基于改进VoVNet的人脸表情识别
2023-09-04王彬彬周心荆
李 娇 王彬彬 周心荆 冉 峰*
(上海大学微电子研究与开发中心 上海 200000) 2(上海大学新型显示技术及应用集成教育部重点实验室 上海 200000)
0 引 言
人脸表情包含着丰富的情感信息,能够直观地反映喜怒哀乐等各种情绪。因此,表情识别可作为情感研究的一个重要方向,是人机交互的重要组成部分[1],在医学、教育、商业营销等领域都有着广泛的应用。
人脸表情识别主要有三个步骤:人脸检测、特征提取及表情分类。其中,特征提取在表情识别任务中起到核心作用,特征提取方法主要有基于传统手工设计的特征提取和基于深度学习的特征提取。
传统手工特征提取方法,如局部二值模式(Local Binary Pattern,LBP)[2]、尺度不变特征变换(Scale Invariant Feature Transform,SIFT)[3]、定向梯度直方图(Histogram of Oriented Gradients,HOG)[4]等,这些方法较为复杂,且不易提取图片的高层次特征。
随着技术的快速发展,越来越多的深度神经网络不断涌现,例如AlexNet[5]、VGG[6]和ResNet[7]等。这些网络被广泛应用于图像、语音等各个领域,在人脸表情识别任务上,也取得了较好的效果。但随着深度神经网络模型的不断发展,它的弊端也逐渐凸显。不断加深、加宽的模型,使得模型参数庞大化、模型计算复杂化,这些都不利于模型在移动端和嵌入式设备中的应用。
基于以上背景,本文提出一种新型网络结构EM_VoVNet。该网络基于VoVNet[8],设计了新的特征提取框架,改变输入尺寸大小为44×44×3,大大减少了模型参数和计算量。采用组合池化的思想,在浅层特征提取时组合了3×3的卷积特征和池化特征的两路特征,丰富了浅层特征图的学习。另外,还在模块内引入了注意力机制,增强不同通道间的特征学习。最终实验证明,设计的EM_VoVNet具有较好的轻量级特性和良好的表情识别率,有利于模型进一步在低内存资源的设备上实现实时表情识别。
