一种基于链路优化的社团挖掘算法及其应用
2023-09-04姚鑫宇肖玉芝赵洪凯
姚鑫宇 肖玉芝 赵洪凯
(青海师范大学计算机学院 青海 西宁 810016) (青海省藏文信息处理与机器翻译重点实验室 青海 西宁 810016) (藏文信息处理教育部重点实验室 青海 西宁 810016)
0 引 言
复杂网络社团挖掘对分析网络拓扑结构起着至关重要的作用,其研究成果被应用到推荐系统和社会网络分析等领域中[1]。Newman等[2]将社团定义为一组在网络内部连接紧密而相互间连接稀疏的子图。社团结构广泛存在于现实世界中,例如通信网络中的不同个体,因为朋友关系而形成团簇。社交网络中基于个体兴趣爱好,自发形成彼此间关联紧密的不同社团。随着5G的发展和移动设备的普及,运营商更加注重分析用户的兴趣偏好,从而为其制定个性化产品推荐,并且依靠用户团体进行推广。因此,在海量数据中运用社团挖掘技术快速划分出不同兴趣爱好社团显得尤为重要。
经典社团挖掘算法有基于模块度优化的G-N算法、Louvain算法和基于标签传播的LPA算法[3]。G-N算法是一种采用分裂思想的社团挖掘算法,算法中通过不断计算边介数并删除介数值最高的连边获取社团划分,但该算法时间复杂度较高,不适用于超大网络规模[4]。Blondel等[5]提出Louvain算法,其计算速度较快,由于采用一种与G-N算法相反的自下而上的凝聚过程,不会对小规模的社团探测产生遗漏。基于标签传播的LPA算法最早由Raghavan等[6]中提出,该算法时间复杂度接近线性时间(O(m),其中m为边数目),但算法运行过程中却因为节点选择随机性导致结果不稳定。
鉴于上述经典社团挖掘算法的优缺点,有学者提出基于节点相似度的社团挖掘算法。化君[7]根据节点相似性提出了ADL-CN算法,该算法通过计算两个节点之间的共邻居数来决定增加或删除两个节点之间的连边进而获得社团结构。武龙举[8]通过计算接近度中心性与Jaccard相似系数提出了一种距离中心性相似度指标,并通过使用K-means聚类算法实现网络中社团的挖掘。节点相似度的计算方法有两种:基于局部信息的节点相似度指标和基于全局信息的节点相似度指标。
