基于热力图像的道路场景稠密多级语义分割方法
2023-09-13杨峰
杨 峰
(吉利汽车研究院(宁波)有限公司,浙江 宁波 315336)
0 引言
语义分割是一种图像处理方法,被广泛运用在自动驾驶、行人识别和视频监控等智慧交通领域。在自动驾驶领域,语义分割能帮助车辆对周围道路环境进行深层次的理解,提高车辆的安全性能,是决定车辆环境感知能力重要的一环。
目前主流视觉感知系统,能利用包含丰富语义信息的彩色图像(Red Green Blue,RGB),进行有效场景理解。现有深度学习语义分割方法已能在良好的光照环境下帮助车辆分析道路场景信息,自动驾驶车辆在道路上行驶。在光照条件很弱,例如阴天、夜间等,由于彩色相机无法全面地捕获周围场景,基于RGB图像的语义分割方法效果可能会明显下降,降低无人驾驶汽车在光照条件很弱的条件下行驶过程中的安全性。热红外相机获取热力信息,可在光线不足的情况下对RGB图像进行有效的信息补充,如图1 所示。基于热力图像融合的语义分割方法能有效提升弱光或黑暗条件下的分割效果。

图1 图像对比
本文提出一种基于彩色图像和热力图像(Red Green Blue-thermal,RGB-T)的稠密多级融合语义分割网络。更深层次的特征包含更丰富的语义信息,网络通过稠密多级融合结构融合多级图像特征,复用深层次特征与低级特征进行融合,能有效提升高分辨率特征语义信息。通过对融合特征进行显著定位,区分图像前景和背景,结合空间注意力机制,使融合特征更加专注于前景目标,提升后续分割任务的性能。本文还将融合特征用于边界监督学习,提高边界特征表达能力,细化分割边界。本文提出的多任务网络监督学习方法,可提高模型特征表达能力,有效提升模型效果。
本文贡献如下:
(1)提出一种新的用于道路场景分析的RGB-T语义分割方法。将语义分割任务分成了4 个阶段,包括稠密多级融合特征提取、前景显著定位任务、目标分割任务和边界细化任务。
(2)提出一个新的稠密多级融合模块(Dense fusion layer),用于提取多级特征,减少上下文语义信息的丢失。同时提出一个新的空间注意力机制模块(SA)用于学习前景区域权重和为目标分割任务提供显著信息。