1 VoVNet介绍
VoVNet由DenseNet密集网络发展而来。Dense Block结构如图1所示。该模块通过逐次卷积,将每层神经网络的输出密集连接到后面的每一层卷积作为输入,大大减少了参数模型。由于聚合了不同层感受野的中间特征,该网络在物体检测任务上取得了良好的效果。但另一方面,由于密集连接的聚合作用,该网络模块的输入通道数不断增加,而输出通道数固定,使得其存在高内存访问成本(Memory Access Cost,MAC)和高能耗的问题,导致模型的推理速度慢。且每个层对之前层的聚合学习、重复利用,会导致中间层的特征信息对最后分类层的提供的有用信息少,造成中间层的特征冗余。

图1 Dense Block结构
在ShuffleNetV2[9]论文中,给出了MAC的计算方式,如下:
MAC=hw(ci+co)+k2cico
(1)
式中,k、h、w、ci、co分别表示卷积核的大小、特征图的高、特征图的宽、输入通道数和输出通道数。卷积层的计算量为B=k2hwcico,若固定B值,则有:
(2)
由式(2)可知,当ci=co时,MAC取得最小值,内存访问成本最低。由此,VoVNet模型中提出了OSA(One Shot Aggregation)模块,如图2所示。OSA模块设定了模块内的卷积具有相同的输出通道数。这使得GPU可以进行高效并行计算,且达到卷积输出、输入通道数相等,从而降低内存访问成本以及能耗。另外,它只在每个卷积模块的最后,进行特征图融合,减少了中间层的冗余特征。
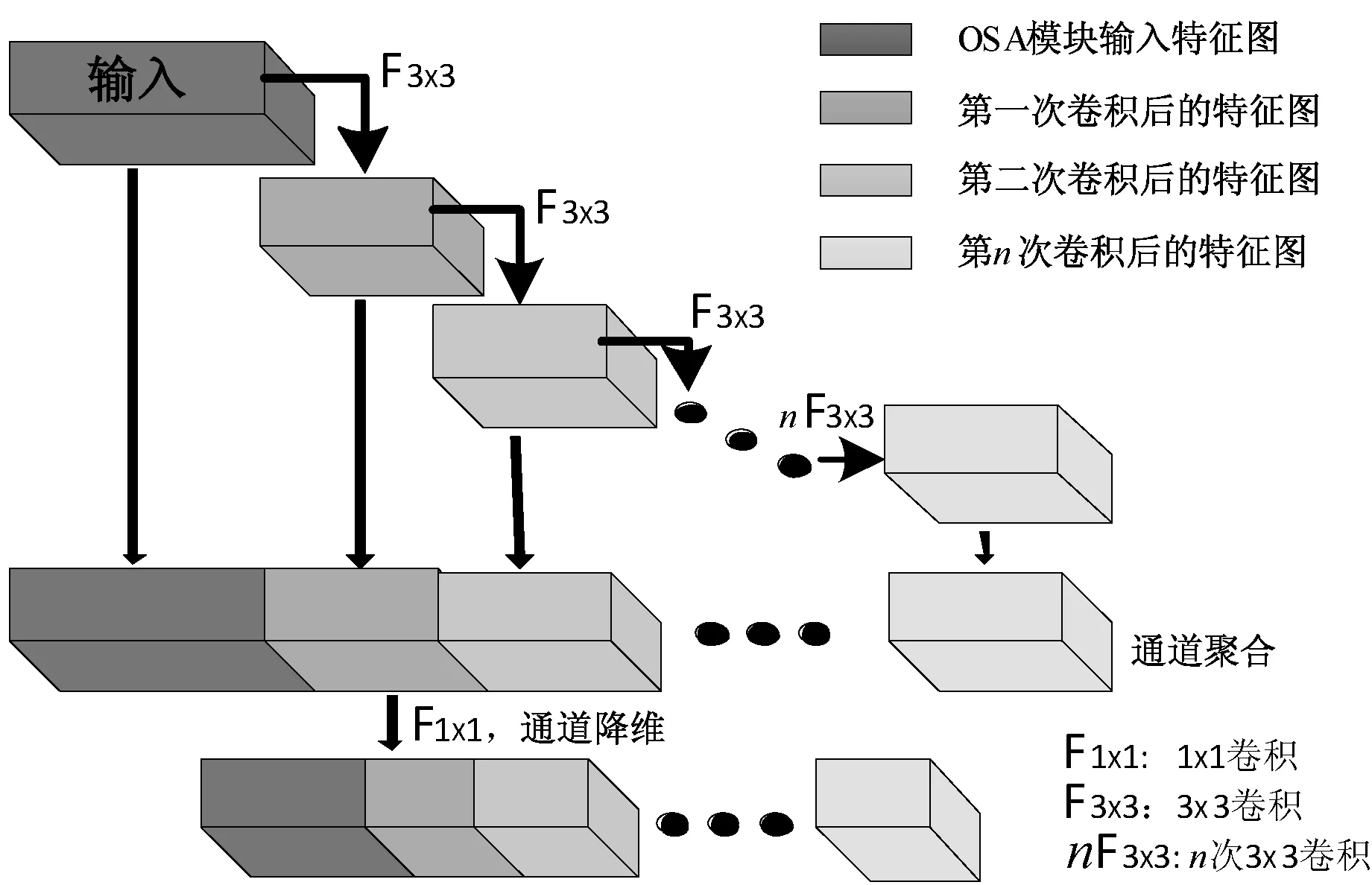
图2 OSA模块结构
