基于半监督引导的网络APT检测知识图谱构建
2023-09-15王梦瑶杨婉霞王巧珍
王梦瑶,杨婉霞,王巧珍,赵 赛,熊 磊
(甘肃农业大学 机电工程学院,甘肃 兰州,730070)
0 引言
近年来,网络安全威胁已经发生翻天覆地的变化,运用先进的攻击方法对某些机构进行持续性、针对性的网络攻击,造成高级持续性威胁(Advanced Persistent Threat,APT)已逐渐引起国内外研究者的重视[1]。不同于传统网络攻击手段,APT 的攻击目标从常见的中断服务转为窃取目标知识产权和敏感数据,具有阶段性强、持续时间长、攻击路径多样化等特点[2]。例如,BlackEnergy 木马攻击的前、中、后期分别使用BlackEnergy、BlackEnergy 2、BlackEnergy 3 逐渐增强的木马病毒,以邮件、文档等多种路径攻击目标。
2015 年,海莲花组织对多个不同国家的科研院所、政府、海事机构等重要部门发起APT 攻击,造成了严重的损失[3]。2016 年,APT 28 组织入侵DNC 邮件系统,造成了严重的数据泄露。同年,Apple 公司首次披露利用IOS Trident 漏洞进行的APT 攻击[4]。2018 年底,新加坡遭受了历史上最严重的APT 攻击,造成包括李显龙总理在内约150万人的健康数据被泄露[5]。据360 天眼实验室发布的《2015 中国高级持续性威胁(APT)研究报告》可知,中国是遭受APT 攻击的主要受害国,全国多个省市均受到不同程度的攻击。其中,北京、广东是重灾区,工业、教育、科研领域和政府机构均受到APT 攻击者的重点关注。
然而,目前仍有大量APT 攻击未被发现,而他们通常已存在较长时间,入侵了很多主机,在被发现前就已经造成了巨大损失,这说明目前APT 攻击检测手段仍然相对滞后,对APT 攻击的响应能力不足。为此,大量学者对APT的攻击开展了深入研究,在检测技术和方法方面已取得不少成果。常见的APT 检测技术与方法主要包括以下3种:
(1)网络流量分析。该技术通过Netflow 或DNS 流量规律进行基线学习与分析以发现异常,但样本获取与相关性分析的难易程度将影响模型准确度。同时,部分研究人员利用数据挖掘与机器学习方法提取正常、异常的行为特征,对未知流量进行分类以提升异常攻击检测率,但无法从根本上解决样本获取的难题。
(2)负载分析(沙箱)。该技术首先模拟运行环境,通过捕获的样本在虚拟环境运行过程中的行为来提取特征,以显著提升特征匹配时效性,但目前沙箱逃逸功能已普遍存在于高级样本中,沙箱效果也大打折扣。
(3)网络取证。该技术通过抓取大量流量报文或日志,通过对安全日志的行为进行建模,将偏离正常行为视为异常,以此检测多步攻击。由于该方法可较好地还原样本与攻击过程,在回溯与应急响应方面价值较高,因此广泛运用于各种新型安全管理系统,但建立完善的攻击模型是系统的关键,因此依然面临着需要精确分析网络流量的问题。
鉴于现有方法存在的问题,最新研究提出构建多源异构APT 攻击大数据知识图谱,通过APT 事件—组织动态关系模型和时间序列演化模型,解除理想样本空间和攻击模型的限制,进而解决APT 攻击检测这一难点问题。
为此,本文采用基于深度学习级联模型结构的新型APT 知识获取方法,解决目前在APT 样本获取方面存在的问题。首先,通过半监督bootstrap 的知识融合方法自动构建APT 知识图谱,进而解决多源异构的APT 数据。然后,采用基于BERT(Bidirectional Encoder Representations from Transformers)+BiLSTM+Self-Attention+CRF 的APT 攻击检测模型,解决APT 攻击实体识别方面存在的难点问题,进而精准构建APT 攻击检测的知识图谱。
