数据库信息管理系统的逻辑架构与功能设计探析
2023-08-26胡劲
胡劲


关键词:信息管理系统;数据库;逻辑架构;功能设计;调优
0 引言
通过对信息管理系统数据库产生瓶颈的原因进行反复研究分析,主要存在不同量级的数据优化的思路不同,数据的量级随着时间的推移而提高。大部分系统分析师一般只对遇到的当前量级数据逐步提出优化方案,例如:1万级无须优化、10万级排查数据结构的合理性、100 万级建立合理的索引[1]。这种优化思路形成了反复对性能修复补丁,并没有一次性解决问题,每个量级的数据性能修复补丁变得更加艰难。
1 基于不同量级数据优化的改进
为了确保数据库结构的统一原则,在逻辑设计阶段表与表之间经常会设计过多的关联,尽可能地减少数据冗余。但在实际应用中,虽然数据冗余低会使数据的完整性得到保证,提高了数据吞吐率,能够清晰地表述出数据属性之间的关系,但当数据库足够庞大的时候,多表之间关联频繁会降低查询性能,加大了客户端程序编程的难度[2];因此,在物理设计阶段,需要根据实际业务需求确定相互存在关联数据表的最大数据容量和字段属性的访问频次,对此类数据表做频繁关联查询,适当并合理地提高数据冗余,为了提高查询性能、系统响应速度,合理提高数据冗余是必须的[3]。真实系统的数据库设计阶段应该根据字段类型、查询语句、算法、索引等多方面进行权衡考虑。
2 实验对比
2.1 数据表设计的优化
1) 数据库表命名将业务表与基础表区分,采用集成基础库分布式数据库设计思路;
2) 字段的类型选择优先级数字、浮点、字符、文本、二进制,能够使用基本类型的尽量选择基本类型,如果强行选择其他优先级低的数据类型会增加存储开销,降低查询和连接的性能;
3) 谨慎区分char 和nvarchar 两种字符类型,不可变长字符类型char 查询速度快,增加硬盘的存储空间,可变长字符类型nvarchar查询慢一点,节省硬盘存储空间;在设计字段的时候可以灵活选择,针对内容固定长度的数据选择char,内容长度变化差距很大数据选择nvarchar;
4) 字段长度设计时,应该根据实际业务需求的最大限度前提下尽可能地简短,满足需求即可,这种做法可以大大提高查询性能,在建立字段索引时也能减少资源的消耗。
2.2 查询的优化
1) 程序在確保功能实现的基础上,对数据库访问建立的连接次数尽可能地少,并且每次数据库连接使用结束之后必须关闭连接,做到建立连接和关闭连接一一对应;
2) 尽量避免向用户端返回过多的数据量,如果数据量较大,应该考虑业务需求分析是否合理,通过查询条件,尽可能缩小对数据表的访问行数和结果集,从而降低网络传输过程的压力;
3) 尽量避免使用select*from Table,一定要用具体的字段名的列表来代替“*”,无须返回业务逻辑中用不上的任何字段;
4) 构建SQL 查询语句时,尽可能把要求使用的索引放在where条件的首列;
5) where条件语句中的等于(=) 运算不要在左边进行函数、算术或表达式运算,否则数据库索引可能会失效;
6) 避免使用游标,因为游标的效率较差,当游标操作的数据大于1万条时,应该考虑改写。
2.3 算法的优化
SQL 语句中经常需要融合复杂的算法来解决业务逻辑问题,数据库越大,算法的瓶颈越容易暴露出来。在此,针对不同的分页语句在不同的数据量级别进行测试分析,优化实验结果如下。
2.4 合理建立高效的索引进行优化
SQL Server 数据库建立索引有两个目的:确保索引字段的唯一性、实现快速查询数据的目的。企业级数据库系统都包括聚集索引和非聚集索引两种索引,非聚集索引的表的数据是根据Heap 结构存储的数据,将全部数据添加在表的尾部,聚集索引的表的数据是根据索引字段的顺序存储,并且数据表的聚集索引有唯一性。