(3)通过对公共数据集的仿真,将所提方法与现有的高性能语义分割方法进行了比较,并证实了本文所提出的方法和新模块的优越性。
1 相关方法发展概况
1.1 RGB语义分割
深度学习极大地提升了语义分割方法的性能。Long等[1]首次提出基于全卷积神经网络的语义分割方法,验证了使用全卷积神经网络方法相对于传统手工提取特征的方法有明显提升。Zhao 等[2]提出金字塔场景解析网络通过金字塔池化模块融合不同层次的信息来提取全局特征。He 等[3]提出自适应金字塔上下文网络,总结了上下文特征在语义分割中的3 个特性,并对深层上下文融合的语义分割方法进行了比较。仿真结果表明,这些多尺度上下文信息提取方法能提升模型特征表达,无法充分利用全局上下文信息,存在一定局限性。
1.2 多模态语义分割
现有多模态语义分割主要包括RGB 图像和深度图像(Red Green Blue-Depth,RGB-D)结合以及RGB图像和RGB-T图像结合的语义分割方法。Li 等[4]提出一种双分支的RGB-D语义分割模型,通过主干网络提取不同层次的特征,从高级特征到低级特征依次进行融合,验证了多模态特征融合的有效性。一些研究[5-6]注重后期融合策略,这些策略忽视了特征融合过程中的高级特征信息。Ha 等[7]提出的面向多光谱场景的自动驾驶实时语义分割方法,验证了在光照条件差的情况下,热红外相机采集的图像可提供额外有用的信息。Sun等[8]使用2 个主干网络分别提取RGB图像和热力图像特征,通过一个解码器恢复图像空间分辨率,忽略了低级特征的融合。Sun 等[9]在解码阶段通过跳跃连接,融合多尺度特征,验证了在光照不充足的情况下,热力图像可帮助检测和分割物体。Xin等[10]则在解码阶段增加特征增强模块,提升模型的特征表达能力。
2 模型设计
本文所提网络总体架构如图2 所示。
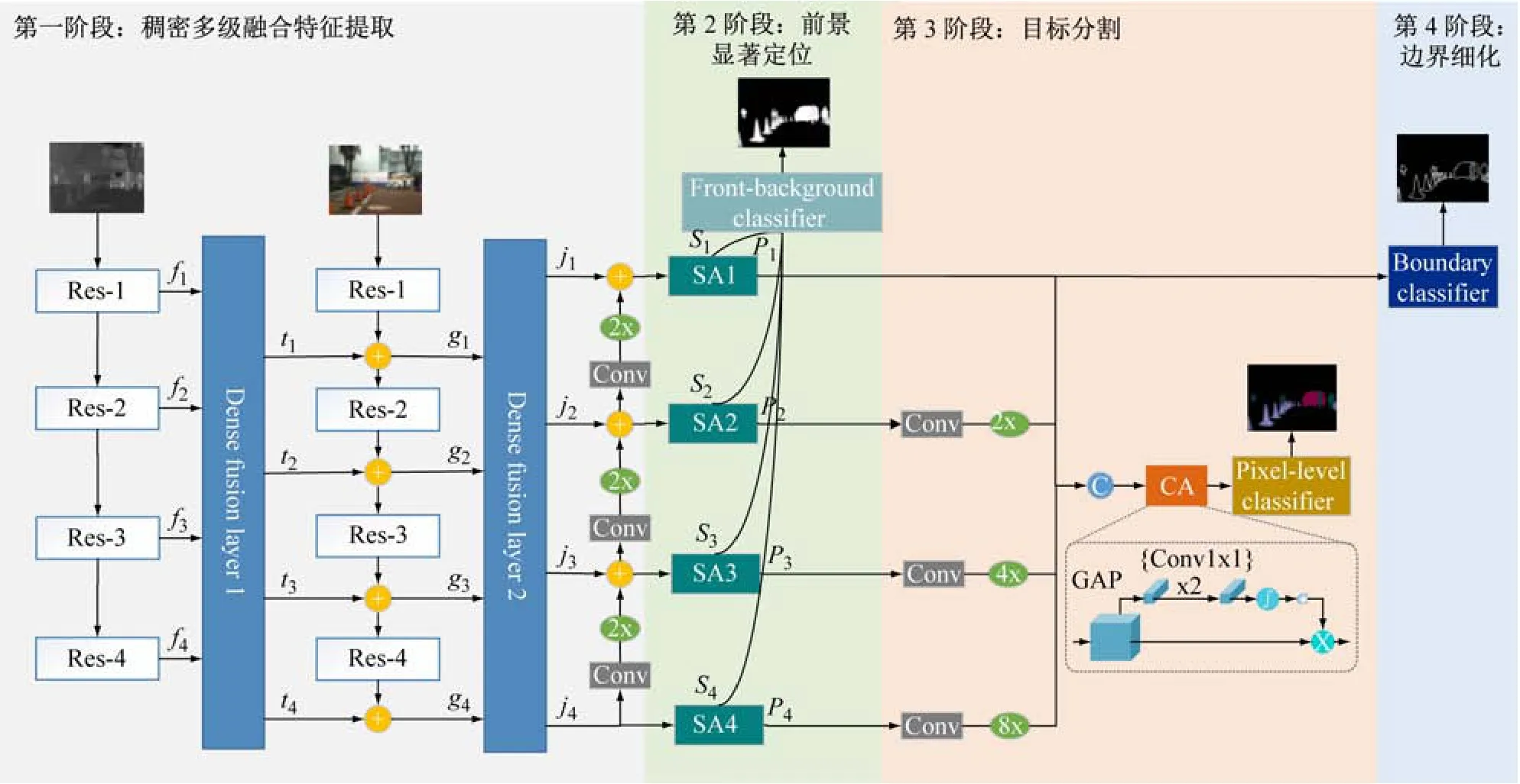
图2 网络整体结构
