轻量级自注意力机制为主干的自然土地覆被分割研究
2023-09-15安昭先魏霖静
安昭先,魏霖静
(甘肃农业大学 信息科学技术学院,甘肃 兰州 730070)
0 引言
目前针对自然土地覆被的分割手段一直采用传统图像分割方法,不同于城市建筑分割任务,自然土地覆被分布广、土地覆被对象形状不规则。将现有的深度学习图像分割方法直接应用于自然土地覆被分割任务上效果不理想,因为这些方法过于追求图像语义,忽视了有限感受野下的局部特征。
因此,本文提出作用于自然土地覆被遥感图像的语义分割方法GFormer,一个在自然土地覆被任务中具有极强分割能力与分割稳定性的深度学习分割方法。本文创新点如下:①提出一个应用于自然土地覆被分割任务的数据集处理手段;②改进了MixTransFormer[1]的结构,使该结构更适应遥感图像的特征提取;③设计一个具备递进式特征融合结构的解码器,迫使解码需按序提取编码器输出的层次性特征。通过与DeepLabV3+[2]、Unet[3]以及SegFormer等进行对比,证明GFormer 在地物覆盖遥感图像分割中具备有效性和鲁棒性。
1 相关工作
国内外针对自然土地覆被的遥感图像分割研究已经有几十年历史,学者们针对不同的场景、数据集提出了众多方法,这些方法根据解决手段可大致分为传统方法和深度学习方法[4]。
传统方法大多 数是基于阈值[5-8]、边缘[9-13]、区域[14-16]、聚类[17-20]、图论[21-23]等的图像分割方法,根据人为定义的特征提取函数作用于遥感图像,对地面覆盖物的颜色、形状、纹理、结构、分部等特征进行数量化描述,再进行分割。传统方法计算量小、分割效果好,且不依赖于学习数据。但传统方法具有处理手段单一、对图像颜色的宽容度低、分割类型少等缺点。
深度学习方法将图像分割任务转化为像素点分类任务,在图像分类工作中表现突出,因此众多学者尝试将深度学习方法应用于图像语义分割任务中。全卷积网络[24](Fully Convolutional Networks,FCN)的编码器由经典的卷积层组成,解码器采用反卷积对卷积层最后一个输出的特征图进行上采样,最后直接在上采样的特征图上进行像素分类,从而解决了语义级别的像素分割问题。FCN 的提出也基本确定了语义分割包含编码器和解码器两部分的基本结构。Unet[3]证明了退化现象在语义分割领域的存在,可使用快捷连接的手段解决模型性能与有效感受野[25]之间的矛盾,并且通过特征融合帮助找回反卷积层上更大尺寸特征图上的特征边缘。DeepLab[2]提出一个新的卷积计算方式——空洞卷积,空洞卷积解决了内部数据结构丢失和空间层级化丢失的问题,并且增加了卷积感受野的大小,降低了重建特征信息的难度,还将条件随机场[26](Conditional Random Field,CRF)引入到整个网络的末端,利用标签的关联信息,进一步提高了语义分割精度。
Transformer 模型的问世带来了一种全新的结构——自注意力机制(self-attention),该结构完全不同于CNN 或RNN,其能自动捕获序列不同位置的相对关联,正是这种特性使得Transformer 在NLP 任务中大放异彩。部分学者随后将其迁移到计算机视觉领域,并取得了不错的成绩,ViT 就是其中一个著名的例子[28]。ViT 引入基于计算机视觉设计的位置编码,将图像转化为序列,一个计算机视觉任务就转化为一个纯seq2seq 的任务。紧接着众多研究人员尝试将ViT 引入语义分割模型,其中一个比较成功的方法是复旦和腾讯联合提出的SETR[29],其在ADE20K[30]排行上获得第一,证明了自注意力机制在语义分割任务中的可行性。但SETR 仍具有一定局限性,其应用在大尺寸图像上的模型参数量过于庞大,也没有像U-Net 一样输出不同层次的特征块进行特征融合。SegFormer[1]设计了一种具有新的层次结构的自注意力机制编码器MixTransFormer,可以输出不同尺寸的特征,且不需要位置编码。
2 数据集及其预处理
研究选取陕西省延安市志丹县中西部地区的卫星遥感图像,此地区植被属于草原化森林草原区,在历史上这里曾有过植被葳蕤的时期,后经历战争破坏和长期的乱砍滥伐,使天然植被一蹶不振、分布不均,从而为自然土地覆被分割提供了先决条件。本文在此地区截取一张16 级的卫星全彩遥感图像,截取窗口大小为X轴方向24 459.85 m,Y 轴方向17 121.89 m,栅格图像左上角世界坐标为(X:12 067 878.03,Y:4 386 873.93)。此栅格图像分辨率为10 240*7 168,由截取窗口大小求得空间分辨率为2.388 7 m/像素,如图1所示。

