基于Transformer 的SM4 算法工作模式识别
2023-09-18池亚平岳梓岩林雨衡
池亚平,岳梓岩,林雨衡
(1.北京电子科技学院 网络空间安全系,北京 100070;2.中国科学院网络测评技术重点实验室,北京 100093)
0 概述
为了实现关键技术安全自主可控,国产加密算法不断发展更新,SM1、SM2、SM3、SM4 及SM9 算法分别在安全性、加密效率方面对标AES、SHA256、RSA 等国际加密算法,目前被广泛应用于国家信息安全领域。
在对密码系统进行监控时,多数情况下研究者只能获得通信传输中的密文,往往不能确定密码系统所采用的密码算法,导致密码分析和密码设备监控工作困难重重[1]。在国密算法密码应用中,对应用国密算法的密码设备的数据流进行密码算法识别和分析,及时发现信息系统在数据通信过程中是否采用规范的国密算法及规范的密码工作模式,可有效加强密码设备监管、检测和主动抵御恶意入侵。
此外,信息安全中的攻与防是相辅相成的,密码算法的识别研究是密码分析领域的重要分支之一,但密码算法识别本身就是变相地对密码算法进行攻击。而从密码算法的角度来看,对抗现有技术对密码算法的识别,也为密码算法设计实现带来了新的思考与考验,由此可见,密码算法识别的研究意义重大。密码算法识别目前有两方面的研究:一方面是利用逆向分析工程对加密算法进行代码层面的分析[2],另一方面是在唯密文条件下对密码算法进行识别,本文研究仅针对后者展开。
本文对SM4 算法5 种工作模式下的密文特征进行可视化分析,利用实验证明深度学习在密码算法识别研究中的可行性,提出一种基于Transformer模型的SM4 算法工作模式识别分类方案,并通过对比其他文献中的相关工作,验证所提方案的有效性。
1 相关工作
从公开文献来看,密码算法识别研究并不多见,现有方案主要针对分组密码展开研究,也取得了一些进展。在密码算法识别任务中,可利用统计检测发现不同分组密码密文的随机程度存在的差异,从而判断密文所属的密码算法。随机性测试方法多达上百种,其中美国商务部国家标准技术协会(NIST)公布的2010 版SP800-22 标准中的15 种随机性检测算法(以下简称NIST 随机性检测)[3]最为典型。
文献[4]指出除随机性相关统计检测外,还有一类统计检测方法与分组密码的分组长度、密码结构等有关,因此基于分组长度,把分组密码看作是一个随机的多输出布尔函数,将256 个密文分组进行异或操作,统计其结果的汉明重量,通过期望值计算判断是否服从二项分布。将此方法用于Rinjdael、Camellia 和SM4算法,结果表明,这3 种算法 分别从第4 轮、第5 轮和第7 轮开始呈现出良好的统计性能。
