图索引结构词袋模型的无人机影像匹配对检索
2023-09-05刘思康郭丙轩鄢茂胜
刘思康,郭丙轩,姜 三,鄢茂胜
(1. 武汉大学测绘遥感信息工程国家重点实验,湖北 武汉 430079; 2. 中国地质大学(武汉),湖北 武汉 430074)
随着无人机的快速发展,无人机影像已成为重要的遥感数据源,并在林业调查[1]、灾区应急[2]、智慧城市[3]等领域得到广泛应用。运动恢复结构(structure from motion, SfM)技术成为无人机影像空中三角测量的标准方案,可直接从重叠影像恢复其位姿和场景三维结构[4-5]。由于影像数据量庞大、位置参数缺失等问题,如何准确、快速地检索出重叠影像对成为提高SfM效率和稳健性的关键问题。
无人机影像匹配像对的检索目的是查询具有空间重叠的影像对。在计算机视觉领域,基于视觉相似性的图像检索是一种常见方法[6-7]。基于词袋模型(bag of words,BoW)检索技术是很多开源SfM框架的首选匹配对查询方法[8]。如Colmap首先利用尺度不变特征变换(scale invariant feature transform, SIFT)算子[9]提取影像描述子;然后采用分层K-means算法生成视觉单词,构建词汇树[10-11];最后采用词汇树的单词-影像倒排索引结构,影像之间相似性采用单词内部描述子之间的汉明距离表示。但计算汉明距离耗时长,且引入很多错误匹配。DBoW(Dorian bag of words)使用词频-逆向文件频率(term frequency-inverse document frequency,TF-IDF)方法对视觉单词进行加权,检索相似影像[12]。该方法利用视觉单词个数和出现该单词的影像个数进行加权,在保证精度的前提下提升匹配像对查找效率。针对大规模匹配像对查找,使用TF-IDF导致检索时浪费大量时间查询相同单词以计算得分。最邻近查找算法中有一系列索引结构,包括哈希表法[13]、树状结构[14]、基于图的索引结构[15]。近年来,基于图的搜索是高维数据最邻近查找趋势,且基于邻近图的近似最邻近搜索方法(ANNS)具有很高的査询效率[16]。文献[17—18]提出了一种基于导航小世界(navigable small world,NSW)的邻近图搜索算法。