公共图书馆智能图书采购探索
2023-09-15杨潇
杨 潇
(首都图书馆,北京 100021)
“推进文化自信自强,铸就社会主义文化新辉煌”[1]是二十大报告中对文化工作的纲领性指导和对文化工作者的新要求。作为公共文化服务主阵地之一,图书馆的主要职能是为群众提供更多、更好、更具时代特色的精神文化资源。图书的选择是保障这一职能发挥的基础,直接决定着图书馆馆藏质量和服务水平。然而,当前国内公共图书馆的图书采购多以采购人员个人的主观意愿和经验为主要依据。将新的信息技术、采购模式和管理模式融入采购决策过程,已成为公共图书馆未来的建设方向。
1 图书智能采购模型相关研究
早期智能化采购的代表性模型是拉斯氏选书模型。国内学者结合图书馆实际情况,提出了许多改进方案[1]。例如,王积和提出了重点藏书和一般藏书两个选书模型[2],胡修琦等人将选书标准分为6项,读者需求划分为三级,构建了选书模型[3]。随着大数据时代的到来,新的技术和算法被引入,图书智能采购决策系统逐渐细化和深入,并从单一算法模式研究转向多算法结合。例如,刘鸿雁等学者提出了以消费者均衡理论为核心的资金按类分配模型[4],赵研科利用Apriori算法和决策树等数据挖掘算法[5],通过对用户历史行为记录的挖掘,开发了图书采购辅助决策系统。此外,许多学者利用人工智能技术,如BP神经网络智能算法[6-8]、贝叶斯网理论[9-10]和随机森林[11],建立不同侧重点的采购模型。周志强等学者将BP神经网络算法和SVM算法与遗传算法GA相结合,搭建了混合智能采购模型[12]。
目前,智能图书采购模型的研究主要集中在高校图书馆领域,公共图书馆的采购模型研究相对较少。然而,高校图书馆和公共图书馆在文献资源馆藏建设方向、读者构成、服务宗旨、经费构成等方面存在显著差异。如果简单地将高校图书馆的采购模式应用于公共图书馆,可能会导致选书方向上的偏差。因此,本文选择首都图书馆2018—2022年的中文图书采购数据作为实验基础源数据,探索一种新的采购模式,以信息技术为主,主观经验为辅,对公共图书馆的智能化采购进行探索。
2 构建适应公共图书馆中文图书采购模型的准备
2.1 书目数据资源信息的建立
为了实现批量化智能操作,我们与供货商和出版社进行了多次沟通和反复修改,最终确定了书目数据提供的格式规范和著录内容的标准化。我们统一了书目模板,其中包括ISBN、题名、副题名、分卷号、分卷名、丛编项、页数、尺寸、分类号、读者对象和图书简介。基于此,我们结合本馆的馆藏资源建设方针,对供货商提供的原始书目数据进行初步分类智能筛选。我们制定了流程图(见图1),以便更好地比对和分析数据信息。
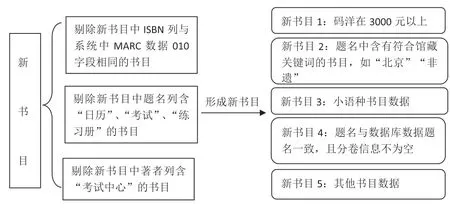
图1 图书采购流程图(前期部分)
经过对数据的分类筛选,可将馆配商所提供的原始书目划分成5 个新书目表。将新书目表1导出,以便日后定期对高码洋图书采购进行有针对性的采访小组内部讨论。对新书目表2则按照馆藏政策进行预订购,导出预订购数据表,采购人员确认后下订。对新书目表3中的图书按每种1册预订购,导出数据表格由采购人员确认后下订。新书目表4 作为连续出版物书目,其情况相对复杂,可分为两种情况进行处理(见图2)。最后,将新书目4处理形成的新书目表6与新书目表5进行汇总,形成一份书目信息表格,以便进行下一步只能采购演算。

表1 程序导出的100本推荐分数最高的图书
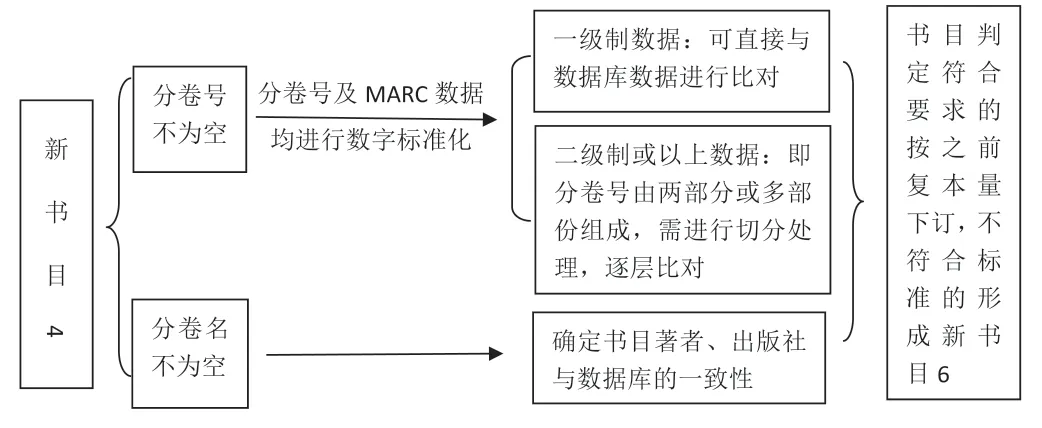
图2 新书目表4的处理流程图
2.2 图书采购推荐算法
图书采购推荐算法是公共图书馆中的一个重要算法。由于缺乏用户行为数据,传统的协同过滤推荐算法无法直接应用于图书馆的新书采购。因此,基于内容的推荐算法和基于知识图谱的推荐算法成为图书馆推荐系统中常用的两种算法。基于内容的推荐算法可以根据图书的属性(如书名、作者、出版社、分类等)来计算它们之间的相似性,然后推荐与历史购买的图书相似的新图书。基于知识图谱推荐算法则通过建立图书之间的关系来推荐相应的图书。例如,如果历史购买中有很多计算机科学类的图书,那么可以推荐其他与计算机科学相关的图书。
本文将基于内容的推荐算法和基于知识图谱的推荐算法相结合(见式(1)),可以进一步提高推荐的准确性和个性化程度。在综合推荐分数的计算中,可以通过调整权重因子来平衡两种算法的影响力。例如,当需要强调基于内容的推荐算法时,可以将权重因子α设定为较大的值;反之,当需要强调基于知识图谱的推荐算法时,可以将权重因子α设定为较小的值。式中,表示第本新图书的推荐分数;表示第 个新图书与历史采购书目中的图书的相似度;表示第个新图书与历史采购书目中的图书的关联度;为调节参数,用于平衡两种算法的推荐分数。