文献[5]根据密码学常识,提出针对密码算法识别任务中的分层思想,即先对密文按照密码体制类别进行分类识别,其中包含古典密码、序列密码、公钥密码、分组密码等,再识别具体密码体制,根据此思想设计双层密码算法识别方案并基于随机森林算法进行实验,结果表明,相比传统单层识别方案,该方案准确率提升了20%左右。
文献[6]完善了密码算法识别任务框架,通过对识别分类问题中的主要难点做进一步分析,对特征提取过程的各环节进行形式化定义,并以此为基准,探究包含随机性检测、统计学中的熵、最大熵、基尼系数等在内的不同特征的属性对识别分类准确率的影响,引入集成学习技术,采用多个基学习器集成对密文进行分类识别,防止选择单一分类器而导致分类模型泛化性能不足。实验结果表明,将熵作为特征提取函数的特征表现更稳定,且较文献[5]方案识别分类准确率有较大提升。
在密码算法识别研究工作中,特别是在基于传统机器学习的方案中,将通过分析密文样本特征,从而识别其密码算法视作文本分类任务,各类密文特征工程的构建过程十分复杂,如随机性特征、熵相关特征等,还需要人工分析筛选有意义的分类特征。深度学习是机器学习和人工智能研究领域的延伸,利用深度学习技术,学者们已在很多领域取得重要成就。卷积神经网络(Convolutional Neural Network,CNN)被证明可以高效提取目标样本特征,被广泛应用于图像识别[7]等领域,并取得了显著成果。文本分类是许多数据分析应用的基础,在这一领域,相较于传统机器学习,深度学习往往表现更佳。文献[8]通过构建神经网络,实现了MARS、RC6、Rinjdael、Serpent、Twofish 等5 类密码算法在ECB 模式下的正确分类,得出在密码生成的底层数学运算过程中存在固有的特性,这些特性在密文中留下了痕迹,因此,可以通过神经网络提取深层次特征来实现分类。文献[9]分别对文本、语音、图片形式的明文文件进行加密,后对密文按8 bit 分块,采用累计求和的方法将分块后的密文映射为二维的向量矩阵,并将得到的二维向量通过固定卷积核的卷积网络,提取密文的卷积特征向量,最后利用随机森林模型对密文进行分类,结果表明,该方法对AES、3DES、Blowfish 的识别准确率平均达到83%。文献[10]在构造密文特征时选择基于NIST 随机性测试,首先对密文按固定大小分块,然后对每一分块进行包括频率检验、块内频数检验、非重叠板块检验、游程检验、近似熵检验等5 种随机性测试,得到每块密文对应的测试结果,并将每一个密文分块的随机性测试结果作为密文的二维特征向量,采用CNN 和循环神经网络(Recurrent Neural Network,RNN)模型对密文特征进行训练,获得了较高的识别准确率。利用深度学习技术对密文进行特征提取,挖掘密文内部特征并实现分类是密码算法识别方面新的研究热点。
