基于双源域迁移学习的肺音信号识别
2023-09-18包善书邓林红
包善书,车 波,邓林红
(1.常州大学 计算机与人工智能学院,江苏 常州 213164;2.常州大学 生物医学工程与健康科学研究院 常州市呼吸医学工程重点实验室,江苏 常州 213164)
0 概述
肺音是临床听诊的一种重要生理信号,其信号特征与肺部疾病有着紧密关联,如从哮喘和慢性阻塞性肺疾病患者的肺音中可听到一种连续型的异常肺音,通常称为哮鸣音(Wheezes)[1],而从慢性支气管炎、肺炎、肺纤维化等患者的肺音中则可听到一种间断型的异常肺音,即所谓的爆裂音(Crackles)[2]。
目前临床听诊中,医生主要依靠经验判断患者的肺音类型以辅助其对患者肺部疾病的诊断。但由于肺音信号混杂着人体复杂生理环境下的背景噪音(如心音、肠道音等),其信噪比往往较低,仅仅依赖医生的主观经验判断容易发生对肺部疾病的漏诊甚至误诊。随着计算机技术的不断发展,运用机器学习等数据驱动的方法实现对肺音信号的智能识别和分类,进而辅助医生诊断患者肺部疾病状况已成为重要的发展趋势[3-5]。
然而,目前肺音识别研究所面临的主要问题在于:传统机器学习方法难以从肺音特征中获取关键信息,导致识别效果不理想;深度学习方法对数据的依赖性较高,而肺音数据稀少且难以获取,致使识别网络容易过拟合,难以完成精准高效的分类识别。近年来使用最广泛的肺音数据集是生物医学健康信息学国际会议(ICBHI)[6]公开的ICBHI-2017,该数据集包含来自126 名受试者的6 898 个带注释的4 类肺音数据,但数据量仍然不够充裕。基于该数据集的肺音识别研究有:文献[7]提出一种特征融合的方法,在融合肺音的短时傅里叶谱特征与小波特征后,采用支持向量机(Support Vector Machine,SVM)识别ICBHI 数据集中的4 类肺音,识别准确率为67.29%;文献[8]采用肺音的梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)特征,通过长短期记忆(Long Short-Term Memory,LSTM)网络分类识别4 类肺音,识别准确率为74%;文献[9]提取肺音的短时傅里叶谱特征,利用一种名为Parallelpooling CNN 的卷积神经网络分类识别4 类肺音,识别准确率为70.45%。由此可见,无论是传统的机器学习算法还是深度学习算法,都难以在肺音识别中取得较好的效果,当前亟需开发一种基于数据自驱动、识别高精度和综合性能优异的肺音识别方法。
