基于改进DeeplabV3+模型的云检测
2023-09-02钟旭辉谭海梁雪莹潘明石一剑
钟旭辉,谭海,梁雪莹,潘明,石一剑
(1.辽宁工程技术大学 测绘与地理科学学院,辽宁 阜新 123000;2.自然资源部国土卫星遥感应用中心,北京 100048)
0 引言
随着遥感技术的不断进步,遥感图像被广泛应用于科学研究、社会服务等多个领域。目前我国的国产卫星以高分一号、高分二号和资源三号为代表,其各项指标都已经接近国际先进水平。国产卫星影像的数量和质量也在不断增长,在社会各个领域发挥着越来越重要的作用[1]。然而,并不是所有的遥感图像都可以直接被用于工程项目和科学研究。其中一个重要的原因就是云层,星载卫星获取的图像通常都包含云层,并且云层的比例相对较大,一般超过50%[2]。在各种大气成分中,云几乎覆盖了地球的三分之二,云的存在会影响遥感设备的使用率和成像质量,并且占用了系统大量的存储空间以及传输带宽,造成了信道和地面设备资源的极大浪费。为了提高卫星遥感图像的利用效率,研制一套能够自动、准确地检测分割遥感图像中云区域的云检测算法,具有非常重要的意义。
大多数的云检测方法主要基于云的光谱特性或纹理特性进行分类[3],目前比较常用的云检测大致可以归为两类,一类为传统算法,另一类为利用神经网络进行检测。传统的云检测算法大多数是依据物理特征,算法比较简单,操作性强,一般是通过人工来划定阈值从而构造一个简单的分类器,以此来进行云检测。其主要是根据云在遥感影像上具有高反射率和低温的特性,当下垫面地物具有跟云相似的反射率和温度值时,将无法对其进行分离。此外,其物理阈值的设定也很大程度上取决于人的经验值,并且传统算法对传感器的光谱通道具有一定的要求,因此具有一定的局限性。王伟等[4]提出了一种结合Kmeans聚类均值和多光谱阈值方法的改进云检测方法。在地物光谱分析的基础上,利用Kmeans聚类均值方法将MODIS数据初步分为两大类。第一类包括云、烟和雪,第二类包括植被、水和土地。然后采用多光谱阈值检测,对第一类干扰进行消除,如烟雾和雪。Li等[5]提出了一种新的光谱空间分类策略,通过集成阈值指数光谱角图、自适应马尔科夫随机场和动态随机共振来提高高光谱图像上轨道云屏的性能。集成阈值指数光谱角图被用于基于光谱信息对云像素进行粗略分类。然后利用自适应马尔科夫随机场对空间信息进行优化处理,显著提高了分类性能。然而,由于机载环境中的噪声数据,出现了错误分类,动态随机共振被用于消除自适应马尔科夫随机场在二值标记图像中产生的噪声数据。由于光学遥感图像中云特征有多样性的特点,且不同的云特征在特征组合中的分布并不具备典型特点,因此利用纹理差异进行云检测仍然存在难题。一些基于改进纹理特征的云检测算法在一定程度上提高了云检测的精度,却存在耗时长、训练难度大、难以自动提取等缺陷。另一种方法是利用深度学习神经网络算法进行云检测。经过训练的卷积神经网络能够充分挖掘图像中的特征,有效地完成遥感图像的云检测。