基于无人机高光谱数据的小麦生物量估测
2023-09-19孙成明
张 敏,刘 涛,孙成明*
(1.扬州大学农学院江苏省作物遗传生理重点实验室/江苏省作物栽培生理重点实验室,江苏扬州 225009;2.扬州大学江苏省粮食作物现代产业技术协同创新中心,江苏扬州 225009)
小麦地上部生物量(以下简称生物量)是反映作物生长状况的重要指标之一。为了实现小麦的最佳生长和减少环境污染,农民需要通过不同生育时期的生物量信息来判断小麦长势,进一步指导施肥。而且在接近生育后期时估算作物的生物量还可用于产量预测[1]。在传统手段上准确测定作物生物量需要破坏性取样[2],这不仅费时费力,而且通常不适用于大面积监测[3]。
随着科学技术的发展,遥感技术逐渐被用于农业监测,为在局部和区域尺度上定量估测作物生物量提供了一种经济高效的方法[4-5]。同时,近乎连续光谱的高光谱传感器的出现,为准确估测生物量等作物理化指标开辟了新的道路[6]。随着无人机(UAV)硬件和软件的快速发展,基于无人机平台的遥感监测越来越多地用作数据收集工具,其操作简单、超高的软硬件集成度、灵活的飞行高度等特点可以快速获取大量遥感数据,而且较低的飞行高度大大提高了遥感数据的空间分辨率[7]。
早期一些RGB相机和多光谱相机计算的颜色指数或植被指数(VI)在估测农学参数时存在一定限制,如基于多光谱的红波段和近红外波段得到的归一化差异植被指数(NDVI),它在估测生物量或叶面积指数时容易出现饱和现象[8-9]。因此,它不能用来准确估测非常密集的冠层生物量[10]。然而,基于高光谱计算的植被指数被认为对量化植被生物量更加敏感[11]。研究结果表明,由特定波段构建的归一化差异植被指数(NDVI)可以提高生物量估测精度。Hansen等[12]的研究中表明,基于NDVI(718、720 nm)的线性模型在用于估算冬小麦生物量时准确度很高。Cho等[13]使用机载高光谱图像发现基于NDVI(740、 771 nm)的线性模型用于估测草的生物量时比基于传统NDVI(665、 801 nm)的线性模型精度更高。Ren等[14]研究表明,基于NDVI(693、 862 nm)的线性模型相对于土壤调整植被指数(SAVI)估测的荒漠草原绿色生物量具有更好的估测性能。
