文本方面级情感分析方法研究综述
2023-09-15汪红松李嘉展曾碧卿
汪红松,李嘉展,曾碧卿
(华南师范大学 软件学院,广东 佛山 528225)
0 引言
文本情感分析[1]也称为观点挖掘[2-3],是自然语言处理(Natural Language Processing,NLP)的重要内容之一,其主要任务是挖掘并分析人们对不同主题、属性等的观点和态度[2]。文本情感分析的主要流程如图1 所示,其中数据预处理是情感抽取的准备工作,主要进行分词、命名实体识别等。情感抽取模块主要用于处理输入的数据,提取输入数据的特征表示。
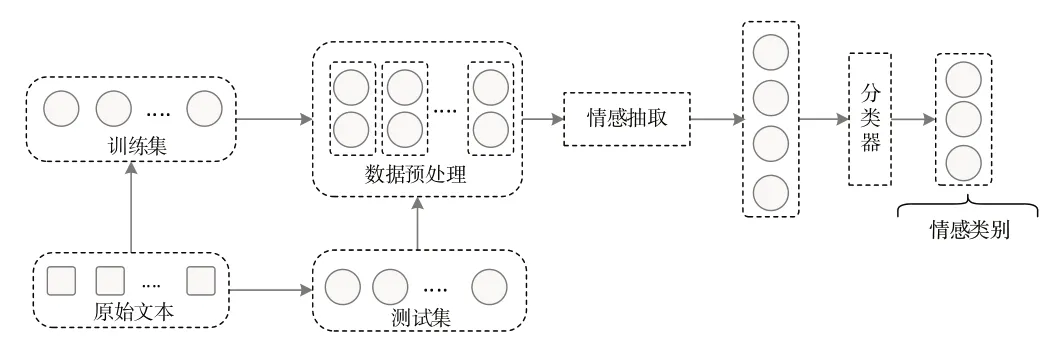
Fig.1 Text sentiment analysis processing flow图1 文本情感分析处理流程
在情感分析领域,狭义的情感分析通常定义为对外界事物的态度,如正面、负面、中立等。传统上,情感分析一般分为3 个层次:句子级别、文档级别、方面级别。早在2002 年,Pang 等[4]提出利用机器学习的方法,将文档的情感倾向作为情感分类依据。随着研究的深入,Wawre 等[5]利用多种监督方式,提出将句子表达的情感极性视为分类问题。近年来,受到深度学习的影响,方面级情感分析(Aspect-based Sentiment Analysis,ABSA)逐渐成为新的研究热点,通过引入不同的场景任务来分析不同的情感元素[6]。
1 相关研究
根据文本的层次粒度,情感分析可分为粗粒度情感分析和细粒度情感分析[7]。粗粒度情感分析主要侧重于句子级与文档级的情感分类,细粒度情感分析通常侧重于对方面词的情感极性进行判断。随着近些年研究的深入,粗粒度的情感分析缺乏捕获实体与句子中相关方面情感极性的能力,无法满足文本层次粒度更细的情感分类要求,因此细粒度文本情感分析受到更广泛的关注[8]。
1.1 方面术语抽取
方面术语抽取(Aspect Extraction,AE)是ABSA 中的一项关键任务,旨在提取句子中存在的方面词[9]。目前,方面术语抽取主要分为显式方面术语抽取与隐式方面术语抽取。
显式方面术语是指文本中能够清晰指明的方面词与目标情感词,常结合统计学习的方法,如条件随机场(Conditional Random Field,CRF)和隐马尔可夫[10]等。Zschornack 等[11]利用注意力机制,提出基于Bi-LSTM 与CRF 的分类器,借助词性标记作为辅助功能,在Bi-LSTM 编码器作用下实现了显式方面术语抽取。
隐式方面术语是指在文本中没有明显指出的方面词与目标情感词,如“袋子里装满了食物,无法再装下水杯”,实体词“袋子”存在一个隐式方面词“容量”。由于隐式方面术语缺乏上下文线索信息,隐式方面术语抽取具有较大难度[12]。Liao 等[13]对隐式事实情感文本进行分类,提出一种结合卷积神经网络和语义依赖树的多层语义融合模型,该模型能够学习词语级、语句级别的语义信息,识别事实隐式情感文本特征。此外,由于缺乏足够的标注数据,很难精准地抽取方面术语,Wang 等[14]首次提出自训练学习方式来解决方面术语提取中标注数据不足的问题。
