基于LightGBM的区块链异常交易检测技术研究
2023-09-06王志强王姿旖王庆德徐华福
王志强 王姿旖 王庆德 徐华福
1(北京电子科技学院网络空间安全系 北京 100070)
2(国家信息中心 北京 100045)
3(广西大数据发展局 南宁 530023)
(wangzq@besti.edu.cn)
随着区块链技术在金融领域的广泛应用,区块链技术的底层协议已逐渐融合当前金融体系的交易制度,推动了实现交易去中心化的价值安全转移,对解决各领域的信任难题具有十分重大的意义[1].区块链技术在资金管理、供应链金融、贸易融资、支付清算等细分领域都有具体的落地案例,金融成为区块链技术应用最多的领域.其中,数字货币是当下区块链应用中最重要的领域,例如比特币和以太币一经投入市场就受到人们的狂热追求.然而随着区块链及数字货币的高速发展,针对区块链交易的网络犯罪事件层出不穷,区块链系统中出现多种因为恶意节点和恶意交易而导致的不同类型的异常交易行为,典型异常交易行为包括DoS攻击(denial-of-service attack)、网络钓鱼、勒索病毒、重入漏洞等.
异常检测指的是通过数据挖掘手段识别数据中的“异常点”,但目前没有工具能够自动检测或标记网络上发生的任何可疑行为或交易的“异常点”,人工也无法完成筛选区块链异常交易,只能通过机器学习或深度学习算法实现对异常交易的快速识别.当前针对区块链异常检测常用的异常检测算法包括随机森林[2-4]、逻辑回归[4]、SVM[5]、双采样集成算法[6]、XGBoost[7-8]、决策树[9]等,都取得了不错的检测效果.然而传统的深度学习模型训练需要大量的训练数据,在小样本情况下容易出现分类器训练不足和过拟合的问题,因此本文面向小样本提出了一种基于LightGBM(light gradient boosting machine)算法的集成学习训练模型的方法,通过计算特征重要性实现特征选择,并利用网格搜索进行参数优化.
1 相关工作与技术
1.1 相关工作
区块链交易是基于区块链技术的交易模式,通过区块链分布式共识算法,在无需任何第三方机构参与的情况下安全存储交易记录,具有去中心化、公开透明、不可篡改的特点,吸引了政府机关、金融机构、资本市场和国际组织的密切关注.在区块链和信息化产业发展的大背景下,如何迅速识别异常交易成为当前的研究热点.
国内外研究人员针对区块链交易安全问题提出了不同的异常检测方法:2018年,Jourdan等人[8]定义了与比特币区块链实体特征相关的新特征,将比特币区块链交易图匿名性的问题表述为1组比特币用户类别上的分类问题,建立了弱攻击者和强攻击者模型,实验验证表明,使用更复杂的特征能有效提高模型的分类性能;2020年Kumar等人[9]通过使用基于监督机器学习的异常检测方法检测账户交易行为中的恶意节点,对外部拥有账户(EOA)和智能合约账户分别采用2种不同的深度学习模型,其检测精度分别达到96.54%,96.82%;2019年,Podgorelec等人[10]提出了一种基于机器学习的自动签名方法,根据历史交易识别异常交易,通过滚动窗口特征提取方式(the rolling window feature extraction)进行特征提取,每笔交易提取45种新特征,利用随机森林分类算法检测潜在的欺诈行为的数字签名,并进行了实验和分析,对所提方法进行了验证;2021年, Ibrahim等人[11]提出了3种欺诈检测模型,分别为决策树、随机森林和KNN,利用相关系数选择最有效的6个特征构建一个新数据集,最终实验表明3种算法显著提高了训练效率,减少训练时间.以上研究表明,特征选择和异常检测结合能有效识别异常账户.