2017 年,Google 推出在Audio Set[10]音频 数据集上训练的VGGish 神经网络,该方法随即在音频分类与识别的研究中得到了较好的应用,显示出在有限数据集基础上获得高精度分类识别的巨大潜力[11-12]。此外,现代有关音频信号的研究往往从时域和频率域2 个方面入手,运用时频分析的方法将信号的时序波形图转化为蕴含频域特征和时域特征的谱图,依据谱图的特征识别信号本身[13]。针对小型音频数据集,借助迁移学习与图像识别的思路,使用大型数据集ImageNet 上的预训练卷积神经网络识别信号也是一种有效的方式。
综上,考虑到迁移学习方法能克服数据集规模较小所致模型识别精度低的问题[14-15],本文借助VGGish 网络在Audio Set 上的预训练参数以及VGG19 在ImageNet 上的预训练参数,提出一种双源域迁移学习方法识别肺音。首先,构建一种VGGish优化模型,针对VGGish 网络的结构特性,在网络全连接层之前融合高效通道注意力(Efficient Channel Attention,ECA-Net)[16]模块;其次,采用多尺度扩张卷积对VGGish 网络的输出特征图进行卷积运算,从而捕获高维向量的内在联系,得到语义信息更丰富的特征;然后,利用双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)从增强后的特征中获取肺音的时序特性;最后,提出一种融合VGGish 优化模型与VGG19 的肺音识别模型(LSR-Net),用训练数据分别训练VGGish 优化模型与VGG19 作为特征提取器,将具有高层语义的特征向量融合后输入CatBoost 算法[17]实现分类。
1 基于双源域迁移学习的肺音识别方法
1.1 基于VGGish 优化模型的肺音识别方法
1.1.1 VGGish 网络
Audio Set包含200多万个音频数据,共600多类,预训练模型VGGish 中的参数蕴含了大量音频数据的通用特性,利用在该数据集上训练好的VGGish网络,能在一定程度上克服过拟合问题,从而对肺音实现较好的分类效果。值得一提的是,Audio Set上用来训练VGGish 的数据不是音频文件的波形信号,而是波形数据转换后具有特定形状的对数梅尔频率谱(Logarithmic Mel spectrum,Log-Mel),具体步骤如下:1)用16 000 Hz 重新采样音频数据;2)对重采样后的音频数据进行短时傅里叶变换,得到频谱图;3)将步骤2)中的频谱图映射到64 阶梅尔滤波器组中计算梅尔频率谱,然后再取对数,得到对数梅尔频率谱;4)以0.96 s 的时长重新组帧,共96 帧,每一帧包含64 个梅尔频带,即对于时长为Ns 的音频文件,所对应的对数梅尔谱图维度为,其中,表示N除以0.96后向上取整数。图1 展示了实验所用肺音数据的时域波形图(上图)与按这种方式转换后的对数梅尔频率谱(下图)。由图1 可见,相对于肺音的波形数据,对数梅尔频率谱蕴含着更多的时频信息。