1.2 方面级情感分析
ABSA 属于细粒度的情感分析任务,首先识别给定文本中的方面词与目标情感词,再预测方面词的情感极性[15]。ABSA 主要对方面词与相应目标情感词的关系进行建模,针对不同的方面术语提取更精细的情感信息。例如“the battery life is also relatively excellent”,方面术语“battery life”的目标词“excellent”表达正面情感。因此,ABSA侧重于分析方面词与目标情感词的关系,以获取更精细的情感极性。在早期的研究中,对于输入句子存在多个方面词的情况,常常采用多次输入同样数据的方法来分析方面词的情感极性。随着研究的深入,人们逐渐发现同一个句子中不同方面词之间存在情感关联,并通过引入上下文的观念,逐步丰富关于ABSA 的研究。
为了进一步了解ABSA,本文以Web of science 为检索文献平台,以 “方面级情感分析”“Aspect Based Sentiment Analysis”为主题词,利用Web of science 官方数据工具对2010—2022 年以ABSA 为主题的文献进行分析。同时,以主题词为中心,通过VOSviewer 工具生成如图2 所示的共现图。总体上,早期ABSA 研究主要依赖于机器学习等方法,引入深度学习方法后,以深度神经网络为基础的模型成为主流的ABSA 研究方法。

Fig.2 Co-occurrence diagram of subject words图2 主题词共现图
2 方面级情感分析方法与技术
目前,ABSA 研究主要分为传统方法和基于深度学习的方法。传统方法主要包括机器学习、情感词典等。由于机器学习在情感分析中属于浅层学习,不涉及特征学习,基于深度学习的方法利用非线性网络模型来获得更符合任务需求的函数,从而实现对数据特征的自动学习。
2.1 方面级情感分析数据集
目前,研究者可以使用公开数据集,也可以通过收集、筛选、过滤等步骤构建数据集。表1 列举了目前ABSA 研究进行模型训练常用的数据集。

Table 1 Introduction to common datasets表1 常用数据集简介
2.2 评估指标
情感分类任务模型通常采用混淆矩阵来评估其性能,评价指标包括准确率(Accuracy)、精确度(Precision)、召回率(Recall)以及F1 值等。评价指标由TP、FP、FN、TN 几个元素组成,具体公式如表2 所示。其中,TP 表示分类器正确地将正类样本预测为正类的样本数量,FP 表示分类器错误地将负类样本预测为正类的样本数量,FN 表示分类器错误地将正类样本预测为负类的样本数量,TN 表示分类器正确地将负类样本预测为负类的样本数量。