Xie等[6]改进了简单线性迭代聚类(simple linear iterative clustering SLIC)方法,将图像分割成高质量的超像素。然后,设计了一个具有两个分支的深度卷积神经网络,从每个超像素中提取多尺度特征,并将超像素预测为包括厚云、薄云和非云在内的3个类别之一。最后,对图像中所有超像素的预测产生云检测结果。Guo等[7]提出了一种具有编码器-解码器结构的新型云检测神经网络,命名为 CDnetV2,作为云检测的系列工作。CDnetV2 包含两个新颖的模块,即自适应特征融合模型和高级语义信息引导流。通过配备这两个提议的关键模块,CDnetV2 能够充分利用从编码器层提取的特征并产生准确的云检测结果。Liu等[8]设计了一种基于卷积神经网络(convolutional neural networks,CNN)和deep forest的超像素级云检测方法。首先,将SLIC和SEED相结合,将遥感图像分割成超像素;之后,利用结构化森林计算每个像素的边缘概率,在此基础上更精确地分割超级像素。分割后的超像素构成了一个超像素级的遥感数据库。
综上所述,许多国内外的专家学者对云检测进行了大量深入的研究,提出了许多云检测的算法,但是传统方法由于受光学遥感影像中云的特征较为复杂,且受水、雪等具有相似纹理特征地物的影响,许多算法都存在对云的漏判误判等问题。另外,使用深度学习算法进行检测存在训练周期长等问题。因此,本文提出了一种基于改进DeeplabV3+的云检测模型,通过加入迁移学习模块来减少耗时,降低训练难度,并且通过改进Xception网络框架以及空间金字塔(atrous spatial pyramid pooling,ASPP)模块的空洞卷积来提高检测精度。
1 研究方法
1.1 DeeplabV3+基础模型
DeeplabV3+模型是在DeeplabV3的基础上进行改进而来,主要包括编码器和解码器这两部分。该模型以DeeplabV3为编码器,其主要作用为提取输入影像的特征,然后通过解码器对提取的特征进行一个解码工作最终获得预测结果。
该网络的主要工作原理为:在编码器里对输入的图像进行一个特征提取,先经过深度卷积神经网络(deep convolutional neural networks,DCNN)获取两个有效特征层(分别为一个低级特征图和一个高级特征图,低级特征层会直接传入解码器,而高级特征层会经过ASPP模块得到多尺度语义特征),然后再对ASPP模块获取的多个特征图进行一个融合,接着经过一次1×1的卷积,然后再输入到解码器。在编码器里先对DCNN里输出的低级特征层进行一个1×1的卷积,对ASPP模块输出的高级特征层进行一个4倍上采样,然后再对上述两个特征层经过一次融合、一次3×3卷积和一次4倍上采样,最终输出对图像的预测结果。其完整网络结构如图1所示。
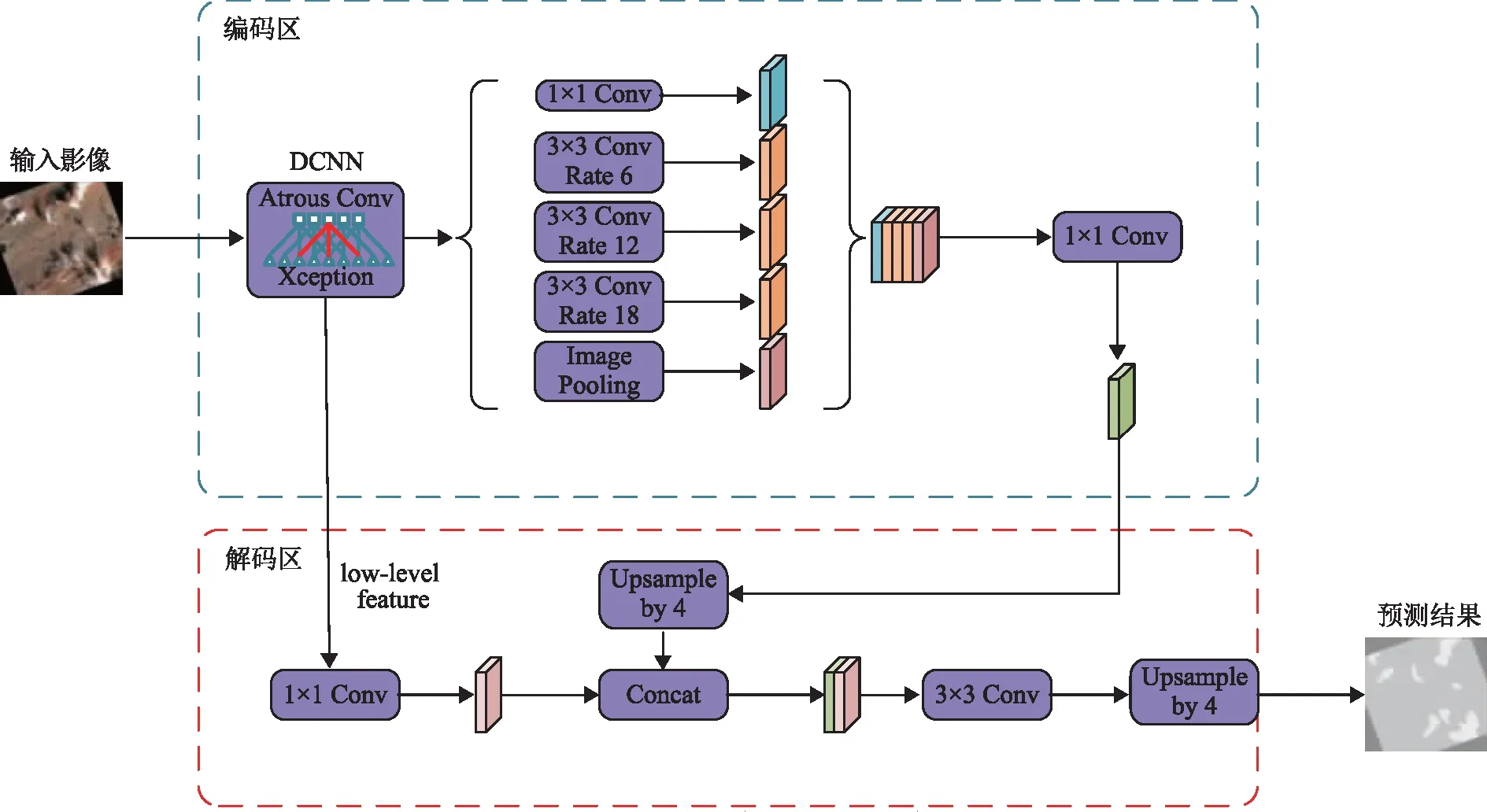
图1 DeeplabV3+网络结构
1.2 Xception网络
