基于内容生成与特征提取的图像情感识别模型研究
2023-09-06尹朝
尹 朝
(广州华商学院,广东 广州510000)
图像情感分析是挖掘情感信息的重要方式。根据图像情感分析结果,可实现从不同角度刻画人类情感变化,辅助人类进行推理、创造、决策等活动,创造更大的经济效益和社会效益。因此,对图像情感进行分析具有重要的意义。目前,常用的图像情感分析方法是从图像模态对图像情感进行分析,如杨松等[1]提出一种基于底层特征和注意力机制的图像情感分类模型:Featurs Net模型,通过充分融合图像的CLAHE 颜色特征和Laplacian 纹理特征,并将其作为模型输入,同时引入CBAM 注意力机制对图像重点区域进行关注,实现了艺术图像情感分析。该模型在艺术图像数据集上的图像情感分析准确率可达到93%,具有良好的实用性;李志义等[2]利用改进的卷积网络模型对图像的颜色和纹理特征进行训练,可实现对图像情感特征的自动抽取,为图像情感分析奠定了基础;Jayanthi 等[3]通过综合考虑人脸静态图像和语音调制情况,采用深度分类器融合方法,提出一种静态图像情感识别方法,可有效识别图像情感,识别准确率达到91.49%。通过上述研究可以发现,目前图像情感分析方法主要集中在从图像模态进行图像情感分析,而图像实际上包含了多种模态信息,除了图像模态信息,还包括文本模态信息,但目前从文本模态上分析图像情感的研究少于从图像模态分析图像情感的研究。因此,本研究提出一种针对图像文本的情感分析方法,利用图像内容生成模型获取图像并生成描述图像的文本内容,然后采用BERT (Bidirectional encoder representation from transformer)模型提取文本内容特征,接着利用SR 样本精选模型对BERT 模型提取的特征进行精选,获取高质量的样本BERT 特征,最后利用分类模型进行图像情感分析。
1 基本算法
1.1 图像内容生成模型