随着网络规模增大,节点间多维性关系增加,在社团挖掘中很难获取节点的全局拓扑信息。因此为了尽可能利用节点的拓扑信息,并准确划分出其归属社团,本文提出一种基于链路优化的P-L(Priority-Louvain)算法,即选取基于局部信息相似度指标对网络链路进行处理,预测网络中未正确采集到的节点关系,删除在收集信息过程中产生的错误关系,形成初始社团结构,并结合Louvain算法的多层次优化Modularity指标衡量社团挖掘结果质量。通过验证,算法既能刻画出社团的紧密程度,又能较大程度地保留节点归属,并且提升了Louvain算法的社团挖掘质量。
本文使用常用数据集与经典的社团挖掘算法Louvain、GN和LPA算法进行实验对比。结果表明,P-L算法在社团挖掘质量上比其他算法均有一定的提升。作为算法的应用,本文构建并刻画了一个两层网络模型,第一层为用户层,第二层为用户使用的App应用层,简称“用户-App”网络。利用P-L算法对网络中所有用户使用的视频类App进行探测划分,得出使用如爱奇艺等App的用户群体,为通信行业的客户细分提供决策。
1 预备知识
1.1 Salton指标
Salton指标[9]即余弦相似性,是一种用于描述两个节点之间的相似度指标,Salton指标值越大,两个节点之间的相似度越高。稀疏网络中Salton指标也具有较好的计算效果。本文利用Salton指标衡量节点间的相似度,进而为链路优化过程提供依据。Salton指标计算式为:
(1)
式中:A和B为网络中的任意两个节点,k(A)、k(B)分别为节点A和节点B的度。
1.2 社团挖掘评价指标
1.2.1模块度Q函数
Newman和Girvan在研究社团挖掘问题的同时,提出了用模块度Q函数衡量社团挖掘的效果。
所谓模块度,是指在网络中连接社团内部节点的边所占比例与某一个随机网络中连接社团内部节点的边所占比例的期望值的差值[10]。其中,这个随机网络的构造方法为:在保持各个节点的社团属性不变的同时,按照节点的度来对网络中的节点进行随机连接。在具有较强社团结构的网络中则社团内部的连边比例应高于随机网络的期望值。模块度计算式为:
(2)
式中:M为已发现的社团个数;L为网络中的边数;ls为社团s中边的数目;ds为社团s中包含边的总数目。
1.2.2NMI指标