1.2 相关技术
1.2.1 决策树
决策树算法采用树型结构,由根节点、内部节点、叶节点组成,是一种典型的分类算法[12].目前常用算法包括ID3,C4.5,CART.表1为3种常用算法介绍:

表1 常用算法介绍
1.2.2 LightGBM
LightGBM是一款基于决策树算法的分布式梯度提升框架,在微软亚洲研究院发表于NIPS的系列论文[13-14]中首次提出,可用于排序、分类、回归以及很多其他的机器学习任务中.随着不断迭代修改,增加了支持叶子索引预测、最大深度设置、特征重要性排序、多分类、正则化、支持特征缺失值、随机森林模式等功能.
传统传统的GBDT算法是以CART分类回归树为基模型的一种集成学习算法,采用基函数的线性组合,不断迭代减小训练过程产生的残差,利用损失函数(loss)作为准确度指标,从而达到分类或回归的效果.LightGBM算法相较于GBDT算法,能训练更少的样本、更少的特征、占用更少的内存,基本思想是利用弱分类器迭代训练得到最优模型.LightGBM算法在GBDT算法上进行的优化包括基于直方图(histogram)的决策树算法[14]、支持高效并行[14]、GOSS算法[13,15-16]、leaf-wise算法[13,17]、EFB算法[13,17]、直接支持类别特征[14,18]和Cache命中率优化[14,19].
直方图算法[13]将连续属性值存储到离散的k个箱子(bin)中,也就是构造宽度为k的直方图.在遍历训练数据过程中,统计离散值在直方图中累加统计量.遍历排序直方图的离散值,找到增益最大的节点作为最优分割点.
LightGBM使用带有深度限制的按叶子生长(leaf-wise)策略[13,15],每次树分支时选择具有最大分裂增益的叶子节点进行树生长,如此循环.增加最大深度限制能有效防止过拟合,按叶子生长能保证在分裂次数相同的情况下,减少误差,保证精度.图1为按叶子生长的决策树:
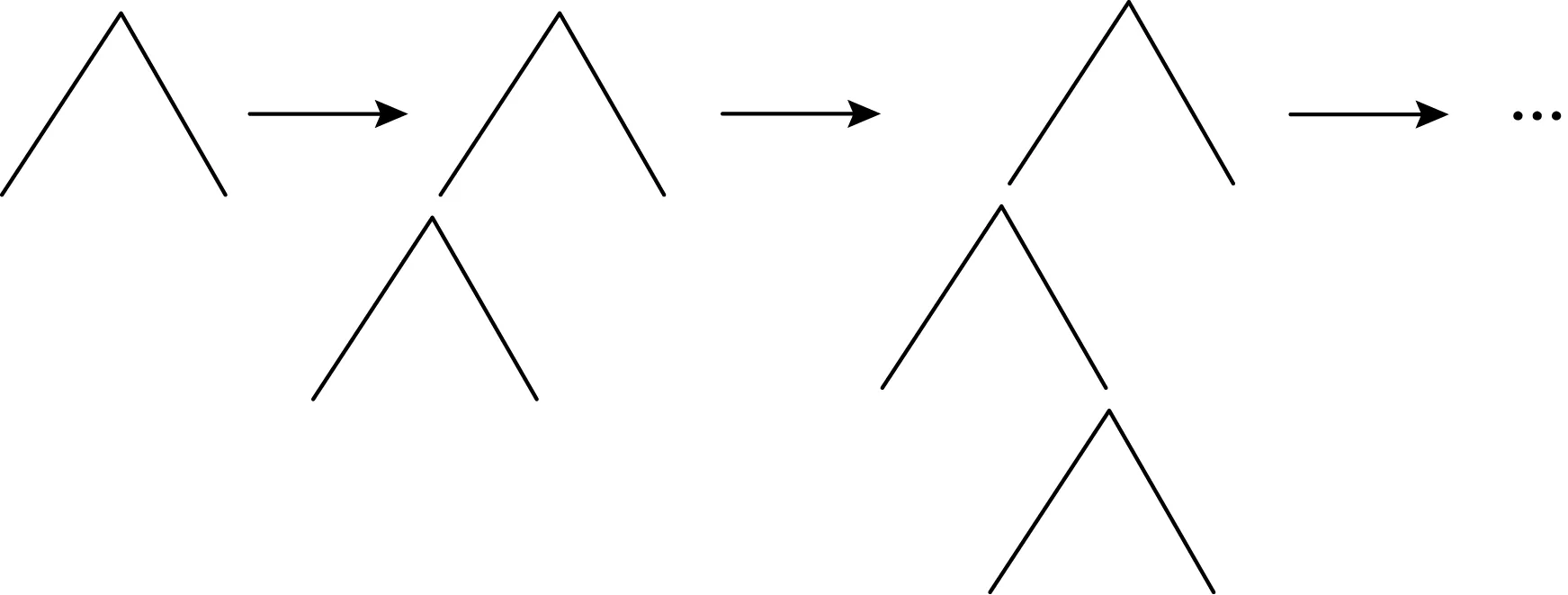
图1 按叶子生长的决策树
LightGBM算法在GBDT算法上的一系列优化在保证准确率的同时,能有效加快GBDT模型的训练速度,减少计算量,降低时间复杂度,减少内存消耗,提高命中缓存率,能有效防止过拟合.因此本文选择LightGBM算法进行区块链异常交易检测.