RGB-T语义分割任务包括稠密多级融合特征提取和3 个多任务分支,即前景显著定位,目标分割和边界细化等任务。在稠密多级融合特征提取阶段,主干网络先提取热红外信息,并将提取的信息作为辅助信息,通过稠密多级融合模块与RGB主干网络进行多模态信息融合,融合后的多尺度信息再次通过稠密多级融合模块对上下文信息进行有效融合。融合后的特征用于前景显著定位任务,结合空间注意力机制可使模型关注前景目标特征,有效提升特征的表达能力。边界细化任务能提升模型边界特征提取能力,细化语义分割任务中不同目标的边界。
2.1 稠密多级融合特征提取
深度卷积神经网络通过下采样来提高模型的感受野,提取图像深层次语义信息,在下采样过程中,图像的小目标信息和边界信息也会丢失。高层次语义信息能有效地用于目标理解,而低级特征包含的边界信息对目标分割边界的恢复尤为重要。本文提出稠密多级融合模块如图3 所示,对低级特征和高级特征进行有效融合,有效利用多尺度信息,并注重高级特征的重用,来为前景显著定位任务提供充分的全局特征,同时保留目标边界特征。

图3 稠密多级融合模块
本文使用ResNet-34 作为模型的主干网络[11],移除其全连接层并保留4 个卷积块。使用ResNet-34 对热力图像进行特征提取,其4 个卷积块的输出作为稠密多级融合模块1(Dense fusion layer 1)的输入,该模块的4 个输出和RGB 主干网络的不同层次特征进行多模态信息融合。融合后的不同层次特征作为稠密多级融合模块2(Dense fusion layer 2)的输入。稠密多级融合模块将4 个不同层级的特征作为输入,通过密集连接结构,复用高层语义信息与低级特征融合,使高分辨率低级特征包含更丰富的高层语义信息。稠密多级融合模块使用1 ×1 的卷积和上采样操作将不同大小的特征统一尺寸并进行拼接。通过一个1 ×1 的卷积对不同等级之间的特征进行信息融合。整个模块在尽量不增加过多计算成本的情况下,考虑不同等级特征之间的融合和显著特征的充分提取。
2.2 前景显著定位任务
参考空间注意力机制思想[12],提出新的空间注意力机制模块(SA)如图4 所示。
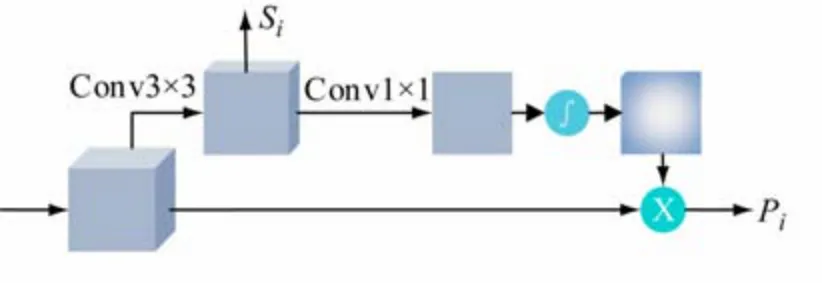
图4 空间注意力机制模块
