基于双流网络的视频级对比学习*
2023-08-31梁梦姿徐大宏
梁梦姿 刘 宏 李 希 徐大宏
(湖南师范大学信息科学与工程学院 长沙 410081)
1 引言
视频表示学习是视频理解的基础任务,在动作识别、视频检索等下游任务中发挥着重要作用。常见的方法是以监督学习方式,使用深度神经网络来提高视频表示学习能力。然而大量的标记是耗时费力的。自监督学习利用无标签数据集对模型进行训练并取得良好的效果。对比学习是自监督学习的主流方法之一,它在图像表征学习方面取得了重 大 进 展。典 型 的 算 法 有SimCLR[1],MoCo[2],BYOL[3]等。最近的研究致力于将对比学习应用在视频表示上。在视频表示学习中,不仅要学习它的空间特征还要学习时序特征,所以它的难度更大。此外,现有的视频对比学习方法,如Pace[4],SeCo[5],CMC[6]等,它们大多是在片段级或帧级定义正对进行对比学习,这限制了在长时间范围内对全局时空的利用。因此合理选择编码器以及合理制定正负对是视频对比学习的关键。
对比学习的目标是训练一个有效的特征编码器。目前,提取视频时空特征的主要架构是卷积网络和Transformer。卷积神经网络主要有两个研究方向:一种是基于2D 卷积的方法。最典型的是双流法[7],一个分支从单帧RGB 图像中提取空间特征,另一个分支从光流中提取时间特征。还有一种是基于3D卷积的方法。它能同时捕获视频中的时空信息[8],但难以捕获较长的时域信息依赖。另一个主流架构是Transformer。它可以使用自注意力机很自然地捕获全局表示,典型的算法有ViT[9](Vision Transformer)。ViTAE[10]在ViT 基础上引入Reduction Cell 和Normal Cell 两 种 模 块,解 决 了Transformer 基于全局自注意力的计算导致计算量较大的问题,同时也解决其捕获局部表示能力的不足。
为了让模型更有效地学习到视频的全局时空表示,本文提出了一种基于双流网络的视频级对比学习框架(VCTN)。文章从两个方面对现有的视频对比学习方法进行改进。在网络结构上,我们采用了CNN 和Transformer 的双流网络并行地提取视频的时间和空间特征。在数据增强上,我们提出了一种基于时间段的增强方法,用来形成正对,从而进行视频级的对比学习。
2 视频级对比学习
2.1 模型的整体框架
本文提出了一种基于双流网络的视频级对比学习方法,如图1 所示,这是模型的整体框架图。这个框架中有两个分支。一个分支叫在线网络(参数为θ),由视频编码器fθ,投影器gθ和预测器qθ三部分构成;另一个分支叫目标网络(参数为δ),由编码器fδ和投影器gδ两部分构成。其中fθ、fδ包括一个Transformer 编码器和一个CNN 编码器,用于提取特征。gθ、gδ是一个多层感知机(MLP,隐藏层为2,其中一个隐藏层维度为4096),用于获取更高维的潜在向量。qθ也是一个多层感知机,用来预测目标网络的投影特征。两个网络相互作用相互学习。在线网络通过优化目标网络更新其参数,目标网络通过计算指数滑动平均值来更新其参数。
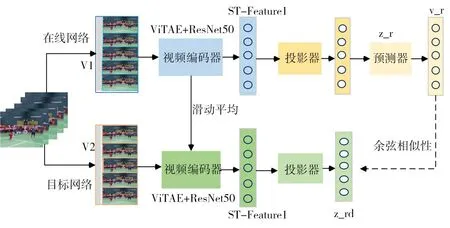