VoVNet主要由OSA模块组成,有三种不同方案的构造。其中,VoVNet-27s包含的OSA模块数最少,相比另外两个模型更具有轻量级特性、参数计算量少、内存资源要求低的优点,因此本文采用该模型进行改造来完成轻量化表情识别网络的搭建。
VoVNet-27s的具体结构如表1所示。其中:c0表示浅层卷积输出通道数;c1表示OSA模块内卷积核输出通道数;n表示模块内的3×3卷积次数;Concat&1×1表示对模块内的所有输出特征图进行融合,并用1×1卷积进行降维,最后输出的卷积核通道数为c2。
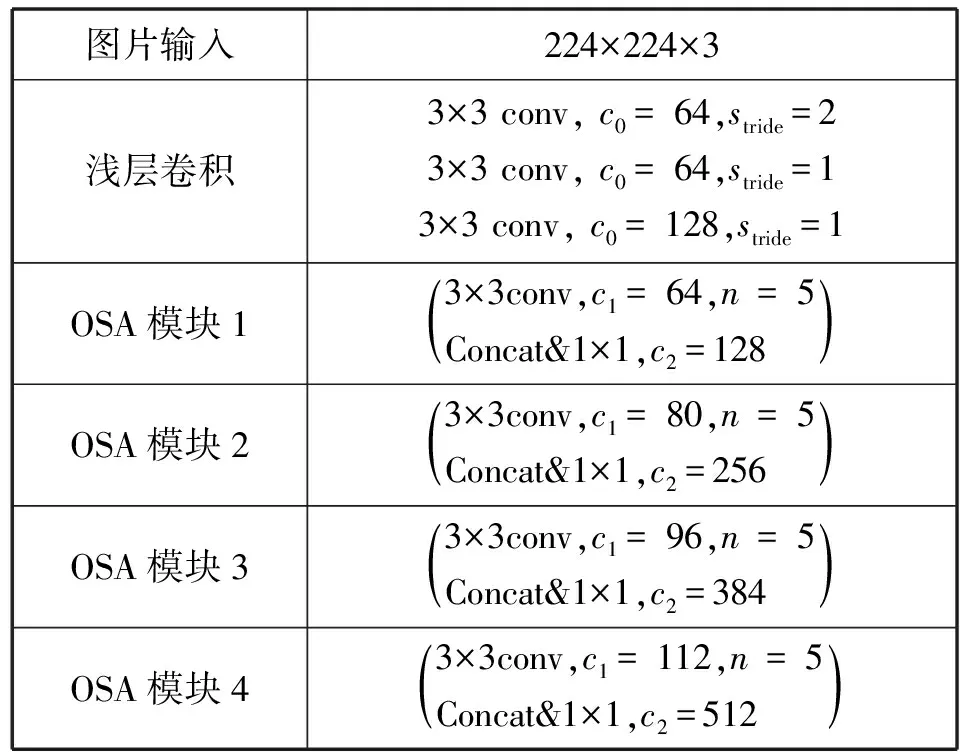
表1 VoVNet-27s的网络结构
2 改进VoVNet结构
2.1 浅层特征提取结构设计
VoVNet应用于目标检测分类任务,需要寻找目标在图像中的位置,再对目标进行分类,因此图像往往具有较大的输入尺寸为224×224×3。而表情识别无须检测目标位置,只需实现对网络输入的人脸图像进行表情分类。因此,实验设置图片和网络模型的输入尺寸为44×44×3,以此来减少网络模型参数和计算量。
表2为改进前后的低层次特征提取模块。可以看出,原模型VoVNet的浅层特征提取结构由三个级联的3×3卷积组成,且其卷积核通道数分别设置为64、64、128。对于改进后模型44×44×3的输入设计,这一特征提取模块设计的参数过多,容易导致实验出现过拟合现象,即在训练时,模型表现出高识别准确率,但在测试时,模型对新数据的预测能力差,识别准确率低,缺少好的泛化能力。

表2 低层次的特征提取
为了提高模型的泛化能力,本文主要采用降低浅层特征层提取维度的方法,重新设计了浅层特征提取的Stem模块,如图3所示。该模块首先通过1×1卷积进行通道扩充,将特征层数目从3层增加至32层,这有利于后续模型进行更充分的特征提取。受PeleeNet[10]设计模块的启发,本文设计了两路的特征提取,与组合池化(同时利用最大值池化与均值池化两种的优势而引申的一种池化策略)相似,这两路分别为最大池化和3×3卷积,该方法通过从不同途径提取浅层卷积层特征,能够增强特征层的表达能力,且改进的Stem模块比原模块具有更少的计算量。
