特征增强的多尺度视觉转换器在遥感图像场景分类中的应用
2023-09-05齐晶胡敏张京波
齐晶 胡敏 张京波
特征增强的多尺度视觉转换器在遥感图像场景分类中的应用
齐晶1,2胡敏2张京波3
(1 航天东方红卫星有限公司,北京 100094)(2 航天工程大学航空宇航科学与技术学院,北京 102206)(3 北京空间科技信息研究所,北京 100094)
传统的基于卷积神经网络的卫星遥感图像场景分类方法忽略了场景图像的全局语义特征以及遥感图像在多个尺度上的鉴别特征。针对此问题,文章在视觉转换器和多尺度特征的基础上,提出了一种基于特征增强型多尺度视觉转换器的遥感图像场景分类方法。该方法采用双分支结构在2个尺度上对遥感图像进行分块,获取到不同大小的图像块,首先利用位置编码和转换器分别对2个尺度下的图像块进行特征学习,再利用通道注意力机制对转换器输出的图像块进行特征增强,最后将2个尺度上学习出的分类标记和增强后的特征进行融合决策,从而实现遥感图像场景分类。采用国际公开的光学遥感图像数据集AID和NWPU-RESISC45进行实验验证,结果表明该方法在AID数据集的场景分类准确率达到(95.27±0.39)%,在NWPU-RESISC45数据集的场景分类准确率达到(92.50±0.14)%,其分类性能优于CaffeNet、VGG、GoogLeNet和ViT等基准方法。该研究成果提升了模型对全局语义和多尺度特征的感知能力,对于提升卫星遥感图像场景分类技术在土地监测、城市规划等方面的应用具有重要意义。
遥感图像 场景分类 深度学习 视觉转换器 多尺度特征 通道注意力
0 引言
场景分类是卫星遥感图像解译应用中的关键技术,该技术旨在根据卫星遥感图像场景内容自动地对场景进行语义分类,为卫星遥感图像解译提供辅助判读。传统的卫星遥感图像场景分类方法多是使用人工特征进行场景的特征描述,难以解决高层语义信息与低层特征之间的语义鸿沟,进而难以提取出能够应对卫星遥感图像场景复杂多变的特征表示。
随着卷积神经网络(Convolutional Neural Networks, CNN)在自然语言处理和计算机视觉等领域中的广泛应用,基于CNN的卫星遥感图像场景分类方法也被深入研究。文献[1]提出了AID航空场景分类数据集,验证了CNN较传统人工特征方法的优势与有效性。文献[2]提出了NWPU-RESISC45遥感卫星图像场景数据集,在更大规模数据量和更复杂多变条件下比较了CNN与人工特征方法的场景分类性能。文献[3]提出了多层堆叠协方差池化(Multilayer Stacked Covariance Pooling,MSCP)方法,该方法将CNN提取的多层特征层进行堆叠,再计算堆叠特征的协方差,最后利用支持向量机进行分类。文献[4]提出了多尺度深度特征表示(Multi-Scale Deep Feature Representation,MDFR)方法,该方法从预训练的卷积神经网络提取多尺度的深度特征并进行特征融合用于最终的遥感场景分类。文献[5]采用多实例学习方法,提出了一种多实例密集连接卷积神经网络(Multiple-Instance Densely-Connected ConvNet,MIDC-Net),该网络在深度特征学习过程中考虑了场景内容的局部语义信息,增强了遥感图像场景深度特征的表征能力。文献[6]提出了一种基于残差注意力的密集连接卷积神经网络(Residual Attention based Dense Connected Convolutional Neural Network,RADC-Net),该方法使用注意力机制和密集链接关注到与遥感图像场景语义相关的局部特征,从而学习出更具鉴别性质的特征。