基于递归特征金字塔的UPSNet全景分割应用研究
2023-09-04李学伟刘宏哲
叶 钊 李学伟 刘宏哲 徐 成
(北京联合大学北京市信息服务工程重点实验室 北京 100101)
0 引 言
全景分割最早是FAIR与德国海德堡大学联合提出的更高要求的分割任务,目前图像分割任务有语义分割、实例分割、全景分割。语义分割是从像素的角度将图像中的不同对象分割出来,语义分割的代表网络有FCN[1]等,深度卷积神经网络图像语义分割研究进展[2]介绍了语义分割研究的进展。实例分割是在语义分割的基础上,将图片中的每一个物体都分割出来,实例分割的代表网络有Mask-Rcnn[3]等。全景分割则是语义分割与实例分割的结合,全景分割将图像分为stuff和things两类,对于stuff类,使用语义分割的方法将其分割,对于things类方法,使用实例分割的方法进行分割,再将两类子网络得到的结果联合预测,得到最终的分割结果,全景分割的代表网络有Panoptic FPN[4]等。
Feature Pyramid Networks[5]自提出以来,被广泛应用于图像检测、图像分割的任务上,通常与ResNet[6]结合使用,对图像进行特征提取。在UPSNet[7]中也使用了这一网络结构,并将其设计成一种可以为语义分割子任务和实例分割子任务共享的主干结构,这种方法可能会产生不准确的特征信息到语义分割子网络和实例分割子网络中,为了获得更加强大的语义信息以及解决这一问题,本文采用建立在特征金字塔网络[5]之上的递归特征金字塔网络[8],该方法通过将额外的反馈连接从自上而下的FPN层合并到自下而上的主干层,将递归结构展开为顺序实现,获得用于对象检测器的主干,从而使该主干可以将图像查看两次或更多次。通过集成FPN的反馈连接到主干网,使得目标检测的错误回传信息可以更直接地反馈调整主干网的参数,减少了错误信息,使主干网再训练得到的特征更好地适应分割任务。
由于全景分割被提出的时间不是很长,所以全景分割的数据集还不是很多,目前常见的有Cityscapes[9]数据集、COCO[10]数据集、Vistas[11]数据集和ADE20K[12]数据集。可以应用于交通场景的数据集只有Cityscapes数据集,针对数据集缺少的问题,本文通过采集,对4 960幅图像进行标注处理,数据集为VOC格式,分为训练集(3 000)、验证集(360)、测试集(1 600)。
根据上述提出的问题,本文在全景分割方法UPSNet的基础上,提出新的网络模型,本文所做的工作有:
