音视频编码AVS3关键技术及其在视频会议系统的应用探究
2023-09-14伍世峰曾磊
伍世峰,曾磊
中国人民解放军广西军区,广西南宁,530022
0 引言
随着社会的发展与进步,人们对信息交流的及时性、准确性和全面性要求不断提高,传统的视频会议系统存在诸多弊端,常常令会议沟通效果大打折扣。高清化、超高清、云化、VR/AR、全息投影等视频会议系统能够有效地解决这一状况,满足人们对高清晰的画面质量、同步音效和最低延时的期待,为与会者提供高效、高质量的视频会议交互系统体验。但是这些视频会议系统产生了海量的音视频数据,需要的传输宽带也进一步增大,以往的视频编码压缩效率已满足不了需求。因此,探索更加高效的音视频压缩编码标准在视频会议系统及多功能会议系统中的应用尤为重要。
传统的视频会议系统和远程监控系统常用H.264和AVS等压缩编码标准,取得了很好的压缩应用效果,但应用于新一代视频会议系统中已有些力不从心。目前,国际上最新一代视频编码标准是AVS3、VVC和AV1,它们是相似又独立的音视频压缩编码工具。它们的应用目标是8K及以上、VR、可动态配置编解码的产品,也包括传统的2D视频、视频点播、广播、视频会议、360°视频等。AVS采用统一许可方式,只收取少量费用,也不向内容使用方、内容提供方收费。本文通过基础块划分结构、帧内预测、帧间预测、变换量化、熵编码、环路滤波等方面简要介绍AVS3编码标准的关键技术;同时,介绍AVS3视频流通过RTP/RTCP协议在RTP/UDP/IP网络协议结构的网络中传输,探索音视频编码AVS3在视频会议系统的应用。
1 AVS3概述
AVS3是由数字音视频编解码技术标准工作组(简称AVS工作组)制定的新一代音视频编解码技术标准,属于AVS系列第三代音视频编解码技术标准,由系统、视频、音频、数字版权管理等四个主要技术标准和符合性测试支撑标准组成。AVS3在编解码效率方面有很大优势,适应多种位率、分辨率和质量要求的高效视频压缩方法的编解码过程,可广泛应用于电视广播、数字电影、网络电视、网络视频、视频监控、实时通信、即时通信、数字存储中。AVS3是全球第一个为面向8K超高清产业及虚拟现实视频产业应用“量身定制”的“智能化”音视频编码技术标准。
2 AVS3音视频编码关键技术
AVS3沿用了基于块的预测变换混合编码框架,其核心技术包括块划分、帧内预测、帧间预测、变换量化、熵编码、环路滤波等模块[1]。AVS3采用了新的编码工具,在编码过程中块划分方案更精细、预测算法更准确高效、变换模式适配性更好以及滤波算法效率更高。AVS3编解码框架如图1所示。
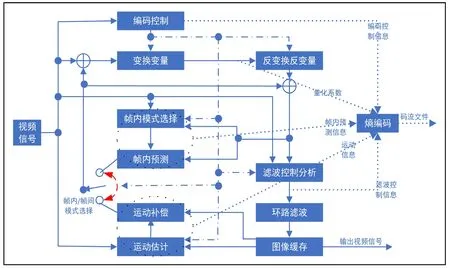
图1 AVS3 编解码框架
2.1 基础块划分结构
AVS3采用了字节跳动公司提出的QT+BT+EQT的基础块划分结构,该方案比在上一代标准(AVS2和HEVC)中采用的四叉树(QT)划分,即将一个编码单元(CU)划分为四个子编码单元(subCU)方案更加灵活,可以更好地支持各种分辨率的视频内容。AVS3中的编码树单元的大小可达128×128,并被划分为最少4×4块。AVS3基于QT方法引入了二叉树和扩展四叉树,这些分割方法引入了非方形CU,为块划分提供了足够的灵活性。其中,BT可以将一个CU划分为左右/上下两个subCU;EQT包含横向和纵向两种工字型划分方式,将一个CU划分为4个subCU。
2.2 帧内预测