Xception网络结构[9]表示的意思是extreme inception,是在InceptionV3[10]的基础上,结合ResNet思想加以改进得来的。Xception主要是将原来Inceptionv3中的多尺寸卷积核特征响应操作替换为深度可分离卷积。对于Xception网络而言,其分为3层,分别是输入层、中间层、输出层;分为14个block,其中输入层中有4个,中间层中有8个,输出层中有2个。
Dai等[11]对Xception进行了进一步的改进,其在entry flow过程中将所有stride=2的max pooling结构替换为stride=2的Sep Conv。这种结构替换并不影响网络的性能,但是由于深度特征图的尺寸较小,不利于语义分割网络的训练,所以,DeeplabV3+在使用Xception网络时,将最后一个stride=2的Sep Conv的stride设定为1。并且,其在每个3×3的depthwise separable convolution的后面都加上了BN(batch normalization)和Relu,重复8次改为16次,目的是为了在训练时增加训练次数,以此来提高训练模型的精确度。
1.3 ASPP模块
ASPP模块是在DeeplabV2时被提出来的,其主要作用是用于提取图像的多尺度语义特征,因为其优秀的结果表现,被广泛地用于图像语义分割的多尺度特征提取部分。
ASPP模块由1个1×1的卷积、3个3×3的空洞卷积和1个全局平均池化组成,其中3个3×3的空洞卷积分别有不同的膨胀率,膨胀率较小的卷积核适合分割较小的目标,膨胀率较大的卷积核适合分割较大的目标。当膨胀率增大时,其卷积核的作用也会逐渐减少,当膨胀卷积尺寸与特征图尺寸一样时,3×3卷积作用效果就变成了1×1卷积,只有卷积和中心起作用。图2紫色立方体是经过Xception网络得到的1/16大小的特征图,将其在ASPP模块中分别进行了1次1×1卷积、3次膨胀率分别为6、12、18的3×3空洞卷积和1次全局平均池化,得到了5个为1/16大小的不同的特征图,然后对这5个特征图进行融合,获得高级特征图,再经过1次1×1的卷积恢复其通道数,输入解码器。
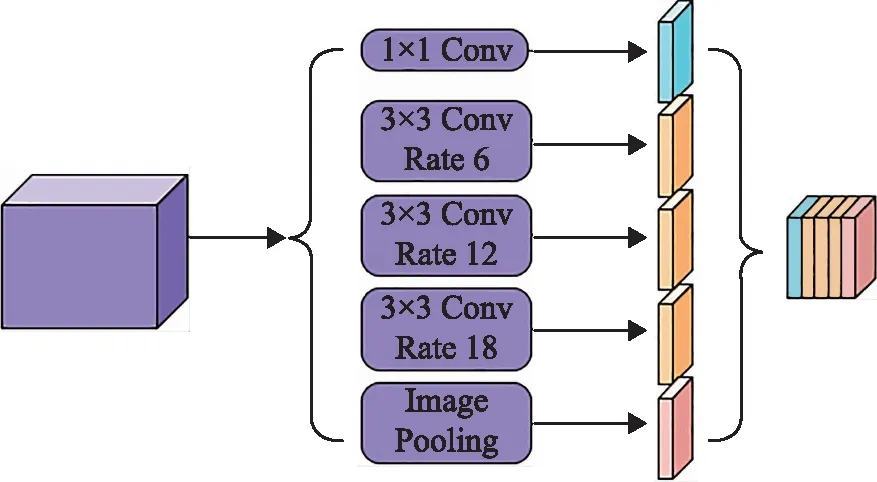
图2 空洞空间金字塔池化模块
2 本文方法
DeeplabV3+是目前较为优秀的语义分割模型之一,但其仍然存在一些不足之处。首先,其目标语义分割存在空洞、误判以及对细小目标的漏判问题。其次,在编码器的Xception骨干网络和ASPP模块进行了多次卷积,参数量庞大,训练时长过长,网络收敛速度慢。最后,在使用原始DeeplabV3+网络进行训练后,发现对于尺寸小的目标分割效果较差。针对原始网络以上的不足之处,本文进行了以下改进:首先对Xception骨干网络和ASPP模块进行了一定的改进,其次在模型训练过程中融入了迁移学习的思路。
改进后的DeeplabV3+模型仍然分为编码器和解码器两部分。改进后的网络结构如图3所示。