1 相关研究
经过对APT 攻击特征的深入分析,研究者发现APT 攻击检测的相关算法主要依赖专家领域知识。例如,Alshamrani 等[6]采用白名单方法,通过学习和对系统正常行为进行建模,从而检测异常行为并发现APT 攻击。Jedh等[7]利用连续消息序列图的相似性,通过挖掘未知异常模式来检测APT。
在基于安全日志的APT 攻击研究中,大多数算法通过建模APT 攻击实现检测[8]。例如,Zou 等[9]建立APT 攻击模型监控民航通信网,以发现实际攻击过程中的模式。Milajerd 等[10]构建基于杀伤链的攻击树模型,关联分析安全日志后生成攻击路径,进而预测下一步攻击行为。Zimba 等[11]首先采用IP 地址关联方法进行聚类,然后利用模糊聚类关联方法构建APT 活动序列集,最后结合对抗时间策略,在较长的时间窗口内分析数据,进而实现在一段时间内检测多步复杂攻击,但该方法仍然依赖于专家知识。
APT 知识图谱呈现了网络威胁的知识资源及其载体,并对其中的知识及其相互关系进行挖掘、分析、构建和显示,有助于发现、挖掘多源异构网络威胁间千丝万缕的关系数据、隐藏信息,提升网络攻击威胁分析的准确性与及时性。因此,近期APT 检测研究侧重于结合最新的知识工程技术构建APT 知识图谱,运用大数据智能分析方法提升APT 检测准确率。Xu 等[12]基于知识图谱提出多领域安全事件关联性分析方法,利用不同领域中与安全事件内在相关的若干属性,建立异常事件与攻击行为间的因果关系。
在网络安全数据可视化交互技术的研究中,Palantir、Splunk 等外国公司在现有安全可视化的基础上,提出新的动态语义相关图分析方法和可视化查询分析方法,已成为网络威胁交互分析的新方向。
当前,在知识图谱构建的研究中,利用深度学习算法设计自动提取、融合知识及实体链接算法是研究的热点[13]。例如,基于深度学习网络的有监督关系抽取算法、实体链接等算法,避免了传统实体链接中手工构建特征的繁琐过程,取得的性能更优[14]。然而,该方法在理解复杂句子时仍存在许多局限性,需要进一步深入挖掘大规模多源异构数据中的多重关系和事件。由于攻击者主动引入干扰信息、IDS 等系统错误,将造成攻击事件的知识图谱存在大量垃圾信息。因此,需要使用一些先进的知识精化算法消除错误、验证一致性,但现有算法仅限于处理简单静态事件,对多源异构数据中复杂事件的处理能力有待提高。
目前,大多数本体推理算法均基于OWL 语言[15],这种大规模知识推理还处于实验室原型系统阶段,对具有复杂字符关系和事件关系描述的字符—事件知识图谱的高效推理支持有待进一步研究。Zhang 等[16]针对网络数据中的多类型实体问题,提出一种基于条件随机场和实体词汇匹配相结合的人名实体提取方法,在整个网络数据集上收集人员姓名,识别正确率、召回率分别为84.5%、87.8%。知识图谱关系抽取主要为了获取实体间的关系,以监督方法、半监督方法为主,目前研究成果较为成熟。Yang等[17]将多实例、多标签的学习机制引入实体关系抽取中,实体和一系列对应的标签是通过图模型及其潜变量进行整合,再经过实体训练进一步获得关系分类器。Cho 等[18]提出一种基于Bootstrap 算法的半监督学习方法来自动建模实体关系。
综上所述,知识图谱的构建技术近年来已取得迅速发展,世界上也出现了许多相关的研究结果,但在提取实体和关系方面仍然存在许多问题尚未解决。为了降低APT事件数据的特征提取和检测难度,首先通过GitHub 中获取的14 年数据构建了一个APT 攻击检测命名实体识别语料库;然后在相关研究中命名实体识别关系,在抽取模型Bert+BiLSTM+CRF 学习中加入Self-Attention 模块,以在原模型基础上进一步提升识别APT 攻击检测实体的准确性;最后研究APT 知识图构建系统的总体框架,侧重于APT 事件知识获取、知识融合等关键技术。
