基于在线医疗咨询文本的抑郁症症状短语的自动识别
2023-08-31聂卉吴晓燕
聂卉 吴晓燕

关键词: 在线医疗咨询文本; 抑郁症; 语义建模; 短语识别
DOI:10.3969 / j.issn.1008-0821.2023.09.006
〔中图分类号〕G202; TP391 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 09-0063-11
据世界卫生组织报告, 抑郁症已成为全球巨大的疾病负担, 约3 8%的世界人口患有不同程度的抑郁症[1] 。要降低疾病危害, 患者尽早接受医疗救助至关重要。“线上问诊” 打破了传统就医模式的时空束缚, 调查显示抑郁症病患对线上问诊的接受度高达92 24%[2] 。在线问诊记录是患者与医生的交流文本, 求诊者对病程、感受、状态、情绪的陈述[3] 反馈出其罹患疾病的性质、严重度及对健康的影响, 是疾病诊断的重要依据[4] 。在真实的医疗场景中, 相较其他疾病, 抑郁症诊断也主要依托量表及患者与医生的交流记录, 因此, 大规模在线问诊记录为抑郁症研究提供了充分的数据支持。
现有基于互联网的抑郁症研究, 主要是通过分析用户生成内容来预测抑郁风险, 首要任务是识别抑郁症状。早期研究采用词典法, 但静态词典不能全面覆盖患者病况, 预测精准度低; 而随后提出的有监督机器学习则需付出人工标注成本。因此, 设计一个无需标注, 也能高效地从患者问诊记录中识别抑郁病症的方案成为本研究要点。
深度学习建模技术在自然语言处理方面性能卓越。基于大规模的抑郁症在线咨询文本语料, 本研究引入深度学习建模技术, 采用无监督机器学习策略构建症状识别模型, 并通过抑郁症典型特征分析、抑郁症风险预测两个实际应用检验症状识别模型的实效。本研究工作旨为辅助医生诊断、提高医疗平台问诊服务效率、增强抑郁症筛查和防控能力提供技术参考。
1文献综述
1.1医学术语与疾病症状的识别研究
与疾病有关的医学术语的识别与表示是医学自然语言处理领域的经典问题[5] 。早期研究主要采用词典和规则匹配法, 如Matheny M E 等[6] 基于关键字和本体规则, 从临床记录中自动抽取传染性疾病的症状。Byrd R J 等[7] 借助词典与语法分析, 从病人记录中提取心力衰竭的描述。基于词典和规则的方法完全依靠医学领域词典和专家, 实际应用中普适性较差[8] 。随后, 学者们提出了有监督机器学习方案, 因为有学习过程, 有监督学习摆脱了外部资源的制约, 可应用于不同场景。用有监督机器学习抽取医学术语的3 个主流算法是支持向量机(SVM)、隐马尔可夫模型(HMM) 和条件随机场(CRF),CRF 应用最广[9] 。叶枫等[10] 以语言符号、词性、构词模式、词边界、上下文为特征, 采用CRF 识别电子病历中包括症状在内的医学命名实体。Forsyth AW 等[11] 用CRF 从乳腺癌患者的诊疗记录中提取疾病症状并判断性质。相较词典匹配, 有监督机器学习方案显著提升了术语识别的查全率, 整体表现更优。但有监督机器学习算法的表现很大程度上取决于特征工程, 存在不稳定性。