图像内容生成是将图像转化为一段描述性文字的过程。其主要通过提取图像特征,并利用卷积神经网络寻找可能存在的目标,再利用相应的规则将目标生成图像内容,实现对图像的文字描述。本研究选用基于注意力机制的图像内容生成模型生成图像文本内容[4]。其主要由编码器和解码器构成,基本结构如图1所示。其中解码器利用LSTM 网络生成描述文本。此外,为确保所有特征向量子集均来自图像关键区域,引入注意力机制分配图像中的语义权重。

图1 基于注意力机制的图像内容生成模型Fig.1 Image content generation model based on attention mechanism
1.2 BERT模型
BERT 模型的基本结构如图2 所示,基模型为Transformer 模型的编码器,通过多头自注意力机制进行文本表示[5]。图2 中,E1~EN表示文本向量化,Trm为Transformer模型编码器结构,TN表示输出。
Transformer 模型编码器结构如图3 所示,包括两层残差&归一化层,以及前馈网络、多头自注意力层、输入层,可实现不同任务并行处理[6]。
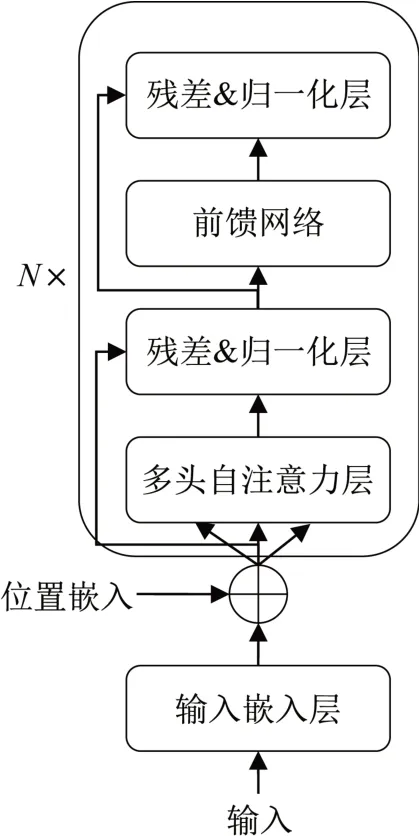
图3 Transformer编码器结构示意图Fig.3 Structural diagram of transformer encoder
2 图像情感分析模型构建
本研究提出的图像情感分析,其核心思路是利用图像内容生成模型生成描述图像的文本内容,再采用BERT 模型提取文本内容特征;然后利用样本精选方法对BERT提取的特征进行精选,获取高质量的BERT特征;最后利用分类器对图像情感进行分类,实现情感分析。其中,本研究使用的图像内容生成模型则采用事先在COCO数据集上预训练好的模型。
2.1 基于BERT的图像内容文本特征提取