2 APT知识图谱构建
APT 攻击事件的知识图谱是与该事件相关的结构化语义描述。它不仅描述了事件的基本属性和攻击特点,还描述组织属性(包括攻击者、防御者和受害者组织)。
现有知识图谱技术主要针对开放领域的大规模网页、多媒体等非结构化海量数据,构建针对人和热点事件抽取实体的知识领域可视化映射图。APT 知识图谱相较于现有知识图谱的不同之处在于,从安全专家提取的威胁开源情报数据库、流量和日志规模数据中构建了一个知识图谱库。威胁情报知识库的主要文档包括样本扫描报告、动态分析报告、域名记录、IP 反查、Whois、组织机构、事件归属等,因此数据来源更多样化和异质化。此外,本文还建立了事件—组织—属性关系网络,统一描述攻击事件的静态和动态知识,提出了一种构建APT 攻击事件知识图谱的方法,包括风险事件知识提取、风险事件知识融合与提炼等。
2.1 APT攻击的知识图谱总体框架
APT 知识图谱的构建是从威胁情报中识别攻击事件、组织等,并针对某一攻击事件从中提取事件名称、攻击时间、攻击偏好、技术特征等信息,从而实现对实体属性的完整勾勒。针对攻击事件具有许多属性依赖性的特点(例如攻击工具与类型间的依赖性等),本文基于威胁情报文本数据集,提出一种深度学习与条件随机场学习相结合的方法提取实体;针对APT 情报数据多源异构特点,重点研究知识的自适应提取策略,解决目前源异构数据提取方法通用性差、多类型数据提取召回率低的问题。
因此,多源异构威胁情报知识库中提取的信息结果,必然包含大量冗余信息、冲突信息和互补信息,数据间存在关系扁平、缺乏层次性的问题,必须通过实体消歧和知识融合技术进行知识精细化。传统实体链接方法依赖手动定义实体和实体上下文相关特征,生成候选实体和实体间的特征向量,并通过向量间的相关性获得实体链接结果,这其中存在与数据分布相关的人工定义特征、不同场景下有限的特征泛化能力等问题。
为此,本文利用深度学习对文本中词和知识库的实体进行联合建模,自动学习词和实体的低维向量表示,并通过向量计算词和实体的相关性。该方法可减少手工定义特征向量的人力负担,解决特征向量稀疏的问题,提升知识实体融合模型的泛化能力。根据上述研究思路,由于APT 事件具有较强的知识专业性和数据多源异构性特征,本文设计的APT 事件知识图谱自动构建整体框架,将APT情报数据、日志数据、流量分析元数据作为构建APT 知识图谱的原始数据。首先对原始数据进行预处理;然后利用实体抽取技术,从预处理后的语料库中抽取APT 知识图谱实体;接下来抽取实体间的关系,构建、融合知识项,以形成APT 知识图谱库。APT 知识图谱的总体框架构建流程如图1所示。

Fig.1 Overall framework construction process of APT knowledge graph图1 APT知识图谱的总体框架构建流程
2.2 APT事件实体与关系抽取方式
APT 知识的实体与关系抽取技术是构建APT 知识图谱的关键技术之一,当前主要的知识获取方式是通过自然语言理解技术获取文本特征,利用机器学习获取APT 知识特征。首先利用实体抽取技术从最初的APT 威胁情报等数据中识别APT 知识实体;然后由APT 事件自动关联APT知识实体;最后利用知识实体间的关系构建APT 知识图谱。本文基于可识别动态语义的BERT 词嵌入和具有记忆的BILSTM 设计了神经网络分层模型,以抽取APT 事件的实体和关系。