近年, 深度学习为医学领域的自然语言处理任务提供了富有潜力的方案。深度学习框架不考虑特征工程, 以分布式向量表示医学文本, 并应用于疾病诊断。如Guo D 等[12] 先利用MetaMap 从病案记录中抽取症状, 然后用词向量表示症状, 再运用深度学习框架(Bi-LSTM)预测疾病发生风险。Luo X等[13] 同样先用MetaMap 提取病案中有关体征和生理的医学术语, 再整合用药等信息, 构建咳嗽诊断模型, 该研究对比了多种机器学习方案, 基于BERT 预训练模型的诊断模型表现最佳。
1.2抑郁症状的提取与应用研究
作为面向特定疾病的医学症状识别研究, 抑郁症症状识别遵循同样的技术路线。Karmen C 等[14] 根据抑郁症量表获取症状术语种子, 然后利用词典拓展同义词, 生成症状词典。Cavazos-Rehg P A 等[15]直接依據《精神障碍诊断与统计手册》(DSM-5),对Twitter 推文中的抑郁症状进行手动编码, 然后统计出与重度抑郁症相关的症状描述。Wu C 等[16]利用电子健康记录检测重度抑郁症的典型症状, 症状识别采用了CRF。深度学习技术则越来越多地在最新的研究文献中出现, Uddin M Z 等[17] 通过公共信息网获取用户生成内容, 根据医生列出的抑郁症状为用户建模, 再运用深度学习框架RNN 预测用户的抑郁症倾向。Yao X 等[18] 运用深度学习框架Att-BiLSTM 构建文本分类器, 对抑郁症社区中用户提及的抑郁症状进行分类整理, 再通过网络分析挖掘症状间的关联。
包括深度学习, 应用有监督机器学习算法, 移植性和标注成本是两个不可回避的问题。面对大规模语料, 有学者尝试了无监督机器学习策略, Ma L等[19] 使用词向量表示症状, 用聚类技术抽取抑郁症状。Usman A 等[20] 首先构建基于词向量的情感词典, 再运用深度聚类算法分析患者发布文本, 以可视化方式呈现患者文本中的情绪。可见, 用无监督机器学习算法识别疾病症状同样可行[21] 。相关研究发现对于患者个性化的陈述, 症状表达存在句法和语义上的变异性[4] , 常无法直接对应单一词项,短语的长度灵活, 表达语义丰富, 显然更适于描述疾病症状。
综上, 无监督机器学习的普适性为在大规模语料集上快速检测抑郁症风险提供了新的技术选择,短语形式的症状描述则能更准确地表达语义, 因此, 采用无监督机器学习策略, 基于语义建模, 实现短语级抑郁症状的自动识别值得探究。
2研究设计
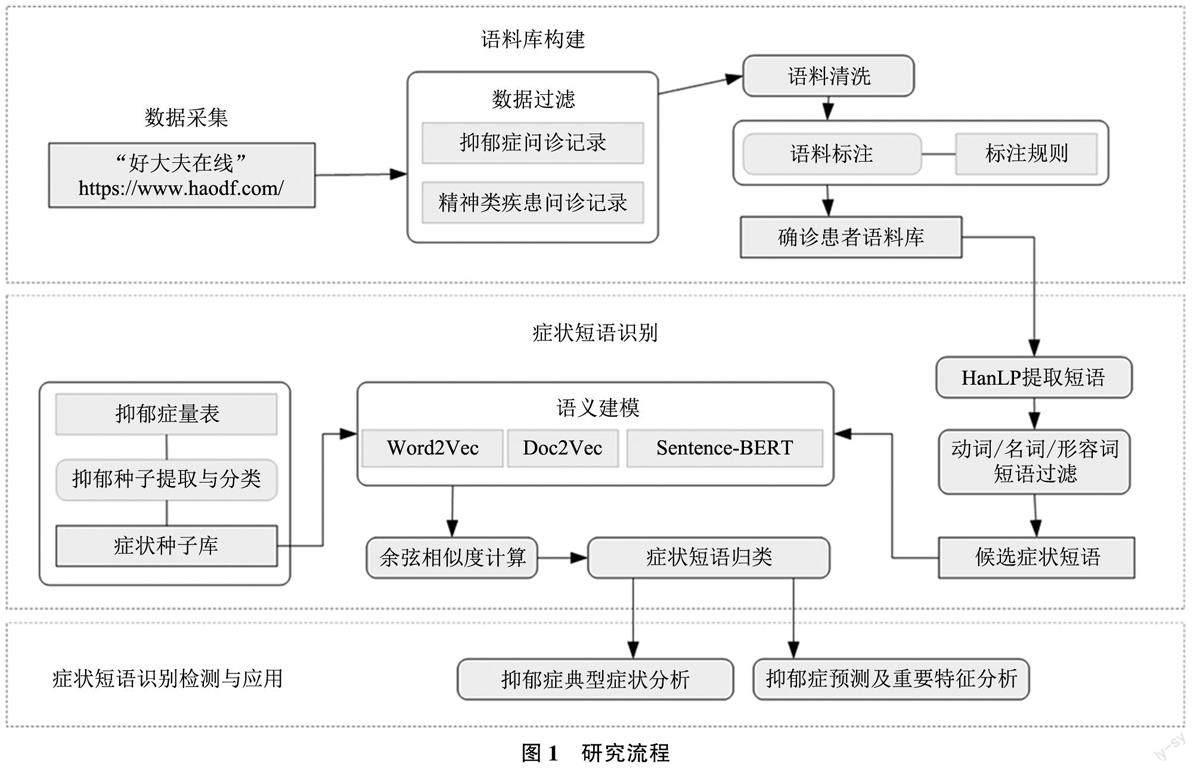
数据层面, 基于求诊者的问诊记录建立语料库,是本研究的首要任务。问诊记录中的“疾病描述”部分包含大量抑郁症状描述, 本研究从中提取这些症状描述, 用于构建患者模型, 并用于抑郁症典型症状分析和抑郁症风险预测两个任务。在原始语料中, 没有字段明确标识病况(是否是确诊患者以及抑郁的程度), 病况从问诊记录中获取, 并据此生成研究语料集。方法层面, 识别症状短语是研究重点, 主要涉及短语抽取与语义建模两个任务。对此, 本研究采用无监督机器学习策略并引入深度学习模型表示症状。应用层面, 在抑郁症典型症状分析和抑郁症风险预测两个具体任务上检测症状识别算法的实效。依据上述设计, 将整个研究分为三部分, 如图1 所示: 语料库构建, 抑郁症状短语自动识别及应用, 核心是症状短语的识别算法。
