基于显著区域优化的对抗样本攻击方法
2023-09-18李哲铭王晋东侯建中张世华张恒巍
李哲铭,王晋东,侯建中,李 伟,张世华,张恒巍
(1.信息工程大学 密码工程学院,郑州 450001;2.中国人民解放军陆军参谋部,北京 100000)
0 概述
在图像分类任务中,基于卷积神经网络的图像分类模型已经达到甚至超过人眼的能力水平[1]。但目前研究表明,当在原始图像上添加特定扰动后,卷积神经网络会以高概率分类出错[2-3]。更重要的是,这些扰动对人眼和机器来说都是不易察觉的[4]。对抗样本的存在给深度神经网络安全带来了巨大的挑战,严重阻碍了模型的实际部署和应用[5-6]。与此同时,对抗样本作为一种技术检测手段,也为测试和提升图像分类模型的安全性和鲁棒性提供了良好的工具[7]。
对抗样本的攻击性能主要体现在两个方面:一是能够欺骗模型,可以使性能良好的图像分类模型分类出错;二是能够欺骗人眼,即人眼无法有效区分对抗样本和原始图像。根据攻击者对模型的了解程度,可以将对抗样本攻击分为白盒攻击和黑盒攻击。白盒攻击需要攻击者掌握模型的结构和参数,但由于实际模型部署中通常设有防护机制,攻击者往往难以获得模型的内部信息。因此,黑盒攻击得到研究者的更多关注。文献[8]提出了FGSM(Fast Gradient Sign Method)方法,该方法可以利用对抗样本的迁移性进行黑盒攻击。文献[9]将动量项引入到对抗样本的生成过程中,提出MI-FGSM(Momentum Iterative Fast Gradient Sign Method)方法,稳定了反向传播过程损失函数的更新方向,进一步提高了对抗样本的黑盒攻击成功率。但由于以上方法是以全局扰动的方式在原始图像上添加对抗噪声,生成的对抗样本与原图存在较大的视觉差异,使得对抗样本因过多的对抗纹理特征而易被人眼察觉。
为有效降低对抗扰动的可察觉性,提高对抗样本的视觉质量,提升其攻击性能,本文将对抗扰动限制在一个特定的局部区域内,并采用优化算法迭代更新损失函数,从而降低对抗扰动的可察觉性,并将攻击成功率保持在较高水平,即主要通过深度神经网络的显著目标检测技术生成可视化显著图,利用该图生成二值化掩模,将该掩模与对抗扰动相结合从而确定显著攻击区域,实现对抗扰动的局部重点区域添加。此外,为进一步提高黑盒攻击成功率,本文通过引入Nadam 算法,优化损失函数更新方向并动态调整学习率,提高损失函数收敛速度,有效避免函数更新过程中的过拟合现象,以生成攻击性能更好的对抗样本。
1 相关工作
随着对抗样本研究的逐步深入,单纯提升对抗样本的攻击成功率已经不能满足对抗攻击测试的要求,还需要考虑由于对抗扰动过大带来的对抗攻击隐蔽性降低的问题。因此,本文研究围绕对抗攻击的隐蔽性,提升其攻击性能,在保持对抗样本的黑盒攻击成功率较高的同时,缩小对抗扰动添加区域,降低对抗样本被发现的可能。
1.1 对抗样本攻击方法
由于本文研究是在FGSM 类方法基础上提出来的,因此首先介绍该类的相关方法。文献[8]提出的FGSM 方法是该类方法的原始版本,该方法沿损失函数的梯度方向单次添加对抗扰动,单步生成的方式使得白盒攻击成功率较低;针对攻击过程中欠拟合问题,文献[10]对FGSM 进行了改进,提出了I-FGSM(Iterative Fast Gradient Sign Method)方法,该方法采用多步迭代的方式添加对抗扰动,使得对抗样本的白盒攻击成功率得到提高,但黑盒攻击成功率有所下降;文献[9]通过引入动量项稳定了损失函数的前进方法,提高了对抗样本的迁移攻击能力;文献[11]提出了DIM(Diverse Input Method)方法,在每轮次迭代循环前,首先对图像进行随机尺度变换和随机填充,提高了输入多样性,有效缓解了过拟合;文献[12]利用图像平移不变性提出了TIM(Translation-Invariant Method)方法,使用卷积的方法实现了图像的批量输入及变换,从而提升了攻击成功率;文献[13]利用图像保损变换,通过尺度不变性实现了模型的拓增,使得生成对抗样本的黑盒攻击能力更强。以上方法均在整张图像上采用全局扰动的方法添加对抗噪声,因此存在对抗样本与原图像视觉差别较大的问题。