面向词向量的APT 知识获取方法分层模型在保证召回率基础上,使得低层网络能尽可能识别APT 事件的知识实体,为后续提升实体识别准确率奠定基础。然后,将低级网络识别结果传递给包含注意力机制的高一层网络BiLSTM-Attention,以再次识别来自低层网络的信息,并将识别结果传递给条件随机场(CRF)模块。最后,输出识别结果中单一合法的实体。
若存在多个APT 事件实体的情况,需要将这些子结果再次传送至高层网络(BiLSTM-Attention)中进行识别,通过多层处理APT 威胁情报文本提升APT 知识实体识别的准确率,具体模型结构如图2所示。

Fig.2 Layered model structure for the extraction of APT knowledge entities图2 APT知识实体提取的分层模型结构
由图2 可见,分层模型底层采用BERT 模型结构。BERT 是一个预训练模型,可根据上下文语义语境编码动态词向量。其中,级联模型的高层网络是一种包含注意机制的结构,采用双向Transformer 编码结构,可直接获得全局信息;RNN 需要逐渐递进才能获取全局信息。因此,本文选用BERT 模型构建分层模型。
同时,为了获取APT 知识实体的具体信息,需将低层网络模型的输出作为高层网络模型的输入。BiLSTM 模型通过前向、后向传播参数获取上下时刻的信息,因此能更快速、准确地编码序列。编码单元的主要组成为Self-Attention 模块,计算表达式如式(1)所示:
式中:Q、K、V为输入词向量矩阵,用输入向量维数进行表达。
Self-Attention 模块根据上述关系来调整每个实体的重要性,为每个实体定义一个包含实体本身、实体与其他实体关系的表达方式,因此相较于单个实体向量全局性更高。Transformer 是基于Multihead 模式对模型聚焦能力在不同位置的进一步扩展,增添了Attention 单元的子空间表示,如式(2)、式(3)所示。
此外,基于BILSTM 融合的Attention 机制,能灵活学习APT 实体的上下文语义信息。BiLSTM 模型虽缓解了单向LSTM 造成的前后编码差异,但无法完美解决时序编码缺陷的问题,如果仅依赖时序输出,模型将难以正确识别APT 事件实体任务。因此,融合Attention 机制是为了关注不同上下文片段中涉及的语义及APT 实体间的关系,然后通过这种关系确定相关APT 事件的实体。
在级联模型中,高层网络构建部分BiLSTM-Attention仅考虑了上下文信息中的长序列问题,忽视了标签中的依附关系。因此,在APT 实体识别中存在标签无法连续出现的问题,APT 的物理边界仍然存在争议。由于在标签决策中,模型无法独自通过隐藏状态完成,需要思考标签间的上下关系来获取全局中的最佳标签,但可通过条件随机场来完成,它可在输出级别时分离相关性。
因此,级联模型中高层网络的输出结果,将利用更深的CRF 网络建模标签序列以纠正错误标签,从而得到更可靠的标签序列。根据上述知识获取算法模型,通过Softmax函数进行激活的全连接层计算分类概率,如公式(5)所示。
其中,WT、bT为可训练参数为第ith个实体类别的概率向量。实体分类任务的损失函数如公式(6)所示。
显然,这数十页“神言”不仅是所谓艺术技巧突出,更重要的是它说出了来自彼岸世界的信息,故而与此岸世界的生活景象难以顺利对接。 这种观点与《托尔斯泰和陀思妥耶夫斯基论艺术》中的观点完全一致,只不过“神言”的数量由七八十页减少到二十至五十页罢了。 罗扎诺夫说:
式中:、分别表示第ith个实体的真实类别标签和实体分类器预测的第ith个实体类别的分布。
2.3 APT知识融合算法
