基于人机交互的端对端手势识别控制框架的设计与实现
2023-08-26霍英陈台兴孙锦森张嘉明林鸿森
霍英 陈台兴 孙锦森 张嘉明 林鸿森

关键词:手势识别;MediaPipe;神经网络;人机交互
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)20-0017-03
0 引言
手势识别[1]和手部检测具有广泛的潜在应用,涵盖车内手势、手语识别、虚拟现实等领域。手势技术使得用户可以在不接触设备的情况下实现控制或互动,因此越来越受到人们的关注和青睐。然而,互联网上的手势识别模型虽然众多,但它们只适用于特定的手势集,缺乏规范和架构设计,最终难以为用户提供方便的使用和构建体验。因此,文章提出了一种端对端、可扩展的框架,允许用户使用手势实时控制计算机系统,实现人机交互[2]。该框架在不同的硬件(CPU/GPU) 和操作系统上工作,并依靠一个中等分辨率的摄像头来检测手势。该框架使用手势技术代替鼠标操作和键盘快捷键,让用户能够通过手势轻松控制桌面。此外,还提供了一个易于使用的配置,用户可以重新映射手势和动作,添加新的自定义动作和手势。
该框架设计了两种手势类型:静态和动态。静态手势指的是单一的手部姿势就能够提供足够的信息来进行分类的手势,例如“V字”手势。而动态手势[3]则不能仅通过一个姿势来检测,需要一连串的姿势才能被理解和分类。例如,在移动手的同时保持手型姿势的手势“( 向上滑动”) ,或者是涉及连续改变手姿势的手势“( 捏”) 。通过将手部运动与连续的姿势变化相结合,可以创造出大量的动态手势。
该框架采用了模块化设计,将其分为若干逻辑组件,每个组件执行特定任务。手势接收器从图像中获取关键点,将其传递给手势识别器,后者使用神经网络对静态和动态手势进行分类。最后,手势执行器执行分类结果的动作。该框架的关键特点是,它具有高度的可定制性。除了内置的鼠标和键盘功能,用户还可以将手势映射到任何桌面操作上,包括Shell等脚本。这使得该系统的使用方式非常灵活。用户可以将手势用于启动应用程序、设置环境等。此外,框架还提供了一种添加新手势的方法,以满足用户不同的需求。
1 准备工作
1.1 识别方法
通过查阅资料,研究者发现了许多关于从静态图像或视频中进行手势识别的文献。这些解决方案通常可以分为以下几类:1) 通过相机或传感器提供纯RGB图像与深度数据(RGB-D) ;2) 通过检测手部关键点(手掌和手指关节)作为中间步骤或直接从视频中执行端到端检测;3) 将检测关键点作为最终目标,而不是手的三维重建[4];4) 手势是预先分割的或必须实时分割的[5]。
基于上述研究,研究者采用单目RGB视频流,并将其输入一个两阶段的神经网络架构。在第一阶段中,使用现成的MediaPipe[6]框架从单个视频帧中检测手部关键点,并生成一个手部关键点序列。在第二阶段中,使用自己的神经网络模型对这个关键点序列进行静态和动态手势的检测。
1.2 识别框架
手势识别在多种领域中有着广泛应用,例如虚拟界面控制、游戏、增强现实/虚拟现实环境交互、汽车人机界面、家庭自动化、教育、零售商业环境以及消费电子产品控制等。手势的高表达性和直观性使其成为这些应用中非常有价值的交互方式。尽管手势识别市场正在快速增长,但几乎没有任何端到端的开源手势识别框架。GRT是一个例外,这是一个为实时手势识别而设计的C++机器学习库,它提供了创建自定义识别器的构建模块。相比之下,研究者使用神经网络作为构建模块,并采用PyTorch[7]框架进行模型开发,可以进一步提高手势识别的准确性和效率。
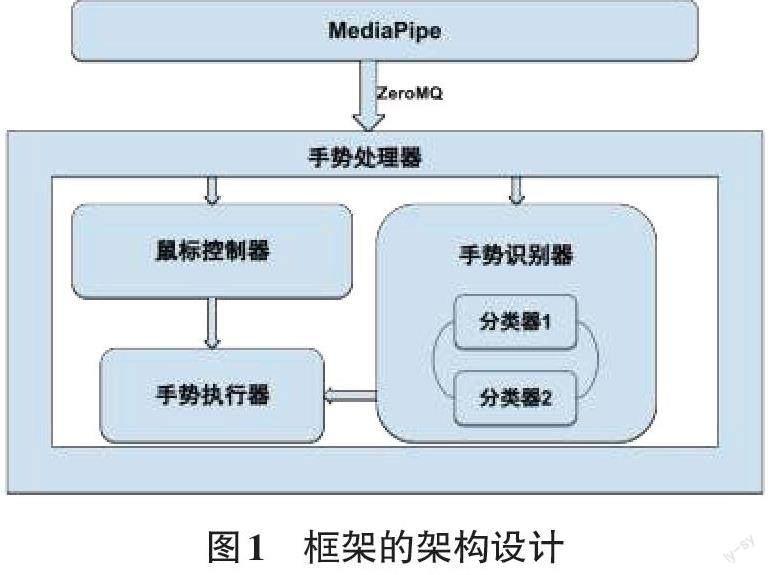
2 架构设计