1.2 显著区域生成方法
显著区域构建的方法一般可分为模型解释的方法和显著目标检测的方法[14]。模型解释的方法可以将分类结果通过反向传播算法逐层传递到输入层,从而确定图像显著特征。文献[15]通过非线性分类器的逐像素分解,提出了一种理解分类决策问题的通用解决方案;文献[16]通过SmoothGrad 方法锐化了基于梯度的敏感度图,并讨论了敏感度图的可视化参数设置方案;文献[17]提出的CAM(Class Activation Mapping)方法将卷积神经网络的全连接层替代为全局平均池化层,从而保留了图像特征的位置信息,但该方法需要修改网络,并重新训练。在显著目标检测的方法中,文献[18]通过子集优化的方法选择显著性对象标注框,该方法在多对象图像中效果较好,但存在边界模糊的问题;为提升边界精度,文献[19]对编码器和解码器设置双向反馈机制,并使模型从显著性预测中提取到更多的边界信息;文献[20]利用弱监督信息建立分类网络和描述网络,并利用转移损失函数协同训练优化模型。基于目标检测的显著图生成方法只需要输入原始图像,而不再需要攻击模型的梯度信息,更符合黑盒攻击的情况设定,因此,该方法选用了显著目标检测的方法生成显著图。
2 基于显著区域优化的攻击方法
本节首先介绍本文的研究思路,由于同一图像不同部位的语义信息含量不同,因此可对重点区域添加对抗噪声,非重点区域少添加或不添加对抗噪声。然后描述将显著图与对抗样本生成过程相结合的方法,实现对抗扰动的局部添加。在迭代生成对抗样本的过程中,通过引入性能更好的优化算法提高对抗样本生成过程中损失函数的收敛速度,从而提升对抗样本的迁移攻击能力。
2.1 问题分析与研究思路
在以往的对抗样本生成方法[9,11]中,通常是对原始图像上每个像素点都进行修改,最终使图像分类决策过程中的损失函数值变大,导致分类出错。这些方法将图像上所有的点看成了等同价值的像素,但在实际上,这种全局扰动的添加方式将一些非必要对抗噪声添加到原始图像上,使得对抗纹理特征更明显,违背了攻击不可察觉的要求,从而降低了对抗样本的攻击性能。同时,将相同大小的对抗扰动添加到不同的位置,其视觉效果也不一样,如果添加到色彩丰富与细节较多的图像语义区域,对抗扰动则不是很明显,而添加到图像的背景区域,如图1 所示,如在蓝天、草地等部位,对抗扰动会比较引人注目,更易被察觉检测,从而造成了攻击失效。因此,本文方法通过在图像显著区域添加对抗噪声,降低了扰动的可察觉性,从而提高了对抗样本的攻击隐蔽性。

图1 对抗样本生成示例Fig.1 Example of adversarial sample generation
此外,由于显著区域的引入会缩小对抗扰动的添加范围,在一定程度上对抗攻击隐蔽性的提高会以黑盒攻击成功率的降低为代价,因此本文分析了对抗样本的攻击特点,引入性能更好的Nadam 优化算法,通过梯度累积及自适应学习率的方法,优化损失函数的收敛过程,使得最终生成的对抗样本具有更好的隐蔽性和攻击性。
2.2 显著区域优化攻击方法
根据图像中语义信息量的不同,可以将图像分为主体部分和背景部分。主体部分对图像分类结果有更大的影响,当对该部分进行遮挡时,图像分类模型的精度会有明显的下降。因此,本文考虑在语义主体的显著区域内添加对抗扰动。
显著目标检测技术可以识别出图像中视觉最明显的物体或区域,并且该区域几乎与图像中的分类标签对应的信息相同。因此,可以运用该技术提取出图像中的主体部分,对该区域添加对抗扰动。在本文研究中,使用了DCFA(Deformable Convolution and Feature Attention)网络模型[21]生成图像的显著图。该模型在图像的低层细节和高层语义信息中提取不均匀的上下文特征,并在空间域和通道域中分配特征的自适应权重,使得生成显著图的边界更清晰准确。该方法将原始图像转化成了像素值在0~255 之间的灰度图,该灰度图称为显著图S。在该显著图中,其语义特征明显的主体部分更接近白色,而主体之外的背景部分更接近黑色,图像的显著特征区域即为白色的区域。