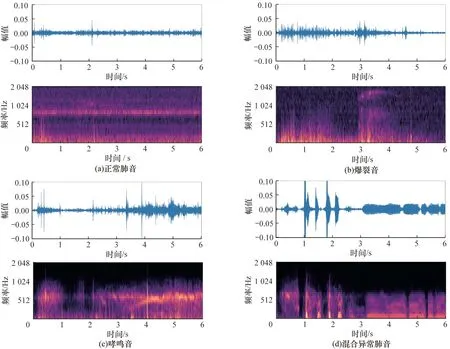
图1 不同类型肺音的波形时域图与对数梅尔频率谱Fig.1 Waveform time domain diagrams and logarithmic Mel spectrums of different types of lung sounds
表1 列出了VGGish 网络的结构及网络层参数。由表1 可见,VGGish 的输入特征图维度为96×64×1,这意味着维度为的对数梅尔频率谱无法直接输入VGGish,因此,常用的方式是让VGGish 按照时序依次学习个时间步内谱图的信息。
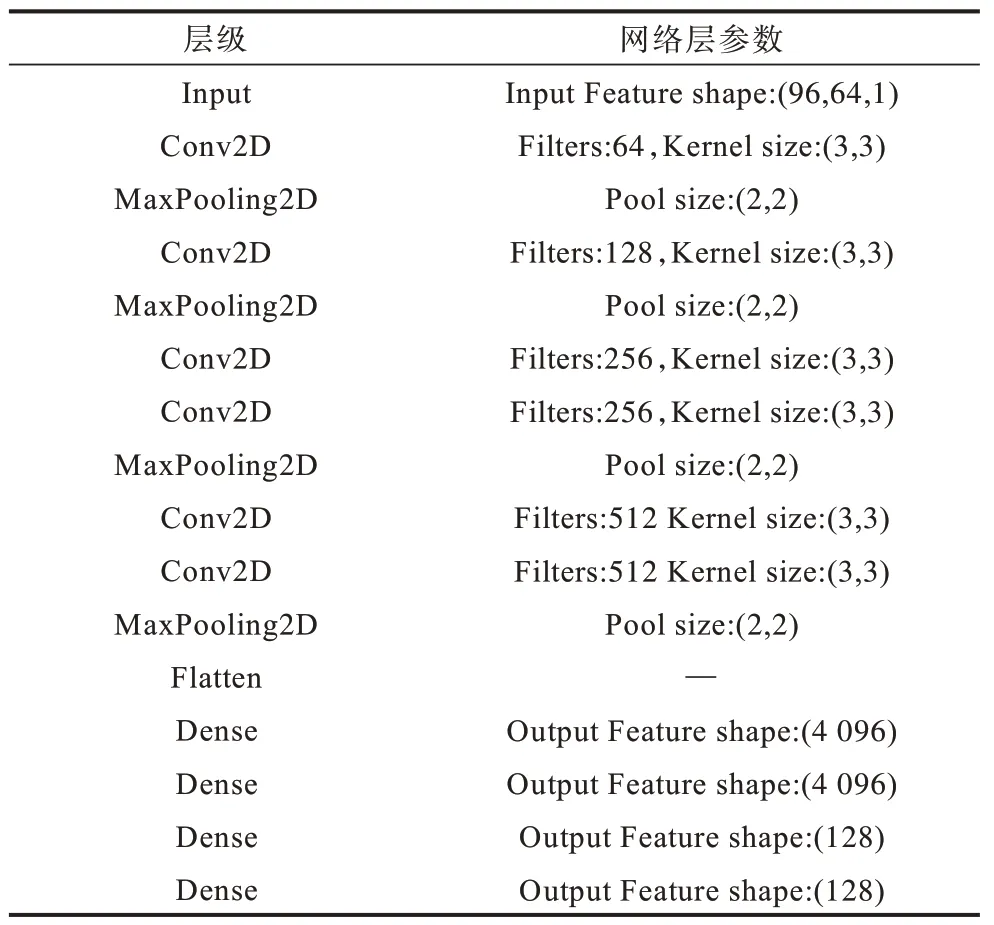
表1 VGGish 网络的结构与网络层参数 Table 1 Structure and network layer parameters of VGGish network
1.1.2 ECA-Net
借助预训练模型能一定程度上克服因肺音数据稀少带来的困扰,但仅依靠预训练参数未必能取得理想的效果。为进一步提高识别精度,本文从模型自身的角度对VGGish 进行改进。由于VGGish 本身是一种卷积神经网络,因此本文考虑在VGGish 中融合通道注意力机制以提升性能。通道注意力包括SE-Net、CBAM[18-19]等,通过实验可以发现,ECA-Net是通道注意力机制中提升肺音识别效果最为显著的一种,其核心功能为:通过学习的方式,为特征向量的通道数分配权重,以利于关注重要特征和抑制次要特征,从而提升识别精度。ECA-Net 结构如图2所示。
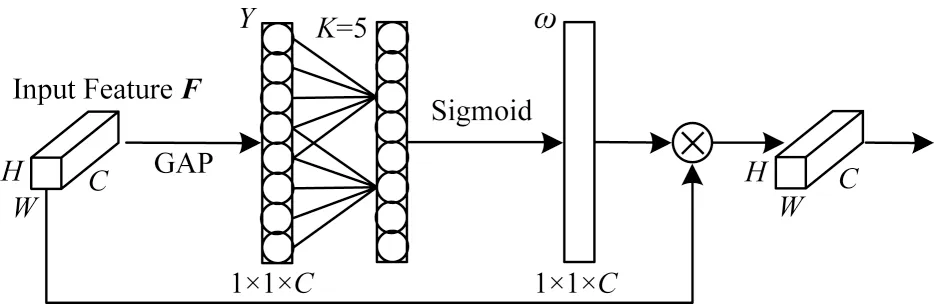
图2 ECA-Net 结构Fig.2 Structure of ECA-Net
设输入特征向量F的数据维度为W×H×C(W与H分别为宽和高,C为通道数),经过全局平均池化(Global Average Pooling,GAP)后,得到一个1×1×C的特征向量Y,这个特征向量经过一维卷积运算与Sigmoid 函数得到通道注意力图ω,ω中的数ωi即为对应通道的权重,最后将每个通道上的数乘上该通道对应的权重,即完成对每个通道权重的分配。ωi与ω的计算公式如式(1)与式(2)所示:
其中:yi为Y的第i个分量;wi为yi对应的权重;k表示局部跨通道交互的覆盖范围,即一维卷积核的大小;Ωi为与yi相邻的K个通道的集合;Convk表示一维卷积;σ为Sigmoid 函数。
1.1.3 特征增强
由表1 可知:对于每个时间步的谱图,VGGish 输出128 维的特征向量;对于Ns 的音频数据,VGGish输出维的特征图。常规思路是直接对维的特征图进行分类,但是这种做法忽略了128 维特征向量内部的关联。
