度法(FGSM)[20]等多种集中式机器学习对抗样本生成策略。
2) L-BFGS、FGSM 等对抗样本生成算法均基于输入迭代构造对抗样本,而纵向联邦学习环境中获取全局样本空间是有挑战性的。本文在上述框架下提出了一种基于生成对抗网络的对抗样本生成算法VFL-GASG,该算法将本地特征的隐层向量作为先验知识训练生成模型,经由反卷积网络产生精细的对抗性扰动,然后借助生成模型从少量样本中学习到对抗性扰动的通用生成算法,从而有较好的泛化能力。
3) 本文在MNIST 和CIFAR-10 等数据集上通过实验验证了VFL-GASG 算法在效率、泛化性、鲁棒性方面的表现。此外,实验发现,即使在只有恶意参与方数量和所持特征数量较少的情况下,对抗攻击也会显著影响模型的性能。最后,通过实验验证不同实验参数对于对抗攻击的影响。
1 理论基础
1.1 纵向联邦学习的对抗攻击
1.1.1纵向联邦学习架构
纵向联邦学习的参与方数据集在样本维度上有重叠,但在特征维度上分布不同,即不同特征空间的参与方在中央服务器的协调下进行联合建模。图1 是一种典型的纵向联邦学习训练流程。①中央服务器和各参与方进行样本对齐,使不同参与方的样本空间同步;②参与方依据本地特征和本地模型进行模型计算,并将结果上传作为全局模型的输入;③中央服务器收到上传数据后,依据全局模型进行模型计算;④中央服务器计算梯度和损失,并将梯度进行反向传播;⑤中央服务器和参与方分别更新全局模型与本地模型;⑥重复②~⑤,直到达到收敛条件。纵向联邦学习推理架构和图1 相似,由于不涉及模型更新,通过①~③就能完成数据推理。多种纵向联邦学习模型均在上述框架下进行部署,如 SecureBoost[21]、Fed-VGAN[22]和SplitNN[23]等。