通过显著图可以将原图像中的显著区域圈定,将原图像分割成了添加对抗扰动区域和不添加对抗扰动区域,进一步将显著图S转换为二值化的显著掩模M,可表示如下:
其中:si,j是显著图S的第(i,j)位置像素值;ϕ为对应的像素阈值;mi,j是二值化后显著掩模M对应的第(i,j)位置的值。该步骤只是对显著图的像素值进行二值化,便于与对抗扰动结合,从而进行添加扰动的取舍,图像大小不发生改变。此时,生成的显著掩模图是一个由0 和1 组成的多维数组,对应显著图特征区域是1,非特征区域为0。
将显著掩模与文献[9]中的动量法结合可以迭代生成对抗样本,其迭代过程可表示为如式(2)~式(5)所示。
其中:g0=0、μ=1、为参数及图像初始化的过程⊙M是将最后一轮迭代生成的对抗样本与原始图像作差,从而得到对抗噪声,再与显著掩模做Hadamard 乘积,从而将显著区域内的对抗扰动保留下来,而非显著区域内的对抗扰动置为零。该方法通过显著掩模将对抗扰动添加过程限制在显著区域内,减弱了背景区域的对抗扰动纹理特征,使得攻击具有更好的隐蔽性。
同时,在实验中发现,当只对显著区域添加对抗扰动时,虽有效地提高了对抗攻击的隐蔽性,但也在一定程度上降低了对抗样本的黑盒攻击成功率。因此,本文从优化的角度对该攻击方法进行了完善提升,以保证在提高攻击隐蔽性的基础上,攻击成功率仍在较高水平。
对抗样本的生成过程是一个有限制条件的优化过程。该过程基于反向传播算法中损失函数的梯度计算,逐步增大图像分类过程中的损失函数值,从而使得分类出错。而在上文提到的动量法中,将损失函数的更新过程以动量累积的形式加以集成,稳定了损失函数的更新方向,从而能够使得对抗样本的生成过程具有更好的收敛特性。利用动量法生成对抗样本虽然攻击性较强,但由于噪声固化、学习率固定等原因,黑盒攻击成功率并不是很高。因此,本文研究将性能更强的优化器引入到对抗样本的局部优化攻击过程中,在图像的显著区域内对生成过程进行优化。
寻找性能更好的优化器主要有两个思路:一方面是对学习路径的优化;另一方面是对学习率的优化。因此,本文方法通过引入Nesterov 算法和RMSprop 算法,组合 形成Nadam 算法,如图2 所示,加快损失函数更新的收敛速度,更快地到达损失函数极大值点,提高对抗样本的迁移性。
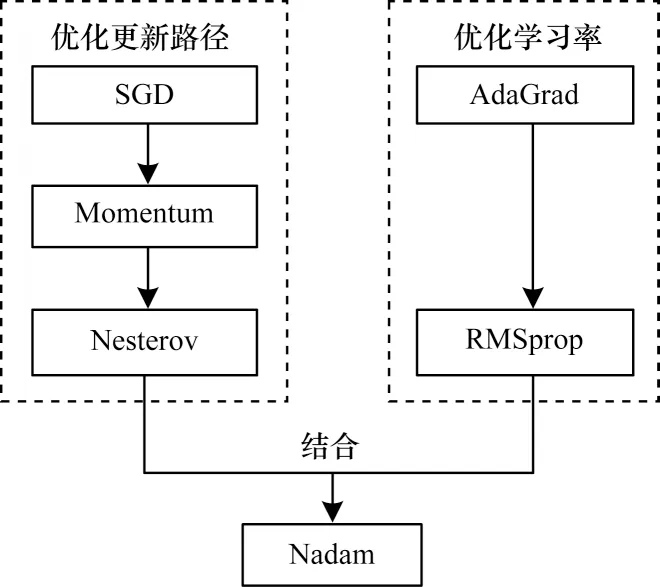
图2 优化算法关系Fig.2 Optimization algorithm relationship
以上的过程可以看作是对动量法的改进,式(6)、式(7)首先引入了Nesterov 算法,实现了在现有对抗样本生成过程中的梯度跳跃,帮助损失函数前进过程中预估梯度变化,并将这种变化计入梯度累积过程,有助于算法更快地跳出局部极值点。
之后,通过RMSprop 算法引入第二动量,实现学习率的动态调整,如式(8)~式(11)所示。
其中:mi+1为第一动量,实现对梯度的累积;β1为其对应的衰减因子;vi+1为第二动量,实现对梯度平方的累积,β2为衰减因子。第一动量的主要作用是稳定损失函数更新过程中的前进方向,而第二动量主要是用以动态调整损失函数前进过程中的学习率,使函数避免陷入局部极值点。
由以上方法可以看出,Nadam 优化算法集成了第一动量和第二动量的优点,可实现梯度历史数据和预估数据的累积,实现损失函数更新路径和学习的优化,可有效提高对抗样本的生成效率。
