嵌入注意力的Gabor CNN快速人脸表情识别方法
2023-09-15南亚会华庆一刘继华
南亚会,华庆一,刘继华
(1.西北大学 信息科学与技术学院,陕西 西安 710127;2.吕梁学院 计算机科学与技术系,山西 吕梁 033001)
0 引言
人脸表情识别(Facial Expression Recognition,FER)是面部相关的研究中较为复杂的任务。通过分析、识别人脸生物特征来反映一个人的情绪状态,在人机交互、机器智能、医疗、虚拟现实等领域有重要作用。
目前为止学术界、工业界对该问题进行了许多研究。人脸表情识别一直是计算机视觉和人机交互领域的热点问题,表情识别的目的是基于人脸图像识别人类的惊讶、悲伤、恐惧等情感状态,使机器能感知、理解人类情感,从而更好地与人类交流互动。
近几年,具有强大特征学习能力的深度学习技术得到了迅速发展,已被广泛应用于面部相关问题研究,例如人脸检测、人脸识别、表情、年龄和性别识别等。其中,卷积神经网络(Convolutional Neural Network,CNN)使表情识别准确率得到了大幅提升,但CNN 最大的缺点是忽略了不同特征间的相对位置,无法从图像中识别姿态、纹理和位置变化。同时,池化操作会丢失部分信息,因此需要更多训练数据对损失进行补偿。此外,CNN 无法学习特征间的关系,倾向于记忆数据而非理解数据,基于CNN 的特征提取仅属于数据驱动技术。
虽然,CNN 强大的特征学习能力为FER 发展作出了贡献,但仍有一些问题尚待解决。例如,CNN 需要足够多的数据来训练模型,避免模型发生过拟合现象,但现有面部表情数据库不足以训练具备深度结构的神经网络,并且实际场景中夹杂着光照、姿态、遮挡等干扰因素,需要模型具有更好的类内差异能力和有效的表情差异表征。同时,在面部相关问题中需要分辨面部特征的细微差别,例如嘴角、眼角变化幅度、皱纹的深浅等。研究表明,面部情绪的变化与嘴、眼睛、眉毛和鼻子区域等区域密切相关,但普通CNN 无法较好地检测、定义面部特征位置关系的差异。为了增强CNN 对方向和尺度变化的适应能力,Luan 等[1]使用传统手工制作的Gabor 小波[2]调制可学习的卷积滤波器,以减少可学习网络参数数量,增强学习特征对方向和尺度变化的鲁棒性。由于Gabor 滤波器和哺乳动物视觉系统中简单细胞的接受频谱非常相似,具有检测纹理、边缘和方向的能力,且Gabor 滤波器与CNN 低层卷积作用类似,因此在分类任务中准确率较高[3]。
人脸感兴趣区域(Region of Interest,ROI)是视觉内容丰富的区域。Gabor 滤波器既能表征人脸的空间频率结构,又能有效捕获人脸ROI 特征,因此广泛应用于FER 任务。Gabor 方向滤波器(Convolutional Gabor orientation Filter,GoF)[1]结合了Gabor 滤波器与传统卷积滤波器的优点,在捕获输出特征图中的空间定位、方向选择性、空间频率选择性等视觉特性方面优于传统卷积核,可有效提取人脸ROI 的特征,因此使用GoF 的深度卷积网络相较于传统CNN 更适合FER。