(1) 针对特征提取不完整,可能会出现错误特征信息的问题,将递归特征金字塔网络融合到特征提取骨干网络中,使其得到准确的、完整的特征。
(2) 针对数据集缺少的问题,本文对自行采集的图像进行标注处理,得到可以进行全景分割的交通场景数据集。
1 相关工作
图像分割作为图像理解领域的热点,是计算机视觉的基础,图像分割是指根据图像的不同特征把图像划分成若干个互不相交的区域,使得这些特征在同一区域内表现出一致性或相似性,而在不同区域间表现出差异性。在机器学习领域,又将图像分割分为语义分割、实例分割、全景分割。目前图像分割技术已经广泛应用在智能交通中的车辆辅助驾驶系统、场景识别、医学影像、人脸识别、机器视觉等各种领域。
传统的图像分割方法主要分为基于阈值的分割方法、基于边缘的分割方法和基于区域的分割方法等。传统的分割方法分割效果较差、鲁棒性低,已经不能满足现在的分割要求。随着分割任务的需求不断提高,机器学习的迅速发展,现在的分割方法基本都是基于深度学习的分割方法,文献[13]对基于深度学习的分割方法进行了介绍。
在特征提取领域中,VGGNet[14]和ResNet[6]是两个具有统治力的方法。VGGNet将大核卷积层替换成多个小核卷积层,使得参数量远小于大核卷积层并且非线性操作也多于大核卷积层,从而学习能力更强,但是由于VGG的层数较多且最后三个全连接层参数众多,导致其会占用更多的内存。ResNet的出现成为深度学习发展的重要转折点,它解决了网络训练的层数越深、误差升高、梯度消失越明显的问题,现在的很多网络通常使用ResNet与FPN的结合作为backbone进行特征提取,本文也是对其进行优化从而达到了更好的分割效果。
自何凯明团队在2018年将全景分割的概念提出以来,全景分割的网络也相继而出。Panoptic Segmentation[15]为全景分割提供的全新的评测指标,Panoptic FPN则是何凯明团队对全景分割网络的实现,使用了Mask-Rcnn与FPN的结合,并且提出希望该网络可以作为backbone,为之后的全景分割网络奠定基础。文献[16]提出了基于距离谱回归的全景分割方法。DeeperLab[17]针对图像解析器设计了几种神经网络策略,尤其对于较高分辨率输入的情形,降低了内存的占用,还提出了新的评价标准,基于区域的角度对图像解析结果进行判断。该网络在速度与精度之间做了平衡,并没有达到最高的精度或者最快的速度。