结合PU学习的遥感影像建筑物自动提取方法
2023-09-02王理根张永忠
王理根,张永忠,3
(1.兰州交通大学 测绘与地理信息学院,兰州 730070;2.兰州市勘察测绘研究院,兰州 730070;3.甘肃大禹九州空间信息科技有限公司 院士专家工作站,兰州 730070)
0 引言
近年来,卫星和无人机遥感技术发展迅猛,海量的遥感影像资源堆积在人们面前,但需要通过遥感影像去获取特定信息的时候,往往由于缺少专业知识或人工工作量过大,使得遥感资源包含的信息无法被充分利用。建筑物是人类活动的重要载体,其分布能够反映城市发展状况,建筑物信息可以广泛应用于城市规划、区域变化检测、城市人口估计等众多领域[1],因此建筑物自动提取成为了遥感影像应用研究的热点方向。
遥感影像建筑物的自动提取往往需要结合多个领域的知识,是计算机视觉、人工智能和遥感信息处理与分析等领域的重要研究内容[2]。基于建筑物典型的形状、光谱等特征的检测方法较早被研究,如Wang等[3]利用直线和角点提取建筑物轮廓,这种方法在建筑物轮廓较为规则的情况下能够获得比较好的提取效果,但其难以适应复杂形状的建筑物;Sun等[4]利用多种规则形状相似性指数提取建筑物,该方法能够处理多种形状的建筑物,但其正确工作的前提是图像分割不存在欠分割和过分割。这些方法在建筑物典型特征易于提取时表现良好,但实际遥感影像中的建筑物形态复杂,典型特征可能被破坏,导致方法提取精度下降。相较之下,机器学习的方法对各种环境和数据适应性更强,Dilek等[5]基于已有建筑物数据库,利用SVM分类器提取建筑物;Li等[6]利用条件随机场模型获取建筑物初始检测,随后融合显著性线索最终提取出建筑物;张仕山等[7]利用模糊集方法,为多种建筑物特征定义概率分布函数,并使用DS(dempster shafer)证据理论综合多特征,得到建筑物检测结果;何直蒙等[8]利用改进的U-Net卷积神经网络来提取建筑物。但这些机器学习模型的训练依赖大量标注数据,而目前标注数据的获取仍主要依靠目视解译。降低模型对标注数据的需求就意味着节省大量人工劳动,许多研究在此方向做出了努力:Wang等[9]通过阴影和形状约束检测到部分建筑物区域后,将阴影、树木和低矩形拟合值的区域作为负样本,与检测出的建筑物区域一起训练监督分类器,但为保证建筑物不会被过分割,其图像的分割过程需要人工修正;Gao等[10]通过阴影、植被、建筑物和裸地样本训练SVM分类器,并实现了阴影、植被和建筑物样本的自动提取,但成分复杂的裸地样本仍然需要依靠人工提取。
如何减少建筑物提取过程的人工工作是本文研究的重点。针对建筑物样本获取的问题,本文提出了一种结合阴影与建筑物空间关系的正样本自动提取模型,通过直线特征和与阴影方位关系的双重限制,自动获取到高精度的正样本。在建筑物提取任务中负样本包含的地物种类过多,难以自动获取[11],所以本文采用了基于PU学习[12](positive-unlabeled learning)的Bagging-PU分类器[13],这种分类器只需要正样本和未标记样本就能完成分类任务,免去了负样本提取的工作。最后,根据建筑物的形态,本文提出了一种基于邻域统计的二值化方法,从分类器输出的概率标签中获取建筑物区域。
1 研究方法