综上,本文提出用于FER 任务的轻量级注意力的Gabor 卷积网络(Gabor Convolutional Network,GCN)。其中,GoF 为CNN 的基本元素,在卷积滤波器上即可实现,易于集成到任何深度架构中。带有注意力机制的GoF 卷积神经网络被称为AGCN,可学习更健壮的特征表示,对具有空间转换的图像优势明显。此外,由于GoF 由一组可学习的卷积滤波器组成,因此AGCN 模型更紧凑、易于训练。分析表明,GoF 在提取面部ROI 特征方面相较于传统滤波器更有效,因此在研究不同深度(层数)、宽度(卷积层中的单元数)和卷积核尺寸的AGCN 体系结构后,设计了一个最优AGCN 模型。同时,将最优AGCN 模型与CNN 架构的AlexNet[4]、VGGNet[5]、ResNet[6]和CapsNet[7]比较发现,所提模型识别精度较好,参数量、空间资源最少。在FERPlus[8]和RAF-DB[9]数据集上的实验表明,所提方案优于目前较先进的FER 方法。
1 相关工作
1.1 Gabor滤波器
Gabor 小波使用复函数作为信息理论应用中傅里叶变换的基础,标准差的乘积在时域和频域均最小。Gabor 滤波器[10]是一种有效的图像表示学习特征提取器,可从图像中提取不变的信息。Gabor 函数基于特定频率和方向的正弦波,表征图像的空间频率信息。二维Gabor 滤波器为正弦波调制的高斯核函数,由虚部和实部组成。实部可描述为:
式中:x'=xcosθ+ysinθ;y'=-xsinθ+ycosθ;λ 表示Gabor 滤波核的实部波长;θ表示Gabor 函数的平行条纹的法线方向,有效值为0°~360°的实数;φ表示相位偏移,有效值为-180°~180°,0°、180°的方程与原点对称,-90°、90°的方程分别于原点成中心对称,是两项直角坐标系中的余弦函数;γ表示空间纵横比,即Gabor 滤波器的椭圆度;σ表示Gabor过滤器中实用的高斯函数标准差。
图1 为Gabor 滤波器对人脸图像提取特征的示例,表明Gabor滤波器能较好地寻找与给定θ相对应的纹理,Hosseini 等[11]研究表明,使用Gabor 滤波特征作为输入能提升CNN 的性能。Ou 等[12]利用经典的8 个方向与4 个尺度的Gabor 滤波识别人脸表情,尽管Gabor 小波可处理图像的尺度和方向变换,但结构较浅,在大规模数据集的分类任务或复杂任务中表现不佳。

Fig.1 Gabor filter banks extracting facial image features图1 Gabor滤波器组提取人脸图像特征
为此,许多研究者试图结合Gabor 小波与深度卷积神经网络进行图像表示学习。Meng 等[13,14]使用不同尺度和方向参数的Gabor 滤波器提取表情局部有用特征,将提取的特征作为数据训练CNN 用于人脸表情识别。Verma等[15]首先基于Viola-Jones 检测算法检测整幅图像中的人脸图像,然后利用Gabor 滤波器在空间域中提取人脸特征,以捕获所有方向的整个频谱,接下来利用Gabor 滤波器提取有意义的面部特征,最后将提取的人脸图像Gabor 特征作为人工神经网络分类器的输入,对人脸表情进行分类。综上,大部分工作均将Gabor 特征或结合提取的Gabor 特征和原始图像作为CNN 输入来训练模型。