该算法通过不断向图中插入顶点,从插入顶点出发找到图中最邻近的M个顶点,建立边作为顶点之间链接关系。随着新顶点的插入,开始插入的顶点与最邻近顶点之间的边成为长距离边,从而使图具有可导航性质,具有更高的查询效率。该过程存在大量高维距离计算,GPU有大量的核能够有效地并行高维距离计算,显著改善了其计算效率。
针对上述问题,本文提出一种基于图索引结构词袋模型(graph structure bag of words,GSBoW),实现无人机影像匹配对的高效检索,将训练好的单词作为顶点,边作为顶点间连接关系,设计NSW图索引结构,描述子在GPU端利用NSW图索引结构的最邻近单词查询;提出一种TF-IDF-Match4计算方法,通过填充词频向量、减少访问冲突、采用共享内存、设计特定数据结构,显著提升TF-IDF计算效率;利用3组无人机影像进行试验,以验证本文方案的可靠性。
1 方法原理
本文主要基于图索引结构的词袋模型,实现无人机影像匹配对检索。主要包含5个步骤:①训练数据准备和SIFT特征提取;②利用分层K-means算法对训练描述子进行聚类,生成词袋模型的视觉单词;③以视觉单词为顶点、单词邻接关系为连接边建立NSW图,构建视觉单词的索引结构;④基于NSW图索引结构进行影像描述子最邻近查找,获取对应视觉单词集合;⑤利用改进的TF-IDF-Match4加权方式,计算查询影像与数据库影像的词频向量,通过比较词频向量相似性,实现相似影像检索。其中步骤①—步骤③在CPU端实现;步骤④—步骤⑤在GPU端实现。
1.1 离线导航小世界图索引结构构建
为了构建视觉单词,采用山东省青岛市城区无人机影像为训练数据(如图1所示)。首先,提取数据集中23 261张影像的SIFT描述子,共得到261 709 511个特征描述子。然后,采用分层K-means聚类算法对特征描述子进行聚类。其中,词汇树层数设置为3;词汇树分支数设置为512。建立词汇树后,词汇树的叶子节点即代表所生成的视觉单词。最后,所有视觉单词作为候选顶点集合V,构建视觉单词的NSW图索引结构。主要步骤包括:①从候选顶点V中随机挑选一个顶点vi;②将顶点vi插入图中,寻找图中顶点vi最邻近的f个顶点,若邻近顶点不足f个,则按最大数查找;③建立vi与这些邻近顶点的边连接关系;④重复步骤①—步骤③,直至候选顶点集合为空。构建过程如图2所示。