Fig.1 Original image图1 原始图像
根据此地区的植被覆盖情况和地貌特性,本文设置了3 个自然土地覆被研究对象:森林植被、低矮植被、农田。语义对象分类示例如图2所示。

Fig.2 Semantic object classification example图2 语义对象分类示例
2.1 数据标注
EISeg(Efficient Interactive Segmentation)[31]是以RITM[32]与EdgeFlow[31]算法为基础,基于飞桨开发的一个高效、智能的交互式分割标注软件。本文采用适用于遥感建筑物标注的轻量化模型HRNet18s_OCR48,该模型以HRNet18s[33]为基础,在OCR48 遥感影像建筑分割数据集上达到拟合。尽管本文采用的数据集主体并非建筑物,但其仍然对本文遥感影像数据中的纹理、空间信息、相邻关系等特征敏感,可进行分割和标注。
为了方便训练集和测试集的划分,并考虑了原始图像的像素尺寸,本文首先将原始图像分割为70 张1 024× 1 024 像素的区块,再单独标注每个区块。区块分割示意图如图3 所示,其中浅色标注的是用于训练的区块(49 个,70%),深色标注的是用于测试的区块(21 个,30%)。考虑到标注人员对土地覆盖类的认知标准存在差异,因此3 位研究人员分别只针对一种自然土地覆被类进行标注。标注图是与遥感图像分辨率一致的单通道图像,然后以农田>森林植被>低矮植被的优先级顺序对标注图进行合并。合并后的标注值如表1 所示,遥感原图与合并后的标注图如图4所示。

Table 1 Labeled pixel value表1 标注像素值

Fig.3 Block division diagram图3 区块分割示意图

Fig.4 Labeled example图4 标注示例
2.2 数据增强
卫星遥感图像相较于其他图像,采集环境稳定、光学特征单一,且具有连续性的特点。本研究考虑到模型对卫星图像的纹理、大小敏感,因此没有针对卫星遥感图像作任何颜色变换,只针对遥感图像进行随机旋转、切分和翻转。在数据增强方面,首先将遥感图像与标注图在通道维度上进行连接,组成一张具有4 个通道的混合图像,接着将混合图像进行随机旋转、切分和翻转,最后将切分好的混合图像在色彩通道维度上进行拆分。本文在数据增强过程中保证了图像没有被缩放或拉伸,且切分后的图像不存在黑域。数据增强手段如图5所示。
上文分割好的区块为70 个,由于区块尺寸大小为 1 024*1 024,再分割后的遥感图像及对应的标注图尺寸大小为256*256,所以包含有效像素点的理论图像数量为 1 120 张。本文分别在49 个训练区块和21 个测试区块上进行再分割和数据增强,得到具有98 000 张图像的训练数据集和42 000 张图像的测试数据集。需要注意的是,由于MixTransFormer 输出的特征块尺寸为2 的负指数次方,所以需使用图像尺寸为2 的指数次方,而不是传统的7 的指数次方。
3 遥感图像语义分割模型
针对卫星遥感图像中自然土地覆盖语义提取的问题,本文对 SegFormer 进行了设计改进,提出了新的遥感语义分割模型GFormer。GFormer 架构设计如图6 所示。网络中OPE、Block 属于模型的编码器,包含一个具有新层次结构的Transformer 编码器,输出多层次、多尺度特征;M1、M2、M3 属于模型的解码器,是一种递进式特征融合解码器,能够将解码器输出的多层次、多尺度特征进行融合,生成最终的语义分割掩码。