前景显著定位任务结合多级融合特征,对图像前景背景进行分类,促使空间注意力机制模块中的权重特征学习到前景信息。不同层次的融合特征通过空间注意力机制模块得到的加权融合特征更加关注图像中的前景区域,有利于降低后续目标分割任务和边界细化任务的难度。前景显著定位任务提取4 个注意力机制模块中的权重特征S1、S2、S3和S4,其中更高层次的低分辨率特征通过1 ×1 卷积和上采样保持和S1特征有相同的尺寸,这4 个同样大小的特征先进行拼接,通过一个1 ×1 的卷积和2 倍的上采样,通过一个3 ×3的卷积和2 倍的上采样,恢复到原始图像分辨率。
2.3 目标分割任务
目标分割任务将之前获取的多级加权融合特征进行组合,并引入通道注意力机制模块(CA)[13],对特征映射通道进行选择性加权,提高融合特征表征能力。使用像素级分类器(Pixel-level classifier)对图像的每个像素进行类别分类。像素级分类器为一个1 ×1 的卷积和两倍的上采样以及一个3 ×3 的卷积和2 倍的上采样的组合结构。
2.4 边界细化任务
图2 中P1、P2、P3和P4包含低级特征,即目标的细节特征和边界信息,同时融合有高层语义信息,有利区分不同的目标主体,细化不同目标之间的边界。边界细化任务通过边界分类器(Boundary classifier)引导模型学习边界特征。
2.5 损失函数
使用带权重的交叉熵损失函数(WBCE)作为前景显著定位任务、目标分割任务和边界细化任务的损失函数
式中:N为输入像素的总数;m为语义类别数量;wj=,其中pj为每个类别的比例。
3 仿真分析
3.1 仿真细节
本文使用MFNet道路场景数据集做相关仿真[7],每张图像的分辨率为480 ×640,一共包含1569 份由InfReC R500 相机捕获的成对RGB图像和热力图像样本以及对应的语义分割标签。在这些图像中,820 份图像是在白天采集的,749 份图像是夜间采集的。此数据集的语义分割标签包含8 个前景物体标签(交通锥、减速带、车道线、汽车、行人、自行车、挡车器、护栏)和1 个背景标签。训练集包含410 个白天样本和374 个夜间样本,验证集包含205 个白天样本和187个夜间样本,测试集包含205 个白天样本和188 个夜间样本。