图3 本文改进的DeeplabV3+模型结构
2.1 Xception网络改进
本文改进的Xception网络是在Dai改进的Xception网络的基础上再对输入层进行改进,其结构如图4所示。在输入流的每个小模块的最前面增加了一个1×1的卷积来降低维度,然后再通过3×3卷积提取特征,再通过一个1×1卷积恢复维度[12]。通过以上改进,既可以使得各个通道的特征都得到充分的学习,提高模型精度,也可以减少参数量,减少模型训练时间。
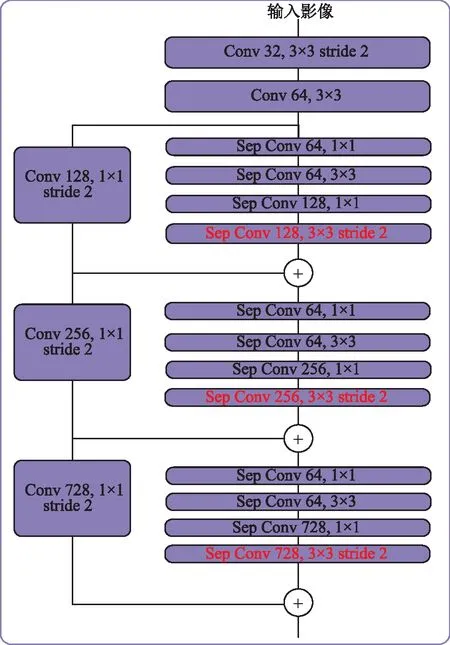
图4 本文改进的Xception输入层结构
2.2 ASPP模块改进
ASPP模块的主要原理是利用不同膨胀率的空洞卷积,进而获取到多尺度的语义特征信息。ASPP模块中进行了3次不同膨胀率的空洞卷积,不同的膨胀率,对于不同尺度的目标分割效果不同。基于原始DeeplabV3+网络对小尺度目标分割效果不理想的问题,本文改进后的ASPP共有4个不同膨胀率的空洞卷积,膨胀率分别为2、4、8、16,增加小膨胀率的空洞卷积以增强对小尺度目标的分割能力。其次,由于3×3的空洞卷积容易学习一些冗余信息,参数量较大,训练时长较长,针对这一问题,在保证不降低原始网络的语义信息提取效果的前提下,本文将3×3的空洞卷积进行了分解,将其分解为3×1和1×3的卷积,使得参数量较原3×3卷积降低了三分之一,参数计算量得到有效的减少,在速度上也得到一定的提升。
2.3 迁移学习
迁移学习是机器学习技术其中的一种,其原理是在一个特定的数据集上,训练过的卷积神经网络被重新改造或迁移到另一个不同的数据集中。重复使用训练过的卷积神经网络,主要原因是训练数据通常需要花费很长的时间[13]。通常来说,迁移学习包含两种策略。第一,微调,包括在基础数据集上使用预训练网络,并在目标数据集上训练所有层。第二,冻结和训练,包括仅冻结并训练最后一层,其他层不变,也可以冻结前几层,微调其他层,这是因为有些证据表明CNN的前几层有纹理滤镜和彩色斑点[14]。
本文使用的迁移学习策略为冻结和训练策略。在冻结阶段,将模型的主干冻结,特征提取网络不发生改变,仅对网络进行微调,训练速度快,花费时间较少;在训练阶段,解冻模型主干网络,特征提取网络和网络所有的参数都会发生改变,训练变缓,花费时间较多。通过融入迁移学习,提高训练效率、缩短训练时间。
3 数据预处理
3.1 样本制作
本文使用的数据集来自于资源三号01、02星,选取多光谱和全色影像共计1 500张,利用Photoshop进行人工勾画,标注云矢量样本,然后使用MATLAB算法对样本进行填充,生成二值图标签。云检测数据标签示例如图5所示。

图5 云检测数据标签样例
3.2 数据增广