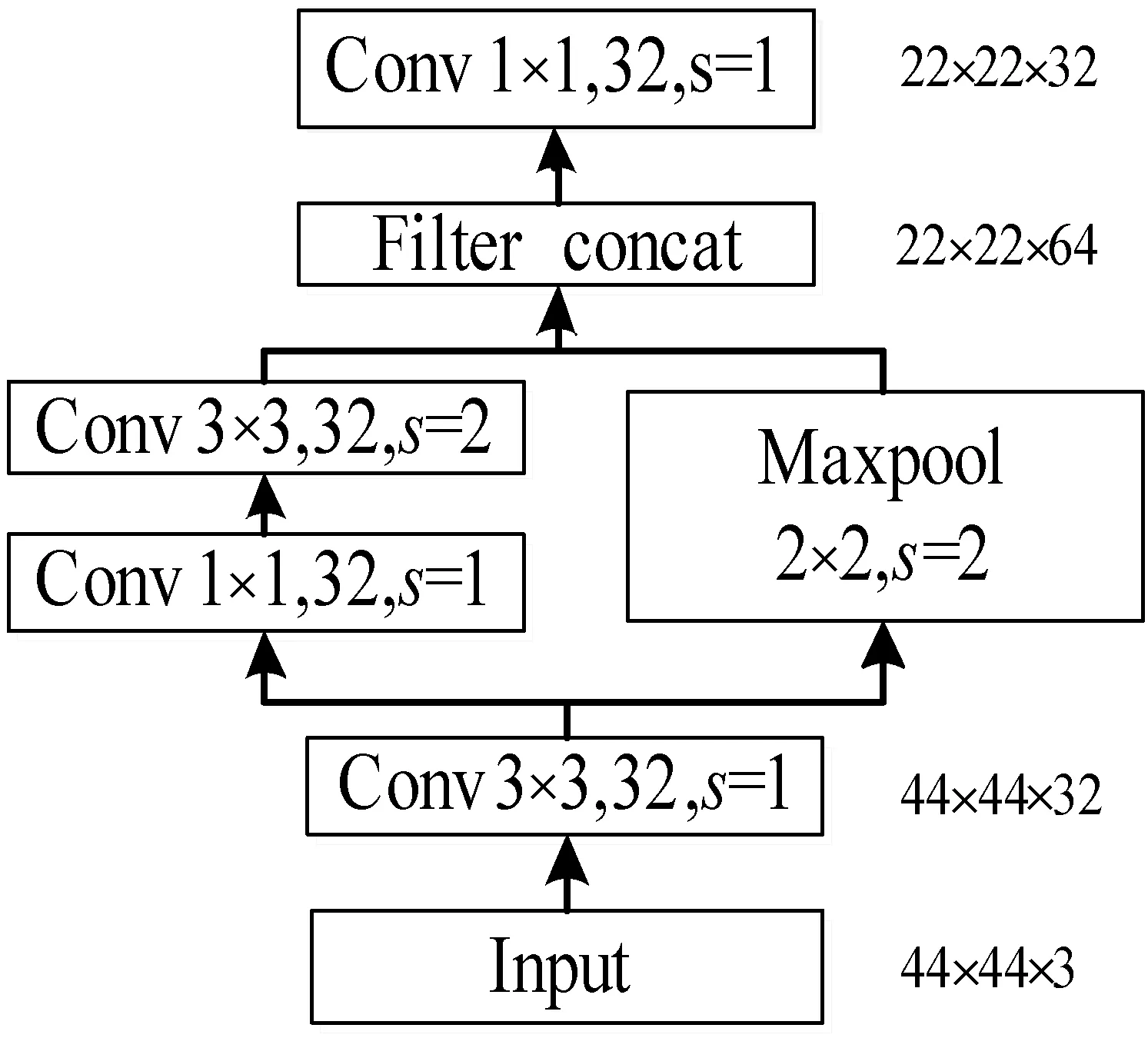
图3 Stem Block
2.2 引入ECA注意力机制
通道注意力机制在改善神经网络性能方面发挥着巨大的潜力,比如SENet[11]注意力机制通过考虑通道间的相关性,对每个通道进行自动学习,获得每个通道的重要程度,以此来增强重要特征图的表达能力;又比如CBAM[12]注意力机制,它在SENet关注通道特征的基础上增加了对空间特征图的关注和权重分配,进一步提高重要特征图的表达能力。然而还有很多方法比如AA-Net[13]、GSoP-Net[14]设计了更复杂的注意模块来获取网络高性能的特征表达,但在另一方面也增加了模型整体的复杂性,增加了卷积计算的负担。而注意力机制ECA模块[15]是一种轻量级的注意模块,它只用参数k,就可以为深度学习模型获取较好的性能增益。因此,为了增强重要特征的表达能力,同时兼顾构建轻量化模型为目的,本文引入参数量较少的轻量级注意模块ECA,其结构如图4所示。
图4中,X∈Rh×w×c为注意力模块的输入特征图,h、w、c分别是特征图的高度、宽度和通道数。X先经过GAP(全局平均池化)得到1×1×C聚合特征向量,再考虑每个通道和它k个邻居的关系来捕获本地跨通道交互,主要是由通过内核大小为k的快速一维卷积实现。然后,用Sigmoid函数对1×1×C的特征向量进行非线性化学习,生成注意力权重Wx,最后将Wx和X的对应元素进行相乘得到新的特征图χ,主要公式如下:
(3)
式中:Wx∈R1×1×C是生成的通道注意力权重;C1D表示一维卷积;GAP是全局平均池化函数;k表示一维卷积的卷积核大小;σ为Sigmoid激活函数;⊗表示对应元素的点乘运算;χ∈Rh×w×c为融合后的输出特征图。