整个数据集样本里背景占像素总量的92.138%,其中栏杆类别只有0.095%,这极大地增加了语义分割难度。对数据集的原始样本使用随机亮度、对比度和饱和度变换以及随机的高斯模糊、随机水平翻转、随机缩放和裁剪的操作来丰富训练样本。
仿真使用的深度学习框架是Pytorch1.7。仿真使用Ranger优化器,权重衰减系数为0.0005。将minibatch设置为4,初始学习率为10-5,epoch设置为300。使用“poly”学习率衰减策略,其指数系数为0.9。
3.2 仿真对比
本文的方法和DFN[15]、SegHRNet[16]、CCNet[17]、APCNet[18]、MFNet[7]、FuseNet[19]、RTFNet-152[20]、FuseSeg-161[9]和ABMDRNet[21]9 个语义分割方法做对比。
表1 列出了MFNet数据集里9 个类别分别的像素准确率(Acc)和交并比(IoU)以及总体的平均像素准确率(mAcc)和平均交并比(mIoU)的仿真结果。各指标结果值越大越好,所提方法基本都优于其他方法。为更进一步验证所提的方法,分别用白天图像和夜间图像测试,表2 总结了比较结果。
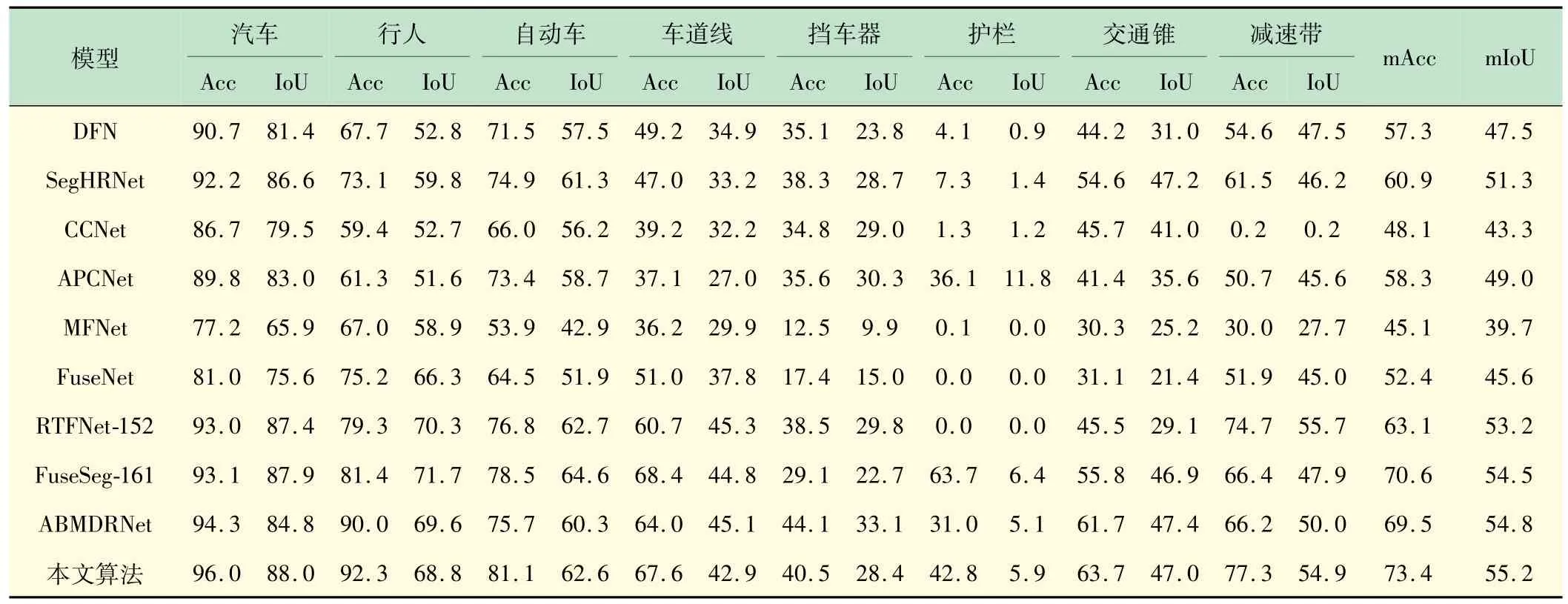
表1 各类别分割结果
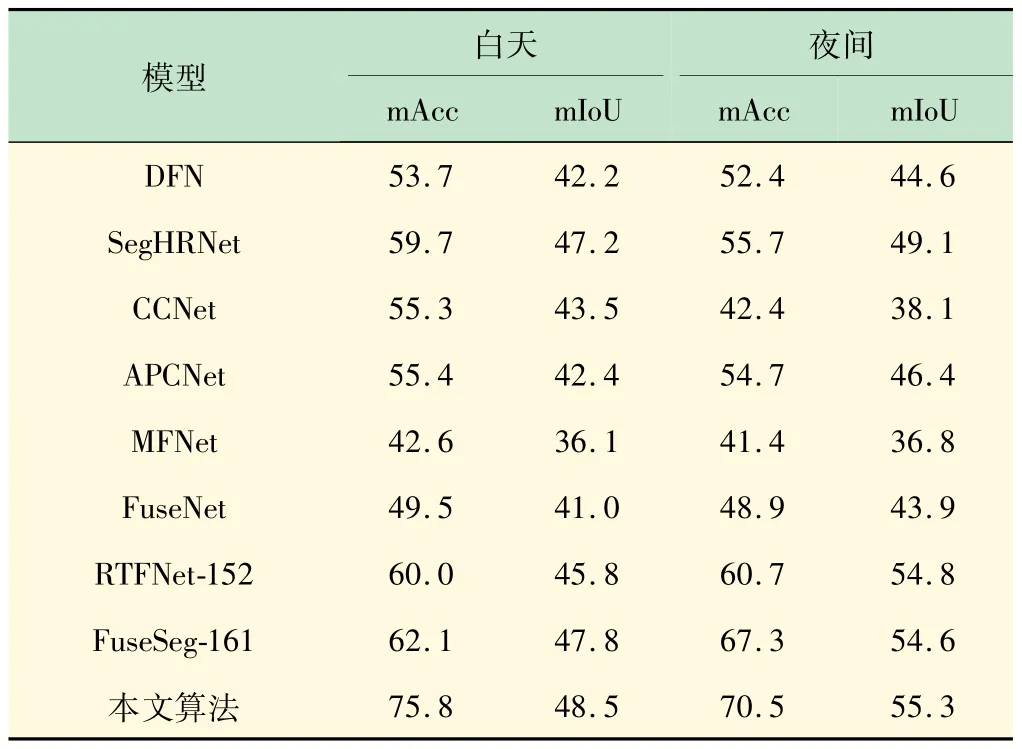
表2 白天和夜间图像仿真结果
如图5 所示,在昏暗、曝光等场景下,所提方法仍能对图像中的物体进行准确定位,生成精确连贯的语义分割图像。当RGB图像无法获取周围语义信息,热力图像可进行一个有效的补充。如图5 所示,显著图像能很好地区分前景目标,减少目标分割任务中背景信息对前景目标的干扰,边界监督也能细化不同目标之间的分割边界。

图5 仿真结果对比
3.3 消融仿真
为验证本文所提出关键内容的有效性,使用相同的参数,在MFNet 数据集进行消融仿真,仿真结果见表3。
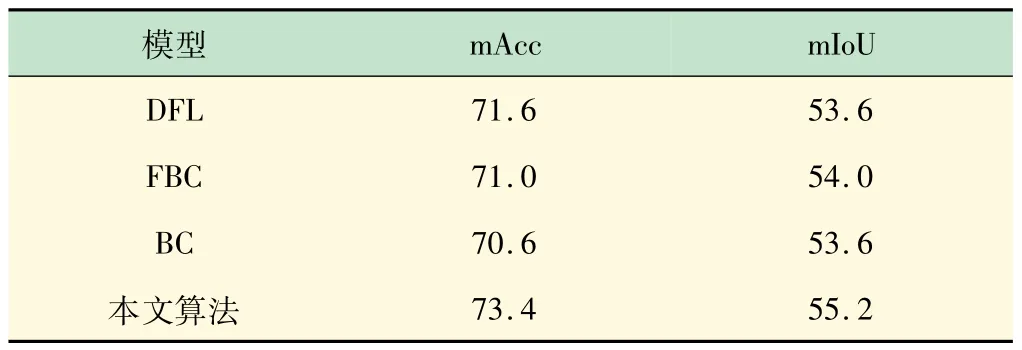
