基于权重词向量与改进TextCNN的中文新闻分类
2023-09-15黄树成
万 铮,王 芳,黄树成
(江苏科技大学 计算机学院,江苏 镇江 212114)
0 引言
文本分类是自然语言处理领域的一项基础且重要的任务,在新闻推荐、搜索引擎、垃圾邮件检测等方面都有着重要应用。尽管文本分类已经有着多年的发展历史,但仍存在着一些不足之处。目前文本分类仍是自然语言处理领域研究的一个热点问题。文本分类是指通过一定的算法,给输入的文本分配一个或多个预先设定好的标签[1]。若只为每个文本分配一个标签,则称为单标签文本分类;若为每个文本分配一个及以上的标签,则称为多标签文本分类。
随着信息技术的快速发展,人们进入了一个信息爆炸的时代,互联网已经成为人们日常生活中获取信息的主要途径之一。其中绝大部分信息都是以文本形式存在的,面对着铺天盖地的文本信息,光靠人力维护是不可能的。那么如何通过机器自动将这些文本信息进行分类以方便人们更好地获取,成为当下的一个研究难题。人们最先把机器学习方法用于文本分类,如改进的TF-IDF、支持向量机[2]、朴素贝叶斯[3]等。传统的机器学习分类方法将整个文本分类问题拆分成特征工程和分类器两部分。特征工程分为文本预处理、特征提取、文本表示3 部分,最终目的是把文本转换成计算机可理解的数字,并封装足够用于分类的信息,再进行分类[4]。虽然这些方法在一定程度上解决了文本分类问题,但仍存在着一些弊端。这些方法过于依赖人工设计的特征,并且对于文本的表示还存在数据稀疏和特征向量纬度过高的问题,对于网络新闻中出现的大量新词不能很好地表示其语义特征。
随着深度学习技术的不断发展,涌现出越来越多性能良好的深度学习模型。这些模型不仅能很好地解决传统机器学习方法存在的数据稀疏和特征向量维度过高的问题,而且准确度也明显提升。但是单一的深度学习模型也有其局限性,如TextCNN 只关注到了局部信息,而往往会忽略掉全局语义,造成分类效果不佳。基于此,本文提出一种混合多神经网络的BA-InfoCNN-BiLSTM 模型。
1 相关工作
若想要让计算机处理语句或文档,首先需要将这些语句或文档转换成数字,将字或词转换为向量的过程称为词嵌入。最开始采用One-Hot 编码,用于判断文本中是否具有该词语。后来发展成根据词语在文本中的分布情况对词进行表示。近年来,随着深度学习的发展,直接推动了词嵌入技术的变革,使得分布式的词语表达得到了大量使用。分布式表示可以克服独热表示的缺点,解决了词汇表示与位置无关的问题。分布式表示通过计算向量之间的距离(欧氏距离、余弦距离)体现词与词之间的相似性。Bengio 等[5]最早使用神经网络来构建语言模型。2013 年,Mikolov 等[6]提出一种浅层神经网络概模型Word2Vec,其包括Continuous Bag-of-Words[7]和 Skip-Gram[8]两种模型训练方法,通过分布式假设(如果两个词的上下文是相似的,其语义也是相似的)直接学习词的词向量,同时为了减少输出层的计算量,使用层次softmax 和负采样对其进行优化。但该方式只考虑了文本的局部信息,未能有效利用整体信息。针对此问题,Pennington 等[9]提出全局词向量(Global Vectors,Glove)模型,同时考虑了文本的局部信息与整体信息。但无论是Word2Vec 还是Glove,本质上都是一种静态的词嵌入方式,无法解决一词多义的问题。2018年,谷歌提出的BERT 模型解决了一词多义的问题[10]。BERT 模型通过联合调节所有层中的左右上下文来预训练未标记的文本深度双向表示,此外还通过组装长句作为输入,增强了对长距离语义的理解。