该优化算法可以自然地与显著区域扰动生成方法相结合,形成基于掩模Nadam 迭代快速梯度法(Mask-based Nadam Iterative Fast Gradient Method,MA-NA-FGM),其过程如图3 所示。在该过程中,首先将原始图像输入到DCFA 模型中,得到显著图并二值化后得到显著掩模;然后将原始图像输入到图像分类模型中,并利用Nadam 优化算法与卷积神经网络反向传输过程中的梯度信息,迭代生成对抗样本,将得到的全局扰动对抗样本与原图像作差,得到全局的对抗噪声;最后再将全局噪声与显著掩模进行Hadamard 乘积,便可得到显著区域内的对抗噪声,将该噪声与原图像相结合,得到最终的显著区域对抗样本。

图3 基于掩模Nadam 迭代快速梯度法示意图Fig.3 Schematic diagram of mask-based Nadam iterative fast gradient method
2.3 对抗样本攻击算法
基于以上分析,本文设计了单模型条件下的对抗样本攻击算法,如算法1 所示。在该算法中,第1 步确定了对抗样本攻击过程的初始条件,第4 步和第5 步是对损失函数学习路径的优化,可以有效地将梯度的历史数据和预估数据考虑进去,从而避免损失函数优化过程中的局部震荡。第6 步引入了第二动量,根据梯度的大小动态调整学习率的大小,从而实现了损失函数更新过程中的动态步长调整,避免了在最后极值点附近反复震荡。在第11、12 步中,实现了对抗扰动的显著区域添加,从而形成了攻击性更强的对抗样本。
算法1单个分类模型攻击算法
输入原始图像x,相应的正确标签ytrue,原始图像对应的显著掩模M,一个卷积神经网络f与相应的交叉熵损失函数L(x,ytrue;θ),总迭代轮数T,当前迭代步数t,输入图像的维度D,对抗扰动的尺寸ε,衰减因子β1与β2

3 实验结果与分析
本节首先介绍实验环境设置、所用的数据集及评价指标等内容,然后通过在数据集上进行大量实验,验证了显著区域对分类结果的影响,并从攻击成功率和攻击隐蔽性两方面来衡量攻击性能,通过与基准方法相比体现本文方法的优势。
3.1 实验设置
实验环境:本文使用Python 3.8.5 和Tensorflow 1.14.0 深度学习框架进行编程及实验测试,服务器内核为Intel Core i9-10900K,内存为64 GB,主频为3.7 GHz。为实现对抗样本的快速生成,在实验中使用NVIDIA GeForce RTX 2080 Ti GPU 加速完成计算过程。
数据集及网络模型:为验证本文所提对抗样本生成方法的有效性,从ImageNet dataset[22]的验证集中随机挑选1 000 张图像,每张图像属于不同的类别。这些图像在所涉及到的图像分类模型上经过测试均能被正确分类,从而使得添加对抗扰动后被误分类的图像均为对抗样本。在攻击测试过程中,使用了4 个正常训练模型[23-25]和3 个对抗训练模型[26]。
评价指标:
1)攻击成功率(Attack Success Rate,ASR)指标。该指标表征的是对抗样本欺骗图像分类模型使之分类出错的能力,也即分类错误率。在实验过程中,用生成的对抗样本在不同的图像分类模型上进行测试,分类出错的图像即为对抗样本,其在总图像个数中所占的比例,也即攻击成功率。攻击成功率计算公式如式(12)所示:
2)图像特征差异性指标。通过引入图像方差,将图像的行间像素信息作为图像的特征值。图像的像素方差计算如式(13)所示:
通过计算原始图像和对抗样本的各像素点位置的方差值,运用特征值相似指标来评估原始图像与对抗样本之间的距离。通常,在计算方差特征值时需要对原始图像进行缩放,m为缩放后的图像尺度,Xˉ为图像每行像素值的平均值。在衡量原始图像的方差特征值与对抗样本的方差特征值的差异时,将其差值进行相似性度量,设置置信度来衡量发生改变的像素点的数量,具体用方差特征相似度(Variance Feature Similarity,VFS)来量化表述,从而方便度量在不同对抗样本生成方法下对抗噪声添加效果的差异性和扰动不可察觉性的强弱。该指标为未改变像素点占所有像素数量的比例,因此为寻找对抗扰动更隐蔽的生成方法,该指标越大越好。