Fig.6 GFormer architecture图6 GFormer架构
在卫星遥感图像分割任务中,MixTransFormer 编码器以其输出多尺度特征和具有稳定分级结构的优势,在性能上具备很大的潜力。然而,卫星遥感图像分割不同于多场景分割,其是一个连续、单场景的分割识别任务。此外,卫星遥感图像分割的目标对象通常呈现出不规则形状、复杂背景和单一纹理等特点。针对这些自然土地覆盖的特征,MixTransFormer 对于低分辨率细节的全局关注,可能会导致在此项任务中影响性能并损害分割能力。因此,本文通过增加高分辨率层编码器(MVT)的深度,同时降低分辨率层编码器(MVT)的深度,迫使MixTransFormer 减弱对低分辨率细节的全局特征提取能力,并提升对高分辨率细节的局部特征提取能力。
3.1 Gformer编码器
MixTransFormer 编码器由OPE 和Block 两部分组成。OPE 用来结合非重叠的图像块或特征块,Block 中包含一个高效的自注意力网络和一个轻量化的FNN 网络,用来生成图像块的特征图。其中,Block 是MixTransFormer 编码器性能优劣的关键,也是模型一个主要的计算瓶颈。
OPE 中仅包含一层卷积层,用于将重叠的块合并,以产生与非重叠过程大小相同的特征。OPE 将给定图像块的层次特征I=C×H/a×W/a 收缩为I^'=C^'×H/2a×W/2a。本文部署的OPE 部分卷积参数如表2所示。

Table 2 OPE parameters表2 OPE参数
ViT 已经证明了自注意力机制在语义分割网络中作为编码器的可行性。在自注意力机制中,Q(查询向量)、K(键向量)、V(值向量)的维度为d=C×H×W,计算方式为:
FNN为自注意力网络提供位置信息,FNN直接由FC网络和3×3的卷积驱动。激活函数选取GELU,许多方法都证明了GELU在语义分割中具有优异的性能。FNN可写为:
相比于具有最佳性能的SegFormer 编码器MiT-B5,本文通过增加浅层Block 层数并减少深层Block 层数,以增强模型对纹理特征的响应。层数信息如表3所示。

Table 3 Number of encoder layers表3 编码器层数
3.2 GFormer解码器
GFormer 解码器包括3 个步骤:MixTransFormer 输出的多级特征X 首先通过再编码器M1 进行再编码,接着将再编码后的特征使用M2 进行递进式融合,最后将融合后的特征通过预测网络M3生成预测掩膜。
语义信息在MixTransFormer 输出的特征块上达到饱和,本文使用4 个融合模块M1 对MixTransFormer 输出的特征块进行再编码,避免直接对输出的多级特征进行融合导致语义信息丢失。M11、M12、M13、M14 分别处理Mix-TransFormer 输出的特征块X1、X2、X3、X4。M1 的部分参数如表4所示。