Luan 等[1]实现了Gabor 卷积神经网络,在每个卷积层中通过不同方向、尺度的Gabor 滤波器调制卷积滤波器,生成卷积Gabor 方向滤波器,赋予卷积滤波器额外的能力以捕获输出特征图中的空间定位、方向选择性、空间频率选择性等视觉属性。Jiang 等[16]提出由4 个Gabor 卷积层和两个全连接组成的轻量Gabor 卷积网络用于FER 任务,在FER2013、FERPlus 和RAF-DB 数据集上的实验表明,所提方法具有良好的识别精度和较低的计算成本。
Hosseini 等[17]提出结合人脸的Gabor 滤波响应与原始人脸图像作为CNN 输入,增强了人脸的褶皱特征,在卷积层早期阶段就能发现面部特征,从而提升了表情识别的整体性能。同时,采用胶囊网络思想捕获面部特征间的关系,被证明对物体的旋转具有鲁棒性。结果表明,该算法相较于普通CNN、胶囊网络性能更优,将Gabor滤波特征作为胶囊网络的输入能提升表情识别的整体性能。
1.2 Gabor方向滤波器
Gabor 滤波器具有U 方向和V 尺度,能将方向信息编码到学习滤波器中,将尺度信息嵌入不同层中,将可操纵特性融入到Gabor 卷积网络中,以捕获输入图片的方向和尺度信息,从而增强相应的卷积特征。标准CNN 中的卷积滤波器在经过Gabor 滤波器调制前,通过反向传播算法进行学习,称为学习滤波器。假设一个学习滤波器的大小为N×W×W,其中W×W为2D 滤波器大小(N 个通道)。为了实现方便,选择N为U用于调制该学习滤波器的Gabor 滤波器的方向数,在已知滤波器上使用U个Gabor 滤波器为给定尺度进行滤波,计算如式(2)所示,具体流程如图2 所示。其中,左半部分为GoF 的调制过程;右半部分展示了一个4 通道GCN 卷积的例子,在GoF 中为了实现方便,通道数设为Gabor方向数U。

Fig.2 Filter modulation process and examples图2 滤波器调制流程与示例
传统CNN 卷积核的基本单位是K×K大小的二维滤波器,而Gabor 卷积神经网络的基本单位是GoF,通常定义为[1]:
第v个尺度定义为:
式中:G(u,v)表示一组K×K的Gabor 核(实部)[10];1≤u≤U、1≤v≤V分别表示方向和频率;Ci,o为一个U×K×K大小的学习滤波器;◦表示G(u,v)、Ci,o每个2D 滤波器间的点乘运算(即也为U×K×K),因此第i个GoF 的实际上是一个U×U×K×K的滤波器。
相较于传统CNN 中H×W特征图的不同之处在于,GCN 特征图F 为U×H×W。因此,F 与一个GoF间的Gabor卷积运算描述为:
式中:*表示标准的3D 卷积操作。
在Gabor 卷积神经网络中,Gabor 滤波器是调制学习的卷积滤波器。具体地,将CNN 的基本元素卷积滤波器改为GoF,以加强Gabor 滤波器对每个卷积层的影响。因此,在深度卷积神经网络中集成Gabor 滤波器,能增强深度特征对方向和尺度变化的抵抗力。
在每个卷积层中,卷积滤波器由不同方向和尺度的Gabor 滤波器调制产生卷积Gabor 方向滤波器(Gabor Orientation Filter,GOF),赋予了卷积滤波器额外的能力,以捕获输出特征图的空间定位、方向选择性、空间频率选择性等视觉属性。
1.3 CBAM注意力卷积模块