3)图像结构相似性指标。用结构相似性指标(Structural Similarity Index Measure,SSIM)[27]来 衡量原图像与对抗样本之间的差异性,该指标相对于峰值信噪比(PSNR)等传统指标,更能符合人眼的判断标准。该指标主要比较亮度、对比度和结构三方面的内容,定义如式(14)~式(17)所示。
其中:l(x,xadv)比较的是原始图像与对抗样本之间的亮度信息;c(x,xadv)和s(x,xadv)分别对应的是对比度信息和结构信息;μx和μxadv为原始图像和对抗样本像素信息对应的平均值;σx和σxadv为像素标准差;σxxadv为原始图像与对抗样本之间的协方差;C1、C2、C3是用以保持l(x,xadv)、c(x,xadv)和s(x,xadv)稳定性的常数。该指标通常归一化为[-1,1]范围内,数值越大,说明两张图像结构相似度越高,本文的目标是使该指标越大越好。
3.2 显著区域对分类结果的影响
在本文的对抗攻击过程中,添加对抗扰动主要是在显著区域内开展。因此,首先验证图像的显著区域对分类结果的影响作用。在实验中设计了基于显著掩模及反向显著掩模两组样本来对比分析,与原图像作Hadamard 乘积可得到只保留显著区域图像Adv-SR,及去掉显著区域的图像Adv-non-SR。利用DCFA 模型生成显著图,之后生成显著性掩模,将对应的像素阈值ϕ设定为15,即大于15 像素值的部位掩模值取为1,在Adv-SR 中作保留处理,在Adv-non-SR 中作去除处理。对比示意图如图4所示。

图4 原始图像、Adv-SR 及Adv-non-SR 对比示意图Fig.4 Schematic diagram of the comparison of original image,Adv-SR and Adv-non-SR
在6 个图像分类模型上进行分类测试,其结果如图5 所示。

图5 原始图像、Adv-SR 及Adv-non-SR 分类正确率对比Fig.5 Comparison of classification accuracy of original image,Adv-SR and Adv-non-SR
从图5 可以看出,Adv-SR 和Adv-non-SR 相对于原始图像的分类正确率均有所下降,Adv-SR 的正确率平均下降了4.8 个百分点,而Adv-non-SR 平均下降了73.3 个百分点。因此,显著区域在图像分类过程中发挥着更大的作用,当对该区域进行攻击时,产生的对抗样本更能有效地使模型分类出错。
3.3 模型攻击对比实验
能够成功实现攻击是对抗样本的基础,本文首先进行图像分类模型的攻击成功率测试。在正常训练模型上生成对抗样本,随后在7 个图像分类模型(包括4 个正常训练模型和3 个对抗训练模型)上进行攻击测试,以白盒和黑盒情况下的攻击成功率为指标衡量对抗样本的攻击表现。实验中选用MIFGSM 为基准方法,验证本文所提出的MA-MIFGSM(Mask-based Momentum Iterative Fast Gradient Sign Method)、MA-NA-FGSM(Mask-based Nadam iterative Fast Gradient Sign Method)方法的有效性,所涉及到的超参数为:最大扰动值为ε=16 像素,迭代轮数T=10,动量衰减因子μ=1,Nadam 衰减因子β1=0.9,β2=0.999,稳定系数δ=10-14。实验结果如表1所示。从表1 数据可以看出,未经过优化过程的显著区域对抗样本生成方法相对于全局扰动的对抗样本生成方法,白盒攻击和黑盒攻击成功率均有所下降,如在Inc-v3 模型上生成的对抗样本作白盒攻击时,MA-MI-FGSM 比MI-FGSM 成功率下降0.3个百分点,而在Inc-v3ens3模型上进行黑盒攻击时,攻击成功率下降了1.7 个百分点,这说明背景区域在一定程度上也影响图像分类的结果,并且重点区域添加的对抗扰动强度也不够。当引入Nadam 优化算法后,对应的攻击算法黑盒攻击成功率得到较大幅度的提升,在Inc-v4 上生成的对抗样本当在其他6 个图像分类模型上进行迁移攻击时,其平均的黑盒攻击成功率提高了7.55 个百分点,体现了本文攻击算法的优势。