3 公共图书馆中文图书采购智能模型的搭建
3.1 基于内容的推荐算法
为了使用基于内容的推荐算法推荐新的图书列表,可以使用TF-IDF算法来提取每本图书的特征向量。首先,将历史MARC数据中的330字段和新书目中的图书介绍内容作为文本数据,使用TF-IDF算法计算每个关键词在文档中的重要性,方法是将关键词在文档中的词频和逆文档频率相乘。然后,选取N个关键词作为每本图书的特征向量。最后,使用余弦相似度来计算每本图书之间的相似度,余弦相似度值越大,表示两本图书越相似。因此,通过基于历史书目的属性和特征,可以从新书目中挑选出具有类似属性和特征的图书。
vectorizer = TfidfVectorizer(max_features=5000)
book_descriptions = history_data['book_description'].fillna('')
book_names = history_data['book_name']
book_name_and_descriptions = book_names+ ' ' + book_descriptions
book_features = vectorizer.fit_transform(book_
name_and_descriptions)
new_book_names = new_data['book_name']
new_book_descriptions = new_data['book_description'].fillna('')
new_book_name_and_descriptions = new_book_names + ' ' + new_book_descriptions
new_book_features = vectorizer.transform(new_book_name_and_descriptions)
similarity_matrix = cosine_similarity(new_book_features, book_features)
recommendations = {}
for i, new_book in enumerate(new_book_names):
similarity_scores = similarity_matrix[i]
recommendation_score = sum(similarity_scores) / len(similarity_scores)
recommendations[new_book] = recommendation_score
sorted_recommendations = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)
3.2 基于知识图谱的推荐算法
基于知识图谱的推荐算法通过构建一个包含每本书、其作者和出版商的图形结构来遴选采购新书。与传统的推荐算法不同,该算法不需要对用户行为进行跟踪或收集,而是利用图书的元数据构建一个整体的知识图谱。具体而言,每本图书作为一个节点,使用图书的元数据作为节点的属性,并通过图书之间的关系(如作者、出版社、主题词、分类号等),尤其是采用相邻历史书籍之间的关联来连接节点,形成一个半结构化的图形数据库。利用构建好的知识图谱,我们可以计算每本新书与历史书籍之间的关联度,从而推荐相关的图书。例如,在推荐新书时,我们可以根据新书的作者、出版商等属性在图谱中找到其邻居节点,并通过计算它们之间的边权重来得到与新书相关的推荐书目。该算法可以帮助用户发现与其喜好相关的新书,同时确保用户的隐私不受侵犯。
graph = build_knowledge_graph(history_data)
new_books = set(new_data['book_name'])
recommendations2 = {}
for book in new_books:
if book not in graph:
continue
for neighbor in graph.neighbors(book):
if neighbor != book and neighbor not in new_books:
weight = graph[book][neighbor]['weight']
if neighbor not in recommendations2:
recommendations2[neighbor] = 0
recommendations2[neighbor] += weight