文献[7]使用了基于ReLu激活函数的特征融合(ReLU-Based Feature Fusion,RBFF)策略,利用迁移学习实现了遥感场景分类。文献[8]提出了基于自注意力的深度特征融合(Self-Attention-based Deep Feature Fusion,SAFF)方法,该方法首先使用预训练的卷积神经网络模型提取卷积特征,再利用空间维度和特征维度上的特征响应进行加权融合,最后用于遥感场景分类。文献[9]设计了一种多级双工融合网络(Multi-Stage Duplex Fusion Network,MSDF-Net),该模型融合了残差和密集链接,以双工形式增强了场景语义特征的表示能力。这些方法在卫星遥感图像场景分类中取得了较好的分类性能,但是没有考虑场景图像内部的长距离依赖关系,这些关系对于提升遥感图像场景的语义特征表达具有重要作用。
最近,转换器(Transformer)模型的兴起为探索图像内部长距离依赖关系提供了新的思路。文献[10]通过将一些卷积层替换为自注意力(Self-attention)层来增强深度特征的全局感知能力,验证了长距离依赖关系有助于提升图像分类性能。文献[11]提出了视觉转换器(Vision Transformer,ViT)模型,该模型将图像分块,引入一个可学习的分类标记,利用基于多头自注意力机制的Transformer编码器将其与图像块一起进行特征学习,将学习到的分类标记作为整个图像的最终特征表示,同时挖掘了图像的长距离依赖关系,取得了较CNN更好的分类能力。需要指出,该模型已成为计算机视觉领域最具代表性的转换器方法。文献[12]在ViT的基础上引入了多尺度特征学习并在自然场景图像分类中取得较好的应用效果。尽管这些方法取得了较CNN明显的优势,但这些方法更多是利用分类标记作为最终特征表示,忽略了特征学习后图像块之间的相互关系,而这些图像块之间的相关关系很大程度上能够进一步增强图像的特征表示能力。
因此,本文提出一种基于多尺度视觉转换器的卫星遥感图像场景分类方法,该方法旨在利用视觉转换器挖掘卫星遥感场景图像的多尺度特征表示能力,同时使用视觉转换器学习出的图像块特征及其依赖关系补充转换器的分类标记进行决策,从而提升整个场景图像的特征鉴别能力。具体地,首先使用大尺度和小尺度的双分支结构对遥感场景图像进行分块,利用转换器编码器对2个尺度下的图像块和分类标记进行特征学习,并使用SE通道注意力[13]对学习出的图像块特征进行进一步特征增强,最终同时使用分类标记和增强后的图像块特征联合进行卫星遥感图像的场景分类。
1 研究方法
考虑到整个遥感场景图像在2个尺度上变化较明显,因此,本文所提遥感图像场景分类方法的处理流程由2个尺度分支构成,即大尺度和小尺度分支,如图1所示。

图1 本文方法的处理流程
在2个分支上分别进行图像分块处理,获得各个尺度下对应的图像块,对各图像块及其对应的空间位置和分类标记(class token)进行嵌入,再利用个多尺度Transformer编码器对嵌入的图像块和分类标记进行特征学习。每个多尺度Transformer编码器包含个大尺度编码器、个小尺度编码器和个交叉注意力模块。每个编码器由归一化层、多头注意力和多层感知机构成,用于学习各嵌入图像块和分类标记的特征表示。为了学习2个尺度上图像块标记(Patch Token)和分类标记的潜在依赖关系,利用交叉注意力模块(Cross Attention Module)实现2个尺度分支上的特征交互,从而捕获图像的多尺度全局语义特征。不同于传统ViT只适用于将分类标记用于分类,本文还考虑了2个尺度分支上的各图像块标记特征。为进一步挖掘有利于分类的图像块标记特征分量,本文使用SE通道注意力[13]学习出显著的特征分量,增强各图像块标记特征,最终通过池化层处理得到2个尺度上该场景图像的特征表示,通过串联融合方式送入交叉熵损失函数用于训练。此外,对于2个尺度输出的分类标记,利用多层感知机进行处理,最后也通过串联融合方式送入交叉熵损失函数。由此,整个模型通过基于图像块标记(Patch Token)的交叉熵损失函数和基于分类标记(Class Token)的交叉熵损失函数进行模型训练。