表1 MA-NA-FGSM 等方法单模型攻击成功率 Table 1 Single-model attack success rate of methods such as MA-NA-FGSM %
本文设计实验将MA-DIM(Mask-based Diverse Input Method)、MA-NA-DIM(Mask-based Nadam Diverse Input Method)和DIM 进行对 比,如 表2 所示。其中,在尺度变化时变换范围为[299,330)像素,其余超参数如前文所述。与基准方法相比,显著区域优化的生成方法显然更具有攻击性,实现了攻击成功率和攻击隐蔽性的性能提升,如在IncRes-v2上生成的对抗样本,MA-NA-DIM 方法相对于MAMI-DIM 方法提高了7.2 个百分点,比DIM 方法的平均黑盒攻击成功率得到进一步提升。需要注意的是,对抗噪声仅仅添加到了图像的显著区域内,此时噪声可察觉性已实现了较大幅度的降低。

表2 MA-NA-DIM 等方法单模型攻击成功率 Table 2 Success rate of single-model attack by methods such as MA-NA-DIM %
在表1 和表2 中,分别进行白盒测试和黑盒攻击测试,4 个模型为对抗样本的生成模型,即分别利用Inc-v3、Inc-v4、IncRes-v2 和Res-101 生成对抗样本,利用在这些已知模型上生成的对抗样本在4 个已知模型和3 个未知模型(Inc-v3ens3、Inc-v3ens4和IncRes-v2ens)上进行攻击测试,在已知模型上进行的是白盒测试,而在未知防御模型上进行的是黑盒测试。表1 中各方法主要是在MI-FGSM 的基础上进行改进对比,其中,MA-MI-FGSM 是在MI-FGSM 的基础上进行了显著性掩模处理,MA-NA-FGSM 是在MI-FGSM 的基础上进行了Nadam 算法优化及显著性掩模处理。类似地,在表2 各方法中,主要是对DIM 方法对 比分析,MA-DIM是在DIM 的基础上进行了显著性掩模处理,MA-NA-DIM 是在DIM 的基础上进行了Nadam 算法优化及显著性掩模处理。
3.4 图像质量对比实验
图像质量对比实验主要有以下3 种:
1)特征差异性指标对比实验。首先对不同方法生成的对抗样本图像特征进行对比分析,运用MIFGSM 方法与本文所提出的MA-MI-FGSM 方法分别在1 000 张图像上生成对抗样本。然后为了方便计算,将对抗样本图像与原始图像缩放至64×64 像素值大小,并将图像分割成64 维的张量形式,以行向量为单位计算其对应的平均值,并求取相应的方差值。将该方差值作为图像的特征值,计算其相似度指标,如图6 和图7 所示。其中,星标、三角标和圆标分别对应原图像素方差、对抗样本像素方差和像素方差的差值,其中圆标线越长,表示原始图像和对抗样本的差值就越大,特征的区别度也就越大,表明在生成对抗样本过程中对原始图像的改动(即添加的对抗扰动)也就越大。因此,本文的目的在于缩小原始图像与对抗样本之间像素方差的差值。由于该差值为反向指标,为更直观地度量其差值,本文引入了特征相似度的概念,即改变的像素点个数在像素值总数所占的比例,而是否发生改变用方差置信度来表示,例如设置置信度为0.95 时,表示变化量在原图方差值的5%浮动范围。在置信度设置为0.95 时,得到对抗样本与原始图像的特征相似度如图6(b)、图6(c)和图7(b)、图7(c)所示,特征相似度越高,说明对抗样本与原始图像越接近,其对抗扰动的不可察觉性越好。相对于全局扰动的对抗样本生成方法,利用本文方法生成的对抗样本与原始图像相比特征相似度更高,这主要是由于在全图像添加对抗扰动的过程中,在图像的背景部分引入了更多的对抗噪声,从而使得对抗样本图像与原始图像之间的特征差异性更大。而本文所提出的方法通过在图像的主体语义区域添加对抗扰动,在尽可能小的范围内对原始图像进行改动,从而使得对抗样本与原始图像之间的特征相似度更大。