AUNet[18]引入了注意力机制[19]并提出了一个统一的端到端的全景分割框架,但是该框架依然需要人工融合stuff和things,并且比较耗费时间。OANet[20]作为全新的端到端的全景分割算法,同样使用了FPN共享Backbone特征,对于stuff和things的分割任务使用不同的head,引入空间排序模块解决了遮挡问题,并在当时获得了最优的结果,但其主干网训练得到的特征可能会产生较多的错误信息到分割任务中的问题仍然存在。
为了减少主干网训练得到的特征产生的错误信息,本文对UPSNet中的Backbone进行改进,提出建立在特征金字塔网络之上的递归特征金字塔网络,通过集成FPN的反馈连接到主干网,使得目标检测的错误回传信息可以更直接地反馈调整主干网的参数,减少了错误信息,使主干网再训练得到的特征更好地适应分割任务。结合递归特征金字塔网络的UPSNet算法,就是对UPSNet全景分割网络进行改进,将UPSNet中的特征金字塔部分替换成建立在特征金字塔之上的递归特征金字塔,从而更好地减少特征提取产生的错误信息,达到更好的分割效果。
2 结合RFP的UPSNet算法
2.1 特征金字塔网络与递归特征金字塔网络
特征金字塔网络自提出以来,被广泛应用于图像目标检测、图像分割的网络框架中,常见的如Faster-RCNN[21]与FPN的结合用于目标检测,Mask-Rcnn与FPN的结合用于图像分割等,其原因在于FPN作为一种CNN特征提取方法可以高效地提取图片中的特征,表1给出了Faster-RCNN使用FPN提取特征与原网络的结果对比,其中:AP@0.5为置信度阈值IOU为0.5时的平均准确率;APs为目标区域小于322的平均准确率;APm为目标区域大于322小于962的平均准确率;APl为目标区域大于962的平均准确率。通过对比可以看出,FPN提取图片中的特征是高效的。FPN的网络结构如图1所示。
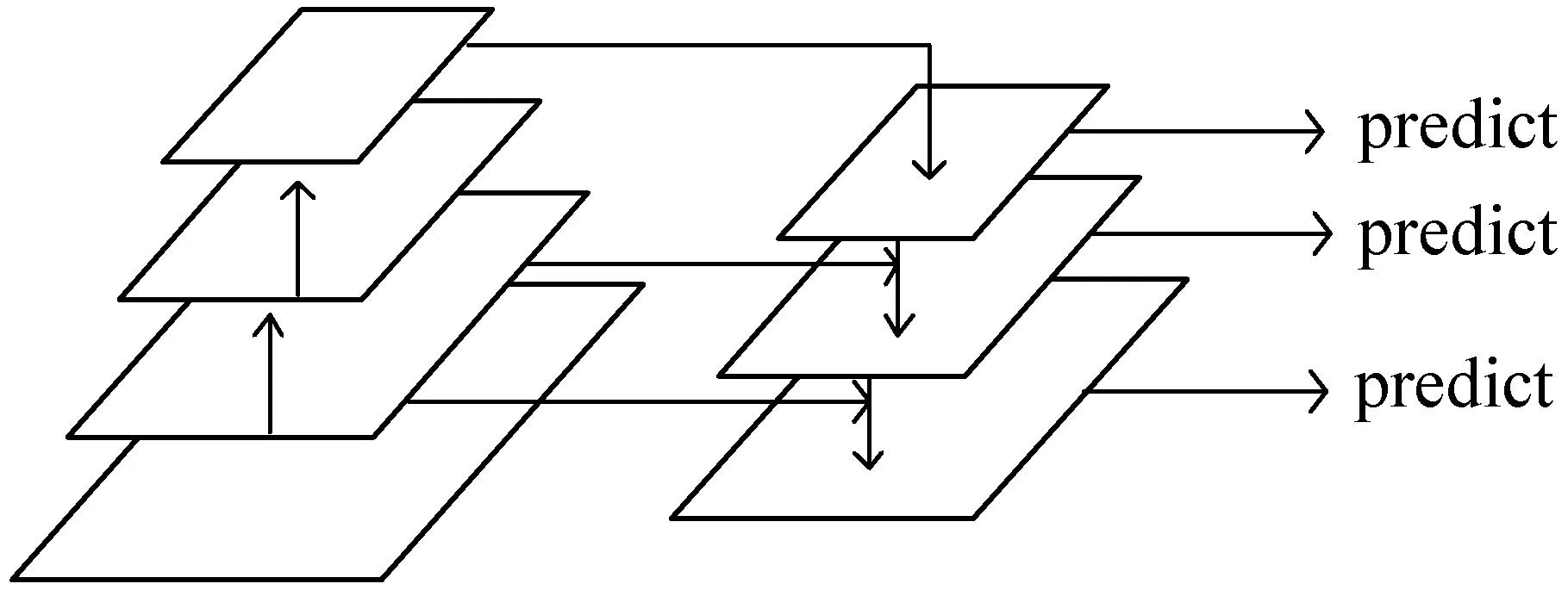
图1 特征金字塔网络结构
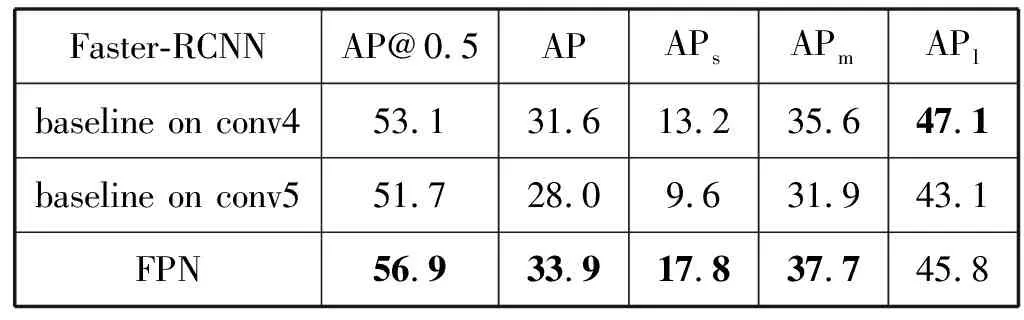
表1 Faster-RCNN在COCO minival set检测结果
从表1可以看出,使用FPN提取特征的Faster-RCNN网络的准确率比原网络使用第五层卷积层提取特征的准确率都要高,比原网络使用第四层卷积层提取特征的准确率在小目标和中等目标上的表现都要好,从而可以说明FPN作为一种CNN的特征提取方法是高效的。