此外,在针对分组密码的公开发表的文献中,很少对其工作模式进行分析,多数文献都默认使用分组密码ECB 模式进行加密获得密文样本。分组密码工作模式可以使算法安全性、加密效率等方面得到增强,不同的应用场景需要采用不同的工作模式。文献[11]定义了分组密码5 种常见的工作模式,包括电码本(Electronic CodeBook,ECB)、密文分组链接(Cipher Block Chaining,CBC)、密文反馈(Cipher FeedBack,CFB)、输出反馈(Output FeedBack,OFB)、计数器模式(CounTeR,CTR)。这5 类工作模式基本情况见表1。
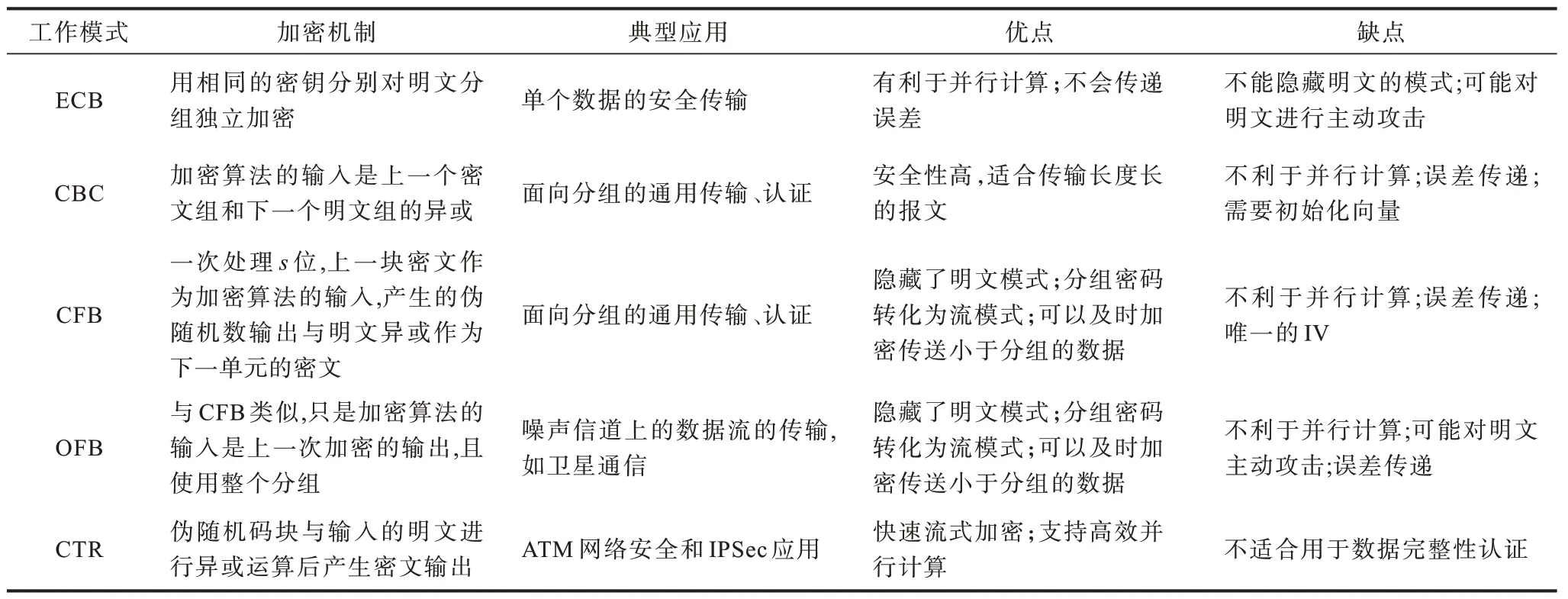
表1 分组密码算法的5 种工作模式 Table 1 Five working modes of block cipher algorithm
对分组密码的加密模式进行识别,可以实现对密码信息系统的监管。文献[12]针对SM4 算法的4 种模式,对其加密后的密文序列从统计学与信息熵角度提取特征,而后利用决策树分类算法进行二分类识别与四分类识别,结果表明,该方法在二分类问题中表现稳定,准确率高达90%以上,而在四分类问题中,区分率在25%左右,与随机猜测准确率相近,识别准确率还有提升空间。
通过上述分析可以看出,现有基于机器学习的SM4 算法工作模式识别准确率不高,深度学习方案尚未得到深入研究,对此,本文主要进行如下工作:
1)参考现有方案中利用随机性检测工具提取密文随机性特征值的思想,结合传统机器学习模型进行实验分析,发现现有密码算法识别方案应用于SM4 算法工作模式分类问题中的不足。
2)通过逐位累加和方式对密文数据集进行处理,输入深度学习模型,分析密文数据处理方式与深度学习方案应用于SM4 算法工作模式分类问题的可行性。
3)设计一种基于Transformer 的SM4 算法工作模式识别方案,并增加SM4-ECB 模式下的密文样本,丰富SM4 算法密文样本。通过对比不同神经网络模型及文献[5]实验结果,验证该模型应用于SM4算法工作模式分类问题的高效性。
2 本文工作
2.1 基于随机性检测的SM4 算法工作模式分类实验分析
在现有方案中应用广泛的随机性检测方法,原理是随机性检测发现不同密码算法加密所得密文的随机程度存在差异,从而判断密文所属的密码算法,另外也可通过随机性检测值分布,比较不同加密方式的加密效果。本节通过将随机性检测方法应用于SM4 算法工作模式分类问题,利用实验分析现有方案应用于该问题存在的不足之处。
2.1.1 实验分析涉及算法及工具介绍