图1 模型的整体框架
2.2 增强视图的构建
对比学习最关键的一部分是构建增强视图。视频比图片多了时间维度。因此本文提出了一个基于时间段的数据增强算法用于构建增强视图。如图2所示,给定一个视频V,首先,将视频均匀划分成T个相等时长且不重叠的片段{S1,S2,S3,…,ST}。然后使用了基于时间段的增强方法构建两个增强视图,该方法融合了随机采样、稀疏采样和整体采样策略。随机采样是从一个片段的随机起始点采样视频帧。稀疏采样是从一个片段中采样一部分视频帧。整体采样是从一个视频的每个片段采样视频帧。具体采样方式如下:
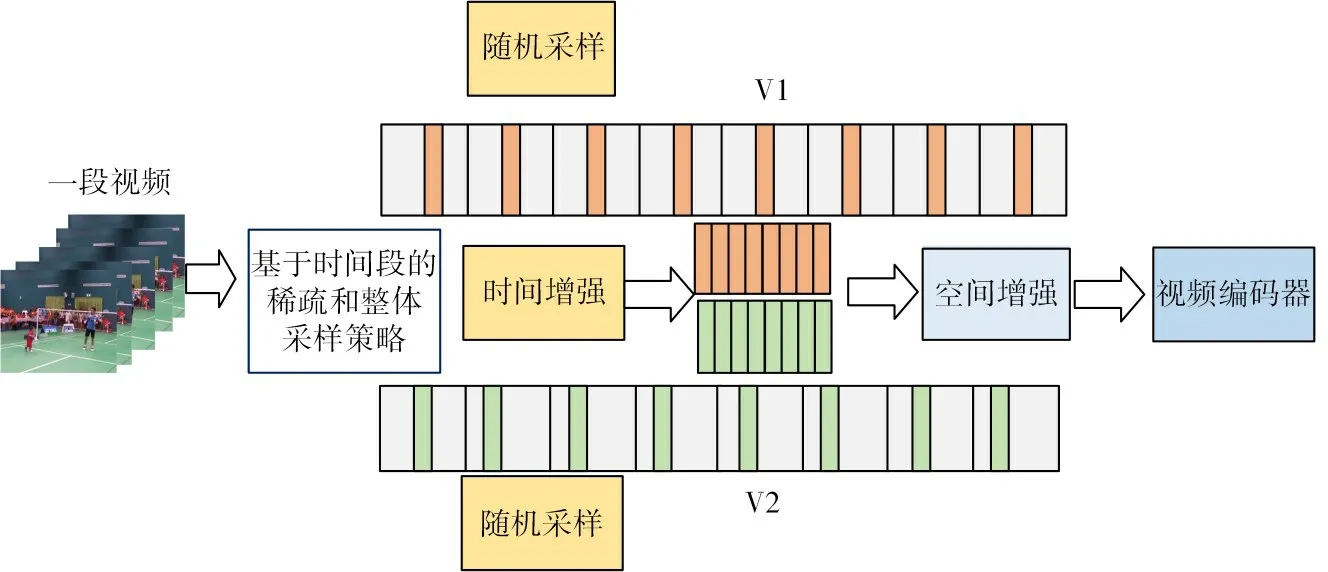
图2 数据增强
1)首先定义每段视频的持续时间ad,ad=num_frames T,其中,num_frames是视频的总帧数,T是视频分段数。
2)接下来就是从每段Si中随机抽取帧数。按照随机采样的方式,假设第一个片段随机数为r1,则第一个片段抽取的帧I1的序号为0×ad+r1。
3)按照稀疏采样的方式,从第一个片段中采样以I1为中心的5帧。
4)整体采样。在每个片段中都采取随机采样和稀疏采样的方式。这样每个片段抽取到的中心帧序号为[0 ×ad+r1,1×ad+r2,…,(T-1) ×ad+rT]。
本文从每个片段Si中随机抽取以Ii为中心的五帧图像。这样一个增强视频V1总共采样得到5×T帧图像。用同样的方式,得到另一个增强视频V2。对于空间数据增强部分,本文使用了随机调整大小和裁剪、水平翻转。
2.3 双流网络结构
为了有效学习到视频的全局时空信息,本文将视频分成多个片段,然后使用双流网络去处理每个片段,再将不同片段提取出来的局部时、空特征分别用平均聚合函数进行融合,最后再将融入全局上下文的时间特征和空间特征拼接得到视频级的时空表示。本文的双流网络使用的是两个独立的网络架构:一个Transformer编码器和一个2D CNN 编码器。
在空间上,本文使用具有内在局部性的Transformer 网络ViTAE 在每一段的中间帧I={I1,…,IT}上提取空间信息。如图3所示,ViTAE包括3个Reduction Cell(RC)和若干个Normal Cell(NC)。RC模块可以让模型学习到视频图像的多尺度不变特征,NC 模块可以让模型学习视频图像的局部特征以及全局依赖关系。本文沿不同时间段提取了大小为T×3×224×224 的RGB 视频序列输入到Vi-TAE 网络中。ViTAE 网络首先使用三个RC 将视频序列逐步下采样4 倍、2 倍和2 倍。然后将RC 的输出token展平与一个可学习的向量class token连接,并添加正弦位置编码。再将这些tokens 送到下面的NC 模块,这些NC 保持tokens 的长度。最后,将最后一个NC 上的class token 输出作为每段的空间特征。

图3 空间网络
在时间上,本文使用2D CNN 去提取时间特征,采用的骨干网络是ResNet50。如图4 所示,在一个片段Si内,本文选用RGB 差分代替光流信息,即所有帧之间两两计算RGB 差分:,然后将其堆叠输入到ResNet50 中。R1,R2]代表以Ii为中心的连续五帧之间的RGB 差分。按照相同的方法,可以得到其他片段的运动视图[R(I2),…,R(IT)]。 再把它们分别送入到ResNet50中提取每一段的时间特征。

