双线性图卷积网络的环南海地区湿地遥感分类
2023-09-04李心媛楼桉君
李心媛,贺 智,2,楼桉君,肖 曼
(1. 中山大学地理科学与规划学院,广东 广州 510275; 2. 南方海洋科学与工程广东省实验室(珠海),广东 珠海 519082)
湿地具有强大的固碳功能[1],在实现我国碳达峰、碳中和目标,构建新发展格局中发挥着重要作用。环南海地区是我国建设“21世纪海上丝绸之路”的关键对象[2]。20世纪60年代以来,区域内快速城市化发展导致湿地面积减少,生态功能下降。对环南海区域开展湿地遥感监测,有利于推动全区域湿地整体性、统筹性保护。
湿地类型多样、斑块小、类间差异小[3],高分辨率遥感影像能更好地满足湿地解译需求。深度学习能有效挖掘遥感数据的深层信息[4],近年来被逐渐应用于湿地分类领域,如卷积神经网络(convolutional neural network,CNN)、生成对抗网络(generative adversarial network,GAN)等已在湿地分类中取得了一定成效[5-7]。
图卷积网络(graph convolution network,GCN)可对全局空间关系建模,能充分利用深层特征及挖掘对象间的关系[8],在湿地分类中具有巨大潜力。双线性模型[9]于2015年被提出,适用于细粒度分类,在提高湿地分类精度中具有广阔前景。基于此,本文提出基于双线性图卷积网络(bilinear GCN,BiGCN)的环南海地区湿地分类方法,以期为环南海地区的湿地监测和保护提供支持。
1 研究区与数据源
1.1 研究区概况
环南海地区共包括9个国家,地处亚热带和热带太平洋西部区域,全年湿润,降雨丰富[10]。该区域地理位置优越,具有重要的经济与军事价值[11]。本文基于FROM-GLC全球10 m分辨率地表覆盖数据[12],以分布集中且涵盖湿地类别多为原则,在环南海海岸带选择3块研究区,如图1所示。
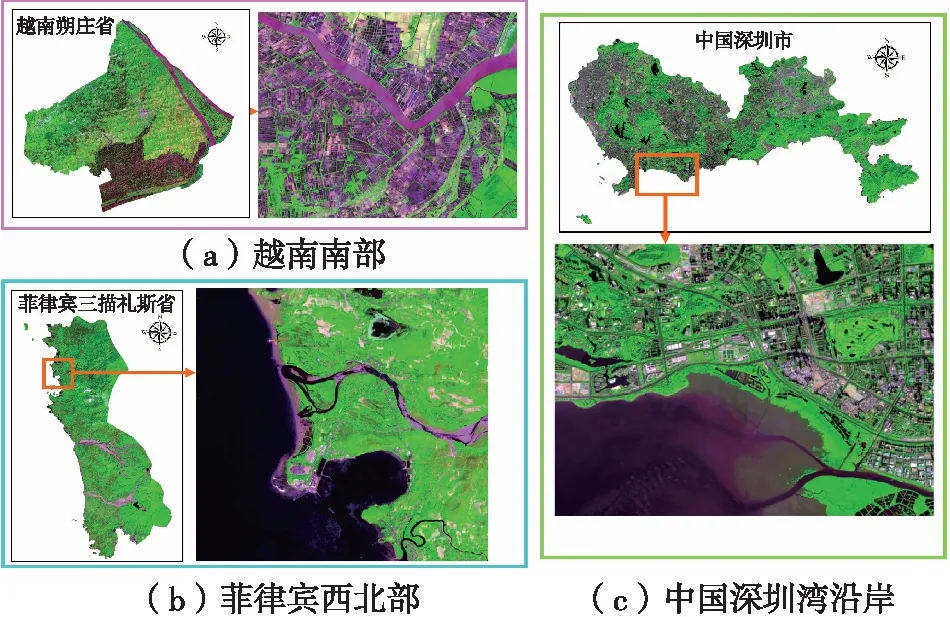
图1 研究区分布
1.2 数据源与数据预处理
针对湿地分类,选取Sentinel-2多光谱影像为主要数据源,从Google Earth Engine平台获取研究区2020年云覆盖率小于10%的Sentinel-2影像并求出均值;针对湿地特性,选取雷达、河网、地形、物候数据作为辅助,输入深度学习网络,以提高对不同类别湿地的辨别能力。数据源信息见表1。其中,雷达数据选用Sentinel-1,GRD级数据产品;河网数据选用OSM(open street map)矢量数据中的water和waterways;地形数据选用SRTM DEM;物候数据在Google Earth Engine上利用全年Sentinel-2影像求出区域空间上每个位置的年最大归一化植被指数和归一化差异水体指数,即全年最绿图和全年最湿图。
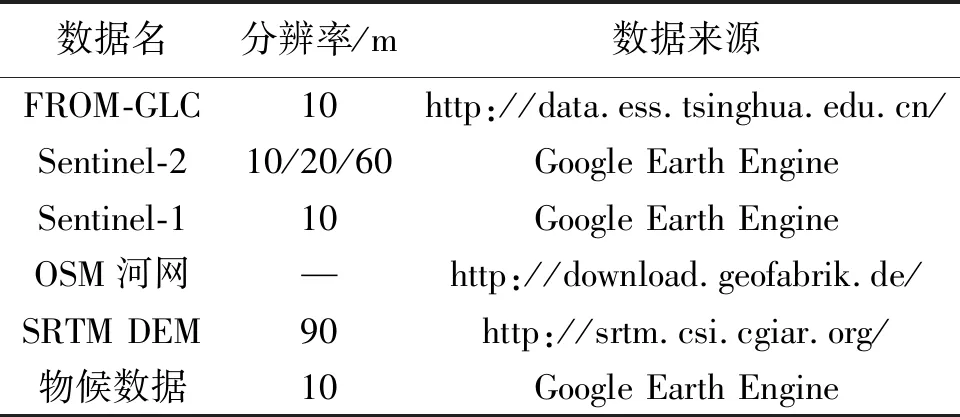
表1 数据源信息
1.3 湿地分类体系与数据集构建
综合考虑研究区实际情况和现有湿地分类标准,构建环南海地区湿地二级分类体系。遵循各类样本数目尽量均衡且在空间上均匀零散分布的原则,对3块研究区进行样本标记,分别构建越南南部数据集、菲律宾西北部数据集、中国深圳湾沿岸数据集,3个研究区大小分别为959×760、815×885、897×642像素。湿地分类体系及各数据集标记样本数见表2,标记样本分布如图2所示。试验随机选取50%的标记样本作为训练集,其余为测试集。