2 基于LightGBM的区块链异常交易检测模型
本文构建的基于LightGBM的异常交易检测模型框架如图2所示,分为数据预处理模块、特征选择模块和分类评估模块.
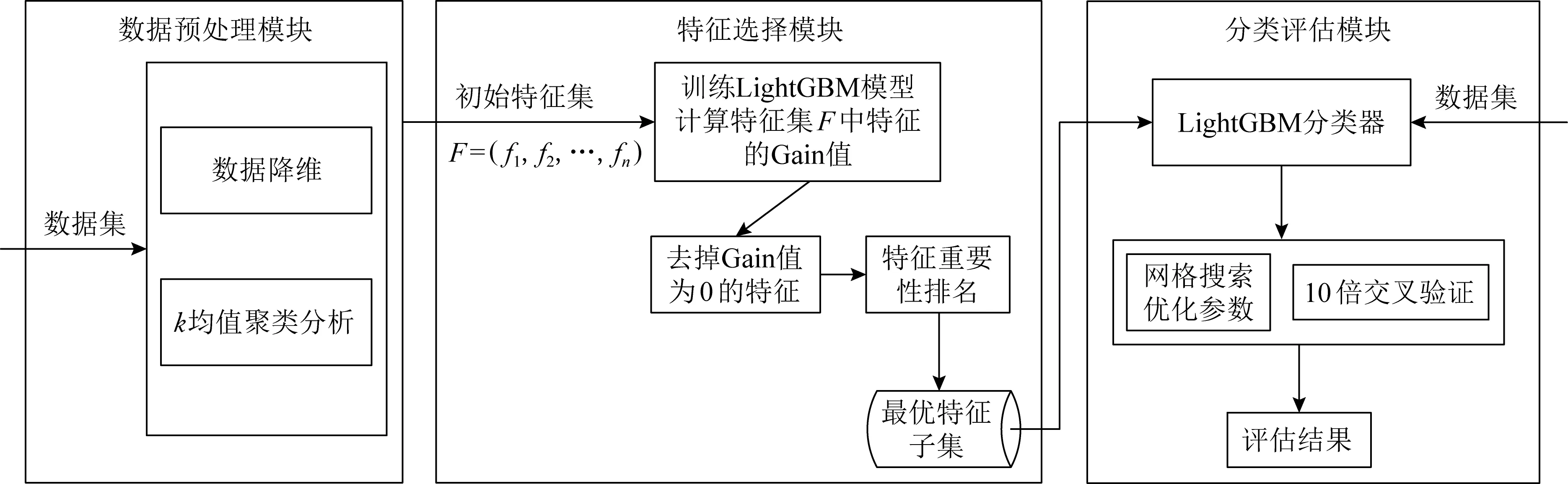
图2 基于LightGBM的异常交易检测模型框架
2.1 数据预处理模块
2.1.1 数据集描述
本文采用的数据集[6]来自以太坊和连接到以太坊的本地客户端,包括2179个被标记为异常的非法账户和2502个正常账户,共有4681个账户、42个特征.这些特征分别属于3种数据类型:整型、字符串型和双精度浮点型.将数据集中正常账户标记为0,异常账户标记为1,所有正常账户都与非法账户进行交叉对比,结果显示,该数据集的所有正常账户都没有进行任何非法活动, 也就是说,正常账户和异常账户之间的行为并无相似度.