BERT 的图像内容文本特征提取采用COCO 训练集上预训练好的BERT-base 和BERT-wwm 语言模型[7-8]。其中,BERT-base 的特征提取采用的是12 个Transformer 编码块;BERT-wwm 特征为全词MASK 特征,是指一个完整的句子被分为若干个子词,而在进行样本训练时,这些子词又被随机MASK。BERT 的图像内容特征提取流程如图4所示。
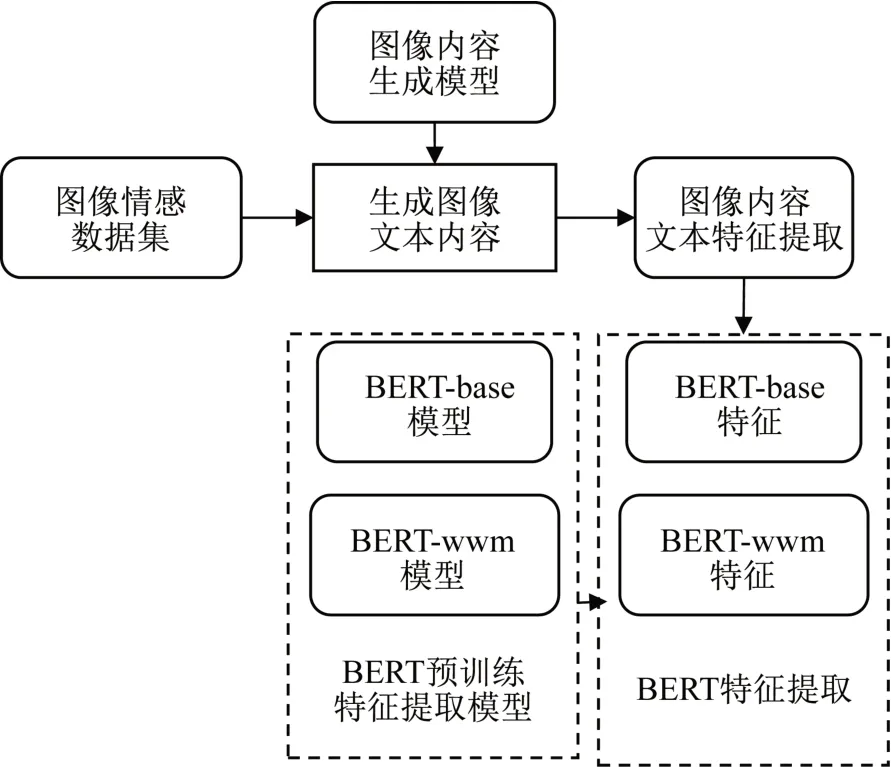
图4 BERT模型提取图像内容特征Fig. 4 Image content features extracted by BERT model
2.2 BERT样本特征精选
为提高图像情感分析的准确性,在2.1 节图像文本内容特征提取的前提下,参考武晋鹏[9]的精选算法,对BERT 样本特征进行精选,便于从原始图像数据集中获取高质量的图像样本,具体步骤为:
(1)输入多个图像数据集,以D1和D22个图像数据集为例。假设D1数据集中图像样本质量低于D2数据集中图像样本质量,且D1包含D2数据集,则从D1中删除D2中全部图像样本,得到D1-2数据集,称为候选数据;
(2)采用一组分类器对D2数据集进行预测。为避免数据集中的内容存在歧义,使用9 种不同分类器进行预测,并通过软投票方式对D2数据集中的每个图像进行预测;
(3)利用D2 数据集训练模型,并对D1-2 候选数据集进行测试,即可从候选数据集中精选出良好的图像样本,标记为Dsr,表示样本精选;
(4)最后,将Dsr 与D2 数据集进行合并,即可得到高质量的图像样本。
2.3 图像情感分析模型构建
在图像文本特征提取和精选的背景下,构建一个多分类器的图像情感分析模型,具体如图5所示。
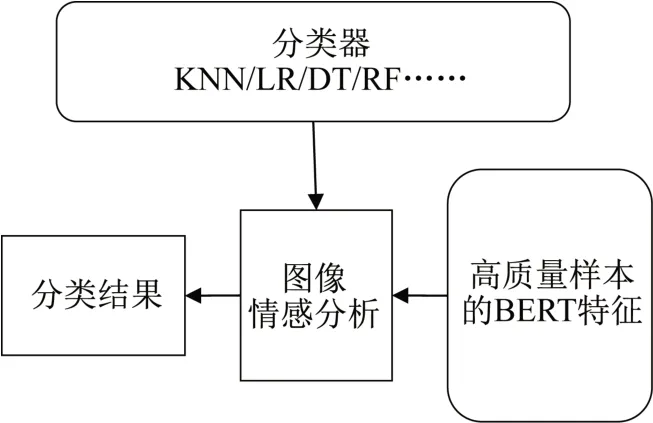
图5 多分类器的图像情感分析Fig. 5 Image emotion analysis based on multiple classifiers
