融合双通道语义特征的情感分析研究
2023-09-15刘司摇周艳玲兰正寅曾张帆
刘司摇,周艳玲,兰正寅,张 龑,曾张帆
(湖北大学 计算机与信息工程学院,湖北 武汉 430062)
0 引言
随着互联网高速发展与通信设备普及,各式各样的社交媒体平台通过网络被推送到生活中,越来越多的用户通过微博、淘宝等应用软件发表对新闻、产品的态度和评价[1]。情感分析的目的是从具有主观性的文本中提取用户情感,属于自然语言处理的基本任务之一[2]。通过情感分析这些评论文本数据,可获取用户对商品的评价或网民对社会新闻的态度,从而精准把握用户需求,调节产品市场方向;引导社会舆论向积极方向发展,避免负面事件进一步发酵。因此,通过情感分析网络交互信息中的用户观点与情绪极具商业价值和社会意义,如何在海量数据中挖掘有效信息,利用深度学习方法更好地捕捉深层次文本语义特征便具有十分重要的研究价值[3]。
目前,文本情感分析方法主要分为:①基于情感词典的情感分析方法[4],但情感词通常具有滞后性,因此通用性不足且耗时耗力;②基于传统机器学习的情感分析方法[5],该方法通过机器学习相关技术提取文本中的情感特征,建立训练模型后预测文本情感,但对特征提取质量的依赖性较大,难以达到满意的效果;③基于深度学习的情感分析方法[6],该方法通过模拟人脑结构,借助多层神经元自动提取、更新、优化特征,从而提升情感分析的准确度,现已取得了较好的性能[7-9],但如何利用深度学习方法抽取更深层次的文本语义特征仍然亟待解决。
本文为了提升中文文本情感分类效果,利用各模型优势捕捉多维度语义信息,增强文本向量表征能力,提出一种融合双通道语义特征(Fused on Dual Channel Semantic Features,FDSF)的情感分析模型。首先,将BERT 作为词嵌入层以获取文本词向量矩阵表示,将其输入BiGRU 来提取全局文本序列特征,并引入注意力机制分配特征向量权重;然后利用CNN 提取文本矩阵多个粒度下的局部特征,并将BiGRU-Attention 与CNN 输出特征信息进行向量融合;最后由全连接层Softmax 分类器输出文本的情感倾向。
1 相关工作
文本向量化是情感分析研究的关键环节,通过神经网络对文本构建词向量矩阵,让机器理解文本语义,对情感极性的判断具有重要的研究意义。常用的词向量表示方法包括One-hot 编码[10]、Word2vec[11]、BERT、Glove[12]等。其中,Glove 词嵌入模型同时考虑了文本的局部和整体语义信息,结合了LSA 与Word2vec 的优点,提升了模型训练速度和分类准确度,但构建的静态词向量仍然无法解决相同文字在不同语句中的一词多义问题。