实验分析涉及的算法为K 近邻(K-Nearest Neighbor,KNN)算法。KNN[13]是一种基于监督学习的分类算法,基本思想是给定一组已正确分类的数据集作为训练集,模型将测试集特征与训练集特征进行对比,计算训练数据和测试数据之间的距离,并比较待测数据与其他数据之间的距离,如果距离大多数样本较近,且这部分数据属于同一类别,则判定待测数据属于该类别。文献[6]中所提出的密码体制识别方案使用该模型进行密码算法分类,本文利用KNN 分类模型对SM4 算法5 种工作模式进行区分。
实验分析涉及的工具为SP800-22 随机性测试套件。目前在密码测评中最常使用的随机性测试工具是美国国家标准与技术研究院2010 年修订的SP800-22 Rev-1a 标准,该标准包含15 个测度指标,用于测试密码算法和伪随机数生成算法所产生序列数据的随机性。文献[14]对这15 个测度指标进行了详细说明,此处不再赘述。需要说明的是,在对输入序列进行15 个随机性检测值计算时,部分检测值有最短长度要求,如表2 所示。

表2 部分检测值长度要求 Table 2 Length requirements of partial detection values 单位:bit
2.1.2 实验分析方案
密码算法识别分类工作中使用最为广泛的方法是基于NIST 随机性检测标准进行随机性特征提取,选择出对密文文件分类具有价值的随机性测度特征,实现对密码算法的识别分类。为探究随机性检测特征对SM4 算法工作模式分类问题的有效性,保证将NIST 随机性检测中15 项检测值统计完整,设置明文文件为256 000 kb 的文本文件,使用GMSSL 国密算法模块[15]调用SM4 算法5 种工作模式对该明文文件进行加密。加密后得到的5 份密文文件均为256 000 kb,将5 份密文文件分别分割为1 000 份,每份256 kb,符合所有测试指标长度要求。借助SP800-22 随机性测试套件对5 000 份密文文件进行检测值提取,流程如图1 所示,实验配置如表3 所示。

图1 特征提取流程图Fig.1 Flowchart of feature extraction

表3 实验环境配置 Table 3 Experimental environment configuration
2.1.3 实验分析结果
将提取出的15 维特征向量输入KNN 模型进行训练并计算在测试集上的识别准确率,5 种模式两两识别结果与混合五分类识别结果如表4 所示。

表4 识别准确率 Table 4 Recognition accuracy %