Table 4 M1 parameters表4 M1参数
GFormer 解码器在融合方式上采用一种新设计的融合结构M2,对编码器输出的多层次特征采用递进式融合的方式,对再编码后的多层次、多尺度特征进行融合。融合器M2 由一层MLP 与BatchNormalization、RELU 拼接而成。在复杂场景下的语义分割任务中,分割对象边缘形状多样、复杂,致使对编码器输出的特征图进行上采样难度大,其特征图边缘的采样效果往往不好,地被覆盖物卫星遥感图像的分割对象却纹理明显。本文并未对原始遥感图像采用放缩、模糊、噪声、颜色干扰等形式的数据增强方法,最大限度地保留了遥感图像的纹理特征。并且在计算机视觉任务中,许多方法都证明了采用特征融合来丰富语义信息是有效的,而特征融合往往采用递进的融合方式。所以本文也借鉴了这种融合思想对多层次特征进行递进融合,即在高感受野特征图像块上递进融合低感受野特征图像块,迫使解码器首先关注宏观语义信息,接着在宏观语义上丰富细节。需要注意的是,在融合前本文对特征块进行了双线性插值,使其统一尺寸为64。M2 共有3 个依次融合再编码的特征块,详细参数如表5所示。
最后将融合后的特征块经过仅由MLP 组成的预测网络M3,生成分割好的预测掩膜。
如图6中的M1、M2、M3所示,解码器可写为:
最后在C×64×64 的标注掩码上,使用双线性插值恢复到原始图片尺寸C×256×256。
4 实验与分析
4.1 实验
4.1.1 实验环境
本文在网络模型训练部分使用TeslaV100,Video Mem为32GB,CPU 为4 核,RAM 为32GB,软件环境为:Ubuntu 18.04LTS,Python3.7,paddlepaddle2.2.2。
4.1.2 模型训练
在上节的实验环境中对第3 章所描述的网络模型进行训练,模型在paddlepaddle 深度学习框架下进行训练。模型训练采用批处理方式,在140 000×0.7(70%的图片作为训练集,其余作为验证集)张图片中,将每32 张作为一个批次(batch)输入模型进行训练,总计训练100 000 个批次。使用Momentum 作为优化器,学习率服从多项式衰减策略。本文使用大比重Momentum、小学习率的策略进行优化,损失函数使用交叉熵损失函数。模型的部分参数如表6—表8所示。

Table 6 Some parameters of model training表6 模型训练部分参数

Table 7 Some parameters of the optimizer表7 优化器部分参数
模型训练过程如图7 所示(对loss 数据作了平滑处理)。从图中可以看出,得益于学习率的线性下降,随着迭代次数的增加,Loss 曲线不断下降并趋于平缓,验证集的MIoU 和Acc 不断升高且波动减小,损失函数基本收敛,表明模型达到了最优。

Fig.7 Model training process图7 模型训练过程
4.1.3 模型预测
本研究采用滑窗的方式对未参与训练的21 个测试区块进行预测,预测结果为单通道暗图,像素值与表1 所示数据一致。预测的部分参数如表9所示。