本文采用了面向地理对象图像分析(geospatial object-based image analysis,GOBIA)方法。GOBIA方法主要研究如何分割遥感影像并产生有意义的地理影像对象,然后基于分割结果对影像进行分析,是遥感与地理信息科学重要的研究领域[14]。相较于基于像素的分析方法,GOBIA方法能够减少分析单元的数量,更贴近人视觉认知模式,能够在一定程度上克服“语义鸿沟”。由于GOBIA方法分析基本单元为分割对象,分割对象的特征是由分割对象内部像素共同决定的,少量噪声像素对整体特征影响不大,所以GOBIA方法具有一定的抵抗噪声的能力[15]。本文提出的方法首先对遥感影像进行分割,然后利用阴影与建筑物的空间关系提取出部分建筑物区域,结合分割结果生成面向对象的正样本,随后利用提取出的样本训练Bagging-PU分类器,获取分割对象的概率标签,然后经过二值化处理得到最终建筑物提取结果。方法流程如图1所示。

图1 建筑物自动提取流程图
1.1 图像分割
GOBIA方法首先需要对图像进行分割,图像分割质量会很大程度上影响最终的分类结果[16]。图像分割难以同时避免过、欠分割错误,欠分割会使分割出的对象包含多种地物,使得该对象无法被归类,而过分割会使得地物的局部特征被分离出来,使分割对象的分布更加复杂。对比分割方法中存在的过和欠的问题,本文选取分割方法时,采用了“宁过不欠”原则。本文采用简单线性迭代聚类分割算法(simple linear iterative clustering,SLIC)[17],在实验了多种分割参数后确定分割区块尺度参数为20像素,紧致度参数m为20,此时分割结果的边缘拟合度较好,且能够保证建筑物不会与其他地物混淆。
1.2 建筑物样本自动提取
大部分建筑物拥有规则的轮廓特征,边界多数由直线段构成。建筑物有一定高度,在阳光下投射出的阴影也是建筑物存在的明显证据[18-19]。根据建筑物的这些特征,本文提出了一种基于方向自适应阴影景观的建筑物样本提取方法。
1)阴影检测。首先将多波段图像转换为亮度图,根据阈值对亮度图进行二值化提取阴影,然后通过形态学开闭操作排除噪声,使阴影形态更完整。为进一步排除其他低矮地物产生的阴影,设置建筑物阴影最短阈值L,排除在光照方向宽度小于L的阴影。本文根据实际情况,选取了阈值L为5 m。
2)建筑物与阴影边界检测。首先,采用LSD(line segment detector)[20]算法提取阴影边界的直线段,剔除长度过短的,剩余的为备选线段。如图2所示,根据与阴影的方位关系,备选线段可以分为3种:线段方向与光照方向一致的为阴影侧边(图2中的蓝色直线段)、背向光源的一侧的边界是阴影的末端(图2中的黄色直线段)、朝向光源的一侧的边界才是寻找的建筑物与阴影的边界(图2中的红色直线段)。

图2 建筑物与阴影的边界
3)方向自适应阴影景观法。为了获取建筑物区域,对ALI[21]采用的阴影景观方法(shadow landscapes method) 进行改进,提出了一种自适应方向阴影景观法(shadow landscapes method with adaptive direction)。自适应方向阴影景观法对每一个建筑物边界线段,构建垂直于此边界线段且面向光照的方向的线性结构元素,根据建筑物实际尺寸和样本提取的实际需求,线性结构元素的尺寸设为4 m。用此线性结构元素对线段做形态学膨胀操作,最后综合所有线段的膨胀结果得到方向自适应阴影景观,如图3蓝色区域所示。

图3 自适应方向阴影景观法提取结果