考虑到扩张卷积能够增大感受野,从而捕获高维度向量中距离较远的元素之间的关系,同时多尺度卷积能从不同的感受野获取信息,从而全面捕获高维向量内部的关联信息,本文提出一种基于多尺度扩张卷积的特征增强的方法,即针对每128 维向量,采用多个大小不同且扩张率不同的一维卷积核进行卷积运算,并将运算后的特征向量相加。上述特征增强示意图如图3 所示。

图3 特征增强示意图Fig.3 Schematic diagram of feature augment
由图3 可见,对于任意128 维的特征向量F,将其分别经过t次一维卷积运算后相加得到增强后的向量。此过程具体由式(3)给出,其中,FAug表示增强后的向量,Convi表示第i次卷积运算。
1.1.4 VGGish 优化模型的构建
本文在VGGish 网络中融合ECA-Net 后,使VGGish 网络按照时序依次学习谱图中的信息。在此基础上,对VGGish 提取的特征图进行特征增强,并使用BiGRU 捕获肺音数据的时序信息,完成对肺音的识别分类。此模型命名为VGGish 优化模型,具体工作原理如图4 所示。本文用VGGish+ECA-Net表示融合了ECA-Net 的VGGish 网络。在图4 中,TimeStep 为时间步,意味着本文只构建了一个VGGish 网络,并非个,相较于使用个VGGish 网络并行处理,可有效减少不必要的内存开销。

图4 基于VGGish 优化模型的肺音识别示意图Fig.4 Schematic diagram of lung sound recognition based on VGGish optimization model
1.2 基于VGG19 网络的肺音识别方法
VGG19 是一种经典的卷积神经网络,其包含16 个卷积层、5 个最大池化层、3 个全连接层。为了使用VGG19 在ImageNet 上的预训练参数,需要将肺音的波形数据转化至规格为224×224×3 的谱图,具体步骤如下:1)将肺音的波形数据转换至规格为224×224×1 的谱图;2)将步骤1)中的谱 图复制3 份,拼接成规格为224×224×3 的谱图。
谱图的形式有多种,考虑到对数梅尔频率谱在音频识别与分类中表现出色,本文依旧选择将肺音信号转换为对数梅尔频率谱,只是谱图的转换方式及参数与转换后的形状与上文中提及的略有不同。为了提升VGG19 的识别效果,本文舍去最后的3 个全连接层,并融合通道注意力模块ECA-Net。基于VGG19的肺音识别示意图如图5所示。

图5 基于VGG19 的肺音识别示意图Fig.5 Schematic diagram of lung sound recognition based on VGG19