从图1可以看出,特征金字塔网络主要分为三个部分:一个自底向上的线路、一个自顶向下的线路、横向的连接。用Ci表示自底向上的部分,则C0表示输入的图片,pi表示自顶向下的部分,Xi表示横向连接的关系FPN的输出可表示为{pi|i=1,2,…,N},则pi可定义为:
pi=Pi(pi+1,Xi),Xi=Ci(Xi-1)
(1)
该算法同时利用了低层特征的高分辨率和高层特征的高语义信息,并且融合了不同层的特征,从而可以达到较好的特征提取效果。
递归特征金字塔网络是建立在特征金字塔网络之上的,除了自底向上的线路、自顶向下的线路、横向的连接外,在此基础上增加了回传的反馈连接。递归特征金字塔网络将特征金字塔网络的输出作为Backbone对应层的特征再次进行卷积,二次卷积完成后,得到的结果再次输出到特征金字塔网络并与之前得到的特征金字塔输出结果进行融合。该模块通过集成FPN的反馈连接,使主干网可以将图像特征查看两次和多次,能够使梯度绕过特征金字塔直接传到骨干网络,提升骨干网络提取特征的能力。同时将二次提取后的特征与原特征融合,使融合后的特征携带更多有效信息,同时过滤一些自上而下过程产生的噪声,达到优于FPN的特征提取效果。其结构如图2所示。
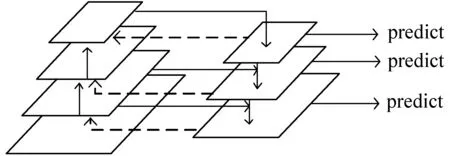
图2 递归特征金字塔网络结构
若用Ai表示为回馈自上而下主干网之前的转换特征,i=1,2,…,S,则输出的RFP特征bi可以表示为:
bi=Bi(bi+1,Xi)Xi=Ci(Xi-1,Ai(bi))
(2)
式中:Bi被定义为第i层自上而下的特征融合操作;Xi表示的是第i层的特征,Xi-1为第i层上一层的特征。Xi-1经过第i层卷积Ci(Xi-1)与回馈自上而下主干网之前的转换特征Ai融合后得到Xi,Xi与上一层的RFP特征融合后得到bi。
图3表示的是将递归特征金字塔网络展开到两步的顺序网络,将额外的反馈连接从自上而下的FPN层合并到自下而上的主干层,将递归结构展开为顺序实现,使用空间池化金字塔[22]模块来实现两个递归特征金字塔的连接,通过该模块可以得到RFP特征,最后将其与输入的Input特征进行融合,得到更加强大的语义信息。
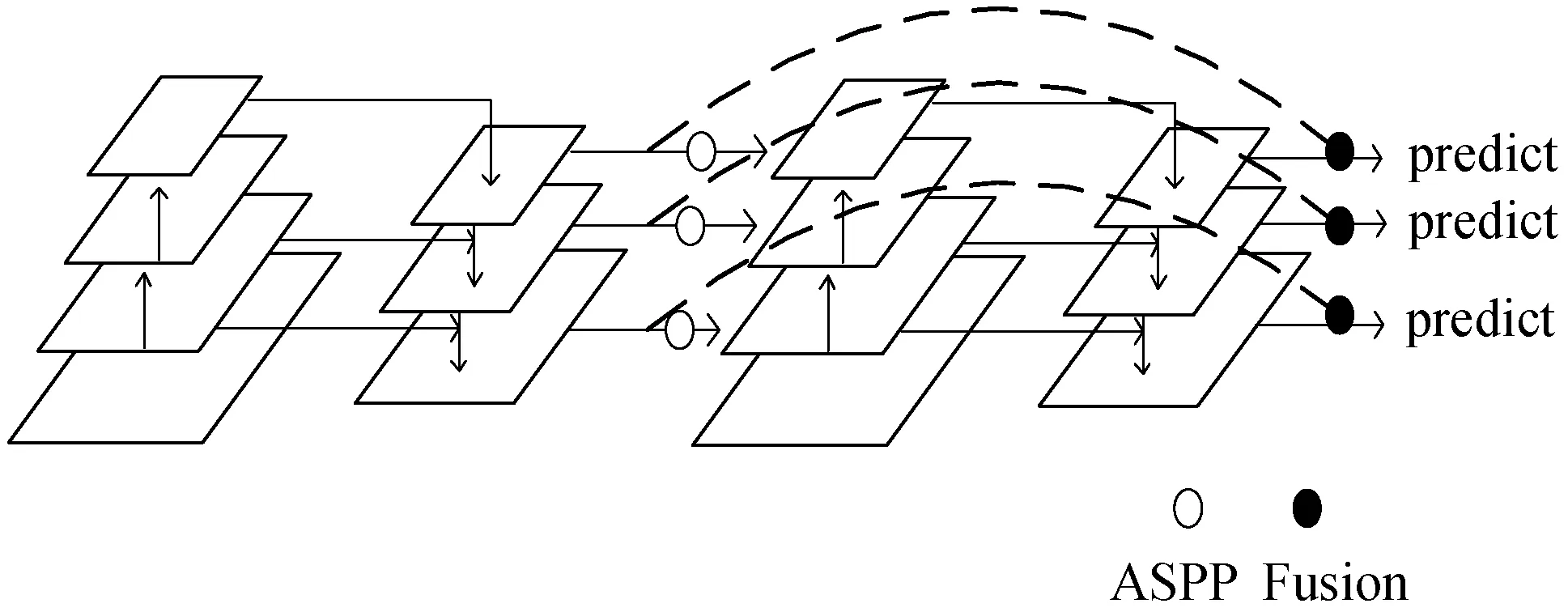
图3 递归特征金字塔网络顺序展开图
由于递归特征金字塔的结构是递归的,从而在递归金字塔的展开结构中,若∀i=1,2,…,S,m=1,2,…,M,则:
(3)