3研究方法
研究采用无监督机器学习方案实现抑郁症状短语的自动识别。算法基本思想是, 基于抑郁症量表先构建症状种子词库, 再从“疾病描述” 文本提取有关症状的叙述(短语形式)作为症状候选项, 计算候选项与种子间的语义相似度, 据此判定候选短语是否为抑郁症症状, 并明确症状的类别。算法核心是如何对短语进行恰当的语义表示, 本研究选择了Word2Vec、Doc2Vec 和Sentence-BERT 3 种语言模型, 通过数据实验从中选出最佳。整个算法包括抑郁症症状种子库构建、候选症状短语提取、症状识别3 个部分。
3.1抑郁症症状种子库构建
抑郁症症状种子是一组描述抑郁典型症状的词项或短语, 是诊断患者抑郁的重要依据。临床检测中, 患者需要填写抑郁测试量表, 医生据此了解其感知、认知、生理、行为等方面的状态, 量表题项中有针对症状的规范表达。例如, 贝克抑郁量表BDI-Ⅱ量表的题项“我比之前睡眠过少” 中“睡眠过少” 就是抑郁症“睡眠障碍” 的典型症状。
研究首先依据国际疾病分类ICD-10(Interna?tional Classification of Diseases, ICD)体系标准诊断中的症状类别建立抑郁症症状分类体系, 再按分类体系从量表题项中梳理出表述症状的代表性短语或词项, 即症状种子。研究共梳理了10 个临床心理学常用量表, 包括贝克抑郁量表Ⅱ(BDI-Ⅱ)、抑郁症DSM-IV 的诊断标准、抑郁症诊断标准ICD-10、流行病学研究中心抑郁量表(CES-D)、老年抑郁量表(GDS)、汉密尔顿抑郁量表(HAM-D)、蒙哥馬利-阿斯伯格抑郁量表(MADRS)、Zung 抑郁自评量表(SDS)、DSM-5 对抑郁症的诊断标准、PHQ-9 抑郁症筛查量表。将从量表中提取的症状种子映射到症状分类体系中, 形成症状种子库。如表1 所示, 症状种子库含有86 个种子词, 对应10类抑郁症典型症状。
3.2候选症状短语提取
候选短语提取在开源汉语语言平台HanLP(ht?tps:/ / www.hanlp.com/ )[22] 上实现。该平台在中文自然语言处理领域有广泛应用, 提供分词、词性标注、命名实体识别、短语识别等基本语言处理功能, 其中, 短语识别基于互信息与信息熵实现。研究利用该平台从“疾病描述” 文本中抽取短语, 并对组成短语的词项进行词性标注, 将含有动词(包括动词v、动词性惯用语vl 和不及物动词vi)、名词(包括名词n、名动词vn、专有名词nz)和形容词(包括形容词a 和名形词an)的短语作为候选症状短语, 短语抽取效果如表2 所示。可以看出, 候选短语中有大量与抑郁症症状有关的叙述, 后续识别任务即通过语义计算确立候选短语与抑郁症典型症状间的关系。
3.3症状识别
要确立候选短语与抑郁症典型症状的语义关联,语义模型的选择是关键。研究选用了Word2Vec、Doc2Vec 和Sentence-BERT 3 个语义模型对抑郁症症状短语向量化。Word2Vec 是经典的词向量模型,成功运用在各种自然语言分析任务中, 完成了从词袋到词向量语义特征表示的跨越[23] 。Doc2Vec[24] 是Word2Vec 的文档级模型。考虑到本研究中, 抑郁症症状采用短语表达, Doc2Vec 模型可能更合理。
