机器学习在聚乳酸加工及性能预测中的应用研究进展
2023-09-05翁云宣张彩丽
王 磊,赵 敏,翁云宣,张彩丽
(北京工商大学化学与材料工程学院,北京 100048)
0 前言
随着不可再生能源的不断减少和环境污染加重,生物基可降解材料受到广泛关注,其中PLA尤为重要。与其他高分子材料相比,PLA 具有单体来源可再生、生产过程无污染、产品可生物降解、物理力学性能较好等优点[1]。
在传统制造中,为了得到不同的PLA产品,目前的研究方法包括科学实验、模型推演、仿真模拟、科学大数据[2],最常用的方法就是通过不断试错以得到理想的性能,然而PLA制品的材料种类、工艺方法以及添加助剂等均会对PLA 的性能产生重要影响,这样研究人员就需要经过大量的重复实验才能得到结果,消耗大量的人力劳动和成本,同时试错法也存在着偶然性和不确定性。高效地寻找新型生物降解材料是现代社会所需要关注的问题,然而不断的试错终究不是最好的方法,它的低效率会在实验过程中浪费大量的时间和材料,同时也会打消市场的积极性。目前,为了解决这一问题,研究者将机器学习应用在PLA 的生产和性能预测中,并且正处于研究探索阶段。
ML 是人工智能领域的一种寻找数据之间规律的算法和技术。近年来,ML 广泛应用在各行各业中,可以准确估计不同现象行为,引起了广大研究人员的注意。例如,Xia 等[3]基于贝叶斯优化,利用机器学习描述势能面,将ML 应用在矿物计算领域,进而筛选晶体结构;刘海知等[4]通过线性分析判别、逻辑回归以及最邻近等算法预测降雨诱发滑坡的概率;Levin 等[5]利用机器学习对急诊患者的重症监护、急诊医疗程序或住院的需要程度进行分级,节省时间,及时救助患者并减少浪费医疗资源;钱琦淼等[6]通过梯度提升树和随机森林算法对单支股票的收益起情况进行预测。同时ML在材料领域也有一定程度的发展,比如Polymer Ge‐nome[7]是基于网络的机器学习能力,可以对聚合物特性进行预测。
ML可以通过有限的实验数据进行训练,并在处理数据的同时完善自身,使得ML 模型更加准确。通过将文献数据、实验结果以及PLA 制品的部分理化性质作为特征参数,可以对PLA的目标性能进行研究,比如将ML用在寻找PLA 材料的最佳组合方式、工艺条件、环境设置上,可以加快PLA 产品的研发、对PLA 进行性能预测以及在生产过程对产品质量进行监测,进而得到理想的PLA 产品,促进市场消费。但由于机器学习是在已有的数据上进行训练的[8],容易受到与测量数据相关联的内在不确定性的影响,使得结果存在误差,研究人员正在积极解决该问题。
1 性能预测
机器学习即计算机自动获取知识,通过设计的算法将已输入的知识结构重组来得到新的知识和结果,同时也是计算机系统自我完善的过程。
机器学习分为监督学习、无监督学习、半监督学习以及强化学习。监督学习是指通过将已知数据和已知结果建立联系,得到映射关系,进而预测新的结果。监督学习在样本数据足够多的情况下具有良好的准确性,但仍存在缺点,在构建模型前期,利用的数据需要人工劳动所得或者有大量的文献数据支撑,不然得到的模型精确度不够。无监督学习与监督学习的不同之处在于不需要得到特征变量与目标值之间的关系,通常被用来研究数据样本之间的联系、进行聚类分析。半监督学习将监督学习与无监督学习相结合,可以进行分类、回归、聚类的组合使用。强化学习比较复杂,强调环境与系统的联系和相互作用反应,擅于模拟新的情况。
ML可以通过对比、归纳等方法运用实验得到的已知数据对结果进行预测,并对预测结果进行检验得到误差值,如果结果在符合规定的范围内,即表明该算法成立。表1 总结了本文介绍的ML 模型在PLA 生产中的应用以及性能预测。