式中:M表示顺序展开的迭代次数;上标t表示操作和特征;令bi(0)=0,Bit、Ait表示不同步骤之间的共享。因为图3表示的是将递归特征金字塔网络展开到两步的顺序结构,所以此时的T=2。
2.2 空间池化金字塔连接的递归特征金字塔网络
在递归特征金字塔网络使用空间池化金字塔(Atrous Spatial Pyramid Pooling)[22]模块用于解决图像特征多尺度的问题。空间池化金字塔采用多个不同采样率的平行空洞卷积层,对每个采样率提取到的特征在不同的分支中进一步处理后融合产生最后的结果。空间池化金字塔的结构如图4所示。
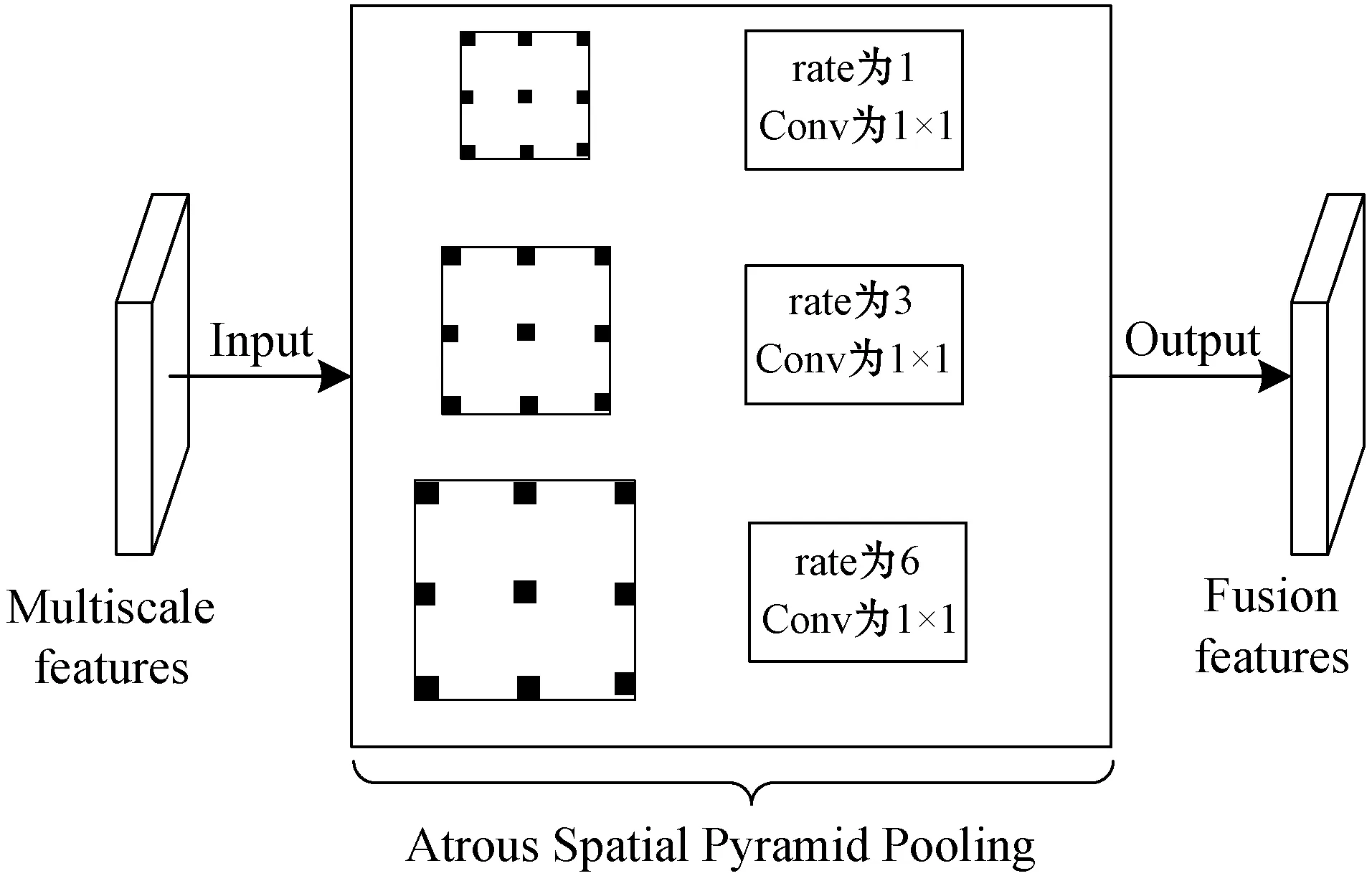
图4 空间池化金字塔模块结构
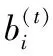
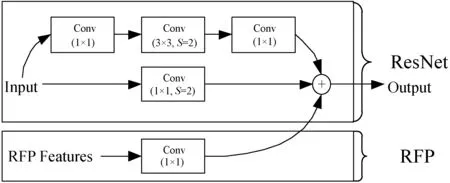
图5 RFP特征和输入特征融合过程
2.3 结合递归特征金字塔网络的UPSNet
本文提出的结合递归特征金字塔网络的UPSNet网络模型主要结构分为用于特征提取的主干网络、用于分割前景类别的实例分割子网络模块、用于分割背景类别的语义分割子网络模块,以及用于将两个子网络模块分割的结果进行联合预测的全景分割模块,最终得到输出的结果,其网络结构如图6所示。
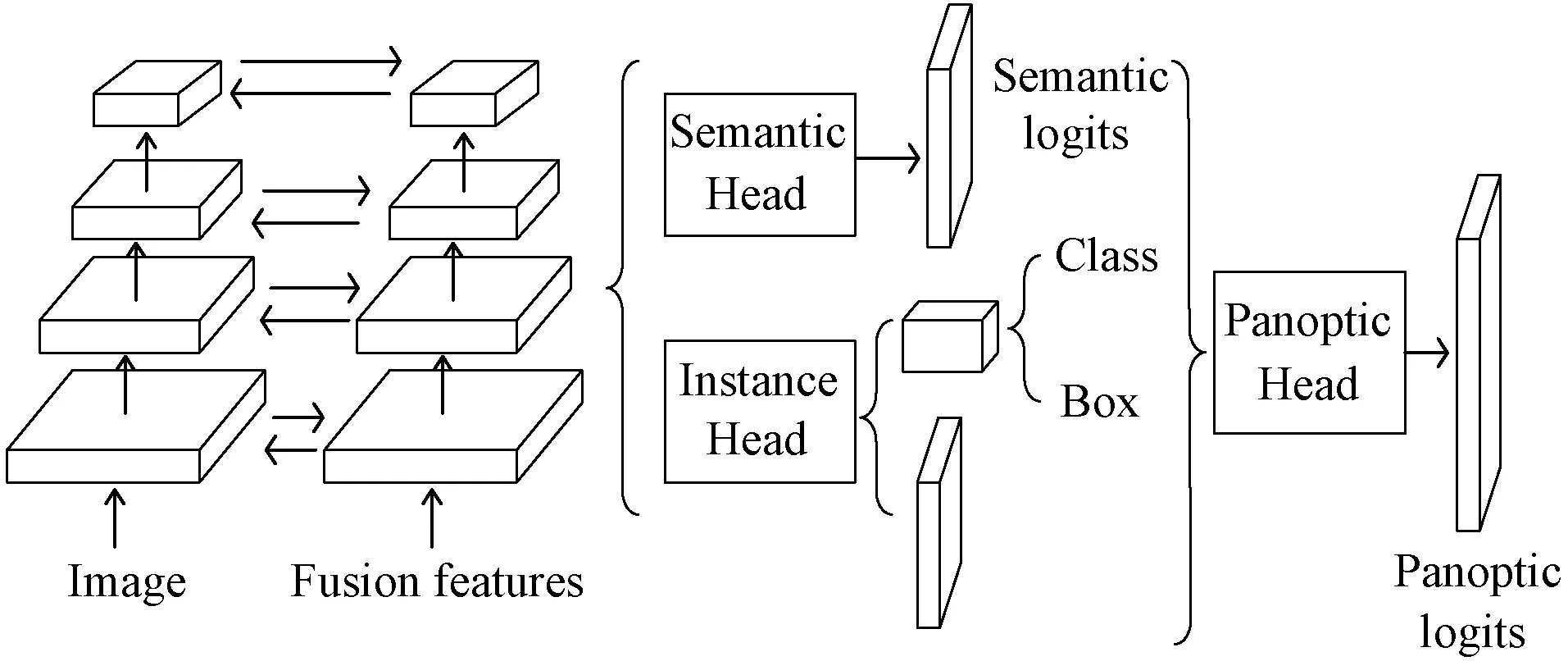
图6 结合递归特征金字塔网络的UPSNet结构
1) 主干网络:本文采用ResNet和RFP作为卷积特征提取的主干网络。将融合后的特征共享到语义分割子网络模块和实例分割子网络模块的网络中。
2) 实例分割子网络模块:采用Mask-Rcnn的网络结构进行分类输出和分割掩码输出,实例子网络模块的目标是产生可以更好地识别事物类的实例表示。最终,这些表述被传递给全景子网络模块有助于logits每个实例。
3) 语义分割子网络模块:语义分割子网络模块的目标是在不区分实例的情况下分割所有语义类。语义分割子网络模块可以帮助改善实例分割,实现things类别的更好分割结果。该语义子网络模块由一个基于可变形卷积的子网组成,该子网以ResNet和RFP融合后的多尺度特征作为输入。将图6中输出的ResNet和RFP融合后的多尺度特征定义为G5、G4、G3、G2,这些特征图包含256个通道数,分别是原始比例的1/4、1/8、1/16和1/32。这些特征图首先独立地经过相同的可变形卷积网络,然后被上采样到1/4比例。然后,将它们联系起来并使用Softmax进行1×1卷积用于语义类的预测。
