基于门控循环单元的家庭热水用量预测模型研究
2023-09-07孙颖楷陈庆明钟益明
孙颖楷 陈庆明 钟益明
(1.广东万和新电气股份有限公司 佛山 528000;2.中山火炬职业技术学院 中山 528400)
前言
随着人们生活水平的提高,居住面积的增大,对家用热水装置以及热水系统的舒适性要求也越来越高,如何确保家庭热水使用及时性和舒适性的同时,制定有效的能源管理策略,降低家庭生活热水、采暖热水等方面的能源消耗,对家庭热水量进行预测研究就具有了一定的实用价值。
研究者一直致力于寻找能够减少能源浪费的策略,主要应用的方法包括基于统计学的方法和基于机器学习的方法,通过对家庭热水等使用数据的分析,可以得到使用时的规律、周期、趋势等信息,同时,还可以通过聚类、关联规则挖掘等技术,发现使用时的行为模式和相应的影响因素等,从而为制定组合能源管理策略提供参考。基于统计学的方法中,ARIMA 模型和季节性分解法是比较常用的两种方法,王平等使用ARIMA 模型来对能源生产和使用进行预测[1],海文龙等则提出了一种基于ARIMA 与卷积长短时神经网络联合使用的燃气负荷预测模型[2]。
由于家庭用能使用习惯通常具有周期性和季节性的特征,相比传统方法,机器学习方法具有端到端学习能力,可以处理非线性关系,以及处理包括多个传感器、多个变量在内的多维数据,能更好地挖掘其中的信息。在基于机器学习的方法中,主要包括神经网络、支持向量回归、随机森林等算法。支持向量回归(SVR)模型可以用于建模用能数据的非线性关系[3];随机森林(RF)模型可以通过对历史数据进行特征选择和集成学习来提高预测准确性。
近年来,循环神经网络(RNNs)在家庭用能方面的研究逐渐增多[4,5],它的主要思想是在网络的内部维护一种称为“状态”的信息,使网络能够记忆过去的输入,进而影响后续的输出。由此,RNN 可以在处理用能等时间序列数据时保留更多的历史信息,从而在此类预测任务中具有一定的优势。其中,最常见的RNN 是长短时记忆网络(Long Short-Term Memory,LSTM)[6]。这种网络结构通过引入门控机制,可以有效地控制历史信息的保留和遗忘,那幸仪等基于小波和LSTM 开展城市天然气负荷方面的研究,结果表明该模型有较高的准确性[7]。
相比于LSTM 模型,门控循环单元(Gated Recurrent Unit ,GRU)模型是一种更简单的RNN 模型[8],只包含重置门和更新门两个门。GRU 模型在保持长期依赖能力的同时,减少了模型参数,提高了模型的训练速度。因此,本文引入GRU 模型来开展研究,提高家庭热水量预测方面的准确性,希望提升能源利用效率同时,能够为家庭用户提供更加智能和舒适的生活热水使用方式。
1 家庭热水用量分析