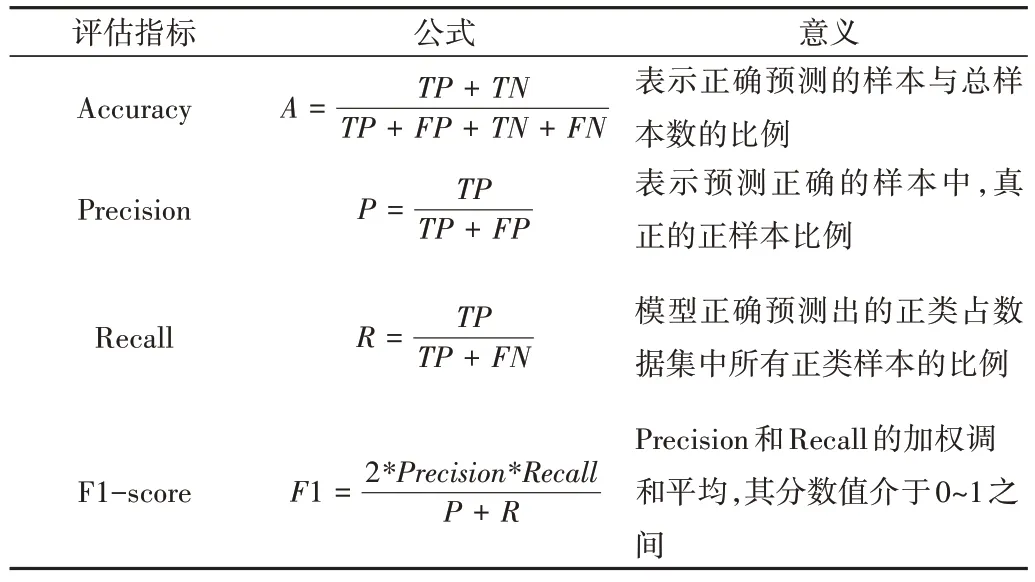
Table 2 Evaluation indicators表2 评估指标
2.3 传统方面级情感分析方法
传统的ABSA 任务主要通过基于规则的方法和基于统计的方法来完成[16]。基于规则的方法需要大量词汇极性标注工作以及由语言学家制定的词典规则,分类任务的准确率与词汇标注结果和规则设定相关。基于统计的方法根据上下文中相似情感词的共现频率,将其归为相同极性,因此一个词的情感极性与上下文中其他词的共现频率相关。表3列出了传统ABSA 分析方法的优缺点。
2.3.1 基于规则的方面级情感分析
基于规则的方法通常使用基础词典,通过扩充基础情感词典,挖掘目标词之间的相互联系。Zhang 等[17]根据方面词之间的依赖关系确定句子的情感极性,通过聚合句子以预测整个文本情感;Tan 等[18]利用先验情感词典将财经新闻分为正面或者负面,并通过构建情感词典确定财经新闻文章中每个句子的情感极性;Gao 等[19]通过构建情感词库和识别不同语言特征来获得不同情感原因的组成比例,并提出基于规则的情感原因检测方法,实验结果证明了情感词典有利于ABSA 分类任务。
2.3.2 基于统计的方面级情感分析
基于统计的方法不依赖于语言学家所制定的语言规则[20],通常从给定的单个语料库中提取方面词,但不同语料库中方面词分布特征的差异未得到充分利用。因此,Pu等[21]利用逐点互信息检测名词短语,并降低依存关系的负面影响,再根据句法依存规则对方面词进行提取;Han等[22]提出一种基于特定领域情感词典的分类方法,通过引入互信息来分配词典中带有词性标签的方面词,并根据方面词情感值从未标记的语料库中选择训练数据,再由基于SentiWordNet 的情感分类器进行文本情感分析。
通过上述分析可以发现,传统的方面级情感分析方法能适应不同领域的目标任务。此外,基于统计的方法不依赖于语言学家制定的规则,减少了人工干预[23]。基于语料库的方法虽然简单,但需要一个较大的数据集来检测方面词极性,才能对给定的文本进行情感分析,依旧无法高效地挖掘不同细粒度实体识别的情感信息。因此,为了更好地探索细粒度情感分析任务,学者们将研究方向转向面向深度学习的情感分析模型。
2.4 基于深度学习的方面级情感分析
深度学习展现了强大的特征提取和文本表达能力以及可扩展性,受到研究人员的高度关注。因此,在ABSA 任务中,基于深度学习的方法逐渐成为人们的研究热点。基于深度学习的ABSA 分类方法利用神经网络进行情感分类时,主要有3个任务[24],如图3所示。
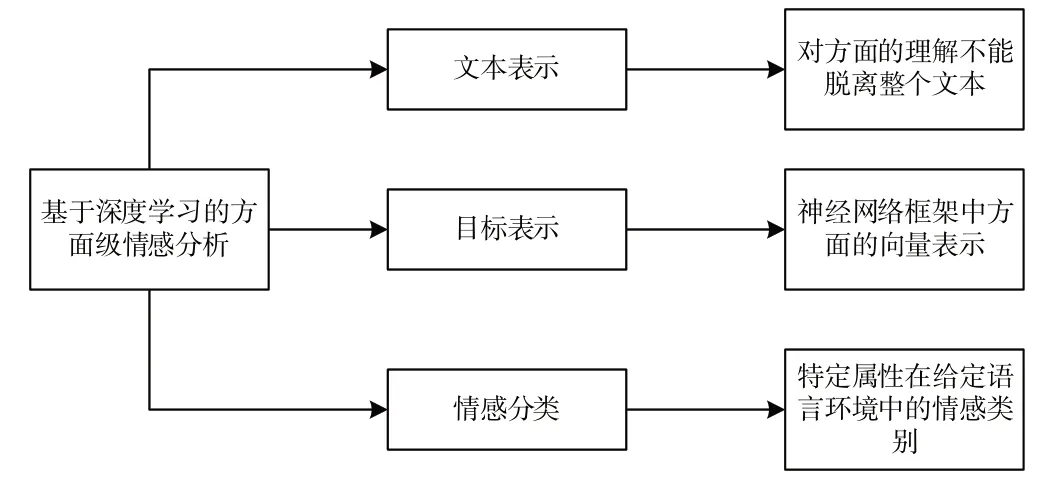
Fig.3 Aspect-based sentiment analysis tasks of deep learning图3 深度学习的方面级情感分析任务