由于深度学习需要大量的标签做为样本,标签的数量以及标签对目标地物勾画的精确度都对所训练出的模型分割的准确度产生明显的影响,所以为了提高模型的精度,需要大量的标签来提高神经网络对目标地物特征的学习。由于深度学习标签的制作耗时耗力,针对这一问题,本文在保证标签类型和质量的前提下,对原标签进行数据增广,增广效果如图6所示,以此来减少人工制作标签的成本,并且可以提高模型的泛化能力。本文采取的数据增广的方法主要有以下几种。
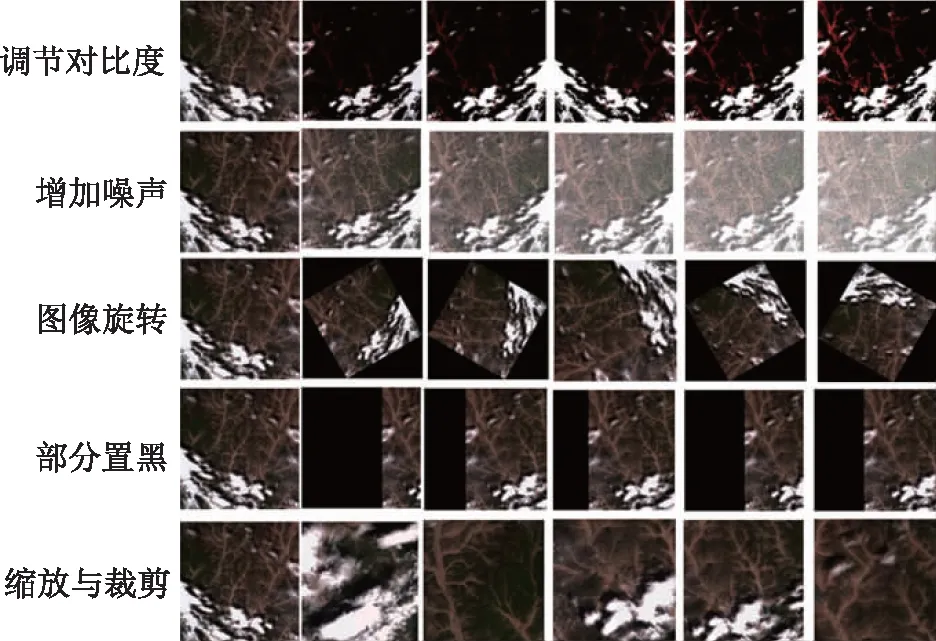
图6 云数据增广方法与样例
1)对比度调节。对比度调节其实是对画面亮度信息做处理,其主要目的是提高画面明暗对比度和增强画面的整体均衡度。
2)增加噪声。通过增加噪声来模拟影像的成像过程,适当增加噪声可以增强学习能力。
3)通过旋转、翻转扩充数据。通过对图像进行旋转和翻转来改变特征的位置,对于模型来说就是不同的数据。旋转或翻转操作是扩充图像数据集的一个简单有效的方法。
4)部分置黑。
5)缩放。实现图片放大或者缩小功能。通过在原始中稍微改动一些截取的区域,增加或者减少背景,最终将这些数据调整到规定的训练数据大小。
4 实验结果与分析
4.1 实验环境
基于Windows10操作系统,显卡型号为NVIDIA Quadro P6000,显卡容量为24 GB,采用的深度学习框架为Pytorch,Pytorch-gpu版本为1.12.0,用于加速深度学习网络的CUDA和CUDNN版本分别为10.0和v7.4.1.5。
4.2 实验数据集
本文所选原始影像为资源01和02星影像,影像原始大小为1 107像素×1 122像素,由于受计算机硬件条件的限制,将影像裁剪为513像素×513像素大小进行训练,将经过数据增广的原始影像裁剪后挑选出了16 619张影像。由于云与某些雪、水体、冰面、高亮地物等的地物特征具有较高的相似性,本文数据集中增加一定数量的负样本,正负样本比例为5∶1,训练集和验证集的比例为9∶1。
4.3 评价指标
为了定量评价本文所改进的云检测的模型效果,使用语义分割中常用的评价指标准确率(accuracy)、精确率(precision)、召回率(recall)、平均交并比(MIoU)4项指标定量评价云识别结果[15]。
4.4 不同网络实验对比
本文所有实验参数设置均相同,具体参数设置为:学习率为5E-6,批量大小为8,迭代次数为200。共设计了4组实验,第1组为传统的DeeplabV3+模型,第2组为PSPnet模型,第3组为Unet模型,第4组为本文方法。对4种模型进行训练,各模型通过测试集的精度评价指标如表1所示。可以看出,在本文数据集上,本文模型相比于传统DeeplabV3+模型准确率提高了3.34%,平均交并比提高了5.39%,相比于PSPnet模型召回率提高了6.84%,相比于UNet模型精确率提高了4.83%。通过对4个精度评价指标对比,本文模型最优。实验结果对比如图7所示。由图7可知,本文所采用4组实验中对纹理特征明显的云检测精度基本相当,但是在有雪、水体以及高亮地物等干扰因素的复杂背景的影像上检测精度存在差异,传统DeeplabV3+模型与UNet模型都对雪存在一定的误判,PSPnet模型分割边缘比较平滑,但是对目标较小的云存在漏判。与前3种方法相比,本文方法对雪、水体和高亮地物的误判比较少,对于检测结果影响不大,对薄云和目标较小的云识别较好,整体提取完整,相比与其他3种方法,云检测精度有所提高。