家庭热水用量有一定的短、中、长期规律性。一般来说,热水使用在一天之中会呈现出早晚高峰的态势。例如,早晨人们起床洗漱和晚上洗澡时段的热水需求较高。热水用量在四季之间等长期趋势上也会呈现明显的差异,如冬季气温较低时,热水使用量会增加等。虽然家庭热水用量也会具有波动,如家庭成员可能会因为度假、出差或参加聚会等情况可能导致热水用量的增加或减少,这给预测带来了相应的难度。考虑到家庭成员的生活有一定的习惯性,因此本文以家庭成员的热水用量,并将环境温度也作为影响热水用量预测的主要参数,在此基础上建立用水趋势的预测模型。
热水用量的大小,与用户使用的时长,冷水端温度,出水温度等有关,本质上是热量消耗问题,因此就可以将家庭热水用量转化为热量值来进行表征[9]。一般家庭用热水量主要会集中在某几个时间段,其余时间零星用水,本文以储水式热水器为研究对象,综合考虑热水器加热功率,选取2 h 为时间间隔进行数据聚合,在保持数据的整体结构同时,降低计算量,以此建立起时序预测模型。
2 门控循环单元
门控循环单元GRU 是一种改进的RNN 结构,其在处理序列数据时,可以将前面的输入与当前的输入进行联合处理,并将上一个时间步的输出作为下一个时间步的输入。通过引入门内部机制来调节信息流,从而使模型能更加稳定且能捕捉长期依赖,提高模型的学习效果。
2.1 GRU 模型结构
GRU 主要包括两个门控单元,更新门(Update Gate)和重置门(Reset Gate)。相较于LSTM,GRU 的张量操作较少,因此,训练速度要比LSTM 快一些。
2.2 更新门(Update Gate)
更新门负责控制隐藏状态的更新程度,通过更新门,GRU 可以学习在不同时间步决定保留或丢弃哪些信息。更新门的计算公式如下:
式中:
zt—更新门的激活值;
σ—Sigmoid 激活函数,取值范围为 [0, 1];
Wz、Uz—权值矩阵;
xt—输入序列的当前时间步的输入;
ht-1—上一个时间步的隐藏状态。
当zt接近0 时,表示保留过去的隐藏状态;当zt接近1 时,表示更新当前的隐藏状态。
2.3 重置门(Reset Gate)
重置门负责控制过去隐藏状态对当前隐藏状态的影响。通过重置门,GRU 可以在更新隐藏状态时,选择性地保留或丢弃之前的信息。重置门的计算公式如下:
式中:
rt—重置门的激活值;
σ—Sigmoid 激活函数,取值范围为 [0, 1];
Wr、Ur—权值矩阵;
xt—输入序列的当前时间步的输入;
ht-1—上一个时间步的隐藏状态。
当rt接近0 时,表示忽略过去的隐藏状态;当rt接近1 时,表示保留过去的隐藏状态。
2.4 候选隐藏状态(Candidate Hidden State)
式中:
tanh—激活函数,取值范围为[-1, 1];
xt—当前输入;