在捕获文本特征方面,Hochreiter 等[11]提出的长短时记忆神经网络解决了梯度爆炸和梯度消失问题;Kalchbrenner 等[12]提出动态卷积神经网络模型处理长度不同的文本,将卷积神经网络应用于NLP;Kim[13]提出文本分类模型TextCNN,该模型结构更简单,利用多个大小不同的卷积核提取文本中的特征,然后对这些不同粒度的特征进行池化操作,从而得到更准确的局部特征;陈珂等[14]利用多通道卷积神经网络模型,从多方面的特征表示学习输入句子的文本信息;Long 等[15]将双向长短时记忆网络与多头注意力机制相结合对社交媒体文本进行分类,克服了传统机器学习中的不足。本文在前人研究的基础上,通过融入前文信息对传统的TextCNN 作出了改进。
2 模型设计
本文提出的BA-InfoCNN-BiLSTM 模型通过在词嵌入层后加入注意力机制进行残差连接来提升重要词的比重,再通过改进的卷积神经网络与双向长短时记忆网络分别提取局部和全局特征,最后将特征进行融合后用于分类。模型整体结构如图1 所示,由输入层、BERT 嵌入层、权重词向量层、改进的卷积层、双向长短时记忆网络层和输出层组成。
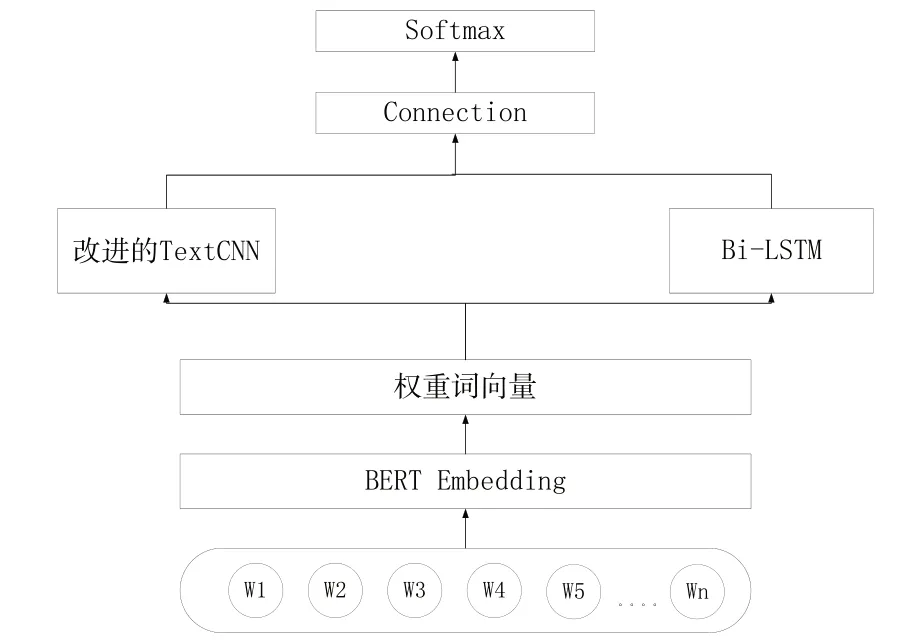
Fig.1 BA-InfoCNN-BiLSTM model structure图1 BA-InfoCNN-BiLSTM 模型结构
2.1 词嵌入层
本模型嵌入层的目的是将文本转化为词向量,首先需要解决的问题就是分词。对于英文文本,单词与单词之间本就以空格隔开,所以英文文本不需要进行额外的分词操作。与英文文本不同的是,中文文本是由字构成,字本身就可以表达出一定的含义,而字与字之间又可以组成词,表达出新的语义。如今两种比较流行的分词方式是:一是像英文文本分词那样,以字为粒度,直接将文本中的字映射为一个向量,这种做法虽然方便,但是往往会割裂文本中字与字所组成的词的意思;二是利用像Jieba 这样的分词工具先对文本进行分词,再将得到的词转化为词向量,但这种方式存在着更严重的弊端,因为分词的好坏会在很大程度上影响最后的分类结果。
如今的分词工具对于陌生词的分词效果较差,在专业名词上更是严重依赖于用户构建的词典,并且对长词的分词效果较差。而新闻标题中往往会产生大量新词,严重影响分词的正确性,从而干扰最后的分类效果。因此,模型使用基于字粒度的词嵌入方式来弥补该弊端。BERT 的中文版本正是以字为单位进行嵌入的,十分适合作为嵌入层。BERT 的两大功能分别是预训练和微调。预训练有两大任务:一是掩码语言模型,即随机遮掩一部分词,然后让模型预测这些词;二是下一句预测,即判断两个句子之间是否有上下文关系来增强模型对句子的理解能力。微调则是在进行下游任务时,模型不断调整其参数的过程,但由于BERT 的结构是由12 个Transformer 编码器构成,计算量较大,十分消耗时间,所以本实验过程中并没有选择进行微调,而只是使用在大规模语料上预训练过的BERT 模型参数完成字到词向量的转换。设有文本T={t1,t2,t3...tn},文本长度为n,将其送入BERT 模型,得到该文本的词向量矩阵E={e1,e2,e3...en}。矩阵大小是n*d,其中d 是每个字的维度。然后将BERT 生成的矩阵E作为注意力层的输入。
2.2 权重词向量层