CBAM 注意力机制[18]由通道注意力机制(channel)和空间注意力机制(spatial)组成。传统基于卷积神经网络的注意力机制倾向于关注、分析通道域,局限于考虑特征图通道间的作用关系。CBAM 从通道和空间两个作用域出发,引入空间注意力和通道注意力两个分析维度,组成了从通道到空间的顺序注意力结构。其中,空间注意力可使神经网络更关注图像中对分类起决定作用的像素区域,忽略无关紧要的区域;通道注意力则用于处理特征图通道的分配关系,对两个维度进行注意力分配以增强注意力机制对模型性能的提升效果。
1.3.1 通道注意力机制模块
图3 为CBAM 中的通道注意力机制模块。首先,将输入特征图分别输入全局最大池化和全局平均池化,基于两个维度压缩特征映射,获得两张不同维度的特征描述,池化后的特征图共用一个多层感知器网络。然后,通过一个全连接层减少通道数,再通过另一个全连接恢复通道数,将两张特征图在通道维度进行堆叠,经过sigmoid 激活函数将特征图每个通道的权重归一化到0~1。最后,将归一化后的权重和输入特征图相乘。

Fig.3 Channel attention mechanism module in CBAM图3 CBAM中的通道注意力机制模块
1.3.2 空间注意力机制模块
图4 为CBAM 中的空间注意力机制模块,主要对通道注意力机制的输出特征图进行空间域的处理。首先对输入特征图在通道维度下进行最大池化和平均池化,将池化后的两张特征图在通道维度进行堆叠。然后,使用7×7 或3×3、1×1 大小的卷积核融合通道信息,使特征图的维度由[b,2,h,w]转化为[b,1,h,w]。最后,将卷积后的结果经过sigmoid 函数对特征图的空间权重进行归一化,再将输入特征图和权重相乘。
在瞬态短路工况,阻尼系统的负荷能力按考虑,对应额定容量相间不对称突然短路的最高温升和温度值分别为72.2 K和125.2 ℃;单相对地不对称突然短路的最高温升和温度值分别为65.7 K和118.7 ℃。

Fig.4 Spatial attention mechanism module in CBAM图4 CBAM中的空间注意力机制模块
1.3.3 CBAM注意力机制
图5 为CBAM 注意力模块总体流程。首先将输入特征图经过通道注意力机制;然后将通道权重和输入特征图相乘后输入空间注意力机制;最后将归一化后的空间权重和空间注意力机制的输入特征图相乘,得到最终加权后的特征图。
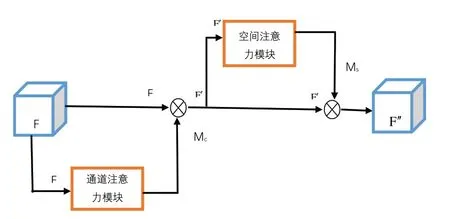
Fig.5 CBAM attention module图5 CBAM注意力模块
2 基于CBAM的Gabor卷积神经网络模型
Gabor 卷积网络使用Gabor 定向滤波器(GoF)的深度卷积神经网络。其中,GoF 为一种可操纵的滤波器,通过Gabor 滤波器组操纵学习到的卷积滤波器生成增强后的特征映射,使用Gabor 卷积的GCN 网络可学习更少的滤波器参数,且注意力模块既不会增加较多参数,还能增强局部特征的提取能力。