rt—重置门激活值,用来控制需要保留多少之前的记忆,如果 为0,那么只包含当前的信息;
ht-1—上一个时间步的隐藏状态。
2.5 隐藏状态更新(Hidden State Update)
最后,GRU 通过结合更新门激活值、过去隐藏状态和候选隐藏状态,计算得到当前时间步输出的隐藏层信息 。计算公式如下:
式中:
ht—当前时间步的隐藏状态;
zt—门控制量;
ht-1—上一个时间步的隐藏状态;
通过这种方式,GRU 可以根据序列中的不同信息,灵活地保留或丢弃过去的隐藏状态,从而在时间序列预测任务中取得更好的效果。
3 基于GRU 的家庭热水用量预测模型
3.1 GRU 模型建立
模型的建立,首先需对获得的热水用量数据进行预处理,为了消除指标的量纲影响,需对数据在归一化/标准化处理的基础上搭建模型,将预测问题转化为监督学习问题,将数据集输入模型进行训练;最后对模型进行评估,并在评估基础上对模型参数进行调优,综合考虑后固化形成最终预测模型。流程如图2 所示。
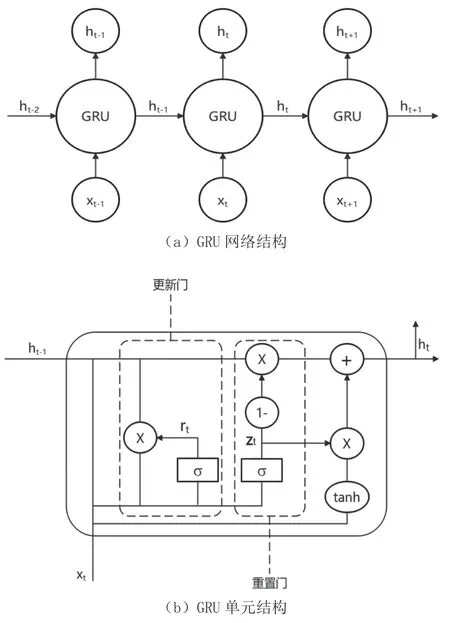
图1 门控循环网络模型及单元结构

图2 GRU 预测模型流程
1)数据预处理
首先,需要收集家庭用能数据,为了提高模型的预测能力,需对数据进行清洗和异常值处理等操作,并对数据集的结构和相关性进行分析,在观察数据的相关性及平稳性的基础上,选择采样频率。然后,可以进行数据归一化处理,以便于模型训练。
2)模型输入
将预处理后的数据划分为训练集和测试集。训练集用于训练GRU 模型,测试集用于评估模型的预测结果。对于预测模型,需要将数据转换为适合模型输入的格式,即将时间序列数据转化为样本序列和目标序列。可以通过设置滑动窗口,将时间序列数据分割成多个样本和目标序列。
3)模型建立
为了训练数据,首先需定义GRU 模型。
输入层:用于接收时间序列数据,通常包括若干时间步的变量值,本文中将前24 h 的用能数据作为输入层样本,加上环境温度,共计13 个输入量;
GRU 层:用于提取时间序列数据的特征,GRU 层中的门控单元可以有效地处理用能数据的依赖关系,可以通过增加层数和神经元数来增加模型的复杂度和预测能力;
输出层:用于输出模型的预测结果,本文为预测下一个时间节点的热水用量。
4)模型训练
在模型建立后,用训练集数据对模型进行训练,在训练过程中,需对模型参数进行调整,包括训练步长、损失函数等,通过最小化损失函数来优化模型的权重参数。可以通过监控模型在训练集和测试集上的损失函数值和预测准确度来评估模型的训练效果,同时可以通过调整模型参数和超参数来进一步提高模型的预测能力,直到训练数据与模型预测数据误差满足预设要求。
5)数据输出