(1)文本表示。文本表示通常使用关键字集,在用向量表达文本时,特征提取算法基于预定义的关键字对文本中的目标词权重进行计算,形成数字向量,即文本的特征向量[25]。
(2)目标表示。目标表示是ABSA 用于表达不同情感的重要任务之一,主要任务是生成与上下文交互的向量,通常使用词嵌入方法得到目标的向量表示。
(3)情感分类。情感分类主要是为了识别特定目标词的情感极性。例如句子“服务器的显卡算力充足,但使用成本昂贵”中,目标词“显卡算力”对应的上下文情感词是“充足”,情感极性为积极,而“价格”对应的上下文情感词是“昂贵”,情感极性为消极。针对此类任务,通常通过引入注意力机制来解决。
基于深度学习的ABSA 任务关键在于文本表示和目标表示,尽管近年来该领域受到研究人员的广泛关注,但目前还缺少适应多种场景任务的ABSA 框架。因此,利用深度学习方法完成ABSA 任务目前仍处于发展阶段。
2.4.1 基于注意力机制的方面级情感分析
早期的研究方法依赖于人工设计或提取与目标相关的情感信息,但这些方法高度依赖于人工设计的特征向量[26]。为了明确目标实体与上下文中情感信息的关系,有学者提出从目标信息挖掘目标词的情感极性[27],但这些方法只考虑目标信息而忽略了上下文信息。基于注意力机制的神经网络模型能隐式地将目标与上下文信息联系起来,因此在自然语言处理领域受到人们关注。
Wang 等[28]结合注意力机制和LSTM,提出ATAELSTM(Attention-based LSTM with Aspect Embedding)网络模型,通过将方面词与句子的隐藏特征表示相结合,提出基于方面词的注意力权重以及将方面词向量与输入向量结合的方法;Chen 等[29]提出基于多注意机制的记忆神经网络模型(Recurrent Attention Network on Memory,RAM),通过记忆存储单元捕获长距离文本中特定方面词的情感极性;Ma 等[30]为了充分利用上下文的语义关系,协调目标与上下文词之间的依赖关系,提出MGAN 模型(Multigrained Attention Network),加强了目标与上下文词之间的相互联系[31]。同时,有学者将传统方法与注意机制相结合。Lu 等[32]提出基于规则的交互式注意力神经网络模型(Interactive Rule Attention Network,IRAN),该模型通过语法规则编码器,进一步提高了目标词与上下文交互能力。
2.4.2 基于预训练语言模型的方面级情感分析
在序列化语言模型中,例如RNN 虽能捕获长距离依赖关系,但由于复合函数求导涉及链式法则,容易出现梯度消失问题。而对于CNN 模型,由于卷积核的存在,导致特征提取时存在局部最优问题。因此,2017 年谷歌提出Transformer 模型框架[33],通过模块化结构引入矩阵运算,提高了模型的并行能力。针对RNN 和注意力机制在建模时存在并行化能力低、梯度消失的问题,Song 等[34]采用注意力机制的编码器对目标词及上下文进行建模,提出结合BERT 预训练语言模型的注意力编码网络。
