机器学习在航空发动机排气温度预测中的应用研究*
2023-08-30易文川唐庆如
易文川 王 兴 王 翔 唐庆如
(1.中国民用航空飞行学院航空工程学院 广汉 618307)(2.中国民用航空飞行学院工程技术训练中心 广汉 618307)
1 引言
离开燃烧室的气体混合物的温度是优化发动机性能和控制排放的关键参数,这是因为排气温度(Exhaust Gas Temperature,EGT)与气缸内的燃烧过程密切相关[1]。EGT 影响排放控制系统的性能。例如,不完全燃烧产物(如一氧化碳和未燃烧碳氢化合物)的催化氧化需要EGT 大于250℃[2]。此外,EGT还可以用于发动机故障诊断和维护,以延长发动机寿命[3~5]。因此,在发动机运行期间预测EGT十分重要。
文献中发表了几种可以预测给定操作条件下EGT 的物理模型[6~7]。一般来说,物理模型包括缸内燃烧模型、传热模型和排气模型。然而,在燃烧后期发生的复杂现象[8]可能使传统物理模型难以准确预测EGT。如果考虑基于数据驱动的预测模型,采用机器学习算法来模拟燃烧过程、传热过程和排气冷却过程,则可以降低预测EGT 的复杂性。文献综述表明,相关模型已成功用于预测EGT[9~14]。总的来说,这些方法支持使用机器学习技术来构建快速、稳健的基于数据驱动的EGT 预测模型,进而协助或替代物理预测模型。尽管EGT 在发动机开发中很重要,但文献中使用机器学习技术预测EGT的研究数量有限,因此本文的目标是研究基于数据驱动的机器学习预测模型在预测EGT 方面的性能。鉴于难以为该任务先验地选择最合适的机器学习算法,评估了不同算法的预测性能,即人工神经网络(Artificial Neural Network,ANN)、随机森林(Random Forest,RF)、支持向量回归(Support Vector Regression,SVR)和门控循环单元(Gate Recurrent Unit,GRU)。总的来说,本文的结果有助于优化发动机性能、排放和寿命,同时能够对从事相关研究的学者有一定的借鉴意义。
2 机器学习算法简介
2.1 人工神经网络
基于数学计算,神经网络算法使用一组相互连接的人工神经元在发动机关键性能参数(燃油流量、滑油压力和转速)和排气温度之间建立非线性关系。如图1 所示,该模型使用了带反向传播算法(此处未显示)的3-N-1架构,隐藏层与输出层的传递函数分别为tansig和purelin。尽管在三层网络结构中没有选择隐层神经元数量N 的一般规则,文献[15]建议N=2n+1,n为输入变量的个数。
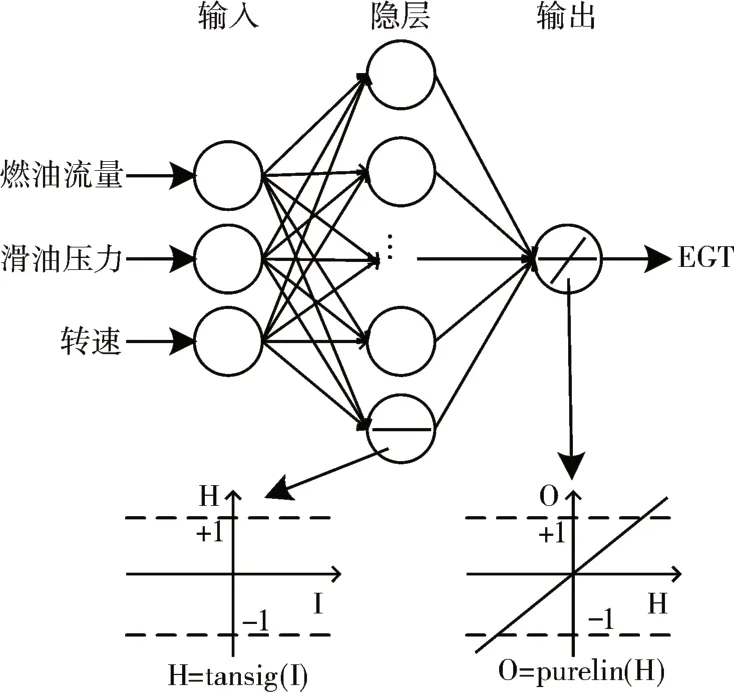