Table 9 Some parameters of the prediction表9 预测部分参数
4.1.4 基于模型标注的面积测算
由于卫星遥感图像焦距与取像距离恒等,并且在模型训练过程中并未对遥感图像进行放缩变换,从而使根据模型标注计算正投影下的真实地面覆盖物面积成为可能。在插值前的模型标注中,每个像素点标注的面积是原始图像的4 倍。因此,只要对模型标注结果进行像素点统计,即可计算得到正投影下的真实地面覆盖物面积。其计算公式如下:
其中,N_sum 为模型标注像素点数量,p 为遥感图像空间分辨率。
4.2 实验结果
4.2.1 性能评价
对模型分类标注结果使用准确率(Accuracy)、精准率(Precision)、召回率(Recall)、均交并比(MIoU)、Dice 系数、kappa 值进行评估。语义分割可看作像素的分类问题,可(1)MixTransFormer 编码器。本文的人工标注精细程度并不高,这也是整个语义分割数据标注面临的普遍性问以将真实标注值与模型预测的标注值组合划分为真正例(True Positive)、假真例(False Positive)、真反例(True Negative)、假反例(False Negative)4 种情形,令TP、FP、TN、FN分别表示其对应的像素数量,并建立混淆矩阵M。设N 为总例数,Ai、Bi分别为混淆矩阵M 第i行、第i列的边际值。
Accuracy 描述的是正确分类的像素数占总像素的比例。计算公式为:
Precision 描述的是正确分类为正像素数占全部预测为正像素数的比例。计算公式为:
Recall 描述的是正确预测为正像素数占全部正样本像素数的比例。计算公式为:
F1 值描述的是精确率和召回率的调和平均数。计算公式为:
MIoU 是语义分割最常用的标准度量手段,描述的是分类为正像素集与正样本像素集的交集和并集之比,直接反映了真实标注与模型预测标注的重叠程度。计算公式为:
Dice 系数是一种集合相似度度量函数,Dice 系数描述的是分类为正像素集与正样本像素集的相似度。计算公式为:
Kappa 值是一种分类一致性检验方法,Kappa 值描述的是分类为正像素集与正样本像素集的一致性程度。计算公式为:
4.2.2 结果分析
图8 展现了不同模型在同一数据集下的分割结果,其中第一行是在测试集中选取一张1 024×1 024 大小的原始图像和人工标注以及各个模型对应的分割结果,后3 行则是森林植被、低矮植被与农田所对应的原始图像、人工标注以及各个模型分割结果的细节展示。表10 展现了本任务中各个语义分割模型在各方面的性能表现。
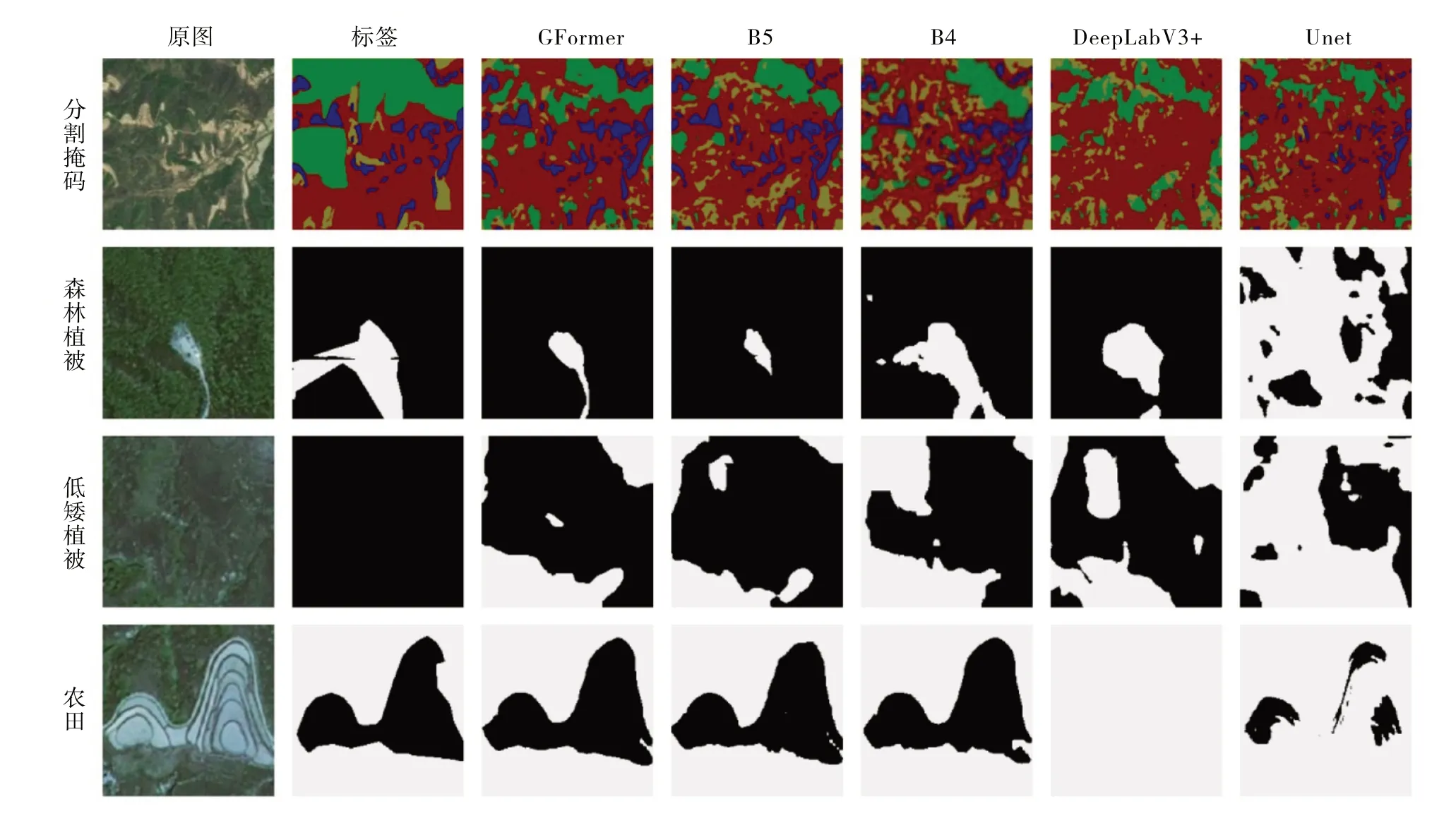
Fig.8 Segmentation results of different models图8 不同模型分割结果
题。一个著名的例子是ADE20K 数据集的作者Adela,其在时隔半年后重复标注61 张图片,对比前后标注得到的MIoU 仅为82%。对比图8 中的人工标注和原图可以明显看出:森林植被的人工标注图中间部分具有一道坏点像素;低矮植被的标注由于过于复杂,人工标注直接将所有像素全部标注为正;农田的人工标注图右上角将本属于农田的一小部分像素错误地排除到标注之外。