本文模型结构如图6 所示,由4 个Gabor 卷积层、4 个CBAM 注意力模块和两个全连接层组成。其中,Gabor 滤波器包含45°、90°、135°、180°方向,即U=4;在Gabor 卷积层中“4×3×3,8”表示8 个Gabor 方向滤波器,其学习滤波器的大小为4×3×3,且尺度值V在不同深度处不同;Max 操作选择每个特征映射的最大通道(每个特征映射包括u个通道);flatten 操作将64×5×5 特征转换为1 600×1 的向量,在所提AGCN 模型中激活函数为ReLU,最大池化核大小为2×2,dropout为0.5。

Fig.6 AGCN model architecture图6 AGCN模型架构
在RAF-DB 数据集上测试的AGCN 模型结果如表1 所示。其中,AGCN4(5×5)为本文模型,由图2 可见其他模型也具有类似结构,即串联GC 层、注意力模块和2 个FC 层(第一个FC 层的输出为1 600×1 的向量)。例如,AGCN4(5×5)_8 有4 个GC 层,每个GC 层中的GoF 数量分别为8、16、32、64,输入数据从100×100 灰度图片中随机裁剪90×90 的图片。AGCN3(3×3)、AGCN3(5×5)、AGCN3(7×7)模型层数和GoF 数量不变,增大卷积核大小既增加了模型参数量,还会降低准确率。

Table 1 Performance comparison of 8 AGCN models on RAF-DB datasets表1 8种AGCN模型在RAF-DB数据集上的性能比较
AGCN3 系列模型相较于AGCN4 系列模型速度更快,但精度至少降低1.6%。AGCN4 相较于AGCN5 在精度和运行效率方面更优,以此证明了不能简单通过增加Gabor卷积层和注意力模块来提升性能。
因此,本文综合考虑模型的识别精度和计算复杂度,采用AGCN4(5×5)模型进行后续实验。
3 实验与结果分析
3.1 实验准备
实验数据集为两个基准表情数据集FERPlus[8]和RAF-DB[9]。其中,FERPlus 数据集属于FER2013 数据集的扩展,标注了10 个标签,主要关注由多数投票选出的高兴、生气、悲伤、惊讶、恐惧、厌恶和平常表情图片;RAF-DB数据集是一个大规模面部表情数据集,包含3 万张面部图片,由40 名训练有素的人类编码员标注了基本或复合表情。为了便于计算,本文只使用了含有基本表情的图片,其中12 271 张用于训练,1 225 张用于验证,3 068 张用于测试。在图像预处理环节从大小为100×100 的灰度输入图片中,随机裁剪出一张90×90 图片,所有图片进行归一化处理。为了防止模型发生过拟合,提升模型泛化能力,将图片在-10°~10°间随机旋转,并以50%的概率随机水平翻转进行数据增强。在训练与测试环节,使用Adam 优化器对模型进行端到端训练,每批次64 个样本,动量系数衰减值为0.9,共训练200 个epoch,学习率每25 次衰减50%,学习率初始值为0.001。
本文采用10-crop 方法来识别测试图片,首先将一张测试图片裁剪为10 张90×90 大小,然后将其分类为这10张裁剪图像平均得分最高的类别。
3.2 实验结果
本文模型在RAF-DB 和FERPlus 数据集上的混淆矩阵如图7 所示。由此可见,高兴表情的识别率最高,厌恶表情的识别率最低。
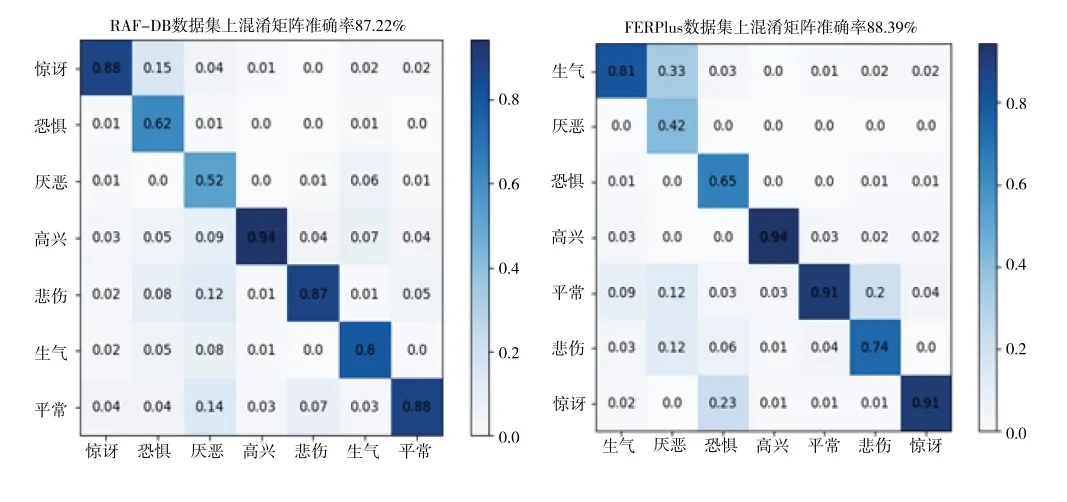
Fig.7 Confusion matrix图7 混淆矩阵