1.3 基于LSR-Net 的肺音识别方法
本文借助VGGish 在Audio Set 上的预训练参数以及VGG19 在ImageNet 上的预训练参数,提出一种基于双源域迁移学习的肺音识别方法LSR-Net。使用训练后的VGGish 优化模型以及VGG19 作为特征提取器,将具有高级语义的特征向量输入CatBoost算法,最终实现肺音的识别。基于LSR-Net 的肺音识别示意图如图6 所示,将肺音信号分别转换为规格为与(224,224,3)的对数梅尔频率谱输入VGGish 优化模型与VGG19,并将输出的256 维与128 维特征向量融合后输入CatBoost 算法。CatBoost 是梯度提升决策树的主流算法之一,较XGBoost[20]与LightGBM[21],其所使用的Ordered boosting 方法能在一定程度上缓解过拟合。

图6 基于LSR-Net 的肺音识别示意图Fig.6 Schematic diagram of lung sound recognition based on LSR-Net
2 实验与结果分析
2.1 实验数据集
本文采用2017 年生物医学健康信息学国际会议提供的公开数据集(ICBHI-2017)和文献[22]公开的数据集(Coswara)作为实验数据集。
ICBHI-2017 中包含来自126 名受试者的6 898 个带注释的4 类肺音数据,其中有3 642 个正常肺音、1 864 个爆裂音、886 个哮鸣音、506 个爆裂音与哮鸣音混合的异常肺音。将数据集按照8∶2 的比例分为训练集与测试集,并将肺音数据的采样时长设置为6 s。
Coswara 为一个持续扩充样本的新冠音频数据集,现阶段包含来自1 000 多位健康受试者与600 多位新冠受试者的肺音、咳嗽、说话等音频数据。实验数据包含来自673 位新冠患者的1 345 个肺音数据以及等量的健康受试者的1 345 个肺音数据。本文将这2 690 个肺音数据按照8∶2 的比例分为训练集与测试集。
2.2 评估指标
本文中的ICBHI 肺音实验数据集有专门的评估指标,即特异性、敏感性与ICBHI-score,相关计算公式如下所示:
其中:TP表示样本的真实值为正类,模型也识别为正类的样本数量;FN表示样本的真实值为正类,模型识别为负类的样本数量,正类可以为任意类型的肺音,除正类外的其余肺音即为负类;Normal 表示正常肺音;Abnormal 表示异常肺音,包含哮鸣音、爆裂音以及两者的混合音;特异性指标Sp表示在正常肺音中,模型识别正确的占其总数的比例;敏感性指标Se表示除正常肺音以外的3 类异常肺音中,模型识别正确的数目占这3 类异常肺音的比例;IICBHI-score为ICBHI-score。