此外,以SM4 算法为例,本文选取15 项检测值中的码元频数统计检测值、游程频数统计检测值、块内频数统计检测值进行统计分布,这3 项检测值在分组密码识别中可作为显著特征值[16],其中,码元频数统计检测值统计密文序列中0 比特和1 比特的比例,游程频数统计检测值统计密文序列中所包含的不同长度游程的数量,块内频数统计检测值统计固定大小的密文序列中特定元素整体的比例。3 项检测值的分布结果如图2~图4 所示,其中,横坐标为随机性检测特征值,纵坐标为对应密文文件数量。
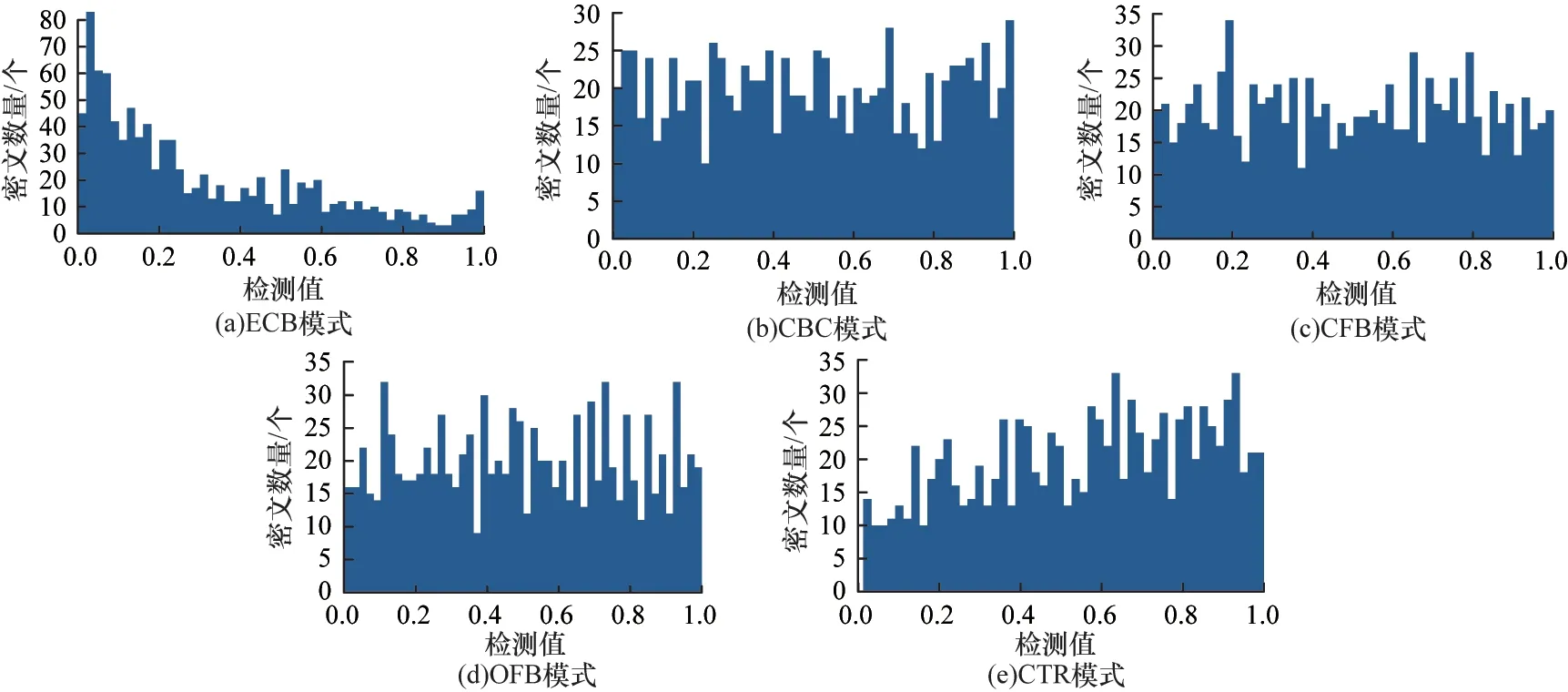
图2 码元频数统计检测值分布Fig.2 The distribution of symbol frequency statistics detection values
从图2 中可以看出:对于ECB 模式,密文文件数量随着特征值增大而减少,且在特征值0.0~0.2 区间内密文文件数量较多;对于CBC、CFB 模式,各特征值对应的密文文件数量分布较为平均;对于OFB模式,个别特征值对应的密文文件数量远大于平均值。
从图3 中可以看出:对于ECB 模式,特征值分布不均匀,在特征值0.0~0.2 区间内密文文件数量较多,在特征值0.5 附近的密文文件数量明显少于两侧密文文件数量;对于另外4 种工作模式,各特征值对应的密文文件数量分布较为平均,其中CBC模式与OFB 模式在特征值0.5 处的密文文件数量较多。

图3 游程频数统计检测值分布Fig.3 The distribution of run-length frequency statistical detection values
从图4 中可以看出:对于ECB 模式,特征值分布不均匀,在特征值0.0~0.2 区间内的密文文件数量较多,在特征值0.5 附近的密文文件数量明显少于两侧密文文件数量;对于另外4 种模式,特征值分布基本相同,无明显特征。
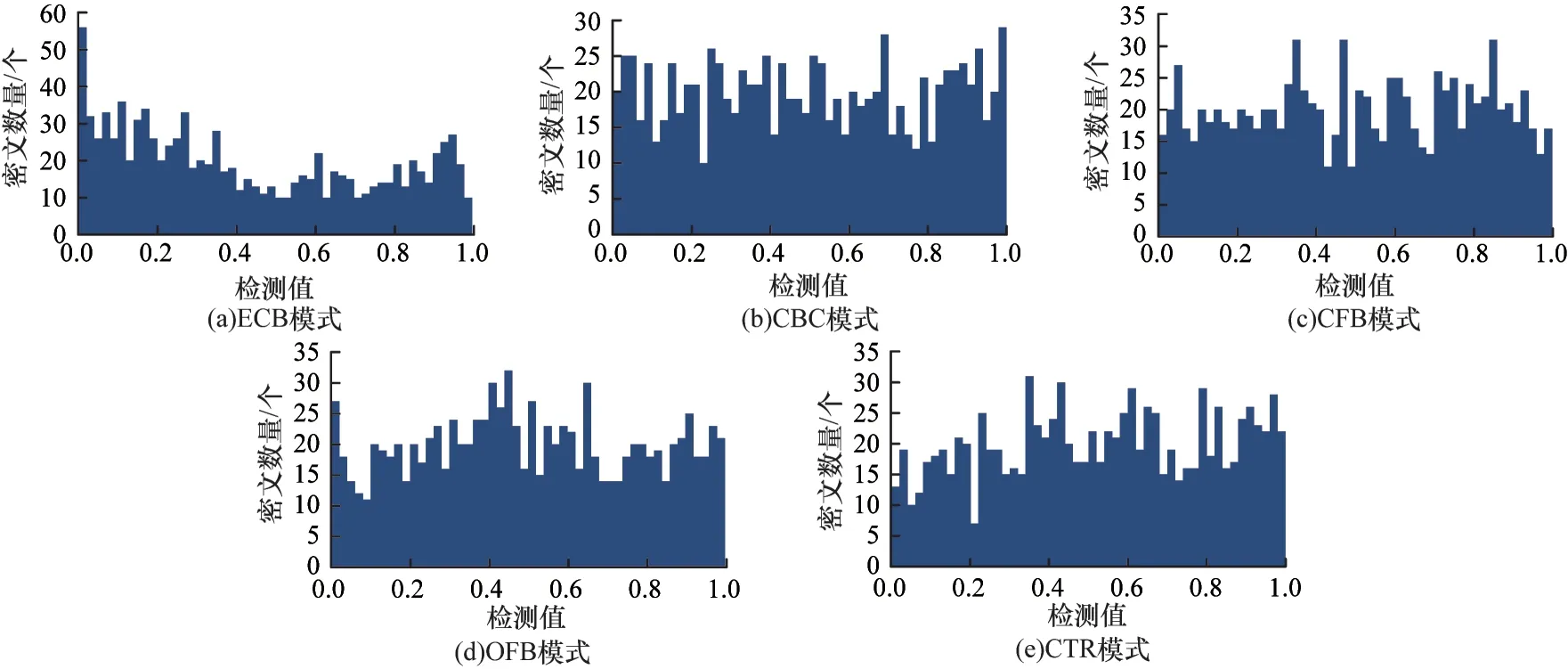
图4 块内频数统计检测值分布Fig.4 The distribution of intra-block frequency statistical detection values
通过基于随机性检测的SM4 算法工作模式分类实验结果可以明显发现,ECB 模式下的密文与其他模式下的密文进行两两识别时,识别准确率较高。
从图2~图4 的随机性检测值分布来看,ECB 模式下密文随机性表现较差,故被认为具有一定规律性,其他工作模式下的密文随机性都表现良好,检测值分布均匀,可认为加密效果良好。当其他模式下密文之间两两识别或5 种模式混合识别时,其余4 种模式在随机性检测值上分布均匀,造成了识别准确率与随机猜测准确率持平,因此利用现有方案中应用广泛的随机性检测特征难以对SM4 算法ECB 模式之外的其他工作模式进行高效识别。