帧内预测是去除空域冗余的重要工具,是利用视频空间域的相关性,使用同一帧图像内邻近已编码像素预测当前的像素,以达到有效去除视频时域冗余的目的。AVS3帧内预测继承了AVS1和AVS2的DC、Plane、bi-linear模式并扩展了角度模式。角度模式的范围不变,但数量增加到63个。像素位置的预测精度方面,AVS3使用多帧内预测滤波技术根据块内像素点的个数和所在位置,使用4组不同的平滑滤波器和插值滤波器生成预测像素。再由参考像素加权得到的预测值进一步通过帧内预测滤波(IPF)处理以提高预测精度,IPF使用相邻参考像素来调整当前预测值,对预测完的预测块边界的像素再次滤波,用于优化帧内预测块的边界,增加周围参考像素与当前预测单元之间的空间关联性,提升预测精度。AVS3还提出了两步色度帧内预测(TSCPM)和多交叉分量预测(PMC)来进一步去除不同颜色分量间的冗余[2]。
2.3 帧间预测
帧间预测是去除时域冗余的重要工具,是利用视频时间域的相关性,使用邻近已编码图像像素预测当前图像的像素,以达到有效去除视频时域冗余的目的,随着AVS标准的发展,越来越多的帧间预测工具被加入标准,主要可以分为三类:预测编码类型、运动信息编码工具、CU级和子块级运动补偿。AVS3沿用了传统帧间预测编码的思路,新增了多种编码工具,包括自适应运动矢量精度(AMVR)、基于历史信息的运动矢量预测(HMVP)、高级运动矢量表达(UMVE)、仿射运动补偿(AFFINE)。
2.4 变换量化
变换可以集中能量,利于熵编码进行系数压缩。AVS3采用了基于位置的变换技术,根据四叉树划分,将CU分成四个子块,每个子块根据其位置使用预先设计的变换核;同时,隐则变换(IST)和子块变换(SBT)引入了新型的转换核DST-Ⅶ和DCT-Ⅷ等,更好地聚集不均匀分布残差的能量,获得更好的能量压缩。最大变换块大小扩展到64×64,对于大平面块编码是有效的。
2.5 熵编码
AVS3标准采用基于扫描区域的系数编码(SRCC)方案对量化系数进行编码[3]。编码过程中,SRCC没有使用系数组概念,采用在扫描区域内进行反zig-zag扫描。首先对区域位置进行编码,然后按照反zig-zag扫描顺序对系数进行编码。扫描区域由x轴上最右边的非零系数和y轴上最下面的非零系数决定,只有扫描区域内的系数具有非零值,并从扫描区域的右下角按反zig-zag扫描顺序进行编码。
2.6 环路滤波
为了减少编码失真带来的阻塞和振响等压缩伪影,AVS3标准采纳了三种环路滤波器对重构图像依次进行去块(Deblock)滤波、样本自适应偏移(SAO)滤波和自适应环路滤波(ALF)。去块滤波的目的是消除因块变换和量化而产生的块效应。对于每个基本块(8×8块),当边界属于CU边界、PU边界或TU边界中的任一个时,使用去块滤波器。去块滤波后,应用样本自适应偏移滤波降低区域平均样本失真,给重构样本加入偏移量来减少伪影。自适应环路滤波是环内滤波的最后阶段,是基于维纳的自适应滤波器,目的是尽可能减少原始样本和重构样本之间的误差。新一代视频编码标准AVS3将卷积神经网络(CNN)应用于AVS3视频编码标准进行了深入探索研究,提出了基于卷积神经网络的环路滤波(CNNLF)代替传统的去块滤波和样本自适应偏移滤波,取得了较好的性能增益。
3 技术及性能简要比较
AVS3相较于AVS1、AVS2和H.265/AVC等编码标准的区别,一是更灵活地划分编码单元。二是帧内预测采用单变换块或拆分变换块模式。三是帧间预测引入了基于位置的变换和子块变换来改进对部分残差块应用不同的变换核,提高残差编码效率。