1.1 图像块嵌入
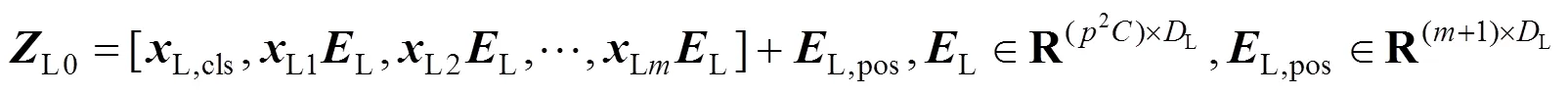

1.2 多尺度转换器编码器


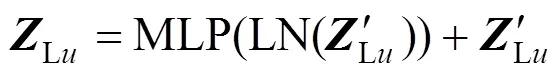



图2 交叉注意力模块

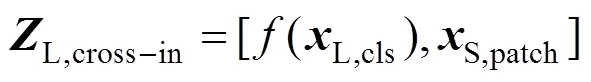





同理,可获得通过交叉注意力模块处理的小尺度分支最终输出

1.3 特征增强及分类





2 实验结果与分析
2.1 数据集
实验使用了2个国际公开的卫星遥感场景图像数据集AID[1]和NWPU-RESISC45[2]用于评估所提方法的分类性能。这2个数据均具备数据量大、类别多、场景变化大等特点,其中AID数据集共10 000张卫星遥感场景图像,包含30个场景类别,每个图像大小为600像素×600像素,空间分辨率变化范围在0.5至8 m。NWPU-RESISC45卫星遥感场景图像数据集包含45个场景类别,每类有700个场景图像,每个图像大小为256像素×256像素,空间分辨率变化范围在0.2~30 m。
2.2 实验设置
为了对比试验,本文和以往基准方法[1-9]保持了相同的训练-测试比率,即从AID数据集中每个类别的图像中随机选择20%进行训练,其余80%作为测试,此外还将AID的训练测试集比率设为50%︰50%。对于NWPU-RESISC45数据集,选取10%当作训练集剩余90%当作测试集,此外还将NWPU-RESISC45数据集的训练测试比率设置为20%︰80%。与基准方法一致,本实验采用总体准确率和标准差来评价分类结果。对每个训练测试集重复实验10次,并将测试集上分类结果的总体准确率和标准差作为最终算法比较结果。
对于大小尺度2个分支,本文根据文献[12]的参数设置,大尺度分支的输入图像通过裁剪后尺寸为224像素×224像素,图像块尺寸为16,小尺度分支的输入图像通过裁剪后尺寸为240像素×240像素,图像块尺寸为12,多尺度Transformer编码器数目为3,大尺度编码器数目为5,小尺度编码器数目为1,交叉注意力模块数目为1,多头注意力的个数为6。该实验使用PyTorch深度学习计算框架,硬件环境为Intel Core i7-9700X CPU(3.60 GHz)以及NVIDIA GTX 2080Ti GPU。
2.3 对比实验分析
表1列出了所有方法在AID数据集上的实验结果。可以看到相比较传统的CaffeNet、VGG和GoogLeNet在遥感图像场景分类的结果,MSCP、MDFR、MIDC-Net、RADC-Net、RBFF、SAFF和MSDF-Net在训练比率为20%和50%的条件下均取得了较好的分类效果,表明特征融合以及注意力机制均提升了CNN深度特征的表示能力。同时,ViT整体优于这些方法,说明Transformer学习出的长距离依赖关系有助于增强特征的鉴别能力。值得注意的是,本文方法在训练比率为20%和50%的条件下取得了(92.07±0.31)%和(95.27±0.39)%的分类准确率,优于其他方法,表明该方法通过融合多尺度视觉Transformer特征,提升了模型对多尺度图像内部长距离依赖关系的挖掘,同时通过各尺度上分类标记和图像块标记特征进行联合学习决策,增强了场景图像特征的表征能力,产生了较好的分类效果, 提升了卫星遥感图像场景分类的应用能力。