表2 湿地地物分类体系及各数据集标记样本信息 个
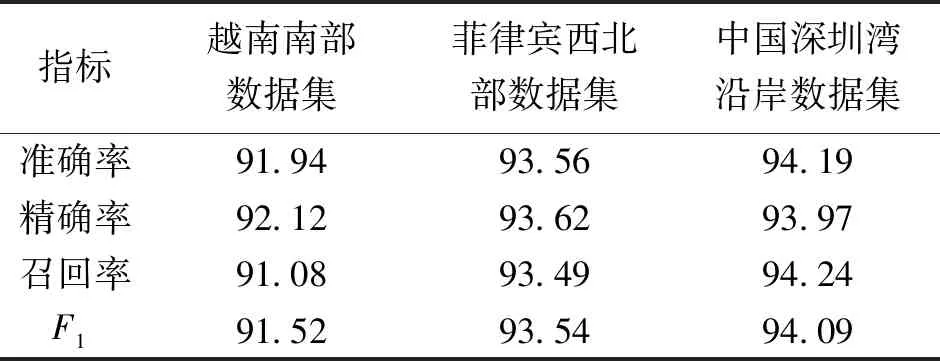
表3 RF二分类精度 (%)
2 研究方法
本文提出的基于BiGCN湿地分类方法如图3所示。首先,采用多尺度分割方法将多光谱遥感影像提取为对象块;其次,使用面向对象的随机森林(random forest,RF)[13]区分湿地与非湿地;然后,对湿地部分基于BiGCN与多源辅助数据进行二级分类,非湿地部分采用随机森林方法进行二级分类;最后,将两部分的分类结果相叠加,得到研究区影像分类结果。