为此,Google 提出采用双向Transformer 编码器的语言表示模型BERT(Bidirectional Encoder Representations from Trans-formers)。Devlin 等[13]通过BERT 模型预训练的文本数据在11 个自然语言处理任务上获得了较好的效果。王宇晗等[14]提出一种基于BERT 的嵌入式主题模型,在主题多样性、建模时的一词多义等问题上表现优越,在大规模文本中能提取高质量、细粒度的主题词。Karimi 等[15]提出一种基于BERT 对抗性训练的新模型,利用对抗性训练完成情感分析中的特征提取、特征情感分类两个主要任务,研究表明在这两个任务中该方法相较于传统方法效果更优。此外,Pang 等[16]基于Transformer 双向编码表示(BERT),通过构造一个方面特征定位模型提出了一种有效的方面级情感分析方法。
随着情感分析研究深入,基于神经网络的深度学习模型受到了众多学者青睐,已广泛应用于自然语言处理领域中。常见的神经网络技术包括卷积神经网络(Convolutional Neural Network,CNN)[17]、循环神经网络(Recurrent Neural Network,RNN)[18]、门控循环单元(Gate Recurrent Unit,GRU)[19]等,以上模型可从文本中提取特征并不断优化,相较于传统机器学习方法无需繁琐的人工标注就能取得更好的效果,并能提取更深层次的句子级特征信息,在下游任务情感分析中的应用效果显著。Jelodar 等[20]通过长短时记忆网络(Long Short Term Memory,LSTM)分析新型冠状病毒的情感,揭示了利用公众舆论和适当的计算技术了解该问题并指导相关决策的重要性,准确度达到81.15%。
除了基于单一神经网络的深度学习算法,越来越多的研究人员考虑结合不同神经网络方法的优点组成混合神经网络的模型,并应用于情感分析。Ume 等[21]提出一种结合CNN 和LSTM 的深度网络,在Twitter 数据集上进行情感分析的结果表明,该模型优于单一机器学习分类器。Liu等[22]提出一种Bert-BiGRU-Softmax 的混合模型,利用BERT 模型作为输出层提取情感特征,以双向门控循环单元(BiGRU)为隐藏层计算情感权重,以注意力机制为输出层,准确率达到95.5%以上。
然而,基于单通道的混合神经网络模型往往会因融合加深网络层次,特征向量压缩损失更多文本语义信息,致使情感倾向发生偏差。基于双通道的混合神经网络模型由两个互不干扰的网络通道组成,充分利用了不同深度学习模型的优势,从多方面提取文本特征语义,在一定程度上降低了网络层次深度造成的语义信息损失。
2 FDSF模型
本文提出的FDSF 模型结构由输入层、BERT 词嵌入层、提取全局语义特征的BiGRU-Attention 层、提取多粒度下局部语义特征信息的CNN 层和语义向量融合输出层构成,如图1所示。

Fig.1 FDSF model图1 FDSF模型
2.1 词嵌入层
预训练模型BERT 以无监督方式,通过大量无标注的文本数据进行训练,得到具有文本语句情感性倾向的词向量。在不同下游任务中无需特意更改模型,只进行相对应的微调即可,相较于Word2vec、Glove、BERT 等常用的词嵌入模型,利用双向Transformer 编码器的多头注意力机制可捕获到更准确的语义信息,解决了相同字词在不同语境中的一词多义问题。