图1 人工神经网络模型示意图
神经元是人工神经网络的基本处理单元,执行两个功能:收集输入和生成输出。输入和输出之间的关系为
其中,wi为第i个输入Ii的权重;b为偏置;f(·)为激活函数;O为神经元的输出。多层前馈网络具有多层结构的神经元,可以在没有反馈连接的情况下单向传递信息。第l+1层的神经元j可表示为
其中,nij为第l层的所有神经元;wlij为连接第l层神经元i和第l+1 层神经元j的权重;blj为第l层神经元j的偏置。
反向传播算法通常用于训练前馈神经网络,它有规则地调整每个训练模型的权重,以最小化网络预测值与实际值之间的误差。在监督学习的过程中神经网络通过迭代的方式学习样本特征。训练网络需要设计合适的网络结构(如隐藏层的层数、每一层神经元的个数等)和超参数(如初始化权重、学习率、正则化参数等)以防止过拟合。
2.2 随机森林
与神经元和人工神经网络之间的关系类似,决策树是随机森林算法的基本处理单元。图2 显示决策树表示一组约束或条件,这些约束或条件按层次组织并从树的根依次应用到终端节点。在处理回归问题时,从数据集中执行递推分割和多元回归以形成决策树。从根节点开始,在树的每个内部节点中重复进行数据分割过程,直到达到之前指定的停止条件。每个终端节点或叶节点都有一个仅适用于该节点的简单回归模型。树的分枝过程一旦完成,就可以进行剪枝,目的是通过降低树的结构复杂性来提高树的泛化能力。

图2 决策树示意图
在决策树的形成过程中,决策树在所有候选分枝中搜索最佳分枝,以最小化结果树的“杂质”:其中,s是节点t处的候选分枝,i(t)为分枝前的“杂质”度量,Δi(s,t)为分枝后的“杂质”减少量。在该等式中,节点t被划分为左子节点tL(比例为PL)和右子节点tR(比例为PR)。基尼指数(Gini index,GI)通常用以衡量“杂质”:
其中,f(tX(xi),j)表示值为xi的样本属于叶节点j和中间节点t的比例,决策树以最小化基尼指数作为分枝标准。
随机森林是一种回归技术,它结合了众多决策树算法的性能来分类或预测变量的值。如果随机森林基于输入矢量{x} 构建了K个决策树,那么随机森林预测模型表示为
其中,Tk(x)为第k个决策树的预测,为所有决策树预测的平均值。
2.3 支持向量回归
支持向量机的基本思想是将输入特征转换为一个高维空间,其中两个类别可以由一个高维曲面线性分离,称为超平面[16]。假设一个训练数据集有N个样本和L个输入特征,对应于已知的输出特征,支持向量回归模型定义如下:
其中,φ是将输入数据映射到高维特征空间的非线性函数;w是垂直于超平面的权重矢量;b为超平面偏置。在软边界约束下,支持向量回归模型的优化定义了一个超平面,该超平面将具有最大边界的训练数据分离。该优化问题可以使用拉格朗日乘数法(Lagrange multiplier method)求解:
其中,γ为核参数。支持向量回归没有设计映射函数、转换数据并计算内积,而是直接将内核定义为输入特征向量的函数。通过引入核表示法,极大简化了该代价函数的优化问题。
2.4 门控循环单元
循环神经网络(Recurrent Neural Network,RNN)在处理时间序列数据时优势明显,作为RNN 的一种变体,长短期记忆网络(Long Short Term Memory,LSTM)增加了一种携带信息跨越多个隐含层的方法,从而防止较上层的信息在传递过程中逐渐失真。但LSTM 的隐含层结构复杂,训练样本的时间过长。门控循环单元在结构上简化了LSTM 网络的门设置,图3为门控循环单元示意图。
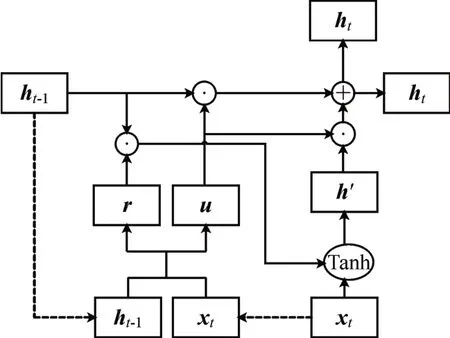
图3 门控循环单元示意图
图中,⊙表示矩阵点乘;⊕表示矩阵相加;Tanh为激活函数,将数据缩放到(-1 ~1) 的范围内;xt为t时刻的输入;ht-1、ht分别为上一节点传递下来的隐状态和当前节点的隐状态;r、u分别为重置门和更新门。门控更新过程为
其中,rt、ut分别为t时刻重置门与更新门的状态;Wr、Wu、Wh′、Wy为学习的参数矩阵;h'、yt分别为当前节点的中间状态和模型输出;σ为sigmoid函数;*代表矩阵点乘。第t个节点的隐藏状态聚集了前t个时间步的信息,用当前输入xt和上一节点传递下来的隐藏状态ht-1进行建模。
3 数据说明及预处理
笔者的前期工作收集了同一架次Cessna-172R 型飞机(使用一台活塞式发动机,型号为IO-360-12A)在约400次飞行训练过程中的机载传感器数据,传感器以离散形式记录数据,数据刷新频率为1Hz。该数据集记录了反映飞机当前性能和状态的52种飞行参数,其中包括7种与发动机直接相关的飞行参数,即油箱油量(FQty)、滑油温度(OilT)、燃油流量(FFlow)、滑油压力(OilP)、转速(RPM)、缸头温度(CHT)和排气温度(EGT),实测数据部分展示如表1所示。

表1 实测数据
由于过拟合会给机器学习模型的训练带来误差,因此需要进行特征子集选择。皮尔逊相关系数通常用来衡量特征之间的相关性[17],7 种飞行参数之间的皮尔逊相关系数如图4 所示。本文以燃油流量、滑油压力和转速作为输入,以建立用于预测EGT的机器学习模型,因为这些参数与EGT高度相关[18]。
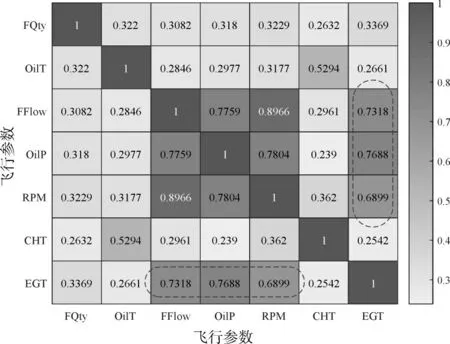
图4 飞行参数之间的相关系数