4)面向对象的建筑物样本提取。自适应阴影景观法提取的结果是基于像素的,为了将其转换为基于对象的样本,统计每个分割对象内像素总数Ni和阴影景观像素数ni,按照比例ri=ni/Ni为分割对象分配标签labeli,计算如式(1)所示。
(1)
式中:标签为1代表建筑物样本;标签为0代表未标记样本。
1.3 基于Bagging-PU分类器的建筑物提取
1) 样本及特征提取。建筑物拥有区别于其他地物的光谱特征、纹理特征、高度特征。选择以下几种特征:计算分割对象各波段像素值的均值和方差作为光谱特征;生成具有旋转不变性和灰度不变性的LBP纹理(local binary pattern)图、与人类的视觉系统类似的gaber纹理图,统计分割对象的两种纹理直方图作为纹理特征;采用分割对象的归一化数字表面模型(normalized digital surface model,nDSM)的均值和方差作为高度特征。其中nDSM由DSM(digital surface model)数据自动生成,其获取过程为:将原始DSM数据划分为45 m×45 m的方格,选取区块内DSM统计值的0.1分位数作为区块中心的DEM高程值,然后再对DEM重采样使其与DSM分辨率保持一致(图4(b)),最后用DSM减去DEM便可得到归一化DSM(图4(c))。

图4 nDSM数据处理
2)Bagging-PU分类器及样本训练。传统分类器需要充足的正样本和负样本进行训练,但是建筑物提取任务中负样本包含的地物种类过多,难以自动获取,在无法获取负样本的情况下使用PU-learning是更优的选择[22],其能够利用大量易于获取的无标记样本进行学习,相较于仅使用正样本的单分类(one-class classification)方法,PU-learning方法效果往往更优。本文采用了Bagging-PU分类器,这种分类器采用了伪标签方法,使得普通的二分类器也可用于PU-learning过程,但使用错误的标签训练会带来学习偏差,所以这里引入了Bagging机制,通过随机采样使标签误差随机化,最后对多个子分类器得到的结果求平均,从而减弱了不准确标签带来的误差。
1.4 基于邻域统计的二值化处理
本文采用的机器学习模型输出是多个子分类器输出的均值,需要进行二值化处理。考虑到建筑物的形态特征,本文提出了一种基于邻域统计的二值化方法,先由分割对象生成邻接图,高于阈值T1的顶点值置为1,低于阈值T2的顶点值置为0,介于T1与T2之间的作为待判断顶点,当待判断顶点的邻接顶点中为1的顶点数量大于为0的顶点数量时该顶点值置为1,否则值置为0。当阈值T1、T2分别设为0.2和0.5时二值化效果如图5(c)所示。
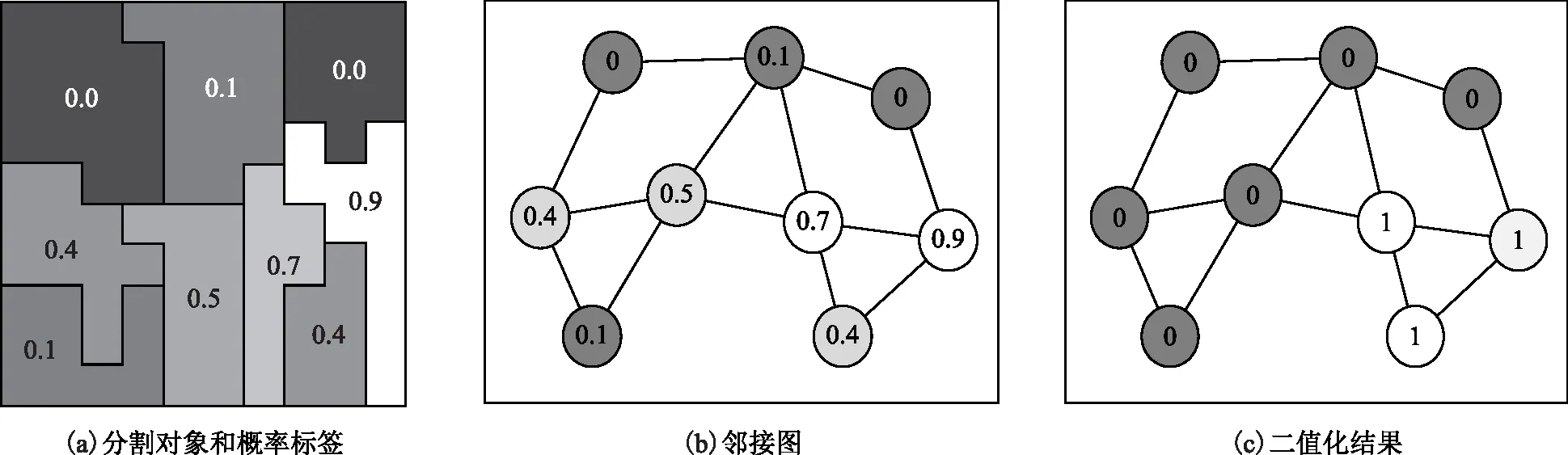
图5 基于邻域统计的二值化
2 实验与分析
2.1 实验数据
采用国际摄影测量和遥感学会2D语义标注大赛提供的ISPRS Vaihingen 语义标记数据集,此数据集包含33张0.09 m分辨率的正射遥感影像,包含3个波段(NIR、R、G),并提供了相应的DSM数据和包括建筑物在内的地物覆盖图。
2.2 建筑物提取实验
从数据集的33张影像上提取出7 981个建筑物样本以及391 282个无标签样本,以此训练Bagging-PU分类器。实验中,Bagging-PU分类器抽样次数T为100,每次未标记样本抽样数量K=0.5×|P|,其中 |P| 为正样本数量。子分类器选择决策树分类器。采用信息熵为分枝标准,树最大深度为30。实验结果如图6所示。