图1 训练数据集
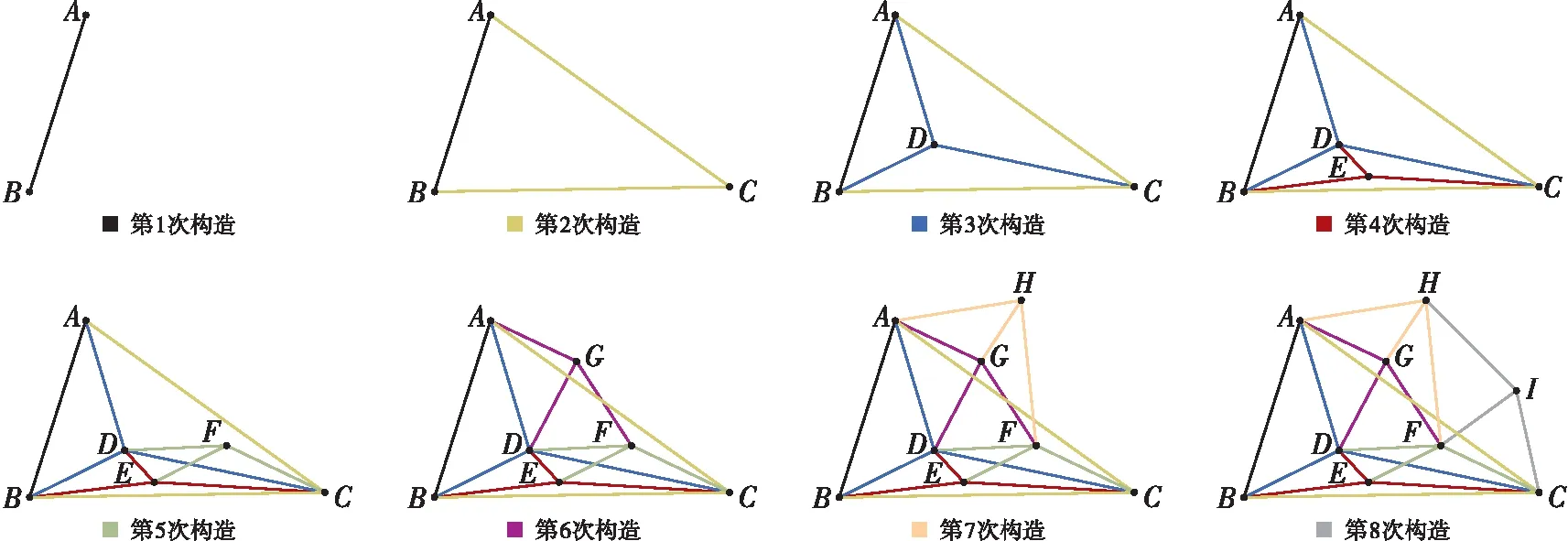
图2 NSW图索引结构构建过程
1.2 基于NSW图索引结构最邻近单词查询
本文基于NSW图索引结构的最邻近查找算法的原理为:默认从索引为G的单词开始,从按照距离降序的优先级队列Q中提取离查询描述子最近的单词,按照距离降序的优先队列Topk中的候选单词顺序更新,并将单词的邻接单词插入Q中,以便于下次查找。当从优先级队列Q中提取的单词距离比搜索到的Topk中距离最大的候选单词更大时,查找循环停止。抽象而言,算法贪婪地沿着一条路径到达查询描述子的最近邻近单词。
在CUDA并行计算架构上,线程束是最基本的执行单元,本文使用一个线程束查找一个描述子的最邻近单词,实现GPU端上描述子的距离计算。GPU并行计算原理如图3所示。①选单词定位:在构建NSW图索引结构时,每个顶点固定连接最邻近的3个顶点,将NSW图索引存储在GPU端,此时需要一个索引即每个顶点的偏移量,存储固定层次图像可消除额外的索引查找,然后乘以固定偏移量定位单词。②批量距离计算:从候选定位单词表中获取对应单词,计算描述子到单词的距离,一个线程束中所有的线程均参与该阶段。每个线程负责一个描述子的4个维度,并行计算128维描述子到单词的距离,最后第1个线程统计所有线程计算结果,并将结果输出到共享内存中的数组。32个线程访问连续存储器地址更容易并行。③数据结构维护:查询过程中多次访问距离、Q、Topk、数组,因此将它们存储到共享内存中,共享内存是流处理器组中的高速内存空间,流处理器访问速度远比全局内存快。
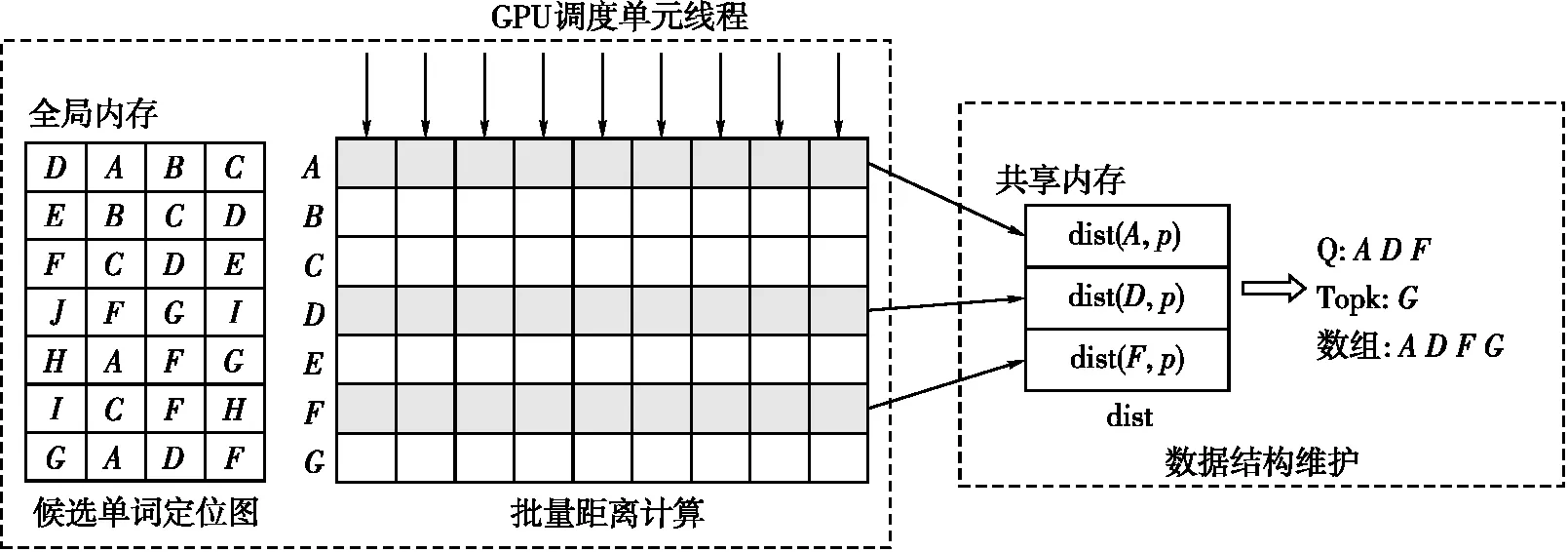
图3 GPU端最邻近查找单词流程
1.3 TF-IDF-Match4计算