图6 “降落伞”对抗样本特征相似度对比示意图Fig.6 Schematic diagram of the "parachute" adversarial examples feature similarity comparison

图7 “熊猫”对抗样本特征相似度对比示意图Fig.7 Schematic diagram of the "panda" adversarial examples feature similarity comparison
对整个实验数据集进行各方法之间的对比分析,实验结果如表3 所示。通过表3 数据可以看出,MI-FGSM 和DIM 的特征相似性指标相差不大,平均值分别为0.534 和0.546,而其对应的显著区域优化方法MA-NA-FGSM 和MA-NA-DIM 的平均特征相似性指标分别为0.697 和0.693,数据指标分别实现了30.5%和26.9%的性能提升。

表3 特征相似性指标对比 Table 3 Comparison of feature similarity indicators
2)结构相似性指标对比实验。为进一步对比原始图像与对抗样本之间在亮度、对比度和结构相似性之间的关系,本文对不同方法生成的对抗样本分别与原始图像进行了结构相似性对比。实验利用ImageNet 数据集中的1 000 张图像,在4 个图像分类模型上分别进行了攻击实验,不同方法的结构相似性指标如表4 所示。通过表4 可以看出,相对于基准方法MI-FGSM 和DIM,本文所提出的对抗样本生成方 法MA-MI-FGSM、MA-NA-FGSM 和MA-DIM、MA-NA-DIM 其结构相似性指标均实现了较大的提高,如在Inc-v3 上利用MI-FGSM 生成对抗样本,其平均SSIM 值为0.574,而利用本文所提出攻击方法MA-MI-FGSM 生成对抗样本的平均SSIM 值为0.785,其提高幅度为32.0%,这说明了本文所提方法可以有效地提高对抗样本与原始图像之间的相似性。同时,当引入Nadam 优化器时,对抗样本与原始图像的结构相似性指标的提高幅度不大,这也验证了优化器的主要作用为提高对抗样本的黑盒攻击成功率。在提高结构相似性的过程中,主要是显著区域添加对抗扰动的方法在发挥作用。
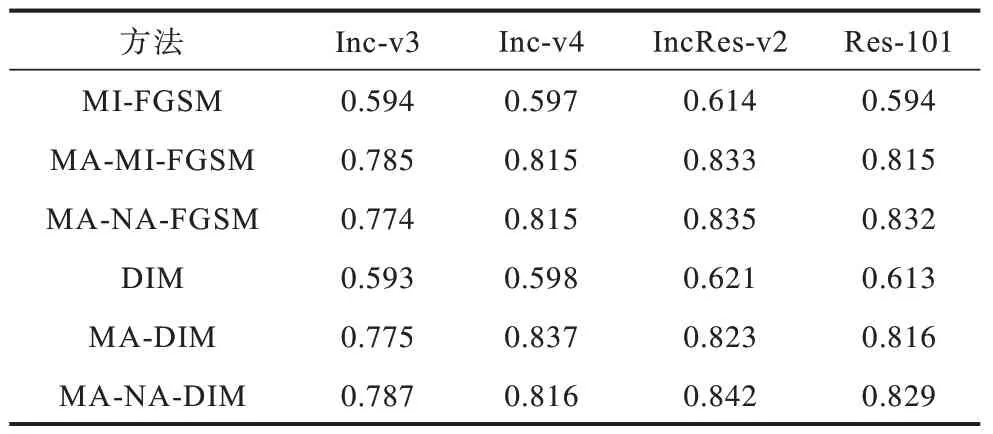
表4 MA-NA-DIM 等方法结构相似性指标对比 Table 4 Comparison of structural similarity indexes of methods such as MA-NA-DIM
此外,为验证本文方法在集成模型上的攻击表现,还通过逻辑值集成的方法进行了集成模型的攻击实验,实验结果如表5 所示。实验在4 个普通训练模型上生成对抗样本,并在3 个对抗训练模型上进行攻击测试,用SSIM 指标衡量对抗攻击的隐蔽性,用ASR 指标衡量对抗样本的攻击性。可以看出,MA-NA-SI-TI-DIM 相对于基准的SI-NI-TI-DIM 方法实现了攻击隐蔽性和攻击成功率的双重提升,其中,显著性指标SSIM 提高了27.2%,黑盒攻击成功率也保持在了92.7%的水平,进一步证明了本文方法的优势。
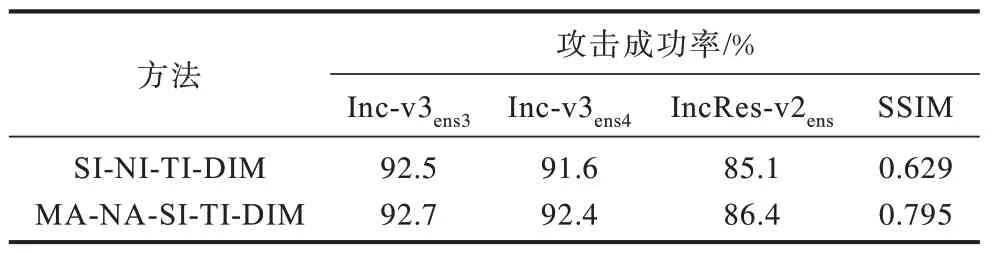
表5 MA-NA-SI-TI-DIM 等方法攻击性能对比 Table 5 Comparison of attack performance of methods such as MA-NA-SI-TI-DIM