NMI(Normalized Mutual information)指标即标准化互信息,用来衡量算法划分出的社团和真实社团之间的相似程度[11]。设X、Y分别表示网络两个特定的社团划分结果,X、Y中的第i位表示第i个节点所归属的社团,互信息越大,X、Y越相近。互信息计算式为:
(3)
式中:p(x,y)表示X、Y的联合分布概率,将互信息调整到0~1之间即为标准互信息。标准互信息计算式为:
(4)
式中:H(X)和H(Y)为熵。
1.2.3ARI指标
ARI指标(Adjusted Rand Index)是应用于评估聚类效果的指标[12],社团挖掘本质上也是一种聚类问题,因此采用ARI指标对社团挖掘效果进行评估,计算式为:
(5)
式中:C为给出的真实网络社团划分。设K表示社团划分的结果,a表示C与K中属于同一社团元素的对数,b表示C与K中不属于同一社团元素的对数。
1.3 Louvain算法
Louvain算法[5]是一种基于模块度优化的社团挖掘算法,该算法具有良好的时间复杂度和社团划分效果。Louvain算法流程如下:
1) 初始,将网络中每一个节点视作一个单独的社团。
2) 从网络中随机选取一个节点执行步骤3)和步骤4)。
3) 对于选定的节点i,找到其全部的邻居节点,同时计算将节点i与其各个邻居节点合并后产生的模块度增益。
4) 找到产生模块度最大增益的邻居节点,若模块度增益值大于0,则将i移动至此节点所在的社团:
当网络中所有的节点都无法再被移动时,将同一社团中的所有节点合并为网络中的一个新节点,这个节点继承该社团与其他社团之间的连边。
5) 对经过重新构建的网络进行迭代,直至网络中所有节点均无法移动,则输出结果,算法结束。
2 P-L算法
2.1 算法描述
为了将Louvain算法推广到连边缺失或噪声网络中,结合Salton指标,提出了一种基于链路优化的社团挖掘算法,记为Priority-Louvain算法,简称P-L。首先使用Salton指标获取整个网络节点相似度矩阵,接着根据设定的相似度阈值重新构建网络,最后使用Louvain算法划分社团。社团划分过程中既充分利用了节点的拓扑信息又提升了Louvain算法划分质量。
算法实现如下:
第一步:根据网络关系生成网络节点相似度矩阵Similarity(v,w),其中v和w为网络中的两个任意节点。流程如下:
输入:网络图G。