对于包含M个单词的导航小世界图,影像可以表示为单词频率所组成的K维向量,采用词频-逆文本频率,对影像的视觉单词进行加权。词频(term frequency,TF)表示某个视觉单词在影像中出现的次数,出现次数越多代表该视觉单词越重要;逆文本频率(inverse document frequency,IDF)是视觉单词的独特性度量。若一个视觉单词仅在几幅影像中出现,则说明该单词具有较高的独特性。假设索引影像表示为词频向量Vd=[(id1,t1)(id2,t2) … (idk,tk)],则词频向量Vd中ti的计算公式为
(1)
式中,nid表示单词i在索引影像d中的次数;nd表示索引影像d包含的总词总数;Ni表示包含单词i的影像数;N表示索引影像的总数;idk表示单词的序号。
考虑到GPU存在大量核数,提出一种GPU端TF-IDF-Match4权重得分计算方法。在计算查询影像与数据库影像的相似性值前,假设单词总数为M,则将影像的词频向量填充到M维,对于未出现单词,将其权重赋值为0,其他单词权重保持不变。将查询影像和数据库影像的词频向量拷贝到GPU端,一个线程负责计算查询影像与数据库中一张影像之间的得分,此时线程内部需要循环词频向量进行对应相乘累加,即可计算相似度,省去大量重复过程,且能实现多线程并行处理。
TF-IDF-Match4方法同时使用了4种GPU端优化计算得分方法:①将词频向量存储在全局内存中,一个线程负责计算检索影像与数据库中所有影像之间的得分。此时一个线程负责计算所有影像,工作量大且全局内存访问速度慢。②将待检索影像词频向量存储到共享内存中,一个块中的一个线程负责计算检索影像与数据库中一张影像之间的得分。此时共享内存是由32个等大小的内存块组成的,一个块中所有线程同时访问同一个内存块不同地址时,会产生内存块冲突。③将待检索影像的词频向量维数加1且赋值为0,此时一个块中所有线程同时访问共享内存时,多个线程访问通道错开,访问的都是不同内存块,内存块冲突减少,线程等待时间大幅降低。④使用float4类型存储词频向量,与float类型相比,多字节向量加载或存储仅需要发出单个指令,每指令字节的比率更高,且特定存储器事务的总指令延迟更低,减少了事务请求次数,提高了计算效率。以上计算方式相比原有CPU端计算,速度有大幅提升。
2 试验与分析
2.1 试验数据