由于使用1D卷积来捕获局部的跨通道交互,参数k决定了局部跨通道信道交互的覆盖范围,不同的通道数和不同的CNN架构的卷积块可能会有所不同。k与C的映射关系如下:
(4)
本实验设置γ=2,b=1。并且将ECA模块添加在OSA模块的最后一层,即对通道降维后的特征图进行通道注意力权重的提取和分配,具体模型如图5所示。
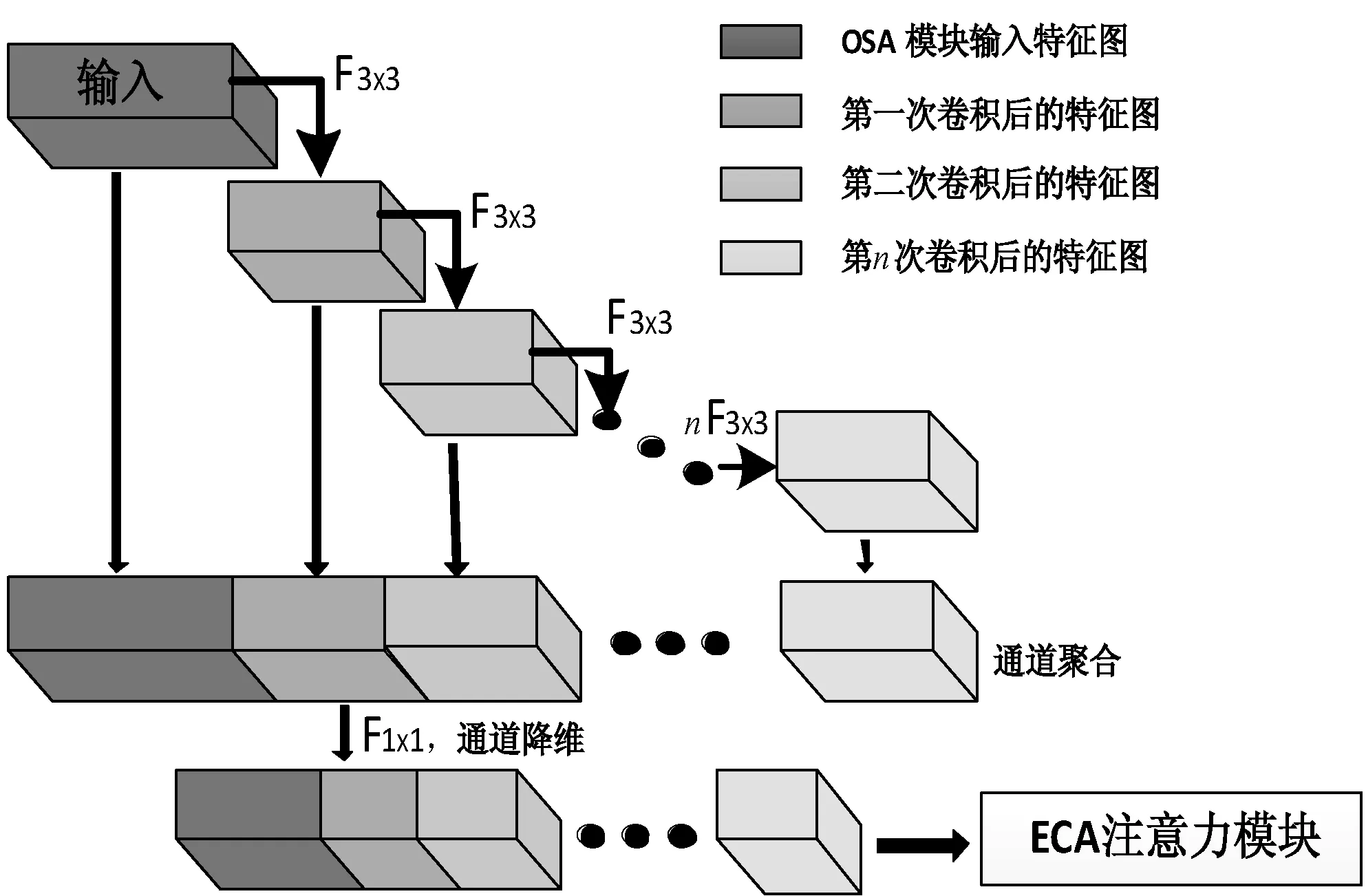
图5 增加ECA注意力模块的OSA模块
2.3 EM_VoVNet网络搭建
本文对EM_VoVNet网络进行搭建,具体结构如表3所示。EM_VoVNet先设有1个Stem block,对输入图像进行卷积和池化两路并行的操作,丰富神经网络对浅层特征图的学习。然后将输出特征图送入3个OSA模块和下采样操作交替的神经网络,依次进行特征图采样和空间降维。最后通过自适应平均池化,以及全连接线性输出进行七种表情分类。

表3 EM_VoVNet网络表
3 实验验证与结果分析
3.1 实验环境
在Windows平台下基于PyTorch框架,对本文所提出的网络进行搭建,计算机硬件配置为Intel core i7-7700HQ(主频2.8 GHz)、内存8 GB、NVIDIA GeForce GTX 1050(2 GB显存)。软件平台为Python 3.7、NVIDIA CUDA 9.2、cuDNN库。
3.2 实验数据集介绍
本文采用常用的FER2013[16]和RAF-DB[17]两个公共数据集进行实验。