鉴于此,以设置不同品种、氮肥梯度和密度处理的小麦大田试验为基础,笔者利用无人机平台搭载高光谱相机获取不同时期小麦冠层反射光谱数据,利用高光谱通道多、光谱分辨率高、信息丰富等特点,提取17种不同的植被指数,充分挖掘冠层反射光谱信息;通过将植被指数与生物量进行相关性分析,筛选与生物量相关性达到显著水平的植被指数构建各生育期生物量的偏最小二乘回归模型(PLSR),并将3个生育时期数据融合在一起构建生物量全生育期估测模型,旨在寻找不同生育时期生物量敏感植被指数,构建多时期生物量估测模型,提高生物量估测精度。
1 材料与方法
1.1 试验地概况试验于2020—2021年在仪征市大仪镇(119°10′E,32°30′N)进行,试验区全年温暖湿润,雨水充沛,四季分明,属亚热带季风气候地区。常年主导风向为东南风,多年平均降水量约1 014 mm,多年平均气温约15.1 ℃,多年平均日照时长约6 h。
1.2 试验材料该试验以扬麦23号、镇麦9号和宁麦13号为研究对象。
1.3 试验方法试验设置4个氮肥梯度:225.0 kg/hm2(N1处理)、202.5 kg/hm2(N2处理)、180.0 kg/hm2(N3处理)、157.5 kg/hm2(N4处理);2个条播密度:225万株/hm2(M1处理)和300万株/hm2(M2处理)基本苗。肥料采用含氮量44%的树脂包衣控释氮肥(控释期180 d),磷钾肥分别为P2O5含量为12%的过磷酸钙和K2O含量为60%的KCl,施用量均为120 kg/hm2,所有肥料均于播前底施。于2020年11月3日播种,小区面积为18 m2,重复2次,共48小区。
1.4 数据获取方式
1.4.1小麦地上部生物量测定。分别于小麦拔节期、孕穗期、开花期进行田间取样。各处理随机选取20株长势均匀的小麦植株,剪掉根系,清水洗净,放入烘箱在105 ℃下杀青30 min后将温度调节到80 ℃继续烘干至恒重,称取干重后换算成单位面积地上部干物重,即地上部生物量。
1.4.2光谱数据获取过程。于拔节期、孕穗期、开花期采用DJI M600 PRO无人机搭载GaiaSky-Mini2机载高光谱成像系统获取试验田块高光谱图像数据,飞行高度为100 m,手动规划航线坐标点,采用定点悬停扫描,航向和旁向重复率均为80%,飞行任务开始前校准镜头调整曝光时间,起飞后拍摄地面3张不同反射率灰布,为后期图像反射率校准提供参考标准。每次飞行时间为10:30—11:30,天气晴朗、无强风。
1.5 数据分析方法
1.5.1光谱数据预处理。使用SpecView对原始数据依次进行镜头校准、反射率校准、大气校正即可得到校准后的高光谱图像数据。使用HiSpectralSticher软件对校准后的高光谱图像进行拼接。使用Envi 5.3软件并利用Subset Data from ROIs工具对拼接完成的高光谱图像进行裁剪。