表1 实验结果对比

图7 实验结果对比图
4.5 消融实验
为了验证本文对Xception骨干网络、ASPP模块的改进以及融入迁移学习的必要性,设计了7组方案进行消融实验。
方案1:使用传统的DeeplabV3+网络,在保持其他地方不做改进的基础上针对Xception网络进行改进。
方案2:使用传统的DeeplabV3+网络,在保持其他地方不做改进的基础上针对ASPP模块进行改进。
方案3:使用传统的DeeplabV3+网络,在保持其他地方不做改进的基础上只融入迁移学习。
方案4:在方案一的基础上对ASPP模块进行改进。
方案5:在方案一的基础上融入迁移学习。
方案6:在方案二的基础上融入迁移学习。
方案7:本文实验方法。
为了定量评价模型效果,消融实验除了使用准确率、精确率、召回率、平均交并比这4项语义分割模型常用的标准评价指标外,还增加了两个时间指标,分别为训练时长和单张影像预测时长。
由表2消融实验结果可得,方案1相比于传统DeeplabV3+,精确率提升了2.05%,MIoU提高了2.6%,训练时间有一定缩减,说明改进Xception网络可以提高模型的精确率,并且可以提高训练效率。方案2相比于传统DeeplabV3+,召回率提高了2.84%,说明改进ASPP模块可以提高模型的召回率。方案3相对于传统DeeplabV3+模型4项精度评价指标相当,但训练时长明显缩短,说明加入ASPP模块可以在不影响精度的前提下大量缩短训练时间。方案7相比于前6个方案,在准确率、精确率、召回率、平均交并比提升更为明显,相比于传统DeeplabV3+模型,准确率提高了3.34%,精确率提高了3.78%,召回率提高了4.47%,平均交并比提高了5.39%,且训练时长和预测时长也有明显的减少,说明在改进Xception网络和ASPP模块并且融入迁移学习模块的情况下,模型精度和训练速度得到了明显提升。消融实验对比结果如图8所示。由图8可知,本文设计的7组消融实验中方案7的精度最高。

表2 消融实验结果对比

图8 消融实验结果对比图
5 结束语
针对现有的云检测时存在误判漏判的问题,本文提出了一种基于改进传统的DeeplabV3+网络的云检测模型,旨在更准确、快速、高效地检测遥感影像中的云。本文通过对Xception网络的每个输入流前增加1×1卷积来降维,然后通过3×3卷积,之后在输出前通过1×1卷积恢复维度,以及对ASPP模块的3×3的膨胀卷积进行2D拆解,以此来达到降低冗余、缩减参数的目的,最后通过融入迁移学习的方法,来提高本文模型的效率与速度;通过改变ASPP模块膨胀卷积的膨胀率,来提高本文模型对不同尺寸的云的检测。通过与其他网络模型进行对比,本文模型准确率和精确率更高,训练速度更快。