在ABSA 研究中,通常将预训练语言模型用于处理输入文本,并将其融入到更深层次的神经网络中。Bai 等[35]在BERT 模型基础上融合语义信息,提出了图注意力网络模 型(Relational Graph Attention Network BERT,RGATBERT),在语义标签依赖信息的加持下,提升了ABSA 的分类性能;Zhang 等[36]为了将动态语义与ABSA 模型融合,提出动态加权的语言模型(Dynamic Re-weighting BERT,DRBERT),通过动态加权分配以更好地进行方面感知的情感理解。此外,有学者为了使ABSA 模型成为通用框架,将ABSA 建模为生成类任务。Yan 等[37]将每个ABSA 子任务目标重新定义为指针索引和情感类别索引混合的序列,并使用统一的生成公式,结合预训练语言模型BART 来完成所有端到端框架中的ABSA 任务。
2.4.3 基于图神经网络的方面级情感分析
虽然上述方法被广泛应用于ABSA,但这些模型缺乏解释相关句法约束和长距离词依赖性的机制,仍难以挖掘细粒度实体在文本中的句法依赖信息。为解决上述问题,Zhang 等[38]结合依存关系树的图卷积神经网络,利用句法信息与目标词的依赖关系挖掘文本的依存信息,证明了句法信息对长距离文本分类的重要性。由于语言的复杂性,当句子中存在多个方面词时,会导致目标词与上下文信息不匹配。针对这种情况,Li等[39]提出双通道图卷积神经网络模型(Dual Graph Convolutional Networks,DualGCN),其中包含一个具有自注意机制的情感模块,利用句法结构和语义相关性减少依赖解析的错误。
当前大部分基于图神经网络的情感分类方法主要集中在学习句子依存树的上下文词与目标词的依存信息,缺乏利用特定目标词的上下文情感知识。因此,Liang 等[40]提出基于依存关系树和情感知识的图卷积神经网络模型Sentic GCN,该模型利用上下文词与目标词之间的依赖关系和情感信息,通过聚合SenticNet 中的情感知识学习上下文词语和特定方面的情感依赖关系,增强方面词与上下文的语义相关性。此外,对于特定方面词的分析,Chen 等[41]提出面向方面词的离散意见生成树模型(Discrete Opinion Tree GCN,DotGCN),该方法将方面词与上下文之间的注意力分数作为句法距离得到新的生成树。
同时,由于依存句法树多数通过句法分析器生成,而句法分析器的编码模式引入了噪声。为了缓解噪声问题,Tian 等[42]设计了类别感知网络,利用注意力机制区分不同的边缘关系,增加了方面词相关的上下文权重。类似的,Liang 等[43]首次提出结合句子成分信息与依赖信息,构造双语法感知注意力网络(Bi-Syntax aware Graph Attention Network,BiSyn-GAT),针对上下文内部与上下文之间的关系进行建模,进而提高对语法信息的有效利用率,降低无关噪声的干扰,增强方面词与上下文之间的情感交互。