在图像情感分析中,由于采用多个分类器,因此可通过枚举实验对图像样本的情感进行分类,如2 个分类器的分类结果与标签一致,则标记为2;3 个分类器的分类结果与标签一致,则标记为3,以此类推。最后,利用最优分类器组合实现图像情感的分类。
3 仿真实验
3.1 实验环境搭建
本次实验在Linux Ubuntu 操作系统上进行,在MATLAB R2018b、Python3.7 软件和Tensorflow 深度学习框架上实现。系统配置I7-10700 CPU,2080TI GPU。
3.2 数据来源及预处理
本次实验数据集来自AMT 公司标注的图像情感分析数据集:Twitter1 数据集和FI 数据集。其中,Twitter1数据集为二分类数据集,包括正面和负面情感2 个类别,由5 名AMT 员工进行情感极性标注分类。其中,正面情感类别中含有图像共769 张,负面情感中含有图像500张。每张图像的情感极性标注包括3种,分别是“全部同意”、“至少4 人同意”和“至少3 人同意”,分别包括581张、689张、769张图像。
FI数据集是多分类数据集,包括生气、娱乐、敬畏、满足、厌恶、兴奋、恐惧、悲伤8 个情感标签,分别包括1266 张、4942 张、3151 张、5374 张、1685 张、2963 张、1032 张、2922 张图像。每张图像的情感极性标注与Twitter1 数据集的标注相同,分别包括5238 张、12644张、21508张图像[10]。
3.3 评价指标
本次实验选用正确率(Acc)评估模型识别性能,并在计算正确率的基础上,分别计算分类器的平均正确率(FAcc)和特征的平均正确率(TFAcc)。以上计算公式为[11]
上式中,TP表示分类正确的阳性样本数;TN表示分类正确的阴性样本数;FP表示分类错误的阳性样本数;FN表示分类错误的阴性样本数;Nclassifier为分类器数量;Nfeature为特征数量。
3.4 结果与分析
3.4.1 基于BERT特征的图像情感分析