BERT 是目前自然语言处理领域最流行的语言模型, 它通过在大规模语料上采用NSP(Next Sen?tence Prediction)机制和掩码语言模型(Masked Lan?guage Model, MLM)做预训练任务, 能够使模型学到丰富的语义知识, 具备理解文本深层语义的能力[25] 。尽管如此, 在句子对回归等任务(如文本相似度计算, 语义聚类)上, 原生BERT 需将句子拼接后输入模型, 再通过带有自注意机制Self-atten?tion 的transformer 网络进行预测, 这导致巨大的计算开销, 在语义相似度搜索等任务上的表现并不理想。为此, Reimers N 等[26] 对BERT 结构进行修改,他们使用孪生网络或3 胞胎网络(Siamese and Trip?let Network)生成维度固定的语句向量, 语义相近的语句, 语句向量的空间距离接近, 通过余弦相似度、欧式距离计算能够快速找到语义相近的语句,这就是Sentence - BERT 的构建原理。相较原生BERT, Sentence-BERT 在不影响准确性的同时,能够大幅提升计算效率(计算余弦相似度大概为0.01 秒), 特别适用于文本相似度计算、文本聚类等无监督机器学习任务[27] 。
Sentence-BERT 的结构如图2 所示。两个语句Sentence A 和Sentence B 通过共享参数的BERT 模型生成它们的字向量(Token Embedding), 再传入池化层(Pooling)进行平均池化操作, 得到固定维度的句向量u 和v。然后计算u 和v 的余弦相似度Cos-similarity(u,v), 并输出。微调过程中均方误差(Mean Squared Error, MSE)为损失函数。在Rei?mers N 等[26] 的实验中, 文本语义相似度计算的评测语料是语义文本相似计算(Semantic Textual Simi?larity, STS)任务的数据, 这些数据是成对带类标的语句, 类标标识了语句间的关系, 取值范围为0~5。评测实验直接用训练好的模型计算语句对的相似度, 然后通过皮尔曼等级相关系数评测模型优劣, 结果显示, 相较原生BERT, Sentence-BERT表现最佳。
本研究要计算种子词与候选症状短语之间的语义相似度, 分别采用了Word2Vec、Doc2Vec 和Sentence-BERT 3 个模型对候选症状短语和种子词向量化, 再计算候选症状短语与每类种子词的语义相似度, 见式(1)。其中, t 为候选症状短语向量, Ci 对应症状类i, 为候选症状短语t 与种子词s的余弦相似度。依据式(1) 分别计算候选词t 与每个症状类Ci(i =1,2,…,10)的相似度, 若相似度的最大值满足阈值设定, 指定相似度最大的类CMax为候选症状t 的类别。
4实验与结果
4.1语料库构建
4.1.1数据源与数据采集