新一代视频编码标准AVS3、VVC和AV1,它们具有相似又独立的编码工具。在块划分方面,编码块的划分作为视频编码的核心技术,AVS3使用新增扩展的四叉树-二叉树划分结构,VVC采用的是三叉树划分结构,AV1使用最大划分尺寸128×128的超级块。在帧预测方面,AVS3定义了仿射运动预测、自适应运动矢量精度、基于历史信息的运动矢量预测以及大跨度预测编码等。VVC定义了67种帧内预测模式、自适应运动矢量残差分辨率、更高运动矢量存储精度等[4]。AV1定义了56种帧内预测模式、动态空间与时间运动矢量参考、重叠块运动补偿、扭曲运动补偿等,并采用高级复合预测[5]。在编码变换方面,AVS3定义基于位置的帧间残差变换、基于帧内预测多核变换等。VVC使用多种变换方式选择,包括子块变换、最大QP由51变为63、变换系数编码时隐藏符号数据等。AV1使用变换块分区、扩展的转换内核等特性。在滤波方面,AVS3使用基于神经网络的滤波技术;VVC使用自适应环路滤波[6];AV1使用受约束的方向增强滤波器、循环恢复过滤器等。总体来说,AVS3、VVC和AV1拥有相似的编码框架和编码工具,但基于相似的编码思想,它们的编码技术都各有创新。
4 基于RTP/RTCP协议的AVS3视频流传输过程
RTP/RTCP协议是音视频实时传输最佳协议。基于RTP/RTCP协议的AVS3视频流传输系统中,音视频在AVS3编码器压缩形成的视频流,采用RTP/UDP/IP网络协议结构传输,而结构里的RTP/RTCP协议架构位于UDP/IP协议上的系统应用层中。RTP协议负责对视频流数据进行封装并实现视频流的实时传输,其核心是数据包格式。但不保证传输可靠性和不提供流量拥塞控制机制,而是借助它的辅助协议RTCP实现。RTCP协议的分发机制与RTP数据包相同,负责实时监控数据传输质量,为系统提供拥塞控制和流量控制[7]。
传输过程中,发送端在发送AVS3视频流数据时,按顺序给数据封装上RTP报头、UDP报头、IP报头,然后把IP数据包通过网络发送至接收端;接收端按反顺序将收到的IP数据包里的各类数据报头取出,对RTP报头进行分析,识别版本、负载类型等的有效性,再利用时间戳和包序列号等信息排序RTP数据报的顺序,重构视频帧,并解码回放。另外,设置QoS反馈机制控制分析接收数据包的时延、抖动、丢包率、最大序列号等信息,并由此判断网络拥塞状况,RTCP根据这些信息周期性向发送端返回RTCP控制包,以检验接收数据的正确性,用于发送端制定流量控制策略以及对输出速率作出自适应控制[8]。AVS3视频流传输结构流程如图2所示。
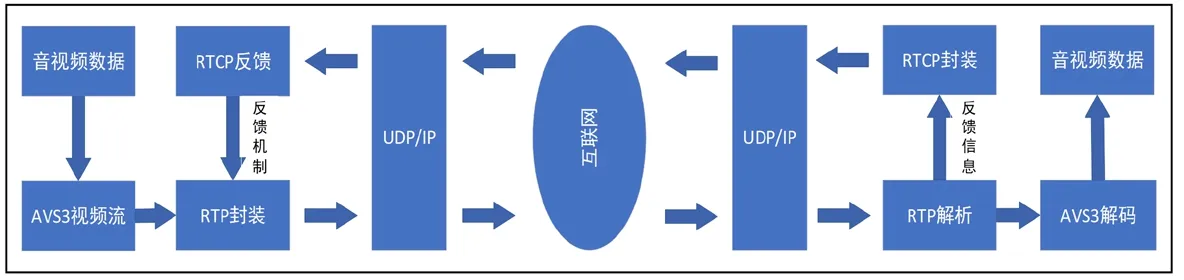
图2 AVS3 视频流传输结构
5 AVS3在视频会议系统中的应用
视频会议系统是摄像头采集画面和前处理后,视频编解码器采用编码算法将视频数据的冗余信息去除,对图像进行高质量压缩、存储,通过传输线路及多媒体设备,将声音、影像及文件资料互传,再将视频进行解码及格式转换,追求在可用的计算资源内,尽可能高质量地重建音视频,实现不同地方的人即时且互动沟通的信息通信系统,旨在为用户提供更高品质的视频体验。视频会议系统音视频数据流程如图3所示。

图3 视频会议系统音视频数据流程
AVS3编码器在发送端通过编码算法,对视频流去除信号中由时间相关性和空间相关性带来的冗余信息,在尽可能保证视频清晰度的前提下进行高效率视频压缩,以减少传输负载,接收端的AVS3解码设备按照解码算法恢复原始信号中的冗余信息,进而复原压缩前信号,并把视频信号处理后通过显示器展现[9]。
6 结语
当前新一代音视频编解码技术标准在面向8K及5G的产业中应用广泛,高清、超高清、云、VR/AR、全息投影等会议形式不断涌现,新一代编码标准有效缓解了传输和存储的巨大压力。AVS3作为面向我国的信息产业需求的编码标准,在视频的压缩、解压缩、处理和表示等方面优势明显,为音视频设备与系统提供高效经济的编解码技术,能够在更低带宽下传输更高质量的动态视频,有效解决视频卡顿、延时、丢包等问题。在会议电视系统、数字广播、数字存储媒体、多媒体通信、流媒体等信息产业中应用前景广阔。AVS3是我国拥有自主知识产权的编码标准,打破了国外专利垄断,形成了自主自控的产业能力,推动了技术生态构建,完善了相关产业链。