1) FER2013 数据集。FER2013 数据集最初是 Kaggle 团队从互联网收集的视频中截获的面部表情图像,被用作表情识别挑战。该数据集包含35 887幅48×48像素的灰色图像,其中训练集(Training)28 708幅,公共验证集(Public Test)和私有验证集(Private Test)各3 589幅,具体表情分类数目如表4所示。图片预处理首先将每幅图像随机裁剪成10幅44×44像素的图像。最后,得到每个面部表情类别在所有10幅图片上的平均得分。

表4 FER2013表情数据集分类
2) RAF-DB 数据集。真实世界情感人脸数据库(RAF-DB)是Li等发布的人脸表情数据集。该数据集包含大约30 000幅面部图像,这些图像在被试的年龄、性别和种族、头部姿势、照明条件、遮挡等方面都有很大的差异。本文选用带有7类基本表情的部分数据集,该基本数据集其中包括训练数集12 271幅图像和测试集3 068幅图像。首先,我们将每幅图像随机裁剪成10幅44×44像素的图像。最后,得到每个面部表情类别的在所有10幅图片上的平均得分。
3.3 实验结果与分析
本文使用了Softmax损失函数和SGD优化技术,通过设置0.01的学习率和0.000 5的权重衰减,来实现损失函数的最优值求解。同时,总的迭代次数设置为300,当迭代次数大于80后,学习率就会每5代降低10%。
实验主要分为两个部分。第一部分,将改进前后的模型在FER2013和RAF-DB两个数据集上进行训练和测试,得到实验对比和实验分析;第二部分,在网络输入图片尺寸相同的条件下,将EM_VoVNet与不同的主流轻量模型比较和分析。
3.3.1实验一:EM_VoVNet的实验效果和分析
为了验证改进结构的有效性,实验将EM_VoVNet在FER2013和RAF-DB两个常用人脸表情识别数据集上进行训练和测试。图6和图7分别展示了EM_VoVNet在FER2013数据集上训练和测试时的准确率和损失值。

图6 FER2013训练集和测试集的准确率
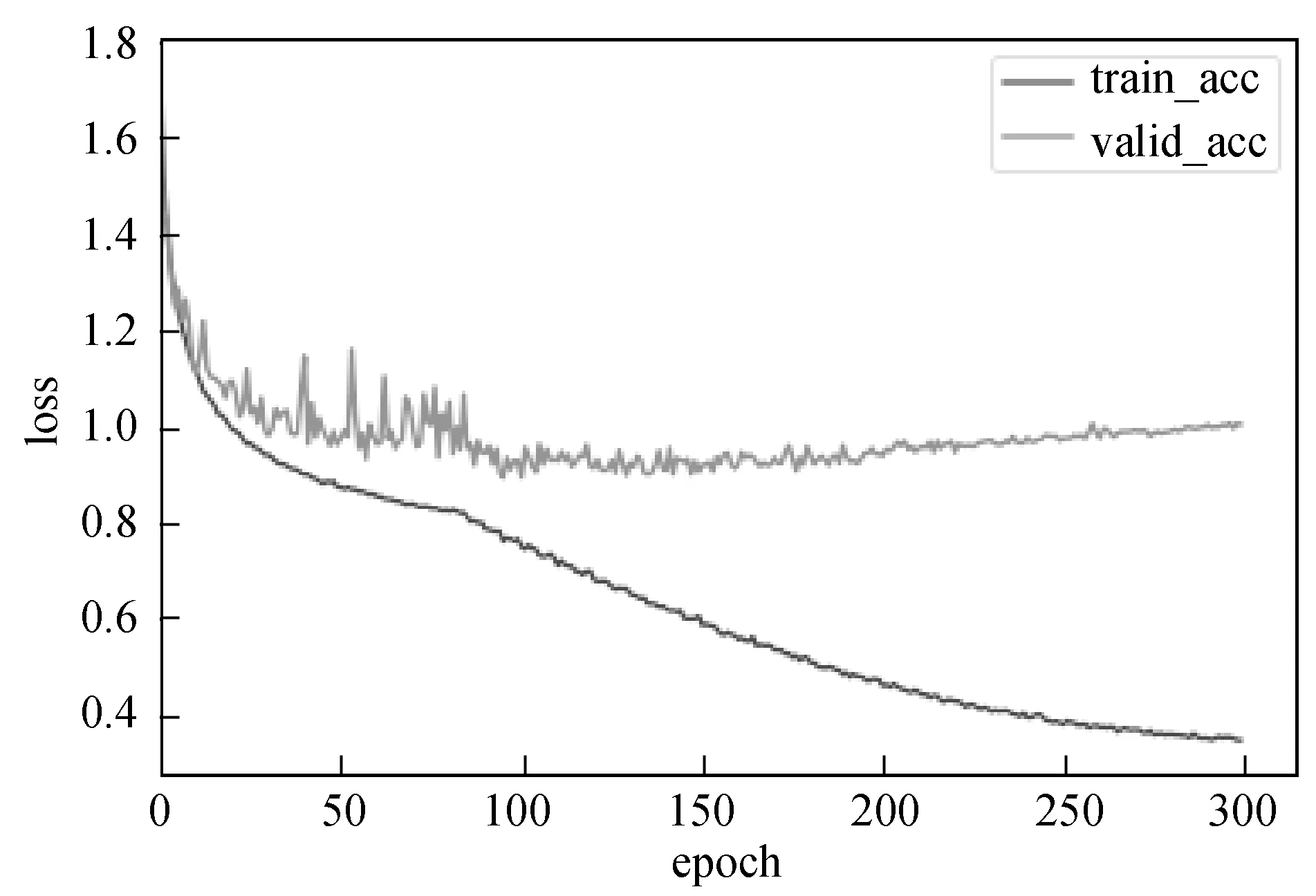
图7 FER2013训练集和测试集的损失值