图1 纵向联邦学习训练流程
1.1.2威胁模型
本文假设纵向联邦学习网络中存在某个恶意的参与方,该参与方利用训练完全的目标模型构造对样本进行攻击。纵向联邦学习场景下的威胁模型通过以下3 个部分进行刻画。
1) 攻击目标
恶意参与方进行对抗攻击的目标是通过在本地所持推理样本的部分特征上添加对抗性扰动,从而使模型在推理样本上分类错误。因此,本文所提算法的攻击效果可以由目标模型在推理集合上分类准确率的下降幅度来度量。
2) 攻击知识
在纵向联邦学习架构中,恶意参与方能够获取其本地数据以及本地模型的详细信息,并且具有训练及推理过程的模型输出和传递参数的完整知识。然而,对于其他参与方的信息,由于存在数据分布和模型架构的差异性,恶意参与方仅能获取其他参与方的嵌入层信息,而无法获知其他参与方的本地数据及模型结构等具体信息。
3) 攻击能力
在纵向联邦学习攻击过程中,恶意参与方可能执行如下操作。①恶意参与方篡改本地数据,以此扰乱模型的训练和推理过程。②恶意参与方修改本地模型和参数信息,并调用全局模型。③恶意参与方通过观测每个通信轮次的模型输出及嵌入层信息来推测其他参与方的信息。
在横向联邦学习攻击过程中,恶意参与方的攻击能力主要聚焦于训练过程的操控,包括在训练阶段篡改数据、模型和参数等信息,以及通过观测信息推测数据隐私。然而,在推理过程中,参与方使用服务器分发的全局模型对本地数据进行独立推理,其推理过程不易受其他参与方的干扰。因此,横向联邦学习中的恶意参与方在推理阶段的攻击威胁性较低[24],如本文中的对抗攻击。尽管目前的研究中许多学者采用对抗样本的生成算法在横向联邦学习的训练过程中实现数据投毒[25]或增强模型性能[26],但这并不属于推理过程的对抗攻击问题。相比之下,纵向联邦学习需要依靠多参与方进行联合推理,恶意参与方可以通过注入对抗性扰动至本地特征,干扰联合推理的结果。相较于横向联邦学习,纵向联邦学习更容易受到不可信来源的参与方对抗攻击的威胁。
1.2 集中式机器学习对抗样本生成算法
集中式机器学习与联邦学习的分布式策略有所不同,其中心节点通常需要汇总并处理所有数据以训练和推理机器学习模型。Szegedy 等[19]首次在集中式机器学习环境中提出了对抗攻击的概念,并向中心节点的真实样本添加微小扰动,尽管这些扰动并未显著改变样本的整体特性,却可能导致机器学习模型分类错误。集中式机器学习的对抗样本生成流程如图2所示。中心节点将训练好的分类模型作为对抗攻击的目标模型;然后,通过向原始图像添加扰动生成对抗样本,并通过目标模型的输出进行扰动迭代;直至满足设定条件,从而生成最终的对抗样本。
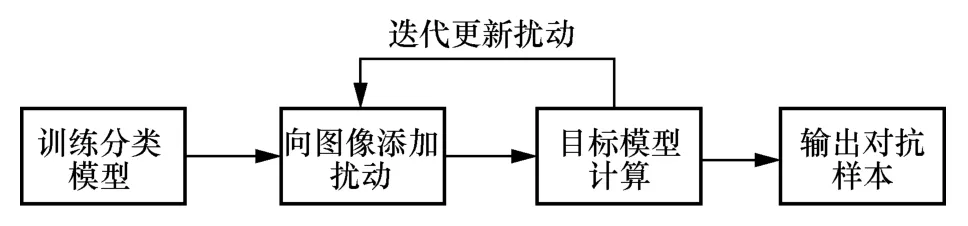
图2 集中式机器学习的对抗样本生成流程
在集中式机器学习环境中,已经发展出了多种对抗样本生成策略,其中代表性方法包括基于优化求解策略的L-BFGS[19]和C&W(Carlini&Wagner)[27],基于梯度迭代策略的 FGSM[20]、I-FGSM[28]、MI-FGSM[29],以及基于像素级扰动策略的显著图攻击(JSMA)[30]。下面介绍不同对抗样本生成算法的理论部分。
1) L-BFGS
Szegedy 等[19]最早提出了集中式机器学习的对抗样本生成算法L-BFGS,该方法将对抗样本的扰动计算转化为如下问题并通过拟牛顿法求解
其中,x是输入的原始图像特征,l是错误的分类标签,r是需要加入的对抗性扰动向量,ℓ 是损失函数。
2) FGSM
Goodfellow 等[20]提出了FGSM 方法,该方法通过计算模型损失相对于输入数据的梯度,在有限扰动的情况下沿着损失函数最大化的方向进行更新。对抗性扰动表示为
其中,ϵ用于控制扰动大小,x和y分别是输入图像特征和真实标签。
3) I-FGSM
Kurakin 等[28]采用迭代的策略,将增大分类器损失函数的过程分解为多个迭代步骤,迭代过程为
其中,α表示每次迭代的步长;Clip 表示裁剪函数,其对生成样本的每个像素进行裁剪,使迭代数据保持在原始图像的ϵ邻域范围内。
4) MI-FGSM
Dong 等[29]为了提升攻击的成功率,通过动量迭代来替代I-FGSM 中的梯度迭代信息策略,同时引入历史扰动来规避迭代过程可能产生的局部最优问题,提高迭代过程的稳定性。该过程可表示为
其中,rt+1和xt+1分别表示第t+1次迭代产生的扰动和对抗样本,μ表示衰减因子。
5) C&W
Carlini 等[27]则在L-BFGS 的优化问题基础上,通过映射变换解决像素溢出的问题,并引入置信度函数来控制错误概率。优化问题表示为
6)JSMA
Papernot 等[30]提出一种通过类别梯度生成像素显著图来筛选干扰像素对的方法。显著性映射为
其中,Zl(x)表示x在分类层l类上的输出。该方法利用显著图来筛选出对目标模型分类输出影响最大的特征对,并在对应像素点上施加扰动。
1.3 生成对抗网络
生成对抗网络(GAN,generative adversarial network)由Goodfellow 等[31]提出,它由生成器G和判别器D 两部分组成。GAN 的核心思想是通过生成器和判别器的对抗训练,学习数据的隐含分布,从而生成与真实数据相似的样本。具体来说,生成器G接收低维随机噪声作为输入并输出伪造样本,其目标是生成能够欺骗判别器的样本,使判别器难以区分真实样本和生成的伪造样本。判别器D 的任务是对输入样本进行判断,输出其作为真实样本的概率。综合考虑生成器和判别器的优化目标,可以表示为
自Goodfellow 首次提出生成对抗网络以来,许多研究者对其进行了改进。Arjovsky 等[32]采用Wasserstein 距离作为损失函数以缓解训练过程的梯度消失问题。Radford 等[33]提出了深度卷积生成对抗网络(DCGAN,deep convolutional generative adversarial network),这种方法将GAN 中的生成器全连接层替换为反卷积层,显著降低了模式坍塌现象出现的频率。在DCGAN 方法中,卷积层通过滑动窗口机制有效地提取高维图像特征,反卷积层则利用这些特征以逆卷积的操作进行图像重建。该方法显著地提高了在图像生成任务中生成对抗网络的训练稳定性。
2 纵向联邦学习对抗样本生成
2.1 问题定义
即最小化恶意参与方对抗性扰动的同时,使中央服务器全局模型在对抗样本上分类错误。表1 定义了纵向联邦学习对抗样本生成的相关参数。