图3 基于BiGCN的湿地分类方法
2.1 基于多尺度分割的对象块获取
采用多尺度分割方法获取影像对象块,越南南部数据集、菲律宾西北部数据集、中国深圳湾沿岸数据集分割后的对象块数目分别约为2000、3300、3000,3个研究区的分割结果如图4所示。
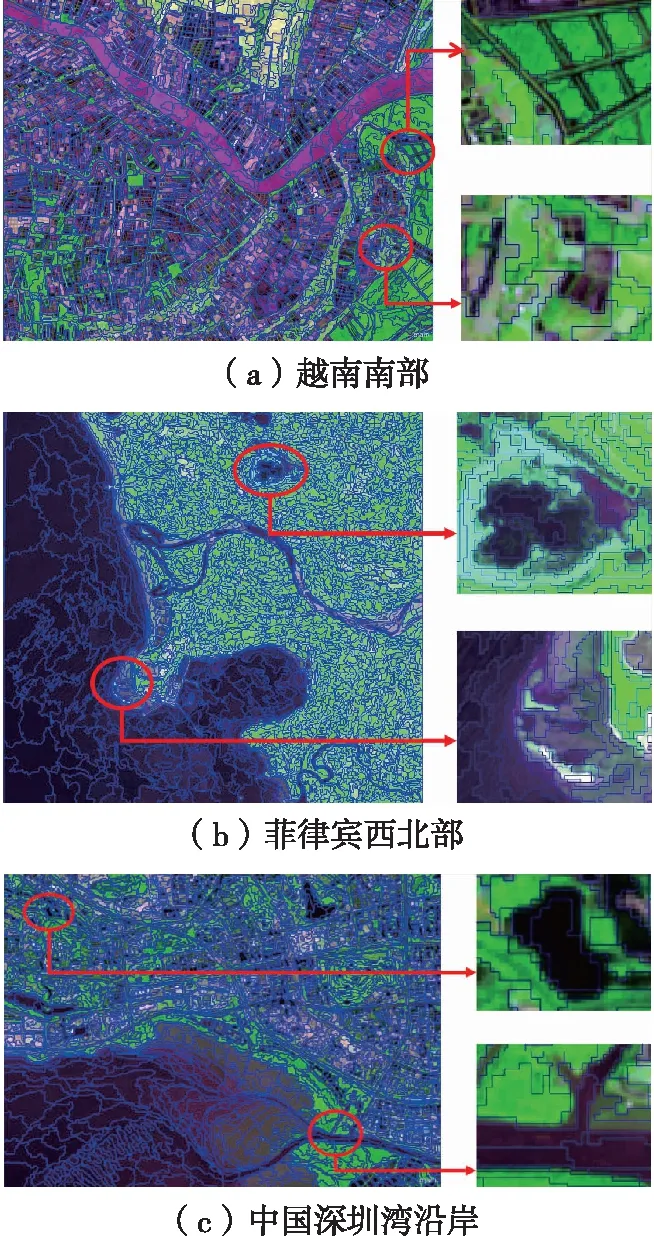
图4 多尺度分割结果
2.2 基于RF的湿地与非湿地二分类
为了减小图卷积的运算量,并提升湿地类内紧凑性和类间的可分离性,利用RF区分湿地与非湿地,获取湿地掩膜。3个数据集上得到的分类结果如图5所示。

图5 湿地与非湿地二分类结果
使用准确率、精确率、召回率、F1值评价二分类结果的精度(见表 3),3个数据集上的分类精度均在91%以上。
2.3 基于双线性图卷积网络的湿地分类
2.3.1 图卷积网络
光谱信号间的关系可以表示为
G=(V,E,A)

L=D-A
为了提高图的泛化能力,使用对称归一化拉普拉斯矩阵
式中,I为单位矩阵。
定义滤波器gθ=diag(θ)对图G进行节点构建,它可以理解为标准化图拉普拉斯矩阵L的特征值的函数。一个图的光谱卷积可以定义为图信号s与滤波器gθ的乘积,公式为
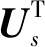

因此,GCN的传播规则为
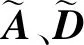
2.3.2 网络模型结构
BiGCN模型结构如图6所示,以Sentinel-2、多源辅助数据、分割对象块及湿地掩膜为输入,利用多层图卷积提取抽象特征,最终输出湿地分类结果。

图6 BiGCN模型结构
(1)根据多源数据和分割结果构建图结构,查找每个对象的邻接对象是构建图结构的基础。如图7所示,对象v1与对象v2、v3、v4以边相邻接,而与对象v5、v6、v7以点相邻接。原始GCN中的查找方法能够搜索到每个对象周围以边相邻接的对象,但以点邻接的对象间关系同样十分密切。因此,本文在邻接对象的查找上作出改进,在仅查找以边邻接对象的基础上增加了以点相邻接的对象。