使用训练好的GRU 模型对测试集进行预测,并将预测结果与实际用能数据进行比较,以评估模型的预测能力。可以使用常见的误差指标,本文采用均方根误差(RMSE)、平均绝对误差(MAE)和相关系数R 来评估模型的预测性能。如果预测误差较小,则表明模型能够有效地预测热水用量等家庭用能数据。
在完成模型的训练和调优后,可以将其进行压缩或裁剪后部署到生产环境中进行使用。
3.2 预测结果及分析
为验证GRU 模型的准确性,以额定功率3 300 W 的万和某型号智能储水式电热水器的连续183 天的热水用水研究数据,聚合为每天12 个时间序列点,共计2 196个时间序列点作为研究样本,将前面169 天的热水量数据划分为训练集,后面14 天数据作为测试集,预测最新2 周(168 个时序点)的热水用量。
GRU 网络训练中,每个时序点的预测都是通过前12个时间序列点和温度数值预测出后1 个时间序列点的热水量值,即GRU 模型的输入长度为13、输出长度为1,设置网络迭代2 000 次,隐含层为1 层,其中神经元数量为100。
作为GRU 效果对比,LSTM 网络训练与GRU 网络训练的参数设置完全一样;而BP 神经网络构建中,兼顾训练时间和效果,设置隐含层1 层、神经元数为80,最大迭代次数为2 000。经过测试,将GRU 模型预测结果与BP、LSTM 算法模型的预测结果进行对比,如图3 所示。
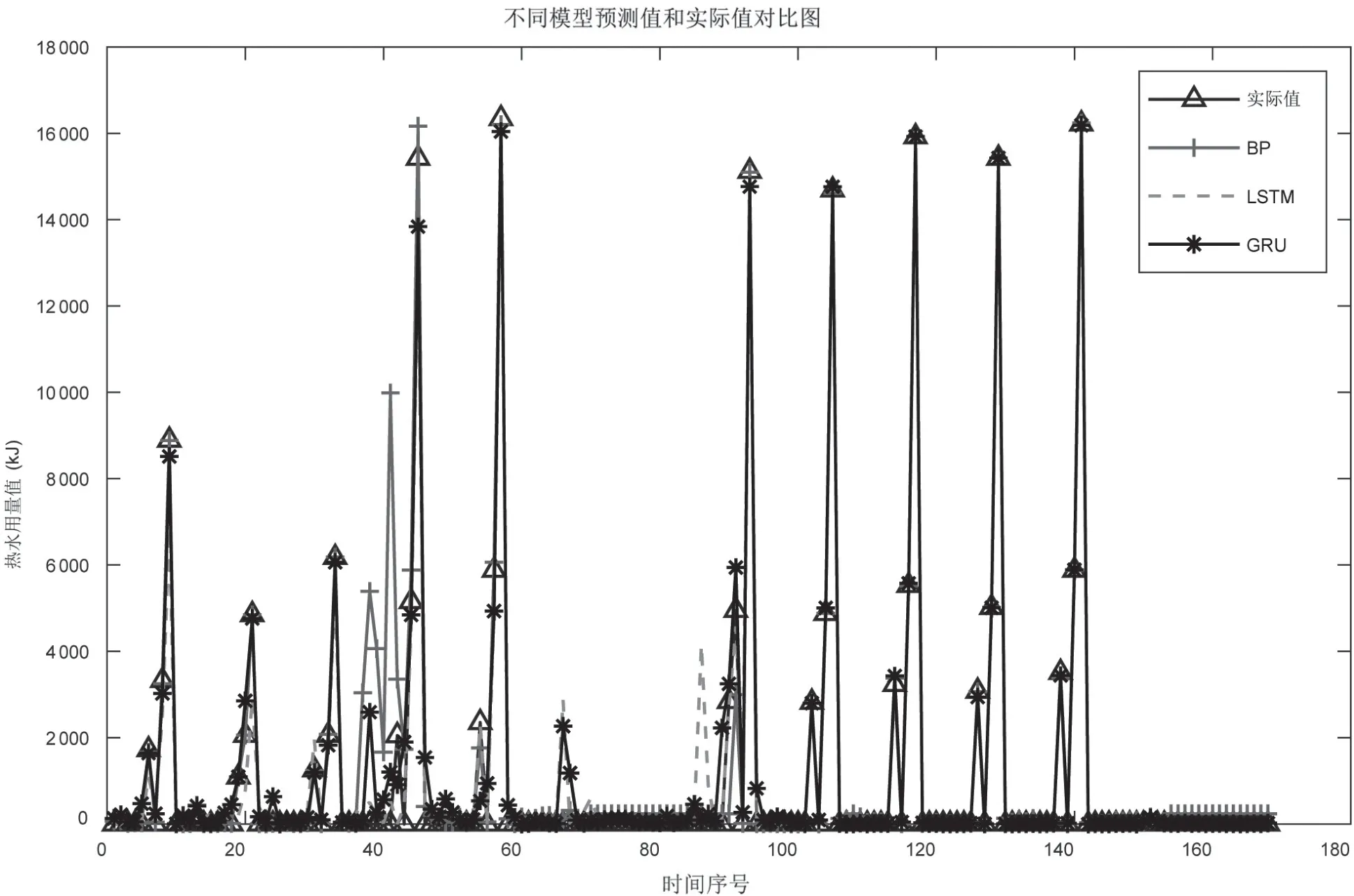
图3 不同算法预测热水量比对
为进一步比较算法的优劣,将3 种预测模型(BP、LSTM、GRU)预测的RMSE、MAE、R 值、训练耗时对比如表1 所示。
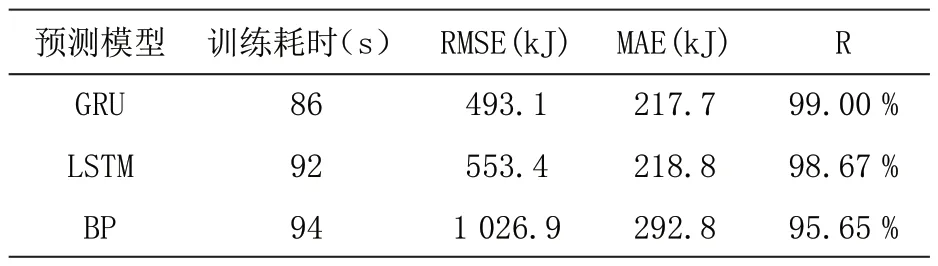
表1 不同算法预测性能结果
从图3 中和表1 中可以看出,三种算法BP、LSTM、GRU 都能较好预测储水式电热水器用户的热水用量,在性能方面,基于GRU 模型预测结果的均方根误差RMSE和平均绝对误差MAE 更小,相关系数R 则更高,所需训练时间对比起来也更短。结果表明,GRU 预测模型能更好地满足热水供应等用能方面的预测需求。
4 结语
需要指出的是,由于家庭能源使用习惯的复杂性,当前的研究还面临着一些挑战。基于机器学习的预测模型需要充分考虑家庭能源使用的复杂性和不确定性,在多模态数据融合方面,家庭用能数据不仅包括电能、燃气能等能源的使用数据,还包括温度、湿度、气压等环境参数数据,这些数据的融合可以更好地提高预测的准确性,因此,需要在未来的研究中进一步探索和完善相应的技术和方法,以及如何对模型进行评估、优化及裁剪等。另外,也可以通过对时间序列进行多因素分解处理,并将预处理后的数据输入到深度学习模型中进行进一步的学习和预测,更好地捕捉序列的特征来提高预测性能。