大约80%的数据用于训练机器学习模型,其余20%用于测试EGT 预测模型的性能。在评估机器学习模型性能期间,根据预测值与实际值之间的差异计算均方根误差(RMSE),以确定预测的精度和偏差。此外,决定系数(R2)用以衡量预测值与实际值的拟合优度。在统计学中,接近1 的R2和接近0的RMSE表示良好的预测性能。
4 机器学习算法性能评估
4.1 机器学习算法在预测EGT中的性能比较
本文使用贝叶斯优化方法获得机器学习模型的最佳超参数。贝叶斯优化已成为支持向量机或深度神经网络等机器学习算法超参数优化的成功工具。该算法在目标函数内部模拟高斯过程模型,通过评估目标函数来训练该模型[19]。贝叶斯超参数优化后,机器学习模型的一些关键超参数如表2所示。
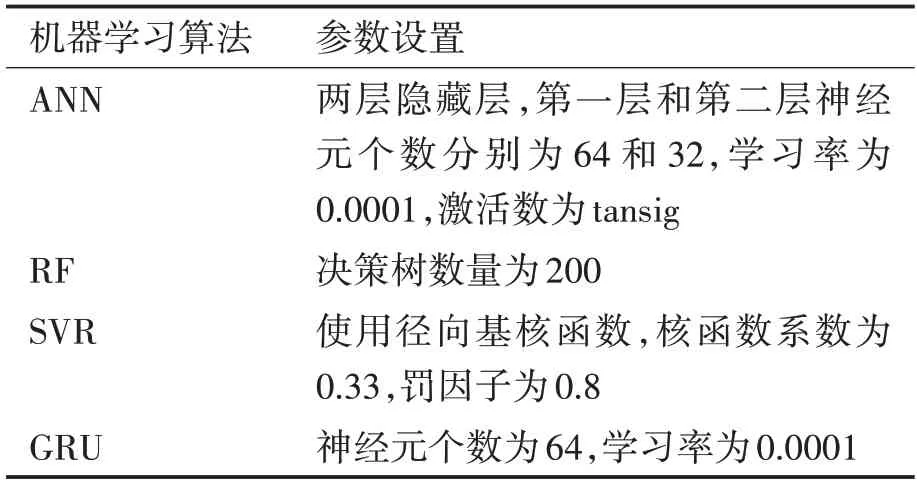
表2 机器学习算法关键超参数设置
超参数优化后训练机器学习模型,并在测试数据上验证EGT 预测模型的性能,结果如图5 所示。实际EGT和预测EGT分别绘制在x轴和y轴上。图5 表明预测存在可接受的偏差。为了帮助评估图5中的模型性能,阴影区域覆盖了误差在±1%(约为12deg F)以内的预测数据,几乎所有的点都聚集在45°对角线上。值得一提的是,接近1 的斜率和接近0的RMSE表明三个模型输入(即燃油流量、滑油压力和转速)足以预测EGT。

图5 机器学习模型预测性能
显然,GRU、ANN 和SVR 的预测性能优于RF,这表现在阴影区域内的点更多、斜率更接近1 且RMSE 更小。此外,RF 高估了EGT 较低的情况,但低估了EGT 较高的情况。尽管RMSE 和阴影区域内的点数几乎相同,但ANN 的表现略优于SVR,这可以通过更接近1 的斜率来证明。GRU 在这四种算法中表现最好,因为图5(d)中阴影区域内的点几乎成线性分布。
图6 在拟合优度上比较了四种机器学习模型的EGT 预测性能,此外,以每秒钟机器学习模型训练的样本数(samples per second,SPS)来衡量模型复杂度并给出对比结果。
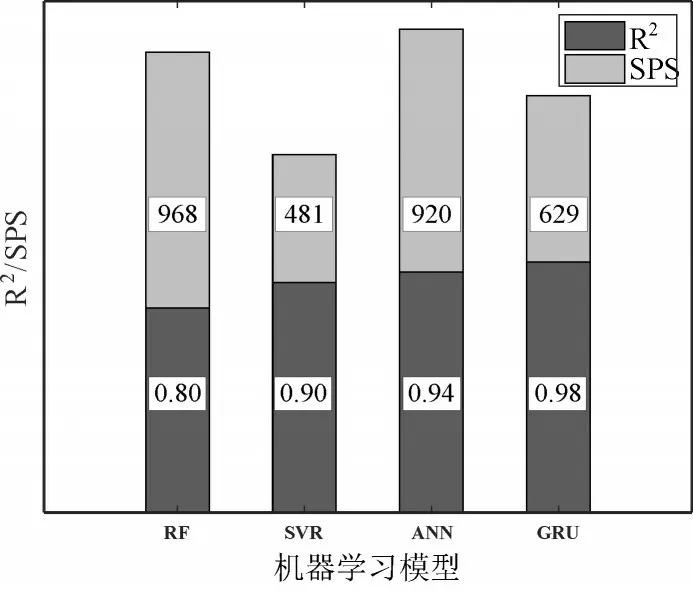
图6 模型的预测性能与复杂度对比
从拟合优度上评估模型预测性能,GRU 预测EGT的准确性最高,而RF算法的准确性最低,这与图5 得出的结论一致。然而,RF 算法的计算效率最高,与之相反,SVR 的计算效率最低但保证了较好的预测精度。如果经过良好训练,ANN 是最合适的EGT 预测算法,在预测精度和计算效率上均表现优异,这在EGT 实时预测时尤其重要。然而,ANN 在正确调整其超参数方面需要大量努力。
4.2 机器学习算法的抗噪能力