输出:网络节点相似度矩阵Similarity(v,w)。
1) 遍历网络图G中的每个节点v。
2) 遍历网络中除v以外的所有节点w。
3) 计算v和w的Salton指标,并填入相应位置。
4) 返回Similarity(v,w)。
第二步:使用Louvain算法对生成的网络节点相似度矩阵Similarity(v,w)进行社团挖掘。流程如下:
输入:Similarity(v,w)。
输出:网络社团划分。
1) 计算网络节点平均度,根据该值设定相似度阈值。
2) 将网络节点相似度矩阵Similarity(v,w)中大于该阈值的元素值置为1;小于该阈值的元素置为0;主对角线元素置为0,从而生成优化后的网络邻接矩阵A(i,j),其中i、j为网络中的节点。
3) 将优化后的网络邻接矩阵A(i,j)转化为网络。
4) 采用Louvain算法进行社团挖掘。
5) 输出最终的网络社团结构。
2.2 两个经典网络实例
2.2.1Zacharykarateclub网络
Zachary karate club网络[13]是由34个成员组成的网络,网络中的节点由每位成员抽象而来,成员与成员间的联系抽象为网络中的连边,网络中共包含34个节点和75条连边。因俱乐部内部对增加会费问题产生分歧,最终社团分裂为以俱乐部主管(0号节点)和校长(32号节点)为中心的两个团体,该网络是用于研究社团的经典网络,常被用于评估社团挖掘算法的效果。为了验证本文算法的正确性与优越性,使用Zachary karate club网络对社团挖掘算法进行比较,并使用Gephi工具进行可视化。
首先通过使用链路优化对Zachary karate club网络进行重构。实验中设定节点间相似度阈值为0.35,即节点与节点间相似度高于0.35则存在连边,若节点与节点间相似度低于0.35则不存在连边,空手道俱乐部生成为一个34×34的相似度矩阵。
对网络进行重构,生成了包含34个节点以及184条连边的新网络,如图1所示。
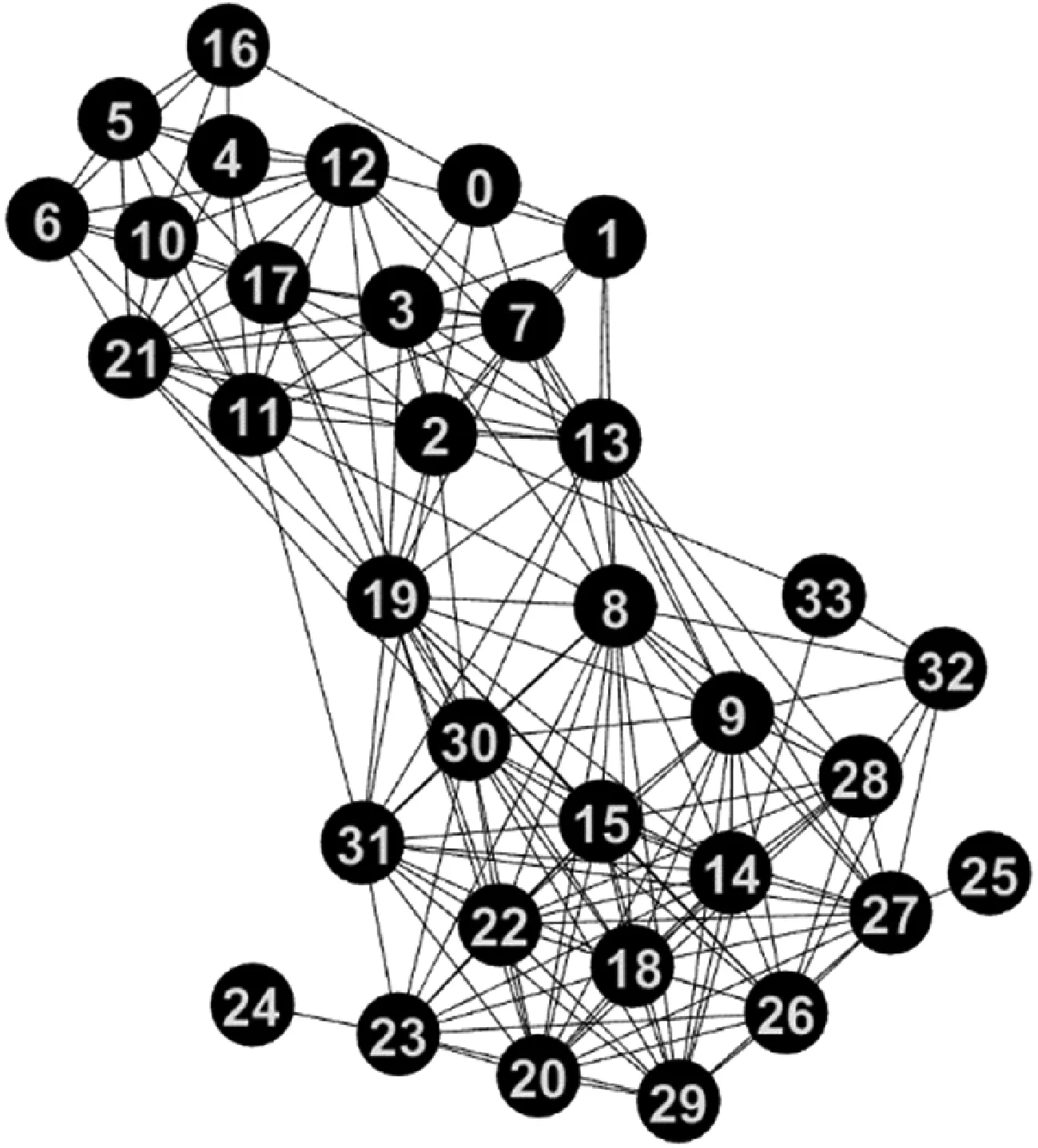
图1 Zachary karate club网络重构图
使用Louvain算法对新网络进行社团挖掘,结果显示仅8号节点的社团划分错误,如图2所示。