3)人工评估测试实验。为更清晰直观地展现对抗样本像素级的扰动细节,并有效评估本文方法在实际应用中的有效性,在ImageNet 数据集上生成对抗样本并进行人眼评估测试。与显著区域优化的生成方法类似,MI-FGSM 方法同属于利用反向传播过程中的梯度信息生成对抗样本的方法,因此,利用这两种方法生成对抗样本,并在调查人群中比较图像对抗扰动的不可感知性。该实验随机选取了10 组图像,每组评测图像由原始图像、MIFGSM 生成的对抗样本及MA-MI-FGSM 生成的对抗样本组成,在每次的评测中,原始图像是固定的,而用于评测的图像是随机的,其中评测图像既包含原始图像又包含利用不同方法生成的对抗样本。图8 展示了原始图像及对抗样本图像的示例,其中,图8(a)为原始图像,图8(b)为利用MI-FGSM生成的对抗样本,图8(c)为利用MA-MI-FGSM 生成的对抗样本。

图8 不同方法生成的对抗样本与原始图像对比图Fig.8 Comparison diagram between the antagonistic sample generated by different methods and the original image
对抗扰动的不可察觉是人的眼睛对物理刺激所产生的感知反馈,由于人眼系统因人而异,并且对图像的判断也受其已有知识的影响。因此,为更为有效地评估对抗扰动的不可察觉性,该研究对不同人群进行了分类的调查研究。设置了甲、乙两个调查组,甲组为普及过对抗样本的人群,乙组为未普及过对抗样本的人群,每个调查组为50 人。在实验时,将10 组图像进行随机显示,让参与评测人员对原始图像和相应的随机图像的相似度进行打分,并要求参与者在3 s 内给出从0 分到10 分的具体分数,分数越高,表示相似度越高,而10 分意味着对抗样本与原始图像完全相同。
图9 所示为对图像对抗样本具备一定了解的人群打分结果,通过对比各条折线可知,让评测人员对随机显示的图像与原始图像的相似度进行打分,当随机显示的为原始图像时,平均得分最高,而当显示对象为对抗样本时,运用MA-MI-FGSM 生成的对抗样本得分更高,说明其与原始图像更为相似,原因主要是该方法将对抗扰动限制在了图像的主体显著区域内,而该显著区域内因固有的更为复杂的纹理特征,使得对抗噪声会被评测人员所忽视。而MIFGSM 方法生成的对抗样本会因背景区域过多的纹理特征而被人眼察觉。

图9 甲组人眼评测结果示意图Fig.9 Schematic diagram of group A eye assessment results
图10 所示为未接触过图像对抗样本人群的调查结果。从图10 可以看出,运用MA-MI-FGSM 生成的对抗样本比运用MI-FGSM 生成的对抗样本具有更高的得分,前者的平均得分为8.88 分,后者为8.16 分。同时也注意到,在第9 组的实验中存在两种方法生成的对抗样本得分相同的情况,这主要是图像的主体区域颜色单一,而背景区域反而复杂导致,如深色背景的白色卡车,此时只在主体区域添加对抗扰动,会影响人们对图像质量的判断。但从评测的整体结果来看,基于显著区域优化的方法在绝大多数情况下具有更强的隐蔽性。

图10 乙组人眼评测结果示意图Fig.10 Schematic diagram of group B eye assessment results
综合图9 和图10 的测评结果,基于显著区域优化方法生成的对抗样本达到了与原图像更高的相似度,从实际应用的角度证明了本文方法的有效性。同时也可以看出,对图像对抗样本知识有一定了解的人群往往对普通方法生成的对抗样本具有更高的辨识能力,这也说明了对抗样本知识普及的重要意义。
4 结束语
本文通过分析现有对抗样本攻击方法存在的对抗噪声明显、全局添加扰动易被察觉的问题,将显著目标检测的方法引入到对抗样本生成过程中,通过在原始图像上划分出显著区域,实现对抗扰动的局部添加。实验结果表明,通过与Nadam 优化算法的结合,保持并提高了对抗样本的攻击成功率,实现了对抗样本黑盒攻击成功率和扰动不可察觉性的双重提升。下一步可将显著区域进一步细化,实现显著区域的分级划分和对抗噪声的更精准添加,从而进一步提升对抗样本的攻击性能,为深度神经网络模型的实际部署和应用提供更好的攻击检测与安全测试手段。