利用3组无人机影像进行试验验证,采用多旋翼无人机进行数据采集。第1组数据来自江苏省南京市鸡鸣寺,包含许多低矮建筑物,共采集325张影像,影像尺寸为4000×3000像素;第2组数据来自山西省运城市大交镇,存在大量裸地覆盖,共采集1082张影像,影像尺寸为7360×4912像素;第3组数据来自湖北省宜昌市三峡大学,从高层建筑物试验区采集4750张影像,影像尺寸为4000×6000像素。
2.2 结果与分析
为分析本文无人机影像匹配对检索算法的效率和精度,利用3组无人机影像数据进行试验,并分别与Colmap词袋模型查询算法、DBow词袋模型查询算法进行对比。采用精度、效率、匹配对数量作为算法性能的评价指标。其中,检索精度是得分排名前m的影像中正确影像个数n与实际参考影像个数m的比值。所有算法均采用C++实现,且运行在配置为英特尔i7-7700K 8核CPU、英伟达GeForce GTX1050ti GPU的台式计算机上。为获取影像匹配对的参考数据,首先利用Smart3D商业软件对每组数据进行空中三角测量处理;然后将连接点数量大于30的影像对标记为参考匹配像对。图4为不同方法的检索精度和匹配对数量。结果表明,本文检索算法在3组数据的匹配对精度和正确匹配对数量均高于Colmap和DBoW,且最大精度可达96.51%。Colmap、DBoW算法的最大精度分别为95.5%、94.6%。进一步分析检索匹配对数量可知,本文算法查找出的正确匹配对数量在不同数据量上均为最高。
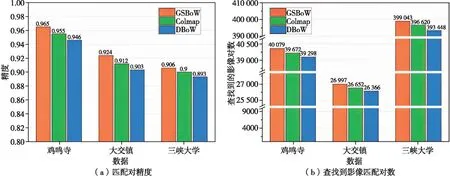
图4 匹配对查找试验结果
检索匹配对详细耗时见表1。结果表明,与Colmap和DBoW使用的K-means树索引结构相比,本文单词检索时间减少一半以上,且单词检索速度与数据量大小无关。同时,考虑到影像相似性计算时间,本文算法的计算效率有显著提升。对于鸡鸣寺数据,本文算法相比Colmap、DBoW,效率分别提升41和25倍。对于大交镇数据,本文算法相比Colmap、BoW,效率分别提升55和30倍。对于三峡大学数据,本文算法相比Colmap、DBoW,效率分别提升76和32倍。试验结果表明,本文提出的TF-IDF-Match4方法,随着数据量的增大,效率提升会更加显著。考虑整体词袋模型查找匹配对的时间消耗,本文算法计算效率有显著提升。对于鸡鸣寺数据,本文整体算法比Colmap、DBoW词袋模型效率分别提升20和13倍;对于大交镇数据,效率分别提升15和30倍;对于三峡大学数据,效率分别提升45和18倍。