表1 相关参数
2.2 纵向联邦学习对抗样本生成框架
如图3 所示,本文提出的纵向联邦学习对抗样本生成框架的流程如下:首先,每个参与方根据其本地模型和数据生成全局模型的输入;接着,联邦学习服务器根据全局模型执行计算,产生用于扰动的更新参数,并反馈给各个参与方,恶意参与方根据回传梯度等参数更新对抗样本;之后,对抗样本被作为恶意参与方的本地模型输入,经迭代更新,直至达到预设迭代次数或其他条件;最终,输出完成的对抗样本。详细过程如算法1 所示。

图3 纵向联邦学习对抗样本生成框架
算法1纵向联邦学习对抗样本生成框架
在该框架下,集中式机器学习对抗样本生成策略可以扩展至纵向联邦学习场景中,本文扩展了多种生成算法,如表2 所示,其中,VFL-LBFGS 和VFL-C&W 通过优化策略生成对抗样本,VFL-JSMA 采用像素级扰动方法生成对抗样本,VFL-FGSM、VFL-IFGSM 和VFL-MIFGSM 则是通过梯度迭代更新的方式产生扰动,这些算法将作为基准算法参与后续实验验证。

表2 纵向联邦学习对抗样本生成算法
2.3 基于GAN 的对抗样本生成
为了解决对抗性扰动的通用性问题,本文在算法1 框架下提出了一种基于GAN 的对抗样本生成算法VFL-GASG。其中,生成器负责生成噪声并将其注入真实样本形成对抗样本;判别器则对真实样本和对抗样本进行分类,以便更精确地辨别这2 类样本。该过程可分为模型训练和对抗样本生成2 个阶段。模型训练阶段指的是利用训练样本完成生成器和判别器的训练,以达到预定的生成目标;而对抗样本生成阶段则是指恶意参与方利用训练好的生成器生成对抗样本的过程。
图4 是基于GAN 的对抗样本生成模型的训练过程,其中,生成模型由多层卷积网络和反卷积网络组成。在该模型中,卷积网络负责处理输入图像,提取深层特征;反卷积网络采用一种与卷积过程相反的运算,从特征空间映射回原始图像空间,它利用由卷积网络提取的特征,加入一定随机噪声,重建出具有对抗性扰动的图像。这种方法有效地避免了由于低维特征重建引发的模式坍塌现象。这种对抗样本对目标模型形成有效的干扰,从而在维持原有识别精度的同时,提高了对抗攻击的有效性。判别器则由卷积网络组成,对输入的真实特征和伪造特征进行二分类。