本模型在BERT 之后引入注意力机制。注意力机制最早是由Bahdanau 等提出的,用于模拟人脑的注意力模型,最早用于图像处理方面。Vaswani 等[16]提出的Transformer便是基于自注意力机制获得单词间的长距离依赖关系。本模型之所以在嵌入层后引入注意力机制,是由于在嵌入层中只使用了BERT 在其他语料上预训练得到的词向量。但是为了避免大量运算,在实验过程中并没有进行微调,没有发挥BERT 中自注意力机制的作用,而在新的语义环境中,每个词在新闻标题中的重要程度也会有所不同。所以在得到词向量之后,需要通过注意力机制对字词权重重新进行分配,以体现不同词对文本全局语义特征的重要程度。注意力分数计算如式(1)所示。其中,Wa是可训练参数,ba是偏置项,tanh 是激活函数,va是可学习的上下文向量。at是经过softmax 函数后得到的ei的权重(见式(2)),然后将每个词向量加权后进行残差连接得到si(见式(3)),最后将得到加权的词嵌入矩阵S={s1,s2,s3...sn}分别送入改进的卷积层和Bi-LSTM 层。
2.3 改进的卷积层
在注意力机制之后引入改进的TextCNN 来提升模型对特征的捕捉能力。TextCNN 能够通过使用不同大小的卷积核实现对N-Gram 特征的提取,从而获取到不同层级的语义特征。但其短板是TextCNN 通过卷积只能获得文本的局部依赖关系,而忽视了远距离语义的影响。所以针对该问题,本模型对TextCNN 的卷积层进行了一些改进。从整体上而言,对语义的理解是以从左到右的顺序进行的,所以进行卷积操作的词之前的文本信息是十分重要的。为解决TextCNN 只关注局部信息的问题,在进行卷积操作的过程中,通过不断融入前文信息来提升模型性能。InfoCNN 过程如图2所示。

Fig.2 InfoCNN process图2 InfoCNN过程
首先根据词向量矩阵S={s1,s2,s3...sn}生成其前文语义矩阵R={r0,r1,r2...rn},如式(4)所示:
其中,r0为零向量,然后用全连接层进行降维,得到前文信息向量G={g0,g1,g2...gn}。接着再用窗口大小为2、3、4 的卷积核W 进行卷积操作,每次卷积操作得到特征ci,提取局部特征的公式如式(5)所示:
其中,h为卷积核Wh滑动窗口的大小,卷积核Wh的大小是h*d,d是词向量维度。Si:i+h-1为从S中第i行到i+h-1行的局部文本矩阵,bh为偏置项,f代表非线性激活函数。最后,结合提取的局部特征和前文信息特征,最终得到的卷积结果ui如式(6)所示:
最后,在得到的结果U中,采用最大值池化策略获取每个通道的最大值,将这些值送入最后的输出层。
2.4 BiLSTM 层
由于循环神经网络特别适合处理序列数据,已被成功应用于自然语言处理等众多时序问题中。为了能有效解决传统循环神经网络的梯度消失或爆炸问题,本模型使用Bi-LSTM 对BERT 和注意力机制得到的权重词向量矩阵进行特征提取。长短时记忆网络结构如图3所示。

Fig.3 LSTM structure图3 LSTM 结构
该网络有3 个门:一是遗忘门,用来控制上一时刻Ct-1保存到当前时刻Ct的特征信息,如式(7)所示;二是输入门,其控制了此时网络的输入Xt保存到当前时刻Ct的特征信息,计算方式如式(8)、式(9)所示;三是输出门,用来控制当前时刻Ct的输出值Yt,计算方式如式(10)—式(12)所示:
但由于长短时记忆网络当前时刻的输出信息是由前一时刻的输出信息和当前时刻的输入信息共同决定的,即当前时刻的输出信息只考虑了该时刻与该时刻之前的信息,而没有考虑该时刻之后的信息,没有充分利用上下文信息。为了解决这一问题,Graves 等[17]提出双向长短时记忆网络。双向长短时记忆网络通过正向和逆向的LSTM 获得第t时刻正向隐藏层状态向量Ylt与逆向隐藏层状态向量Yrt,并将Ylt和Yrt拼接起来作为最终的隐藏层状态向量Yt,该向量包含了上下文信息。计算方式如式(13)所示:
2.5 输出层
模型最后的输出层是把改进的卷积层得到的结果与Bi-LSTM 层得到的结果进行拼接融合,然后引入全连接层进行降维,之后用Dropout 方法让降维后的特征向量以一定的概率失活,从而避免出现过拟合现象。最后送入softmax函数[18]进行分类,得到最终的预测结果。
3 实验与分析
3.1 实验数据集
为了验证本模型在新闻主题文本分类任务上的有效性,本文使用两个以新闻为主题的数据集进行实验,如表1所示。

Table 1 Data set information表1 数据集信息
(1)新浪新闻数据集。新浪新闻数据集中的数据来自于新浪新闻2018—2022 年间产生的新闻标题。通过收集这些新闻标题,然后经反复筛选压缩及过滤后,整理生成新浪新闻数据集。该数据集共包含20 万条短文本,分为电子竞技、地产、体育、股市、科学、财经、时事、教育、政治、明星10个类别,每类包含2万条数据。
(2)搜狐新闻数据集。通过网络开源搜狐新闻数据集进行数据清洗,去除部分缺少标签的数据,并去除新闻内容,只保留新闻主题。数据集包含旅游、电子竞技、地产、军事、体育、股市、科学、财经、时事、教育、政治、明星共 12个类别。
3.2 实验设置
(1)实验环境。本实验在PyCharm 上进行代码编写,编程语言选择Python 3.7 版本,深度学习框架选择Pytorch 1.1 版本,CPU 型号为AMD EPYC 7302 16-Core Processor,内存为252GB,GPU 型号为GeForce RTX 3080,显存为10GB。
(2)实验参数。由于模型使用BERT 的中文版本进行词嵌入,所以词向量的维度设为768。卷积层中使用3 种大小不同的二维卷积核,卷积核的高度分别为2、3 和4,卷积核宽度与词向量维度相同,每种卷积核的数量为256。BiLSTM 层中的隐藏单元个数为128,dropout 的参数大小设置为0.1。每次训练的批次batch_size 大小为128,学习率大小为0.000 5,每句话的最大长度为32,epoch 数为3。
3.3 实验结果与分析
本文将BA-InfoCNN-BiLSTM 模型与当前较流行的几种分类方法进行了比较。
(1)TextCNN。由Kim[13]提出的TextCNN 在CNN 概念的基础上,让卷积核宽度与词向量维度保持一致进行特征提取,然后拼接最大值池化后的特征,最后送入softmax 函数进行分类。
(2)TextRNN。由Liu[19]提出的TextRNN 在LSTM 概念的基础上,取单向LSTM 最后一个时间步的隐藏层状态向量作为新闻标题的语义表示,然后将该向量送入softmax 函数中进行分类。
(3)DPCNN。由Johnson 等[20]提出的一种通过增加卷积神经网络的深度来获取长距离语义关系的模型。
(4)FastText。Facebook 于2016 年开源的一种文本分类方法,FastText 在保证与CNN 和RNN 等深层网络同等准确率的基础上,提升了训练速度。
(5)Att-BiLSTM。通过在双向长短时记忆网络后引入注意力机制,对双向长短时记忆网络提取的特征分配不同权重,从而突出重要词的作用。
(6)BERT。BERT 是一个多层双向的Transformer Encoder 模型,主要分为两个阶段:预训练和微调。在预训练阶段,模型会在大量没有标注的语料上进行训练;在微调阶段,模型会对预训练得到的参数进行初始化,然后在进行下游任务过程中对参数进行调整。