4) 全景分割模块:该部分用于将上述的实例分割子网络模块和语义分割子网络模块进行整合,整合完成后对其结果进行组合输出。将语义分割子网络模块的logits表示为X,其中通道大小、高度和宽度分别为Nst+Nth、H和W。X可以沿着通道维度分为两个张量Xst和Xth,这两个张量分别对应于stuff和thing类。对于任意图片,本文将图片中的实例数定义为Ninst,对于不同的图片,Ninst是不同的。全景分割模块的目标是首先生成一个对数张量E,其大小为(Nst+Ninst)×H×W,然后确定每个像素的类和实例ID。本文首先将Xst分配给E的第一个Nst通道以提供分类的logits。本文将实例分割子网络模块的logits表示为Y,logitYi大小为28×28,对于任何的实例i,同时将获得其boxJi和类IDKi。在训练过程中,Ji和Ki是ground truth的box和类ID,在推断过程中,它们是由Mask R-CNN预测的。因此,本文只需从Ki对应的Xth通道中取Ji内的值,就可以从语义子网络模块Xmaski获得第i个实例的另一个表示。Xmaski的大小为H×W,其在boxJi外的值为零。然后通过双线性插值法将Yi插值回与Xmaski相同的比例,并在框外补零,以获得与Xmaski兼容的形状,将其表示为Ymaski。第i个实例的最终表示是ENst+i=Xmaski+Ymaski。当本文用所有实例的表示填充E后,将沿着通道维度执行Softmax来预测像素级。其方法结构如图7所示。
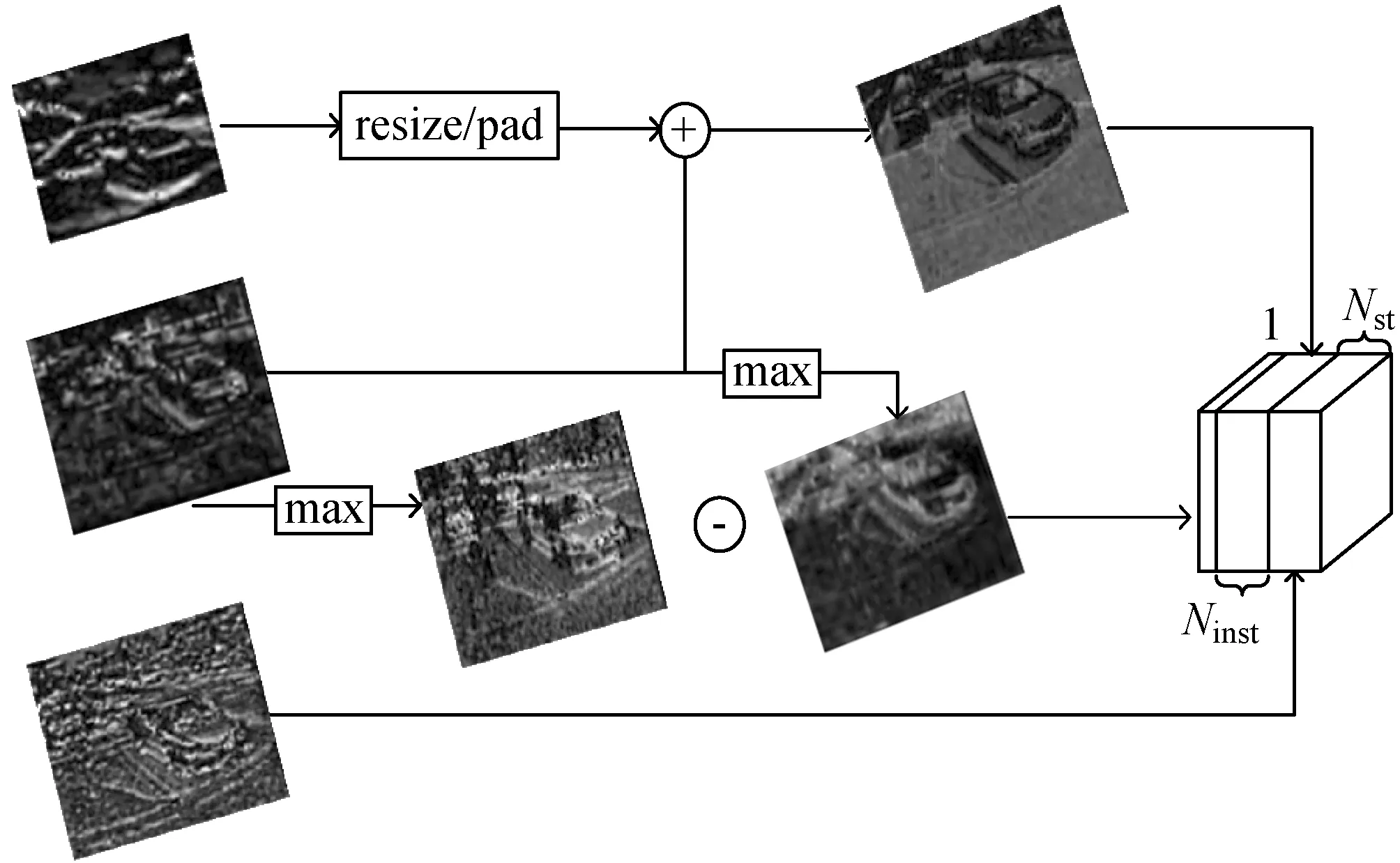
图7 全景分割模块结构
3 实验结果和分析
3.1 实验评价指标
本文的实验评价指标采用的是何凯明团队在提出全景分割概念时给出的新评价指标PQ、SQ(Segmentation Quality)、RQ(Recognition Quality),其中:PQ以可解释和统一的方式捕获了所有类别(stuff和things)的性能;PQth表示计算可数的实例(things)类别的性能;PQst表示无定形和不可数的区域(stuff)类别的性能;SQ表示匹配后的预测segment与标注segment的mIOU;RQ是熟悉的F1 Score[23],广泛用来计算全景分割中每个实例物体识别的准确性。在文献[15]中,将PQ的计算定义为:
PQ=SQ×RQ
(4)
(5)
(6)
(7)