对于新冠数据集Coswara,同样使用特异性和敏感性作为评估指标。同时考虑到数据集中2 类样本的个数相同,因此使用准确率作为第3 个指标。
2.3 VGGish 优化的有效性验证
本文提出一种VGGish 优化模型,单独运用VGGish 可以实现肺音的识别,即将VGGish 网络按时序学习后输出的特征向量直接输入全连接层分类。基于VGGish 的肺音识别示意图如图7 所示。
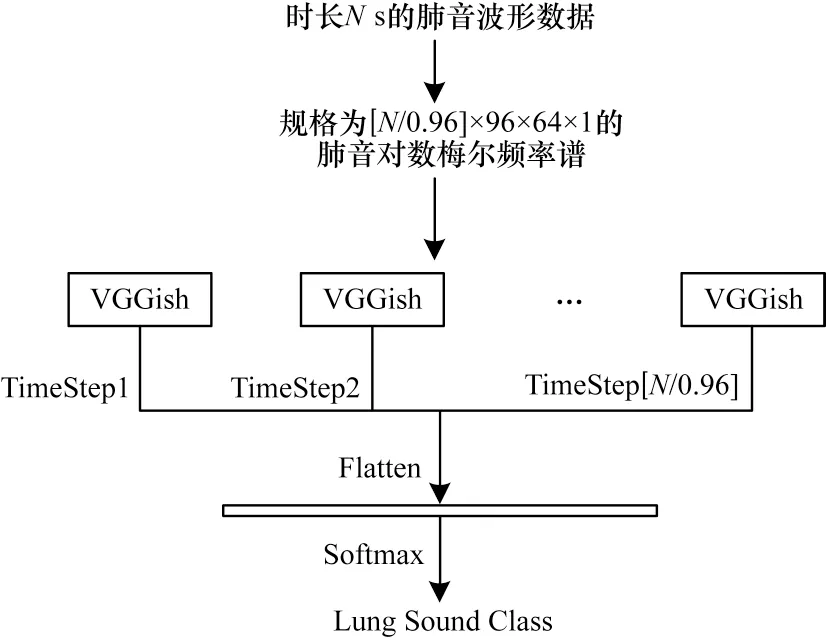
图7 基于VGGish 的肺音识别示意图Fig.7 Schematic diagram of lung sound recognition based on VGGish
为了验证本文对VGGish 优化的有效性,将原VGGish 网络添加任一优化方式后的VGGish 网络与VGGish 优化模型在ICBHI-2017 与Coswara 数据集上进行实验,结果如表2 和表3 所示。实验结果显示,VGGish 优化模型的指标较原VGGish 提升显著,且在VGGish 中任意优化方式都会提高模型的性能。这些结果说明本文采用的多种优化方式结合的方法是合理且有效的。

表2 VGGish优化的有效性验证(ICBHI-2017数据集实验结果)Table 2 Validation of VGGish optimization(experimental results on ICBHI-2017 dataset)%
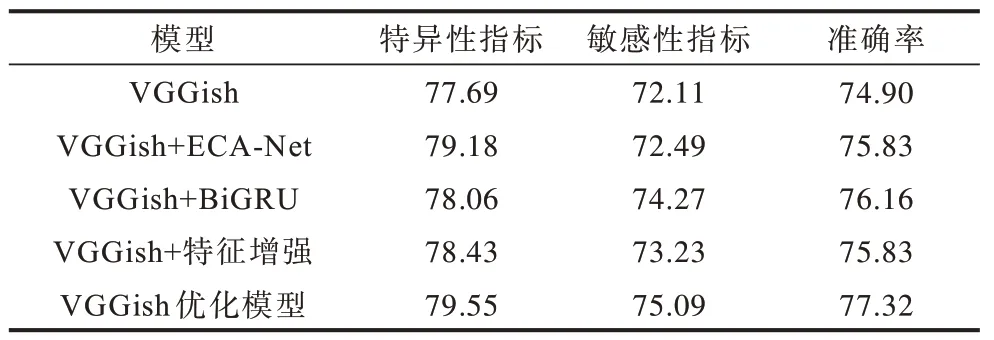
表3 VGGish 优化的有效性验证(Coswara 数据集实验结果)Table 3 Validation of VGGish optimization(experimental results on Coswara dataset)%
2.4 ImageNet上不同预训练模型对肺音的识别效果
本文借助VGG19在ImageNet上的预训练参数实现肺音识别,ImageNet作为最具权威代表的图像数据集,其上的预训练模型不仅仅只有VGG19。本文使用ImageNet 不同的预训练模型在肺音数据集上进行实验,实验结果如表4 和表5 所示。实验结果显示,较其他卷积神经网络,VGG19对肺音的识别效果最好。虽然ResNet、DenseNet等结构更优异的卷积神经网络在许多计算机视觉任务中取得了比VGG19更佳的效果,但在数据量较为稀少的肺音数据上表现得并不出色。这进一步说明,现有的肺音数据的确不够充裕,致使网络过拟合现象严重,泛化能力弱。
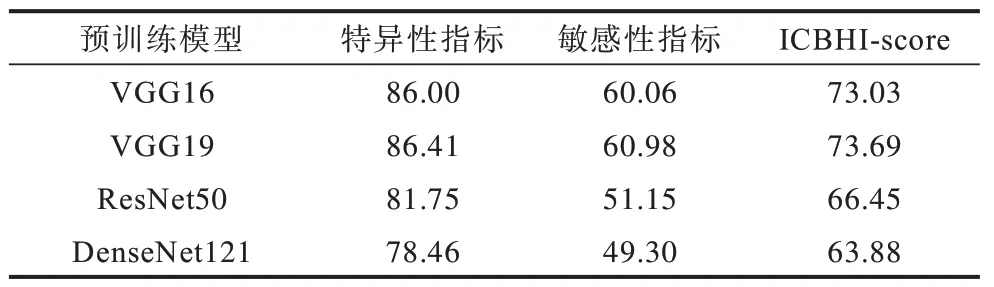