图6 建筑物提取各步骤结果
图6显示了建筑物提取不同步骤的结果。从图6(b)结果看到,自动提取的建筑物样本其基于像素统计的精确率高达0.975,说明本文提出的自适应方向的阴影景观方法可以提取出良好的建筑物样本,这为Bagging-PU分类器的训练提供了数据基础。最终建筑物提取结果精确率和召回率分别能够达到 0.850 和 0.886,表明该分类器可以应用于建筑物检测任务。
表1列出了部分图像基于像素的评价。可以看出本文方法在不同图像上表现较为稳定,33张影像总体F1分数和IoU达到0.864和0.761,总体精度达到了0.928。

表1 建筑物提取结果评价
综合目视结果和各评价指标来看,本文提出的建筑物提取方法对复杂环境有一定的适应能力,在图6中可以看出许多建筑物在样本提取阶段由于自身形状不规则或者阴影形态不完整并未被检出,但在PU Learning提取阶段仍然能被识别出来,获得了较好的召回率。因为PU Learning分类器的输入并不包含阴影或形状特征,所以本文方法在样本提取阶段设置的较为严苛的阴影和形状条件并不会使最终结果出现明显偏差。
2.3 对照实验
为了进一步分析本文方法的合理性,设计了如下实验。(1)将本文方法中基于对象的分析方法替换为基于像素的方法。(2)采用固定方向的阴影景观方法提取建筑物样本。(3)使用Tian等[23]提出的高度阈值方法提取建筑物样本(使用归一化植被指数制作植被掩膜,排除植被覆盖区域,然后指定建筑物高度阈值,使用nDSM数据初步提取建筑物样本),然后将提取出的样本作为PU Bagging分类器的输入。对照实验结果如表2和表3所示。
由表3可知,面向地理对象的分析方法对比面向像素的方法F1分数和IoU指标分别提升了0.054和0.081,说明在本文场景中面向地理对象的分析方法优于面向像素的方法,面向像素的分析方法不仅处理的数据量大大增加,提取结果也易受噪声像素干扰。由表2可以看出,本文方法提取的样本在数量和质量上都高于固定方向阴影景观方法,而最终的提取结果上看本文方法在F1分数和IoU两项指标上也分别有0.018和0.027的提升。
由表2可以看出,高度阈值方法提取的样本数量远高于本文方法,但样本质量却并不高,样本精确率较本文方法低了0.178,且由于采用高度阈值提取样本在高度特征上存在明显偏差,不符合PU Learning的随机采样假设,所以此时PU Learning分类器无法再采用高度特征作为输入,从而影响了最终的建筑物提取结果。
3 结束语
为了减少建筑物检测任务所需的人工工作量,本文提出了一种不需要样本输入的建筑物自动检测方法。在ISPRS Vaihingen数据集上的实验表明方法在复杂环境下获得了较为准确的提取效果。本文建筑物提取方法对于阴影关系这种难以量化的特征采用了人工设计方法提取分析,而光谱、DSM等机器学习模型擅长处理的量化特征由分类器处理。根据数据的不同特性分别处理,能够更好地利用遥感数据包含的丰富信息,提升数据自动化解译效果。但本文方法也存在一些问题:检测出的建筑物在边缘仍然容易出现漏检和错检,进一步提高检测效果可以结合建筑物的边缘和形状特征优化检测结果;对影像数据特征提取不够深入,引入神经网络技术提取影像更深层次的特征信息可能是未来改进的方向。