对于每一个Class,唯一的匹配将预测和ground turth片段分成三组:真阳性(TP)、假阳性(FP)和假阴性(FN),分别表示匹配的片段、不匹配的预测片段和不匹配的ground turth片段。IOU为两个区域重叠的部分除以两个区域的集合部分的结果。
此外,本文还将各个网络模型在同一硬件平台的运行100次的平均时间(AvgTime)进行对比,从而得到综合的对比结果。
3.2 实验数据集
在本文的实验中,使用的数据集是Cityscapes[9]数据集,Cityscapes[9]数据集拥有5 000幅在城市环境中驾驶场景的图像,具有19个类别的密集像素标注,覆盖率达到97%,其中8个类别具有实例级的分割,图片尺寸大小为1 024×2 048,是目前最常用的公开的全景分割数据集之一。表2给出了Cityscapes[9]数据集中本文需要关注的类别和其对应的TrainID,共19类。
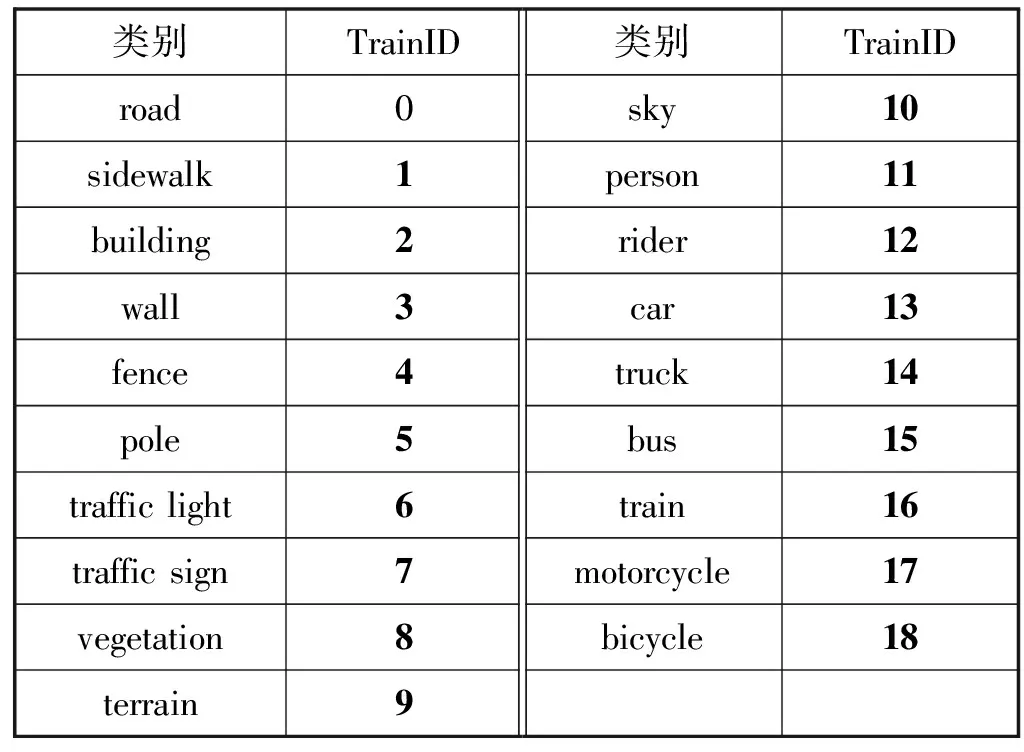
表2 Cityscapes数据集类别和TrainID
3.3 实验硬件平台
本文实验使用的硬件平台如下:ubuntu 16.04操作系统,Pytorch 1.1.0深度学习框架,编程语言为Python 3.6,硬件基础为NVIDIA GeForce GTX 1080 Ti with 4GPUs。
3.4 实验结果
本文将采用ResNet-50和FPN的UPSNet网络和ResNet-50和RFP的改进网络在其他条件不变的情况下与自行标注的交通场景的全景分割数据集进行了实验对比,实验结果如表3、表4、图8所示。本文方法比基准方法的PQ提升了3.6百分点。同时,本文将采用ResNet-50和FPN的UPSNet网络和ResNet-50和RFP的改进网络在其他条件不变的情况下使用Cityscapes数据集进行了实验对比,本文方法比基准方法的PQ提升了2.8百分点,实验证明,本文的改进是有效的。

(a) Image(b) UPSNet(c) UPSNet with RFP图8 实验结果对比
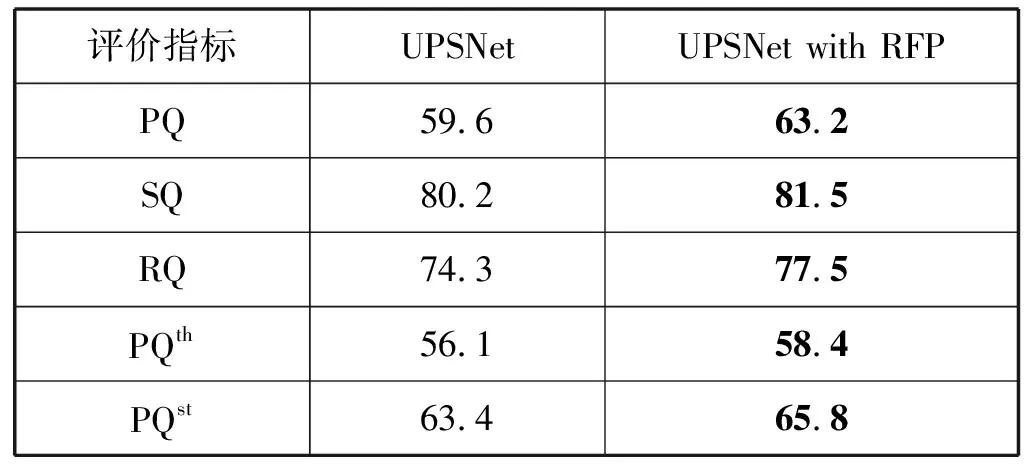
表3 自行标注的数据集下实验结果对比(%)
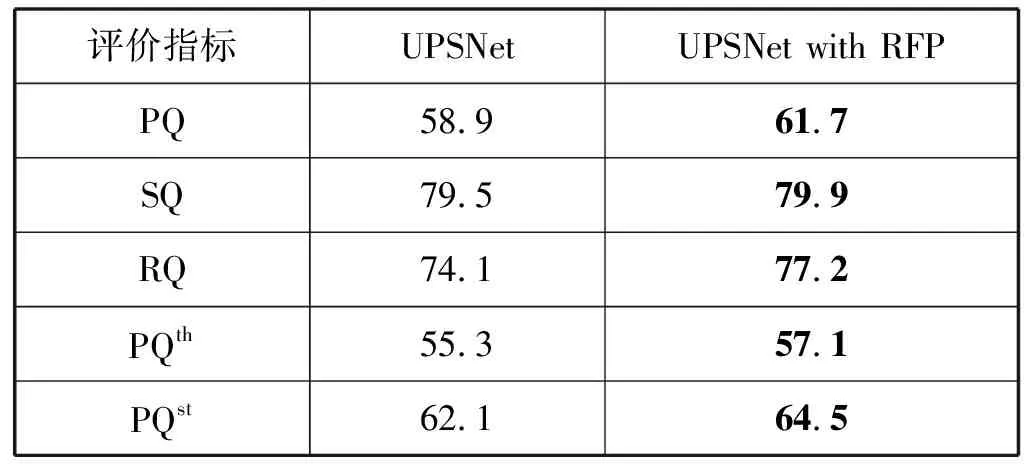
表4 Cityscapes数据集下实验结果对比(%)
通过使用我们自行标注的数据集下的实验结果对比可以看出,结合了递归特征金字塔的改进网络在新的全景分割评价指标下的表现比原始的网络有了较好的提升。