表4 ImageNet 上不同预训练模型的识别效果比较(ICBHI-2017 数据集实验结果)Table 4 Comparison of recognition effects of different pre-training models on ImageNet(experimental results on ICBHI-2017 dataset)%
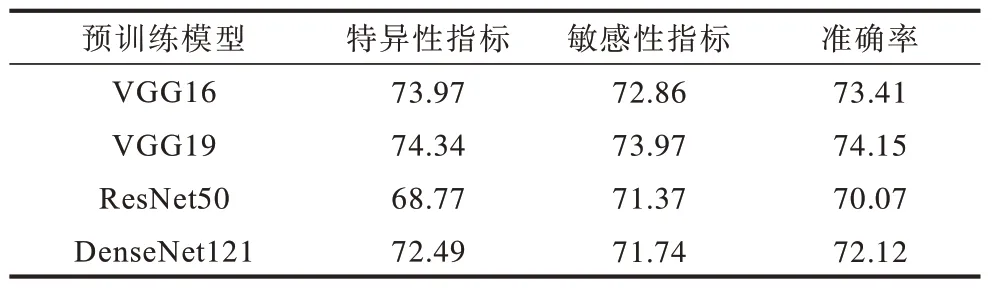
表5 ImageNet 上不同预训练模型的识别效果比较(Coswara 数据集实验结果)Table 5 Comparison of recognition effects of different pre-training models on ImageNet(experimental results on Coswara dataset)%
2.5 LSR-Net 对肺音的识别效果
本文使用训练后的VGGish 优化模型与VGG19作为特征提取器,将具有语义的高层特征向量融合后输入CatBoost 算法以构建LSR-Net。图8 与图9 所示的混淆矩阵分别展示了LSR-Net 在ICBHI-2017 与Coswara 上对每种肺音分类的具体情况。由图8 的混淆矩阵可知,该模型在ICBHI-2017 分类结果的各项指标中,特异性指标为88.75%,敏感性指标为72.04%,ICHBI-score 为80.39%;由图9 的混淆矩阵可知,该模型在Coswara 上分类结果的各项指标中,特异性指标为80.66%,敏感性指标为77.69%,准确率为79.18%。由此可以看出,LSR-Net 对肺音的识别效果较VGGish 优化模型与VGG19 有较大提升。
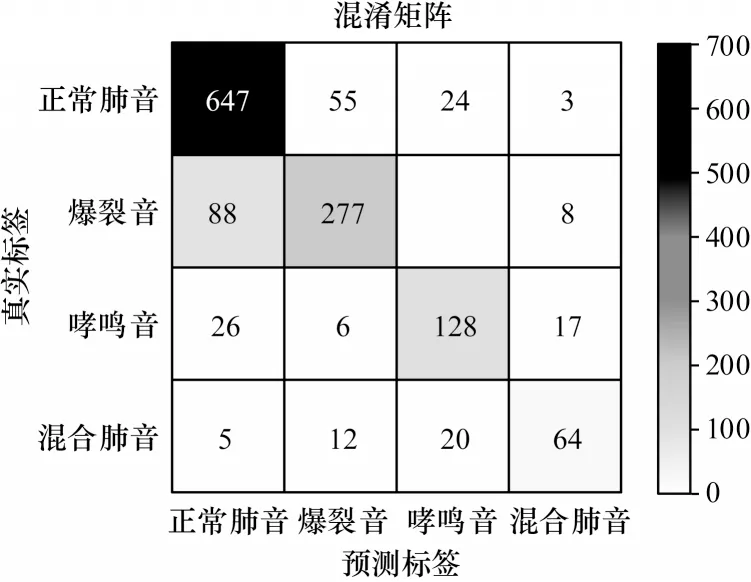
图8 LSR-Net 在ICBHI-2017 上对肺音识别的混淆矩阵Fig.8 The confusion matrix of LSR-Net for lung sound recognition on ICBHI-2017

图9 LSR-Net 在Coswara 上对肺音识别的混淆矩阵Fig.9 The confusion matrix of LSR-Net for lung sound recognition on Coswara
为探究识别效果的提升是否仅与CatBoost 算法有关,而与双源域的预训练模型结合无关,本文分别将VGG19 单独结合CatBoost、将VGGish 优化模型单独结合CatBoost 在肺音数据集上进行实验,结果如表6 和表7 所示。实验结果显示,无论是VGG19结合CatBoost,亦或是VGGish 优化模型结合CatBoost,对肺音的识别效果均没有LSR-Net 好,从而验证了本文提出的双源域迁移学习方法的性能优越性。