2.4.4 基于目标的方面级情感分析
目标—方面级情感分析(Target Aspect-Based Sentiment Analysis,TABSA)是ABSA 领域的另一个研究热点。TABSA 的主要任务是识别目标和方面的细粒度信息,例如在句子“location1 is your best bet for secure although expensive and location2 is too far”中有“location1”和“location2”两个不同的目标词,目标词“location1”有“safety”和“price”两个不同的方面词,而目标词“location2”只有“price”一个方面词。
Saeidi 等[44]提出一个用于TABSA 的基准数据集Senti-Hood,该数据集被标注为城市社区领域,在逻辑回归函数和LSTM 模型的训练下,提供一个更加强大的基线。对于TABSA,以往的方法是将方面词权重初始化为同一个值,再计算平均向量,但这种方式将不同方面词与目标之间的情感关系过度简单化。因此,Ma 等[45]提出分层注意力模型Sentic LSTM,通过引入外部知识来扩展LSTM 单元,解决了分层注意力机制在推断给定目标词和相关情感词时关系不明确的问题。为了从预定义的方面词集合中提取细粒度的意见极性,Liu 等[46]提出利用外部“记忆链”,结合延迟内存更新机制的网络架构,在TABSA 基线任务上取得了实质性改进。
针对方面词在不同上下文中具有相同向量表示而丢失了上下文相关信息的现象,Liang 等[47]在输入层嵌入预训练语言模型向量,并提出新的模型架构,利用稀疏系数向量从上下文中调整目标词和方面词的嵌入,而不是使用上下文无关或随机初始化的向量,并且在优化方面词表示过程中,让其尽量远离无关的目标词。
2.4.5 基于外部情感知识的方面级情感
虽然神经网络在ABSA 中具有优异的表现,但神经网络模型性能与数据集大小有密切联系,若缺乏数据会导致神经网络模型发挥不出应有的性能。但现有的用于ABSA的公共数据集都相对较小,为了解决数据集与神经网络不匹配的问题,学者们提出了基于外部情感知识的方法[48]。
基于外部情感知识的方法能够减少模型对数据的依赖,并且结构化知识和情感知识能够提高模型性能。在结构知识方面,Nguyen 等[49]提出将句子结构信息融入注意力机制的网络模型ALAN,结合LSTM 神经网络,取得了较好的分类效果;Wang 等[50]认为词与从句之间的情感信息同样需要得到重视,因此在句子层面采用语义分割方法将句子分割成若干个子句,进一步证明了上下文语义信息对于方面词的重要性。
2.4.6 基于深度学习的方面级情感分析方法对比