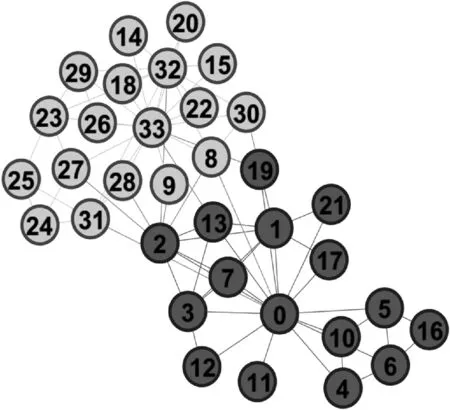
图2 P-L算法在Zachary karate club网络运行结果
为了进一步验证算法的可靠性,利用P-L算法与Louvain算法、LPA标签传播算法和G-N算法在Zachary karate club网络针对模块度Q函数值、NMI指标、ARI指标和社团划分数量上进行比较,最终结果如表1所示。
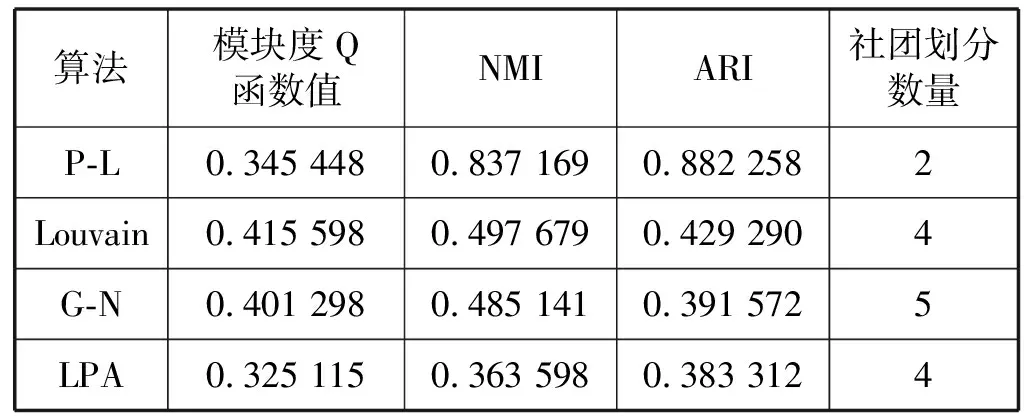
表1 各社团挖掘算法在Zachary karate club网络上结果比较
经过实验比较发现,相比于其他三种经典算法,P-L算法对社团挖掘质量有显著提升。从表1中看到,P-L算法中的Q函数值小于G-N算法和Louvain算法中的Q函数值,通过查阅资料,得知Zachary karate club网络是由一个完整的社团分裂而来,所以分裂后的两个社团成员间仍然存在着较多的联系,造成P-L算法在进行链路优化增加社团内部连边的同时也增加了较多的社团间连边,导致Q函数值略低,但是整体社团划分质量较好。
2.2.2Football网络
Girvan等[14]通过对美国115所大学球队间的613场橄榄球比赛进行统计,建立了Football网络模型。将这115支队伍抽象为网络中的节点。613场比赛抽象为网络中的连边,便构成了Football网络。对Football网络进行社团挖掘后的结果一般为8~12个社团。运用P-L算法,该网络最终划分为12个社团。算法运行过程与Zachary karate club网络相同。社团挖掘结果如图3所示。

图3 P-L算法在Football网络上运行结果
通过计算得出,网络模块度为0.866 882,社团划分数量为12个,P-L算法与其他社团挖掘算法对比见表2,在Football网络上,无论是划分数量还是划分质量均比较优越。
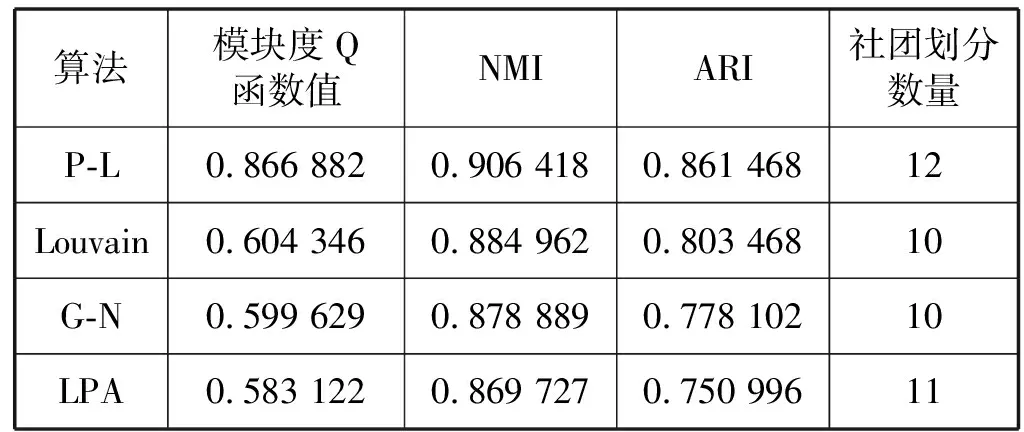
表2 各社团挖掘算法在Football网络上结果比较
3 实证社交网络社区划分
3.1 数据预处理
随着互联网的快速发展,人们更倾向于借助手机来获取各种社交应用并进行交流。对于通信行业运营商而言,分析客户使用产品的行为,制定个性化产品推荐变得非常重要。