2.2 深度学习方案的可行性实验证明
文献[17]将卷积神经网络应用于文本分类任务之中,并取得了较好的实验结果。本节通过引入深度学习技术,利用二维卷积神经网络对SM4 算法工作模式进行分类,证明深度学习方案的可行性以及提出的数据处理方式的有效性。
2.2.1 实验方案
本文针对SM4 密码算法5 种工作模式混合的情况,提出一种基于深度学习的分类方案。首先为验证深度学习方案应用于SM4 算法工作模式分类问题的可行性,将密文视为序列型文本,将其加密模式作为标签,利用卷积神经网络模型提取密文内部特征,实现对密文所属加密模式较高的分类准确率。由于传统的一维卷积神经网络在相同卷积核情况下获得的感受野较少,在训练过程中容易出现过拟合现象[18],因此本文采用二维卷积神经网络对密文特征图进行特征提取及分类。
本文采用4 000 kb 大小的文本文件进行实验,利用GMSSL 国密算法模块调用SM4 算法5 种工作模式对该文本文件进行加密。加密后得到的5 份密文文件大小均为4 000 kb,将5 份密文文件分别分割为1 000 份,每份4 kb。对于每份密文,以十六进制读取密文文件,经归一化形成4 096 个像素值,而后转化为64×64 像素的灰度图,用于二维卷积神经网络输入,该数据集称为数据集A。数据集A 获取流程如图5 所示。训练集、测试集分布及神经网络结构分布见表5 和表6。
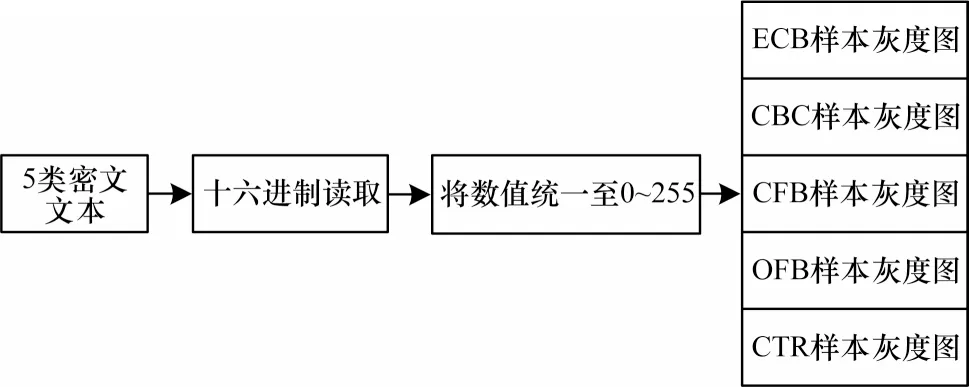
图5 数据集A 获取流程图Fig.5 Flowchart of dataset A acquisition

表5 数据集分布 Table 5 The distribution of dataset 单位:个

表6 神经网络结构 Table 6 Neural network structure
文献[6]指出密文组织形式对密码算法识别准确率有较大影响。因此,本文利用Python 编写数据处理工具,实现将密文以十六进制读取并转换为二进制比特串,然后按照指定位数进行累加,将结果形成相应大小的灰度图用于神经网络输入,该数据集称为数据集B。数据集B 获取流程如图6 所示。本文将原始4 kb(4 096 Byte)密文按32 bit 进行累加,后转换为32×32 像素的样本灰度图输入二维卷积神经网络进行识别分类,数据集分布与表4 保持一致,在此基础上计算识别准确率。
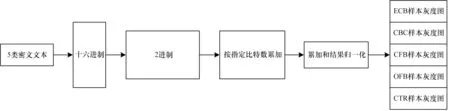
图6 数据集B 获取流程图Fig.6 Flowchart of dataset B acquisition
2.2.2 实验结果分析