本文提出了一种基于半监督的Bootstrapping 知识融合技术。首先,利用知识提取算法得到由三元组表示的APT知识项;然后,利用知识融合技术构建APT 知识图谱。由于提取的信息存在高度碎片化、离散化、冗余和模糊现象,因此将未融合的信息碎片视为各自的APT 知识图谱,利用实体对齐和实体链接达到融合多个APT 知识图谱的目的。
目前,实体对齐问题的方法包括本体匹配与知识实例匹配。其中,本体匹配法主要解决APT 知识实体对齐问题,通常由基本匹配器、文本匹配、结构匹配、知识表示学习等方法组成,根据APT 知识图谱的现实需要,通过知识图谱的表示学习技术达到实体对齐目的。
本体匹配方法利用机器学习中的表示学习技术,将图中实体和关系映射为低维空间向量,利用数学表达式计算实体间的相似度。首先将知识图谱KGb、KGe映射到低维空间,得到相应的知识表示,分别记为KGb0和KGe0;然后在此基础上,通过人工标注的实体对齐学习数据集D,即实体对间的对应关系为φ:KGb0↔KGe0。知识实体(APT 攻击关键词和同义词)的对齐过程如下:
步骤1:选择种子实体。遍历、选取待融合的多个知识图谱KGe中的所有实体ee。
步骤2:预处理种子实体。
步骤3:通过动态索引技术索引属性。
步骤4:采用精简过滤方法剔除相似度低的实体,构造对应的实体对(eb,ee),即现有知识图谱KGb中实体集结合的节点。
步骤5:使相似度较高的实体对分布在多个块中,并作为候选对齐实体对。
步骤6:通过匹配算法进行评分,例如基于属性相似度和结构相似度的聚合模型学习方法。
步骤7:根据评分结果进行排名,排名越低的实体对表示两个实体间对齐程度越高。
步骤8:采用基于图相似性传播的引导程序迭代对齐方法,选择与种子实体置信度高的匹配实体对达到实体对齐,进而有效整合APT 知识。
3 实验与结果分析
3.1 实验环境
本文实验环境为:Intel(R)Core(TM)i7-8750H CPU @ 2.20 GHz,GPU NVIDIA GTX 1050Ti,磁盘大小为2 TB。实验开发语言为Python,编译器为Pycharm,采用Tensorflow 深度学习开发平台。
3.2 测试数据语料库
本文使用数据来自Github,整理了2006-2020 年不同来源的APT 事件报告。其中,APT 事件报告数据的大小约16.4 GB,APT 相关实体约9 200个,如表1所示。

Table 1 Data set表1 数据集
由表1 可知,APT 报告多为非结构化数据,部分报告仅包含了攻击过程中的详细描述及攻击活动造成的影响,并未包含实验中所需事件信息样本。因此,基于上述数据特征,有必要处理APT 事件的样本数据。首先人工提取实验所需相关事件样本,然后将提取的事件信息样本进行序列标注,最后将处理后的数据作为实验主要数据,进一步构建APT 知识图谱语料库。
语料库中包括APT 攻击组织、攻击类型、攻击时间、攻击事件和攻击目的等实验所需事件信息样本信息。例如,The Dropping Elephant 事件是由于东南亚和南海问题,针对美国在内各国政府和公司发起的攻击行为。在准确提取APT 事件特征前,需对文本进行序列标注,以更好地提升模型训练性能。序列标注中最关键的步骤是为数据赋予标签,通常会使用简单的英文字母为词语赋予标签,常用数据集标注方法包括BIO、BIOES、IOB 等。本文使用目前最流行的BIO 标注方法进行标注,该方法首先使用YEDDA 工具对预处理后的APT 攻击事件文本语料库进行手动标注,然后编写Python 脚本处理标注后的数据,得到基于BIO 注释的APT 事件文本数据序列。