在模型训练过程中错误标签带来的是错误的惩罚,所以数据标注的精细程度直接影响着模型训练结果。观察图8 中DeepLabV3+[2,34]和Unet 在农田上的预测结果,DeepLabV3+和Unet 都是以卷积为核心的语义分割网络,Unet存在严重的欠分割问题,DeepLabV3+严重到未观测到这块农田。
由于农田占总像素的比例小,本文加大了对农田分类错误的惩罚,该做法在保持数据平衡的同时,也破坏了模型对特征的敏感程度。对不同种类的地面覆盖物信息敏感程度不同,这也许是以卷积为核心的语义分割框架效果不理想的原因。反观图8 中以高效自注意力机制为编码器的语义分割模型在农田上的预测结果,不仅基本正确分割了农田,而且正确预测了标签中错误标注的像素,展现了高效的自注意力机制作为编码器具有极强的鲁棒性。
(2)GFormer 解码器。SegFormer-B5 是SegFormer 框架下分割表现最好的模型,同时也是规模最大的模型。Seg-Former-B4 具有稍差于SegFormer-B5 的分割表现和更小的模型规模,并具有一致的模型结构。SegFormer-B4 具有与GFormer 一样的高效自注意力机制编码器,仅在层数布局与OPE 参数上稍有不同,所以SegFormer-B4 具有与GFormer 相似规模的编码器。由于GFormer 采用了更轻量化的解码器,因此GFormer 的模型规模更小。从表10 中可看出,SegFormer-B5、SegFormer-B4 的Flops 分别比GFormer 高60.3%和37.26%,SegFormer-B5 模型参数量比GFormer多30%,GFormer的参数量与SegFormer-B4大致相同。
对比图8 中GFormer、SegFormer-B5 和SegFormer-B4在森林植被与农田上的分割结果,GFormer 不仅正确预测了标签中错误标注的像素,而且具有比标签更圆滑的边界。因此,GFormer 具有比SegFormer-B5 和SegFormer-B4更贴合实际的分割结果。对比表10,GFormer 也具有比SegFormer-B5和SegFormer-B4更好的性能。
SegFormer-B4 的规模适合提取遥感图像中植被覆盖的语义特征,但其解码器的能力不足以有效地解码编码器中蕴含的语义特征。本文设计的递进式融合结构的解码器具有比SegFormer解码器更强的解码能力。
5 结语
地被覆盖物的遥感图像分割一直是地图科学研究的重点,该任务具有数据量大、采集难度高、标注困难、分割稳定性差等问题。本文提出一种基于轻量级图像自注意力机制编码器与具有递进式融合结构解码器的地被覆盖物分割方法,构建GFormer模型,对地被覆盖物的卫星遥感图像进行语义级别的图像分割。GFormer 展现了基于注意力机制的语义分割算法极强的鲁棒性,全新设计的递进式特征融合结构编码器在遥感图像分割中也具有更强的解码能力。虽然本文方法在模型规模基本不增加的情况下提升了卫星遥感图像分割能力,但模型的编码器规模仍然占比较大,如何在保证分割表现的情况下进一步减小解码器规模是接下来的工作重心。