为比较不同特征提取及分类器的图像情感分析结果,联合KNN、SVM、GBDT、LR、RF、DT、NB、Ada 等8种分类器在Twitter1 和FI 数据集上进行分析,结果如图6 所示。由图6(a)可知,BERT-wwm 特征在Twitter1数据集上的平均正确率最高,达到72%,在FI数据集上的平均正确率也较高,为64%;由图6(b)可知,LR分类器在Twitter1数据集上和FI数据集上的平均正确率最高,分别达74.2%和59.1%。DT分类器在Twitter1数据集和FI 数据集上的平均正确率最低,约为65.0%和47.3%。由此说明,BERT-wwm特征的图像情感分析准确率最高,选择BERT-wwm的特征提取方法较为合适。
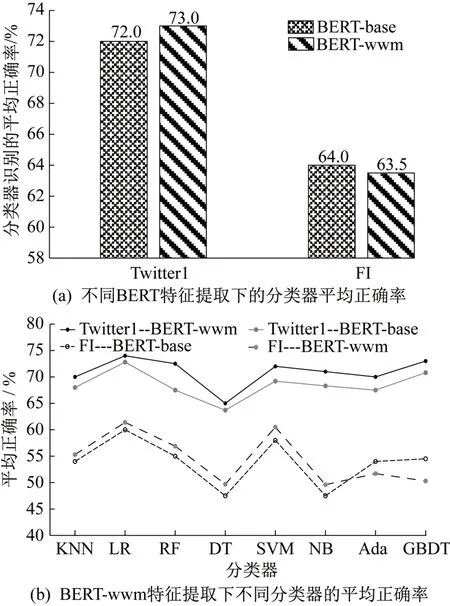
图6 不同特征在不同分类器下的平均准确率Fig. 6 Average accuracy of different features under different classifiers
为更形象地区别BERT-wwm 和BERT-base 2 种特征提取下的分类差异,利用t-SNE 技术对样本特征的分类进行可视化,结果如图7 所示。由图7 可知,BERT-base 和BERT-wwm 的样本特征分布都较为集中,但BERT-wwm 特征分布更紧密些。因此,进一步说明选用BERT-wwm特征的合理性。

图7 不同特征可视化结果Fig.7 Visualization results of different features
3.4.2 基于内容生成与BERT-wwm 特征精选的图像情感分类
为验证本研究构建的图像情感分析模型的有效性,基于BERT-wwm 特征,并结合情感极性标注中采用的多种策略进行样本精选分类,得到表1和图8的结果。
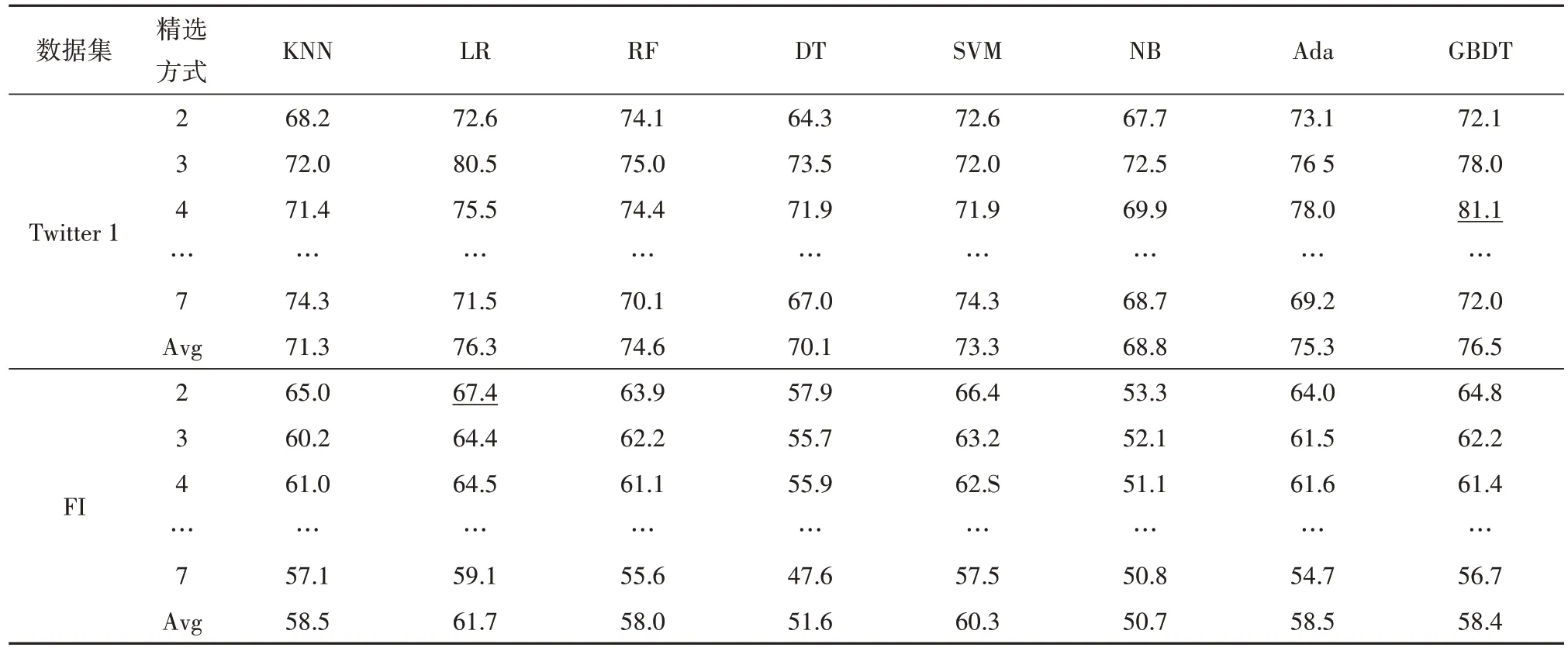