2.1.2 数据降维及聚类分析
为实现数据可视化,本文采用主成分分析法(pca)压缩数据维度用于k均值聚类分析(k-Means),将数据集划分为2类,生成图3所示的2维散点图(红色样本点为正常账户,蓝色为异常账户).图3显示样本分群效果非常明显,不存在不同类别样本点的重叠,可以看出2组样本对应的点非常分散(如左上角红色点和右下角蓝色点),说明2组样本间相似度比较低,样本间有较好的区分度,而左下角数个样本点聚在一起,说明样本点间的相似度较高.
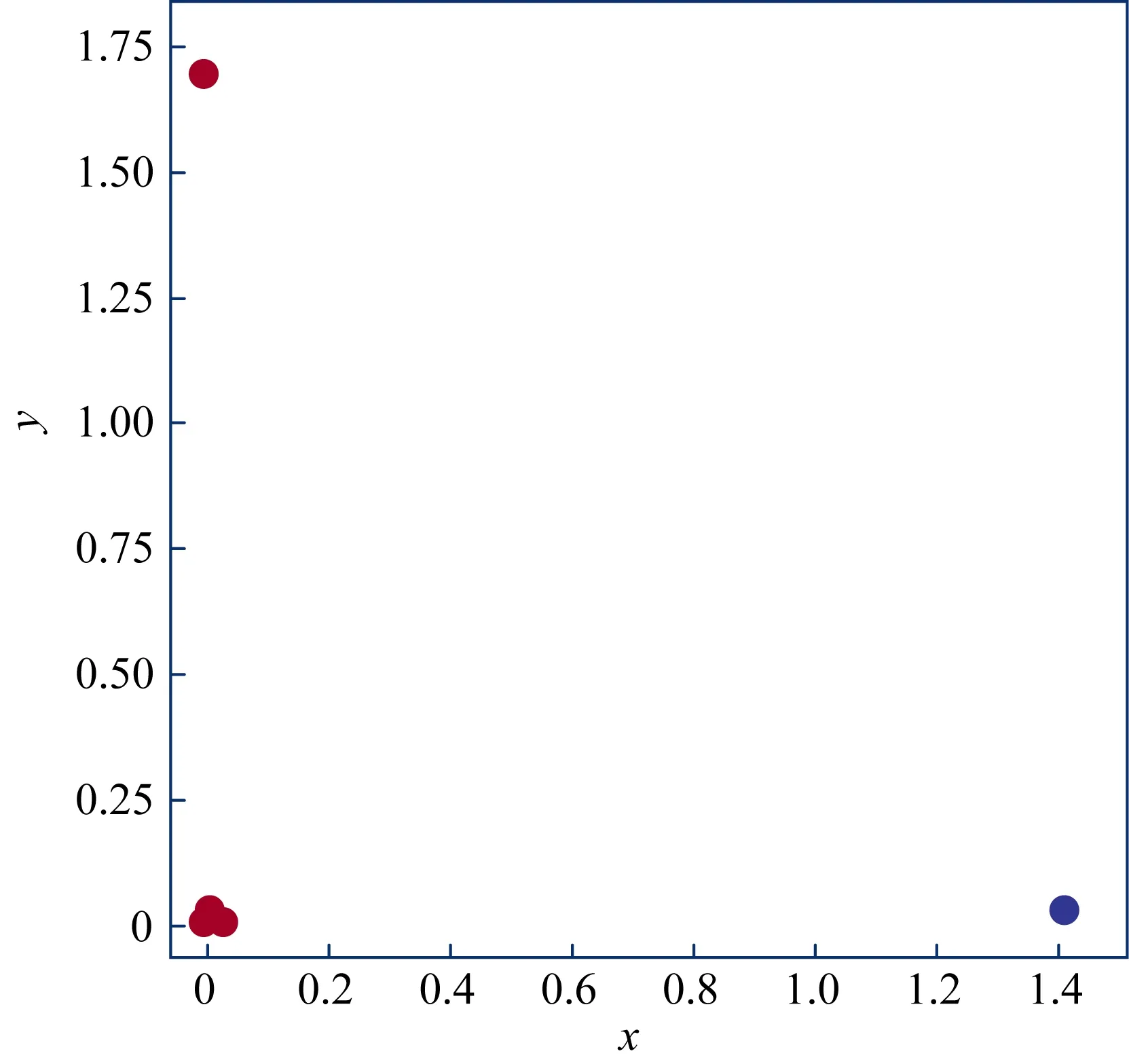
图3 与账户类别有关的PCA 2维散点图
2.2 特征选择模块
基于树的模型可以用来评估特征重要性,特征J的全局重要度[12]是特征J在单棵树中的重要度的平均值,计算公式如式(1)所示:
(1)
其中M为树的数量.特征J在单棵树中的重要度[12]如式(2)所示:
(2)
其中L为树的叶子节点数量,L-1即为树的非叶子节点数量(构建的树都是具有左右孩子的二叉树);vt为与节点t相关联的特征.
LightGBM使用Split和Gain这2个重要指标量化模型所训练的所有特征的重要性.Gain用来衡量使用该特征进行分裂后带来的总增益,Split则表示使用该特征进行分裂的分裂次数.本文采用Gain(信息增益)作为特征重要性衡量指标,输出结果为30×2矩阵,选取排名前30的特征作为新的特征子集:第1列为特征,第2列为以Gain为衡量指标的重要性值.特征选择伪代码如算法1所示:
算法1.特征选择算法.
输入:训练集Q={X_train,Y_train}、测试集T={X_test,Y_test}、特征集F={f1,f2,…,fm};
输出:特征重要性排序.
begin
forF不为空 do
使用特征集F以LightGBM算法训练模型;
计算各个特征Gain值;
对特征Gain值进行排序,Newrank=sort(Rank);
更新特征排序列表,Update(L)=L+F(Newrank);
删除贡献值为0的特征,Update(F)=F-F(Newrank);