评估机器学习算法的抗噪能力也很有意义。实际情况下,数据样本中掺杂噪声信号是不可避免的,噪声信号的强弱将影响EGT 预测的准确性[20]。本文对模型的输入样本添加不同功率的噪声信号,用以模拟发动机在真实飞行环境下可能受到扰动而导致传感器记录的数据产生噪声。原始数据与噪声的功率比用信噪比(Signal to Noise Ratio,SNR)来描述:
其中,x(t)为原始数据;n(t)为噪声。在不同的信噪比条件下,对四种机器学习模型的EGT预测性能进行评估,结果如图7 所示。一般来说,所有机器学习模型的预测性能都随着信噪比的增加而提升,当信噪比在9dB~21dB 时,所有模型的预测性能显著提升。对于SNR 在15dB~30dB 的情况,GRU 在所有机器学习模型中表现最佳,但信噪比低于18dB 时,随着信噪比的降低,GRU 的预测性能快速下降,信噪比低于12dB 时,它的表现最差。因此,GRU 保证高预测性能的前提是模型输入需要高质量的无噪声数据。此外,在低信噪比(小于15dB)条件下,ANN 的预测性能优于其他机器学习模型。

图7 不同信噪比条件下机器学习模型的预测性能
4.3 机器学习算法的鲁棒性与泛化能力
为了说明机器学习算法的鲁棒性与泛化能力,从整个数据集中多次随机划分训练集和测试集,对文中提到的模型进行多次训练与测试。
图8(a)显示了使用四次随机选择的80%数据训练后的机器学习模型拟合优度。结果表明,无论训练集如何,机器学习模型都表现良好,相似的R2证明了这一点。在监督训练后,对其余20%数据进行EGT 预测。图8(b)表明,无论是在训练集还是测试集,机器学习模型都表现出了相似的拟合优度,这说明模型的预测性能从训练集泛化到测试集。总的来说,RF、SVR、ANN 和GRU 均是稳健EGT预测算法。

图8 分析机器学习模型的鲁棒性与泛化能力
5 结语
在燃烧后期发生的复杂现象可能使传统物理模型难以准确预测EGT。本文的目的是研究当使用燃油流量、滑油压力和转速作为模型输入时,用实测数据训练的机器学习模型是否有助于EGT 预测。鉴于难以为该任务先验地选择最合适的机器学习算法,评估四种经典机器学习回归算法在预测EGT方面的性能,即人工神经网络、随机森林、支持向量回归和门控循环单元。主要结论如下:
1)四种机器学习模型在可接受的误差范围内预测了排气温度,这表明三个模型输入(即燃油流量、滑油压力和转速)足以预测EGT。
2)模型性能相互比较时,门控循环单元的预测精度最高,但它通常需要高质量的无噪声数据;随机森林的精确度最低,但需要的计算资源最少;支持向量回归在耗费高计算资源的前提下保证了较好的预测精度;人工神经网络是最合适的预测算法,但它存在繁琐的超参数调整过程。