为了更清晰地对比上述方法,表4 列举了部分基于深度学习的ABSA 实验效果,表中粗体字表示同类型方法中较优的结果。在处理ABSA 任务时,通常会利用不同模型的优势以及避免模型缺陷来达到较优的结果,因此可以预测未来针对ABSA 的任务会更加专注于结合不同方法,并且通过对预训练模型的微调,实现更好的情感分析效果。
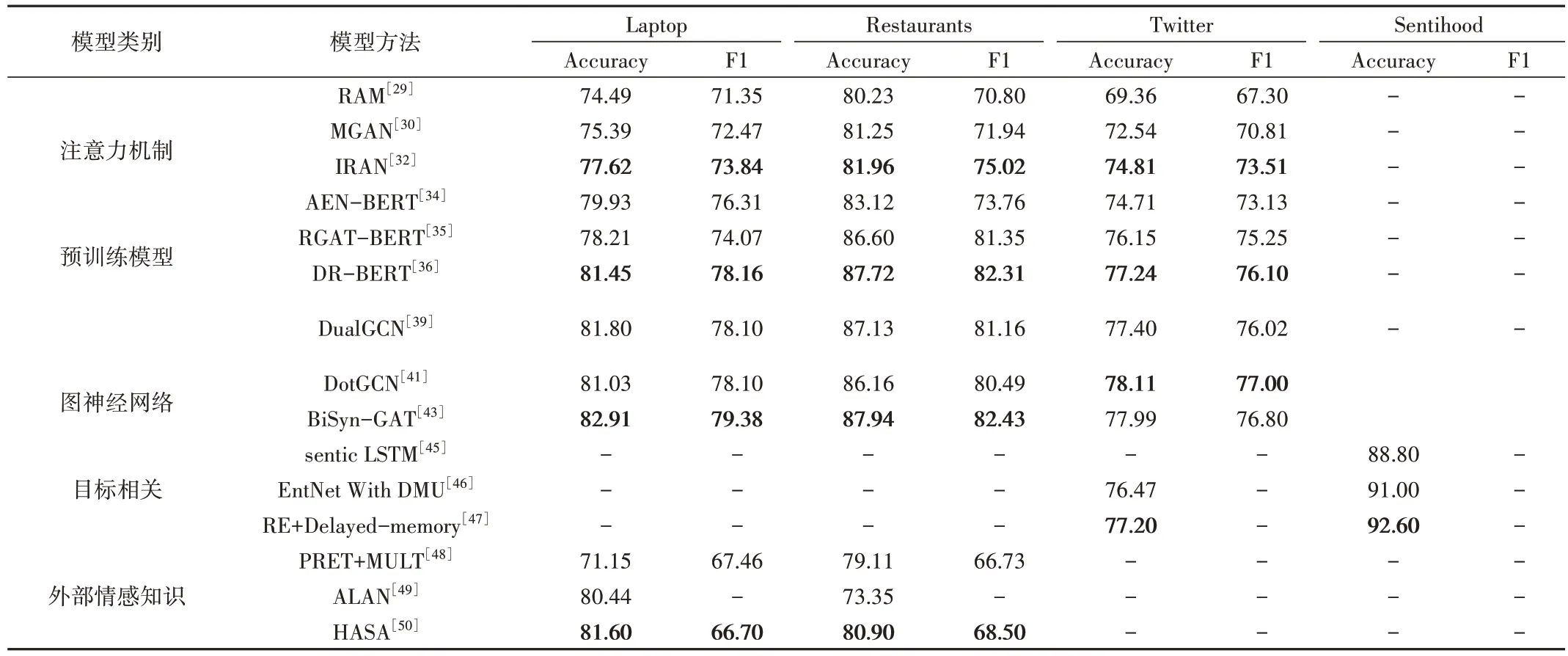
Table 4 Aspect-based sentiment analysis methods based on deep learning表4 基于深度学习的方面级情感分析方法
基于注意力机制的方法在计算时,考虑了目标词与上下文信息。基于预训练语言模型的方法提供了更好的模型初始化参数,将注意力机制与预训练语言模型相结合,使得目标任务具备更好的泛化性。基于图神经网络的方法能处理非连续的目标词,解决非欧式空间问题,借助语法解析树获得语义相关性更强的目标词。基于外部情感知识的方法常结合语料库来提升模型的情感分析能力。基于目标的方法需根据给定的目标词,形成目标词和方面词的组合,推断出文本的情感极性。
同时,从表中可以看出,综合运用不同模型,并取其利、去其弊,能达到较优的效果,这也说明了当前方面级情感分析研究方法的趋势,即结合不同方法,运用大规模预训练模型并进行参数微调,以期得到更好的实验效果。上述方法的具体比较如表5所示。

Table 5 Comparison of aspect-based sentiment analysis methods based on deep learning表5 基于深度学习的方面级情感分析方法比较
3 方面级情感分析发展趋势
国内外学者针对不同的ABSA 任务已提出了各种各样的模型框架,并取得丰硕的研究成果,模型的精度、数据处理能力都在不断提升。目前,ABSA 尚处于发展阶段,仍存在许多值得研究的问题。
3.1 隐式情感分析
目前大部分ABSA 的研究对象是显式的目标情感词,而对于隐式ABSA 的研究还处在初步发展阶段。例如反讽、隐喻等特殊形式的文本,通常隐含与字面相反的意思,以夸张、比喻等手法对人或者事物进行揭露[51]。隐式情感的表达方式在生活中广泛存在,如“手机只是你生活的一部分,而你确是它的全部,请放下身边杂事,多陪陪手机”,该句子的真实情感是讽刺人们过度使用手机。但隐式情感分析的复杂性和不确定性使隐式情感分析成为一项具有挑战性的任务。隐式情感分析的主要任务是从文本中挖掘出蕴含的情感信息,现有的主要方法是基于特征和规则以及基于上下文的方法。
Lou 等[52]利用外部情感常识检索情感信息和句子的句法信息,为每个句子构建情感图和依赖图,通过交互式建模情感信息和依赖信息,推断出句子的隐含情感;Mao等[53]提出无需任何预处理即可在单词级别识别和解释隐喻情感的方法,并在机器翻译任务中,能够识别隐喻词并将其替换成常见的同义词;Javdan 等[54]在ABSA 任务基础上,利用BERT 模型提取上下文对话序列和对话回复之间的情感关系,并确定提取的方面词是否具有讽刺意义。