表1 本研究构建的图像情感分析模型的识别结果/%Tab.1 The recognition results of the image emotion analysis model constructed in this study/%
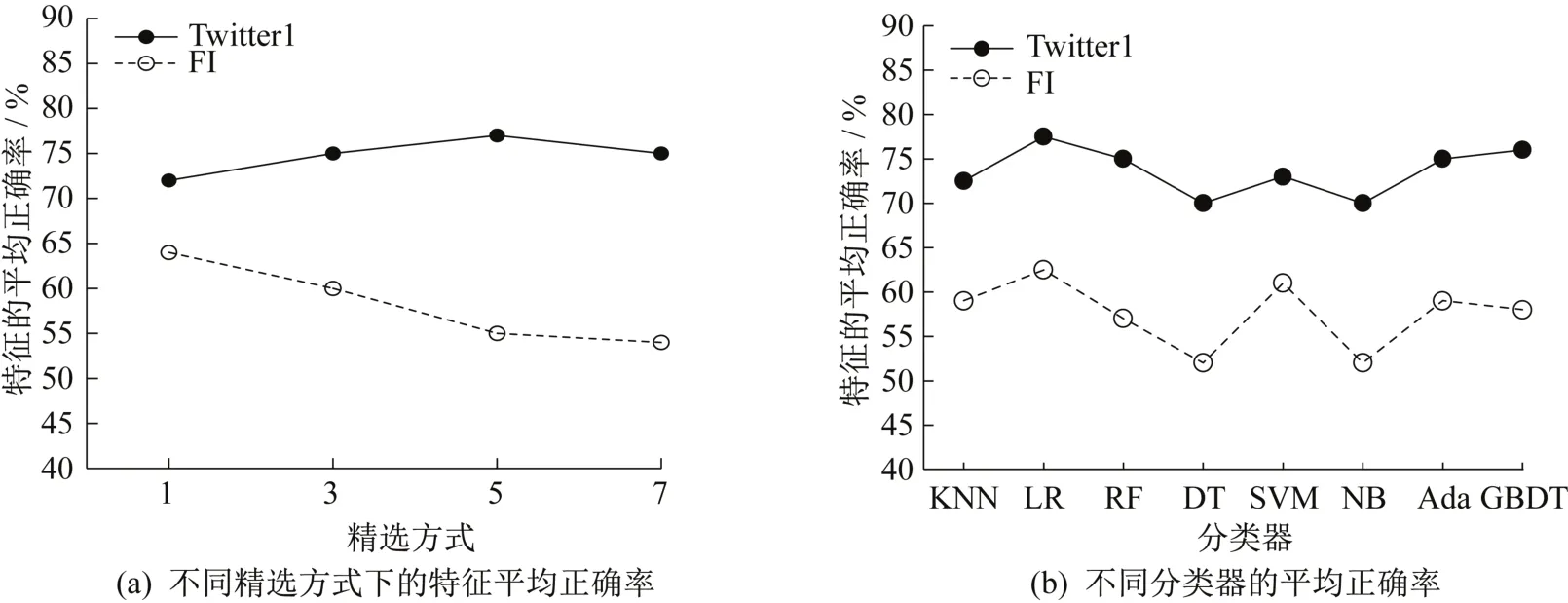
图8 特征平均正确率Fig. 8 Average accuracy of features
由表1 可知,在Twitter1 数据集上,采用精选方式4 并使用GBDT 分类器得到的图像情感分析准确率最高,为81.1%;采用精选方式2,并使用DT 分类器得到的图像情感分析准确率最低,为64.3%。在FI数据集上,采用精选方式2 并使用LR 分类器得到的图像情感分析准确率最高,为67.4%,采用精选方式7 并使用DT 分类器进行情感分析的准确率最低,为47.6%。由此说明,在Twitter1 数据集上精选方式不宜过宽松或过严格,精选方式5 较为合适;在FI 数据集上精选方式应尽量严格,即精选方式7 较为合适。
图8为BERT-wwm特征精选下不同精选方式的平均正确率。由图8(a)可知,Twitter1 数据集上精选方式5 的平均正确率最高,在FI 数据集上精选方式2 的平均正确率最高。因此,在Twitter1 数据集上采用精选方式5,在FI 数据集上采用精选方式2 较好。图8(b)为分别采用精选方式5 和精选方式2 在Twitter1 数据集和FI数据集上不同分类器的平均正确率。由图8(b)可知,GBDT 模型和LR 模型的平均正确率最高,NB模型的平均正确率最低。
综上所述,对Twitter1 数据集应选用较为松散的精选方式;对FI数据集应选用较为严格的精选方式。
同时,为验证本研究构建的图像情感分析模型性能,分析不同分类器在BERT-wwm 特征下的平均正确率变化和最高正确率变化,结果如图9所示。由图9可知,BERT-wwm 特征的样本精选方式可提高识别的正确率,且对FI 数据集的提升效果更好。