“好大夫在线” (https://www.haodf.com/ )是国内领先的在线医疗平台。据最新统计, 该平台收录了国内1 万多家正规医院的89 万名医生的信息,累计服务量超过7 900万人次[28] 。问诊记录规模在国内在线医疗平台中名列前茅。基于该平台的数据质量及在医疗服务领域的权威性, 本研究将其作为数据源, 采集了“好大夫在线” 近3 年问诊记录百万余条, 其中361 647条记录来自精神科、心理咨询科和神经内科, 从中筛选出抑郁症医疗咨询记录71 654条。每条记录包含疾病描述、疾病名、患者性别、年龄、病程等字段。其中, “疾病描述”为文本型字段, 是患者面对医生针对个人病情的详细陈述, 为患者问诊的主要内容。本研究选择该字段内容提取患者的病征、情绪、心理状态和行为,数据采集样例如图3所示。
4.1.2 抑郁症预测评测语料
抑郁症预测评测语料用于检验抑郁症人群的自动识别效果。研究采用关键词匹配策略从问诊记录中提取确诊信息, 并对语料做标注。具体步骤如下:
首先对“疾病描述” 的内容进行分词, 剔除单个字词语、数字、标点符号及过短(文本长度<18)记录, 获得抑郁症问诊记录70 705条。算法遍历每条记录内容, 依据匹配规则, 提取确诊信息。例如: “…今天去了北京安定医院诊疗。做了心理评估, 结果为轻度抑郁。…”, 由此断定问诊者患“轻度” 抑郁症, 将其问诊记录标注为“轻度”。完成初始标注后, 进行抽样检查, 发现部分确诊情况只是患者推测, 如“感觉有轻/ 中/ 重度抑郁”,故设定“非确诊” 规则对初标注语料进行二次梳理与核查, 最终获得带抑郁症程度标记的语料8391条, 其中, 重度抑郁3090条, 中度抑郁3016条, 轻度抑郁问诊记录2 285条。另外, 从非精神类疾病的问诊记录中随机抽取2 797条, 归为“非抑郁”, “非抑郁” 疾病涵盖多种疾病, 这些疾病在生理层面与抑郁症可能存在类似症状, 如“头痛”“乏力”, 但精神情志层面与抑郁症应有显著差异。将这类问诊记录与抑郁症问诊记录进行整合, 分成“轻度、中度、重度、非抑郁” 4 组, 共计11188条, 语料命名为DATASET1。
4.1.3抑郁症症状识别评测语料
研究采用Word2Vec、Doc2Vec 和Sentence-BERT3 个语义模型表示症状短语, 抑郁症症状识别语料用于评测3 个模型的性能表现。语料标注采用人工方式, 从抑郁症患者的70 705条问诊记录中随机抽取800 条, 对照抑郁症症状分类体系, 如表2 所示, 对“疾病描述” 文本中提及的候选症状短语进行人工归类, 示例如表3 所示。形成一个小规模的评测语料集DATASET2。
4.2抑郁症症状识别模型
采用4.1.3 的症状短语识别方法, 在DATA?SET2 上进行实验。Word2Vec 和Doc2Vec 基于361 647条来自精神科、心理咨询科、神经内科的问诊记录构建。3 个语言模型的参数设置如表4 所示。另外, 依据算法, 在确定候选短语t 的症状类别C 时, 要求t 与C 的相似度超过阈值ε。研究将ε 作为参数, 通过实验确定, 如图4(a)、图4(b)所示。