由图6可知,训练250代后,训练集和测试集的准确率都趋于稳定,且测试集准确率达到了70.33%。由图7可知,此时的训练损失值也在0.4以下,趋近于0。
为了更清晰地展示EM_VoVNet在人脸表情识别任务中的表现,本文提供了网络在数据集FER2013上测试得到的混淆矩阵,如图8所示。其中,纵向标签栏为真实表情标签,横向标签栏为预测表情标签。
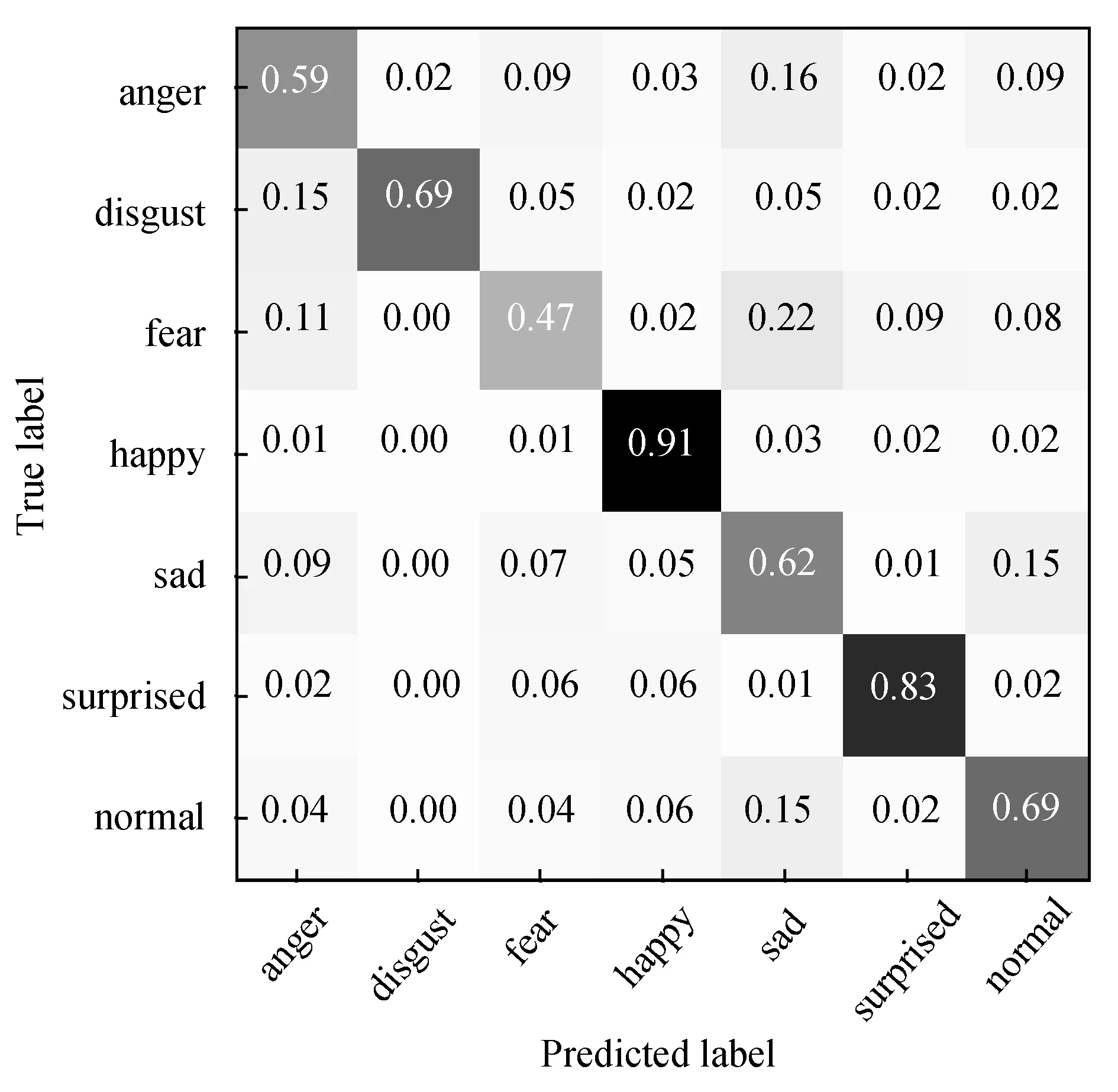
图8 FER2013混淆矩阵
从混淆矩阵中可以看出,高兴的识别准确率最高,其次是惊讶,而其余五种表情的识别效果并不是很好。其主要原因是高兴和惊讶相对于其他表情具有更明显的表情特征。比如高兴大多伴有咧嘴、瞳孔微缩,甚至眯眼的特征,而惊讶则是大都具有张嘴成O形和睁大眼的特征。而其余五种表情,尤其是害怕的表情,会因为皱眉的动作和难过的表情具有类似的特征,由此标签就容易被误判,从而降低表情识别率。
实验还将改进模型与原模型进行了实验对比。从表5中可见,EM_VoVNet的模型参数仅为VoVNet的4.5%,且FLOPs仅为原模型的23.6%。在保证相近的模型处理速度下,EM_VoVNet相比VoVNet在FER2013数据集上识别准确率提高了1.62百分点,在RAF-DB数据集上识别准确率提高了1.17百分点,由此可见改进模型具有较优的轻量性和较高的识别率。
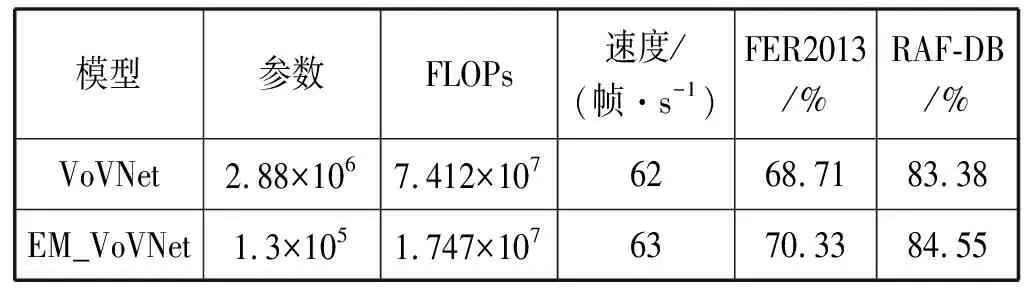
表5 EM_VoVNet与VoVNet的实验结果对比
3.3.2实验二:相同图片尺寸输入时不同主流轻量模型的实验比较和分析
现有的主流轻量网络有MobileNet、ShuffleNet、SqueezeNet等系列模型,为了验证EM_VoVNet的高效性,本文以以上模型作为对比模型,设置每个结构具有相同大小的图像输入尺寸为44×44×3,然后在FER2013和RAF-DB两个数据集上进行实验,主要从模型参数、模型复杂度FLOPs、模型处理速度、测试集准确率4个方面进行计算和记录。实验所得结果如表6所示。