如表7 所示,通过改变训练迭代次数,该二维卷积神经网络模型在训练迭代100 轮过程中出现最高识别准确率53.64%,显著优于随机猜测准确率25%,从总体结果可以看出,将原始密文转换为特征灰度图后,采用深度学习的方法可以更好地提升在SM4算法5 种工作模式下的密文五分类问题中的识别准确率,证明利用深度学习可以从密文中获取细粒度特征,有效提升识别准确率。

表7 CNN 识别结果(数据集A)Table 7 The recognition result of CNN(dataset A)
将数据集B 输入该二维卷积神经网络中,实验结果如表8 所示。通过对比表7 与表8 可以看出,将数据集A 和数据集B 分别输入2-CNN 中,后者的识别准确率较前者有显著提升,证明了该密文数据处理方式的有效性。

表8 CNN 识别结果(数据集B)Table 8 The recognition results of CNN(dataset B)
2.3 基于Transformer的SM4算法工作模式识别方案
第2.2 节证明了利用深度学习可以有效提升SM4 算法工作模式识别准确率。在自然语言处理任务中,Google 提出的Transformer 模型[19]被广泛应用并取得了很好的效果,该模型与传统神经网络模型结构不同,其包含的自注意力机制可兼顾上下文特征与局部细微特征,避免文本上下文语义特征[20]的缺失,具有出色的序列细粒度特征提取能力。因此,本文提出一种基于Transformer 的SM4 算法工作模式识别方案。
2.3.1 Transformer 模型
Transformer 模型整个网络结构由注意力机制组成,把输入的一张图片分成N个无重叠固定大小的Patch,然后将每个Patch 全部拉成一维向量,合并得到N维矩阵。使用Linear Projection 规整矩阵长度和位置信息,再融入全局信息,将它们输入Transformer 编码器进行全局注意力计算和特征提取,通过MLP 分类后,输出多分类结果。
Transformer 模型的计算复杂度主要由多头注意力模块决定,这也是模型的突出特点。注意力计算公式为Softmax(QKT)V,当序列长度为N、输入维度为H时,由于每个token 都需要与所有token 计算相似性,因此QKT这项做矩阵乘的复杂度为N×H×H×N,即平方复杂度O(N2)。
2.3.2 识别方案
基于Transformer 的SM4 算法工作模式识别方案流程如图7 所示,由于数据集B 被证明用于神经网络输入后分类效果更好,因此将数据集B 输入该Transformer 模型中分类并计算准确率。
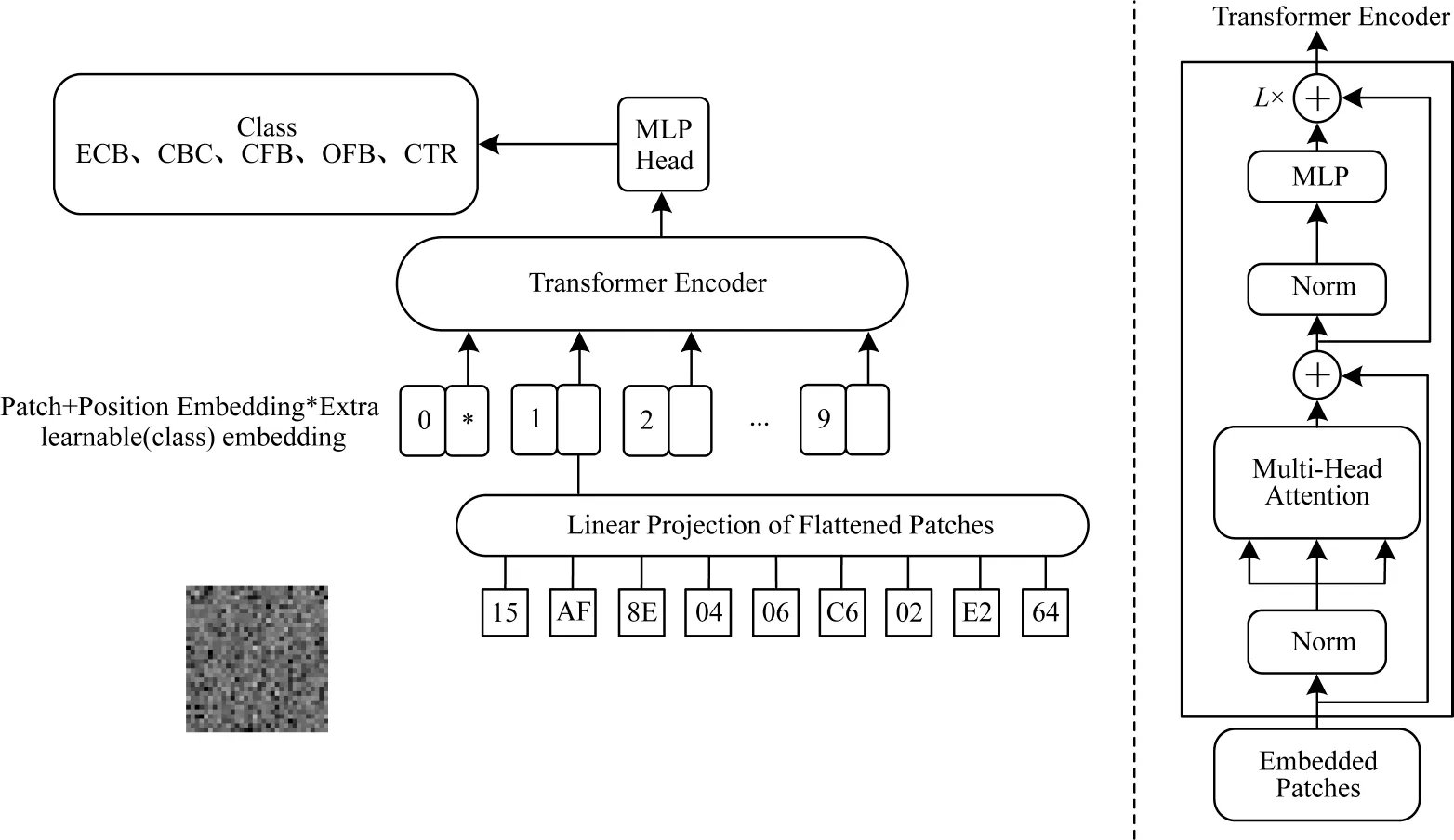
图7 基于Transformer 分类方案流程图Fig.7 Flowchart of classification scheme based on Transformer