在RAF-DB 数据集上,惊讶表情容易误识别为平常或高兴,恐惧表情容易误识别为惊讶、悲伤、高兴或生气,厌恶表情容易误识别悲伤、平常、高兴或惊讶,高兴表情容易误识别为平常,悲伤表情容易误识别为平常或高兴,生气表情容易误识别为高兴或恐惧,平常表情容易误识别为悲伤或高兴。在FERPlus 数据集上,生气表情容易误识别为平常、高兴或悲伤,厌恶表情容易误识别为生气、平常和悲伤,恐惧表情容易误识别为惊讶或悲伤,高兴表情容易误识别为平常,平常表情容易误识别为悲伤或高兴,悲伤表情容易误识别为平常,惊讶表情容易误识别为平常。
图8 为误识别的表情图片,一部分误识别是因为遮挡、光照、模糊等客观因素所导致。由此可见,当数据集搜集、标注等不一致时,每个数据集所呈现的误识别现象并不统一,但高兴表情均容易被误识别为平常,原因是高兴表情和平常表情在日常生活中最为常见,有些人在高兴的时候脸部表现十分明显,然而有些人与平常表情的差异 不大。

Fig.8 Examples of misidentification on two datasets图8 两个数据集上误识别样例
图9 为与本文架构相同的GCN 和AGCN 模型提取的特征热力图。由此可见,AGCN 模型提取的特征注意力较为集中,使得大部分表情关键区域局部特征的提取能力得到了提升;GCN 模型提取特征分散,例如平常表情关注眼睛和嘴巴区域变化,该模型只提取嘴巴区域的特征,因此容易产生分类错误。

Fig.9 Model characteristic heat map图9 模型特征热力图
3.3 比较实验
将本文AGCN 模型与AlexNet[19],VGG16[19]、VGG19[20]、ResNet-18[19]、ResNet-34[20]和CapsNet[21]这些在FER 中广泛使用的知名CNN 架构进行比较,结果如表2所示。由此可知,本文模型在RAF-DB、FERPlus 数据集上识别精度最优,AlexNet、CapsNet 模型相较于其他模型明显较差。在精度方面,AGCN 模型相较于传统VGG16、ResNet-18 模型的性能更高,在RAF-DB 数据集上使用一个epoch 来评估模型的计算复杂度发现,AGCN 模型的训练时间6.13 s,分别为AlexNet、VGG16、ResNet18 的1/7、1/21、1/8。
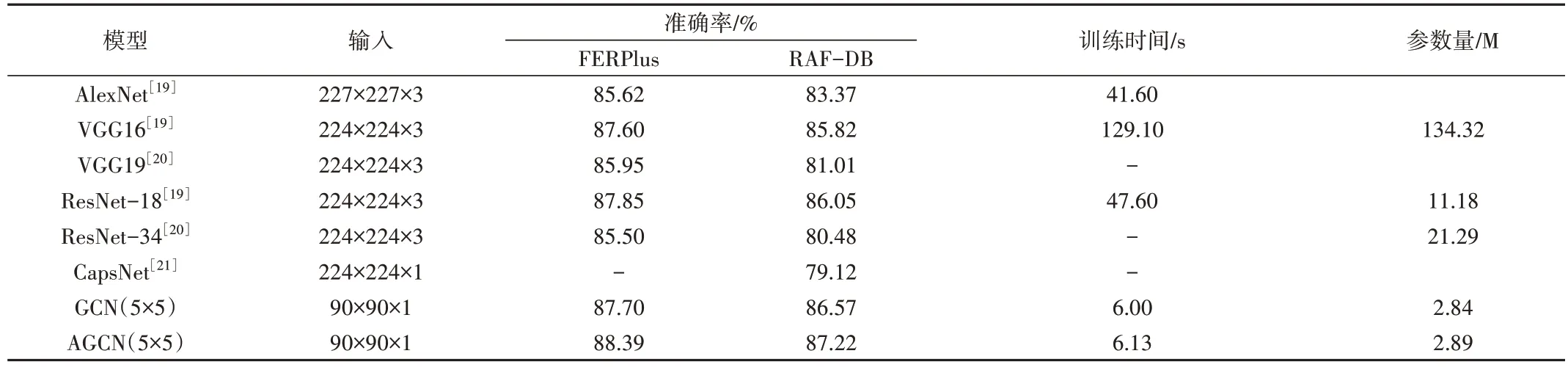
Table 2 Comparison of some well-known CNN architectures表2 一些知名的CNN架构比较
综上,本文模型相较于FER 领域一些高效的CNN 架构而言,具有更好的识别精度,所需计算资源和内存成本更少。
3.4 FER性能比较
为了使模型达到最优精度,许多方法在大型数据集上进行预训练。为此,本文模型在focal loss 损失的监督下,在AffectNet 数据集[22]上进行预训练,具体结果如表3 所示。本文模型的识别率分别为88.39%、87.22%,SPD-Attention 局部流行注意力网络架构[20]通过流行注意力模块,对原始图片和n张局部裁剪图片的联合特征向量提取的分类特征进行表情预测,整体识别率为87.9%和86.63%,但模型相当复杂,不利于实际使用。