表3 各模型下消融仿真结果
(1)稠密多级融合模块的有效性。设计一个变体模型DFL,该模型去除了本文方法中的两个稠密多级融合模块,直接将热力图像通过ResNet-344 个卷积块的输出和RGB图像通过ResNet-344 个卷积块的输出对应相加,得到4 个输出结果依次代替图2 中的j1、j2、j3和j4。此变体模型DFL 的仿真结果见表3,与具有稠密多级融合模块的原方法相比,性能变差,此充分说明了所提出的新型稠密多级融合模块的优越性。
(2)前景显著定位的有效性。设计一个变体模型FBC,该模型去除了图2 中第2 阶段前景显著定位的内容,包括4 个新型空间注意力机制模块,一个前景分类器和前景监督。此变体模型FBC 的仿真结果见表3,与具有前景显著定位内容的原方法相比,性能明显变差,充分说明所提前景显著定位内容的显著区域区分能力。
(3)边界细化的有效性。设计一个变体模型BC,该模型去除了图2 中第4 阶段边界细化的内容,此变体模型BC的仿真结果与具有边界细化内容的原方法相比明显变差,具体数据见表3。这证明了第4 阶段边界细化内容的重要性。
4 结语
本文提出一种基于深度学习的RGB-T 道路场景语义分割方法,此方法不光将语义分割任务细化成4个阶段,这4 个阶段相辅相成,每个阶段都对网络做了特定的优化,还引入2 个新模块,本方法在道路场景数据集上表现出了极大的优越性。有望为无人驾驶车辆对道路场景感知方向的新技术做出贡献。
四个现代化,关键是科学技术的现代化。没有现代科学技术,就不可能建设现代农业、现代工业、现代国防。
科学技术是生产力,这是马克思主义历来的观点。现代科学技术的发展,使科学与生产的关系越来越密切了。科学技术作为生产力,越来越显示出巨大的作用。现代科学为生产技术的进步开辟道路,决定它的发展方向。一系列新兴的工业,都是建立在新兴科学基础上的。当代自然科学正以空前的规模和速度,应用于生产,使社会物质生产的各个领域面貌一新。社会生产力有这样巨大的发展,劳动生产率有这样大幅度的提高,靠的是什么?最主要的是靠科学的力量、技术的力量。
——摘自《邓小平在1978 年3 月全国科学大会开幕式上讲话》