1.5.2植被指数提取。该研究利用MATLAB R2020a软件,通过预处理后的高光谱图像分别计算和提取了每个处理较为常用的17种植被指数(详细植被指数名称见表1)。关于这些植被指数的研究较多,在小麦的生长监测中早已被证明具有很高的相关性和可靠性。

表1 植被指数及计算方法
1.6 建模方法及模型验证指标为了构建最佳的小麦生物量估测模型,采用偏最小二乘回归(PLSR)进行建模,PLSR融合了主成分分析法和多元线性回归算法,有效地消除了多元线性回归中各变量的共线性,剔除了冗余信息,以提高计算的效率[28]。该研究利用Python 3.9和scikit-learn库进行PLSR建模,训练集和验证集比例为3∶1。通过决定系数(R2)、均方根误差(RMSE)检验模型的精度。
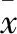
2 结果与分析
2.1 各生育期植被指数与生物量的相关性分别对拔节期、孕穗期、开花期和全生育期的植被指数和生物量进行相关性分析,结果见表2。拔节期、孕穗期、开花期样本数均为24个,全生育期样本数为72个。从表2可以看出,拔节期17种植被指数中与生物量相关性最低的是WBI指数,相关系数仅为-0.286,其余指数与生物量的相关性均达到极显著相关水平,其中相关系数最高的是DVI和RDVI指数,相关系数均为0.784。孕穗期TCARI指数与生物量的相关性最低,相关系数为0.188,未达到显著相关水平;除NPCI指数和MCARI指数与生物量只达到显著相关水平外,其余植被指数均与生物量均达到极显著相关水平,其中相关系数最高的指数是GNDVI,系数为0.766。开花期有4个植被指数与生物量达到极显著相关水平,相关系数最大的是WBI,为-0.642。全生育期除GNDVI与生物量相关性未达到显著水平、NPCI达到显著水平外,其余15种植被指数与生物量的相关性均达到极显著相关,其中相关系数最高的是WI指数,相关系数为-0.799。
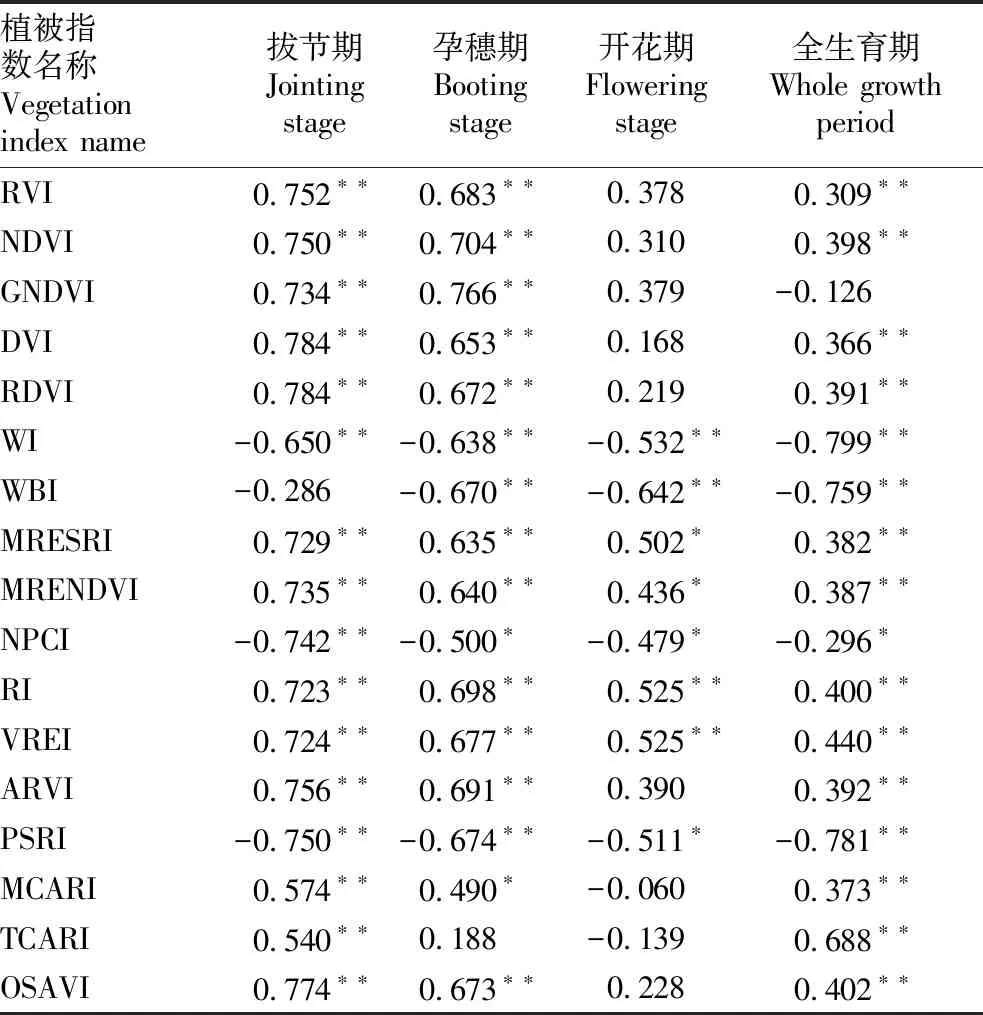
表2 基于高光谱数据的不同植被指数与生物量的相关性