聚集索引:数据库表的数据是根据索引字段的顺序存储,索引项的顺序与表中记录的物理存储顺序必须保持一致;对于聚集索引不需要再有另外单独的数据页,因此,每张数据表中最多只能创建唯一的一个聚集索引[4]。
非聚集索引:数据库表的数据记录存储顺序与索引字段顺序无关,非聚集索引采用叶结点的数据页和数据行中逻辑指针指向索引字段值。因此,逻辑行数量与数据表行数据量完成保持一致[5]。
1) 建立高效索引的思路;
2) 结合实际情况浅谈索引使用过程中的误区。
理论的目的是应用,应用次数越多,经验越丰富。
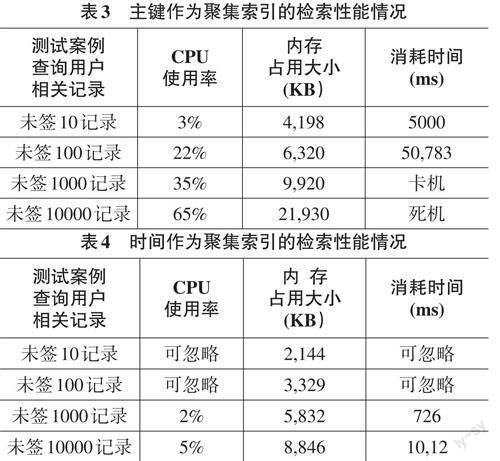
误区一:主键就是聚集索引
通常习惯在每个数据表中建立一个自动增长的TableKey 列或以Gid 为值的列为主键,像SQL Server 数据库系统就会将它默认为聚集索引,类似于这样的聚集索引并不能完全发挥最大的性能优势;要想使用聚集索引达到最大性能优势,应该根据查询中的条件缩小范围和避免全表扫描,某种情况下使用TableKey 主键作为聚集索引是一种资源浪费[6] 。
在无纸化网络办公系统的公文、会议、督办等模块中,无论是首页提示用户待签收的公文、会议提醒、督办提醒,还是用户进行已办公文、会议、督办等查询操作,只要是按需进行数据查询都将离不开字段的是“时间”和用户的“人员ID”。
误区二:建立索引就一定能够提高数据查询的性能与速度
两条完全相同的SQL 语句:select TableKey from 0T1ab-l2e1 w,h并ere且 时针间对>同一20个22-da0t1e- 字20段a建nd立 时索间引<;索20引22区-别一种是对“时间”字段建立非聚集索引,两种方案是对“时间”字段建立聚集索引,两种查询速度有着很大的差距。所以,并不是所有字段上只要建立索引就一定能够提高查询性能与速度[7]。
要想建立合适的索引,应该根据数据的分布情况加以分析,例如:无纸化网络办公系统公文表中有着百万级数据量的“时间”字段,有着上千条不同日期的记录,同一个日期又存在若干条公文记录,根据建立高效索引的思路得出在此字段上建立聚集索引是最佳的选择。
误区三:只要提高数据查询性能与速度的字段就全部加聚集索引
SQL Server 虽然只能建立一个唯一的聚集索引,但经常会出现同时多个字段都需要建立聚集索引的情况,这时通常可以把他们合并一起建立一个复合索引,也并非所有的字段都适合加入聚集索引,需要根据实际情况权衡选择。
复合索引查询性能的主要体现是查询条件中是否用到索引中的全部列。比如:根据无纸化网络办公系统公文中的“人员ID”和“时间”字段,通过分析这两个字段非常重要,并且基本上都会同时出现在查询条件当中,那么就可以将它们合并建立一个复合的聚集索引,并且“时间”为起始列、“人员ID”排在后列[8]。
3) 其他事项
只有建立合理的索引才有利于提高数据查询的性能,如果过多或者不当的建立索引会导致系统产生更严重的瓶颈,因为每一个索引都会导致存储空间的增加和数据库会做更多复杂的工作,并且产生大量的索引碎片。所以,要想建立一个合理的索引体系,需要融合更多的实战应用分析,结合调优结果精益求精建立索引,才能使数据库的性能达到最佳的状态。
3 结论
综上所述,通过大型信息管理系统中的数据库设计和优化进行反复论证,本文针对数据库设计和优化提出以下几点思路:1) 数据表中每一个字段的设计都必须非常严谨,比如数据类型选择、长度设计等;2) 查询语句的优化是SQL效率优化的一个方式,可以通过优化SQL语句来尽量使用已有的索引,避免全表扫描, 从而提高查询效率;3) 不断优化复杂的算法来解决数据量大的业务逻辑问题;4) 建立最合理的索引体系可以大大提高系统的性能。