通过使用公开的城市道路场景数据集的实验结果对比可以看出,结合了递归特征金字塔的改进网络对于stuff类的分割结果比原网络的提升较大,对于things类的分割结果比原网络也有一定的提升。
图8显示的是Cityscapes数据集下的分割结果,可以看出改进的网络的分割效果要比原网络更清晰,边缘的分割效果也比原网络好,对于较为密集的不同类别,分割的结果也要好于原网络。
本文还将改进的网络与其他优秀的全景分割网络在Cityscapes数据集上进行了实验对比,实验证明,本文提出的基于递归特征金字塔的改进网络是有效的,结果如表5所示。
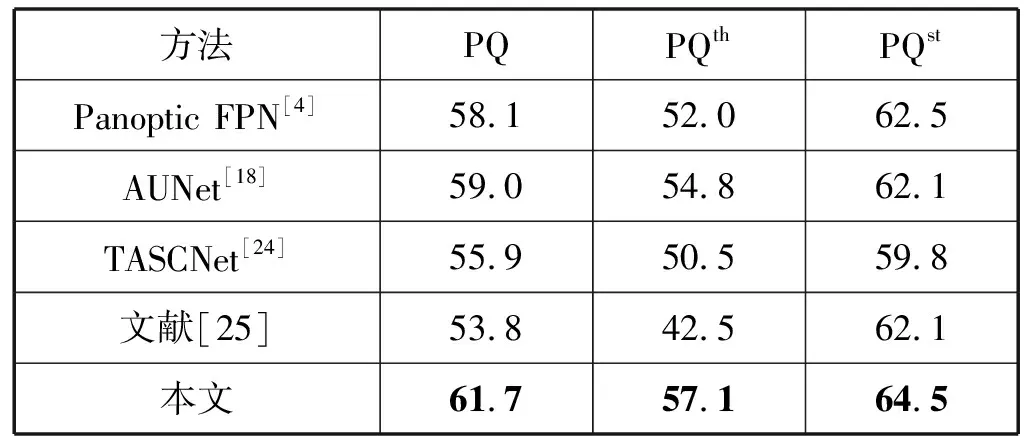
表5 Cityscapes数据集下与其他全景分割网络的实验对比(%)
3.5 运行时间对比
本文使用了NVIDIA GeForce GTX 1080 Ti GPU将改进后的网络与AUNet[18]、Panoptic FPN[4]、原网络运行100次的平均时间(AvgTime)对比,得到的结果如表6所示。
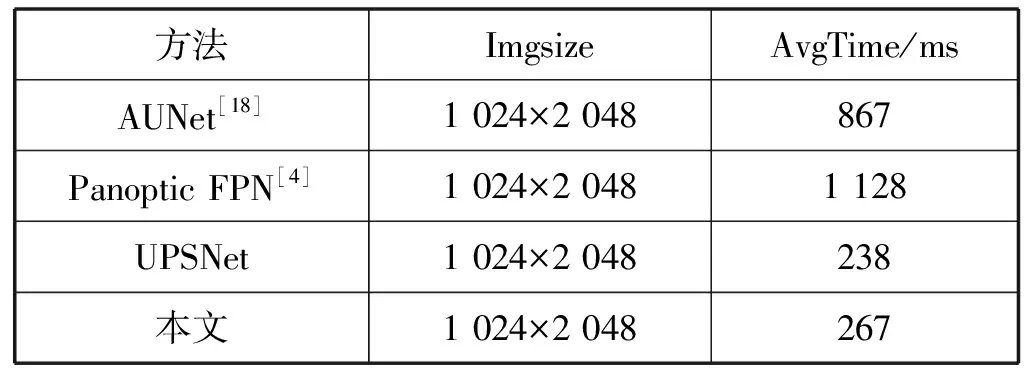
表6 同一硬件平台下Cityscapes数据集运行时间对比
可以看出,在Cityscapes数据集下,UPSNet的速度相对其他优秀的全景分割网络是比较快的,相对其他网络而言更适合应用于城市道路场景用于辅助驾驶,而改进后的网络与原网络相比,时间相差无几,分割的结果有所提升,实验证明,改进的网络是有效的。
4 结 语
本文针对全景分割网络UPSNet在特征提取阶段可能产生的特征提取不充分的问题,以及为了减少错误的特征信息到之后的语义分割子网络和实例分割子网络中,对其特征提取阶段进行改进,提出结合特征递归金字塔(RFP)的UPSNet改进网络。经过与基准网络在自行标注的交通场景全景分割数据集和Cityscapes数据集下的实验结果对比,本文网络比基准网络的PQ值都有较大的提升。另外,本文还与其他优秀的全景分割网络在Cityscapes数据集下进行了实验结果对比,可以发现本文的改进是有效的。实验证明,本文改进后的网络更加适用于复杂的交通场景,比原网络更加适合于应用在智能驾驶中。在接下来的工作中,本文将对基准网络的子网络进行优化,研究如何在两个子网络之间可以做到更好的共享,如何将两个子网络预测的结果进行更好的结合,从而可以更好地应用在自动驾驶领域。