Table 3 Performance evaluation on the FERPlus and RAF-DB datasets表3 FERPlus和RAF-DB数据集上的性能评估
A-MobileNet[23]为基于轻量级MobileNet V1 的注意力模型,模型深度为27 层,参数量为3.4 M,在FERPlus、RAF-DB 数据集上分别达到88.11%、84.49% 识别率。SCN+ResNet18[24]为了抑制表情数据集中不确定性,提出一种简单、有效的自治愈网络,在RAF-DB 数据集上识别率相较于本文方法提升了0.92%,模型参数量为11 M。DICNN[25]为双集成卷积神经网络,参数量较少速度快,可在移动端部署,但识别精度相对较低。孙冠[26]为了缓解注意力网络对重点局部区域关注不充分的问题提出滑动窗口块,设计了由ResNet-50网络提取特征图+注意力模块的滑动块注意力网络+注意力模块的全局注意力网络组成的LGSBAN-AM 模型,该模型相较于本文方法效果几乎相当,但基于ResNet-50 网络的参数非常多且不易训练。黄苑琴[27]提出在VGG16 模型中加入SGE 注意力模块以增强特征提取能力,在FERPlus 数据集上达到了89.5%的识别率,但在RAF-DB 数据集上仅为86.7%。吴晗[28]提出在ResNet-18 网络中引入通道注意力模块+空间注意力模块+区域特征编码模块识别表情,但在FERPlus 数据集的准确率相较于本文方法降低了4.69%。赵爽[29]提出融合多尺寸的局部注意视觉Transformer 表情识别方法MS-LAViT,识别效果相较于本文方法在FERPlus、RAF-DB 数据集上分别提升0.51%、0.26%,但训练ViT 模型需要大量的训练数据和算力。王广宇[30]提出改进残差网络Y-Net 表情识别方法,相较于本文方法在FERPlus、RAF-DB 数据集上的精确度分别降低1.89%和2.02%。
综上,本文所提AGCN 模型不仅结构简单,而且在识别率、参数量和消费算力等方面较为均衡,在FERPlus、RAF-DB 自然环境数据集上的识别精度优于大多数最新的FER 方法,原因在于情绪识别与某些识别任务不同,主要依赖面部ROI 信息。例如,对于人脸识别而言,整个面部信息相较于局部特征更重要,GOF 刻画局部纹理的特征非常有利,CBAM 注意力模块可在通道和空间层集中提取更为显著的特征,因此AGCN 模型能有效提取面部表情且所需计算资源非常少。同时,本模型仍属于一种CNN,因此能与任何应用于FER 领域的传统CNN 的技术相结合。
4 结语
由于面部表情变化主要集中在眼睛、眉毛、嘴巴和鼻子等局部区域,Gabor 滤波器特别适用于局部纹理,Gabor核与传统卷积滤波器调制的GoF 在捕获面部ROI 特征方面非常有效。因此,本文在使用GoF 的深度CNN 基础上引入注意力模块,提出一个仅为6 层结构的轻量级AGCN模型。
实验表明,本文所提模型相较于AlexNet、VGG16、VGG19、ResNet-18、ResNet-34 和CapsNet 这些在FER 中广泛使用的知名CNN 架构而言,识别性能更好且所需计算资源更少。