3.2 情感文本生成
文本生成不仅仅关注文本传递的信息(摘要、问答),传递文本的方式也同样值得关注。对于ABSA 而言,情感文本生成是生成以方面词为中心的文本,如具有特定情感(兴奋、生气、伤心等)的文本。Wang 等[55]采用无监督学习的方式,在文本生成器中建立一个基于惩罚的目标,通过训练多个生成器和多分类器生成具有特定情感标签的文本;Du 等[56]提出在情感文本生成的每一步中采用自回归高斯分布对回复语义进行建模,增强了以实体词为中心的情感表达,降低了传统情感对话过程中无意义回复的频率。因此,目前在情感文本生成领域,研究热点逐渐转向以方面词为中心的情感表达,丰富以实体词为中心的情感文本信息。
3.3 多模态情感分析
社交媒体上并不仅有文本能够表达人们的情感,图片、音频、视频等同样能够表达人们的情感。因此,通过设计用于提取视觉特征语义的新方法对多模态数据进行统一分析已成为一个重要的研究领域。进行多模态情感分析时,需要对带有情感色彩的图文、视频等多媒体信息的主题或某些方面进行分析、处理、归纳和推理。Liang 等[57]将多模态情感分析与讽刺识别相结合,从模态内情感依赖关系和模态间情感依赖关系两方面出发,对输入样本进行联合学习,推断多模态数据的讽刺识别结果;Ju 等[58]结合多模态方面术语提取和多模态情感法分类,提出带有辅助的跨模态关系检测联合学习方法,利用辅助文本图像控制视觉信息的应用,并根据联合提取的方面信息获取方面级别的情感分类。
总而言之,ABSA 的研究热点和未来面临的问题与挑战还不止于此。对于文本而言,不仅需要考虑最终的情感极性,而且需要考虑用户生成的文本是否符合语法规则,以及如何处理表情符号等问题。此外,寻找一个合适的统一框架来完成各种ABSA 任务也是目前的发展趋势之一。
4 结语
随着信息技术的快速发展,社交平台数量的急剧上涨,以用户为中心的言论信息量也呈爆发式增长。言论信息可用于情绪化分析,已广泛应用于电子商务、心理治疗、舆情监控等领域,具有较高的商业价值与社会价值。在情感分析领域,对于ABSA 的研究是一个重要的子任务。本文简要介绍了情感分析的常用方法,主要阐述ABSA 近年来常用的分类技术和研究热点,并简要分析ABSA 未来的发展趋势。
目前,深度学习具有自动提取特征、较强的非线性数据处理能力以及能显著降低人工标注成本等优势,在情感分析研究中得到了广泛应用,但是深度学习所带来的红利也渐进尾声,单纯的模型复用和模型叠加并不能很好地提高分类效果。随着研究的深入,基于浅层的情感分类任务逐渐陷入瓶颈。文本情感分析的研究任务逐渐向情感理解、情感生成、情感交互方面不断深入,研究范围已从单模态数据逐渐拓展到多模态数据。因此,ABSA 的研究还在不断发展中,对于复杂语法、讽刺识别、跨领域多模态等情感分析任务的研究正方兴未艾。