如图2 所示,BERT 模型利用双向Transform-er 编码器提取文本中的语义信息。其中,w1,w2,…,wn表示文本输入,通过多层Transf-ormer 训练得到对应的文本输出O1,O2,…,On。Transformer 编码器由多个编码器组成,每个编码器分为多头自注意力层和前馈层,自注意力层的主要作用是在捕获词向量时能考虑该单词与其他单词的上下文语义关联,有利于在深度学习任务中聚焦更重要的单词,加快训练速度。

Fig.2 BERT word embedding图2 BERT词嵌入
考虑到在复杂的任务中,自注意力机制层对文本的拟合程度不够,前馈神经网络的两个线性层能加强Transformer 的表达能力。因此,在进入解码器前,Transformer 编码器还会对输出进行残差连接和层规范化。
在预训练过程中,BERT 模型引入了两个任务,分别为遮蔽语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。其中,MLM 语言模型通过[Mask]掩码随机遮挡数据集中部分单词,然后让模型利用上下文预测被隐藏的单词,目的是为了更准确地捕捉单词表征;NSP 任务通过判断前后句子间的合理性来理解文本的构造。因此,BERT 预训练模型拥有优秀的语义表征能力,非常适用于情感分析任务。
2.2 CNN层
CNN 是一种由输入层、卷积层、池化层和全连接层4部分组成的一种深度前馈神经网络,因良好的特征提取能力被广泛应用于计算机视觉等领域,近几年也有越来越多学者将其应用于情感分类,如图3所示。

Fig.3 CNN local feature extraction图3 CNN局部特征提取
CNN 具有的局部感受野和权值共享优点,可减少模型训练参数,非常适合提取局部特征。因此,本文采用CNN提取局部文本情感特征信息。其中,卷积层通过卷积计算得到经过映射的特征,在池化层中深度学习模型通常采用最大池化对特征降维后得到一维向量,该一维向量可看为经过卷积层映射后得到文本数据的主要特征,最后全连接层将得到的特征进行连接。局部情感特征Fw的计算过程如式(1)所示。
式中:bc表示偏移项;W为卷积核;*为卷积运算;Xi:i+h-1表示从i到i+h-1 个词向量;f(·)为非线性激活函数。
2.3 BiGRU层
RNN 将文本序列按时间顺序依次输入网络中处理,结合单词前后关联进行特征提取,然而当文本序列长度过长时会造成梯度弥散和梯度爆炸问题,导致后期模型无法有效获取前向序列文本信息。门控循环单元作为RNN 的变体,结构中的重置门、更新门机制分别更新、重置文本序列,有效解决了RNN 在短序列文本上的瓶颈依赖问题,GRU 结构如图4 所示,前向传播的GRU 网络计算公式如式(2)—式(5)所示。

Fig.4 GRU network model图4 GRU网络模型
式中:σ为sigmoid 激活函数,将其函数值控制在(0,1)范围内;Wz、Wr均为GRU 网络的权值矩阵;ht-1为前一时刻的状态信息;ht为当前隐藏状态;为候选隐藏状态。