图4 基于GAN 的对抗样本生成模型的训练过程
在训练过程中,诚实参与方根据其本地模型和样本特征执行本地计算,并将结果作为全局模型输入上传。恶意参与方通过生成器对真实特征进行编码来产生对抗性扰动,然后将这些扰动添加到真实样本上形成对抗样本。接着,恶意参与方将对抗样本输入到本地模型中进行计算,并将结果上传至服务器。服务器根据全局模型计算模型输出及损失ℓadv。恶意参与方将真实样本和对抗样本输入判别器,计算对抗损失 ℓGAN。计算完成后,判别器和生成器根据全局损失ℓ分别更新模型参数。恶意参与方重复上述过程,直到收敛后保存模型G、D。具体过程如算法2 所示。
算法2VFL-GASG 模型的训练过程

图5 基于GAN 的对抗样本生成模型的生成过程
3 实验评估
本节首先详述实验设定,包括实验环境、数据集和模型结构;其次展示不同对抗样本生成算法所产生的对抗样本及其攻击效果;再次通过实验验证VFL-GASG 在效率、鲁棒性和泛化性上的能力;最后在纵向联邦环境中,通过实验分析不同参数对对抗攻击的影响。
3.1 实验设置
1) 实验环境
本文实验运行于以下环境:Intel(R) Xeon(R)Gold,64 内核,2.3 GHz,内存128 GB,V100 GPU,Ubuntu 16.04 操作系统。本文提出的对抗样本生成算法基于Pytorch 框架和foolbox 库实现。
2) 数据集
本文数据集选用了 MNIST、CIFAR-10 和ImageNet-100。其中,MNIST 数据集是一个广泛应用于图像分类任务的手写数字图像数据库,包含60 000 个训练样本和10 000 个测试样本,每个样本都是28 像素×28 像素的灰度图像;CIFAR-10 数据集也常用于图像分类任务,是一个包含10 个不同类别的彩色图像数据集,每个图像为32 像素×32 像素,总计包含50 000 个训练样本和10 000 个测试样本;ImageNet-100 数据集是ImageNet 大规模视觉识别任务的子数据集,包括100 个类别的样本数据,共计50 000 个训练图像和10 000 个测试图像,经处理后每个图像为214 像素×214 像素。
本文构建了一个包含3 个参与方的仿真纵向联邦学习环境。其中,2 个参与方被设定为诚实参与方,主要负责本地模型的计算和数据上传;另一个参与方被设定为恶意参与方,其任务是生成对抗样本。在基于特征维度的数据划分过程中,诚实参与方和恶意参与方所持有的特征数量的比例保持在1:1,这种设计能够在相对平衡的初始环境中评估和比较算法性能。
3) 模型架构
本文将目标模型在测试集上的分类准确率下降幅度作为对抗攻击的度量,首先训练目标模型,然后在测试样本上添加扰动生成对抗样本,统计对抗样本在目标模型上的准确率。对抗样本在目标模型的准确率越低,那么对抗攻击的效果越好。在构建本地模型和全局模型的过程中,本文设计了不同的分类模型(图6 的目标模型1 与目标模型2),经过训练后,该模型在MNIST 和CIFAR-10 测试集上的准确率分别为97.27%和79.91%,而选用ResNet模型作为ImageNet-100 的目标模型,分类准确率为65.09%。本文采用深度卷积生成对抗网络来改善训练的稳定性。判别器包括4 层卷积网络,生成器包括3 层卷积网络、4 层ResNetBlock 和3 层反卷积网络。

图6 GAN 及目标模型网络结构
3.2 对抗样本生成
为了直观展示对抗样本的生成效果,本文在上述实验环境中进行重建数据的可视化,分别在MNIST 和CIFAR-10 数据集上生成对抗样本,当恶意参与方完成计算后,将不同参与方的样本特征进行整合来直观展示对抗样本生成的效果。如图7 和图8 所示,尽管样本在局部位置出现了微小的扰动,然而总体上并未影响图像的辨认。