本文使用准确率作为评估指标,实验结果如表2、图4所示。

Table 2 Accuracy表2 准确率 %

Fig.4 Experimental results图4 实验结果
BA-InfoCNN-BiLSTM 模型在新浪新闻数据集和搜狐新闻数据集上分别获得了95.07%与84.95%的准确率。与前6 个模型相比,BA-InfoCNN-BiLSTM 模型取得了最好的效果。与6 个模型中效果最好的Bert 模型相比,BA-Info-CNN-BiLSTM 模型在新浪新闻数据集上的准确率提升了0.66%,在搜狐新闻数据集上的准确率提升了0.71%,从而证明了BA-InfoCNN-BiLSTM 模型通过在词嵌入后加入注意力机制补充词的重要程度,再分别捕获多粒度下的局部信息和全局语义信息,可以有效提升模型的准确率。
3.4 消融实验
为了验证BA-InfoCNN-BiLSTM 模型中不同组件对于模型的有效性,本文通过消融实验进行验证。BA-BiLSTM为原模型中去掉了改进TextCNN 层的模型,仅将BiLSTM最后一个时间步的隐藏状态向量作为全局语义特征用于分类输出。BERT-InfoCNN-BiLSTM 为原模型中去掉了注意力机制的模型,在嵌入层后使用改进的TextCNN 层和BiLSTM 层分别捕捉局部与全局特征,将两种特征融合后输出。BA-InfoCNN 为原模型中去掉了BiLSTM 层的模型,使用改进的TextCNN 层捕捉多个粒度下的局部语义特征并将其用于分类,同时将输出改为直接输出。BA-CNNBiLSTM 为了去掉原模型中对TextCNN 的改进部分,使用融合后的结果用于分类。消融实验结果如表3所示。
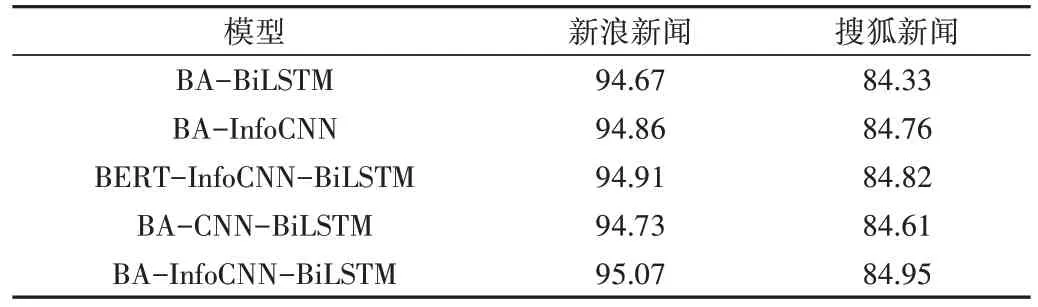
Table 3 Ablation experiment results表3 消融实验结果 %
首先将BA-BiLSTM 的实验结果与本文提出的BA-InfoCNN-BiLSTM(以下简称BAIB)进行对比,在两个数据集上BAIB 的效果都明显优于BA-BiLSTM,说明提取局部信息对分类结果有一定影响。将BA-InfoCNN 的实验结果与BAIB 相比,BAIB 的效果要优于BA-InfoCNN,说明BiLSTM能够有效提取全文信息特征,提升模型效果。BAIB 去除注意力机制之后的效果也不如BAIB,说明使用注意力机制凸出词在句子中的重要性对于提升分类效果也是很有必要的。最有意义的是,将没有改进的BAA-CNN-BiLSTM 融合模型与BAIB 进行比较,发现融入前文信息的卷积网络分类更准确,模型对文本语义的理解更充分。
4 结语
本文提出的文本分类模型BA-InfoCNN-BiLSTM 通过融合改进的卷积神经网络和循环神经网络,解决了传统的单一深度学习网络提取信息不充分、分类效果差的问题。相比于其他融合模型,本模型直接在词嵌入后加入注意力机制,生成权重词向量,突出重要词对整体语义的影响,然后分别送入卷积神经网络和循环神经网络,同时对卷积神经网络进行了改进。在进行卷积操作过程中融入部分前文信息,让卷积神经网络不再仅关注局部信息。最终的实验结果表明,该方法对分类的准确率有一定提升。接下来为了使模型得到进一步优化,可以从以下方面入手:考虑到文本进行分类时,文中存在较多干扰信息以及一些专业性较强的名词,可以在词向量动态训练过程中加入对抗扰动,以进一步提升生成的新闻文本词向量的鲁棒性以及表征能力。