表1 AID数据集中20%和50%训练比例下的总体准确率和标准差
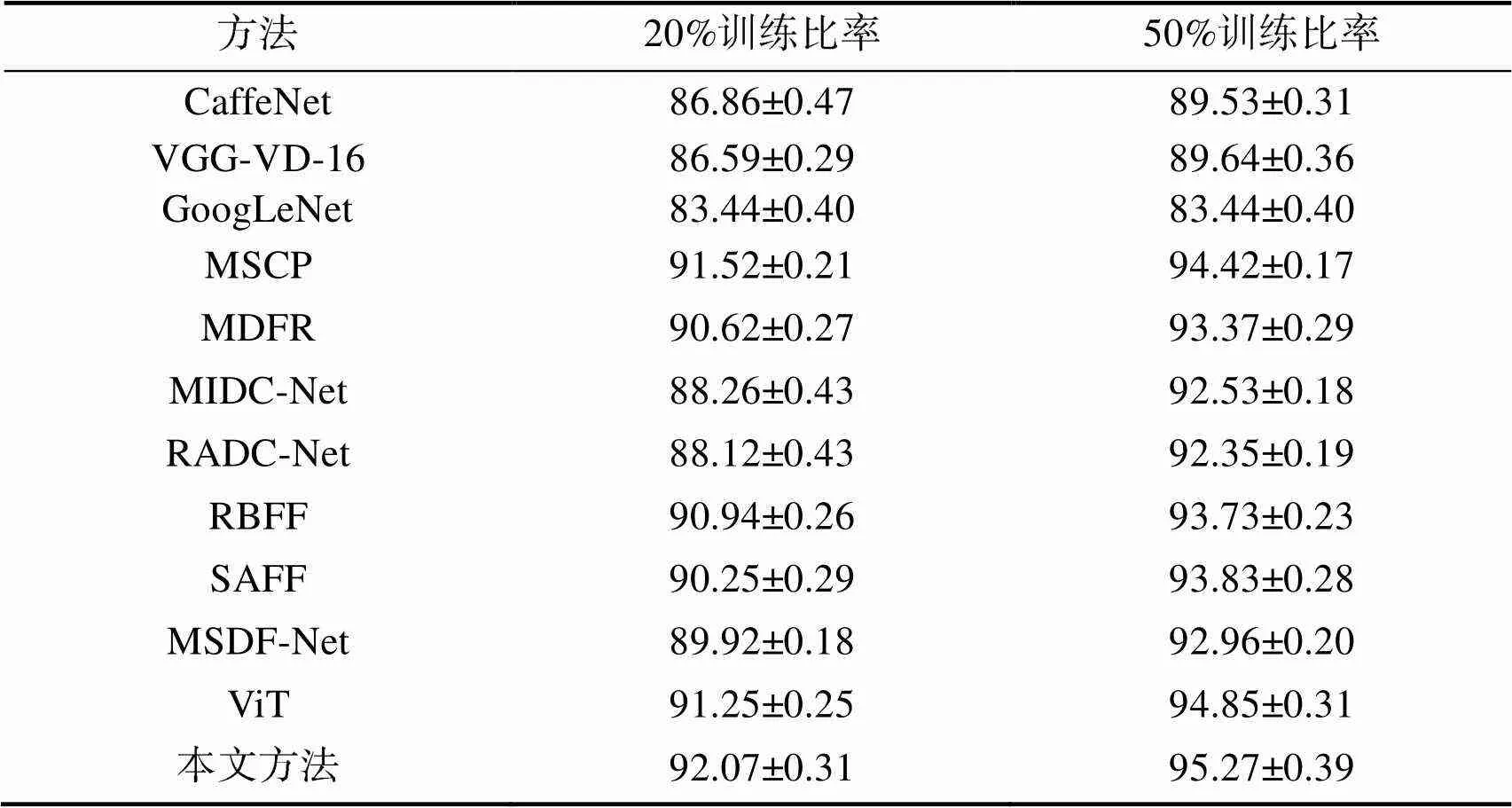
Tab.1 STDs and overall accuracies of different methods under 20% and 50% training ratios in the AID dataset 单位:%
表2是训练比率为10%和20%条件下所有方法在NWPU-RESISC45数据集的分类结果。相比较AID数据集,NWPU-RESISC45数据集数据量较大、场景变化条件更大,因此所有方法的分类识别结果均整体低于AID数据集结果。由表2可以看到,MSCP、MDFR、MIDC-Net、RADC-Net、RBFF、SAFF和MSDF-Net在训练比率为10%和20%条件下的分类性能整体优于经典的场景分类方法CaffeNet和GoogLeNet。特别地,VGG的分类效果优于CaffeNet、GoogLeNet、MSCP、MDFR、MIDC-Net、RADC-Net、RBFF、SAFF和MSDF-Net,这表明在NWPU-RESISC45数据集上VGG特征具有较强的鉴别能力。此外,ViT的分类效果优于以上基于CNN的场景分类方法,说明在分辨率、场景内容及场景类别等变化因素更多的条件下,Transformer学习到的特征更加有效。同时,本文方法依然优于其他方法,在2种训练比例上分别达到了90.17%和92.5%的准确率,分别优于其他方法4.45%~6.8%和3.57%~5.56%,说明本文方法充分考虑了遥感场景图像在多尺度上的长距离依赖关系以及Transformer编码器中分类标记和图像块标记联合表征能力,因此取得了较好的分类识别结果。另外,本文方法识别结果的标准差较小,也反映出所提方法更加稳定鲁棒,有助于卫星遥感图像场景分类的实际工程应用。
表2 NWPU-RESISC45数据集中10%和20%训练比例下的总体准确率和标准差

Tab.2 STDs and overall accuracies of different methods under 10% and 20% training ratios in the NWPU-RESISC45 dataset 单位:%
2.4 泛化能力分析
为了验证所提方法在真实遥感场景分类应用中的泛化能力,本文使用GID[14]数据集进行实验验证,该数据集包含了建筑物、耕地、森林、草地和水体5个场景大类共150张图像,大小为6 800×7 200。为进一步研究场景更细粒度分类,该数据集对5个场景大类进行了15个场景子类的细分,即田、灌溉地、旱耕地、花园地、乔木林地、灌木林地、天然草地、人工草地、工业用地、城市住区、农村住区、交通用地、河流、湖泊和池塘。每个类别包含2 000张遥感图像。针对GID数据集的15个子类,本文分别选取每类的10%和20%用于训练,剩下的90%和80%用于测试,实验结果如表3所示。可以看出,本文方法不同训练比率下优于VGG和ViT方法,说明该方法所学习出的多尺度全局语义特征更有利于分类,同时,基于图像块标记的通道注意力机制进一步提升了模型的特征表示能力。
表3 GID数据集中10%和20%训练比例下的总体准确率

Tab.3 Overall accuracies of different methods under 10% and 20% training ratios in the GID dataset 单位:%