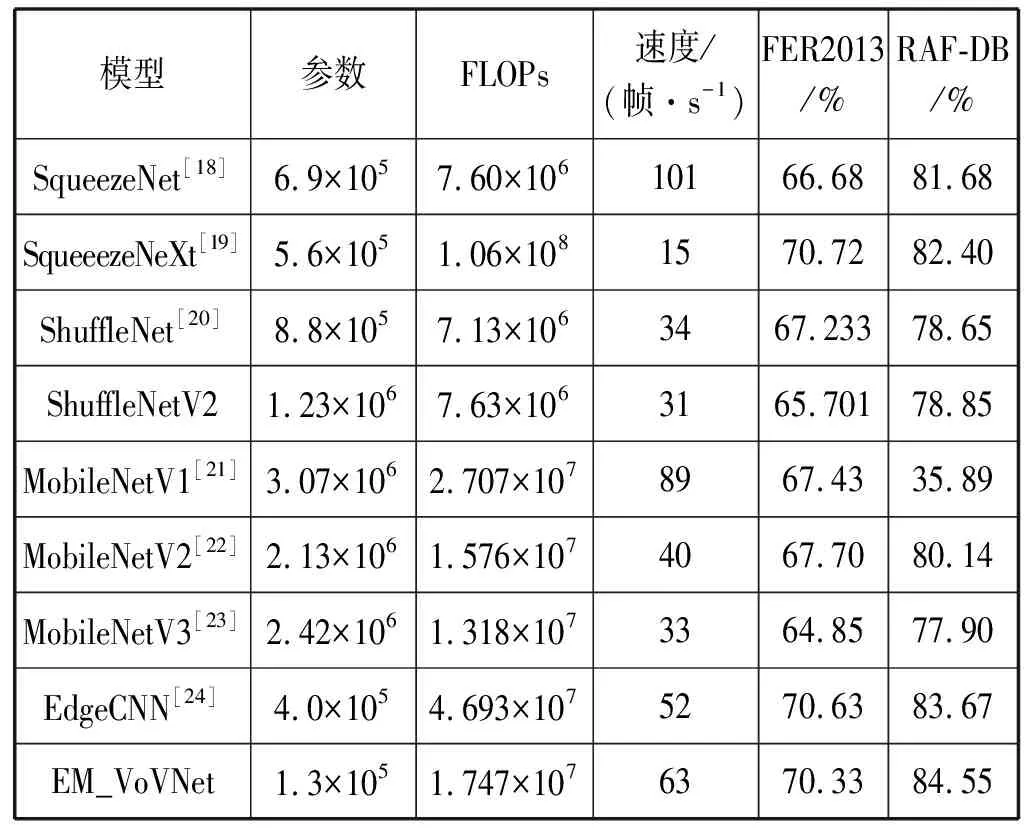
表6 相同图片尺寸输入的轻量模型在表情识别上的比较
表6中,SqueezeNet用的是1_1的版本,SqueeezeNeXt用的是1.0-SqNxt-23的结构,MobileNet和MobileNetV2使用1x 的扩张系数,MobileNetV3使用MobileNetV3-small模型。
从RAF-DB数据集上看测试效果,EM_VoVNet达到了最高的测试集准确率,且EM_VoVNet的参数值最小,非常有利于模型在低内存资源的硬件上存储。
从FER2013数据集上看测试效果,EM_VoVNet的实验准确率仅次于SqueeezeNeXt和EdgeCNN,但SqueeezeNeXt的模型过于复杂、模型处理速度最慢,性能不佳。而相比之下,EM_VoVNet具有低参数、低FLOPs、较快运行速度和高准确率的特点,模型性能佳。虽然EM_VoVNet的准确率比Edge CNN低0.3百分点,但在模型参数、FLOPs和模型处理速度三个方面,EM_VoVNet都具有更大的优势。
4 结 语
本文基于VoVNet进行改进,提出轻量化的人脸表情识别网络EM_VoVNet。该网络通过减少模块数、通道数的模型优化技术减少网络参数和计算量。重新设计VoVNet的浅层特征提取模块,并且引入通道注意力机制,增强通道间相关性特征的学习。最终,将设计的EM_VoVNet网络与其他主流轻量型识别网络共同在FER2013和RAF-DB数据集上进行实验对比,实验结果表明该网络具有最优轻量性和良好准确率。接下来将EM_VoVNet移植到低内存硬件设备上,构建完整的实时表情识别系统。