其中,在Twitter1 数据集,Ada 对平均正确率的提升幅度最大,为5.46%,GBDT 对最大正确率的提升幅度最大,为11.63%;在FI 数据集上,KNN 对平均准确率和最大准确率的提升幅度最大,分别为5.31%和12.63%。由此说明,BERT-wwm 特征对样本精选模型有效,通过选择适当的分类器可较大幅度地提升模型识别性能,可验证图像情感分析模型的有效性。
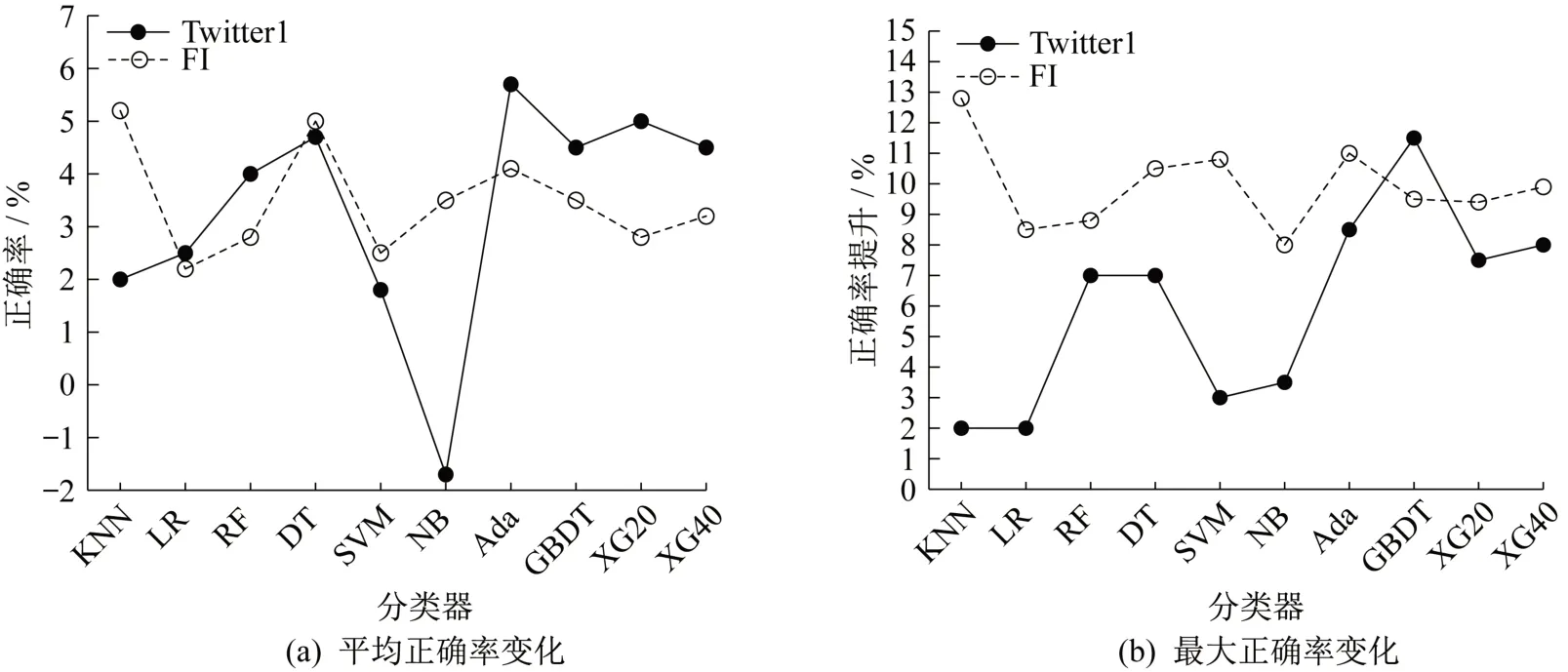
图9 样本精选相对提升幅度Fig. 9 Relative increase of sample selection
3.4.3 分析模型对比
为验证本研究图像情感分析模型的优越性,与常用的CCA、GS-XGB 等主流图像情感分析模型进行对比,结果如表2 所示。由表2 可知,在Twitter1 数据集上,SPN模型的识别正确率最高,为81.37%,本研究图像情感分析模型的正确率为81.10%,略低于SPN 模型,但优于其他模型;在FI 数据集上,本研究模型的正确率最高,为67.40%,高于其他对比模型。综合来看,本研究图像分析模型具有一定的优势。

表2 不同模型识别正确率对比/%Tab. 2 Comparison of recognition accuracy of different models /%
4 结 论
综上所述,本研究构建的图像情感分析模型,基于注意力机制的图像内容生成模型生成图像文本内容,并采用BERT提取图像生成文本内容特征,然后通过样本精选,获取高质量的BERT-wwm图像特征,最后训练不同分类器,实现了图像情感的分析,具有较高的正确率。相较于CCA、SPN、FTR101等常用图像情感分析模型,本研究模型对图像情感分析的正确率最高,在Twitter1数据集上的识别准确率达到81.1%,在FI数据集上的识别准确率达到67.4%,具有一定的优越性和实用性。本研究的创新是实现了文本模态到图像模态情感的分析。但由于条件限制,正确率仍有待进一步提高。