式(2)为更新门表达式,更新门决定了前一个时间状态信息传递到当前时间的状态信息程度,值越大说明前一时刻传递的信息越多;式(3)为重置门表达式,重置门控制丢弃前一时刻信息的程度,重置门值越小代表忽略越多。尽管GRU 能有效捕捉长序列文本语义信息,但单向GRU只能从前往后读取文本数据信息,导致其只能保留前向文本特征。因此,在前后文语义关联较强的文本中,单向GRU 无法较好地提取语句中的隐藏信息。
为了准确捕获文本情感倾向,FDSF 模型采用双向门控单元(BiGRU)提取文本序列特征。BiGRU 由两个反方向的单向GRU 组成,能同时保留过去、未来文本语义特征,可结合上下文更准确地预测当前内容。如图5 所示,在BiGRU 网络中,设t时刻计算的前向输出为,后向输出为,将双向输出拼接融合得到最终输出。
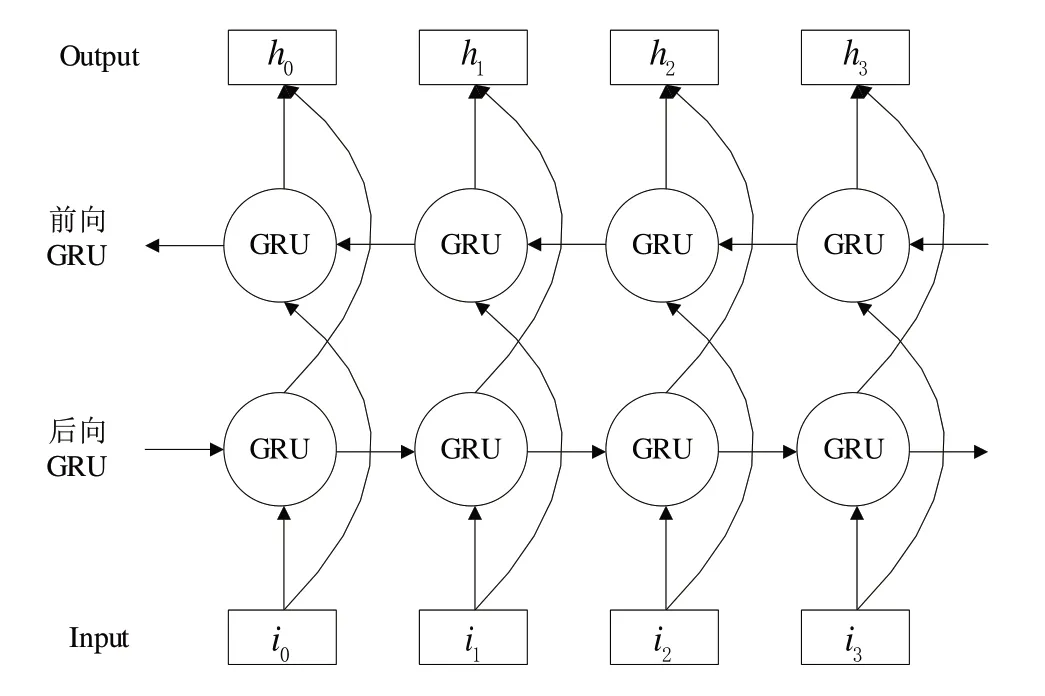
Fig.5 Bidirectional GRU network model图5 双向GRU网络模型
2.4 Attention层
考虑到文本情感分析中每个字词对整个文本的情感倾向贡献度不同。本文为了强调关键信息在全文中的作用,通过FDSF 模型将BiGRU 最后时刻的隐藏层作为全局语义特征表示,并加入自注意力机制。注意力机制根据每个单词在全文中的相关程度分配权重,最终的输出即为BiGRU 输出向量的加权和[23]。具体数学计算公式如式(6)所示:
式中:Wω为权值矩阵;bω为偏置项;at为t时刻经过归一化处理得到的权重;Fc为经注意力机制加权后最终的全局语义特征信息。
2.5 融合输出层
首先将经过CNN 通道获取的局部情感特征Fw和经过BiGRU-Attention 通道获取的全局情感特征Fc进行拼接融合,得到最终的融合情感特征。然后,将融合情感特征通过全连接层输出Softmax 分类器运算得到最终分类预测概率。
式中:Ws为全连接层的权值矩阵;bs为偏置项。
3 实验与结果分析
3.1 实验环境
本文测试模型采用版本为Python+Pytorch1.9.0 深度学习框架,实验环境为Google 提供机器学习服务器Colaboratory,内置GPU 为NVIDIDA Tesla T4-16 G。
3.2 实验数据集
为验证FDSF 模型在中文情感分析任务上的有效性,本文使用ChinaNLPcorpus 组织提供的中文情感分析数据集online_shopping_10_cats 和中科院谭松波学者收集的酒店评论语料数据集进行比较实验。其中,online_shopping_10_cats 为ChinaNLPcorpus 组织公开发表的情感分析数据集,包含10 种线上交易情感数据,包括正面、负面情感两种倾向,共计62 773 条数据(正向情感样本31 727 条,负向31 046条),本文按照7∶3的比例划分正负情感样本;酒店评论数据集包含正倾向性情感7 000 条,负倾向性情感3 000条,本文设置训练样本9 000条,测试样本1 000条。