3 结束语
本文提出了一种多尺度视觉转换器的卫星遥感图像场景分类方法,该方法使用大小尺度双分支结构对场景图像分块,利用视觉Transformer编码器对大小尺度分支上的图像进行特征编码,同时将2个分支上学习出的分类标记和图像块标记联合建模用于融合决策,从而实现卫星遥感图像场景分类。在国际公开的2个场景图像分类数据集AID和NWPU-RESISC45上表明所提方法具有较好的场景分类能力,同时也验证了多尺度遥感场景图像内部长距离依赖关系以及分类标记和图像块标记的联合学习有助于提升场景图像特征的表征能力。
[1] XIA G S, HU J W, HU F, et al. AID:A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification[J]. IEEE Transactions on Geoscience and Remote Sensing,2017, 55(7): 3965-3981.
[2] CHENG G, HAN J W, LU X Q. Remote Sensing Image Scene Classification: Benchmark and State of The Art[J]. Proceedings of the IEEE, 2017, 105(10): 1865-1883.
[3] HE N J, FANG L Y, LI S T, et al. Remote Sensing Scene Classification Using Multilayer Stacked Covariance Pooling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(12): 6899-6910.
[4] ZHANG J, ZHANG M, SHI L K, et al. A Multi-Scale Approach for Remote Sensing Scene Classification Based on Feature Maps Selection and Region Representation[J]. Remote Sensing, 2019, 11(21): 2504-2523.
[5] BI Q, QIN K, LI Z L, et al. A Multiple-Instance Densely-Connected Convnet for Aerial Scene Classification[J]. IEEE Transactions on Image Processing, 2020, 29: 4911-4926.
[6] BI Q, QIN K, ZHANG H, et al. RADC-Net: A Residual Attention Based Convolution Network for Aerial Scene Classification[J]. Neurocomputing, 2020, 377: 345-359.
[7] AREFEEN M A, NIMI S T, UDDIN M Y S, et al. A Lightweight ReLU-Based Feature Fusion for Aerial Scene Classification[C]//2021 IEEE International Conference on Image Processing, September 19-22, Anchorage, AK, USA, 2021: 3857-3864.