图7 在MNIST 上生成的对抗样本

图8 在CIFAR-10 上生成的对抗样本
本文进一步在ImageNet-100 数据集上生成对抗样本,如图9 所示。相比于MNIST 和CIFAR-10上生成的对抗样本,ImageNet-100 上样本的轮廓更清晰,视觉效果与原始图像更相似,噪声的直观感受更小。

图9 在ImageNet-100 上生成的对抗样本
表3 统计了不同对抗样本生成算法在目标模型上的分类准确率。结果表明,所有的对抗攻击都导致了模型分类准确率的大幅下降,这证明了对抗样本生成框架的有效性。然而,不同生成算法的效果存在差异,VFL-C&W 生成的对抗样本使模型的分类准确率下降最多,其能够在引入细小对抗扰动的同时保持较高的攻击效果。VFL-JSMA 通过选择对分类结果影响最大的像素对来生成对抗样本。尽管这种算法改变的像素较少,但个别像素值的变动较大,因此,在实际的对抗攻击中,这种算法生成的对抗样本更容易被识别。VFL-FGSM、VFL-IFGSM、VFL-MIFGSM、VFL-LBFGS 算法在攻击效果上相近。而本文提出的VFL-GASG 算法在攻击效果上接近于VFL-C&W 算法,这证明该算法在纵向联邦学习场景中可以保持较高的攻击成功率。

表3 不同对抗样本生成算法在目标模型上的分类准确率
3.3 效果对比
在效率方面,本文在3 个数据集的测试图像上分别生成了10 000 个对抗样本,并统计了所需时间,如表4 所示。在使用VFL-GAN 生成对抗样本的过程中,恶意参与方仅需将原始图像输入生成器,生成器就可以计算出相应扰动,这种方式减少了参与方之间的数据传输次数,因此在计算复杂度上具有明显优势。基于表4,本文提出的VFL-GASG 算法在对抗样本的生成效率上明显优于其他算法,生成样本耗时分别为5.51 s、9.99 s 和167.89 s,这甚至少于VFL-FGSM 算法。虽然在表2 中VFL-C&W 算法展示了较好的攻击效果,但其代价是极高的计算复杂度,VFL-C&W 的计算耗时远超其他方法。而本文提出的VFL-GASG 算法不仅保持了高攻击成功率,同时在生成效率上也表现出显著优势。
为了探究对抗样本对模型的鲁棒性,本文调整了3 个数据集上目标模型的参数和网络结构,得到新的目标模型A、B 和C。接着,将原对抗样本输入这些模型,通过观察对抗样本在新目标模型上的准确率变化来评估对抗样本对于模型的鲁棒性。如表4 所示,即使调整了目标模型,这些对抗样本仍能显著降低模型的准确率,特别是VFL-GASG 生成的对抗样本依然使不同模型分类准确率大幅下降,这证明联邦模型迭代后,VFL-GASG 生成的对抗样本仍能有效干扰模型。
表5 展示了基于不同训练样本比例所训练的生成模型所产生的扰动对目标模型准确性的影响,其中极差反映了度量指标在各比例间的变动幅度。结果显示,即使训练样本的比例存在差异,VFL-GASG算法都能显著降低目标模型的Top1 分类准确率,这证实了VFL-GASG 在部分样本上对抗性扰动生成算法的泛化能力。在纵向联邦学习的环境中,即使泄露了少量样本信息,该算法也能够利用这些信息构建噪声生成网络,进而构造对抗攻击。相比之下,其他对抗样本生成算法需要对每个输入样本进行独立的计算与迭代,其泛化能力相对较差。