表1 ML模型在PLA生产中的应用以及性能预测Tabl.1 Application of ML model in PLA production and its performance prediction
机器学习在PLA 性能预测方面有很好的优势,ML可以将大量的数据进行分析处理,将数据进行分类判断以及数据拟合,对其构建的模型进行不断优化,以得到理想的ML模型和预测结果。
1.1 优化3D打印模型及参数
增材制造技术(AM,即3D 打印技术)是一种快速成型制造的技术,以数字模型作为基础,将材料逐层打印成型的方法,可以将数字设计的产品转换到三维实体[9]。该技术由于生产便利、生产周期短以及可以加工复杂结构的产品等优点,被广泛利用在许多制造行业和领域。在3D 打印过程中,有许多因素影响着制品的性能,如原料种类、设备、工艺方法、设计图案等都影响着制品性能。其中PLA 是3D 打印材料中常用的热塑性线材,PLA 熔融温度较低且加热过程中无刺鼻气味的特点适合用于3D打印。
如果使用传统方法则需要进行大量的实验以制成零件、检验零件,并找出各因素与疲劳寿命之间的关系,如此一来,将消耗大量的生产成本和时间,故采用ML 方法将大大缩短实验时间。Hassanifard 等[10]通过使用线性回归、多项式回归和随机森林回归模型,研究了PLA 样条缺口形状、光栅方向和熔体内部空隙对PLA 疲劳寿命的影响,并将预测结果与基于临界距离理论的解析方法得到的数据进行比较得出,ML模型对疲劳寿命的预测更好。
如果没有监测步骤,3D 打印机会持续打印零件,直到完成所有部分,这样会浪费材料,以及打印过程中存在的缺陷都将会打印出来,当在工厂里进行大型生产时,则将会产生巨大的损失,如果在打印过程的各个(关键)阶段进行质量检查来检测缺陷,不仅有助于实施纠正措施,同时还可以消除打印不合格零件而产生的浪费。Delli 等[11]通过在3D 打印PLA 过程中暂停,利用Python 代码进行自动拍摄图像,将图像进行处理,并利用ML 模型SVM 对产品好坏进行分类。图1 是SVM的基本概念,该方法可以检测PLA 生产过程中补全失效缺陷及几何缺陷或结构缺陷。但该过程存在需要暂停生产才能拍摄和只能拍摄俯视图图像的局限性。
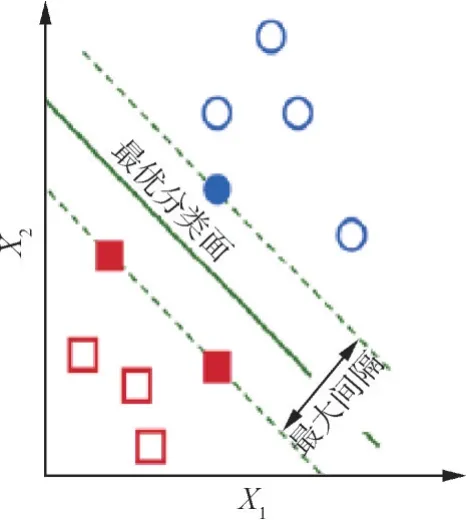
图1 SVM的基本概念[11]Fig.1 Basic concept of SVM[11]
Meiabadi 等[12]使用熔丝制造(FFF)打印机通过进一步发展ANN 和ANN‐GN 来对PLA 的韧性、零件厚度和生产成本进行预测,得到与之相关的影响因素,进而提高PLA 制品的产量和质量。图2 是单一ANN 模型与ANN‐GN 混合模型与目标值的偏差(韧性)。研究者得到韧性与机械应用相关,构建时间与生产成本相关,填充比例和图层厚度之间的相互作用影响印刷部分厚度。

图2 ANN‐GA混合模型、ANN单一模型与目标值的偏差[12]Fig.2 Deviation from target values for the hybrid ANN‐GA and single ANN methods[12]
ML 模型在3D 打印PLA 材料的生产过程中发挥了非常好的效果,在多个方面都展现出了ML 算法的优越性。在3D 打印的处理中,ML 算法可以帮助优化工艺参数以及进行过程缺陷监测,进而帮助从业人员进行生产前计划、产品质量评估和控制。然而,人们也开始注意到ML 技术可能会发生的数据泄露,越来越关注AM中的数据安全问题[13]。
1.2 预测PLA屈服应力
在工厂生产实践中,如果在生产过程中出现错误,只能在发现不合格产品之后,再对机器进行检查,逐一排除出现故障的部分或者对材料质量问题进行排查,这个过程消耗大量时间,加大了生产成本。许多研究者把目光放在了减少从生产到发现产品质量问题反馈的时间,进而降低生产时间以及及时监测产品质量。