[8] CAO R, FANG L Y, LU T, et al. Self-Attention-Based Deep Feature Fusion for Remote Sensing Scene Classification[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 18(1): 43-47.
[9] YI J J, ZHOU B C. A Multi-Stage Duplex Fusion Convnet for Aerial Scene Classification[C]//2022 IEEE International Conference on Image Processing, October 16-19, Bordeaux, France, 2022: 166-170
[10] BELLO I, ZOPH B, VASWANI A, et al. Attention Augmented Convolutional Networks[C]//2019 IEEE/CVF International Conference on Computer Vision, October 27–November 2, 2019, Seoul, Korea, 2019: 3285-3294.
[11] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale[J]. arXiv 2020, arXiv: 2010.11929.
[12] CHEN C R, Fan Q F, PANDA R. CrossVIT: Cross-Attention Multi-Scale Vision Transformer for Image Classification[C]//2021 IEEE/CVF International Conference on Computer Vision, October 10-17, Montreal, Canada, 2021: 347-356.
[13] HU J, SHEN L, ALBANIE S, et al. Squeeze-and-Excitation Networks[C]//2018 IEEE/CVF International Conference on Computer Vision, June 18-23, Salt Lake City, UT, USA, 2018: 7132-7141.
[14] TONG X,XIA G,LU Q, et al. Land-cover Classification With High-Resolution Remote Sensing Images Using Transferable Deep Models[J]. Remote Sensing of Environment, 2020, 237: 111322.
Enhanced Multi-Scale Vision Transformer for Scene Classification of Remote Sensing Images
QIJing1,2HU Min2ZHANG Jingbo3
(1 DFH Satellite Co., Ltd., Beijing 100094, China)(2 School of Aerospace Science and Technology, Space Engineering University, Beijing 102206, China)(3 Beijing Institute of Space Science and Technology Information, Beijing 100094, China)
Traditional Convolutional Neural Network (CNN)-based methods for scene classification of satellite remote sensing images fail to explore the global semantic features within the scene image and the features at different scales. To address this problem, according to vision transformer (ViT) and multi-scale features, an enhanced multi-scale vision transformer method for scene classification of remote sensing images is proposed in this paper. The two-branch structure is used to divide the entire remote sensing image into patches with different sizes from two scales, and the position encoding and ViT are firstly performed on the patches from at the two scales for feature learning respectively. Then channel attention mechanism is used to enhance the discriminant ability of features generated by patch tokens of ViT. Finally, the class tokens from at the two scales and the enhanced patch features are fused for final scene classification. Experiments on the public optical remote sensing image datasets (AID and NWPU-RESISC45) validate that our method obtains the accuracy of (95.27±0.39)% on AID dataset and the accuracy of (92.50±0.14)% on NWPU-RESISC45 dataset and outperforms other deep learning-based scene classification methods (e.g. CaffeNet, VGG, GoogLeNet and ViT). The researd results improves the awareness capability of model to global semantics and multi-scale features. It is of great importance to satellite remote sensing images scene classification application (e.g. land monitoring and urban planning).
remote sensing image; scene classification; deep learning; vision transformer; multi-scale feature; channel attention
V445
A
1009-8518(2023)04-0079-09
10.3969/j.issn.1009-8518.2023.04.009
2023-01-05
齐晶, 胡敏, 张京波. 特征增强的多尺度视觉转换器在遥感图像场景分类中的应用[J]. 航天返回与遥感, 2023, 44(4): 79-87.
QIJing, HU Min, ZHANG Jingbo. Enhanced Multi-Scale Vision Transformer for Scene Classification of Remote Sensing Images[J]. Spacecraft Recovery & Remote Sensing, 2023, 44(4): 79-87. (in Chinese)
齐晶,男,1987年生,2012年获北京航空航天大学控制科学与工程专业硕士学位,高级工程师。主要研究方向为航天任务分析与设计。E-mail:qijing_004@163.com。
胡敏,男,1983年生,2012年获航天工程大学装备学院发射工程专业博士学位,教授。主要研究方向为航天任务分析与设计。E-mail:jlhm09@163.com。
张京波,男,1984年生,2007年获北京理工大学机械电子工程专业学士学位,高级工程师。主要研究方向为航天软环境研究管理。E-mail:172296668@qq.com。
(编辑:毛建杰)