图4 时间信息
2.4 损失函数
本文遵循BYOL 方法,选用均方误差MSE 作为视频的损失函数。本文的对比学习目标是最大化具有相同上下文的视频片段之间的相似性。对于V1,先将它送入在线网络中,通过视频编码器fθ提取ST-Feature1 ,再经过投影器gθ得到投影向量zr。然后经过预测器qθ得到预测向量vr。对于V2,先 将 它 送 入 目 标 网 络 中,通 过fδ提 取S分后T-的别。F预e对归at测一uvrre输化,2出的,zr再d方-v两经r法和个过如目向g式标δ量 (得网1进)到络所行投的示归影。投一向最影量化后输得z用r出d到。归然一后和化的MSE函数作为损失函数。如式(2)所示,其中, 是点积运算。
按照相同的方式,将V2送到在线网络,V1送到目标网络计算出对称损失函数l2。因此,整个视频的损失函数为
模型训练过程中只有在线网络的参数θ根据梯度进行更新,目标网络的参数δ依据滑动平均公式进行更新,如式(4)所示,其中τ是目标衰减率,τ∈[0 ,1] 。
3 实验
3.1 数据集
本文在UCF-101[11]和Kinetics-400[12]两个广泛使用的动作数据集上进行实验。UCF-101 由来自101 个不同动作类别的13320 个视频组成,其中约9.5k 视频用于训练,3.7k 视频用于测试。Kinetics-400 拥有大约30 万剪辑过的视频,涵盖400 个类别。其中240k用于训练、20k用于验证,40k用于测试。
3.2 实现细节
在输入方面,本文采用基于时间段的采样算法,默认将段的数量设置为8,从每段中随机抽取以Ii为中心的五帧图像,这样增强视频V1共包含40 帧。用同样的方式,可以得到另一个增强视频V2。在空间数据增强方面,本文首先将视频帧的大小调整为256×320,然后随机裁剪为224×224。在训练时,本文遵循与BYOL 相同的方法去预训练视频编码器(ResNet50和ViTAE-S)。在优化方面,本文使用的是LARS优化器,初始学习率设置α=0.2,并随批大小线性缩放(α=0.2×BatcℎSize/256 ),权重衰减为1.5×10-6,本文使用余弦衰减计划衰减学习速率而不重启。对于目标网络,指数移动平均参数τ从τbase=0.996 开始,在训练过程中增加到,其中k为当前训练步长,K为最大训练步长数。
3.3 下游动作分类
为了验证所提框架的有效性,本文在两种情况下进行评估:1)线性评估;2)微调。本文首先在大型数据集Kinetics-400 上对网络进行预训练,批量大小为512,训练时间为200 个周期。然后在较小的数据集UCF-101 上对网络进行微调。本文选用Top-1 准确率(Accuracy)作为评估模型框架的指标。
3.3.1 Kinetics-400的线性评估
线性评估的方法是保持视频编码器上的参数固定不变,然后在生成的视频表示上训练分类器。本文选择在Kinetics-400训练集的视频表示上训练分类器,最后在其验证集上进行评估。从表1 可以看出,本文的方法在Kinetics-400 数据集上取得了66.8%的准确率,高于以往的算法。其中,比SeCo方法高4.9%,比VCLR高2.7%。