图7 考虑点邻接的图结构
(2)建立图结构后,采用双线性模型思想搭建两路并行的子网络,每路网络中包含两层图卷积,分别包含64和128个隐藏单元。两层图卷积之间使用Swish激活函数,它同ReLU一样有下界无上界,能够防止梯度饱和问题,具有非单调且平滑的特点,能够有效提升网络性能,公式为
(3)对两路网络的输出特征进行双线性池化运算,将两路网络的特征融合,公式为
bilinear(l,I,fA,fB)=fA(l,I)TfB(l,I)
式中,I为输入影像;l为输出特征图的位置序号;fA和fB分别为两路网络的特征。通过两路并行的网络进行特征提取及双线性池化操作,两路网络可以分别实现区域检测和特征提取的功能,且互为补充,能够有效实现细粒度分类。
(4)对两路特征融合后的向量执行一个概率为0.5的Dropout层、一个全连接层,并根据全连接层输出中最大值的位置确定湿地地物类别。
2.3.3 试验环境及参数设置
本文深度学习框架使用Tensorflow,硬件设备为Intel(R)Core(TM)i7-6700 CPU @ 3.40 GHz 3.41,内存为8 GB。BiGCN模型学习率设置为0.001,最大迭代次数设置为300。
3 结果与分析
3.1 分类结果
为验证湿地分类方法的有效性,选取5种典型分类模型进行对比试验,包括支持向量机(support vector machine,SVM)[15]、RF、K近邻法(K-nearest neighbor,KNN)[16]、CNN、GCN。各模型在已构建的3个数据集上得到的分类结果如图8—图10所示。
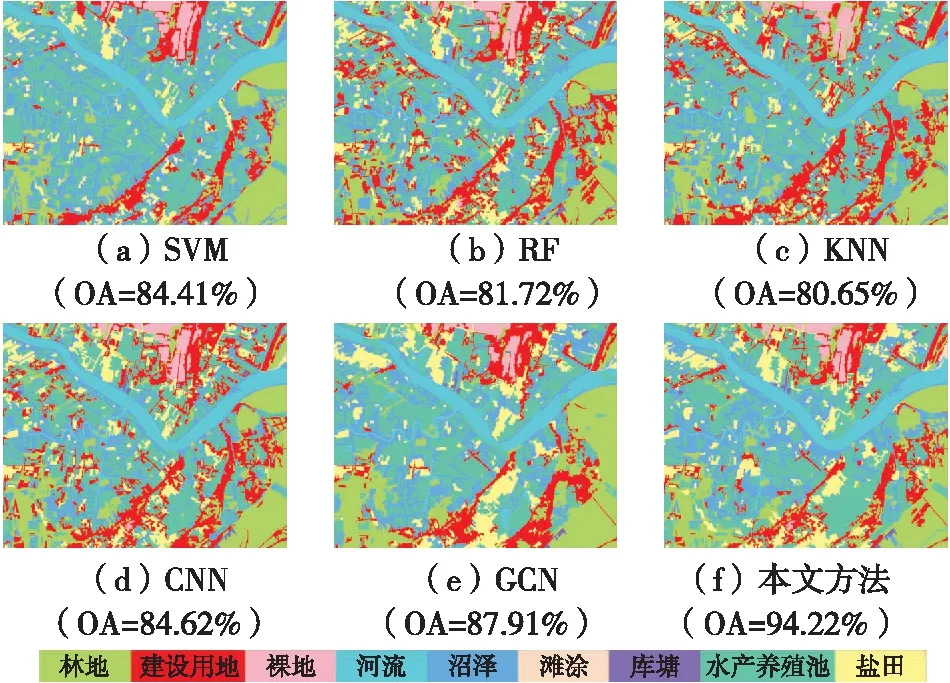
图8 越南南部数据集分类结果
可以看出,SVM、RF、KNN这3种非深度学习方法在3个数据集上的总体分类精度(overall accuracy,OA)均在85%以下,低于3种深度学习方法;而在3种深度学习方法中,两种GCN方法的分类精度高于CNN;使用本文分类方法得到的湿地分布图与真实情况的吻合度最高且OA最高,3个数据集上的OA均超过92%。
由图8可以看出,对于越南南部数据集,CNN和GCN的OA略微高于3种非深度学习方法,本文方法分类精度显著高于其余5种方法。对非湿地和湿地的判别,RF、KNN和CNN中存在较多将湿地误判为建设用地的情况。对湿地二级类的判别,深度学习方法能够将河道边缘的沼泽与河流本身区分开;GCN分类结果图中存在将河流误判为水产养殖池的情况,而CNN与本文方法对河流的分类正确且完整;影像最右侧区域中间部位有一处网格状分布、沼泽穿插于间隙的林地,CNN将穿插的沼泽误判为建设用地,原始GCN将整块区域误判为林地,没有将林地格网间的湿地判别出来,而本文方法则判别准确。
由图9可以看出,对于菲律宾西北部数据集,3种非深度学习方法的OA均低于77%;而深度学习方法的OA均大于83%。RF、GCN和本文方法对滩涂的判别更为准确,而SVM、KNN和CNN对沿海地区的滩涂存在漏分现象;对于该区域北部的两片湖泊,多数方法将其误判为河流、裸地或海洋,CNN和本文方法则能将其较为完整、匀质地判别出来。此外,该区域内河流东部河道中存在较多沼泽,用于对比的几种方法大多将沼泽误判为建设用地,而本文方法能将其正确判别。