研究者利用开源框架MediaPipe来检测摄像头捕捉的图像中的手部关键点。MediaPipe模块从摄像头读取数据,进行处理并生成关键点,接着通过ZeroMQ (一种消息传递队列)将其传输给手势接收器。手势接收器接收关键点后将其传输给手势识别器,后者对其进行特征编码,并送入神经网络进行手势检测。最后,手势接收器将检测到的手势发送到手势执行器,以执行相应的动作。
2.1 MediaPipe
一个跨平台框架,提供各种机器学习解决方案。MediaPipe中的手部跟踪器[8]是一个高保真的解决方案,可以从单一图像中推断出手部的21个三维坐标,跟踪平滑,能够应对自我封闭的情况,也就是手覆盖自身。在使用其手部跟踪功能时,它能够跟踪用户的手掌并生成手部坐标或关键点。
2.2 手势接收器
手势接收器充当其他模块的控制器。它能够从MediaPipe模块接收到关键点,并将其传递给手势识别器和鼠标跟踪器进行处理。随后,它将处理后的输出(即手势名称)传递给手势执行器,以执行相应的操作。
2.3 手势识别器
手势识别器是一个核心模块,用于对给定的关键点进行手势分类。为此,框架使用了两个神经网络,一个用于检测静态手势,另一个用于动态手势。这些神经网络的结构和训练细节将在后续章节中详细介绍。通过这些神经网络的处理,框架能够对手势进行准确的分类,并将分类结果传递给其他模块以执行相应的操作。
2.4 鼠标追踪器和手势执行器
鼠标追踪器模块能够实时追踪用户手指在屏幕上的移动,并将其映射到光标的移动。通常情况下,使用食指尖端作为追踪鼠标的关键点。随着手指的移动,追蹤器可以将其在屏幕上的运动投影到光标的移动上。
手势执行器模块接收手势识别器所识别的手势名称作为输入,并根据预定义的手势动作映射表执行相应的操作。框架预先定义了一小部分手势及其对应的动作,以涵盖常见的使用情况。
3 手势识别器
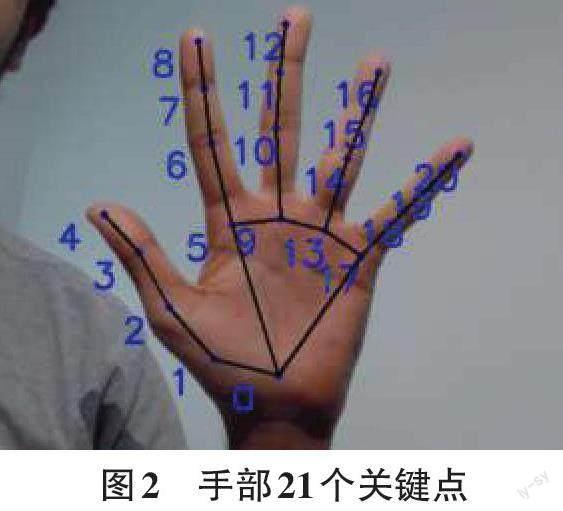
手势识别器的输入是由MediaPipe生成的21个三维关键点,每个关键点对应于手上的一个位置。每个关键点由三个坐标组成,分别表示该点在三个维度上的位置(x,y,z )(x,y,z )。因此,手势识别器的输入向量是一个长度为63的向量。这些输入向量经过预处理,被转换为神经网络期望的特征,以便进行手势分类。具体如下所述:
3.1 静态手势
3.1.1 特征提取
由MediaPipe生成的21个关键点被转换为神经网络所需的向量。该向量是通过计算相对手部向量得出的,即输入关键点之间的向量差。这些相对向量以一种位置不变的方式编码手的姿势信息,也就是说,无论手在网络摄像头的视野中处于什么位置,都能检测到相同的手势。以第一个相对手部向量(从手掌底部到拇指的第一个关节)为例,可以通过以下方式计算得出:
其中,V0V0和V1V1代表图2中标有0和1的点的三维坐标,V01V01代表它们之间的相对向量。通过计算一共有16个相对的手部向量(拇指4个,其他手指3 个),每个手部向量由(x,y,z )(x,y,z ) 坐标组成,总共有48个坐标。最后,添加上标志手,即执行手势的手,这个49-D向量被送入神经网络。
3.1.2 数据集
在进行网络训练时,研究者收集了自己的数据,并创建了一个小型的数据集。研究者采用了以下方法收集这些数据:首先指定手势的名称,然后执行Me? diaPipe 框架并捕获关键点。这些关键点被记录在CSV文件中,并与相应的手势名称一起使用。对于每个手势,收集了约2 000个样本。虽然实现静态手势相对简单,但手只能做出有限的姿势,具有一定的局限性。因此需要收集动态手势的数据以提高模型的泛化能力。
3.2 动态手势
3.2.1 特征提取