sorted_recommendations2 = sorted(recommendations2.items(), key=lambda x: x[1], reverse=True)
def build_knowledge_graph(data):
# 创建知识图谱
graph = nx.Graph()
# 添加节点
for _, row in data.iterrows():
book = row['book_name']
author = row['author']
publisher = row['publisher']
graph.add_node(book, bipartite='book')
graph.add_node(author, bipartite='author')
graph.add_node(publisher, bipartite='publisher')
# 添加边
graph.add_edge(book, author, weight=1)
graph.add_edge(book, publisher, weight=1)
return graph
3.3 综合推荐分数
综合基于内容的推荐算法和基于知识图谱的推荐算法,可以为采购人员提供更全面和准确的推荐服务。为了得到综合推荐分数,我们使用加权平均法,其中权重参数α为0.8。该值是根据实验结果得到的最优值,但对于不同的数据集,可能需要进行调整。
首先对基于内容的推荐算法得到的推荐结果进行加权平均,其中权重为0.8,然后对基于知识图谱的推荐算法得到的推荐结果进行加权平均,其中权重为0.2。最终,将两者得到的推荐分数加和,得到综合推荐分数。
combined_recommendations = {}
for book, score in sorted_recommendations:
if book not in combined_recommendations:
combined_recommendations[book] ={'book_score': 0.8 * score}
else:
combined_recommendations[book]['book_score'] += 0.8 * score
for book, score in sorted_recommendations2:
if book in combined_recommendations:combined_recommendations[book]['graph_score'] = 0.2 * score
sorted_combined_recommendations =sor ted(combi ned_recom mend ations.items(),key=lambda x: x[1]['book_score'] + x[1].get('graph_score', 0), reverse=True)
3.4 实验结果
本实验使用了最近5年的图书采购数据,并给定了一个新的图书列表。基于此,我们开发了一个推荐程序,采用基于内容和知识图谱的推荐方法,对给定的新书列表进行推荐。具体而言,程序计算了每本书基于内容和知识图谱的推荐分数,并采用加权α值为0.8的方法对两种推荐分数进行综合评分,以得到最终的推荐分数。最后,程序将所有推荐的图书按照推荐分数进行排序,输出前100本推荐分数最高的图书(见表格1)。
通过本实验的结果可以发现,该推荐程序能够找到那些与给定书籍具有相似主题和内容的书籍,同时还能考虑到知识图谱中的关联性。这表明,当推荐系统利用基于内容和知识图谱的推荐方法进行综合评估时,能够为读者提供更加个性化和精准的推荐服务。值得一提的是,该推荐系统还具有一定的健壮性(Robustness),能够在不同的α值下表现出不错的推荐效果。为了验证推荐系统的性能,我们还进行了一些额外的实验。具体来说,我们分别在不同的α值下进行实验,发现在α值为0.8时,推荐系统的性能最佳。这进一步证实了该程序的有效性和实用性。
4 结束语
随着人工智能技术的不断发展,它为图书馆各项业务的创新升级提供了新的思路与方式。作为一名新时代的图书馆采购人员,我们需要紧跟时代的发展,不断加深对人工智能的学习与研究,并结合图书馆的图书采购流程,探索其应用的结合点和突破点,助力传统图书采购工作的转型。同时,随着用户行为数据的引入,我们可以应用更多的智能算法,如协同过滤、深度学习等,从而进一步提高推荐算法的准确性和可靠性。在未来,我们可以逐步引入各大权威图书榜单的实时数据等内容,使图书采购更具综合性与时效性,推动智能图书馆的不断发展。通过人工智能技术与图书馆采购流程的结合,我们可以更好地满足读者需求,提高图书的利用率和借阅量,从而为图书馆的可持续发展做出贡献。■