对加工监测可以从两方面进行,一种是对机器零件的磨损或者故障进行监测,比如数控机床执行零件加工时可以利用ML 模型对刀具磨损进行实时监测[14],另一种是对零件制品的性能特征进行监测。
Mulrennan 等[15]通过在狭缝模具安装传感器,将其中得到的数据用ML模型(将主成分分析与随机森林结合,用决策树构建)来预测PLA 的屈服应力,即预测双螺杆挤出PLA 时的拉伸性能,进而达到实时监测生产过程中产品质量,在产生问题时及时停止,同时该模型能随着时间的推移进一步改进自身的准确性和精准度。
由此可见,通过对产品容易得到的特性进行实时监测,将数据输入ML 模型可以做到即时了解产品的某一性能,进而对产品的质量进行监测。所以,如果在工厂大范围应用ML 模型,并将所需监测的性能都用模型进行预测,那么可以做到实时监测每个产品的质量,加大产品的合格率以及减少对生产故障的发现和反应时间。
1.3 预测低密度PLA泡沫密度
研发具有特定性能的发泡材料是一项繁杂且有难度的事情,如果能利用恰当的工具和方法进行研究,可以大大加快新材料的研究进程,减少生产研发过程中产生的浪费以及加快发泡材料市场的发展。
为了得到指定密度的PLA 产品,需要控制多个变量来进行实验,如果通过传统的试错,那么需要控制太多的变量组合来进行实验,将会耗费大量的实验材料,然而通过ML 模型可以将多个参数结合起来,并且得到多样的参数组合来进行密度预测,将密度与可控的少数变量联系起来,找出其中的函数关系,在之后的密度研究中,可以更加准确快速的找到与之对应的条件因素。
Albuquerque 等[16]通过集成方法将多个ML 模型组合起来对PLA 密度进行预测,并将PLA 泡沫的密度通过温度、压力和时间的函数来表达,其中包含多个与密度相关的参数,最终得到集成模型。该ML 集成模型是梯度提升、随机森林、核岭和支持向量回归模型的线性组合。在研究过程中,首先对其所要研究对象进行编码,用Python codes (Python 3)来执行,计算变量对之间的相关性,图3 是所有样本的每一对变量的相关性的热图表,主成分分析技术(PCA)选择样本和特征来建立回归模型,然后对建立的模型用网格搜索进行超参数优化,最后进行检验即可得到最优ML 集成模型。其中,红色和蓝色格分别代表正相关和负相关。
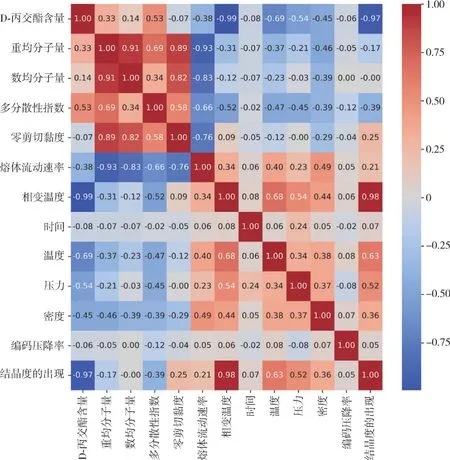
图3 数据集中所有样本每一对变量(包括特征和目标)之间相关性的热图表[16]Fig.3 Heatmap table of correlations between every pair of variables (features and target are included) of all samples in the dataset[16]
图4 是通过集成模型进一步改进预测的方案。最终的集成模型是平均绝对误差(MAE)最小的模型,由该模型预测的参数制备的PLA发泡材料的实际密度与预测值一致。其中,Ens 代表集成模型;ŷEns、m、Ci、ŷML(i)、MMAE(y,ŷEns)分别代表集成模型预测值、集成模型个数、正系数、ML模型预测值、集成模型预测值与目标值的平均绝对误差。由此可见,研究者可以利用ML模型将PLA 的性能由可控条件来进行调控,并得到具体的函数关系。在实际的生产中,可以得到指定性能的产品。

图4 通过集成模型进一步改进预测的方案,最终的集成模型是MAE最小的模型[16]Fig.4 Scheme used to further improve the predictions via an ensemble model. The final ensemble model was the one with the smallest MAE[16]