评测指标是识别10 类症状短语的准确率、召回率和F1 值的微平均值。如图4(a)所示, 模型Word2Vec 和Sentence-BERT 的表现优于Doc2Vec。当ε∈[0.5,0. 6]时, Word2Vec 和Sentence-BERT的F1 值接近, 分值最高。细分ε 的实验结果见图4(b)。整体观察, 当ε =0.51 时, Sentence-BERT的表现最好, F1 值为70.27%, 略优于Word2Vec的最好表现(F1 = 70.09%)。准确率指标上, Sen?tence-BERT 最好达到73.85%, 高Word2Vec 3.76个百分点, 表明Sentence-BERT 的错误率更低。但召回率指标上, Sentence-BERT 为67.03%, 低于Word2Vec(召回率70.09%)。权衡两个模型, 研究认为对于疾病症状识别任务, 在语料相对充足的前提下, 准确率更重要。因此, 后续采用Sentence-BERT 表示短语, 阈值ε 设定为0.51。因该评测语料规模相对较小, Sentence-BERT 症状识别算法的实效在抑郁症患者典型特征分析和抑郁预测两个任务上将做进一步检测。
4.3抑郁症典型症状分析
将4.2 的抑郁症症状识别算法应用于DATA?SET1。针对不同抑郁程度的病人, 抽取“疾病描述” 中的症状短语进行统计。图5 展示了“轻度,中度, 重度” 3 组患者问诊记录中症状短语的分布情况。总体观察, 严重困扰抑郁症患者的3 类症状分别是心境低落(类1)、睡眠障碍(类9)和精力下降(类3), 3 类症状的出现频率显著高于其他症状; 而不同抑郁程度的患者, 3 类症状出现频率差异不大, 说明心境低落、睡眠障碍和精力下降是抑郁患者的共有表现。但图4 揭示出, 随着患者病情加重, 兴趣和愉快感丧失(类2)、自伤或自杀观念行为(类8)、食欲下降(类10)症状的提及率逐步上升, 尤其轻度、中度和重度患者问诊记录中有关“自伤或自杀观念行为(类8)” 的短语的提及率有显著差异, 说明“自伤或自杀观念行為” 的出现是抑郁严重度诊断的重要依据, 严重抑郁伴随着极端行为的发生, 这一结论与临床检测量表的测度依据一致, 从一定程度上检验了症状识别算法的效力。
4.4根据症状识别抑郁人群
该实验通过建立抑郁症预测模型明确抑郁症人群的典型特征, 进一步检验本文提出的症状识别算法的实效。根据10 类症状创建10 个特征变量, 若“疾病描述” 中提及了某类症状, 则对应的特征变量赋1, 否则为0, 即将病情描述文本转换为10 维的0/1矢量, 以症状矢量为输入, 预测问诊者是否为确诊病人。
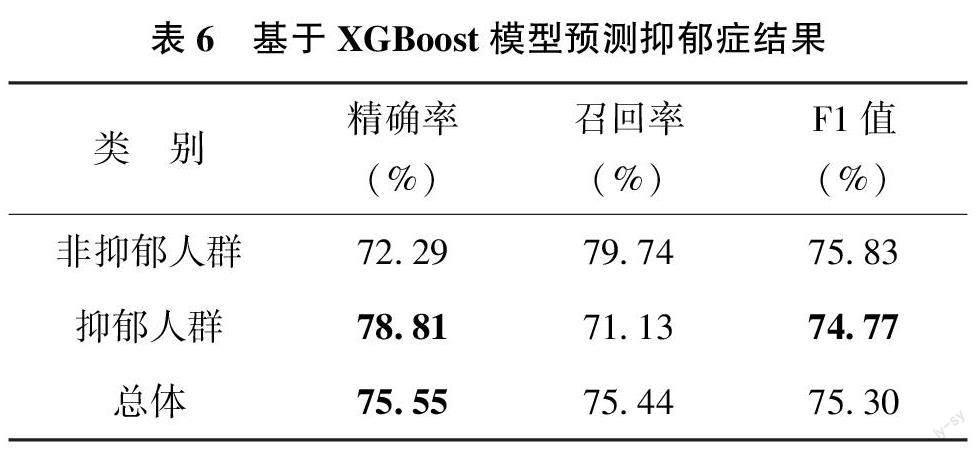
预测模型选用了分类性能优异, 并能够进行特征重要性分析的XGBoost 集成树算法[31] 。以DATA?SET1 为实验数据, 按1∶4划分为测试集和训练集。在训练集上采用五折交叉验证的网格搜索法确定重要参数, 参数取值及最优参数结果如表5 所示, 采用最优参数模型对测试集的问诊记录做预测。结果如表6 所示, 二分类模型的F1 值达到75.3%, 精确率和召回率接近, 均在75%以上, 模型整体表现较理想。对抑郁患者的识别能够达到精确率(78.81%), 高于非抑郁患者(72.29%), 说明基于症状特征构建的预测模型能较好区分抑郁与非抑郁症患者。