2.2 基于显著相关植被指数的小麦生物量模型构建根据前述相关分析的结果可知,在小麦拔节期、孕穗期和全生育期各有16种植被指数与生物量达到显著相关水平,在小麦开花期有8种植被指数与生物量达到显著相关水平。该研究以达到显著相关为筛选标准,利用各生育期与生物量达到显著相关水平的植被指数构建偏最小二乘回归模型,并绘制训练集生物量1∶1线图(图 1)。
从图 1可以看出,各时期生物量的估测值和真实值均较为均匀的对称分布在1∶1线两侧,图1D(全生育期)和1B(孕穗期)中各点围绕1∶1线分布更加紧凑,线性趋势更为明显,图1A(拔节期)中各点分布更为松散,松散程度最高的是图1C(开花期)。与之对应的是各生育期生物量模型的决定系数(R2),R2最高的是全生育期为0.82,孕穗期精度次之,R2为0.72,拔节期和开花期R2分别为0.61和0.54。孕穗期、拔节期、开花期生物量模型均方根误差(RMSE)依次为461.74、472.05、742.97 kg/hm2,R2越高则RMSE越低,但R2最高的全生育期模型的RMSE反而也是最高,为818.60 kg/hm2。
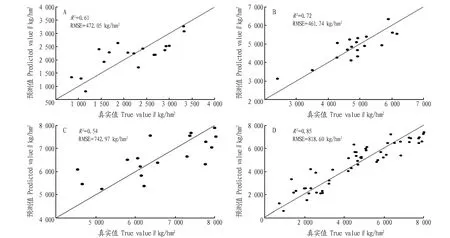
注:A.拔节期;B.孕穗期;C.开花期;D.全生育期。
2.3 基于显著相关植被指数的小麦生物量模型验证表3是各生育期小麦生物量PLSR估测模型中各植被指数对应的权重和常数项。利用各生育期预留的小麦生物量验证数据代入到模型中对各生物量估测模型进行精度验证,同时绘制真实值和估测值的1∶1线图(图 2)。
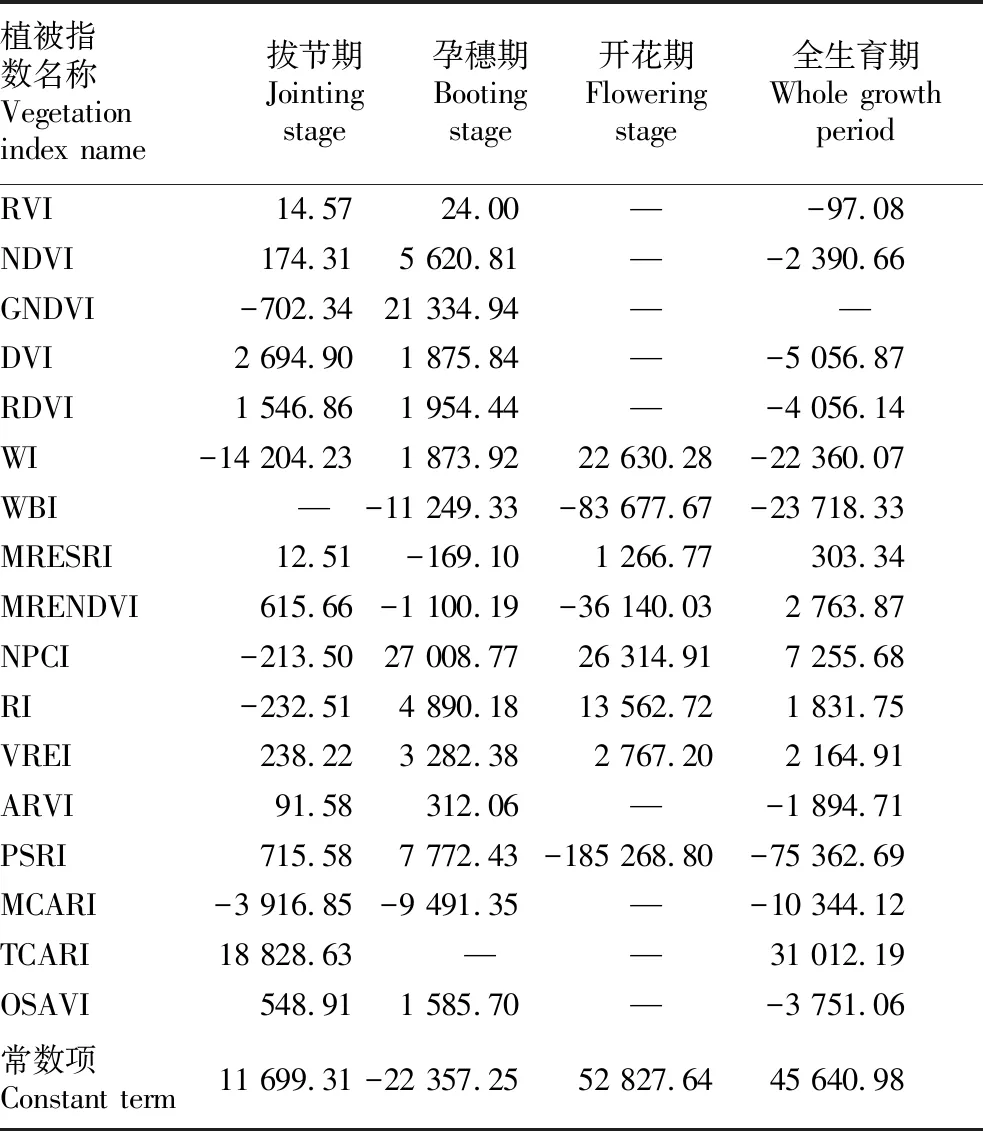
表3 各生育期生物量PLSR模型参数
从图 2可以看出,图2D中各点分布最靠近1∶1线,而且均匀分布在线的两侧,50%左右的点几乎分布在线上;图2A、B中各点分布也较为均匀,图2C中各点分布效果最差。各生育期PLSR模型的验证精度均较建模精度有所提高,拔节期、孕穗期、开花期和全生育期的R2分别为0.68、0.82、0.57和0.93,较建模R2分别提高0.07、0.10、0.03和0.11,RMSE分别为354.92、402.09、652.86和519.67 kg/hm2,较建模RMSE分别降低了117.13、59.65、90.11和298.93 kg/hm2。
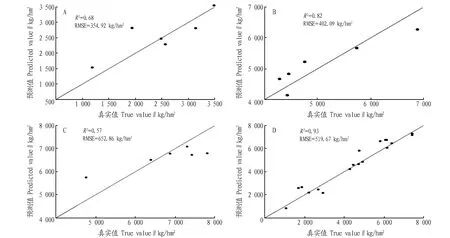
注:A.拔节期;B.孕穗期;C.开花期;D.全生育期。
3 讨论