针对APT 事件特征,对文本的实体定义了攻击组织(Organization)、攻击目的(Purpose)、攻击目标(Target)、攻击类型(Type)、攻击工具(Tool)、攻击媒介(Medium)、攻击事件(Event)、攻击时间(Time)8 种类型。其中,8 个实体类别的元素标注中B-XX 表示实体开始,I-XX 表示实体中间或结尾,O 表示定义实体之外的实体。通过BIO 标记方法定义每个实体类别的标签,得到满足词向量生成层的输入语料库标准,最后将语料库中训练集、测试集及验证集按照6∶2∶2的比例进行划分。
3.3 模型性能分析
本文模型输入数据为APT 威胁情报、事件报告等文本数据,通过神经网络的分层模型抽取文本数据的实体和关系,从而构造三元组知识条目,目的是从输入文本的非结构化数据中提取APT 的基本属性,例如攻击特点、攻击工具等。APT 组织为与事件相关的黑客组织和检测组织,例如国家、实体组织、黑客组织等。APT 知识实体关系包括事件关联关系,例如APT 攻击工具的更新或攻击类别的延伸。同时,模型还提取APT 事件行为属性、组合流量特征和攻击场景特征信息。为模型性能评估,本文选择准确率、召回率和F1 评估实体关系抽取算法的性能,模型参数设置如表2所示。

Table 2 Main parameters of knowledge extraction algorithm model表2 知识提取算法模型主要参数
3.3.1 Batch_size值因素
参数Batch_size 值决定下降方向,在合理范围内增大Batch_size 值既能提升内存利用率、矩阵乘法的并行化效率,还会增加下降方向的准确性。例如,BIGRU+CRF 模型的Batch_size 值不同,样本数量会对模型性能产生一定影响。
本文将Batch_size 值设定为8 和16 进行比较实验,具体数据如表3 所示。由此可见,当样本数量小于样本1 时(样本数量为300 个),Batch_size=8 的模型性能更优;当样本数量增大到样本2 时(样本数量为440 个),Batch_size=16 的模型性能更优;当样本数量为样本3 时(样本数量为715 个),Batch_size=16 的模型性能更优。综上,模型在Batch_size=16 时性能最佳,因此设置Batch_size=16 进行后续实验。
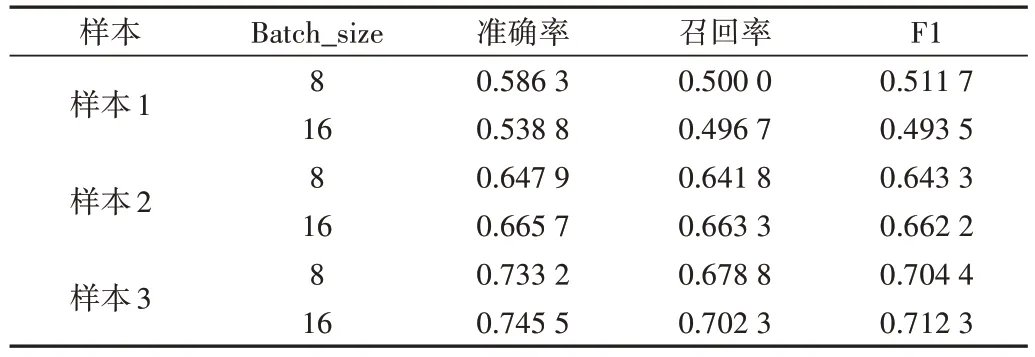
Table 3 Effect of Batch_size on model BIGRU+CRF表3 Batch_size对模型BIGRU+CRF的影响
3.3.2 数据集因素
GRU 为LSTM 的简化版本,擅长执行长期记忆任务,既能解决长期依赖问题,还可通过保留有效信息提取APT 威胁情报文本的APT 知识实体特征。BIGRU 的前向、后向传播过程类似双向长短期记忆神经网络,但性能受限于样本数量,即保持其他参数不变,当样本数量较少时,BIGRU 模型性能优于BILSTM,但在样本数量较多时,BILSTM 模型性能优于BIGRU。
由图4 可见,在Batch_size=16 时,当样本数量小于样本1 时,BIGRU+CRF 模型的准确率高于BILSTM+CRF 模型;当样本数量增加为样本2 时,BIGRU 的性能不及BILSTM;当样本数量为样本3 时,BILSTM+CRF 模型和BIGRU+CRF 模型性能均有所提升,但BILSTM 性能仍旧优于BIGRU。综上,若数据量较少时应使用BIGRU,当样本数量较大时应选用BILSTM 模型。
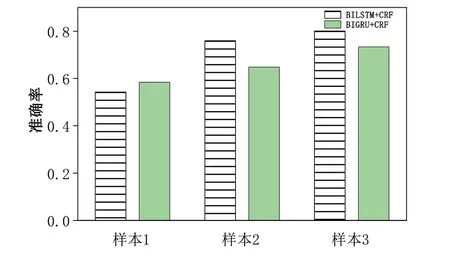
Fig.4 Impact of different datasets on model performance图4 不同数据集对模型性能造成的影响
根据上述结论,在后续实验中选取对模型性能最优的样本数量(样本3)为实验数据。其中,样本1 数量为300个,样本2数量为440个,样本3数量为715个。