XGBoost 同时计算出10 类症状特征变量的相对重要度。特征重要度反映各特征项在预测任务中的贡献, 据此也可揭示抑郁症人群的典型症状。结果如图6 所示, 心境低落(类1)、睡眠障碍(类9)、自伤或自杀的观念或行为(类8)3 类症状是诊断抑郁症的重要因素, 基于XGBoost 的特征重要度排名与抑郁症典型症状特征分析结果一致。心境低落(类1)、睡眠障碍(类9)是患者提及率最高的症状, 特别是心境低落(类1), 其重要度远高出其他9 个变量。这两个症状也是抑郁症诊断标准ICD-107 列出的抑郁症主要特征。自伤或自杀的观念或行为(类8)是区分抑郁程度的重要线索, 同样也是临床判断病患病况的关键信息。这些与临床抑郁症诊断标准相吻合结论, 间接验证了本文抑郁症状自动识别算法的有效性。
5研究结论与局限
5.1研究结论
本研究利用心理学领域的抑郁症测度量表, 运用自然语言处理及深度学习建模技术, 以无监督机器学习方法实现了基于患者在线问诊记录的抑郁症症状的自动抽取。基于抽取的疾病症状, 对不同抑郁程度的患者进行了典型症状分析, 并实现抑郁症人群的自动检测, 检验了本文抑郁症症状识别算法的有效性。主要结论归结为以下两点:
方法层面, 在评测语料上, 本文提出算法的症状识别精度为73.85%。应用该算法分析抑郁症患者典型特征、识别抑郁症人群, 结果与临床诊断标准基本一致, 验证了算法的可行性与合理性。症状短语的语义建模实验比较了3 个深度学习模型,Word2Vec、Doc2Vec 和Sentence-BERT, 具有深层次语义表达能力Sentence-BERT 整体表现最佳, 表明强化短语的语义表示, 用无监督的机器学习方案也能够有效识别疾病症状。
应用层面, 从患者问诊记录中的“疾病描述”中提取抑郁症症状, 应用描述统计和集成树算法XGBoost 对抑郁症群体的典型症状进行分析。描述统计得出的结论是, 心境低落、睡眠障碍和精力降低是抑郁症患者的共有症状, 兴趣和愉快感丧失、自伤或自杀观念行为、食欲下降是中/ 重度病患的典型表现。抑郁症人群的预测实验则揭示, 心境低落、睡眠障碍、自伤或自杀的观念或行为是诊断抑郁症的3 个主要依据。这些依据在线医疗文本数据得出的结论与临床心理学的抑郁症诊断标准相吻合, 说明本方案在实际应用中能为医生快速诊断病情提供有价值的参考, 而检测手段的自动化将有助于提升医疗平台对危重患者的响应能力, 采取有效的干预措施, 降低病症带给人类健康的危害。
5.2研究局限和后续研究思考
本研究有3点不足, 为后续工作提供了研究思路: ①本研究重点分析医疗咨询文本中患者疾病症状的显性表达, 用短语描述症状, 尽管运用了语义模型, 但语句的上下文信息并未纳入模型, 这可能导致抑郁症的某些症状表述未能提取, 从而对抑郁症人群识别模型的预测精度产生影响。后续考虑直接利用疾病描述本文建模, 基于隱性表达的特征预测抑郁症发生风险, 并与本文模型进行对比; ②因症状短语的标注成本较高, 症状识别评测语料规模偏小。本研究通过两个下游任务检测算法, 后续将扩大评测语料的规模, 进一步优化算法; ③将症状提取结果应用于检测抑郁人群, 以实现抑郁症早期发现, 而抑郁严重程度预测将有助于实施个性化治疗, 这将成为未来的另一探索方向。