本文使用某运营商提供的实验训练数据构建了网络模型,并利用P-L算法进行社团检测。实验数据包含1 174位用户和用户使用的6款视频类App见表3所示。

表3 用户App使用情况
其中爱奇艺、腾讯和优酷三家视频平台分属于百度系、腾讯系和阿里系应用,代表了传统视频平台,快手、抖音和西瓜视频代表了新兴短视频平台。本文通过对用户数据进行采集、分析、处理以及模型构建等过程后,利用社团挖掘技术,将用户根据其使用的视频平台准确聚类。为运营商根据社团规模和社团划分推出流量套餐业务提供了决策参考。
通过用户使用特定App流量大小衡量用户对其爱好程度。同时由于传统视频类App和短视频类App应用场景不同,其所产生的流量信息并不能直接使用,因此首先对用户流量数据进行标准化处理[15-16]。数据标准化过程如下:
输入:某款App的用户流量信息xi、使用人数n。
输出:流量信息标准化结果a。
具体步骤如下:

4) 输出用户流量标准化信息a。
为方便后期比较,本文对App进行了编号(详见表4),并根据标准化结果a将每款App的用户分为低于平均流量、低于但接近平均流量、高于但接近平均流量和高于平均流量四个等级(详见表5)。

表4 App编号表
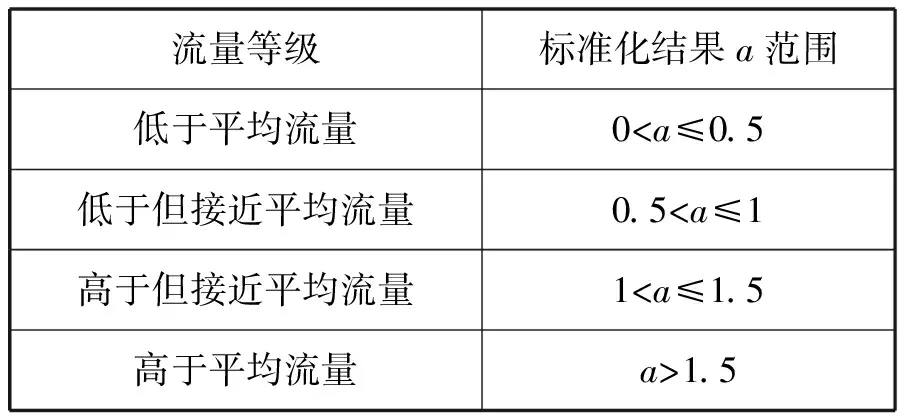
表5 流量等级表
3.2 网络模型构建
根据数据预处理的结果,将数据分为用户层和App层,用户层包含1 147个用户,App层包含6款App,如图4所示,“用户-App”两层网络的初始模型。
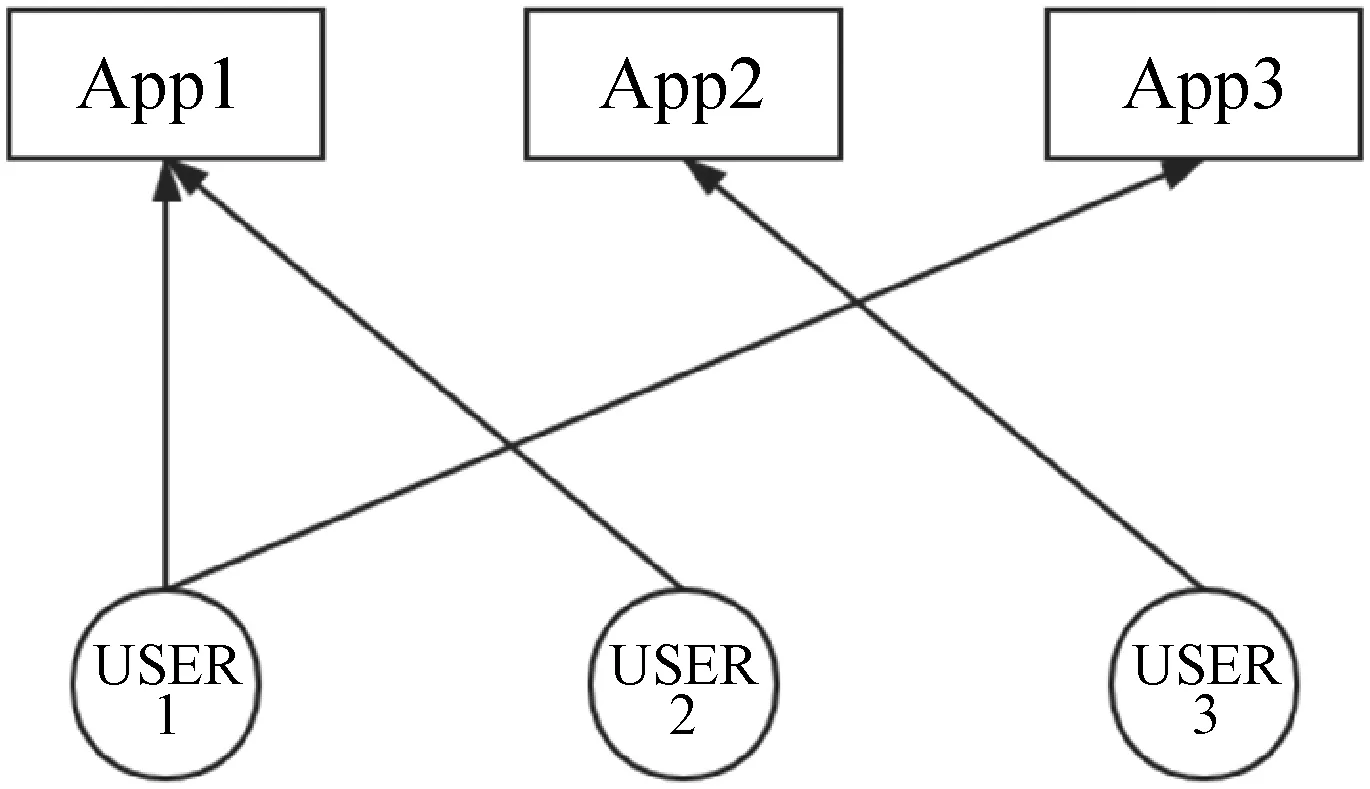
图4 “用户-App”网络示意图
可以看出,两个独立网络层内没有连边,层间依据用户使用App行为进行连边。为了构造用户与用户间的关联,结合App流量等级差异值,利用随机概率p刻画用户层内节点连边关系。即将“用户-App”层间关系映射成用户层内关系,并生成最终的网络模型G。构建规则如下:
1) 针对使用一款App的用户。若用户间使用同款App且流量等级相同,则用户间以概率p1连边。若用户间使用同款App但流量等级不同,则用户间以概率p2连边。
2) 针对使用多款App的用户。
(1) 若用户使用的App和流量等级均与使用单款App的用户群体相同,则该用户以概率p3与仅使用单款App的用户群体进行连边。