在建立最佳模型的过程中,选择适合的变量特征可以确定其中包含的相关性,即在不能定量分析的前提下,可以建立特征变量与目标函数的关系和模型。作者认为这可以直接得到相关变量的关系,解决了在个别领域理论知识的不成熟导致的技术进展缓慢的问题。
1.4 预测PLA拉伸性能
PLA 复合材料广泛应用于各个领域,如农用织品、帐篷布、地垫等,且在未来的市场中仍有较大的开发空间,比如PLA复合材料由于其良好生物相容性、可降解性在医疗领域中广泛应用,像一次性输液用具、手术用的缝合线和药物缓释包装剂等,都采用了PLA 复合材料[17]。PLA复合材料的力学性能取决于添加的填料性能,填料可以分为有机填料和无机填料,而添加的填料取决于复合材料的应用领域。填料的强度、化学稳定性、基体的强度及基体与填料的界面结合力均影响着PLA复合材料的力学性能[18]。
Alakent 等[18]采用回归树模型的统计学习方法研究了PLA 复合材料的拉伸强度,通过整合统计学范式的工具以及利用PLA复合材料的文献数据构建回归树模型,进而确定测量拉伸强度的实验特征,然后使用MATLAB的统计学和机器学习工具箱进行计算,最后对模型进行验证和评估,得到了加工方法、加工温度和分子量与PLA 拉伸强度的关系。图5是最终的回归树模型。但该方法仍存在缺陷,部分缺失数据会导致该模型的不准确,故仍有较大进步空间。

图5 最终的回归树[18]Fig.5 Final regression tree[18]
回归树是通过对知识进行归纳和提取,并进行规律性的形式进行总结的机器学习算法,在建立关系后可以通过修剪和调整进行优化、减小误差。作者认为ML模型在大量的数据统计方面有很大的优势,如果将需要的PLA 性能方面的数据输入,并采用适当的统计方法,可以得到理想的性能预测结果。
1.5 预测PLLA/PGA复合材料的相对结晶度
PLLA 随着等温温度的升高或者等温时间的延长,等温结晶所形成的晶体会逐渐向更加稳定的趋势发展,但其结晶速率较慢,故研究者们通常以PLLA 为基体制成复合材料来加快结晶速率[19]。与PLLA 结晶速率相关的因素有结晶温度、结晶时间、分子量以及分子链自身结构等,可通过改变相关条件来观察PLLA复合材料结晶速率。
Wang 等[20]通过6 种不同的人工智能类别,包括4 个人工神经网络,2 个自适应神经模糊推理系统以及最小二乘支持向量回归来预测PLLA/PGA 复合材料的相对结晶度与结晶时间、温度和PGA 含量的关系,并将基于统计的精度指标用来为每种机器学习技术找到最可靠的拓扑结构。表2 是寻找机器学习方法的最佳结构特征的试错过程总结,得到复合材料的结晶度随PGA 含量和结晶时间的增加而增加,但温度对相对结晶度的影响太复杂而不易解释。ML 模型可以对相互关联的、有理论依据的PLA 性能变量进行预测和推算拟合,但对于处理影响复杂的变量仍有困难。

表2 寻找ML方法最佳结构特征的试错过程总结[20]Tab.2 Summary of the trial‐and‐error process to find the best structural features of the ML methods[20]
人工神经网络在模拟复杂现象方面有很大的优势,即使一个隐藏层的非线性、连续、可微激活函数的神经网络模型也能够模拟复杂的现象[20],自适应神经模糊推理系统是将模糊逻辑和神经元网络有机结合的新型的模糊推理系统结构,即将模糊控制的模糊化、模糊推理和反模糊化3 个基本过程全部用神经网络来实现,通过学习能有效的计算出隶属度函数的最佳参数。