end for
end
2.3 分类评估模块
本模块主要工作内容为模型训练,并通过基于网格搜索的参数调优实现模型优化,最终得到最佳模型.由于本文采用的数据集较小,所以引入网格搜索法通过穷举法遍历参数列表,对参数自动进行排列组合,从而筛选出最佳参数组合.其原理是:首先选择当前对模型影响最大的参数进行调优,每组参数都采用10倍交叉验证来评估,通过给定取值区间,按照顺序进行搜索,直到最优,再对下一个影响较大的参数进行调优,以此类推,直至所有的参数调优结束,选出最佳参数组合.参数max_depth和n_estimators用来防止模型陷入过拟合状态,提高模型适应能力.函数输入为LGBM分类器需要优化的参数,输出为10倍交叉验证的模型精度.网格搜索参数调优伪代码如算法2所示.本文调整的参数及参数说明如表2所示.

表2 被调参数说明
算法2.网格搜索调优算法.
输入:训练集Q={X_train,Y_train}、测试集T={X_test,Y_test}、参数列表max_depth=[2,3,4,5,6,7,8],n_estimators=[100,150,200,250,300];
输出:grid_result.best_params,grid_result.best_score,grid_result.scores.
begin
使用LightGBM算法训练模型;
函数GridSearchCV实现网格搜索与10倍交叉验证同步进行;
使用网格参数对数据进行训练;
计算准确率score;
end
算法2输入为LightGBM分类模型需要优化的参数max_depth和n_estimators,将数据集均分为10组,每次随机选择1组作为测试集,其余9组作为训练集,每组超参数进行10次评估,得到10个准确率,最终选择最优参数组合建立模型,输出结果为grid_result.best_params(交叉验证中取得最佳准确率的参数组合),grid_result.best_score(交叉验证中取得的最佳准确率),grid_result.scores(不同参数组合下的准确率).