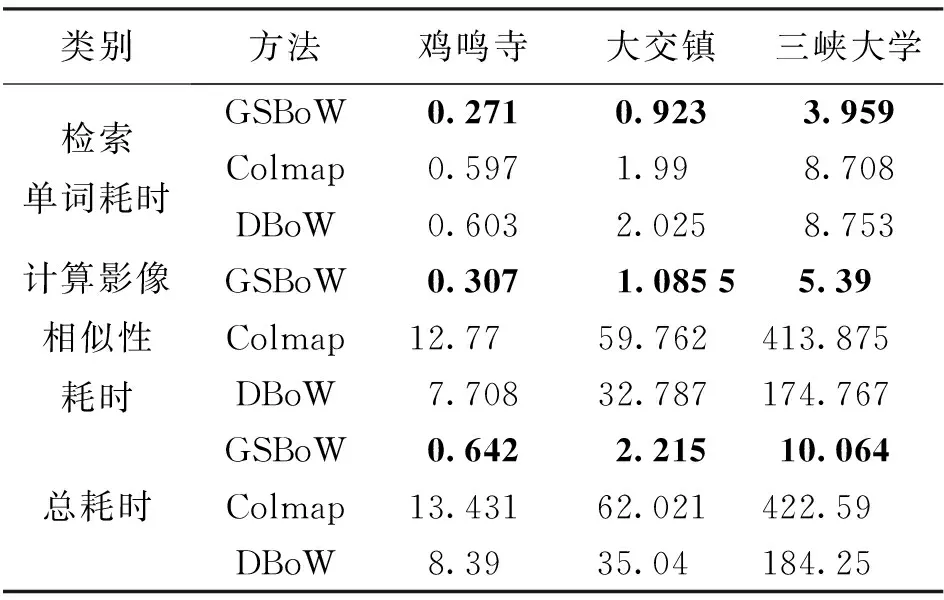
表1 匹配对查询耗时详细信息 min
为进一步分析本文无人机影像匹配对检索方法的有效性,将影像匹配对检索结果应用到稀疏点云三维重建中。使用开源库Colmap中的稀疏点云三维重建算法,并从影像入网张数、三维重建效率、重建点云数量、空中三角测量精度4个方面进行评价,统计结果见表2。对于入网张数而言,3组数据均全部入网,说明3种方法在无GPS的情况下均能提供有效的匹配对,完成空中三角测量完成构网。对于点云数量而言,本文算法提供的匹配对生成的点云个数明显高于Colmap、DBoW算法生成的点云个数,说明提供的正确匹配像对占总体的比例更大,生成的点云个数更多。鸡鸣寺数据上点云个数最大相差24 000,大交镇数据最大相差18 982,峡大学数据最大相差206 932。对于稀疏点云重建时间和空中三角测量精度而言,本文算法最小精度达1.15像素,最大精度达1.29像素,最短重建时间为20.15 min,最长重建时间是3572 min,在不同数据上整体稀疏点云重建的时间和空中三角测量精度也均低于Colmap、DBoW算法,说明本文算法提供的正确匹配对更多,去除错误匹配耗时更短,整体空三平差速度更快。
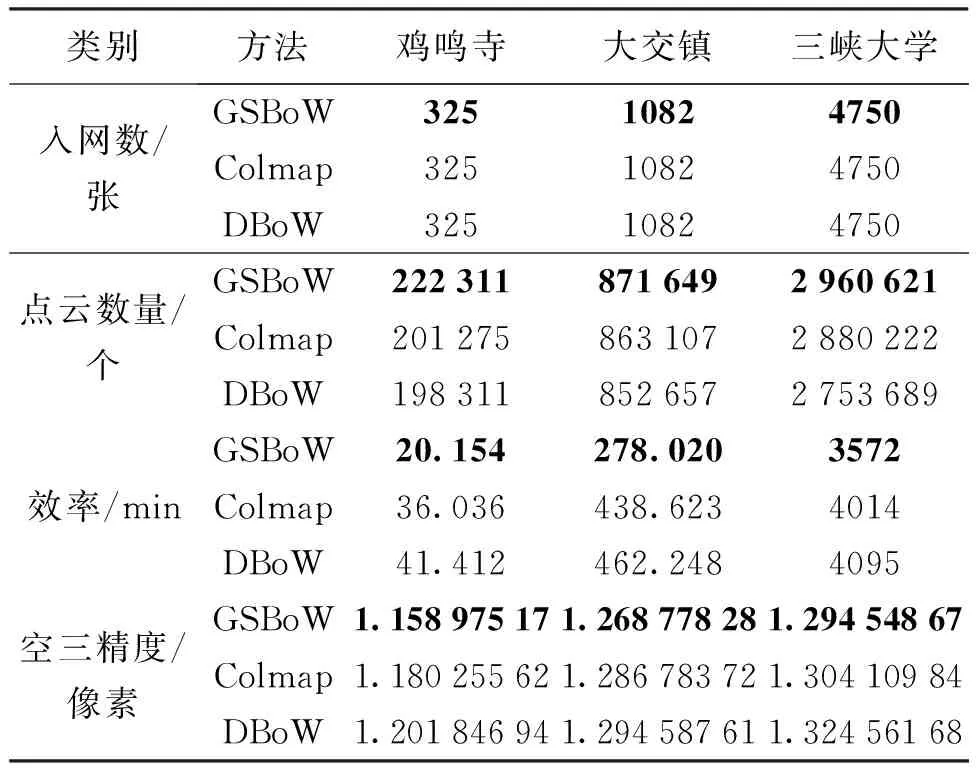
表2 试验数据详细信息
3 结 语
本文利用单词建立图索引结构,将传统的基于树查找单词转化为基于图查找单词,设计了一种导航小世界图索引结构最邻近查找单词的算法,大幅提高了影像查找对应单词效率。针对词袋模型的词频-逆文本频率逆序索引结构,提出了一种TF-IDF-Match4算法,在GPU端优化计算得分方法,大幅提升了计算匹配对得分效率。利用3组无人机影像数据进行试验,结果表明,本文模型查询无人机影像匹配对,显著提高了查找初始匹配效率,比Colmap词袋模型最高提升45倍,比DBow词袋模型最高提升18倍;同时显著地提高了初始匹配精度,即提供的初始匹配对在三维重建中能够取得更高的精度。