2.3.3 实验结果分析
为验证本文将Transformer 模型应用于该问题的有效性,将数据集B 分别输入循环神经网络、残差神经网络进行分类,并与文献[12]中实验结果进行对比。Transformer 模型识别准确率如表9 所示,不同神经网络的识别准确率随着训练轮数的变化曲线如图8 所示,其中,2-CNN、RNN、ResNet 均使用SGD(Stochastic Gradient Descent)作为优化器,Transformer 模型使 用 Adam(Adaptive Moment Estimation)作为优化器。可以看出,Transformer 模型经过较少轮数的模型训练,就可以达到非常高的识别准确率。

图8 不同神经网络模型识别准确率Fig.8 Recognition accuracy of different neural network models
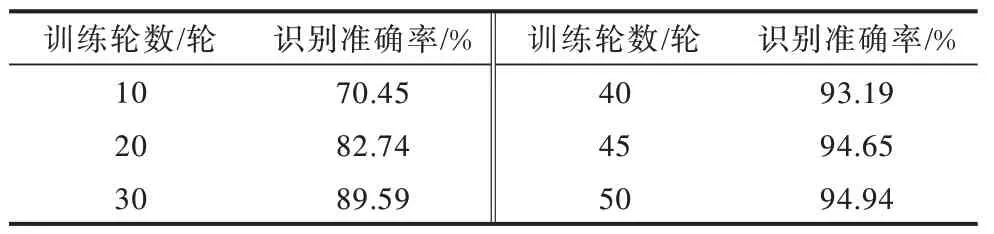
表9 Transformer 识别结果 Table 9 The recognition result of Transformer
不同神经网络模型的识别准确率如表10 所示,一方面证明了将密文所属加密模式分类问题视为文本分类任务进行处理,而后利用深度学习模型自主挖掘密文特征可以有效对密文所属加密模式进行区分,另一方面也证明了Transformer 模型在此类问题上的优势。

表10 不同模型实验结果对比 Table 10 Comparison of experimental results by different models %
3 结束语
本文通过随机性检测值结合KNN 算法实验分析,指出现有密码算法识别方案应用于SM4 算法工作模式识别工作的不足,证明深度学习技术解决该问题的可行性。在此基础上,提出一种基于Transformer 模型的SM4 算法工作模式识别方案,并通过对比不同神经网络模型和当前工作的最新文献实验结果,证明该方案的有效性。现有密码算法识别方案大多基于传统机器学习或构建复杂的密文特征工程,耗时费力。本文方案避免了构建复杂特征工程,且样本文件大小均为4 kb,其引入深度学习技术,较现有其他密码算法识别方案中使用的密文样本文件显著减小。
未来可探索更新颖高效的密文处理方式和神经网络结构,不断提升模型泛化性,对小众密码算法[21-22]进行识别。由于不同算法结构之间存在密文特征分布上的差异性[23-24],因此可针对特定结构算法展开进一步识别与研究。另外,密文在现实中被包裹在各类网络协议数据包中,因此,还需要结合加密流量分析[25]领域相关内容进行研究。