该研究中不同生物量与植被指数相关性分析可以看出,拔节期和孕穗期生物量与各植被指数的相关性的相关程度很高,分别有16和14种植被指数达到极显著相关,而且拔节期相关系数绝对值大多达到0.7,孕穗期相关系数绝对值普遍在0.6以上;而开花期17种植被指数中只有8种达到显著相关,其中4种达到极显著相关,许多在拔节期和孕穗期均极显著相关的植被指数在开花期均未达到显著相关。这可能是因为拔节期和孕穗期小麦植株冠层叶片不够密集、叶片重叠率低,而到了开花期植株冠层茂盛、空间重叠率高,导致植被指数出现饱和现象[15]。Gao等[8-9]的研究都认为基于多光谱的红波段和近红外波段得到的归一化差异植被指数(NDVI),它在估测生物量或叶面积指数时容易出现饱和现象,Clevers等[10]认为,光谱饱和现象使得一些植被指数在估测密集植被的冠层生物量时精度受限。陈鹏飞等[29]研究指出,NDVI与OSAVI可用于准确估测中低生物量信息,在较高冠层生物量条件下估测能力显著下降。该研究结果同样表明,模型在估算拔节期和孕穗期的生物量精度高于开花期,这可能是由于开花期植被相对较密,使得光谱饱和现象更为严重。此外,有研究表明,机器学习模型对训练数据的量具有较高的要求[30-32]。对于全生育期而言,数据量的增加使得模型被训练得更为充足,各指数的信息被挖掘得更为充分,这也解释了利用全生育期数据训练的模型相较而言,精度提升明显。尽管RMSE相较拔节期和孕穗期有所提高,这是由于融入了开花期的数据,使得实测生物量的基数增大。
4 结论
该研究提取了基于无人机高光谱数据共提取了的17种植被指数,并通过相关性分析筛选了各生育期与生物量相关系较高的植被指数,以构建最优的PLSR模型。结果显示,各生育期与生物量存在显著相关系的植被指数存在差异,其中在拔节期,相关系数最高的是DVI(r=0.784)和RDVI(r=0.784);孕穗期最高的是GNDVI(r=0.766);开花期最高的是WBI(r=-0.642);全生育期最高的是WI(r=-0.799)。该研究所构建的PLSR模型能够很好地拟合生物量与植被指数之间的关系。对于拔节期,精度达到0.68;孕穗期精度达到0.82;开花期精度达到0.57;全生育期精度达到0.93;该研究中,在低植被覆盖的拔节期和孕穗期,模型受到的饱和效应较小,精度也高于高植被覆盖的开花期;此外,具有更多训练样本的全生育期具有更高的精度。
整体而言,该研究结合相关系分析和PLSR算法所构建的小麦生物量估算模型具有良好的精度,能够为田间作物长势监测与农田生产决策提供有效的信息与参考。