为了提取特征向量,将输入序列中的每一帧转换为一个向量,该向量由以下内容组成:手掌底部的绝对坐标,即V0xV0x和V01yV0y。这是因为一些手势,如“向上刷”“向右刷”,涉及手的移动;手掌底部的时间坐标。这包括该坐标相对于上一个时间段的位置变化,从而获取手势方向信息;相对手部向量的坐标。与静态情况类似,这些坐标用于捕捉手的姿势。
3.2.2 数据集
为了训练动态手势识别模型,使用SHREC[9]数据集。这个数据集包含2 800个序列,包括14种手势,如“向上滑动”“点击”等常见手势,以及“滑动+”等更复杂的手势。这些序列是可变长度的,由多人以两种方式进行采集:使用整个手掌或只使用手指。为了收集更多数据,框架还提供一个脚本,用于记录动态手势的数据。
4 模型训练和结果分析
通过PyTorch-Lightning 框架来建立神经网络分类器。PyTorch-Lightning是一种开源深度学习框架,它提供了模块化的模型开发工具,让用户能够快速地构建神经网络。该框架提供了训练、验证和测试等功能,同时也支持分布式训练。其优点是可扩展性强、易于使用、性能良好等。使用该框架能够显著减少代码量,并加快开发速度。
4.1 静态手势
为了检测静态手势,使用一个具有两个线性层的前馈神经网络分类器,该分类器接收特征向量并将其归类为可用的手勢之一。该网络经历了大约50次迭代,训练后的混淆矩阵如图3所示。虽然无法记录所有可能的静态手势,但考虑到后续用户的扩展性,研究者采用了一些处理方法以解决数据不平衡的问题。除了相关的手势集,还引入了一个“空”手势,如果没有检测到相关的手势,就会选择这个手势。为了训练分类器,收集了各种不相关的静态手势,并将它们标记为空。尽管这提高了分类器的性能,但仍然出现许多假阳性的情况。为了解决这个问题,通过对“空”手势的得分进行缩放,手动校准分类器的softmax输出。
4.1.1 实验结果
这些优化使静态分类器能够在多个用户和不同的照明条件下达到很高的检测精度,并取得了验证准确率为98.52%的良好性能。此外,研究者还对响应时间进行了检测,发现没有明显的延迟。
4.2 动态手势
为了更准确地检测动态手势,采用由线性层组成的递归神经网络,与双向GRU相连,对传入的特征进行编码。在检测动态手势时,关键问题在于准确计算手势的起始和结束时间。为了避免这个问题,研究者使用信号键来表示手势的起始和结束,并将键盘中的“Ctrl”键用作信号键。这种方法能够处理不同长度的手势,并减少错误分类的数量。除了SHREC提供的手势外,研究者还使用这种方法增加了一个名为“圆圈”的手势。尽管“圆圈”是一个复杂的手势,但网络在测试期间能够准确检测出该手势,这表明网络也能成功地应用于其他手势。
4.2.1 实验结果
研究者使用混淆矩阵对各种手势进行了分类和评估,结果如图4所示。图4表明,动态手势的性能比静态手势低,平均准确率约为85%。这是因为动态手势涉及两个因素:手的姿势和手随时间的位移。从混淆矩阵中可以看出,那些涉及手部位移的手势(如“滑动”) 被准确地检测出来,而那些涉及手指方向变化的手势(如“点击”) 则相对较难。
在多次测试中,出现领域不匹配的问题。具体来说,研究者使用了由RGB相机捕获的数据流进行测试,而SHREC数据集是由英特尔RealSense深度相机记录的。由于这种领域不匹配,框架在测试过程中失去了一定的准确性。为了解决这个问题,研究者计划改进特征计算方法,并使用更大、更具代表性的数据集进行训练。通过这种方式,可以提高模型的准确性和可靠性,以更好地适应各种不同的环境。
5 结论
文章提出了一个基于人机交互的端对端手势识别控制框架,其可以通过用户的偏好进行定制。除了提供一个全功能的键鼠替代品外,框架还支持自定义手势和动作的添加,以便用户在不同的环境下使用。未来,研究者的目标是通过提高检测精度进一步改进这个框架,使得增量训练新手势更加有效,并进行用户研究以评估框架的可用性。