(2) 若用户使用的App和仅使用单款App的用户群体相同但流量等级不同,则该用户以概率p4与仅使用单款App的用户群体进行连边。
经过大量对比实验,针对网络模型G,确定了4种连边概率取值,分别为p1=0.020、p2=0.016、p3=0.160、p4=0.100。
网络模型G包含了1 174个节点,8 331条连边。网络直径为7,平均聚类系数为0.061,平均路径长度为3.415,其拓扑结构如图5所示。

图5 网络模型G可视化图
3.3 基于P-L算法的社团划分
为验证选取Salton指标的合理性。本文设计了一组对比实验,分别使用Salton指标和Jacaard相似系数来进行链路优化,在同一相似度阈值且划分结果相近的前提下基于Salton指标优化后的网络,其模块度函数值为0.748 301,基于Jaccard相似系数优化后的网络模块度函数值为0.499 243。结果表明采用Salton指标的P-L算法可以正确地对网络进行社团划分。相对于Salton指标,Jaccard相似系数值偏低且链路优化后的网络模块度函数值小于Salton指标。因此,采用Salton指标预测的社团内部链接与外部链接的比值要更大。
不同社团挖掘算法在实证网络上的运行结果如表6所示。显然,P-L算法在社团划分精度和模块度值上均表现出较优性。该算法成功识别了6款App社团(如图6)。不难看出,抖音用户更倾向于使用爱奇艺,快手用户更倾向于优酷视频。根据划分结果,制定短视频类与传统视频类相结合的流量包,在增加用户体验的同时进行用户团体推广。

表6 各社团挖掘算法在实证网络上结果比较

图6 P-L算法在实证网络上运行结果
4 结 语
本文利用节点相似度设计了基于链路优化的Louvain社团挖掘算法,并通过实验证明了该算法的可行性及准确性。通过建立“用户-App”模型来将算法进行推广和应用。该算法无须预先设定社团划分数目,只需要调整相似度阈值可提高划分精度,并且算法在连边稀疏或密集的网络中均具有良好的适应性。在实验过程中,算法在做划分时会出现一些孤立节点或错误划分的情况,因此下一步将对算法存在的缺陷进行改进并将算法推广到复杂多层网络模型中,针对层间关联的差异性进行社团挖掘。