3 实验结果分析
3.1 评价指标
本文实验主要采用混淆矩阵(confusion matrix)、准确率(Accuracy)、精准率(Precision)、召回率(Recall)、F1和ROC曲线AOC作为二分类异常检测效果的评价指标.分类结果混淆矩阵如表3所示:
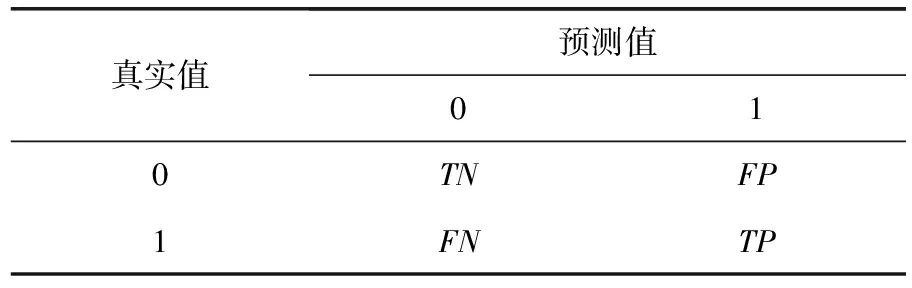
表3 分类结果混淆矩阵
Accuracy,Precision,Recall,F1具体定义如式(3)~(6)所示:
(3)
(4)
(5)
(6)
ROC曲线以及AUC定义如下:ROC曲线的横坐标为假正例率(FPR),纵坐标为TPR(真正例率);AUC为ROC曲线下的面积.FPR,TPR具体定义如式(7)(8)所示:
(7)
(8)
3.2 实验环境
本文采用编程语言为Python,操作系统为Windows10,64位,处理器为Intel®CoreTMi7-1065G7 CPU@1.30GHz,处理器频率为1.50GHz,16GB内存.
3.3 实验结果展示
3.3.1 本文方法的功能实验
在2.2节中提到本文采用Gain作为特征重要性衡量指标,特征重要性排名如图4所示.排名前3个特征分别为Total_Ether_Received,Time_Diff_between_first_and_last(Mins)和Avg_Value_Received.通过网格搜索交叉验证,本文确定了2个超参数max_depth和n_estimators的最佳值分别为8和200,具体描述见2.3节,最终LightGBM异常检测模型参数设置如表4所示:

图4 特征重要性排名

表4 参数设置
如图5所示,混淆矩阵由10倍交叉验证产生,该模型平均产生了7个假正类和7个假负类,即模型预测为正常账户实为异常账户的数量和模型预测为异常账户实为正常账户的数量.
3.3.2 对比实验
为了更好地验证本文提出的异常检测算法的有效性,将本文模型检测效果与文献[6]提出的随机森林和XGBoost模型进行对比,如表5所示,本文提出的算法平均准确率、精准率和召回率均为0.97,检测效果最好.

表5 本文算法与其他算法检测效果对比
4 结 语
为检测异常交易账户,本文提出了基于LightGBM算法的异常交易检测方法.使用分为“正常”和“异常”账户的平衡数据集,采用GBDT(梯度提升决策树)作为基模型进行特征选择,网格搜索10倍交叉验证确定了2个模型参数max_depth和n_estimators的最优值,分别为8和200.实验表明,本文提出的LightGBM模型在10倍交叉验证中准确率、召回率和AUC等方面明显优于现有的XGBoost和随机森林方法,同时大幅提高了训练效率.未来将探索搭建区块链平台,搜集更多数据对模型进行训练,选取新的特征选择方法提高检测性能,设计新的异常检测模型或异常检测算法.