为验证模型的有效性,将本文所提方法与GRU 模型[19]、BiGRU 模型[24]、TextCNN 模型[17]、AEN-BERT 模型[25]、DPCNN 模型[26]、BERT-base 模型[13]这些主流深度学习分类模型进行比较。具体的,GRU 模型使用单向GRU网络提取文本序列特征,将最后时刻隐藏层输入全连接层进行情感分类;BiGRU 模型采用双向GRU 网络结合上下文语义信息,增强模型在文本序列上的特征提取能力;TextCNN 模型通过卷积层提取文本情感特征,运用最大池化提取最重要的情感特征,最后输入全连接层进行情感分类;DPCNN 模型通过加深网络以增强文本情感特征提取能力,达到提升金字塔结构分类性能的目的;BERT-base模型以BERT(基于Transformer 的双向编码模型,具有强大的语义表征能力)为预训练模型获取文本动态词向量后链接全连接层,然后将其输入Softmax 分类器中输出最终情感倾向;AEN-BERT 模型利用标签平滑方式在一定程度上解决了模糊情感文本的极性判断,通过融合注意力机制对方面词进行建模。实验参数设置如表1所示。

Table 1 Experimental parameters表1 实验参数
3.3 评价标准
本文通过准确率(Accuracy)、精确率(Precision)、召回率(Recall)与F1 值作为评价标准,如式(10)—式(13)所示,指标计算的混淆矩阵如表2 所示。其中,TP 为预测为正的正样本,FP 为预测为正的负样本,FN 为预测为负的正样本,TN 为预测为负的负样本。

Table 2 Confusion matrix表2 混淆矩阵
3.4 实验结果及分析
为验证FDSF 模型的在情感分析任务上的可靠性,避免出现偶然性结果。首先对epoch 进行10 次循环后采集数据测试集的准确率、精确率、召回率和F1 值,然后求均值进行比较验证。online_shopping_10_cats 数据集和酒店评论数据集上的实验结果如表3、表4 所示。由此可知,本文提出的FDSF 模型在中文情感分类任务上相较于其它深度学习模型,在各项评级指标方面均最优。其中,各模型的F1值柱状图如图6所示。

Table 3 Experimental results of online_shopping_10_cats dataset表3 online_shopping_10_cats数据集上的实验结果(%)

Table 4 Experimental results of hotel reviews dataset表4 酒店评论数据集上的实验结果(%)
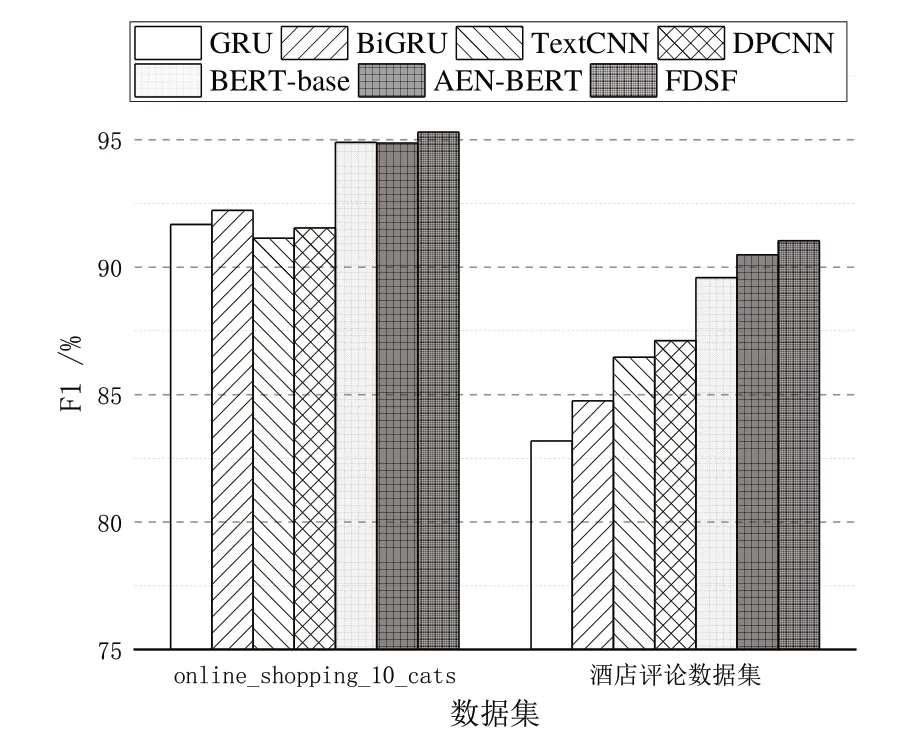
Fig.6 F1 value histogram analysis图6 F1值直方图分析