作者认为进行机器学习模型的构建前提是找到合适的机器学习技术,可以通过查阅文献和对变量特征与目标属性进行分析,进而选择效果更好的机器学习技术,但是在鲜少有人研究的领域,那么进行机器学习研究就变得繁琐、困难起来。
1.6 PLA热降解程度分类
PLA 基复合材料的降解分为4 种,分别是水解降解、微生物降解、热降解和光降解[21]。在高于 200 ℃的条件下PLA 容易发生热降解,其热降解过程及机理非常复杂,包含了自由基降解机理和非自由基降解机理。PLA 制品的力学性能与热降解的程度有关[22],为了产品能更好地在现实中使用,必须要得到不同环境下PLA的热降解程度,从而对PLA进行性能优化。
Zhang[23]通过控制温度或时间来对PLA 进行热降解模拟,并获得傅里叶变换红外光谱的数据,采用4 种机器学习算法对PLA试样的热降解程度进行分类。其中多分类逻辑回归和多分类神经网络可以准确预测降解行为。图6 是用于多分类逻辑回归的机器学习模型的流程图。同时,将得到的光谱可以对模型进行训练,从而提高精度。然而光谱可能由于采集环境和仪器操作而产生多余的图像,这将对模型的准确性产生影响[24]。

图6 用于多分类逻辑回归机器学习的流程图[23]Fig.6 Flow diagram of machine learning models for multi‐class classification[23]
研究者用到的4 种机器学习算法为多分类决策森林、多分类决策丛林、多分类逻辑回归以及使用最小最大归一化的多分类神经网络。其中决策森林和决策丛林通常被用来对数据进行分类,逻辑回归算法是预测结果概率的统计方法。利用以上4 种机器学习模型预测PLA 的降解行为、降解程度是一种对实验结果的分类和预测,再对其进行训练以提高精度和准确性。
机器学习并不能完全准确地预测结果,但可以在误差允许范围内不断提高准确性,为产品的研究、生产以及投放到市场当中去,提供了极大的便利,但同时也要注意到更为全面的影响因素,以面对使用过程中出现的各种各样的问题。
2 结语
研究者们可以通过了解聚合物的特性帮助选择合适的材料用于各个领域,以及合理选择加工过程中设备的参数、环境条件等因素来达到材料想要的目标属性[25]。用传统的方法寻找正确的加工参数以达到理想的性能,需要大量的实验以及消耗大量的实验材料和实验时间,同时长久的研发过程明显会延迟市场的发展,打消市场发展的积极性。与此同时,在工厂的生产过程中,一般情况下产品出现问题都是在产品制成之后检查时才能被发现,在这个过程中浪费了大量生产时间和生产材料,会增大生产成本,进而影响市场经济。
研究者们将ML 模型应用在PLA 生产过程中,可以有效解决以上2 个问题。ML 算法可以通过输入有限的数据,用算法预测结果,在后续的预测和验证中不断完善自身的准确性和正确率。正如PLA 的密度、拉伸强度、屈服应力、结晶性能、疲劳寿命、韧性、降解程度都可通过ML 模型进行预测,并取得了理想的结果,如果从实验的角度,有太多的因素会影响到PLA 的性能,彼此之间息息相关,这给研究者带来了很大的难度,利用ML 模型,这个问题可以有效解决。另外,ML模型可以监测生产过程中产品的形状缺陷以及性质(如拉伸性能),这样可以做到产品质量的及时反馈,大大减少了生产过程中的损失。作者认为ML 模型还可以用在监测生产聚合物设备上的监测,如喷嘴、切粒机内部刀具等的实时监测,以及在生产过程中,从多个角度来观察产品性能,利用ML 模型同时预测PLA 产品的多个性能,综合监测产品的质量等。
最后,作者认为ML 模型在PLA 生产上的作用有非常大的潜力,符合未来的发展趋势,会有越来越多的研究者投入到这一方面上来,同时不仅仅是PLA,许多聚合物都可以利用ML 模型进行预测性能,监测产品质量,甚至是设计新型材料。