3.4 模型性能比较
基于上述实验的数据集和算法,为了进一步验证Bert+BiLSTM+Self-Attention+CRF 模型在实体识别的优越性,将其与BiLSTM+CRF、BiGRU+CRF、Bert+CRF、Bert+Bi-GRU+CRF 和Bert+BiLSTM+CRF 模型进行比较,结果如表4所示。同时,从Bert+BiLSTM+Self-Attention+CRF 算法模型中分别增加、去除或替换不同的模块进行消融实验,以验证知识抽取模型中不同模块各自的优势。

Table 4 Model performance comparison表 4 模型性能对比
由表4 可见,Bert 模块能显著提升算法性能,原因为Bert 层采用了Masked LM、Next Sentence Predictio 两种方法分别捕捉词语和句子级别的representation,模型在Bert 层捕获全局上下文信息并对数据进行预处理,体现了Bert 层在捕获全局上下文信息方面的有效性。由Bert+CRF、Bert+BiLSTM+CRF 模型可知,去除BiLSTM 层后知识获取算法的准确率有所降低,因为通过堆叠的LSTM 层生成的上下文字符表示难以较好地建模上下文间的依赖关系。此外,由Bert+BiLSTM+CRF、Bert+BiLSTM+Self-Attention+CRF 模型可知,加入注意力机制后能提升模型的知识提取性能,原因为注意力机制的记忆网络可将上下文感知信息整合到神经模型中,以帮助神经模型准确识别稀有实体和上下文相关实体。
实验表明,Bert+BiLSTM+Self-Attention+CRF 模型在验证集上的结果最优,F1 值可达82.50%,证实了Bert+BiLSTM+Self-Attention+CRF 模型中各功能模块的有效性。本文还研究了模型F1、准确率及召回率随epoch 值增加发生的变化,如图5所示。

Fig.5 Trend of Bert+BiLSTM+Self Attention+CRF model changing with epoch图5 Bert+BiLSTM+Self-Attention+CRF 模型随epoch变化的趋势
由图5 可见,在第6 个epoch 值后,本文模型的F1、准确率及召回率均趋于稳定,说明此时模型参数基本为最优值,证实了Bert+BiLSTM+Self-Attention+CRF 模型在知识识别算法稳定性中具有较好的性能。
4 结语
本文研究了构建知识图谱检测APT 的关键技术,包括知识提取和融合,根据攻击事件的诸多属性和APT 情报数据的多源异质性,提出一种深度学习与条件随机场学习相结合的知识提取方法,重点解决了知识的自适应抽取问题,提升了知识抽取的召回率。
同时,针对APT 情报数据冗余信息较多、信息冲突显著的特点。首先,通过实体消歧、知识融合技术精细化知识;然后,利用深度学习对文本的词、知识库的实体进行联合建模,以自动学习词和实体的低维向量表示;最后,通过向量计算获得词和实体的相关性,以减少人工定义特征向量的开销,解决特征向量稀疏的问题,提升知识实体融合模型的泛化能力。
本文在不同样本数量、Batch_size 值的实验参数下,与其他模型进行比较测试的结果表明,Bert+BiLSTM+Self-Attention+CRF 模型在准确率、召回率、F1 值等方面表现更优。然而,本次实验均在同一个数据集下进行,后续将考虑利用更全面的APT 事件数据,以研究不同数据集对实验结果造成的影响。
此外,为了进一步提升APT 检测的准确率,考虑在现有模型基础上进行改良,构建更大、更完整的APT 知识图谱,加强知识图谱在网络安全防护中的应用。