图9 菲律宾西北部数据集分类结果
由图10可以看出,对于中国深圳湾沿岸数据集,该区域北部有一处L形湖泊,SVM、RF和KNN均将其误判为水产养殖池,而深度学习方法均分类正确,且准确判别了深圳湾沿岸林地与滩涂间的过渡带沼泽。CNN和GCN对二级湿地类的分类精度均优于SVM、RF、KNN,但在南部浅海水域和滩涂的交界处,GCN存在将其误判为水产养殖池的情况,在最南部的滩涂和林地交界处,CNN和GCN分别将其误判为水产养殖池和湖泊,而本文方法则分类正确。总之,本文方法在该数据集上的OA相较于GCN显著提升,提升幅度超过4%。

图10 中国深圳湾沿岸数据集分类结果
3.2 消融试验
设计5组消融试验进一步检验本文模型各部分的作用,使用OA、平均准确率(average accuracy, AA)和Kappa系数对分类结果进行精度评价,消融试验的分类精度与用时见表 4,可以得到如下结论。
(1)相较于双线性模型的网络,仅使用单通道网络的运算用时大幅缩短,但精度较低,3个数据集上单通道网络的OA比双线性网络分别降低3.01%、1.72%、3.52%。可见,构建双线性网络进行湿地分类,尽管消耗更长的模型训练时间,但分类精度有显著提升。
(2)加入多源辅助数据后,由于数据量明显增加,运算速度有小幅降低,但3个数据集的分类精度都得到明显提升,其中菲律宾西北部数据集OA提升约3.79%。
(3)考虑点邻接对象后,3个数据集运算用时均缩短了约3%,且分类精度均有小幅提升。点邻接对象加入后,每个对象的空间信息量更为丰富,提升了网络的辨别能力,提高了湿地分类效率。
(4)相较于ReLU,使用Swish激活函数在3个数据集上得到的OA、AA和Kappa均有小幅提升,其中中国深圳湾沿岸数据集提高最多,3项指标均提高1%以上;两种激活函数运算时间基本相当,ReLU的用时稍短于Swish。可见,Swish激活函数的运算量略大于ReLU,但分类表现更优。
(5)不加掩膜时,分类精度较低且模型训练耗时更长;加入掩膜后,3个数据集的分类用时分别缩短195.70、842.22、1 003.69 s。可见,使用分层分类的方法首先把差异较大的湿地和非湿地分开,然后对湿地部分进行细分,有助于同时提高分类精度与分类效率。
4 结 语
本文针对环南海地区湿地监测需求,利用Sentinel-2影像制作了3组环南海地区湿地分类数据集,并提出一种基于BiGCN的湿地分类方法。该方法基于面向对象的分层分类思想,首先区分湿地与非湿地,然后构建适用于湿地细粒度分类的BiGCN模型,并对湿地类型进行细化,且采取多种策略对分类效果进行优化(如使用双线性模型、在构建图结构时考虑以点邻接的节点及采用性能更优的Swish激活函数等)。试验结果表明,在所构建的3组数据集上,本文方法均能够达到92%以上的总体分类精度,比原始图卷积网络提高4%以上,且分类耗时大幅缩短,同时也优于多种常用的湿地分类方法。未来研究将聚焦于小样本上的湿地高精度分类。