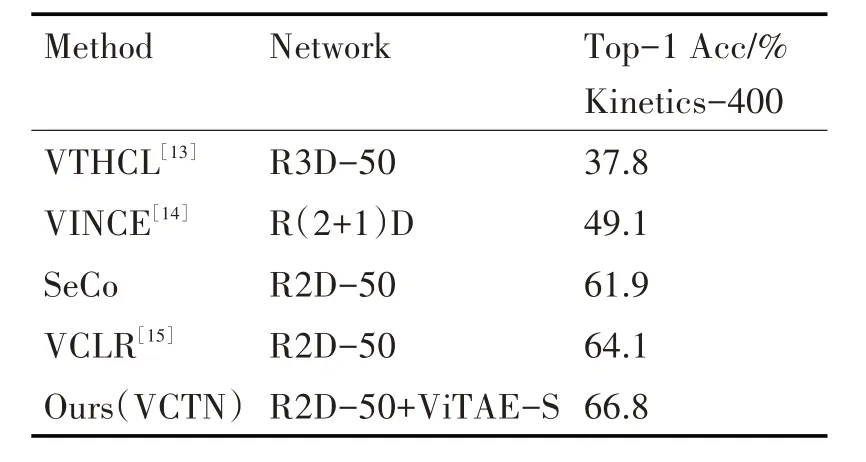
表1 Kinetics-400的线性评估
3.3.2 UCF-101的微调
在表2 中,本文进一步将VCTN 与最近的自监督行为识别方法进行了比较。本文在UCF-101 数据集上对所有层进行微调。为了公平的比较,本文只列出了在Kinetics-400 上预训练的方法。从表2中可以看出,本文使用2D ResNet50 的方法优于使用3D ResNet 的方法。同时,与SeCo 相比,本文的方法VCTN 在UCF-101 数据集上带来了4.3%的性能提升。同样,与VCLR 相比,UCF-101 的准确率从85.6%提高到87.7%。这些结果验证了本文的VCTN可以有效地学习到视频的全局时空表示。

表2 UCF-101的下游动作分类
3.4 消融实验
本文进行多个实验来分析框架的不同组件,以验证在VCTN 中使用的每个单独组件的有效性。除非另有说明,实验均在Kinetics-400 数据集上进行。
3.4.1 网络体系结构
在表3 中,本文研究了网络架构对实验结果的影响。“R2D-50+ViTAE-S”表示本文的默认视频编码器。“仅R2D-50”表示在时间和空间上仅只使用2D ResNet-50 和线性转换层来提取每帧的特征。“R2D-50+ViT”表示时间上使用2D ResNet-50提取特征,空间上使用Vision Transformer提取特征。实验结果表明,本文的默认网络在Kinetics-400 数据集取得的准确率优于其他两个网络,达到66.8%。
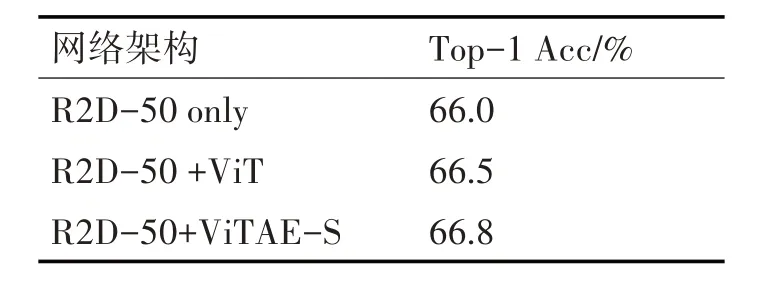
表3 在不同网络架构上的消融实验
3.4.2 时间数据增强的研究
在实验中,本文将K=8 作为默认的分段数,现在讨论分段数对本文所提方法的影响。从表4 中可以看到,片段数量从1 增加到8,准确率不断提高,从60.1%提高到66.8%。这表明在训练视频编码器时使用全局上下文的必要性。但是当使用更多的段T=16时,性能趋近饱和,只提高了0.2%。因此,本文选择T=8,以获得更好的训练速度与准确率的权衡。除此之外,本文还研究了RGB 差分对实验结果的影响。从表5 中可以看到,与直接叠加五帧输入的网络相比中,使用RGB 差分堆叠获得的准确率高1.7%。
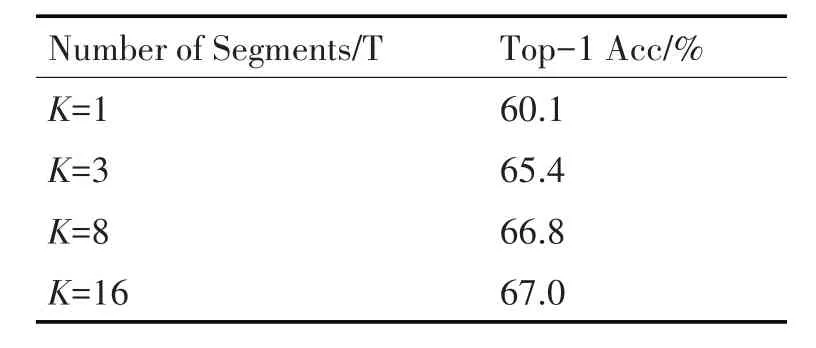
表4 在不同数量段上的消融实验

表5 RGB差分的效果影响
4 结语
本文提出了一个基于双流网络的视频级对比学习框架(VCTN),采用CNN 架构和Transformer 架构代替以往双流网络仅使用CNN 的方法,从而提取到了更丰富的时空特征。同时,本文提出了一种基于时间段的数据增强采样算法,用来生成正对,从而加深了长时间范围内对全局时空的利用。本文在UCF-101 和Kinetics-400 两个广泛使用的动作数据集上进行实验。实验表明,本文所提出的方法在Kinetics-400 数据集上取得66.8%的分类准确率,在UCF-101 数据集上取得87.7%的分类准确率。