由图6 可见,FDSF 模型在文本情感分析任务上性能良好,BiGRU 在两个数据集上的F1 值相较于GRU 分别提升1%~3%,验证了双向门控循环机制在全局语义特征提取方面的优势。基于BERT 的3 类模型的各项指标均明显优于GRU、BiGRU 和TextCNN 模型,说明预训练模型提取的动态词向量具有更好的语义表征能力,这也是FDSF 采用BERT 预训练模型作为双通道词嵌入层的原因。
虽然,AEN-BERT 方法的F1值接近本文模型,但FDSF在两个数据集上相较于AEN-BERT 方法分别提升0.43%、0.65%,进一步说明了FDSF 模型通过提取、融合多粒度下的局部和全局语义特征,能有效提升模型性能。
3.5 消融实验
本文设计消融实验,以验证FDSF 模型中各层结构对模型的有效增益情况。其中,FDSF-CNN 为采用全局语义特征通道进行情感分析的模型;FDSF-BiGRU-Att 为原模型减去BiGRU 结构和注意力机制后的模型,词嵌入后利用CNN 提取多粒度下的局部语义特征进行分类;FDSF-Att为原模型减去BiGRU 结构后的注意力机制层模型,实验结果如表5所示。
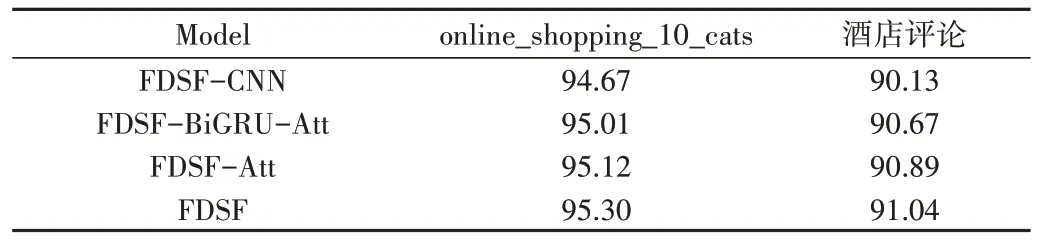
Table 5 Ablation experiment results表5 消融实验结果(%)
由表5 可知,上述消融模型相较于BERT-base 模型在两类数据集上的F1 值均具有一定提升,说明BiGRU、CNN和注意力机制融合BERT 均能效提升模型语义特征提取能力。实验发现,FDSF 相较于结合门控循环单元与注意力机制进行全局语义特征提取的FDSF-CNN 模型、结合CNN进行局部语义特征提取的FDSF-BiGRU-Att 模型,在性能方面具有一定程度的提升,表明FDSF 模型通过双通道融合特征向量的方式能提升模型性能。FDSF-Att 与FDSF 结果相差0.18%,说明在保持双通道结构的前提下,融入注意力机制能为模型性能带来增益。
综上所述,FDSF 模型通过双通道方式融合BERT、Bi-GRU、Attention 机制、CNN 模型的优势,能显著提升模型在情感分析任务上的性能,充分提取文本语义特征信息以深入分析情感倾向。
4 结语
本文针对文本情感分类问题,充分结合了BERT、CNN、BiGRU 模型与Attention 的优势,提出融合双通道语义特征的情感特征模型。首先采用BERT 预训练语言模型提取文本情感特征的动态表示,并将其分别输入两个通道进行下游分类任务;然后在CNN 通道中提取局部情感特征,在BiGRU-Attention 通道中提取全局情感特征;最后加权融合两个通道特征,并输入Softmax 分类器得到最终结果。
在online_shopping_10_cats、谭松波酒店评论数据集上,与其他深度学习分类模型进行比较实验的结果表明,FDSF 模型在准确率、精确率、召回率、F1 值均最优,证明了FDSF 模型在文本情感分析任务中的有效性和优势。然而,考虑到通过双通道特征融合时会损失部分特征信息,未来将探究如何选择性地保留更多关键特征信息,寻求更优的融合方式获得更准确的情感倾向。