表7 CatBoost 算法对模型性能的影响(Coswara 数据集实验结果)Table 7 Impact of CatBoost algorithm on model performance(experimental results on Coswara dataset)%
2.6 不同的方法在肺音数据集上识别效果比较
对数梅尔频率谱与梅尔频率倒谱系数是音频领域常用的特征,神经网络、支持向量机与极端梯度提升决策树则是音频识别中常用的分类器。表8 显示了常用识别方法与LSR-Net 在Coswara 上的实验结果。实验结果显示,本文中的LSR-Net无论是特异性或是敏感性指标都明显高于对比的常用识别方法,这主要得益于LSR-Net 中的预训练参数一定程度上解决了音频信号共性特征学习的问题,从而表现出色。

表8 不同方法的性能比较(Coswara 数据集实验结果)Table 8 Comparison of performance of different methods(experimental results on Coswara dataset)%
目前有关肺音识别的研究大多集中在ICBHI-2017 数据集上,将不同识别方法与LSR-Net 进行比较,实验结果如表9 所示。实验结果显示,本文提出的LSR-Net 的特异性、敏感性指标与ICBHIscore 均高于其他对比方法。此外还可以发现,当未使用数据增强或者迁移学习方法时,识别效果欠佳,这再次验证了本文从迁移学习方法着手的正确性。
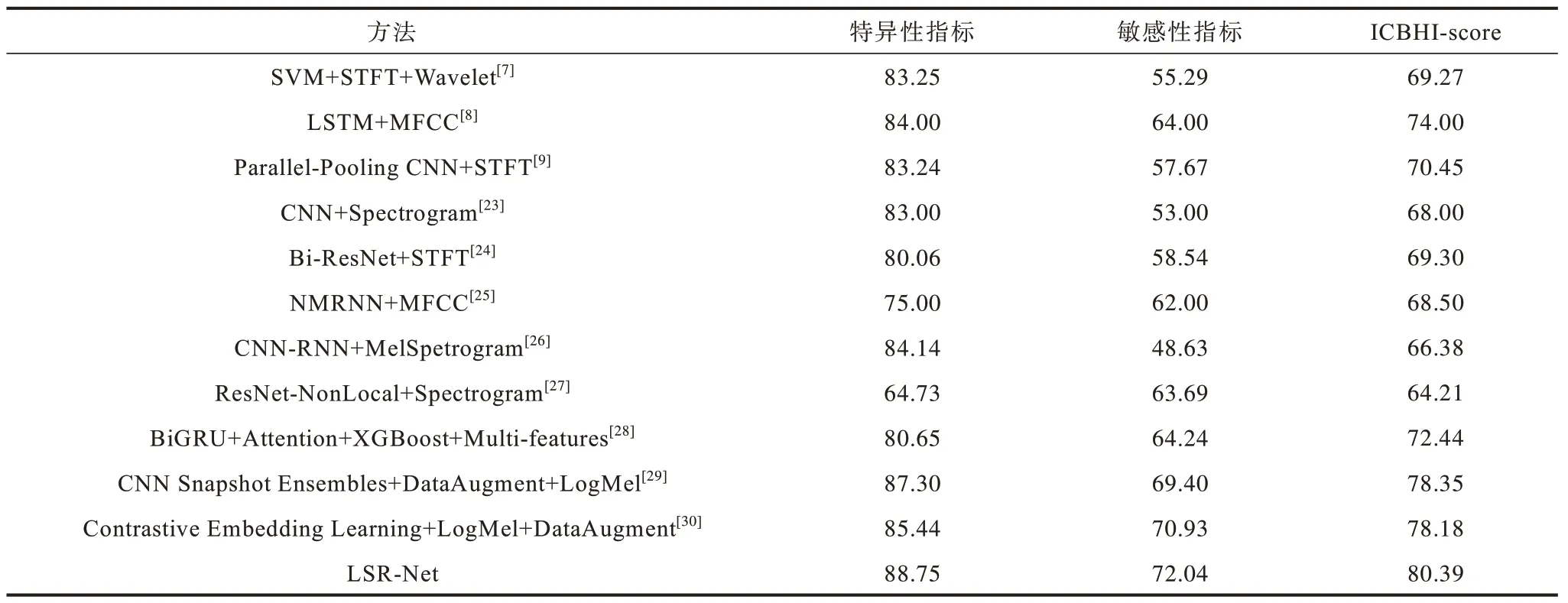
表9 不同方法的性能比较(ICBHI-2017 数据集实验结果)Table 9 Comparison of performance of different methods(experimental results on ICBHI-2017 dataset)%
3 结束语
本文针对肺音识别中因数据集规模较小所致识别精度不高的问题,提出一种基于双源域迁移学习的肺音识别方法。借助VGGish 网络在Audio Set 上的预训练参数以及VGG19 在ImageNet 上的预训练参数,缓解网络的过拟合问题。在此基础上,提出一种VGGish 优化模 型、VGG19 与CatBoost 算法结 合的肺音识别模型LSR-Net。在ICBHI-2017 与Coswara 数据集上的实验结果表明,LSR-Net 性能优于现有的肺音识别方法。下一步将尝试把特征融合、帧加权等技术运用到LSR-Net中,并综合考虑多个不同源域上的预训练模型,探究更适合肺音声学特征的识别模型,为临床肺音听诊提供更高精度的辅助识别技术。