表5 不同训练样本比例的攻击效果
3.4 不同实验设置的影响
在对抗攻击过程中,攻击者利用其持有的特征创建对抗样本以混淆目标模型,恶意参与方特征数量可能影响对抗攻击的效果。为了探究恶意参与方特征数量对攻击效果的影响,本节在不同恶意参与方特征数量条件下评估了不同对抗样本生成算法的攻击效果,实验结果如图10 所示。本节实验分别在MNIST、CIFAR-10、ImageNet-100数据集上根据不同的敌手特征数量对图像划分,例如,在Imagenet 数据集上,敌手客户端分别持有0~224 维的不同高度像素,其余像素则均匀分配给诚实参与方。随着恶意参与方特征数量的增加,模型的分类准确率在一定范围内呈线性下降趋势。值得注意的是,即使敌手只持有较少的特征,其攻击也能显著影响模型性能,例如当特征数量分别为8、8 和56 时,VFL-GASG 在3 个数据集上产生的对抗攻击使模型分类准确率分别下降30.80%、22.36%和17.62%;当恶意参与方特征数量超过总体特征的50%时,模型分类准确率均保持在较低水平。

图10 恶意参与方特征数量对于对抗攻击的影响
本节探究了不同恶意参与方占比对纵向联邦对抗攻击的影响,结果如图11 所示。实验设置在8 个参与方中引入不同比例(0%、12.5%、25%、50%)的恶意参与方,评估其对模型性能的影响。实验表明恶意客户端数量的增加引发了对抗攻击效果的显著提升,并导致目标模型分类准确率大幅降低。即使恶意参与方比例仅为12.5%,模型分类准确率也表现出显著下滑。当恶意参与方比例达到50%时,模型分类准确率进一步降低至31.38%、42.89%和22.36%。以上结果表明,保证联邦学习环境的安全性以防止恶意参与方的参与,对于维持模型的高分类准确率具有至关重要的意义。

图11 恶意参与方占比对纵向联邦对抗攻击的影响
本节针对MNIST、CIFAR-10 和ImageNet-100数据集,探究了参与方数量和实验参数配置如何影响VFL-GASG 对抗攻击的效果,如图12 所示。在将参与方总数设为2、4、6、8 的不同场景中,设定其中一个参与方作为恶意参与方并进行特征均匀分配。图12 的实验结果表明,随着参与方数量的增长,对抗攻击的攻击准确率显著降低,这是因为受扰动的特征数量随着参与方数量的增加而减少,而其他参与方提供的建模特征则会缓解恶意参与方对攻击的影响。另一方面,实验参数设定可以影响损失优化方向中各项的相对重要性。当扰动参数λr较大时,模型的攻击准确率降低较慢,意味着模型优化过程更注重于减小扰动,而不是攻击效果。反之,当生成对抗网络的参数λGAN增大时,生成模型则更多地倾向于降低目标模型的性能,以提高对抗攻击效果。值得注意的是,在MNIST 和CIFAR 数据集上10~12 轮的部分准确率曲线有上升趋势,这是因为λr相比于λGAN过小,导致模型更倾向于牺牲对抗性扰动而注重提高攻击效果,但经裁剪后的图像使攻击效果反而下降。这些实验结果表明,合适的模型参数对于对抗攻击VFL-GASG尤其关键。

图12 参与方数量和实验参数配置对VFL-GASG 攻击效果的影响
4 结束语
本文探讨了纵向联邦学习环境下的对抗样本生成问题。首先,在纵向联邦学习架构的背景下详细分析了对抗攻击的威胁模型,进而为纵向联邦学习环境构建了一种具有高扩展性的对抗样本生成框架,并扩展了不同机器学习对抗样本生成策略作为基准算法。鉴于生成算法的泛化能力的要求,提出了一种基于 GAN 的对抗样本生成算法VFL-GASG,该算法在生成模型中通过卷积-反卷积网络构建精细化扰动。通过在多个数据集上的实验证明,该算法在生成效率、鲁棒性和泛化性方面表现出优良的性能,符合纵向联邦学习环境的需求。即便在恶意参与方数量较少或其持有的特征数量较少的情况下,模型的准确性也会受到对抗攻击的显著影响。进一步,通过实验分析了可能影响对抗攻击效果的各种因素,为后续研究提供有意义的借鉴。
